원문: Building powerful image classification models using very little data by. François Chollet
이 글은 적은 양의 데이터를 가지고 강력한 이미지 분류 모델을 구축하는 방법을 소개합니다. 수백에서 수천 장 정도의 작은 데이터셋을 가지고도 강력한 성능을 낼 수 있는 모델을 만들어볼 것입니다.
저희는 세 가지 방법을 다룰 것입니다.
- 작은 네트워크를 처음부터 학습 (앞으로 사용할 방법의 평가 기준)
- 기존 네트워크의 병목특징 (bottleneck feature) 사용
- 기존 네트워크의 상단부 레이어 fine-tuning
저희가 다룰 케라스 기능은 다음과 같습니다.
ImageDataGenerator: 실시간 이미지 증가 (augmentation)flow:ImageDataGenerator디버깅fit_generator:ImageDataGenerator를 이용한 케라스 모델 학습Sequential: 케라스 내 모델 설계 인터페이스keras.applications: 케라스에서 기존 이미지 분류 네트워크 불러오기- 레이어 동결 (freezing)을 이용한 fine-tuning
시작하기 전에 머신을 위해 최상의 학습 환경을 조성해보겠습니다.
- 케라스, SciPy, PIL을 설치해주세요. 만약 NVIDIA GPU를 사용하실 분이라면 cuDNN을 설치해주세요. 물론, 저희는 적은 양의 데이터만 다룰 것이기 때문에 GPU는 꼭 필요하지 않습니다.
- 이미지를 학습, 테스트 세트로 나누어 아래와 같이 준비해주세요. 확장자는
.png또는.jpg를 권합니다.
GPU 텐서플로우를 사용하실 경우 conda를 이용해서 설치하실 것을 권합니다. [참고].
data/
test/
dogs/
dog0001.jpg
dog0002.jpg
...
cats/
cat0001.jpg
cat0002.jpg
...
train/
...
고양이와 강아지 이외의 이미지 데이터를 찾으신다면 Flickr API를 활용해보는 것을 추천드립니다. 태그 기반 검색을 사용해서 라이센스 제약이 없는 이미지를 쉽게 찾을 수 있습니다.
이번 실험은 캐글 데이터를 가지고 진행됩니다. 학습 데이터로 1,000장의 고양이 사진과 1,000장의 강아지 사진을 사용하고, 검증 데이터로는 각각 400장을 . 적은 데이터로 효과적인 모델을 학습할 수 있는지 알아보기 위해 원본 데이터 25,000장 중에서 일부만 가져왔습니다 (효과적으로 학습할 수 있어요 :).
사실 1,000장의 사진을 가지고 복잡한 이미지 분류 모델을 학습시키는 것은 정말 어렵습니다. 하지만 실제 상황에서 자주 접하게 될 법한 문제입니다. 의료 영상 같은 경우 이 정도의 데이터를 구하는 것조차 거의 불가능하죠. 적은 데이터를 가지고 최대 성능을 쥐어짜는 것이야말로 데이터 과학자의 핵심 자질이라 할 수 있습니다.

고양이 vs 강아지 대회를 캐글에서 개최한지 이제 근 5년이 되어가는데, 그때 당시만 하더라도 캐글에서는 다음과 같은 발표문을 냈습니다.
"In an informal poll conducted many years ago, computer vision experts posited that a classifier with better than 60% accuracy would be difficult without a major advance in the state of the art. For reference, a 60% classifier improves the guessing probability of a 12-image HIP from 1/4096 to 1/459. The current literature suggests machine classifiers can score above 80% accuracy on this task [참고]."
몇 년 전만 하더라도 정확도 60%조차 달성하기 어려울 것이라고 전문가들은 단언했지만, 이제는 80% 정확도 정도 도달할 수 있을 것이라는 내용입니다.
당시 집계된 참가자 순위표를 보시면 1등 팀이 거의 99% 정확도를 달성한 것을 확인하실 수 있습니다. 저희는 그중에서도 극히 일부의 데이터만 사용할 예정입니다. 같은 성능을 내는 건 아무래도 쉽지 않겠죠.
