This is a fork of this, experimenting with different curriculum topics and themes.
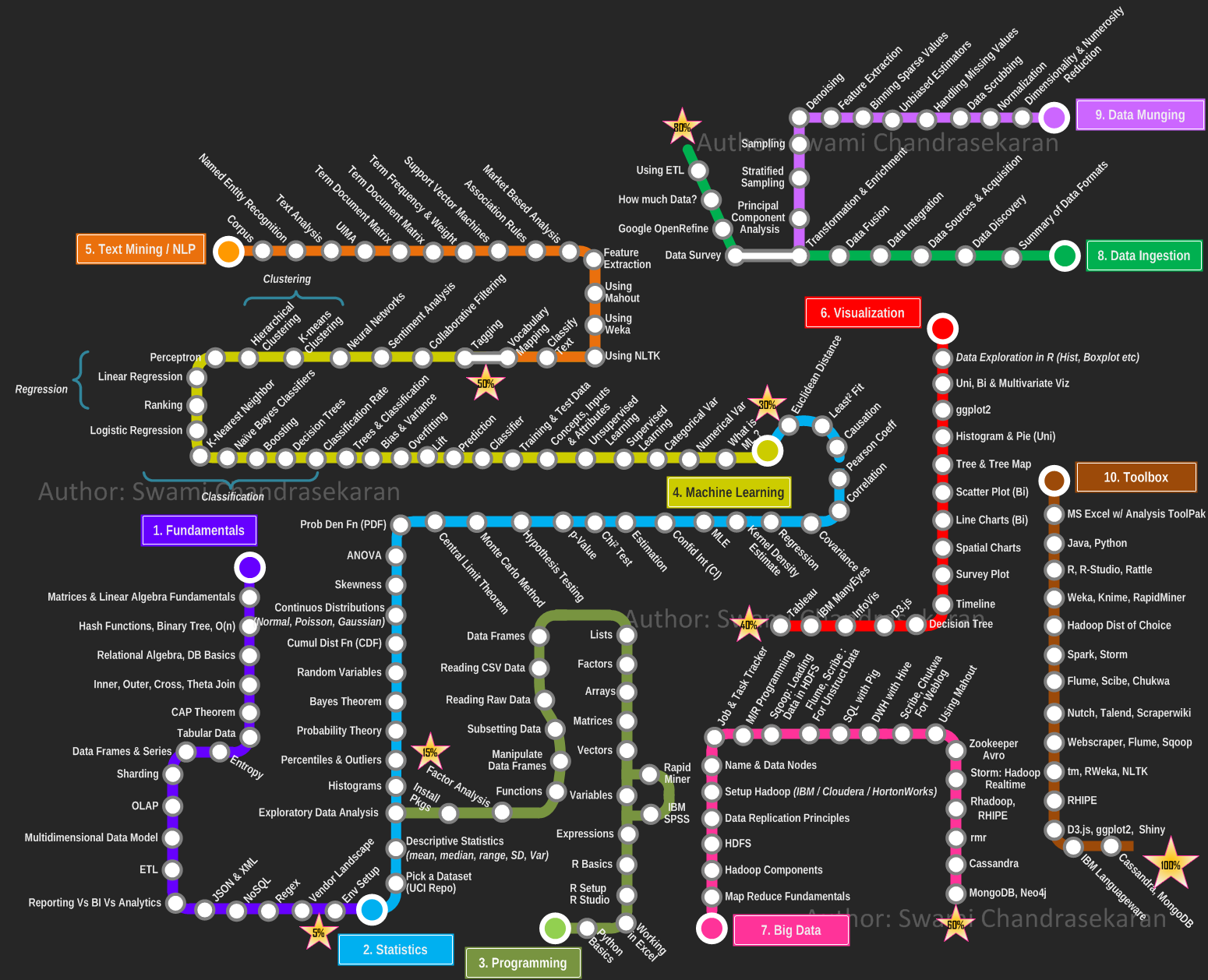
Intro to Data Science [UW / Coursera](https://www.coursera.org/course/dat * Topics: Python NLP on Twitter API, Distributed Computing Paradigm, MapReduce/Hadoop & Pig Script, SQL/NoSQL, Relational Algebra, Experiment design, Statistics, Graphs, Amazon EC2, Visualization.asci) Algebra-Steven-Levandosky/dp/0536667470/ref=sr_1_1?ie=UTF8&qid=1376546498&sr=8-1&keywords=linear+algebra+levandosky#)
- Forecasting: Principles and Practice Monash University / Book *uses R
- Problem-Solving Heuristics "How To Solve It" Polya / Book
- Think Bayes Allen Downey / Book
- Capstone Analysis of Your Own Design; Quora's Idea Compendium
- Toy Data Ideas
Skills
Matrices and Linear Algebra fundamentals
Linear Algebra / Levandosky [Stanford / Book](http://www.amazon.com/Linear-
Coding the Matrix: Linear Algebra through Computer Science Applications [Brown / Coursera](https://www.coursera.org/course/matrix)
Hash Functions, Binary Tree, O(n)
Relational Algebra
DB Basics
Inner, Outer, Cross, Theta join
CAP Theorem
abular data
Entropy
Data Frames and Series
Sharding
OLAP
Multidimensional Data Model
ETL
Reporting vs. BI vs. Analytics
JSON & XML
NoSQL
Regex
Vendor Landscape
Env setup
- Statistics Stats in a Nutshell / Book Pick a dataset
- Linear Programming (Math 407) University of Washington / Course
Skills
Descriptive statistics
Exploratory Data Analysis
Histograms
Percentiles and outliers
Probability theory
Bayes Theorem
Random Variables
Cumulative Distribution Function (CDF)
Continous Distributions (Normal, Poisson, Gaussian)
Skewness
ANOVA
Probability Density Functions
Central Limit Theorem
Monte Carlo Method
Hypothesis testing
p-value
Chi squared test
Estimation
Confidence intevals (CI)
MLE
