本文转载自互联网,侵删 本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
喜欢的话麻烦点下Star哈
本系列文章将整理到我的个人博客
更多Java技术文章会更新在我的微信公众号【码猿技术专栏】上,欢迎关注 该系列博文会介绍常见的后端技术,这对后端工程师来说是一种综合能力,我们会逐步了解搜索技术,云计算相关技术、大数据研发等常见的技术喜提,以便让你更完整地了解后端技术栈的全貌,为后续参与分布式应用的开发和学习做好准备。
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【码猿技术专栏】联系我,欢迎你参与本系列博文的创作和修订
喜欢的话麻烦点下Star哈
很多东西在时序图中体现的已经非常清楚了,没有必要再一步一步的作介绍,所以本文以图为主,然后对部分内容加以简单解释。
绘制图形使用的工具是 PlantUML + Visual Studio Code + PlantUML Extension
本文对 Tomcat 的介绍以 Tomcat-9.0.0.M22 为标准。
Tomcat-9.0.0.M22 是 Tomcat 目前最新的版本,但尚未发布,它实现了 Servlet4.0 及 JSP2.3 并提供了很多新特性,需要 1.8 及以上的 JDK 支持等等,详情请查阅 Tomcat-9.0-doc。
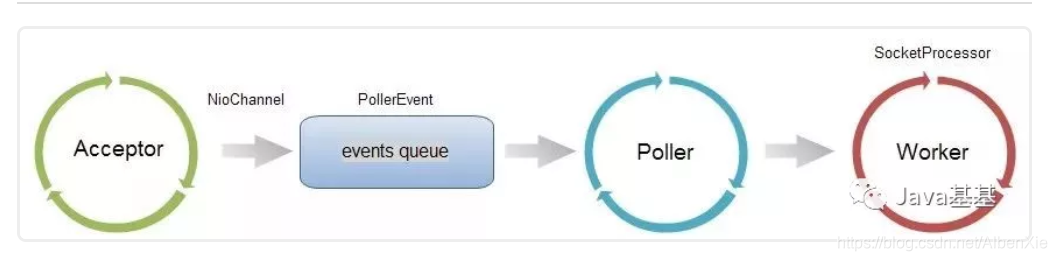
Connector 启动以后会启动一组线程用于不同阶段的请求处理过程。
-
Acceptor 线程组。用于接受新连接,并将新连接封装一下,选择一个 Poller 将新连接添加到 Poller 的事件队列中。
-
Poller 线程组。用于监听 Socket 事件,当 Socket 可读或可写等等时,将 Socket 封装一下添加到 worker 线程池的任务队列中。
-
worker 线程组。用于对请求进行处理,包括分析请求报文并创建 Request 对象,调用容器的 pipeline 进行处理。
Acceptor、Poller、worker 所在的 ThreadPoolExecutor 都维护在 NioEndpoint 中。