저는 이런 말을 자주 듣습니다: “deep learning is only relevant when you have a huge amount of data”. 데이터가 정말 많을 때 비로소 딥러닝을 해볼 만하다는 것입니다. 전혀 엉뚱한 소리는 아닙니다. 컴퓨터가 알아서 데이터의 특성을 파악하려면 학습할 수 있는 데이터가 많아야 합니다. 이미지처럼 차원이 높은 데이터, 즉 복잡한 데이터는 더욱 더 그렇겠죠. 하지만 대표적인 딥러닝 모델인 CNN은 바로 이런 문제를 해결하기 위해 설계된 모델입니다—학습한 데이터가 적은 경우라도 말이죠. 별도의 데이터 조작 없이 적은 데이터를 가지고도 간단한 CNN을 처음부터 학습시켜보면 괜찮은 성능이 나오는 것을 확인할 수 있을 것입니다.
하지만 이 글에서 다루는 딥러닝 모델의 핵심 장점은 바로 재사용성입니다. 예를 들어 매우 큰 데이터셋을 가지고 학습된 이미지 분류 또는 음성인식 모델은, 조금만 수정을 가하면 아예 다른 문제 상황에서도 사용할 수 있게 됩니다. 더구나 최근에는 학습이 완료된 이미지 분류 모델이 많이 공개되어 누구나 이용할 수 있게 되었습니다. 이를 활용하면 아주 적은 데이터를 가지고도 강력한 이미지 분류 모델을 손쉽게 만들 수 있습니다.
모델이 적은 이미지에서 최대한 많은 정보를 뽑아내서 학습할 수 있도록 우선 이미지를 augment 시켜보도록 하겠습니다. 이미지를 사용할 때마다 임의로 변형을 가함으로써 마치 훨씬 더 많은 이미지를 보고 공부하는 것과 같은 학습 효과를 내는 겁니다. 이를 통해 과적합 (overfitting), 즉 모델이 학습 데이터에만 맞춰지는 것을 방지하고, 새로운 이미지도 잘 분류할 수 있게 합니다.
이런 전처리 과정을 돕기 위해 케라스는 ImageDataGenerator 클래스를 제공합니다. ImageDataGenerator는 이런 일을 할 수 있죠:
- 학습 도중에 이미지에 임의 변형 및 정규화 적용
- 변형된 이미지를 배치 단위로 불러올 수 있는
generator생성.generator를 생성할 때flow(data, labels),flow_from_directory(directory)두 가지 함수를 사용합니다.fit_generator,evaluate_generator함수를 이용하여generator로 이미지를 불러와서 모델을 학습시킬 수 있습니다.
예시를 한번 살펴봅시다.
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode=`nearest`)앞서 언급했듯이 ImageDataGenerator는 이미지 augmentation을 도와주는 친구입니다. 이미지를 마음대로 바꾸면 곤란하니까 저희가 몇 가지 지시 사항을 줄 것입니다. 각각의 인자가 어떤 사항을 지시하는지 설명드리겠습니다.
rotation_range: 이미지 회전 범위 (degrees)width_shift,height_shift: 그림을 수평 또는 수직으로 랜덤하게 평행 이동시키는 범위 (원본 가로, 세로 길이에 대한 비율 값)rescale: 원본 영상은 0-255의 RGB 계수로 구성되는데, 이 같은 입력값은 모델을 효과적으로 학습시키기에 너무 높습니다 (통상적인 learning rate를 사용할 경우). 그래서 이를 1/255로 스케일링하여 0-1 범위로 변환시켜줍니다. 이는 다른 전처리 과정에 앞서 가장 먼저 적용됩니다.shear_range: 임의 전단 변환 (shearing transformation) 범위zoom_range: 임의 확대/축소 범위horizontal_flip: True로 설정할 경우, 50% 확률로 이미지를 수평으로 뒤집습니다. 원본 이미지에 수평 비대칭성이 없을 때 효과적입니다. 즉, 뒤집어도 자연스러울 때 사용하면 좋습니다.fill_mode이미지를 회전, 이동하거나 축소할 때 생기는 공간을 채우는 방식
케라스 공식 문서를 보시면 이외에도 다양한 인자가 있습니다.
