OpenCV is the huge open-source library for computer vision, machine learning, and image processing and now it plays a major role in real-time operation which is very important in today’s systems. By using it, one can process images and videos to identify objects, faces, or even the handwriting of a human.
Object Detection is a computer technology related to computer vision, image processing, and deep learning that deals with detecting instances of objects in images and videos By applying object detection, you’ll not only be able to determine what is in an image, but also where a given object resides! In this section we will understand a variety of object detection methods:
- Simply looking for an exact copy of an image in another larger image.
- It simply scans a larger image for a provided template by sliding the template target image across the larger image.
- The main option that can be adjusted is the comparison method used as the target template is slid across the larger image.
- The methods are all some source of correlation base metric.
- So we can see the different methods that opencv has available

- A corner is a point whose local neighbourhood stands in two dominant and different edge directions.
- Or simply a corner can be interpreted as the junction of two edges or an edge is a sudden change in brightness.
- There are various corner detection algorithms
- We will take look at some of the most popular algorithms:
- Harris Corner Detection
- Shi-Tomasi Corner Detection
- Harris Corner Detection
- Published in 1988 by Chris Harris and Mike Stephens.
- The basic intuition is that corners can be detected by looking for significant change in all directions.
- Shi-Tomasi Corner Detection
- Published in 1994 by J. Shi and C. Tomasi in their paper Good Features to Track.
- It made a small change to the Harris Corner Detector which ended up with better results
- It changes the scoring function selection criteria that Harris uses for corner detection.
- Harris Corner Detection uses:
- R = λ1λ2 – k( λ1 + λ2)
- Shi-Tomasi uses:
- R = min(λ1, λ2)
- Harris Corner Detection uses:

- Expanding to find general edges of objects
- Canny Edge Detection Method
- Apply Gaussian filter to smooth the image in order to remove the noise.
- Find the intensity gradients of the image.
- Apply non-maximum suppression to get rid of spurious response to edge detection.
- Apply double threshold to determine possible edges.
- Track edge by hysteresis: Finalize the detection of edges by supressing all other edges that are weak and not connected to strong edges.
- Combining both concepts to find grid in images (useful for applications).
- Often cameras can create distortion in an image such as radial distortion and tangential distortion
- A good way to account for these distortions when performing like object tracking is to have a recognizable pattern attached to the object being tracked.
- Grid patterns are often used to calibrate cameras and track motion.
- Contours are defined simply as a curve joining all the continuous points having same colour or intensity.
- Contours are a useful tool for shape analysis and object detection and recognition
- OpenCV has a built in Counter finder function that can also help us differentiate between internal and external contours (eg – grabbing the eyes and smile from a cartoon face).
- Allows us to detect foreground vs background.
- Feature matching extracts defining key features from an input image (using ideas from corner, edge and contour detection).
- Then using a distance calculation, finds all the matches in a secondary image.
- More advanced methods of detecting matching object in another image, even if the target image is not shown exactly the same image we are searching.
- Feature Matching results:

- Notice how the input image is not exactly what is shown in the secondary image
- 3 methods of feature matching are:
- Brute-Force Matching with ORB Descriptors
- Brute-Force Matching with SIFT Descriptors and Ratio Test
- FLANN based Matcher
-
Metaphorically, Watershed Algorithm transformation treats the image it operates upon like a topographic map, with the brightness of each point representing it’s height, and finds the line that runs along the tops of ridges.
-
Any grayscale image can be viewed as a topographic surface where high intensity denotes peaks and hills while low intensity denotes valleys
-
As the “water” rises, depending on the peaks (gradient) nearby, “water” from different valleys (different segments of the image), with different colors could start merge.
-
To avoid this merging, the algorithm creates barrier (segment edge boundaries) in locations where “water” merges.
-
The algorithm can then fill every isolated valley(local minima) with different colored water(labels).
-
Advances algorithm that allows us to segment images into foreground and background
-
Also allows us to manually set seeds to choose segments of an image.
- A common example is the use of coins next to each other on a table
- Attempting to segment these coins can be difficult:
- It may be unclear to the algorithm if it should be treated as one large object or many small objects.
- The watershed algorithm can be very effective for these sort of problems
- A common example is the use of coins next to each other on a table
- Haar Cascades to identify faces in images
- We will be able to very quickly detect if a face is in an image and locate
- However we won’t know who’s face it belongs to.
- We would need a really large dataset and deep learning for facial recognition.
- Main feature types:
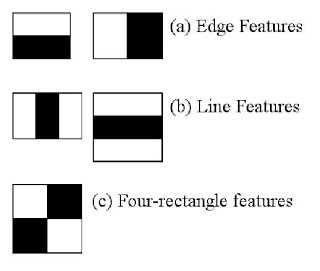
- Each feature is a single value obtained by subtracting sum of pixels under white rectangle from sum of pixels under black rectangle.
- Realistically, our images won’t be perfect lines and edges.
- These features are calculated by:
- mean(dark region) – mean(light region)
- A perfect edge would result in a value of one.
- The closer the result is to one, the better the feature.
- The Voila-Jones algorithm solves this by using the integral image.
- Resulting in an O(1) running time of the algorithm
- The algo also saves time by going through a cascade of classifiers.
- This means we will treat the image to a series(cascade)of classifiers based on the simple feature .
- Once an image fails a classifier, we can stop attempting to detect a face.
Author:Anjali Saini
Email:anjalisaini302@gmail.com