

Xorbits is a scalable Python data science framework that aims to scale the whole Python data science world, including numpy, pandas, scikit-learn and many other libraries. It can leverage multi cores or GPUs to accelerate computation on a single machine, or scale out up to thousands of machines to support processing terabytes of data. In our benchmark test, Xorbits is the fastest framework among the most popular distributed data science frameworks.
As for the name of xorbits, it has many meanings, you can treat it as X-or-bits or X-orbits or xor-bits,
just have fun to comprehend it in your own way.
Codes are almost identical except for the import,
replace import pandas with import xorbits.pandas will just work,
so does numpy and so forth.
The source code is currently hosted on GitHub at: https://github.com/xprobe-inc/xorbits
Binary installers for the latest released version are available at the Python Package Index (PyPI).
# PyPI
pip install xorbitsAs long as you know how to use numpy, pandas and so forth, you would probably know how to use xorbits.
All Xorbits APIs implemented or planned include:
| API | Implemented version or plan |
|---|---|
| xorbits.pandas | v0.1.0 |
| xorbits.numpy | v0.1.0 |
| xorbits.sklearn | Planned in the near future |
| xorbits.xgboost | Planned in the near future |
| xorbits.lightgbm | Planned in the near future |
| xorbits.xarray | Planned in the future |
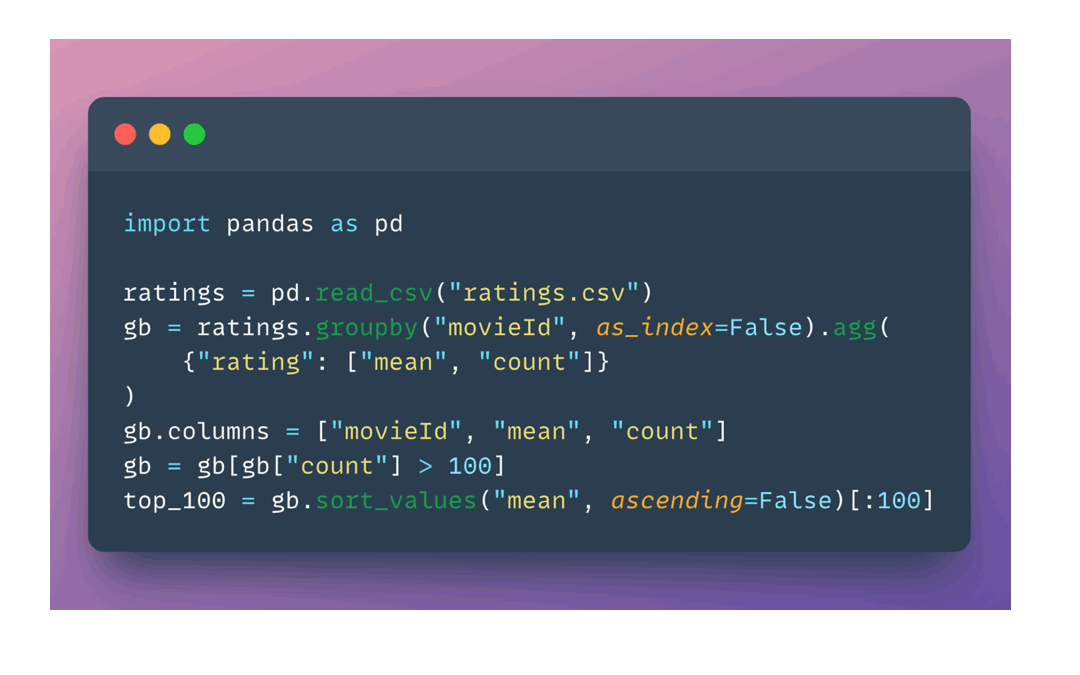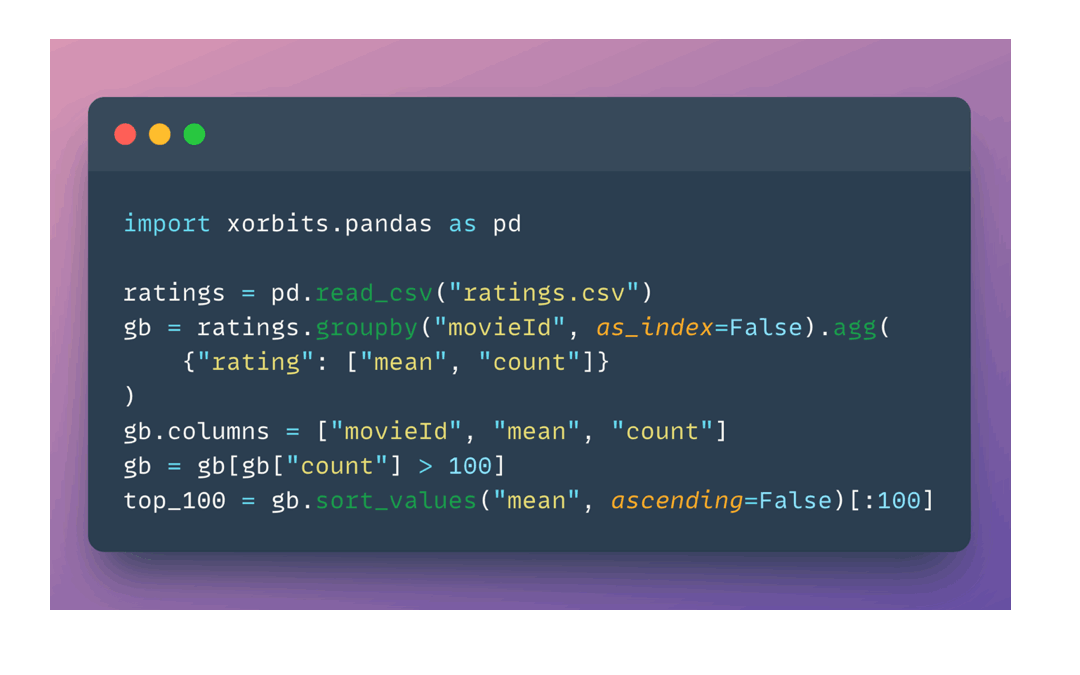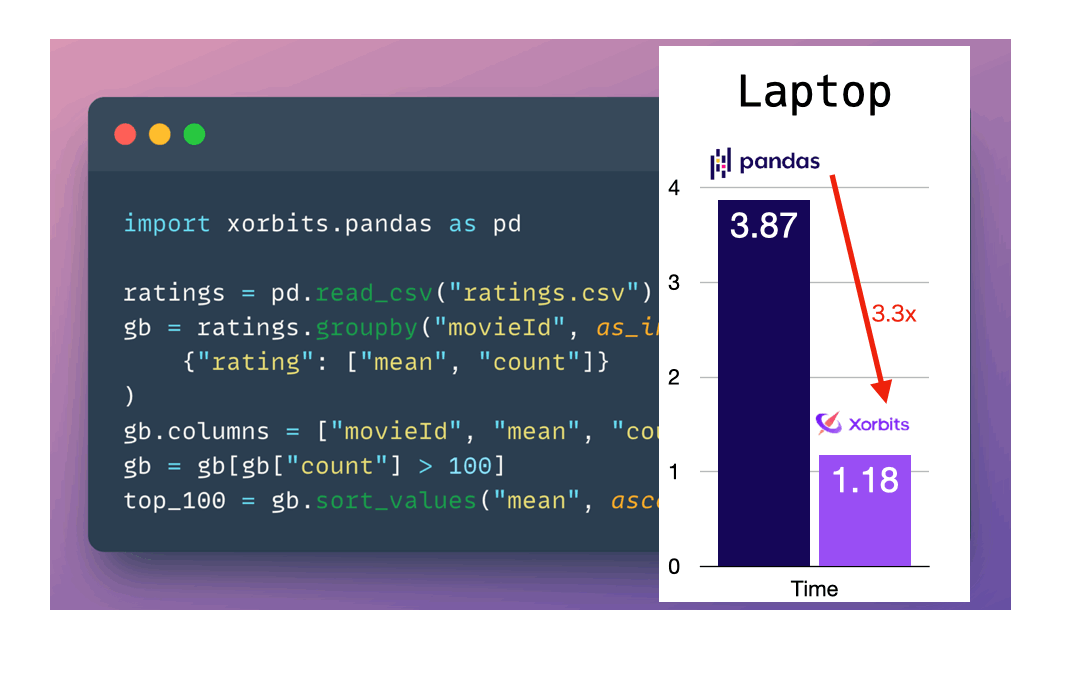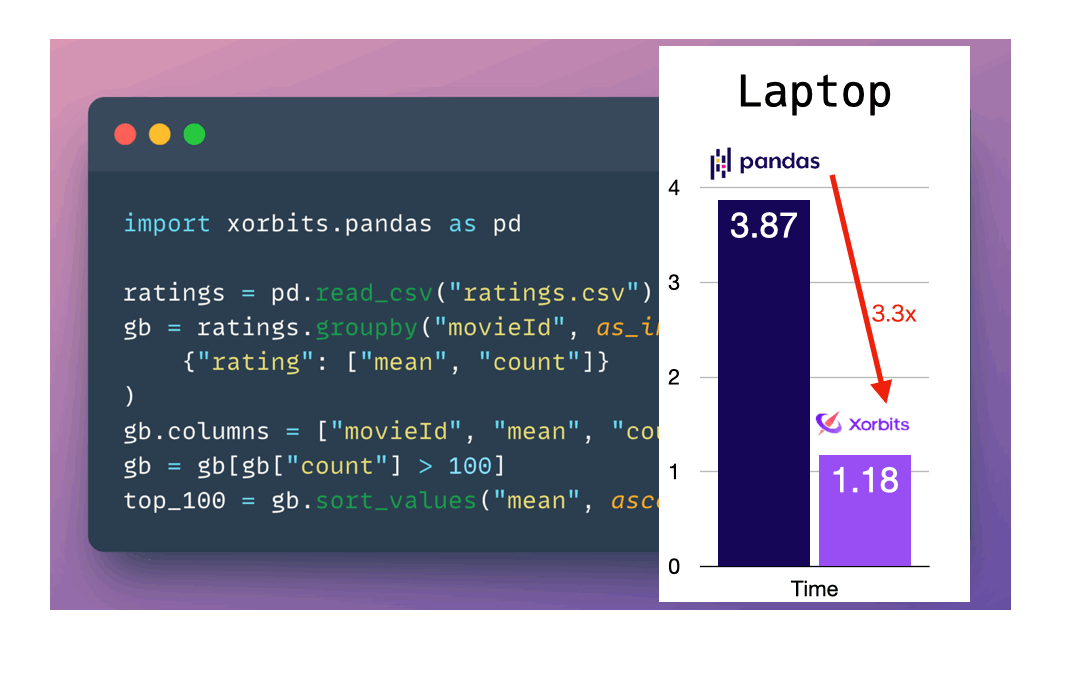
Xorbits is the fastest compared to other popular frameworks according to our benchmark tests.
We did benchmarks for TPC-H at scale factor 100 (~100 GB datasets) and 1000 (~1 TB datasets). The performances are shown as below.

Q21 was excluded since Dask ran out of memory. Across all queries, Xorbits was found to be 7.3x faster than Dask.

Across all queries, the two systems have roughly similar performance, but Xorbits provided much better API compatibility. Pandas API on Spark failed on Q1, Q4, Q7, Q21, and ran out of memory on Q20.
