UKBsearch is a search tool to retreive term(or terms) from UKBiobank HTML files and tab files downloaded in the local drive.


- from pypi
pip install ukbsearch
- from github
pip install https://github.com/danielmsk/ukbsearch/raw/main/dist/ukbsearch-0.2.2-py3-none-any.whl
This UKBsearch requires the following packages:
- rich
- pyreadr
- prettytable
- pandas
- pytabix
optional arguments:
-h, --help show this help message and exit
-v, --version show program's version number and exit
-s, --searchterm search. terms (ex: age smoking)
-s age
-s age smoking
-s 'smok*'
-s '*age' 'smok*'
-l, --logic logical operator for multiple terms [or(default), and]
-s '*age' 'smok*' -l and
-s age 'smok*' -l or
-o, --out title of output file
-o searchresult_20220322
-t, --outtype output type [console(default), csv, udi]
-t csv
-t console csv
-t udi
-t console udi
-p, --path directory path for data files (.html, .Rdata) (default: /data2/UKbiobank/ukb_phenotype)
-p /other/path/for/ukb/html/.
-u, --udilist FileID and UDI list for saving data from tcf files
-u ukb39003 3536-0.0 3536-1.0 3536-2.0
-d, --savedata save data from .Rdata [csv, rdata]
-d csv
-d rdata
-d csv rdata
-i, --index
index tab file and make tcf file (ex. ukb39003.tab)
ukbsearch -s 'ag*' 'smok*' -l and
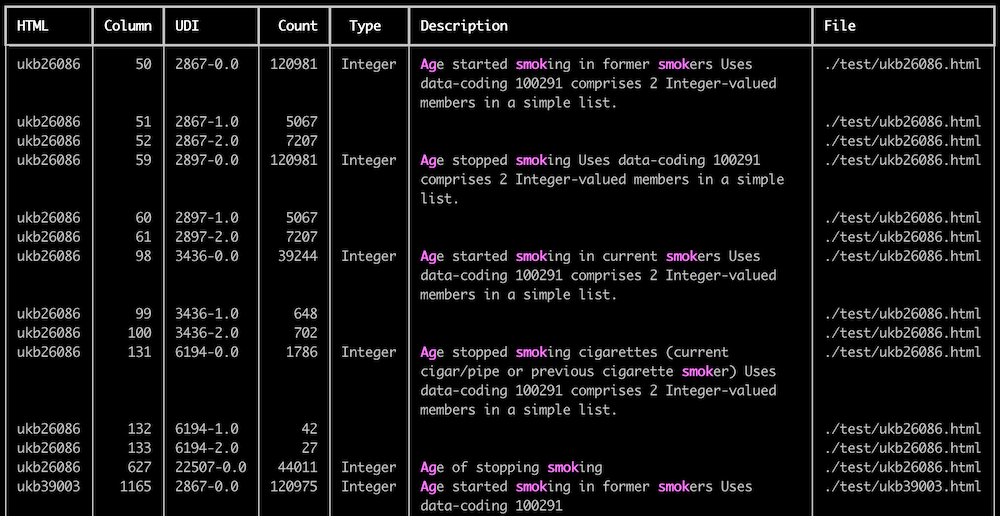
ukbsearch -s age
ukbsearch --searchterm age
ukbsearch -s 'ag*'
ukbsearch -s '*ge'
- The logical operators (
andoror) are supported.
ukbsearch -s age smoking
ukbsearch -s age smoking -l or
ukbsearch -s age smoking -l and
ukbsearch -s 'ag*' 'smok*' -l and
ukbsearch -s 'ag*' 'smok*' -l and -t udi
ukbsearch -s 'ag*' 'rep*' -l and -o test1 -t csv
(= ukbsearch --searchterm 'ag*' 'rep*' --logic and --out test1 --outtype csv)
ukbsearch -s 'ag*' 'rep*' -l and -o test1 -t console csv
ukbsearch -s 'ag*' 'rep*' -l and -o test1 -t console udi csv
- The default path is
/data2/UKbiobank/ukb_phenotype.
ukbsearch -s age -p /other/path/for/ukb/html/.
ukbsearch -i ukb26086.tab
This step generates .tab.tcf.gz, .tab.tcf.gz.tbi, and .tab.tcf.gz.idx. After generating tcf files, the tab file is no longer required to search.
ukbsearch -u ukb39003 3536-0.0 3536-1.0 3536-2.0 -d csv -o test3
(=ukbsearch --udilist ukb39003 3536-0.0 3536-1.0 3536-2.0 --savedata csv --out test3)
ukbsearch -u ukb39003 3536-0.0 3536-1.0 ukb26086 20161-0.0 21003-1.0 -d csv rdata -o test3
ukbsearch -s 'ag*' 'rep*' -l and -d csv -o test3
ukbsearch -s 'ag*' 'rep*' -l and -d rdata -o test3
- 0.2.2 (2022-04-05)
- change saving type for a single file
- remove csvi (inversed form) option.
- 0.2.1 (2022-03-25)
- add csvi (inversed form) option.
- debug unsaved values issue.
- 0.2.0 (2022-03-24)
- implementated tab file indexing based on tabix.
- 0.1.1 (2022-03-23)
- changed default path to
/data2/UKbiobank/ukb_phenotype
- changed default path to
- 0.1.0 (2022-03-21)
- first released.