diff --git a/.gitignore b/.gitignore
index 475fb7ef..be2e5283 100644
--- a/.gitignore
+++ b/.gitignore
@@ -4,7 +4,10 @@
**/outputs/
**/multirun/
-
+# Docs
+docs/output/
+docs/source/generated/
+docs/build/
# Byte-compiled / optimized / DLL files
__pycache__/
diff --git a/.readthedocs.yaml b/.readthedocs.yaml
new file mode 100644
index 00000000..58e9fa45
--- /dev/null
+++ b/.readthedocs.yaml
@@ -0,0 +1,31 @@
+# .readthedocs.yaml
+# Read the Docs configuration file
+# See https://docs.readthedocs.io/en/stable/config-file/v2.html for details
+
+# Required
+version: 2
+
+# Set the OS, Python version and other tools you might need
+build:
+ os: ubuntu-22.04
+ tools:
+ python: "3.10"
+
+# Build documentation in the "docs/" directory with Sphinx
+sphinx:
+ fail_on_warning: true
+ configuration: docs/source/conf.py
+
+# Optionally build your docs in additional formats such as PDF and ePub
+formats:
+ - epub
+
+# Optional but recommended, declare the Python requirements required
+# to build your documentation
+# See https://docs.readthedocs.io/en/stable/guides/reproducible-builds.html
+python:
+ install:
+ - requirements: docs/requirements.txt
+ # Install our python package before building the docs
+ - method: pip
+ path: .
diff --git a/README.md b/README.md
index 910ed810..0a49f9e4 100644
--- a/README.md
+++ b/README.md
@@ -1,19 +1,20 @@
-
+
# BenchMARL
[](test)
[](https://codecov.io/gh/facebookresearch/BenchMARL)
+[](https://benchmarl.readthedocs.io/en/latest/?badge=latest)
[](https://www.python.org/downloads/)
 [](https://pepy.tech/project/benchmarl)
+[](https://discord.gg/jEEWCn6T3p)
```bash
python benchmarl/run.py algorithm=mappo task=vmas/balance
```
-
[](examples) [](https://colab.research.google.com/github/facebookresearch/BenchMARL/blob/main/notebooks/run.ipynb)
[](https://wandb.ai/matteobettini/benchmarl-public/reportlist)
@@ -58,6 +59,7 @@ the domain and want to easily take a picture of the landscape.
* [Reporting and plotting](#reporting-and-plotting)
* [Extending](#extending)
* [Configuring](#configuring)
+ + [Experiment](#experiment)
+ [Algorithm](#algorithm)
+ [Task](#task)
+ [Model](#model)
@@ -280,10 +282,9 @@ Currently available ones are:
In the following, we report a table of the results:
-| **
[](https://pepy.tech/project/benchmarl)
+[](https://discord.gg/jEEWCn6T3p)
```bash
python benchmarl/run.py algorithm=mappo task=vmas/balance
```
-
[](examples) [](https://colab.research.google.com/github/facebookresearch/BenchMARL/blob/main/notebooks/run.ipynb)
[](https://wandb.ai/matteobettini/benchmarl-public/reportlist)
@@ -58,6 +59,7 @@ the domain and want to easily take a picture of the landscape.