Generator를 이용해서 학습하기 전, 먼저 변형된 이미지에 이상한 점이 없는지 확인해야 합니다. 케라스는 이를 돕기 위해 flow라는 함수를 제공합니다. 여기서 rescale 인자는 빼고 진행합니다—255배 어두운 이미지는 아무래도 눈으로 확인하기 힘들 테니까 말이죠.
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode=`nearest`)
img = load_img(`data/train/cats/cat.0.jpg`) # PIL 이미지
x = img_to_array(img) # (3, 150, 150) 크기의 NumPy 배열
x = x.reshape((1,) + x.shape) # (1, 3, 150, 150) 크기의 NumPy 배열
# 아래 .flow() 함수는 임의 변환된 이미지를 배치 단위로 생성해서
# 지정된 `preview/` 폴더에 저장합니다.
i = 0
for batch in datagen.flow(x, batch_size=1,
save_to_dir=`preview`, save_prefix=`cat`, save_format=`jpeg`):
i += 1
if i > 20:
break # 이미지 20장을 생성하고 마칩니다결과는 다음과 같습니다. 저희는 이러한 이미지로 모델을 학습하게 되는 것입니다. 잘못된 학습 예시가 있다면 augmentation 인자를 다시 한 번 조절해보세요.

앞서 언급했듯이 이미지 분류 작업에 가장 적합한 모델은 CNN입니다. 우선 특별한 기법을 사용하지 않고 소규모의 CNN을 처음부터 학습시켜 볼 겁니다. 데이터가 많지 않기 때문에 먼저 과적합 문제부터 해결해야 합니다. 이미지를 효과적으로 분류하려면 대상의 핵심 특징에 집중해야 합니다. 고양이와 강아지를 분류하는데 털 색깔을 기준으로 하면 안되겠죠. 하지만 학습 데이터 속에 있는 강아지가 대부분 짙은 털빛을 갖고 있고 고양이는 털빛이 연하다면 그렇게 학습이 될 수 있습니다. 학습 데이터가 적을수록 이런 문제가 더 심하겠죠.
Generator를 이용해서 이미지 augmentation을 수행하는 목적이 바로 이런 과적합을 막는 데에 있습니다. 하지만 augmentation에도 한계가 있죠. 단순 기하학적인 변형으로 이미지의 특성이 크게 달라지진 않으니까요. 가장 중요한 것은 모델의 엔트로피 용량, 즉 모델이 담을 수 있는 정보의 양을 줄이는 것입니다. 오타가 아닙니다. 모델의 복잡도를 늘리면 담을 수 있는 정보가 많아져서 이미지에서 더 많은 특징을 파악할 수 있게 됩니다. 하지만 그만큼 분류 작업에 방해되는 특징도 찾게 될 겁니다—앞서 언급한 털빛 같은 특징 말이죠. 오히려 모델의 복잡도를 줄이면 가장 중요한 몇 가지 특징에 집중해서 분류 대상을 정확하게 파악하고, 새로운 이미지도 정확하게 분류해낼 수 있게 됩니다.
엔트로피 용량을 조절하는 방법은 다양합니다. 대표적으로 모델에 관여하는 파라미터 개수를 조절하는 방법이 있습니다. 레이어 개수와 레이어 크기가 여기에 해당하죠. 저희가 작은 규모의 CNN을 사용하는 이유가 여기에 있습니다. 또한, L1, L2 정규화 (regularization) 같은 가중치 정규화 기법이 있습니다. 학습하면서 모든 가중치를 반복적으로 축소하는 방법인데, 결과적으로 핵심적인 특징에 대한 가중치만 남게 되는 효과가 있습니다.
저희는 레이어 개수, 그리고 레이어당 필터 개수가 적은 소규모 CNN을 학습시킬 겁니다. 학습 과정에서는 데이터 augmentation 및 드롭아웃 (dropout) 기법을 사용합니다. 드롭아웃은 과적합을 방지할 수 있는 또 다른 방법입니다. 하나의 레이어가 이전 레이어로부터 같은 입력을 두번 이상 받지 못하도록 하여 데이터 augmentation과 비슷한 효과를 냅니다.
