generated from databricks-industry-solutions/industry-solutions-blueprints
-
Notifications
You must be signed in to change notification settings - Fork 0
/
Copy path02_CreateTables.py
194 lines (148 loc) · 9.43 KB
/
02_CreateTables.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
# Databricks notebook source
# MAGIC %md
# MAGIC # Creating Tables
# MAGIC To prepare for training we are going to turn our labels into something called masks. A mask is meant to identify each pixel in an image as just background that we are not interested in or label that pixel as a certain asset class. The mask and image will be two columns in a delta table where each column is stored as raw bytes. We will be utilizing bytes stored directly in delta tables so that we can pack more records into a file and not be as IO bound. Using each raw image as an individual object in cloud storage would cause an unnesceeary amount of overhead making a cloud storage call for each invidual image.
# MAGIC
# MAGIC 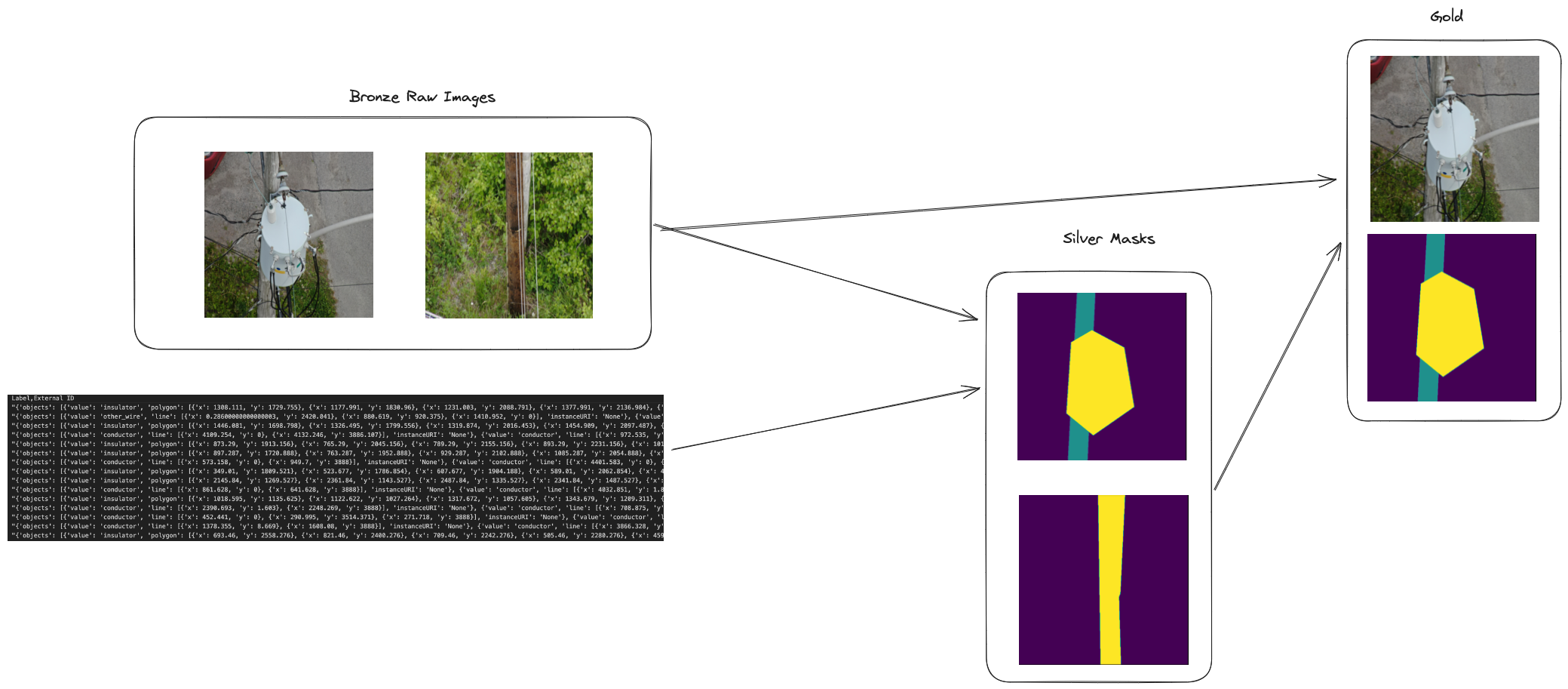
# COMMAND ----------
# MAGIC %run ./00_Intro_and_Config
# COMMAND ----------
# MAGIC %md
# MAGIC ## UDF to create image masks from class labels
# MAGIC In order to create a mask the labels for that image need to be drawn onto a blank canvas that is the same size as the original image. Each pixel will either get a background label (0) or a class label that can be any number assigned to a class. For example an insulator could be class number 4. The important thing is that classes need to be numbers for our machine learning model to understand
# COMMAND ----------
import cv2
import os
import numpy as np
import json
from pyspark.sql.functions import udf, from_json
@udf('binary')
def create_mask_from_polygons(image_bytes, polygons):
polygons = json.loads(polygons) # load our json labels into a python dictionary
# Read the original image to get its dimensions
x = np.frombuffer(image_bytes, np.uint8) # get the bytes of the image passed into the user defined function
img = cv2.imdecode(x, cv2.IMREAD_GRAYSCALE) # create an open cv image out of the numpy array
h, w = img.shape # get the height and width of the image
# Initialize a blank grayscale image of the same dimensions
# So we can start to color it in with our different classes
mask = np.zeros((h, w), np.uint8)
# Draw masks for each object in the image
for class_id, class_polygons in polygons.items():
for polygon in class_polygons:
cv2.fillPoly(mask, [np.array(polygon, np.int32)], color=int(class_id))
# Return the mask to be saved in delta
_, encoded_img = cv2.imencode('.png', mask)
masked_byte_array = encoded_img.tobytes()
return masked_byte_array # going to be stored as bytes
# COMMAND ----------
# MAGIC %md
# MAGIC ## Convert Raw Label Data to Structured Values
# MAGIC The json values are a little difficult to work with so we are going to transform them to have more structure and map them from their human readable class to a computer model version
# COMMAND ----------
# This dict will map the original class names to numeric for our computer vision model to consume
obj_mapping = {
"insulator": 4,
"crossarm":3,
"conductor":5,