* [Reporting and plotting](#reporting-and-plotting)
* [Extending](#extending)
* [Configuring](#configuring)
+ + [Experiment](#experiment)
+ [Algorithm](#algorithm)
+ [Task](#task)
+ [Model](#model)
@@ -280,10 +282,9 @@ Currently available ones are:
In the following, we report a table of the results:
-| **Environment
** | **Sample efficiency curves (all tasks)
** | **Performance profile
** | **Aggregate scores
** |
-|---------------------------------------|-------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------|
-| VMAS |  |
|  |
|  |
-
+| **
|
-
+| **Environment
** | **Sample efficiency curves (all tasks)
** | **Performance profile
** | **Aggregate scores
** |
+|---------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| VMAS | 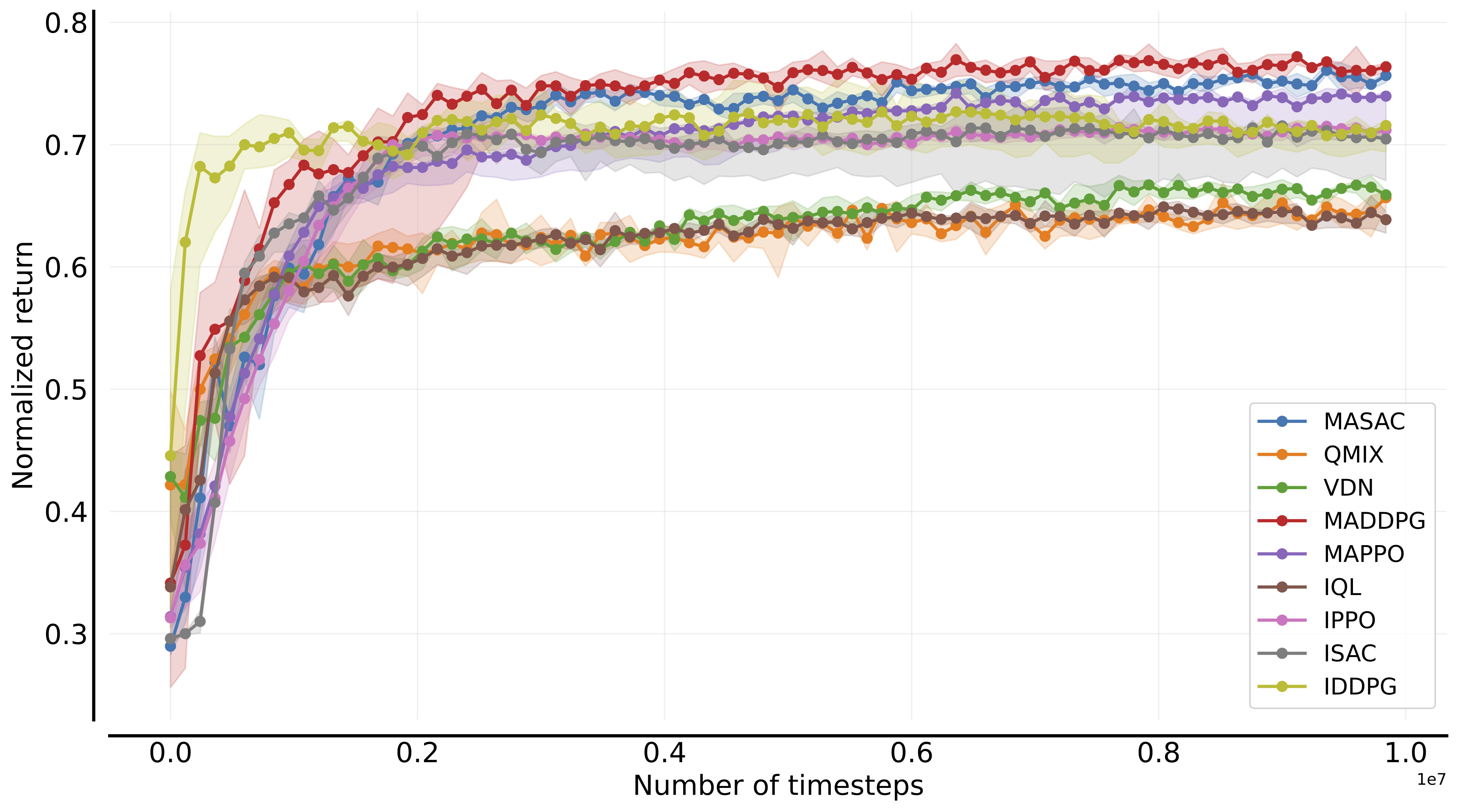 |
| 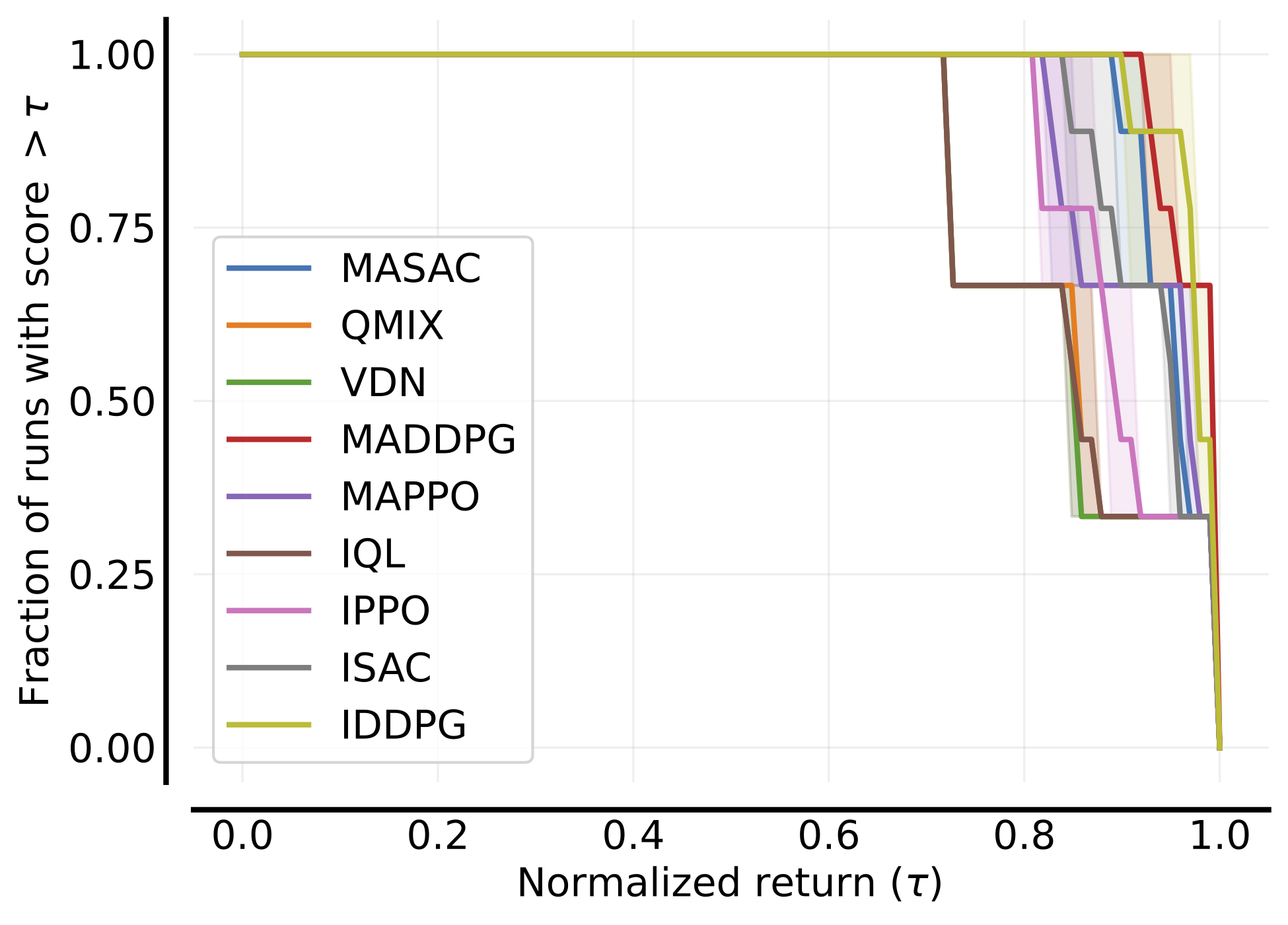 |
| 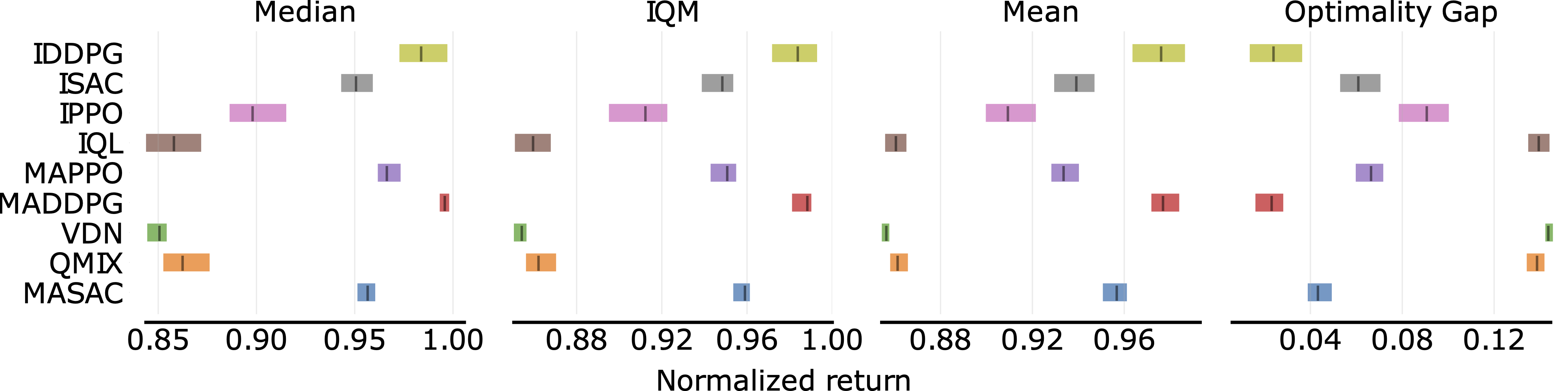 |
## Reporting and plotting
@@ -295,9 +296,9 @@ your benchmarks. No more struggling with matplotlib and latex!