위에서 묘사한 모델을 생성할 코드입니다. Convolution 레이어 3개를 쌓아놓은 간단한 형태로, ReLU 활성화 함수를 사용하고, max-pooling을 적용합니다. CNN 기법을 처음 고안한 Yann LeCun이 1990년대에 제시한 아키텍처와 유사한 형태입니다.
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(3, 150, 150)))
model.add(Activation(`relu`))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3)))
model.add(Activation(`relu`))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation(`relu`))
model.add(MaxPooling2D(pool_size=(2, 2)))모델의 상단에는 두 개의 fully-connected 레이어를 배치할 것입니다. 마지막으로 sigmoid 활성화 레이어를 배치합니다. 만약 분류하고자 하는 클래스가 3가지 이상이면 softmax 활성화 레이어를 사용하시면 됩니다. 손실 함수는 binary_crossentropy를 사용합니다. 이 또한 클래스가 3가지 이상이면 categorical_crossentropy를 사용하시면 됩니다.
model.add(Flatten()) # 이전 CNN 레이어에서 나온 3차원 배열은 1차원으로 뽑아줍니다
model.add(Dense(64))
model.add(Activation(`relu`))
model.add(Dropout(0.5))
model.add(Dense(2))
model.add(Activation(`sigmoid`))
model.compile(loss=`binary_crossentropy`,
optimizer=`rmsprop`,
metrics=[`accuracy`])
이제 본격적으로 데이터를 불러옵시다. flow_from_directory() 함수를 사용하면 이미지가 저장된 폴더를 기준으로 라벨 정보와 함께 이미지를 불러올 수 있습니다.
batch_size = 16
# 학습 이미지에 적용한 augmentation 인자를 지정해줍니다.
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# 검증 및 테스트 이미지는 augmentation을 적용하지 않습니다. 모델 성능을 평가할 때에는 이미지 원본을 사용합니다.
validation_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
# 이미지를 배치 단위로 불러와 줄 generator입니다.
train_generator = train_datagen.flow_from_directory(
`data/train`, # this is the target directory
target_size=(150, 150), # 모든 이미지의 크기가 150x150로 조정됩니다.
batch_size=batch_size,
class_mode=`binary`) # binary_crossentropy 손실 함수를 사용하므로 binary 형태로 라벨을 불러와야 합니다.
validation_generator = validation_datagen.flow_from_directory(
`data/validation`,
target_size=(150, 150),
batch_size=batch_size,
class_mode=`binary`)
test_generator = test_datagen.flow_from_directory(
`data/validation`,
target_size=(150, 150),
batch_size=batch_size,
class_mode=`binary`)이제 본격적으로 학습을 시작합니다. 각 에폭 (epoch) 당 GPU에서는 약 20~30초, CPU에서는 300~400초 정도 걸립니다. 너무 급하지 않다면 CPU에서도 충분히 학습을 돌릴 수 있는 시간입니다.
model.fit_generator(
train_generator,
steps_per_epoch=1000 // batch_size,
validation_data=validation_generator,
epochs=50)
model.save_weights(`first_try.h5`) # 많은 시간을 들여 학습한 모델인 만큼, 학습 후에는 꼭 모델을 저장해줍시다.이렇게 학습을 돌린 결과, 50에폭*으로 0.79-0.81의 검증 정확도 (validation accuracy)를 달성했습니다. 캐글 대회가 열린 2013년을 기준으로 저희는 이미 업계 최고 수준을 달성한 것입니다. 더군다나 데이터도 2000장밖에 안 쓰고, 모델을 최적화하려는 별다른 노력도 없이 말이죠. 캐글 대회 순위표 기준 215명 중 100위권에 들었습니다. 적어도 115명의 참가자는 딥러닝을 사용하지 않았나 봅니다. ;)
*여기서 에폭 수 50은 임의로 정한 값입니다. 학습을 돌린 결과, 학습셋과 테스트셋의 성능이 크게 다르지 않게 나와 과적합이 일어나지 않은 것을 확인했습니다. 50이 괜찮은 에폭 수였던 것이죠. CNN 규모가 작고, 드롭아웃 계수도 높았기 때문에 50 에폭만으로는 과적합이 일어나지 않았던 것으로 예상해볼 수 있습니다.
