Cortex为Prometheus提供了水平可扩展,高可用性,多租户的长期存储 。
- 水平可扩展: Cortex可以跨集群中的多台机器运行,超过了单台机器的吞吐量和存储量。这使您能够将指标从多个Prometheus服务器发送到单个Cortex集群,并在单个位置跨所有数据运行“全局聚合”查询。
- 高度可用:在集群中运行时,Cortex可以在机器之间复制数据。这使您能够在机器故障中幸存下来,而不会在图表中留下空白。
- 多租户: Cortex可以将数据和查询与单个群集中的多个不同独立Prometheus源隔离,从而使不受信任的各方共享同一群集。
- 长期存储: Cortex支持Amazon DynamoDB,Google Bigtable,Cassandra,S3和GCS来长期存储度量标准数据。这样一来,您可以持久地存储数据,其时间长于任何一台计算机的生命周期,并将此数据用于长期容量规划。
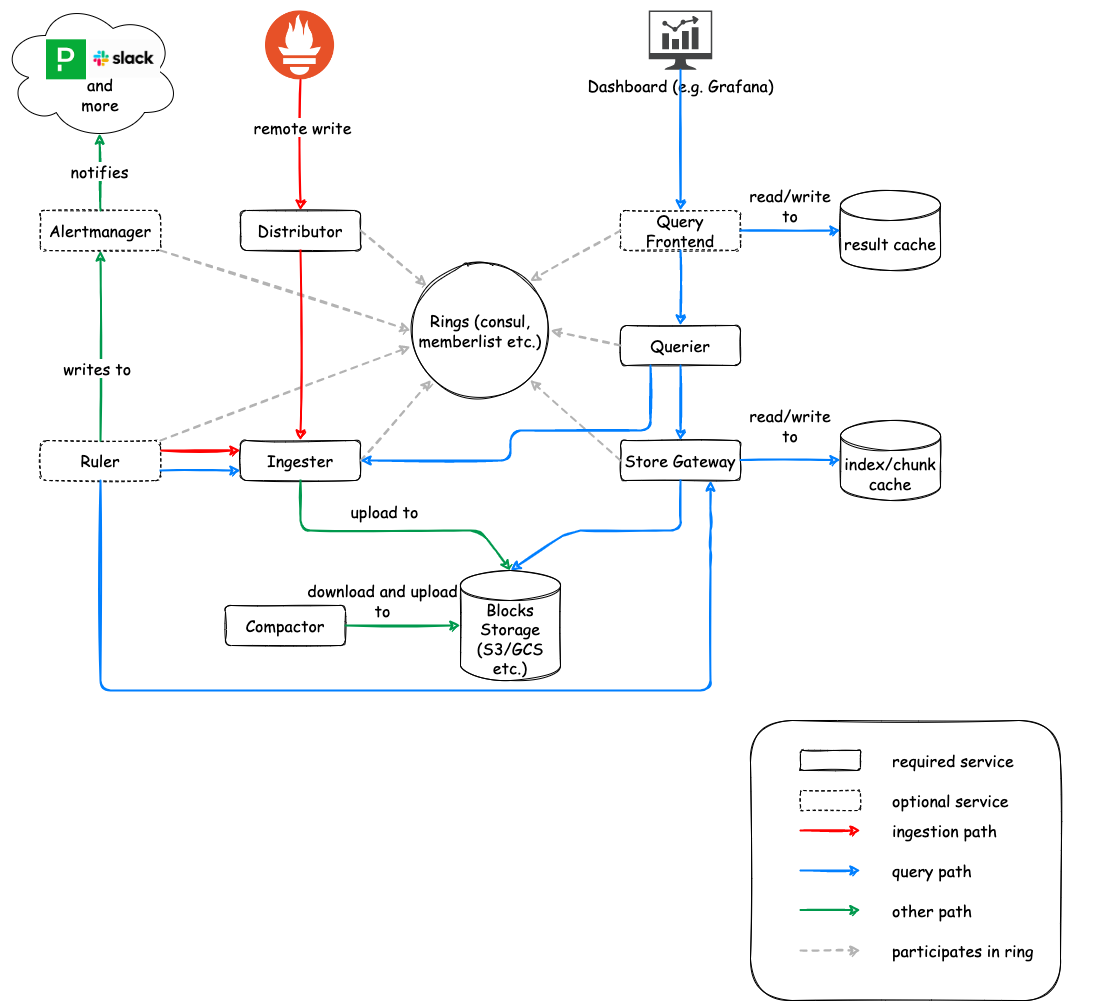
- Distributor
- Ingester
- Querier
- Query frontend (optional)
- Ruler (optional)
- Alertmanager (optional)
- Configs API (optional)
VictoriaMetrics是一种快速,经济高效且可扩展的时间序列数据库
vmstorage -存储数据 vminsert-vmstorage使用一致的散列将摄取的数据代理为分片
Thanos是一组组件,可以组成具有无限存储容量的高可用性指标系统,可以将其无缝添加到现有Prometheus部署之上。
Thanos利用Prometheus 2.0存储格式在任何对象存储中经济高效地存储历史度量数据,同时保留快速查询延迟。 另外,它提供了所有Prometheus安装的全局查询视图,并且可以即时合并Prometheus HA对中的数据。

- 跨所有连接的Prometheus服务器的全局查询视图
- 重复数据删除和合并从Prometheus HA对中收集的指标
- 与现有Prometheus设置无缝集成
- 任何对象存储都是其唯一的,可选的依赖关系
- 对历史数据进行下采样以大幅提高查询速度
- 跨集群联合
- 容错查询路由
- 简单的gRPC Store API,可跨所有指标数据进行统一数据访问
- 自定义指标提供程序的轻松集成点