[](examples/plotting)
-
-
-
+
+
+
## Extending
@@ -322,7 +323,6 @@ in the script itself or via [hydra](https://hydra.cc/docs/intro/).
We suggest to read the hydra documentation
to get familiar with all its functionalities.
-The project can be configured either the script itself or via hydra.
Each component in the project has a corresponding yaml configuration in the BenchMARL
[conf tree](benchmarl/conf).
Components' configurations are loaded from these files into python dataclasses that act
@@ -333,8 +333,7 @@ You can also directly load and validate configuration yaml files without using h
### Experiment
-Experiment configurations are in [`benchmarl/conf/config.yaml`](benchmarl/conf/config.yaml),
-with the experiment hyperparameters in [`benchmarl/conf/experiment`](benchmarl/conf/experiment).
+Experiment configurations are in [`benchmarl/conf/config.yaml`](benchmarl/conf/config.yaml).
Running custom experiments is extremely simplified by the [Hydra](https://hydra.cc/) configurations.
The default configuration for the library is contained in the [`benchmarl/conf`](benchmarl/conf) folder.
diff --git a/benchmarl/__init__.py b/benchmarl/__init__.py
index f953c5ca..96fd64ed 100644
--- a/benchmarl/__init__.py
+++ b/benchmarl/__init__.py
@@ -4,13 +4,22 @@
# LICENSE file in the root directory of this source tree.
#
+
+__version__ = "0.0.4"
+
import importlib
+import benchmarl.algorithms
+import benchmarl.benchmark
+import benchmarl.environments
+import benchmarl.experiment
+import benchmarl.models
+
_has_hydra = importlib.util.find_spec("hydra") is not None
if _has_hydra:
- def load_hydra_schemas():
+ def _load_hydra_schemas():
from hydra.core.config_store import ConfigStore
from benchmarl.algorithms import algorithm_config_registry
@@ -28,4 +37,4 @@ def load_hydra_schemas():
for task_schema_name, task_schema in _task_class_registry.items():
cs.store(name=task_schema_name, group="task", node=task_schema)
- load_hydra_schemas()
+ _load_hydra_schemas()
diff --git a/benchmarl/algorithms/__init__.py b/benchmarl/algorithms/__init__.py
index b9e18647..f0e2d20a 100644
--- a/benchmarl/algorithms/__init__.py
+++ b/benchmarl/algorithms/__init__.py
@@ -4,6 +4,7 @@
# LICENSE file in the root directory of this source tree.
#
+from .common import Algorithm, AlgorithmConfig
from .iddpg import Iddpg, IddpgConfig
from .ippo import Ippo, IppoConfig
from .iql import Iql, IqlConfig
@@ -14,6 +15,27 @@
from .qmix import Qmix, QmixConfig
from .vdn import Vdn, VdnConfig
+classes = [
+ "Iddpg",
+ "IddpgConfig",
+ "Ippo",
+ "IppoConfig",
+ "Iql",
+ "IqlConfig",
+ "Isac",
+ "IsacConfig",
+ "Maddpg",
+ "MaddpgConfig",
+ "Mappo",
+ "MappoConfig",
+ "Masac",
+ "MasacConfig",
+ "Qmix",
+ "QmixConfig",
+ "Vdn",
+ "VdnConfig",
+]
+
# A registry mapping "algoname" to its config dataclass
# This is used to aid loading of algorithms from yaml
algorithm_config_registry = {
diff --git a/benchmarl/algorithms/common.py b/benchmarl/algorithms/common.py
index 5e0b86f2..3702b75d 100644
--- a/benchmarl/algorithms/common.py
+++ b/benchmarl/algorithms/common.py
@@ -23,7 +23,7 @@
from torchrl.objectives.utils import HardUpdate, SoftUpdate, TargetNetUpdater
from benchmarl.models.common import ModelConfig
-from benchmarl.utils import DEVICE_TYPING, read_yaml_config
+from benchmarl.utils import _read_yaml_config, DEVICE_TYPING
class Algorithm(ABC):
@@ -32,7 +32,7 @@ class Algorithm(ABC):
This should be overridden by implemented algorithms
and all abstract methods should be implemented.