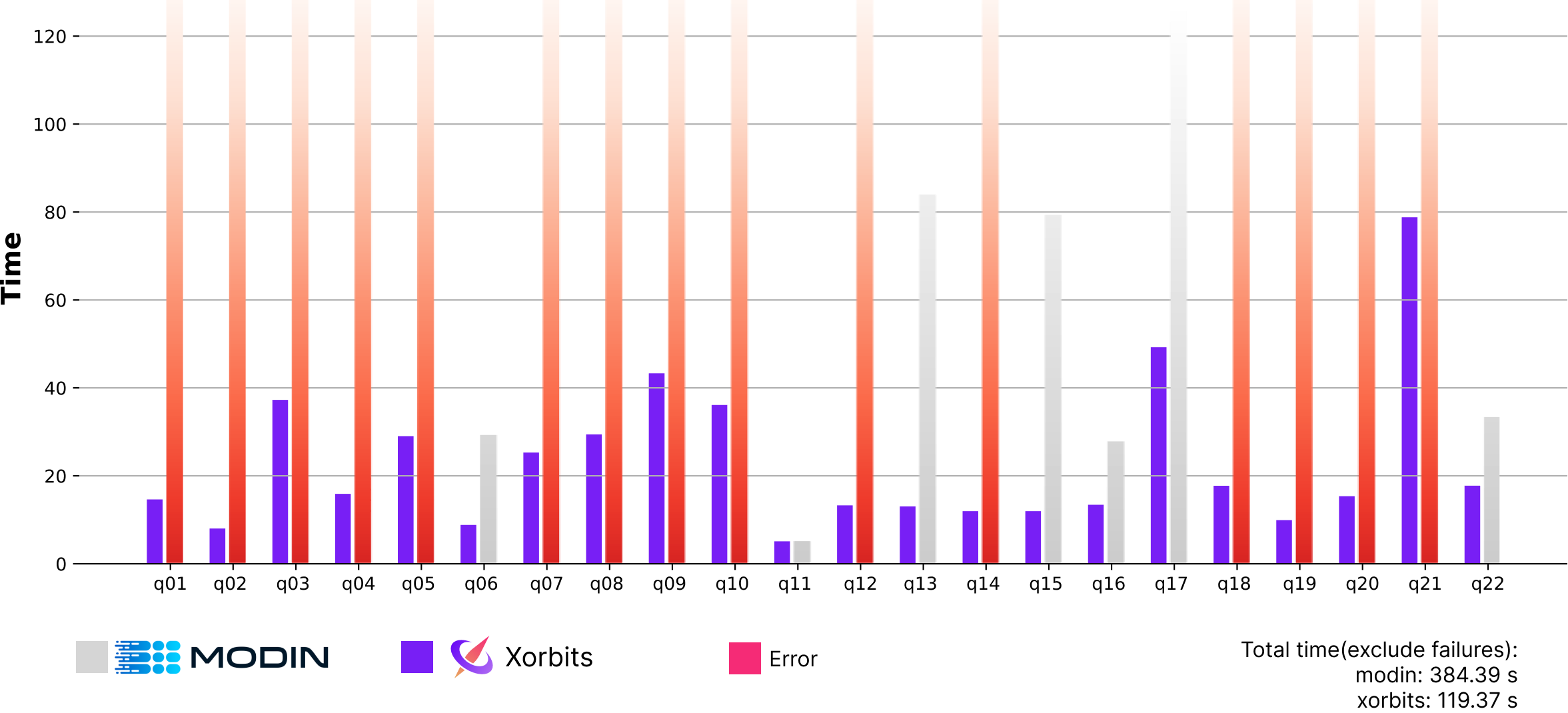
Although Modin ran out of memory for most of the queries that involve heavy data shuffles, making the performance difference less obvious, Xorbits was still found to be 3.2x faster than Modin.

Although Xorbits is able to pass all the queries in a row, Dask, Pandas API on Spark and Modin failed on most of the queries. Thus, we are not able to compare the performance difference now, and we plan to try again later.
For more information, see performance benchmarks.
Xorbits can be deployed on your local machine, largely deployed to a cluster via command lines, or deploy via Kubernetes and clouds.
| Deployment | Description |
|---|---|
| Local | Running Xorbits on a local machine, e.g. laptop |
| Cluster | Deploy Xorbits to existing cluster via command lines |
| Kubernetes | Deploy Xorbits to existing k8s cluster via python codes |
| Cloud | Deploy Xorbits to various cloud platforms via python codes |
The official documentation is hosted on: https://doc.xorbits.io
Main goals we want to achieve in the future include:
- Transitioning from pandas native to arrow native for data storage,
it will reduce the memory cost substantially and is more friendly for compute engine. - Introducing native engines that leverage technologies like vectorization and codegen to accelerate computations.
- Scale as many libraries and algorithms as possible!
More detailed roadmaps will be revealed soon, stay tuned!
The creators of Xorbits are mainly those of Mars, we built Xorbits currently on Mars to reduce duplicated work, but the vision of Xorbits suggests that it's not appropriate to put everything into Mars, instead, we need a new project to support the roadmaps better. In the future, we will replace some core internal components with other upcoming ones we will propose, stay tuned!
| Platform | Purpose |
|---|---|
| Discourse Forum | Asking usage questions and discussing development. |
| Github Issues | Reporting bugs and filing feature requests. |
| Slack | Collaborating with other Xorbits users. |
| StackOverflow | Asking questions about how to use Xorbits. |
| Staying up-to-date on new features. |