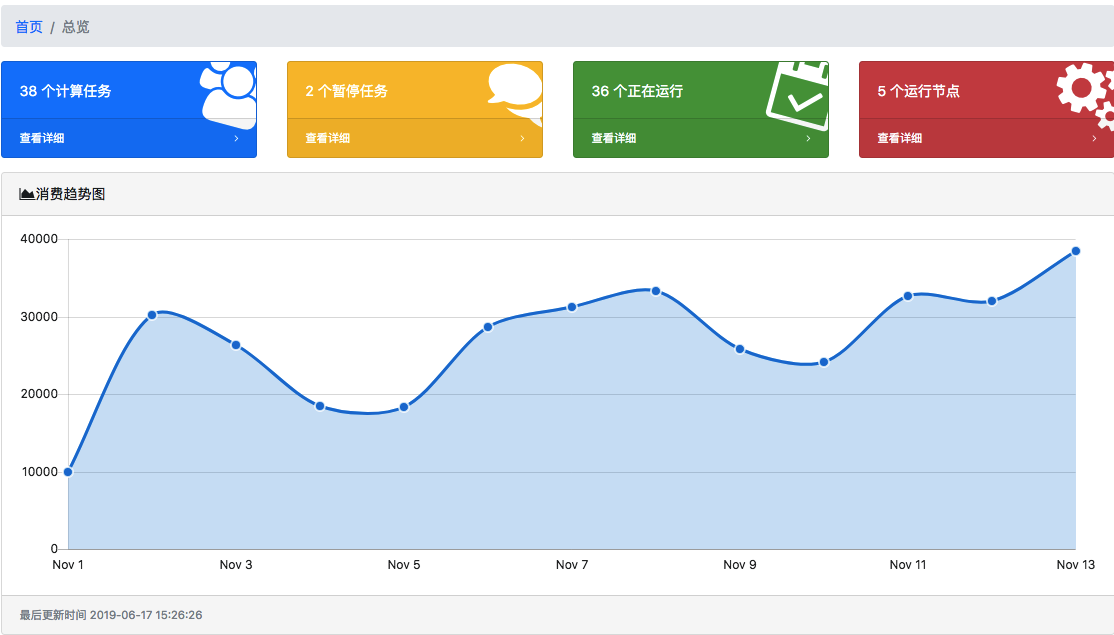
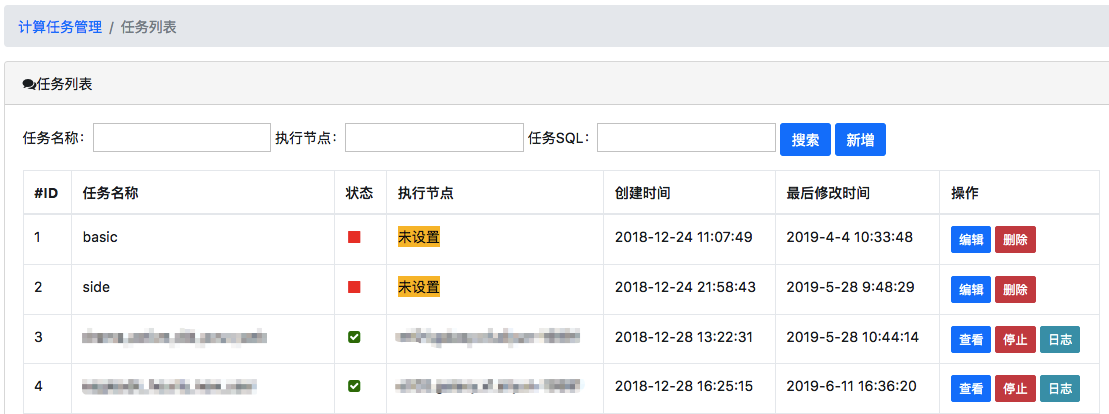
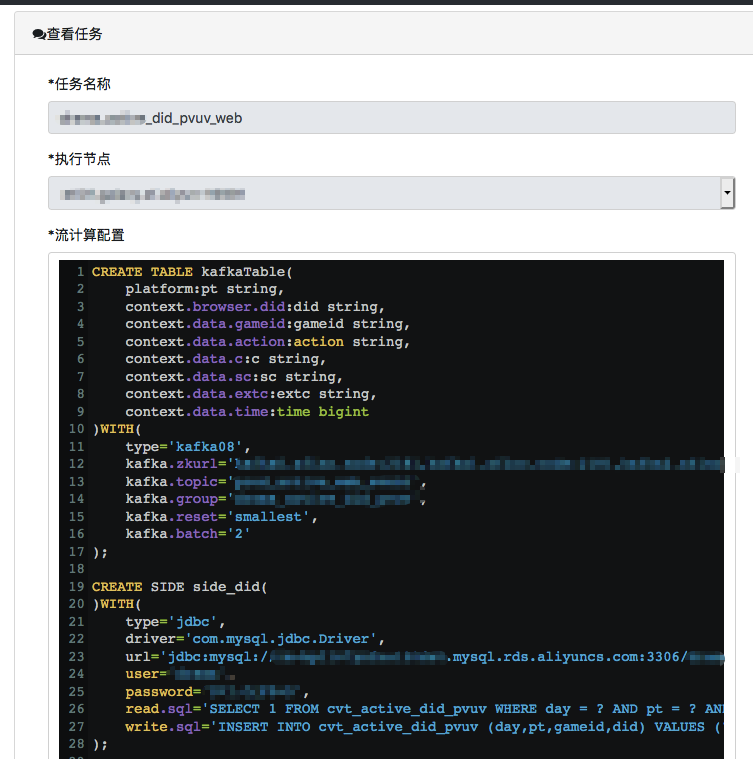
Streamer流计算引擎是一个基于Apache Calcite的实时计算框架,没有采用大家熟知的Spark和Flink,自研的Kafka消费者,来处理 Kafka的数据,实现实时计算的目的。
通过Calcite实现了Kafka和JDBC数据源的JOIN,可以很方便的把Kafka中的数据,当作一张无边界的表来使用。
- 目前只支持Kafka的数据源,后面考虑支持更多。
- 支持JDBC的维度表,来实现某个维度的去重,比如某日的UV。
- 支持 Console 、JDBC 、Redis和企业微信的SINK。
CREATE TABLE kafkaTable(
context.device.did:did string,
context.device.factory:factory string,
context.device.model:model string,
context.data.time:time timestamp
)WITH(
type='kafka08',
kafka.zkurl='kafka:2181/kafka',
kafka.topic='topic',
kafka.group='test',
kafka.reset='smallest',
kafka.batch='10'
);
CREATE SINK jdbcSink(
)WITH(
type='jdbc',
driver='com.mysql.jdbc.Driver',
url='jdbc:mysql://host/tmp?useSSL=false',
user='tmp',
password='password',
sql='INSERT INTO tmp (did,factory,model,createAt,updateAt) VALUES (?,?,?,?,?) ON DUPLICATE KEY UPDATE factory =? , model =? , updateAt =? '
);
insert into jdbcSink select did,factory,model, MIN(CAST(`time` as timestamp)) as createAt , MAX(CAST(`time` as timestamp)) as updateAt , factory , model , MAX(CAST(`time` as timestamp)) as updateAt FROM kafkaTable GROUP BY did,factory,model;