- Args:
+ Args:
experiment (Experiment): the experiment class
"""
@@ -104,14 +104,13 @@ def _check_specs(self):
def get_loss_and_updater(self, group: str) -> Tuple[LossModule, TargetNetUpdater]:
"""
Get the LossModule and TargetNetUpdater for a specific group.
- This function calls the abstract self._get_loss() which needs to be implemented.
+ This function calls the abstract :class:`~benchmarl.algorithms.Algorithm._get_loss()` which needs to be implemented.
The function will cache the output at the first call and return the cached values in future calls.
Args:
group (str): agent group of the loss and updater
Returns: LossModule and TargetNetUpdater for the group
-
"""
if group not in self._losses_and_updaters.keys():
action_space = self.action_spec[group, "action"]
@@ -144,7 +143,7 @@ def get_replay_buffer(
) -> ReplayBuffer:
"""
Get the ReplayBuffer for a specific group.
- This function will check self.on_policy and create the buffer accordingly
+ This function will check ``self.on_policy`` and create the buffer accordingly
Args:
group (str): agent group of the loss and updater
@@ -165,7 +164,7 @@ def get_replay_buffer(
def get_policy_for_loss(self, group: str) -> TensorDictModule:
"""
Get the non-explorative policy for a specific group loss.
- This function calls the abstract self._get_policy_for_loss() which needs to be implemented.
+ This function calls the abstract :class:`~benchmarl.algorithms.Algorithm._get_policy_for_loss()` which needs to be implemented.
The function will cache the output at the first call and return the cached values in future calls.
Args:
@@ -192,7 +191,7 @@ def get_policy_for_loss(self, group: str) -> TensorDictModule:
def get_policy_for_collection(self) -> TensorDictSequential:
"""
Get the explorative policy for all groups together.
- This function calls the abstract self._get_policy_for_collection() which needs to be implemented.
+ This function calls the abstract :class:`~benchmarl.algorithms.Algorithm._get_policy_for_collection()` which needs to be implemented.
The function will cache the output at the first call and return the cached values in future calls.
Returns: TensorDictSequential representing all explorative policies
@@ -217,7 +216,7 @@ def get_policy_for_collection(self) -> TensorDictSequential:
def get_parameters(self, group: str) -> Dict[str, Iterable]:
"""
Get the dictionary mapping loss names to the relative parameters to optimize for a given group.
- This function calls the abstract self._get_parameters() which needs to be implemented.
+ This function calls the abstract :class:`~benchmarl.algorithms.Algorithm._get_parameters()` which needs to be implemented.
Returns: a dictionary mapping loss names to a parameters' list
"""
@@ -323,13 +322,16 @@ class AlgorithmConfig:
Dataclass representing an algorithm configuration.
This should be overridden by implemented algorithms.
Implementors should:
- 1. add configuration parameters for their algorithm
- 2. implement all abstract methods
+
+ 1. add configuration parameters for their algorithm
+ 2. implement all abstract methods
+
"""
def get_algorithm(self, experiment) -> Algorithm:
"""
Main function to turn the config into the associated algorithm
+
Args:
experiment (Experiment): the experiment class
@@ -349,7 +351,7 @@ def _load_from_yaml(name: str) -> Dict[str, Any]:
/ "algorithm"
/ f"{name.lower()}.yaml"
)
- return read_yaml_config(str(yaml_path.resolve()))
+ return _read_yaml_config(str(yaml_path.resolve()))
@classmethod
def get_from_yaml(cls, path: Optional[str] = None):
@@ -359,7 +361,7 @@ def get_from_yaml(cls, path: Optional[str] = None):
Args:
path (str, optional): The full path of the yaml file to load from.
If None, it will default to
- benchmarl/conf/algorithm/self.associated_class().__name__
+ ``benchmarl/conf/algorithm/self.associated_class().__name__``
Returns: the loaded AlgorithmConfig
"""
@@ -370,7 +372,7 @@ def get_from_yaml(cls, path: Optional[str] = None):
)
)
else:
- return cls(**read_yaml_config(path))
+ return cls(**_read_yaml_config(path))
@staticmethod
@abstractmethod
diff --git a/benchmarl/algorithms/iddpg.py b/benchmarl/algorithms/iddpg.py
index 2bf1657c..742a49ef 100644
--- a/benchmarl/algorithms/iddpg.py
+++ b/benchmarl/algorithms/iddpg.py
@@ -19,6 +19,16 @@
class Iddpg(Algorithm):
+ """Same as :class:`~benchmarkl.algorithms.Maddpg` (from `https://arxiv.org/abs/1706.02275 `__) but with decentralized critics.