여기서 눈여겨 볼만한 점은 검증 정확도가 변동이 심하다는 것입니다. 본래 정확도 (accuracy)라는 통계 지표가 변동성이 큰 것이기도 하고, 검증 이미지가 500장밖에 되지 않기 때문에 그렇습니다. 변동성이 큰 만큼, 신뢰성이 조금 떨어지는 지표이죠. 저희 모델이 정말로 제대로 학습이 된 건지, 단지 평가에서 운이 좋았던 것인지 확실하지 않은 겁니다. 이럴 때 사용하기 좋은 방법으로 k-fold cross-validation이 있습니다. 같은 데이터로 더욱 신뢰할 수 있는 평가 결과를 낼 수 있지만 그만큼 시간이 오래 걸리는 방법입니다.
더욱 정교한 접근 방식은 대규모 데이터셋에 이미 학습된 기존 네트워크 (convolutional neural network)를 활용하는 것입니다. 이러한 네트워크는 이미지를 파악하기에 유용한 특징을 추출하는 법을 이미 잘 배웠습니다. CNN의 앞쪽 레이어에서 이러한 특징을 추출하고, 뒤쪽 레이어에서 그 특징들을 가지고 이미지를 분류하겠죠. 저희는 앞쪽 레이어만 쏙 빌려와서 높은 성능의 모델을 만들어볼 겁니다. 앞쪽 레이어를 통과시켜서 추출된 특징을 바로 bottleneck, 즉 병목 특징이라고 부릅니다.
이처럼 기존의 네트워크를 활용하는 방식을 transfer learning이라 부릅니다. 대규모 데이터셋에서 학습한 내용을 새로운 문제 상황으로 옮겨온 격이기 때문이죠.
저희는 대규모 ImageNet 데이터셋에 마리 학습된 VGG16 네트워크를 사용할 것입니다. 사실 ImageNet에는 이미 고양이와 강아지 사진, 즉 고양이와 강아지 클래스가 포함되어 있으므로 VGG16은 고양이 vs 강아지 문제를 이미 접해보았습니다. 사실 고양이와 강아지 분류는 원본 VGG16 모델을 그대로 사용해도 되는 문제입니다. 하지만 ImageNet에 없는 클래스를 분류하는 데에도 병목 특징을 사용하여 뛰어난 모델을 만들 수 있습니다. 고양이와 강아지는 단지 예시입니다.
VGG16 아키텍처는 다음과 같습니다.
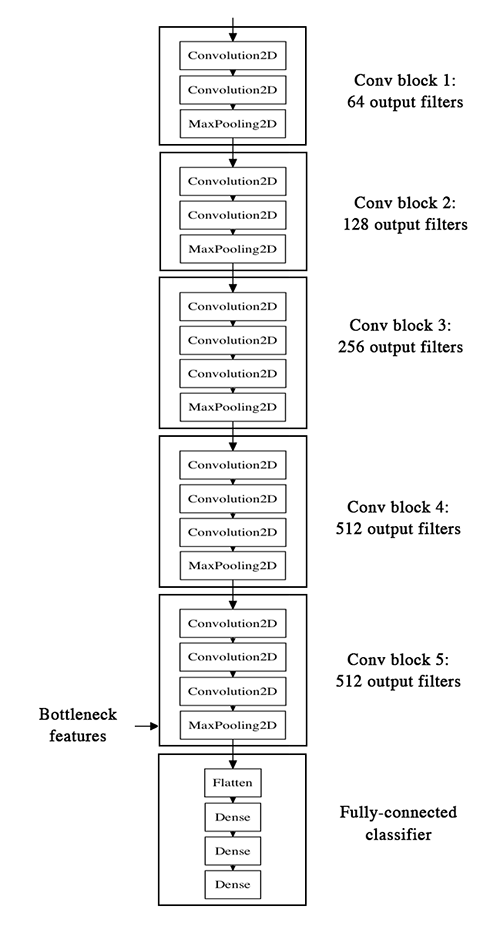
우리의 전략은 다음과 같습니다. 우선 VGG16에서 convolution 레이어로 이루어진 앞단만 가져옵니다. 뒤쪽의 fully-connected 레이어는 배제합니다. 그리고 이미지 데이터를 이 부분 모델에 넣고 돌려서 마지막 레이어에서 출력되는 병목 특징을 NumPy 배열에 담습니다. 이 병목 특징은 모두 수치적인 값으로 이루어져 있습니다. 마지막으로, 작은 fully-connected 모델을 만들어서 이 병목 데이터를 가지고 학습시킬 것입니다. 이때 병목 데이터는 학습, 검증, 테스트셋으로 분리해서 관리해야 합니다.
