
![]()
![]()


PyStreamAPI is a Python stream library that draws inspiration from the Java Stream API. Although it closely mirrors the Java API, PyStreamAPI adds some innovative features to make streams in Python even more innovative, declarative and easy to use.
PyStreamAPI offers both sequential and parallel streams and utilizes lazy execution.
Now you might be wondering why another library when there are already a few implementations? Well, here are a few advantages of this particular implementation:
- It provides both sequential and parallel streams.
- Lazy execution is supported, enhancing performance.
- It boasts high speed and efficiency.
- The implementation achieves 100% test coverage.
- It follows Pythonic principles, resulting in clean and readable code.
- It adds some cool innovative features such as conditions or error handling and an even more declarative look.
- It provides loaders for various data sources such as CSV, JSON, XML and YAML files.
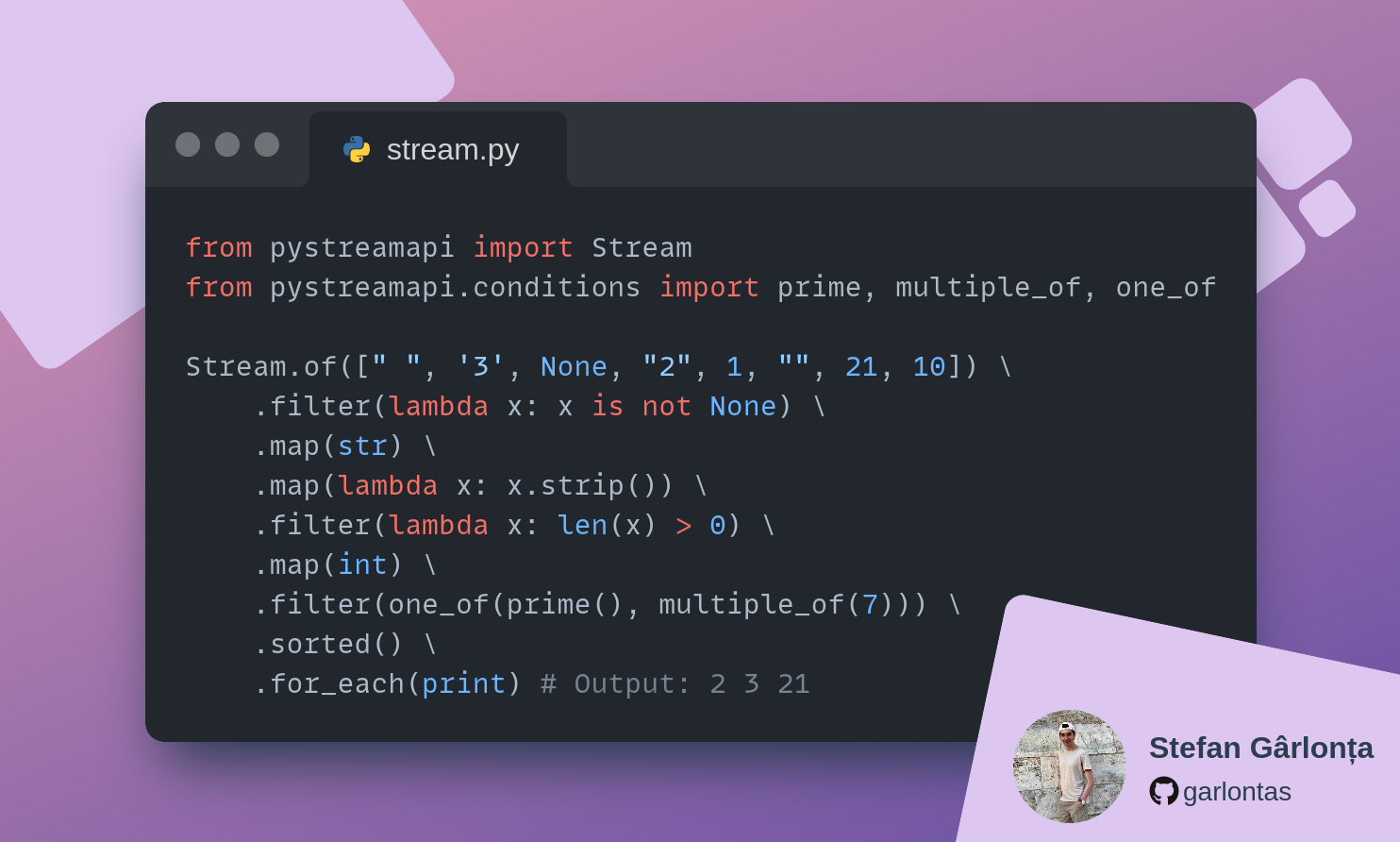
Let's take a look at a small example:
from pystreamapi import Stream
Stream.of([" ", '3', None, "2", 1, ""]) \
.filter(lambda x: x is not None) \
.map(str) \
.map(lambda x: x.strip()) \
.filter(lambda x: len(x) > 0) \
.map(int) \
.sorted() \
.for_each(print) # Output: 1 2 3And here's the equivalent code in Java:
Object[] words = { " ", '3', null, "2", 1, "" };
Arrays.stream( words )
.filter( Objects::nonNull )
.map( Objects::toString )
.map( String::trim )
.filter( s -> ! s.isEmpty() )
.map( Integer::parseInt )
.sorted()
.forEach( System.out::println ); // Output: 1 2 3A Stream is a powerful abstraction for processing sequences of data in a functional and declarative manner. It enables efficient and concise data manipulation and transformation.
Similar to its counterparts in Java and Kotlin, a Stream represents a pipeline of operations that can be applied to a collection or any iterable data source. It allows developers to express complex data processing logic using a combination of high-level operations, promoting code reusability and readability.