"pole":1,
"cutouts":0,
"other_wire":0,
"guy_wires":0,
"transformers":2,
"background_structure":0
}
@udf("string")
def transform_labels(objects):
if objects is None: # if there are no objects in the image then exit early
return {}
obj = json.loads(objects) # load the objects from string to json
obj_dict = {} # instantiate an empty return dict
for v in obj['objects']: # loop through all objects in the image
cls = v['value'] # get the string class value
cls_int = obj_mapping[cls] # convert to the integer version
if obj_dict.get(cls_int) is None: # create a new sub dict for the class if it does not exist already
obj_dict[cls_int] = [] # create an empty list for the new class
pnts = v.get('line') if v.get('line') is not None else v.get('polygon') # extract all of the points for the object
obj_list = []
for pnt in pnts: # convert all of the points to float and add it as the object points
pnt_list = []
pnt_list.append(float(pnt['x']))
pnt_list.append(float(pnt['y']))
obj_list.append(pnt_list)
obj_dict[cls_int].append(obj_list)
return json.dumps(obj_dict) # return the mapped object points
# COMMAND ----------
# MAGIC %md
# MAGIC ## Get the Raw Images and Save to Delta
# MAGIC The first real work happens in this cell where we read from the volume where all of our images are located and save them as a delta table. This allows us to do transformations faster downstream of this
# COMMAND ----------
raw_images = f"{project_location}raw_images/"
raw_df = (
spark.read.format("binaryfile") # read the images as binary so we can get the file names and the byte content
.load(raw_images)
.selectExpr("*","replace(_metadata.file_name,'%20') as file_name") # cleans the file name to remove spaces
)
raw_df.write.mode("overwrite").saveAsTable(f"{CATALOG}.{SCHEMA}.raw_images_bronze") # write out the images to a bronze delta table
# COMMAND ----------
# MAGIC %md
# MAGIC ## Get the Raw Label Data and Save to Delta
# MAGIC The label data is the other starting table. We read in the csv file and apply some json structure to the label column in the csv
# COMMAND ----------
from pyspark.sql.functions import to_json, from_json
# read the csv label file and apply some json structure to the label column
label_df = (
spark.read.csv(f"{project_location}label_data", header=True)
.withColumnRenamed("External ID","file_name")
.withColumn("Label",from_json("Label","objects array<struct<value:string, line:array<struct<x:float,y:float>>,polygon:array<struct<x:float,y:float>>>>")) #schema to grab the fields we want. There are objects and lines
.selectExpr("Label","replace(file_name, ' ') as file_name")
)
label_df.write.mode('overwrite').saveAsTable(f"{CATALOG}.{SCHEMA}.label_data") # write out the labels to a delta table
# COMMAND ----------
# MAGIC %md
# MAGIC # Combine Label and Images to Create Mask Dataset
# MAGIC Join the image bytes to the label datset so that we can pass each value to the masking function that was built earlier. This will be saved to a new table for further processing
# COMMAND ----------
# read the raw images and join to the labels
mask_df = (
spark.sql(f"""
select A.file_name,content, to_json(label) as label from {CATALOG}.{SCHEMA}.raw_images_bronze A