+
+ Args:
+ share_param_critic (bool): Whether to share the parameters of the critics withing agent groups
+ loss_function (str): loss function for the value discrepancy. Can be one of "l1", "l2" or "smooth_l1".
+ delay_value (bool): whether to separate the target value networks from the value networks used for
+ data collection.
+
+ """
+
def __init__(
self, share_param_critic: bool, loss_function: str, delay_value: bool, **kwargs
):
@@ -227,6 +237,8 @@ def get_value_module(self, group: str) -> TensorDictModule:
@dataclass
class IddpgConfig(AlgorithmConfig):
+ """Configuration dataclass for :class:`~benchmarl.algorithms.Iddpg`."""
+
share_param_critic: bool = MISSING
loss_function: str = MISSING
delay_value: bool = MISSING
diff --git a/benchmarl/algorithms/ippo.py b/benchmarl/algorithms/ippo.py
index f7190630..0dd9bfa2 100644
--- a/benchmarl/algorithms/ippo.py
+++ b/benchmarl/algorithms/ippo.py
@@ -22,6 +22,21 @@
class Ippo(Algorithm):
+ """Independent PPO (from `https://arxiv.org/abs/2011.09533 `__).
+
+ Args:
+ share_param_critic (bool): Whether to share the parameters of the critics withing agent groups
+ clip_epsilon (scalar): weight clipping threshold in the clipped PPO loss equation.
+ entropy_coef (scalar): entropy multiplier when computing the total loss.
+ critic_coef (scalar): critic loss multiplier when computing the total
+ loss_critic_type (str): loss function for the value discrepancy.
+ Can be one of "l1", "l2" or "smooth_l1".
+ lmbda (float): The GAE lambda
+ scale_mapping (str): positive mapping function to be used with the std.
+ choices: "softplus", "exp", "relu", "biased_softplus_1";
+
+ """
+
def __init__(
self,
share_param_critic: bool,
@@ -270,6 +285,8 @@ def get_critic(self, group: str) -> TensorDictModule:
@dataclass
class IppoConfig(AlgorithmConfig):
+ """Configuration dataclass for :class:`~benchmarl.algorithms.Ippo`."""
+
share_param_critic: bool = MISSING
clip_epsilon: float = MISSING
entropy_coef: float = MISSING
diff --git a/benchmarl/algorithms/iql.py b/benchmarl/algorithms/iql.py
index 8838c8fa..526c3d79 100644
--- a/benchmarl/algorithms/iql.py
+++ b/benchmarl/algorithms/iql.py
@@ -18,6 +18,15 @@
class Iql(Algorithm):
+ """Independent Q Learning (from `https://www.semanticscholar.org/paper/Multi-Agent-Reinforcement-Learning%3A-Independent-Tan/59de874c1e547399b695337bcff23070664fa66e `__).
+
+ Args:
+ loss_function (str): loss function for the value discrepancy. Can be one of "l1", "l2" or "smooth_l1".
+ delay_value (bool): whether to separate the target value networks from the value networks used for
+ data collection.
+
+ """
+
def __init__(self, delay_value: bool, loss_function: str, **kwargs):
super().__init__(**kwargs)
@@ -175,6 +184,8 @@ def process_batch(self, group: str, batch: TensorDictBase) -> TensorDictBase:
@dataclass
class IqlConfig(AlgorithmConfig):
+ """Configuration dataclass for :class:`~benchmarl.algorithms.Iql`."""
+
delay_value: bool = MISSING
loss_function: str = MISSING
diff --git a/benchmarl/algorithms/isac.py b/benchmarl/algorithms/isac.py
index 20df1ac1..972b762f 100644
--- a/benchmarl/algorithms/isac.py
+++ b/benchmarl/algorithms/isac.py
@@ -26,6 +26,30 @@
class Isac(Algorithm):
+ """Independent Soft Actor Critic.
+
+ Args:
+ share_param_critic (bool): Whether to share the parameters of the critics withing agent groups
+ num_qvalue_nets (integer): number of Q-Value networks used.
+ loss_function (str): loss function to be used with
+ the value function loss.
+ delay_qvalue (bool): Whether to separate the target Q value
+ networks from the Q value networks used for data collection.
