- Java 8
- Jersey Client (Virtual web client for workers to operate on)
- Apache Commons CLI (Handling CLI flags)
- JSoup (Scraping response bodies, used for stripping urls)
- Junit (Unit testing framework)
- Hamcrest (Personal preference to make testing functions more intuitive)
- Tomakehurst (Mocking http services)
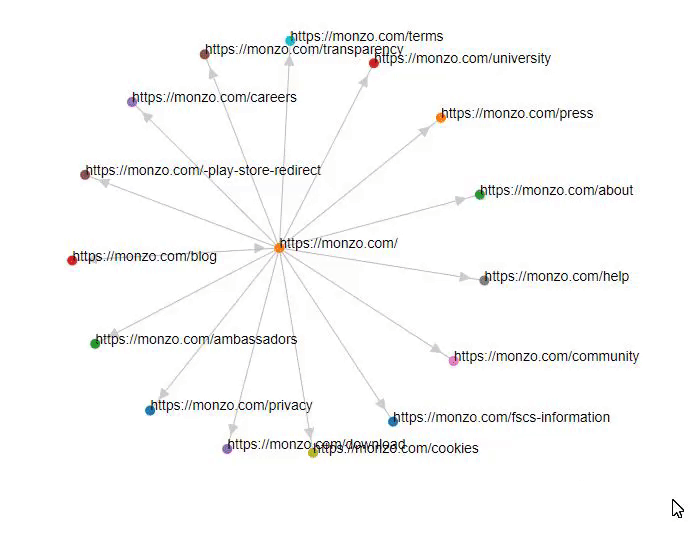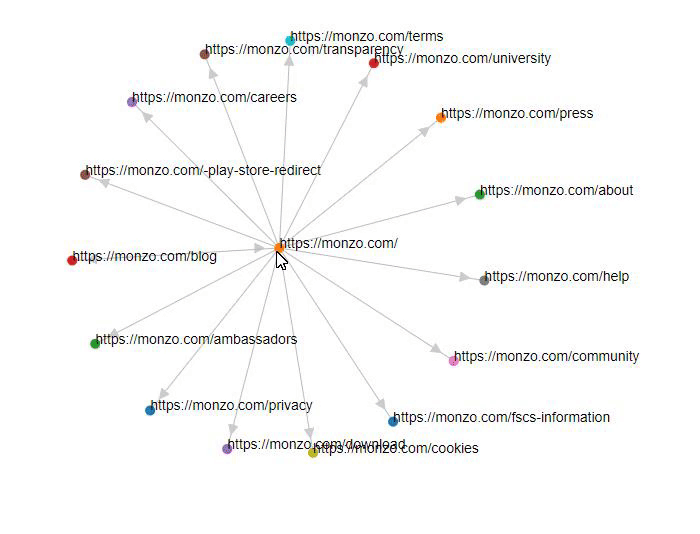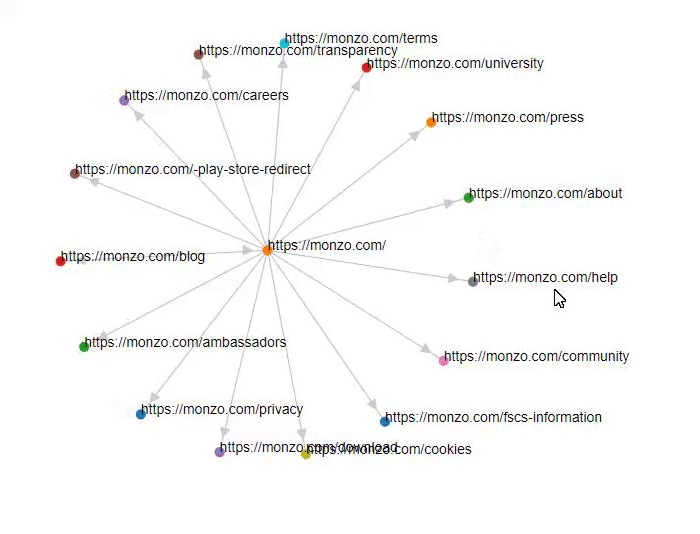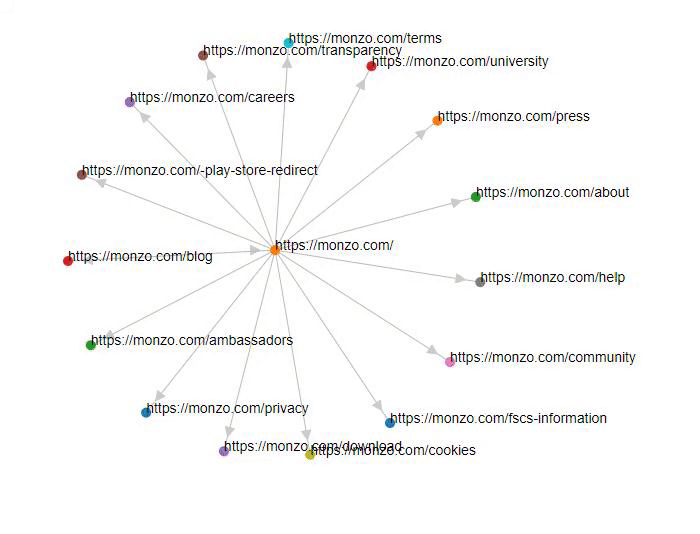
- D3 (Supporting graph visualisation)
Navigate to the javacrawler folder containing the \src folder, and run:
mvn package
Finally, the runnable file can be executed by executing the following command:
$ java -jar target/javacrawler-1.0-SNAPSHOT.jar
Alternatively, the following flags are provided:
--url=<siteUrl>: Default is https://monzo.com--crawlers=<crawlerCount>: Default is 25--txt_output=<textfilename>: Default is sitemap.txt--html_output=<htmlfilename>: Default is visualised.html
$ java -jar target/javacrawler-1.0-SNAPSHOT.jar --url=https://monzo.com --crawlers=10 --txt_output=result.txt --visual_output=webgraph.html
