Home
"Take big bites. Anything worth doing is worth overdoing." — Robert A. Heinlein, Time Enough for Love
Very honored to receive the Google OSPB 2022 award for my work on ugrep. But let's not forget all the people who offered suggestions, comments and otherwise contributed to the project!
Ugrep is typically faster than other grep for common search patterns. See performance comparisons. Ugrep uses new methods from our research. For example, to avoid costly CPU branches that are hard to predict by the CPU's branch predictor, ugrep uses a new logic and arithmetic hashing technique to predict matches. When a possible match is predicted, a pattern match is performed with our RE/flex library. This DFA-based regex library is much faster to match patterns than other libraries such as PCRE2, even when PCRE2's JIT is enabled. In addition, ugrep's worker threads are optimally load-balanced with lock-free job queue stealing. We also use AVX/SSE/ARM-NEON/AArch64 instructions and utilize efficient non-blocking asynchronous IO.
The new method I've invented and implemented in ugrep is presented in my talk at the Performance Summit IV. I've added more details in this article. Regex pattern matching in ugrep uses this new technique in addition to multi-string matching.
We were looking for a grep tool to quickly dig through hundreds of zip- and tar-archived project repos with thousands of source code files, documentation files, images, and binary files. We wanted to do this without having to expand archives, to save time and storage resources. With ugrep we have the ability to specifically search source code (with option -t) while ignoring everything else in these huge zip- and tar-archives. Even better, ugrep can ignore matches in strings and comments in source code using "negative patterns", e.g. with pre-defined patterns ugrep -f c++/zap_strings -f c++/zap_comments .... To keep ugrep clean BSD-3 source code unencumbered by GPL or LGPL terms and conditions, I wrote my own tar, zip, pax and cpio unarchivers from scratch in C++ that call external decompression libraries linked with ugrep.