사실 VGG16 하단부 위에 fully-connected 레이어를 얹은 후, VGG 부분은 동결시키고* 얹은 레이어만 학습해도 됩니다. 하지만 이 경우, 학습 스텝마다 VGG 앞단의 연산을 수행해야 하기 때문에 학습 시간이 상당히 길어집니다. 특히 CPU를 사용할 경우 시간이 너무 오래 걸리게 됩니다. 병목 방식을 사용하면 이러한 연산을 최소화할 수 있습니다. 다만 augmentation은 어려워지겠죠**.
* 동결 (freezing): 학습시키고자 하지 않은 레이어는 가중치를 동결시켜서 연산량을 줄일 수 있습니다.
** 한 이미지당 (이미지를 무작위로 변형하여) bottleneck을 여러 개 생성하면 augmentation의 효과를 낼 수는 있습니다.
이 실험의 전체 코드는 여기서 찾을 수 있습니다. 학습된 모델은 GitHub에서 내려받을 수 있습니다. 모델을 생성하고 불러오는 과정은 예시 코드에서 확인하실 수 있습니다. 저희는 병목 특징을 추출하는 방법을 살펴보겠습니다.
batch_size = 16
generator = datagen.flow_from_directory(
`data/train`,
target_size=(150, 150),
batch_size=batch_size,
class_mode=None, # 라벨은 불러오지 않습니다.
shuffle=False) # 출력되는 병목 특징이 어디서 왔는지 알 수 있도록 입력 데이터의 순서를 유지합니다 (사전순으로 cat 1000장, dog 1000장 순서로 입력이 들어옵니다).
# 이미지를 모델에 입력시켜 결과를 가져옵니다. 본래 어떤 예측 결과가 출력되어야 하지만 모델의 일부만 가져왔기 때문에 병목 특징이 출력됩니다.
bottleneck_features_train = model.predict_generator(generator, 2000)
# 출력된 병목 데이터를 저장합니다.
np.save(open(`bottleneck_features_train.npy`, `w`), bottleneck_features_train)
generator = datagen.flow_from_directory(
`data/validation`,
target_size=(150, 150),
batch_size=batch_size,
class_mode=None,
shuffle=False)
bottleneck_features_validation = model.predict_generator(generator, 800)
np.save(open(`bottleneck_features_validation.npy`, `w`), bottleneck_features_validation)이제 저장된 병목 데이터를 불러와서 소규모 fully-connected 모델을 학습시킵니다.
코드 실행 중 문제가 발생하면 생성한 병목 데이터가 날아갈 수 있으므로 저장 후 불러오는 방식을 사용합니다.
train_data = np.load(open(`bottleneck_features_train.npy`))
# 앞서 언급한 바와 같이 병목 특징은 순서대로 추출되기 때문에 라벨 데이터는 아래와 같이 손쉽게 생성할 수 있습니다.
train_labels = np.array([0] * 1000 + [1] * 1000)
validation_data = np.load(open(`bottleneck_features_validation.npy`))
validation_labels = np.array([0] * 400 + [1] * 400)
model = Sequential()
model.add(Flatten(input_shape=train_data.shape[1:]))
model.add(Dense(256, activation=`relu`))
model.add(Dropout(0.5))
model.add(Dense(1, activation=`sigmoid`))
model.compile(optimizer=`rmsprop`,
loss=`binary_crossentropy`,
metrics=[`accuracy`])
model.fit(train_data, train_labels,
epochs=50,
batch_size=batch_size,
validation_data=(validation_data, validation_labels))
model.save_weights(`bottleneck_fc_model.h5`)모델의 크기가 워낙 작으므로 정말 빠르게 학습시킬 수 있습니다. CPU에서도 에폭 당 1초 정도밖에 걸리지 않습니다.