With Streams, you can perform a wide range of operations on your data, such as filtering elements, transforming values, aggregating results, sorting, and more. These operations can be seamlessly chained together to form a processing pipeline, where each operation processes the data and passes it on to the next operation.
One of the key benefits of Stream is lazy evaluation. This means that the operations are executed only when the result is actually needed, optimizing resource usage and enabling efficient processing of large or infinite datasets.
Furthermore, Stream supports both sequential and parallel execution. This allows you to leverage parallel processing capabilities when dealing with computationally intensive tasks or large amounts of data, significantly improving performance.
pystreamapi.Stream represents a stream that facilitates the execution of one or more operations. Stream operations can be categorized as either intermediate or terminal.
Terminal operations return a result of a specific type, while intermediate operations return the stream itself, enabling method chaining for multi-step operations.
Let's examine an example using Stream:
Stream.of([" ", '3', None, "2", 1, ""]) \
.filter(lambda x: x is not None) \ # Intermediate operation
.map(str) \ # Intermediate operation
.map(lambda x: x.strip()) \ # Intermediate operation
.filter(lambda x: len(x) > 0) \ # Intermediate operation
.map(int) \ # Intermediate operation
.sorted() \ # Intermediate operation
.for_each(print) # Terminal Operation (Output: 1 2 3)Operations can be performed on a stream either in parallel or sequentially. A parallel stream executes operations concurrently, while a sequential stream processes operations in order.
Considering the above characteristics, a stream can be defined as follows:
- It is not a data structure itself but operates on existing data structures.
- It does not provide indexed access like traditional collections.
- It is designed to work seamlessly with lambda functions, enabling concise and expressive code.
- It facilitates easy aggregation of results into lists, tuples, or sets.
- It can be parallelized, allowing for concurrent execution of operations to improve performance.
- It employs lazy evaluation, executing operations only when necessary.
