A C++ dominant framework for pulling real-time data via public endpoints from six crypto exchanges to compute a crypto currency arbitrage that is both mathematically profitable and a proper amount to trade to get realistic profitability. The framework can detect bilatreal, trilateral, quadliteral, and pentalateral arbitrages from a single set of crypto currency data.

Pulling active ticker data and select orderbook data via public API endpoints from all trading pairs across 6 crypto exchanges is about 2.7 MB of JSON string data per pull. That is about 46.6 GB of ticker and orderbook data per day from only 6 exchanges. This framework downloads active ticker data, parses active ticker data, performs arbitrage finding, formats the arbitrage path, downloads relevant orderbook information, and determines realistic profitability. Most of these operations are expensive, time consuming operations that in the end will net a path that is deemed profitable. If the path takes too long to compute the profitability/trading opportunity may have disappeared.
For the reason that speed is royalty in this situation, C++ is used on all time dominant operations and all operations that could have benefited from embarrassingly or data parallelism were accommodated. On my own hardware, the time dominant factor of this framework is downloading json data from public endpoints. Over 99% of time is spent simply downloading ticker and orderbook data, which is both good and bad, see time break down soon. Operations acting on operable data are efficient, which makes the framework suffers from outside factors that can not be avoided without additional hardware or data costs.
Install all libraries*
$ sudo apt-get install make cmake nlohmann-json3-dev curl python3 pip$ pip install requests bs4$ cd Framework$ bash shell_driver.sh- shell_driver.sh will initializes the framework by building, compiling, and applying user selected options
* commands given for Linux Debian environment
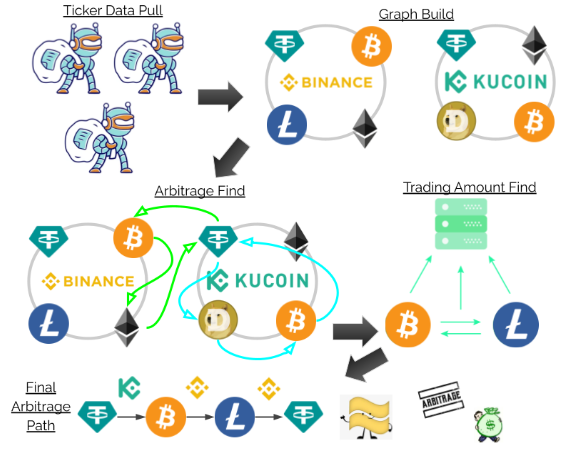
The project is set up into five main section crypto ticker data pulling, graph building, arbitrage finding, orderbook data pulling, and trading amount determination
A Crypto Currency arbitrage refers to the practice of buying and selling cryptocurrencies across different exchanges or markets to take advantage of price discrepancies and make a profit.
The mathematical formula for an arbitrage is
For numerical stability with floating point operations, the formula can be converted to
With trading fees included,
Every set of Trades that satisfy this inequality is considered a profitable arbitrage by purely ticker data. However, there are many sets of trades with a profitability of less than 0.1%, which may be ideal for a high frequency traders but are not viable for an average trader
Adding a lower bound profit threshold allows for a certain degree of profitability before a arbitrage path is said to be viable by an individual user,
- LowerThreshold is percentage expressed as a decimal
- An UpperThreshold of default 200% profitability is implemented to avoid looping over outdated ticker and orderbook data
To find sets of trades that satisfy the equation above, the arbitrage_finder.hpp implements a brute force path searching algorithm from a given source coin. As every arbitrage path starts and ends with the same coin, each path is a cycle within the graph data structure being used.
Within this graph data structure, each vertex is a tradable crypto currency and each edge away from said vertex is a trading pair available on some exchange. There may be multiple edges from one vertex to another and that equates to a trading pair offered on multiple exchanges. The end goal of discovering an arbitrage path is to complete the trades in the path as soon as possible on relevant exchanges. To do this, a user will end up overspending the average user by placing bids at or above ask price and asks at or below bid price to create the best chance to for automatic order completion. This structure choice makes edge weights in a trading pair the ask price from the start currency to the end currency and bid price for the vice versa.
As the arbitrage path finding algorithm satisfies the mathematical formula described above based on ticker prices, the path falls prey to discovering paths that are profitable by ticker data, but the order book lacks liquidity to support a similar profitability. The path may be profitable by ticker data but is fruitless without knowing how much one should trade.
The ideal trading amount algorithm takes the path found by the arbitrage finding algorithm and determines an upper bound for a trading amount. The algorithm will peak into the top-N, N is specified by the user, active trades in the orderbook for each trade in the path. Looking into each of these active trades will allow the algorithm to recognize trading pairs with low liquidity on either the bid or ask side.
The result of this algorithm will determine a realistic profitability, the corollary slippage rate from ticker profitability, and the amount of source capital the user should trade.
As seen in framework usage, this framework is driven by a shell script
This shell script generates a user setting file from user input, if one is not already present. Described below are each setting. Once user settings are generated, the arbitrage framework can be used freely and these user settings can be updated at any time. A sample user_setting.txt file is provided here for reference or if the generate_user_settings.py proves to cause unintended behavior or is hard to use for a user.
Parameter: pathLen
Type: Int
Sets the arbitrage path length the arbitrage finding algorithm will search. In practical terms, set the number of trading pairs in a given arbitrage sequence the framework is allowed to search through. Choice between length 2, 3, 4, or 5.