이미 주요 특징이 추출된 상태이기 때문에 분류 작업을 하는데 큰 모델이 필요하지 않습니다. 오히려 모델을 크게 잡으면 과적합이 발생할 수 있겠죠.
Train on 2000 samples, validate on 800 samples
Epoch 1/50
2000/2000 [==============================] - 1s - loss: 0.8932 - acc: 0.7345 - val_loss: 0.2664 - val_acc: 0.8862
Epoch 2/50
2000/2000 [==============================] - 1s - loss: 0.3556 - acc: 0.8460 - val_loss: 0.4704 - val_acc: 0.7725
...
Epoch 47/50
2000/2000 [==============================] - 1s - loss: 0.0063 - acc: 0.9990 - val_loss: 0.8230 - val_acc: 0.9125
Epoch 48/50
2000/2000 [==============================] - 1s - loss: 0.0144 - acc: 0.9960 - val_loss: 0.8204 - val_acc: 0.9075
Epoch 49/50
2000/2000 [==============================] - 1s - loss: 0.0102 - acc: 0.9960 - val_loss: 0.8334 - val_acc: 0.9038
Epoch 50/50
2000/2000 [==============================] - 1s - loss: 0.0040 - acc: 0.9985 - val_loss: 0.8556 - val_acc: 0.9075
0.90-0.91의 검증 정확도 도달했습니다. 나쁘지 않습니다. 앞서 언급했듯이 VGG16 학습 데이터에 이미 고양이와 강아지 사진이 포함되어 있어서 더더욱 성능이 높게 나왔지만, 그렇지 않은 경우에도 병목 방식을 사용할 수 있습니다.
여기서 더더욱 성능을 개선하고자 한다면 학습하는 레이어 개수를 늘리면 됩니다. 기존에는 VGG16 뒤에 추가한 fully-connected 레이어만 학습했다면, 이제는 VGG16 최상단의 convolution 레이어까지 같이 학습시키는 것입니다. 즉, 미리 학습된 기존 네트워크의 일부 상단 레이어에 미세한 가중치 업데이트를 수행하여 지금 다루는 문제의 주어진 데이터에 좀 더 최적화시키는 것입니다. 이를 fine-tuning이라 부르며, 다음과 같이 구현됩니다.
- 미리 학습된 VGG16의 CNN 부분 불러오기
- 앞서 학습을 마친 fully-connected 모델 추가
- 마지막 convolution 레이어를 제외한 부분 (나머지 레이어) 동결
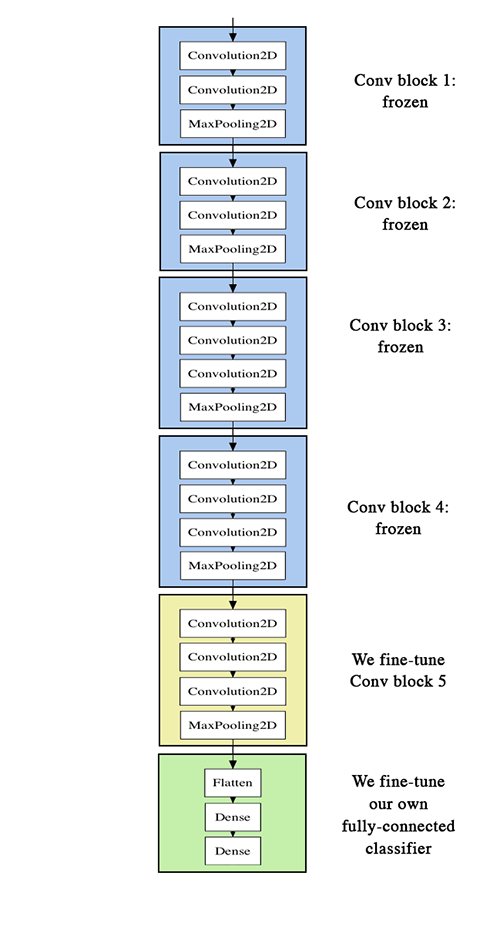
이때, 몇 가지 주의할 점이 있습니다.
