



💫 易用,高效,统一的全管道自动时间序列分析工具,支持时间序列预测,分类,回归以及异常检测。
亲爱的朋友们,我们在为热爱AutoML/NAS的专业人士和学生提供具有挑战性的机会。目前,我们的团队遍布北京(总部)、上海,成都,美国等世界各地,欢迎有志之士加入我们的团队DataCanvas Lab! 请您发送您的简历到 yangjian@zetyun.com.
HyperTS是一个Python工具包,提供了一个端到端的时间序列分析工具。它针对时间序列任务的整个AutoML流程实现了灵活的全覆盖,包含数据清洗,数据预处理,特征工程,模型选择,超参数优化,结果评估以及预测曲线可视化等。
多模驱动, 轻重结合是HyperTS的关键特性。因此,您可以随意切换统计(+机器学习), 深度学习及神经架构搜索等模式来获得强大的评估器。
简单易上手的API。您可以简单操作创建一个实验,然后run()它,便会获得一个最佳的全pipeline模型。然后针对得到的model执行.predict(), .predict_proba(), .evalute(), .plot()等操作来对做各种各样的时间序列结果分析。
提示:
- Prophet是被HyperTS需要的, 当您使用
pip安装HyperTS前建议先使用conda安装Prophet。 - Tensorflow对于HyperTS是可选依赖, 如果您使用到深度学习及神经架构搜索模式, 请安装tf。
HyperTS在Pypi上可用,可以使用pip安装:
pip install hyperts您也可以安装HyperTS通过conda的conda-forge通道:
conda install -c conda-forge hyperts如果您想体验最新的功能, 您可以通过如下方式从github安装:
git clone git@github.com:DataCanvasIO/HyperTS.git
cd HyperTS
pip install -e .
pip install tensorflow #optional, recommended version: >=2.0.0,<=2.10.0更多安装细节及注意事项,请看 安装指南.
| 中文文档 / 英文文档 | 描述 |
|---|---|
| 数据规范 | HyperTS期待什么样的数据? |
| 快速开始 | 如何快速正确地使用HyperTS? |
| 进阶之梯 | 如何释放HyperTS的巨大潜能? |
| 自定义化 | 如何定制化自己的HyperTS? |
时间序列预测
您可以使用make_experiment()快速创建并运行一个实验,其中train_data和task作为必需的输入参数。在以下预测示例中,我们告诉实验这是一个多变量预测任务,开启stats模式(统计),因为数据包含时间戳和协变量列,因此timestamp和covariates参数也必须传给实验。
from hyperts import make_experiment
from hyperts.datasets import load_network_traffic
from sklearn.model_selection import train_test_split
data = load_network_traffic()
train_data, test_data = train_test_split(data, test_size=0.2, shuffle=False)
model = make_experiment(train_data.copy(),
task='multivariate-forecast',
mode='stats',
timestamp='TimeStamp',
covariates=['HourSin', 'WeekCos', 'CBWD']).run()
X_test, y_test = model.split_X_y(test_data.copy())
y_pred = model.predict(X_test)
scores = model.evaluate(y_test, y_pred)
model.plot(forecast=y_pred, actual=test_data)
时间序列分类 (点击拓展)
from hyperts import make_experiment
from hyperts.datasets import load_basic_motions
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
data = load_basic_motions()
train_data, test_data = train_test_split(data, test_size=0.2)
model = make_experiment(train_data.copy(),
task='classification',
mode='dl',
tf_gpu_usage_strategy=1,
reward_metric='accuracy',
max_trials=30,
early_stopping_rounds=10).run()
X_test, y_test = model.split_X_y(test_data.copy())
y_pred = model.predict(X_test)
y_proba = model.predict_proba(X_test)
scores = model.evaluate(y_test, y_pred, y_proba=y_proba, metrics=['accuracy', 'auc', f1_score])
print(scores)时间序列异常检测 (点击拓展)
from hyperts import make_experiment
from hyperts.datasets import load_real_known_cause_dataset
from sklearn.model_selection import train_test_split
data = load_real_known_cause_dataset()
ground_truth = data.pop('anomaly')
detection_length = 15000
train_data, test_data = train_test_split(data, test_size=detection_length, shuffle=False)
model = make_experiment(train_data.copy(),
task='detection',
mode='stats',
reward_metric='f1',
max_trials=30,
early_stopping_rounds=10).run()
X_test, _ = model.split_X_y(test_data.copy())
y_test = ground_truth.iloc[-detection_length:]
y_pred = model.predict(X_test)
y_proba = model.predict_proba(X_test)
scores = model.evaluate(y_test, y_pred, y_proba=y_proba)
model.plot(y_pred, actual=test_data, history=train_data, interactive=False)时间序列元特征提取 (点击拓展)
from hyperts.toolbox import metafeatures_from_timeseries
from hyperts.datasets import load_random_univariate_forecast_dataset
data = load_random_univariate_forecast_dataset()
metafeatures = metafeatures_from_timeseries(x=data, timestamp='ds', scale_ts=True)更多示例及使用技巧,请移步: 中文示例.