+ target_entropy (float or str, optional): Target entropy for the
+ stochastic policy. Default is "auto", where target entropy is
+ computed as :obj:`-prod(n_actions)`.
+ discrete_target_entropy_weight (float): weight for the target entropy term when actions are discrete
+ alpha_init (float): initial entropy multiplier.
+ min_alpha (float): min value of alpha.
+ max_alpha (float): max value of alpha.
+ fixed_alpha (bool): if ``True``, alpha will be fixed to its
+ initial value. Otherwise, alpha will be optimized to
+ match the 'target_entropy' value.
+ scale_mapping (str): positive mapping function to be used with the std.
+ choices: "softplus", "exp", "relu", "biased_softplus_1";
+
+ """
+
def __init__(
self,
share_param_critic: bool,
@@ -358,6 +382,8 @@ def get_continuous_value_module(self, group: str) -> TensorDictModule:
@dataclass
class IsacConfig(AlgorithmConfig):
+ """Configuration dataclass for :class:`~benchmarl.algorithms.Isac`."""
+
share_param_critic: bool = MISSING
num_qvalue_nets: int = MISSING
diff --git a/benchmarl/algorithms/maddpg.py b/benchmarl/algorithms/maddpg.py
index df79de41..60501708 100644
--- a/benchmarl/algorithms/maddpg.py
+++ b/benchmarl/algorithms/maddpg.py
@@ -19,6 +19,15 @@
class Maddpg(Algorithm):
+ """Multi Agent DDPG (from `https://arxiv.org/abs/1706.02275 `__).
+
+ Args:
+ share_param_critic (bool): Whether to share the parameters of the critics withing agent groups
+ loss_function (str): loss function for the value discrepancy. Can be one of "l1", "l2" or "smooth_l1".
+ delay_value (bool): whether to separate the target value networks from the value networks used for
+ data collection.
+ """
+
def __init__(
self, share_param_critic: bool, loss_function: str, delay_value: bool, **kwargs
):
@@ -283,6 +292,8 @@ def get_value_module(self, group: str) -> TensorDictModule:
@dataclass
class MaddpgConfig(AlgorithmConfig):
+ """Configuration dataclass for :class:`~benchmarl.algorithms.Maddpg`."""
+
share_param_critic: bool = MISSING
loss_function: str = MISSING
diff --git a/benchmarl/algorithms/mappo.py b/benchmarl/algorithms/mappo.py
index cae735e9..c856642f 100644
--- a/benchmarl/algorithms/mappo.py
+++ b/benchmarl/algorithms/mappo.py
@@ -21,6 +21,21 @@
class Mappo(Algorithm):
+ """Multi Agent PPO (from `https://arxiv.org/abs/2103.01955 `__).
+
+ Args:
+ share_param_critic (bool): Whether to share the parameters of the critics withing agent groups
+ clip_epsilon (scalar): weight clipping threshold in the clipped PPO loss equation.
+ entropy_coef (scalar): entropy multiplier when computing the total loss.
+ critic_coef (scalar): critic loss multiplier when computing the total
+ loss_critic_type (str): loss function for the value discrepancy.
+ Can be one of "l1", "l2" or "smooth_l1".
+ lmbda (float): The GAE lambda
+ scale_mapping (str): positive mapping function to be used with the std.
+ choices: "softplus", "exp", "relu", "biased_softplus_1";
+
+ """
+
def __init__(
self,
share_param_critic: bool,
@@ -301,6 +316,8 @@ def get_critic(self, group: str) -> TensorDictModule:
@dataclass
class MappoConfig(AlgorithmConfig):
+ """Configuration dataclass for :class:`~benchmarl.algorithms.Mappo`."""
+
share_param_critic: bool = MISSING
clip_epsilon: float = MISSING
entropy_coef: float = MISSING
diff --git a/benchmarl/algorithms/masac.py b/benchmarl/algorithms/masac.py
index 95c67ae7..291a6588 100644
--- a/benchmarl/algorithms/masac.py
+++ b/benchmarl/algorithms/masac.py
@@ -20,6 +20,29 @@
class Masac(Algorithm):
+ """Multi Agent Soft Actor Critic.
+
+ Args:
+ share_param_critic (bool): Whether to share the parameters of the critics withing agent groups
+ num_qvalue_nets (integer): number of Q-Value networks used.
+ loss_function (str): loss function to be used with
+ the value function loss.
+ delay_qvalue (bool): Whether to separate the target Q value
+ networks from the Q value networks used for data collection.