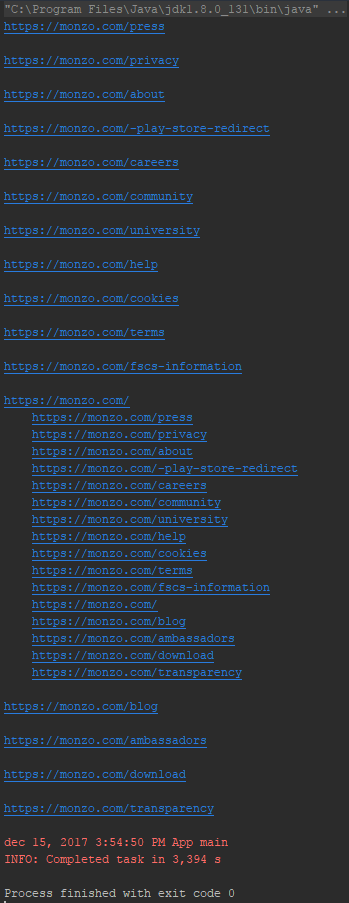
- This will scrape https://monzo.com
- This will use up to 10 concurrent threads working in the pool
- This will store the result in text-format in result.txt (inside the project's root folder, see console output for exact location details)
- This will store the visual graph in webgraph.html (inside the project's root folder, see console output for exact location details)
- Some feedback will be provided to the user, eg. when receiving bad input. This feedback could be more explicit to mention in more detail what exactly it is that went wrong.
- A more sophisticated logging system could be set-up by splitting different levels of logging priority into different streams and separating levels of concern. Eg. any low level importance logs can be written to a verbose log file, whereas high importance log levels (such as exceptions) can be written to a separate file or even be thrown into a messaging queue, for some kind of logging service to catch up.
- External pages will not be crawled nor considered as child node for any given url.