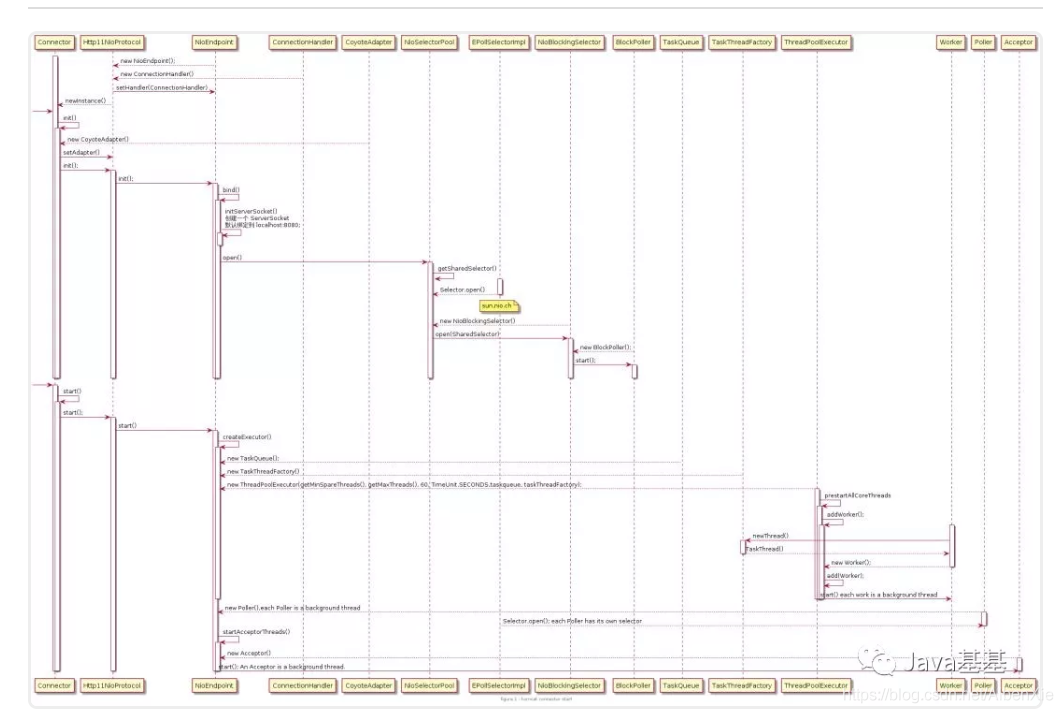
-
initServerSocket(),通过 ServerSocketChannel.open() 打开一个 ServerSocket,默认绑定到 8080 端口,默认的连接等待队列长度是 100, 当超过 100 个时会拒绝服务。我们可以通过配置 conf/server.xml 中 Connector 的 acceptCount 属性对其进行定制。
-
createExecutor() 用于创建 Worker 线程池。默认会启动 10 个 Worker 线程,Tomcat 处理请求过程中,Woker 最多不超过 200 个。我们可以通过配置 conf/server.xml 中 Connector 的 minSpareThreads 和 maxThreads 对这两个属性进行定制。
-
Pollor 用于检测已就绪的 Socket。默认最多不超过 2 个,Math.min(2,Runtime.getRuntime().availableProcessors());。我们可以通过配置 pollerThreadCount 来定制。
-
Acceptor 用于接受新连接。默认是 1 个。我们可以通过配置 acceptorThreadCount 对其进行定制。
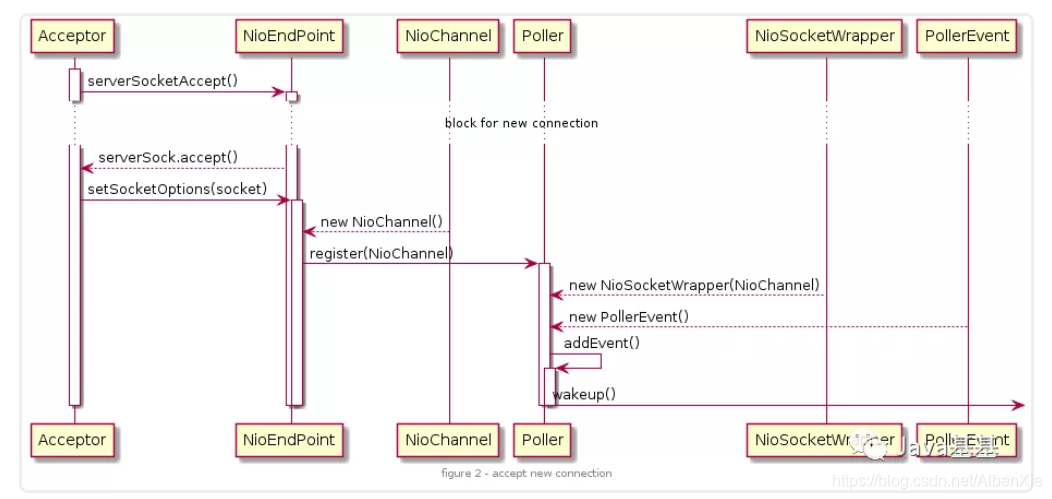
-
Acceptor 在启动后会阻塞在 ServerSocketChannel.accept(); 方法处,当有新连接到达时,该方法返回一个 SocketChannel。
-
配置完 Socket 以后将 Socket 封装到 NioChannel 中,并注册到 Poller,值的一提的是,我们一开始就启动了多个 Poller 线程,注册的时候,连接是公平的分配到每个 Poller 的。NioEndpoint 维护了一个 Poller 数组,当一个连接分配给 pollers[index] 时,下一个连接就会分配给 pollers[(index+1)%pollers.length].