HyperTS支持以下特性:
多任务支持: 时间序列预测、分类、回归以及异常检测。
多模式支持: 大量的时序模型,从统计模型到深度学习模型,再到神经架构搜索。
多变量支持: 支持从单变量到多变量时间序列任务。
协变量支持: 深度学习模型支持协变量作为时间序列预测的输入特征。
概率置信区间: 时间序列预测可视化可以显示置信区间。
多样化的预处理过程: 异常值裁剪,缺失时间补齐,缺失值填充,序列平滑,归一化等。
丰富的指标: 从MSE、SMAPE、Accuracy到F1-Score,多种性能指标来评估结果,指导模型优化。
强大的搜索策略: 采用网格搜索、蒙特卡罗树搜索、进化算法,并结合元学习器,为时间序列分析提供了强大而有效的管道。
贪婪融合: 精细化的贪婪融合组合出最强大的模型。
交叉验证: 多种时序交叉验证策略保证模型的泛化性。
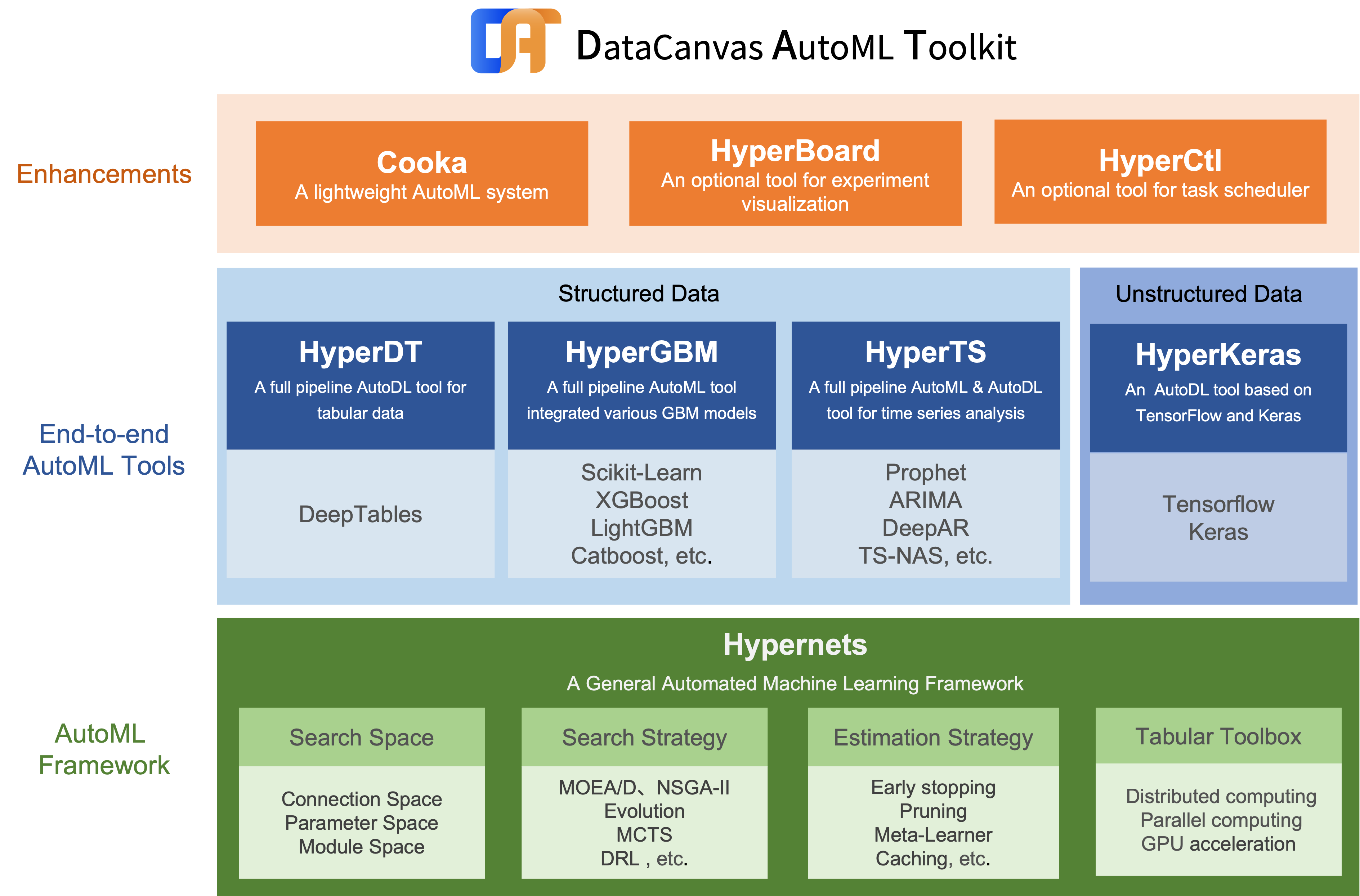
- Hypernets: 一个通用的自动机器学习框架。
- HyperGBM: 一个集成了多个GBM模型的全Pipeline AutoML工具。
- HyperDT/DeepTables: 一个面向结构化数据的AutoDL工具。
- HyperTS: 一个面向时间序列数据的AutoML和AutoDL工具。
- HyperKeras: 一个为Tensorflow和Keras提供神经架构搜索和超参数优化的AutoDL工具。
- HyperBoard: 一个为Hypernets提供可视化界面的工具。
- Cooka: 一个交互式的轻量级自动机器学习系统。
如果您想引用HyperTS在您的研究中,请使用下面信息:
Xiaojing Zhang,Haifeng Wu,Jian Yang. HyperTS: A Full-Pipeline Automated Time Series Analysis Toolkit. https://github.com/DataCanvasIO/HyperTS. 2022. Version 0.2.x.
BibTex:
@misc{hyperts,
author={Xiaojing Zhang,Haifeng Wu,Jian Yang.},
title={{HyperTS}: { A Full-Pipeline Automated Time Series Analysis Toolkit}},
howpublished={https://github.com/DataCanvasIO/HyperTS},
note={Version 0.2.x},
year={2022}
}
![]()
HyperTS是由数据科学平台领导厂商 DataCanvas 创建的开源项目。