L'atelier se décompose en une suite d'exercices eux-mêmes composées d'une série de tests à faire passer au vert. Les tests sont à compléter, ainsi qu'éventuellement d'autres classes de l'exercice associé (Repository...).
Cet atelier a été testé avec Eclipse, mais n'importe quel IDE fera l'affaire. Si vous souhaitez bénéficier d'un support top-moumoute de Maven et SpringData, nous vous recommandons chaudement d'utiliser SpringSource ToolSuite. Importez le projet en tant que "Projet Maven existant".
Le seul point d'achoppement réside dans l'intégration de QueryDSL avec votre IDE. Les fichiers de configuration nécessaires à Eclipse sont versionnés (utilisateurs d'autres IDE: ces étapes de configuration peuvent varier).
L'application enregistre des adresses de clients. Le domaine métier est modélisé comme suit :
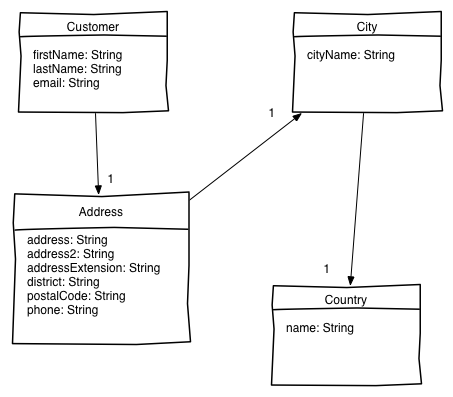
Le jeu de données ainsi que la configuration de l'application sont déjà en place.
Il ne vous reste qu'à compléter les tests de la classe JpaTest (pensez à modifier CustomersRepository). Celle-ci s'appuye sur une base de données H2 embarquée.
- Trouver un client par son ID (ID 42)
- Récupérer tous les clients
- Obtenir une liste paginée de clients (2nde page [les pages sont indexées à partir de 0], 5 clients par page)
- Obtenir les clients dont le nom suit un prédicat, défini via des "explicit queries"
- Trouver des clients par nom et par ville, en s'appuyant sur QueryDSL (CustomersRepository doit maintenant étendre
QueryDslPredicateExecutor)
Documentation Spring Data/Mongo DB
Cette application modélise des posts de blog, lesquels sont rédigés par des auteurs (Author) et commentés (Comment). Le modèle est illustré ici :
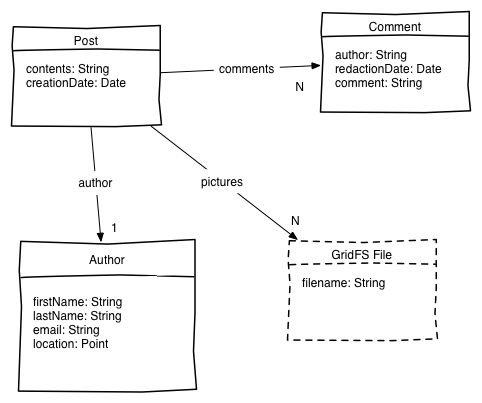
Ici encore, la configuration de l'application et le jeu de données vous sont fournis.
Complétez la classe de test MongoTest.
- Trouver des posts dont le texte contient une séquence (ici: "Miami")
- Trouver tous les auteurs dans un rayon de 70 (cercle centré sur l'origine : [0,0]) dont le nom de famille commence par "Biv"
- Trouver toutes les images d'un post, via le repository custom
PostRepositoryImpl. Votre implémentation se basera surGridFsTemplate, lequel exécutera une instance deorg.springframework.data.mongodb.core.query.Query. Vous pouvez la construire avec des objets criteria (ex:org.springframework.data.mongodb.gridfs.GridFsCriteria.whereFilenameappartient àpost.getPictures()).
Documentation Spring Data/Neo4J
(Inspiré du travail de Michael Hunger.)
Tout le monde connaît Twitter. Il paraîtrait même que Twitter a migré vers la base de données Neo4J! Nous avons utilisé l'application de Michael afin de récupérer les tweets mentionnant #cloudfoundry (http://www.cloudfoundry.com) et de persister le résultat. Le jeu de données vous est donc fourni.
Le domaine métier s'articule comme suit :
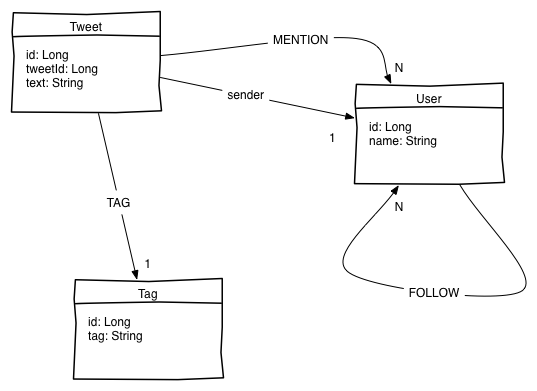
Modifiez la classe Neo4JTest et faites passer les tests au vert !
- Trouver un utilisateur par son nom (ici : @ebottard, càd "ebottard")
- Rédiger la requête permettant de retrouver des tweets par le nom de leur auteur, afin de récupérer les tweets d'un utilisateur (ici : @ebottard, càd "ebottard")
- Retrouver les suggestions de comptes à suivre pour un utilisateur (ici : Chris Richardson (@crichardson, càd "crichardson")), en utilisant une requête Cypher
- Faire suivre ces suggestions à un compte utilisateur (ici : Andy Piper (@andypiper, càd "andypiper")), en se basant sur la requête précédente
- Trouvez tous les tweets mentionnant un tag (ici : #devoxx), en utilisant le DSL Java de Cypher
- Exécuter
mvn tomcat:run - Ouvrir/curl/utiliser Spring Shell sur 'localhost:8080/hands-on-springdata'
- Explorer :)