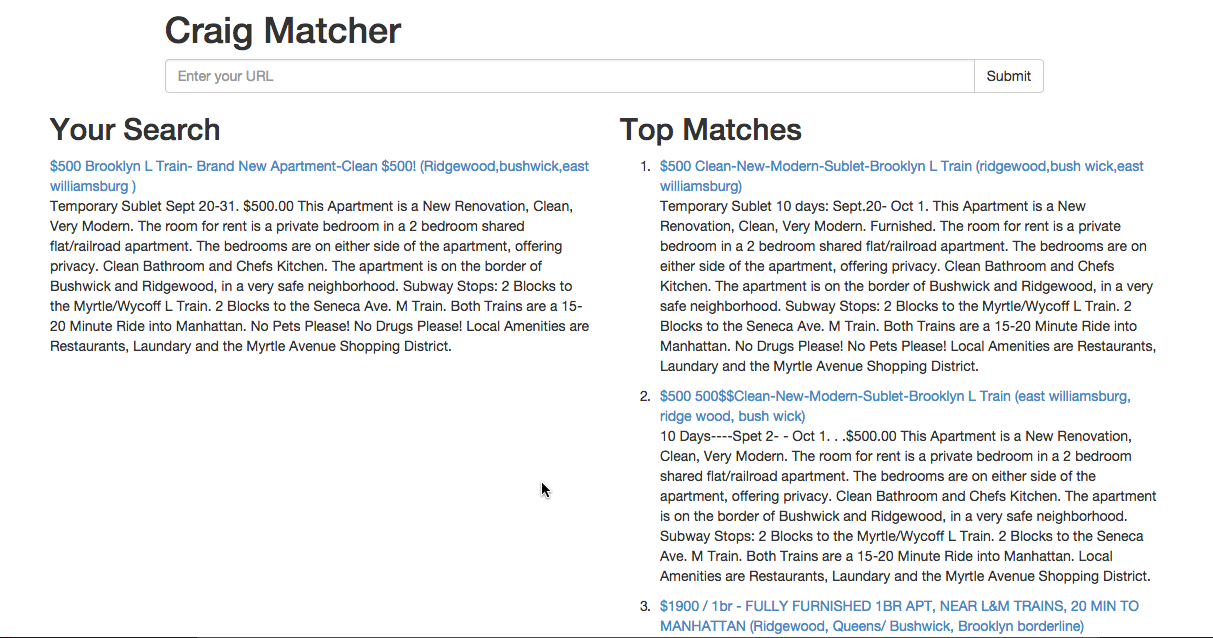
An app that allows you to find similar sublet postings in NYC on Craiglist based on the textual information contained in the documents. This project has various components and is still in progress.
- Text processing with NLTK, such as tokenization, stopwords removal and stemming.
- Building a VSM(vector space model) for a collection of documents using the scikit-learn library. Results are used to compare with my own implementation of the algorithms.
- Crawling data from NYC sublet postings on Craigslist using Scrapy. By default, each run will scrape the first 10 pages of https://newyork.craigslist.org/sub/, which contains 1000 postings with their titles and contents. The job is scheduled to run once a day.
- Data storage and retrieval using MongoDB, with Flask-PyMongo and scrapy-mongodb (MongoDB pipeline for Scrapy).
(Refer to linked pages for details)
In information retrieval, tf-idf is a standard method for measuring the importance of a word in a document with resepct to a corpus.
A vector space model is a way to represent a collection of documents in a high-dimensional space, with each row of the matrix being a document represented by a sparse vector composed of tf-idf weights.
With the vector representations, we can mesaure the similarity between two documents using consine similarity.
- Assuming that you have
pipinstalled, runpip install -r requirements.txtto install dependencies. - Set the URI of your database in your environment. For localhost, you can set it to
mongodb://localhost:27017
export MONGOHQ_URL=<DB_PATH>
To scrape data (the first 1000 postins) from https://newyork.craigslist.org/sub/:
- Run
scrapy crawl craigto start the spider. Output will be logged in the console. When the crawl job is done, check your database to make sure that thepostingscollection contains rougly 1000 documents.
To run the app:
- Run
python craig.pyto start the server - Visit the running app at
http://localhost:7000/