Fine-tuning을 수행하려면 모든 레이어가 1차적인 학습을 마친 상태여야 합니다. 예를 들어 미리 학습된 convolution 모델 위에 갓 초기화된 fully-connected 레이어를 갖다 붙이면 안 됩니다. 무작위로 초기화된 가중치 때문에 자칫 너무 큰 가중치 업데이트가 발생할 수 있습니다. 그렇게 되면 convolution 레이어 가중치가 교란될 수 있습니다. 방대한 데이터를 학습해서 얻어진 기존 네트워크의 가중치를 너무 크게 바꿔서 핵심 학습 내용을 잃게 되는 것입니다. Fine-tuning의 핵심은 그런 문제가 없도록 미세하게 조정하는 데 있습니다. 그렇기 때문에 최상단 레이어를 먼저 학습시킨 후에 학습된 레이어를 얹어서 그다음 convolution 레이어를 미세 조정해야 합니다.
전체 네트워크가 아닌 마지막 convolution 레이어만 미세 조정하는 이유는 앞서 언급한 엔트로피 용량 때문입니다. 내부 용량이 큰 전체 네트워크를 학습하게 되면 과적합이 쉽게 일어날 수 있습니다. 더 나아가서, 하단 레이어는 주로 선이나 모서리와 같은 일반적인 특징을 추출하는 역할을 하므로 이를 미세 조정해도 큰 성능 향상을 기대하긴 힘듭니다.
미세 조정을 할 때는 아주 작은 learning rate를 사용해야 합니다. 또한, RMSProp보다는 SGD와 같이 안정적인 학습 속도를 유지하는 optimizer를 사용하는 것이 바람직합니다. 이도 이전 학습 가중치를 훼손하지 않기 위함입니다.
이 실험의 전체 코드는 여기서 찾을 수 있습니다.
VGG 하단을 불러온 후, 앞서 학습한 fully-connected 모델을 추가합니다.
# 최상단 레이어를 생성합니다
top_model = Sequential()
top_model.add(Flatten(input_shape=model.output_shape[1:]))
top_model.add(Dense(256, activation=`relu`))
top_model.add(Dropout(0.5))
top_model.add(Dense(1, activation=`sigmoid`))
# 기존 네트워크와 마찬가지로 이 방식에서는 최상단 레이어도 미리 학습되어 있어야 합니다.
# 앞서 학습시킨 가중치를 불러옵니다.
# VGG convolution 기반 위에 최상단 레이어를 얹습니다.
model.add(top_model)최상단 convolution 레이어 직전까지 모든 레이어를 동결시킵니다.
# VGG 하단의 25개 레이어는 동결키십니다.
for layer in model.layers[:25]:
layer.trainable = False
# 아주 작은 learning ratefmf 가진 SGD/momentum optimizer를 사용합니다.
model.compile(loss=`binary_crossentropy`,
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=[`accuracy`])마지막으로, 아주 작은 learning rate를 사용하여 모델을 학습시킵니다.
batch_size = 16
# 이미지 augmentation을 설정합니다
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode=`binary`)
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode=`binary`)
# Fine tuning 학습을 수행합니다.
model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size)에폭 수 50으로 0.94의 검증 정확도를 달성했습니다. 훌륭합니다!
여기서 성능을 더 늘리고자 한다면, 다음과 같은 방법을 추천해 드립니다.
- 더 강한 이미지 augmentation
- 더 높은 dropout 계수
- L1 및 L2 정규화 (weight decay라고도 부릅니다)
- 높은 정규화 계수와 함께 더 많은 convolution 레이어 미세 조정
이번 글은 여기서 마치겠습니다! 앞서 수행한 실험 코드는 아래 모두 제공되어 있습니다.
이 글은 2018 컨트리뷰톤에서
Contribute to Keras프로젝트로 진행했습니다.
Translator: 허남규
Translator email : itsnamgyu@gmail.com