-
addEvent() 方法会将 Socket 添加到该 Poller 的 PollerEvent 队列中。到此 Acceptor 的任务就完成了。
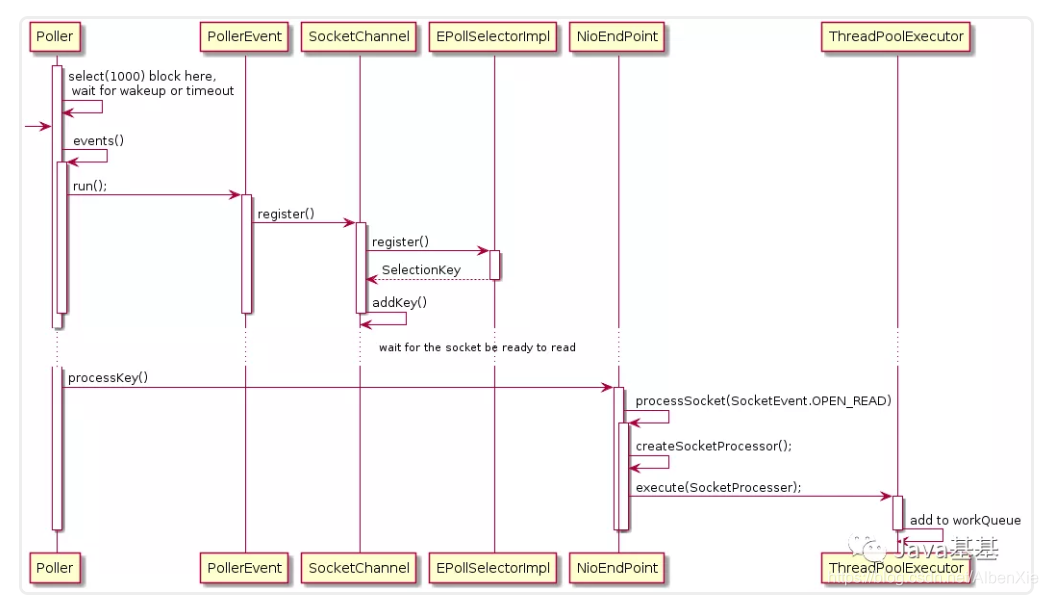
-
selector.select(1000)。当 Poller 启动后因为 selector 中并没有已注册的 Channel,所以当执行到该方法时只能阻塞。所有的 Poller 共用一个 Selector,其实现类是 sun.nio.ch.EPollSelectorImpl
-
events() 方法会将通过 addEvent() 方法添加到事件队列中的 Socket 注册到 EPollSelectorImpl,当 Socket 可读时,Poller 才对其进行处理
-
createSocketProcessor() 方法将 Socket 封装到 SocketProcessor 中,SocketProcessor 实现了 Runnable 接口。worker 线程通过调用其 run() 方法来对 Socket 进行处理。
-
execute(SocketProcessor) 方法将 SocketProcessor 提交到线程池,放入线程池的 workQueue 中。workQueue 是 BlockingQueue 的实例。到此 Poller 的任务就完成了。
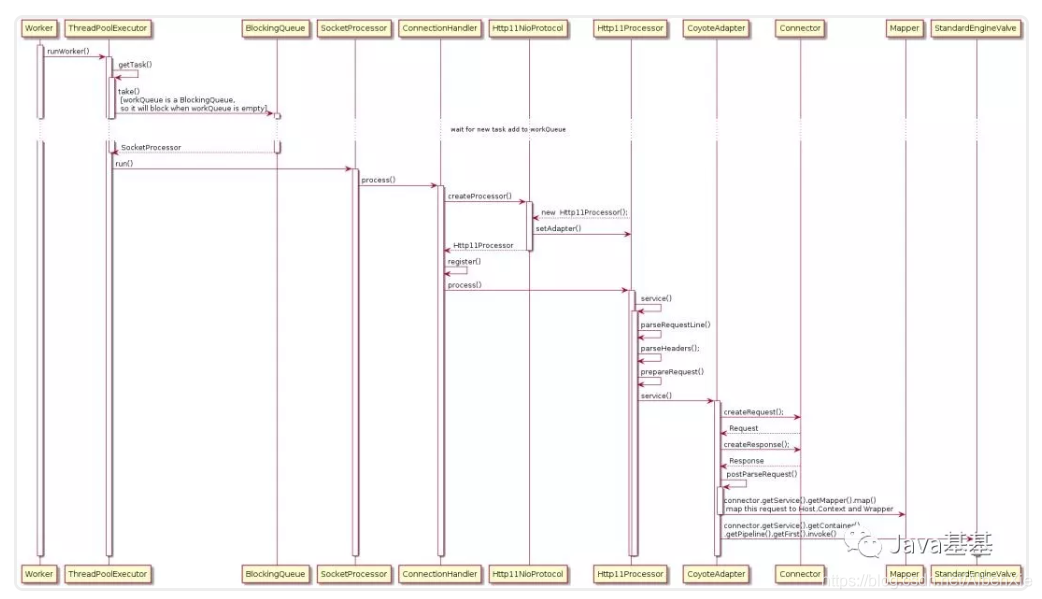
-
worker 线程被创建以后就执行 ThreadPoolExecutor 的 runWorker() 方法,试图从 workQueue 中取待处理任务,但是一开始 workQueue 是空的,所以 worker 线程会阻塞在 workQueue.take() 方法。
-
当新任务添加到 workQueue后,workQueue.take() 方法会返回一个 Runnable,通常是 SocketProcessor,然后 worker 线程调用 SocketProcessor 的 run() 方法对 Socket 进行处理。
-
createProcessor() 会创建一个 Http11Processor, 它用来解析 Socket,将 Socket 中的内容封装到 Request 中。注意这个 Request 是临时使用的一个类,它的全类名是 org.apache.coyote.Request,
-
postParseRequest() 方法封装一下 Request,并处理一下映射关系(从 URL 映射到相应的 Host、Context、Wrapper)。
-
CoyoteAdapter 将 Rquest 提交给 Container 处理之前,并将 org.apache.coyote.Request 封装到 org.apache.catalina.connector.Request,传递给 Container 处理的 Request 是 org.apache.catalina.connector.Request。
-
connector.getService().getMapper().map(),用来在 Mapper 中查询 URL 的映射关系。映射关系会保留到 org.apache.catalina.connector.Request 中,Container 处理阶段 request.getHost() 是使用的就是这个阶段查询到的映射主机,以此类推 request.getContext()、request.getWrapper() 都是。