Kernel Density Estimate
Regression
Covariance
Correlation
Pearson Coefficient
Causation
Least squares fit
Euclidean Distance
- Probabilistic Programming and Bayesian Methods for Hackers Github / Tutorials
- PGMs / Koller Stanford / Coursera
Skills
Unix cli install programs and packages
Bash basics
cat, grep, wget etc
piping
understand stdio
Python
Regex
MS Excel w/ Analysis ToolPak
Java
R, R-studio, Rattle
IBM SPSS
Weka, Knime, RapidMiner
Hadoop ditribution of choice
Spark, Storm
Flume, Scibe, Chukwa
Nutch, Talend, Scraperwiki
Webscraper, Flume, Sqoop
tm, RWeka, NLTK
RHIPE
D3.js, ggplot2, Shiny
IBM Languageware
Cassandra, MongoDB
-
Algorithms
-
Algorithms Design & Analysis I Stanford / Coursera
-
Algorithm Design Kleinberg & Tardos / Book
-
Databases
-
SQL Tutorial W3Schools / Tutorials
-
Introduction to Databases Stanford / Online Course
-
Python (Learning)
-
New To Python: Learn Python the Hard Way, Google's Python Class
-
Python (Libraries)
-
Basic Packages Python, virtualenv, NumPy, SciPy, matplotlib and IPython
-
Data Science in iPython Notebooks (Linear Regression, Logistic Regression, Random Forests, K-Means Clustering)
-
Bayesian Inference | pymc
-
Labeled data structures objects, statistical functions, etc pandas (See: Python for Data Analysis)
-
Python wrapper for the Twitter API twython
-
Tools for Data Mining & Analysis scikit-learn
-
Network Modeling & Viz networkx
-
Natural Language Toolkit NLTK
Skills
Variables
Vectors
Matrices
Arrays
Factors
Lists
Data Frames
Reading CSV data
Reading Raw data
Manipulate Data Frames
Functions
Factor Analysis
The art of converting or mapping data from one "raw" form into another format that allows for more convenient consumption of the data with the help of semi-automated tools. Expect to spend 80% of your workday doing some sort of data wrangling.