Over 1000 test cases are evaluated when you install ugrep. We at our research lab (and many others) use, test, and evaluate ugrep regularly and we cannot accept errors. Our RE/flex library that is used by ugrep has been around for several years and is stable. Ugrep also meets the highest quality standards (A+) for C++ source code according to lgtm. We continue field-testing ugrep. If there is any problem, let us know by opening an issue, so everyone benefits!
Some examples of what's new that other grep tools don't offer:
Option -Q opens a query UI to search files as you type (press F1 or CTRL-Z for help and options):
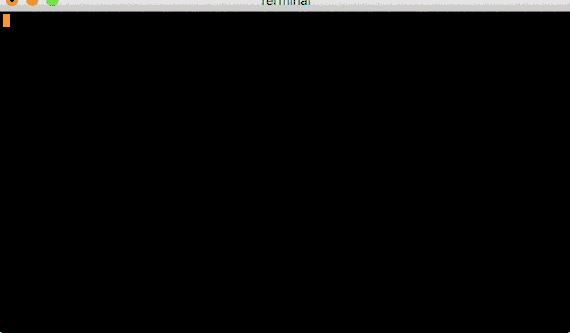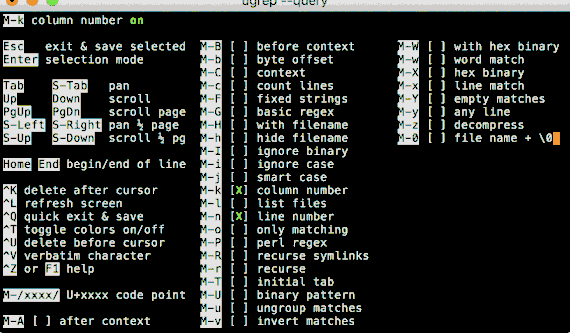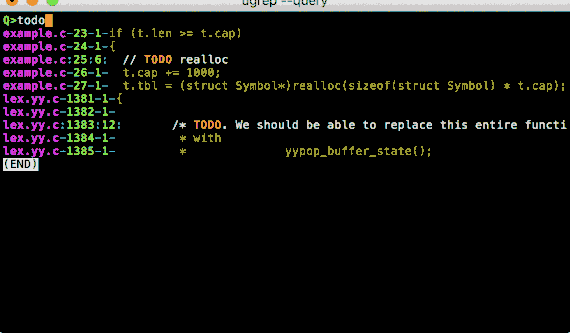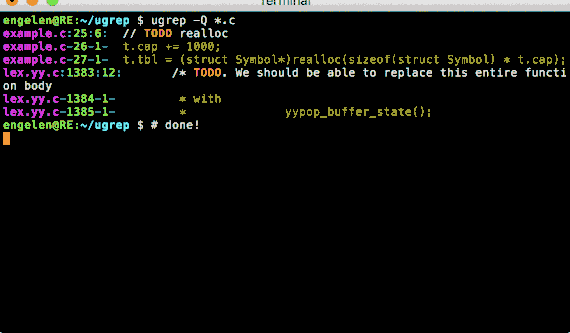
Option -t searches files by file type and predefined source code search patterns can be specified with option -f:

Option -z searches archives (cpio, pax, tar, zip) and compressed files and tarballs (zip, gz, bz2, xz, lzma, Z, lz4, zstd):

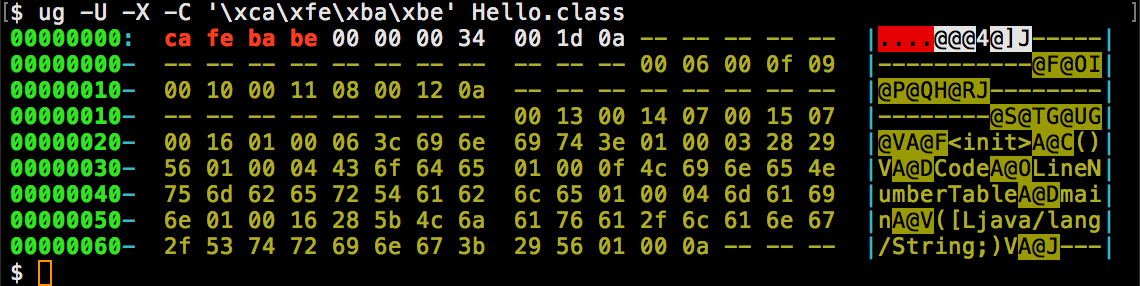
Options -U, -W and -X search binary files, displayed as hexdumps:
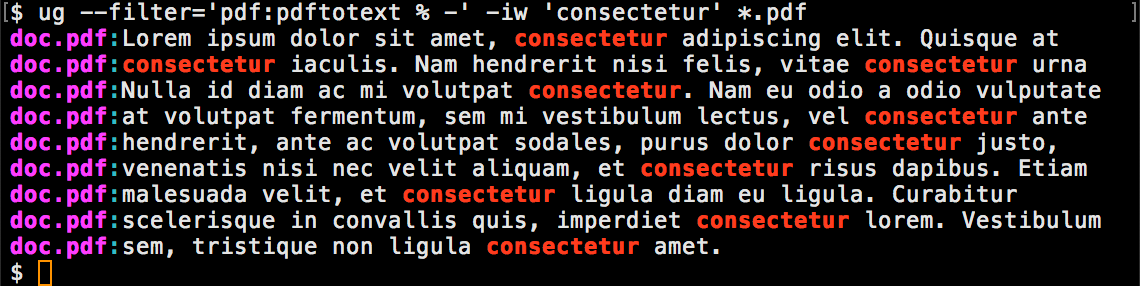
Option --filter searches pdf, office documents, and more:
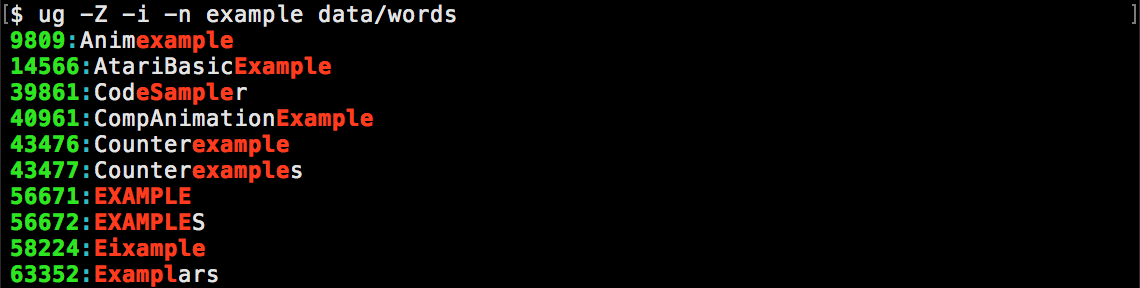
Option -Z searches for fuzzy (approximate) matches within an optionally specified max error:
Option --pretty enhances the output to the terminal. You can specify pretty in a .ugrep configuration file so that ug -l lists directory trees instead of the traditional flat grep list:

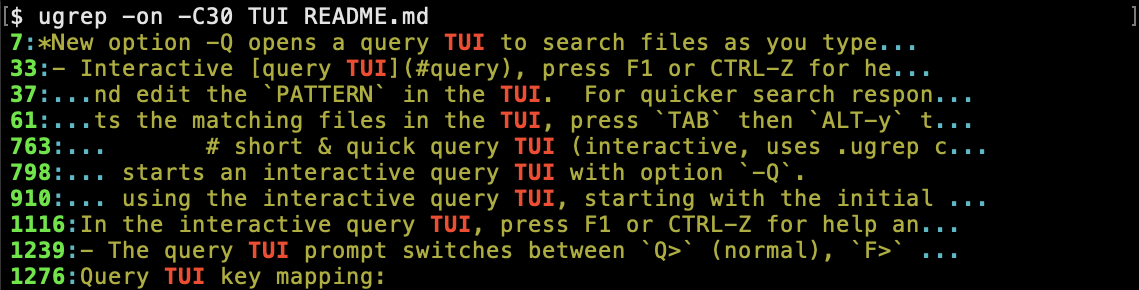
Context options -ABC also works with option -o to display the context of the only-matching pattern part on a line to fit the specified number of columns:
Not really. We carefully designed and gradually implemented ugrep without limits, unlike some other grep tools that warn about potential truncated output under certain conditions. For example, unlike other grep tools, there are no practical limitations on the match size for multiline patterns, even when its context (option -C) is large. There is no limit on the file size, which may exceed 2GB. The maximum regex pattern length is 2GB. If the pattern causes excessive memory requirements due to its size and complexity, then an error message may be generated before ugrep starts searching. This should not happen in any practical use case.
Yes. New features will be added. Further speed enhancements can be expected too. We also listen to ugrep users. Users are actively sharing their experience with ugrep. You can share suggestions for features by posting them as project issues for enhancements.
It's all in one README on GitHub.
U name it. The U wasn’t used by any other grep tools I could find, so “ugrep” was a logical choice. But if you really must, take a pick:
- User friendly grep (yes it is, but that's not the only goal)
- Universal grep (yes, it supports features of competing greps, but what does Universal mean?)
- Ultra grep (yes it is ultra fast, but ultra ... what?)
- Uberty grep (sounds too über...)
- Unzymotic grep (too fab...)
- u grep (you grep? sounds just right!)
Absolutely! There are many ways to contribute. If you have a suggestion or if you're not happy with something then post it as an issue.
A shout out and a big thank you to our heroes, the project contributors: rbnor, ribalda, theUncanny, ucifs, NightMachinary, jonassmedegaard, cdluminate, grylem, ISO8807, 0x7FFFFFFFFFFFFFFF, bolddane, marc-guenther, rrthomas, illiliti, stdedos, bmwiedemann, pete-woods, paoloschi, mmuman, alex-bender, smac89, htgoebel, gaeulbyul, dicktyr, andresroldan, AlexanderS, NapVMk, chy-causer, camuffo, trantor, essays-on-esotericism, hanyfarid, reneeotten, wahjava, idigdoug, ericonr, juhopp, emaste, zoomosis, ChrisMoutsos, wimstefan, navarroaxel, korziner, carlwgeorge and others.
Please ⭐️ the project if you use ugrep (even occasionally) to thank the contributors for their hard work!
-- Robert