- connector.getService().getContainer().getPipeline().getFirst().invoke() 会将请求传递到 Container 处理,当然了 Container 处理也是在 Worker 线程中执行的,但是这是一个相对独立的模块,所以单独分出来一节。
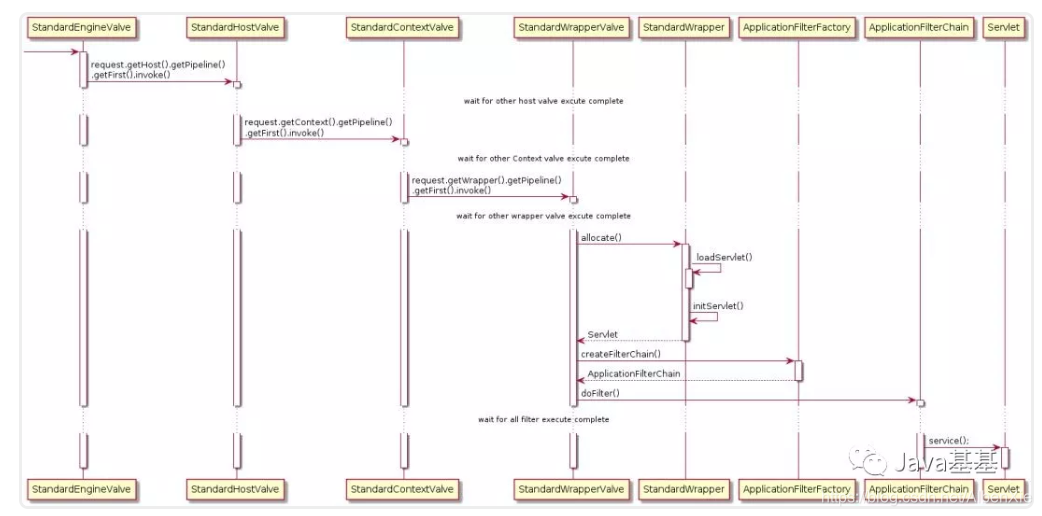
-
需要注意的是,基本上每一个容器的 StandardPipeline 上都会有多个已注册的 Valve,我们只关注每个容器的 Basic Valve。其他 Valve 都是在 Basic Valve 前执行。
-
request.getHost().getPipeline().getFirst().invoke() 先获取对应的 StandardHost,并执行其 pipeline。
-
request.getContext().getPipeline().getFirst().invoke() 先获取对应的 StandardContext,并执行其 pipeline。
-
request.getWrapper().getPipeline().getFirst().invoke() 先获取对应的 StandardWrapper,并执行其 pipeline。
-
最值得说的就是 StandardWrapper 的 Basic Valve,StandardWrapperValve
-
allocate() 用来加载并初始化 Servlet,值的一提的是 Servlet 并不都是单例的,当 Servlet 实现了 SingleThreadModel 接口后,StandardWrapper 会维护一组 Servlet 实例,这是享元模式。当然了 SingleThreadModel在 Servlet 2.4 以后就弃用了。
-
createFilterChain() 方法会从 StandardContext 中获取到所有的过滤器,然后将匹配 Request URL 的所有过滤器挑选出来添加到 filterChain 中。
-
doFilter() 执行过滤链,当所有的过滤器都执行完毕后调用 Servlet 的 service() 方法。
-
《How Tomcat works》
https://www.amazon.com/How-Tomcat-Works-Budi-Kurniawan/dp/097521280X
-
《Tomcat 架构解析》– 刘光瑞
-
Tomcat-9.0-doc
-
apache-tomcat-9.0.0.M22-src
http://www-eu.apache.org/dist/tomcat/tomcat-9/v9.0.0.M22/src/
-
tomcat架构分析 (connector NIO 实现)
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【码猿技术专栏】一位阿里 Java 工程师的技术小站,作者不才陈某,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
Java面试宝典: 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 “Java面试宝典” 即可免费无套路获取。