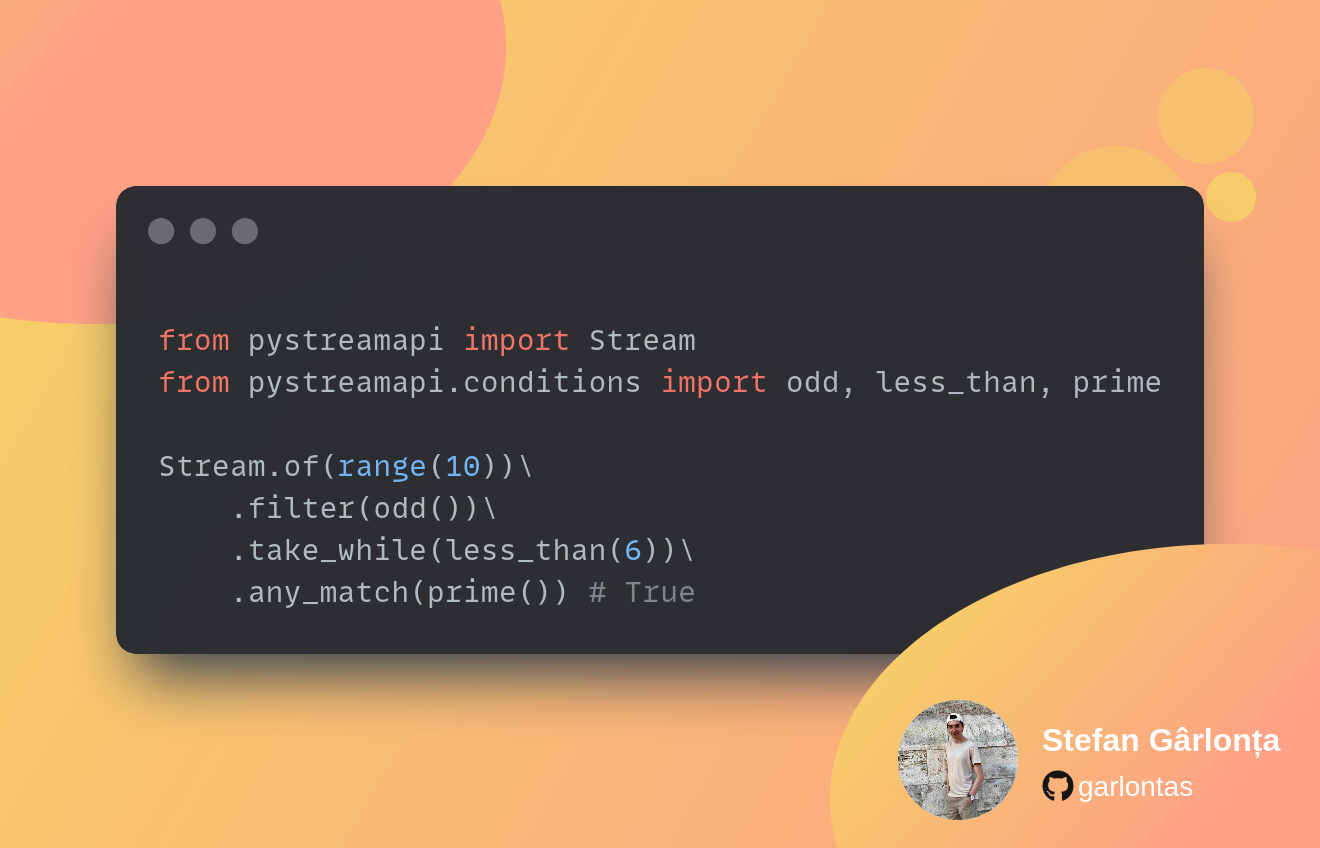
Conditions provide a convenient means for performing logical operations within your Stream, such as using filter(), take_while(), drop_while(), and more. With PyStreamAPI, you have access to a staggering 111 diverse conditions that enable you to process various data types including strings, types, numbers, and dates. Additionally, PyStreamAPI offers a powerful combiner that allows you to effortlessly combine multiple conditions, facilitating the implementation of highly intricate pipelines.
PyStreamAPI offers a powerful error handling mechanism that allows you to handle errors in a declarative manner. This is especially useful when working with data that you don't know.
PyStreamAPI offers three different error levels:
ErrorLevel.RAISE: This is the default error level. It will raise an exception if an error occurs.ErrorLevel.IGNORE: This error level will ignore any errors that occur and won't inform you.ErrorLevel.WARN: This error level will warn you about any errors that occur and logs them as a warning with default logger.