Parameter: startCoin
Type: String
Sets the arbitrage path start and end value. Each arbitrage is a cycle in a graph data structure and the startCoin or source coin is the start and end of that cycle. Profitability will be determined based on the starting amount of this coin
Parameter: tradeAmt
Type: Double
Sets the minimum trading amount value of each trade in an arbitrage path in terms of the startCoin currency. All of 6 supported exchanges have a minimum trading amount value for each market order, which equates to roughly 10-20 USDT. By default, the tradeAmt is set the value of 20 USDT in the startCoin currency the user selects.
Parameter: exchangeRemove
Type: list[String]
Sets the exchanges the user wishes to remove from data pulling. It is suggested to remove Binance, if using this framework from a US IP Address. Removing exchanges will speed up all operations, but will decrease the amount of possible arbitrages and potentially overall profitability.
Parameter: lowerBound
Type: Double
Sets the minimum profitability threshold for a arbitrage path to be deemed as profitable. A 0.03 lowerBound refers to a profitability of 3% before an arbitrage path is deemed as profitable.
Parameter: coinReq
Type: Int
Sets the number of coins to request from the CoinGecko API. An API request is made to retrieve the top coinReq by 24hr trading volume using the request_coingecko_api.py script.
Parameter: volReq
Type: Double
Sets the minimum 24hr trading volume to request for each coin requested via the CoinGecko API. An API request is made to retrieve the top coinReq by 24hr trading volume using the request_coingecko_api.py script.
Parameter: debugMode
Type: Int/Boolean
Places the arbitrage framework into debug mode. Facilitates all features of the framework for exactly one successful arbitrage find. Debug mode will print important arbitrage log information such as graph size, arbitrage path information, orderbook parsing, and ideal size finding.
Parameter: timeMode
Type: Int/Boolean
Places the arbitrage framework into time mode. Facilitates all features of the framework to benchmark the time dominant operations of the framework. These operations include ticker data pulling, arbitrage finding, orderbook pulling, and ideal amount finding.
Parameter: orderBookDepth
Type: Int
Sets the depth to request from each trading pair orderbook when determining realistic profitability and price slippage in the ideal trading amount algorithm. The higher the depth the longer each API request will take to generate and download. It is also unlikely that orderbooks will have a large amount of active trades (250+), if it is not a extremely popular trading pair. It is also worth noting that the deeper one looks into an orderbook for potential trading liquidity the more spread one will deal with.

Pinging and downloading ticker and orderbook data via public exchange endpoints takes a lot of time that cannot be avoided. Each public endpoint web request will take, see benchmarks, between 1 and 3 seconds. To avoid a serial implementation of doing one request after another, the requests are multithreaded (assuming multiple threads are available) to reduce the total time to make all endpoint data requests around 3 seconds with the slowest endpoint request being the bottleneck. API pulling code
This type of exchange data pulling from public api endpoints is freely available via open-source projects such as ccxt and freqtrade. I choose six strong exchanges to allow myself the opportunity to learn to pull and manipulate trading data.
- Coming soon
- Will feature breakdown of time between different processes with different numbers of computational threads
- Will feature breakdown of bilateral, trilateral, quadlateral, and pentalateral arb finding times with different numbers of threads
-
Format the data into a matrix and use k matrix multiplies to maximize the profitability wit an entry in the result or intermediate matrix being the argMax of a row from matrixA and column from matrixB
-
Reduces arbitrage algorithm complexity to
$O((k+1)*n^{([2.34, 3])})$ , where k is the number of desired trades, for larger arbitrage paths and is quite amendable to parallelization - Easy to calculate but would be harder to trace the path from the result
-
Reduces arbitrage algorithm complexity to
-
Along with (k+1) matrix multiplies is the idea of tropical algebra for currency arbitrage outlined in this paper that uses more sophisticated mathematical formuli, such as the kronocker and Karp's Algorithm
-
Another option is Johnson's algorithm or Floyd-Warshall to compute an all-pairs shortest path
- Both will yield the greatest possible profitability for an arbitrage is fed data correctly
- Both suffer from tracing profitability to the actual path as multiple intersecting arbitrage paths in the graph will produce incorrect tracing
- The shortest path from any given vertex to another does not directly result in a arbitrage path, which would imply additional required computations
- No guarantee that the shortest path from one vertex to another and back is of reasonable length (could have very long trade paths)
-
A final option is linear programming with a linear solver for both improving the computational speed of the arbitrage finder and amount of optimizer
- There are multiple providers of free/payed linear solvers such as Gurobi, MATLAB, HiGHS, or any others
- Constraints could be freely added by used such as certain coins to favor or avoid, path length, minimal or maximal exchanges to make trades on, min or max of trading a coin or set of coins, bias towards coins that have or have not been traded before
- Objective function would be the maximization profit from available trades at any given time
- Separate objective function could be the optimized trading amount from the parsed orderbook data
-
Additionally before deploying the framework as an active trading bot, one should consider hooking up the arbitrage paths that the bot finds to a Twilio text message/email bot. The Twilio application could send a user text messages about discovered arbitrage paths and the user could manually check them to recognize potential strengths and weaknesses of this framework. From there, a user can tweak user customization or my code entirely to feel comfortable with the framework before deploying an active trading bot
- This crypto arbitrage framework was done for personal interest. It is possible that this framework will output a false positive path that produces financial loss because of outdated orderbook data so any outside use of this code is at the users discretion and risk
- Very few exchanges offer cross exchange trades, so keeping balances on all exchanges in use would be required for the best market order completion speed. Else one would have transfer funds from exchanges and pay additional fees and suffer for a slower execution of an arbitrage path.
- If trading on multiple exchanges with large enough balances, it is possible for a user to parallelize market order submission by trading each pair independently. If the arbitrage path is profitable at order completion, the result overall will be profitable