left join {CATALOG}.{SCHEMA}.label_data B using(file_name)
""").withColumn("mask_labels",transform_labels('label'))
.withColumn("mask_binary", create_mask_from_polygons("content", "mask_labels")) # utilize the mask udf to generate object masks for each image
.drop("content")
)
mask_df.write.mode("overwrite").saveAsTable(f"{CATALOG}.{SCHEMA}.silver_mask") # Save the masks to a silver delta table
# COMMAND ----------
# MAGIC %md
# MAGIC # Create Training Dataset with Original Images and Masks Combined
# MAGIC Joining the original image from the first image table to the masks gives us the final gold level dataset that can be used for training our computer vision model. This will be helpful to not have to join these multiple times in the future if we try different models
# COMMAND ----------
# Join the masks and raw images together and save to a single gold table.
gold_df = (
spark.sql(f"""
select mask_binary, content as image_binary, A.file_name
from {CATALOG}.{SCHEMA}.raw_images_bronze A join {CATALOG}.{SCHEMA}.silver_mask B using(file_name)
""")
)
gold_df.write.mode("overwrite").saveAsTable(f"{CATALOG}.{SCHEMA}.gold_asset_inventory")
# COMMAND ----------
# MAGIC %md
# MAGIC # Create Test Train Split
# MAGIC The final step of our data preparation is going to be splitting the gold dataset up into training and validation data. This will allow our model to train on the majority of the data, but allow it to check in on how it's learning by using the test set
# COMMAND ----------
# Create a test/train split and save these to a volume so the petastorm can easily pick them up
gold_satellite_image =spark.table(f"{CATALOG}.{SCHEMA}.gold_asset_inventory")
(images_train, images_test) = gold_satellite_image.randomSplit([0.8, 0.2 ], 42) # randomly split the dataset into 80% training and 20% test
images_train.write.mode("overwrite").save(f"{project_location}gold_asset_train")
images_test.write.mode("overwrite").save(f"{project_location}gold_asset_test")
# COMMAND ----------
# MAGIC %md
# MAGIC
# MAGIC © 2024 Databricks, Inc. All rights reserved. The source in this notebook is provided subject to the [Databricks License](https://databricks.com/db-license-source). All included or referenced third party libraries are subject to the licenses set forth below.
# MAGIC
# MAGIC | library | description | license | source |
# MAGIC |----------------------------------------|-------------------------|------------|-----------------------------------------------------|
# MAGIC | pytorch-lightning | lightweight PyTorch wrapper for ML researchers | Apache Software License (Apache-2.0) | https://pypi.org/project/pytorch-lightning/ |
# MAGIC | opencv-python | Wrapper package for OpenCV python bindings| Apache Software License (Apache 2.0) | https://pypi.org/project/opencv-python/ |
# MAGIC | segmentation-models-pytorch | Image segmentation models with pre-trained backbones. PyTorch. | MIT License (MIT) | https://pypi.org/project/segmentation-models-pytorch/ |
# MAGIC | shapely |Manipulation and analysis of geometric objects |BSD License (BSD 3-Clause) | https://pypi.org/project/shapely/ |