This is how you can use them:
from pystreamapi import Stream, ErrorLevel
Stream.of([" ", '3', None, "2", 1, ""]) \
.error_level(ErrorLevel.IGNORE) \
.map_to_int() \
.error_level(ErrorLevel.RAISE) \
.sorted() \
.for_each(print) # Output: 1 2 3The code above will ignore all errors that occur during mapping to int and will just skip the elements.
For more details on how to use error handling, please refer to the documentation.
To start using PyStreamAPI just install the module with this command:
pip install streams.py Afterward, you can import it with:
from pystreamapi import Stream🎉 PyStreamAPI is now ready to process your data
PyStreamAPI offers two types of Streams, both of which are available in either sequential or parallel versions:
-
(Normal)
Stream: Offers operations that do not depend on the types. The same functionality as Streams in other programming languages. -
NumericStream: This stream extends the capabilities of the default stream by introducing numerical operations. It is designed specifically for use with numerical data sources and can only be applied to such data.
There are a few factory methods that create new Streams:
Stream.of([1, 2, 3]) # Can return a sequential or a parallel streamUsing the of() method will let the implementation decide which Stream to use. If the source is numerical, a NumericStream is created.
Note
Currently, it always returns a
SequentialStreamor aSequentialNumericStream
Stream.parallel_of([1, 2, 3]) # Returns a parallel stream (Either normal or numeric)Stream.sequential_of([1, 2, 3]) # Returns a sequential stream (Either normal or numeric)# Can return a sequential or a parallel stream (Either normal or numeric)
Stream.of_noneable([1, 2, 3])
# Returns a sequential or a parallel, empty stream (Either normal or numeric)
Stream.of_noneable(None) If the source is None, you get an empty Stream
Stream.iterate(0, lambda n: n + 2)Creates a Stream of an infinite Iterator created by iterative application of a function f to an initial element seed, producing a Stream consisting of seed, f(seed), f(f(seed)), etc.
Note Do not forget to limit the stream with
.limit()
Stream.concat(Stream.of([1, 2]), Stream.of([3, 4]))
# Like Stream.of([1, 2, 3, 4])Creates a new Stream from multiple Streams. Order doesn't change.
PyStreamAPI offers a convenient way to load data from CSV, JSON, XML and YAML files. Like that you can start processing your files right away without having to worry about reading and parsing the files.
You can import the loaders with:
from pystreamapi.loaders import csv, json, xml, yamlNow you can use the loaders directly when creating your Stream:
For CSV:
Stream.of(csv("data.csv", delimiter=";")) \
.map(lambda x: x.attr1) \
.for_each(print)For JSON:
Stream.of(json("data.json")) \
.map(lambda x: x.attr1) \
.for_each(print)You can access the attributes of the data structures directly like you would do with a normal object.
For XML:
In order to use the XML loader, you need to install the optional xml dependency:
pip install streams.py[xml_loader]Afterward, you can use the XML loader like this:
Stream.of(xml("data.xml")) \
.map(lambda x: x.attr1) \
.for_each(print)The access to the attributes is using a node path syntax. For more details on how to use the node path syntax, please refer to the documentation.
For YAML:
In order to use the YAML loader, you need to install the optional yaml dependency:
pip install streams.py[yaml_loader]Afterward, you can use the YAML loader like this:
Stream.of(yaml("data.yaml")) \
.map(lambda x: x.attr1) \
.for_each(print)For a more detailed documentation view the docs on GitBook: PyStreamAPI Docs
Stream.parallel_of([" ", '3', None, "2", 1, ""]) \
.filter(lambda x: x is not None) \
.map(str) \
.map(lambda x: x.strip()) \
.filter(lambda x: len(x) > 0) \
.map(int) \
.sorted()\
.for_each(print) # 1 2 3def fib():
a, b = 0, 1
while True:
yield a
a, b = b, a + b
Stream.of(fib()) \
.limit(10) \
.for_each(print) # 0 1 1 2 3 5 8 13 21 34Note that parallel Streams are not always faster than sequential Streams. Especially when the number of elements is small, we can expect sequential Streams to be faster.
Bug reports can be submitted in GitHub's issue tracker.
Contributions are welcome! Please submit a pull request or open an issue.