Skills
Dimensionality & Numerosity Reduction
Normalization
Data Scrubbing
Handling missing values
Unbiased estimators
Binning sparse values
Feature Extraction
Denoising
Sampling
Stratified Sampling
Principal Component Analysis
Summary of Data Formats
Data Discovery
Data Sources & Acquisition
Data Integration
Data Fusion
Transformation and enrichment
Data survey
Google OpenRefine
How Much Daya
Using ETL
Skills
Data Exploration in R (Hist, boxplot etc)
Uni, Bi and multivariate Viz
ggplot2
Histogram & Pie (Uni)
Tree and Tree Map
Scatter Plot
Line Charts
Survey Plot
Timeline
Decision Tree
D3.js
InfoVis
IBM ManyEyes
Tableau
- Mining Massive Data Sets Stanford / Book
- Mining The Social Web O'Reilly / Book
- Introduction to Information Retrieval Stanford / Book
- Analysis
- Python for Data Analysis O'Reilly / Book
- Big Data Analysis with Twitter UC Berkeley / Lectures
- Social and Economic Networks: Models and Analysis / Stanford / Coursera
- Information Visualization "Envisioning Information" Tufte / Book
- Machine Learning / Ng Stanford / Coursera
- A Course in Machine Learning / Hal Daumé III UMD Online Book
- Programming Collective Intelligence O'Reilly / Book
- Statistics The Elements of Statistical Learning
- Machine Learning / CaltechX Caltech / Edx
Skills
Numerical Var
Categorical Var
Supervised Learning
Unsupervised Learning
Concepts, Inputs and Attributes
Training and Test Data
Classifier
Prediction
Lift
Overfitting
Bias and variance
Classification
Trees and classification
Classification rate
Decision trees
Boosting
Naive Bayes Classifiers
K-Nearest neighbour
Regression
Logistic regression
Ranking
Linear regression
Perceptron
Clustering
Hierarchical clustering
K-means clustering
Neural Networks
Sentiment analysis
Collaborative Filtering
Tagging
- NLP with Python O'Reilly / Book
Skills
Corpus
Named Entity Recognition
Text Analysis
UIMA
Term Document Matrix
Term Frequency and weight
Support Vector Machines
Association rules
Market Based Analysis
Feature Extraction
Use Mahout
Use Weka
Use NLTK
Classify Text
Vocabulaty Mapping
- Healthcare Twitter Analysis Coursolve & UW Data Science
Map reduce fundamentals
Hadoop
HDFS
Data Replication Principles
Setup Hadoop (IBM / Cloudera / HortonWorks)
Name & Data nodes
Job and task tracker
M/R Programming
Sqoop: Loading Data in HDFS
Flube, Scribe: For Unstructured Data
SQL with Pig
DWH with Hive
Scribe, Chukwa For Weblog
Using Mahout
Zookeeper Avro
Storm: Hadoop Realtime
Rhadoop, RHIPE
rmr
Cassandra
MongoDB, Neo4j
- Coursera
- Khan Academy
- Wolfram Alpha
- Wikipedia
- Kindle .mobis
- Great PopSci Read: The Signal and The Noise Nate Silver
- Zipfian Academy's List of Resources
- A Software Engineer's Guide to Getting Started w Data Science
- Data Scientist Interviews Metamarkets
Please Share and Contribute Your Ideas -- it's Open Source!
This is an introduction geared toward those with at least a minimum understanding of programming, and (perhaps obviously) an interest in the components of Data Science (like statistics and distributed computing). Out of personal preference and need for focus, the curriculum assumes and mainly uses Python tools and resources, except where marked as R, Java etc.