+ target_entropy (float or str, optional): Target entropy for the
+ stochastic policy. Default is "auto", where target entropy is
+ computed as :obj:`-prod(n_actions)`.
+ discrete_target_entropy_weight (float): weight for the target entropy term when actions are discrete
+ alpha_init (float): initial entropy multiplier.
+ min_alpha (float): min value of alpha.
+ max_alpha (float): max value of alpha.
+ fixed_alpha (bool): if ``True``, alpha will be fixed to its
+ initial value. Otherwise, alpha will be optimized to
+ match the 'target_entropy' value.
+ scale_mapping (str): positive mapping function to be used with the std.
+ choices: "softplus", "exp", "relu", "biased_softplus_1";
+ """
+
def __init__(
self,
share_param_critic: bool,
@@ -434,6 +457,8 @@ def get_continuous_value_module(self, group: str) -> TensorDictModule:
@dataclass
class MasacConfig(AlgorithmConfig):
+ """Configuration dataclass for :class:`~benchmarl.algorithms.Masac`."""
+
share_param_critic: bool = MISSING
num_qvalue_nets: int = MISSING
diff --git a/benchmarl/algorithms/qmix.py b/benchmarl/algorithms/qmix.py
index fd3bd7cd..f4edc1fd 100644
--- a/benchmarl/algorithms/qmix.py
+++ b/benchmarl/algorithms/qmix.py
@@ -18,6 +18,16 @@
class Qmix(Algorithm):
+ """QMIX (from `https://arxiv.org/abs/1803.11485 `__).
+
+ Args:
+ mixing_embed_dim (int): hidden dimension of the mixing network
+ loss_function (str): loss function for the value discrepancy. Can be one of "l1", "l2" or "smooth_l1".
+ delay_value (bool): whether to separate the target value networks from the value networks used for
+ data collection.
+
+ """
+
def __init__(
self, mixing_embed_dim: int, delay_value: bool, loss_function: str, **kwargs
):
@@ -200,6 +210,8 @@ def get_mixer(self, group: str) -> TensorDictModule:
@dataclass
class QmixConfig(AlgorithmConfig):
+ """Configuration dataclass for :class:`~benchmarl.algorithms.Qmix`."""
+
mixing_embed_dim: int = MISSING
delay_value: bool = MISSING
loss_function: str = MISSING
diff --git a/benchmarl/algorithms/vdn.py b/benchmarl/algorithms/vdn.py
index 8e250f83..4ac77ab8 100644
--- a/benchmarl/algorithms/vdn.py
+++ b/benchmarl/algorithms/vdn.py
@@ -18,6 +18,15 @@
class Vdn(Algorithm):
+ """Vdn (from `https://arxiv.org/abs/1706.05296 `__).
+
+ Args:
+ loss_function (str): loss function for the value discrepancy. Can be one of "l1", "l2" or "smooth_l1".
+ delay_value (bool): whether to separate the target value networks from the value networks used for
+ data collection.
+
+ """
+
def __init__(self, delay_value: bool, loss_function: str, **kwargs):
super().__init__(**kwargs)
@@ -189,6 +198,8 @@ def get_mixer(self, group: str) -> TensorDictModule:
@dataclass
class VdnConfig(AlgorithmConfig):
+ """Configuration dataclass for :class:`~benchmarl.algorithms.Vdn`."""
+
delay_value: bool = MISSING
loss_function: str = MISSING
diff --git a/benchmarl/benchmark/__init__.py b/benchmarl/benchmark/__init__.py
new file mode 100644
index 00000000..0fca8b53
--- /dev/null
+++ b/benchmarl/benchmark/__init__.py
@@ -0,0 +1,7 @@
+# Copyright (c) Meta Platforms, Inc. and affiliates.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+#
+
+from .benchmark import Benchmark
diff --git a/benchmarl/benchmark.py b/benchmarl/benchmark/benchmark.py
similarity index 75%
rename from benchmarl/benchmark.py
rename to benchmarl/benchmark/benchmark.py
index a2a296a0..6d59eaff 100644
--- a/benchmarl/benchmark.py
+++ b/benchmarl/benchmark/benchmark.py
@@ -13,6 +13,20 @@
class Benchmark:
+ """A benchmark.
+
+ Benchmarks are collections of experiments to compare.
+
+ Args:
+ algorithm_configs (list of AlgorithmConfig): the algorithms to benchmark
+ model_config (ModelConfig): the config of the policy model
+ tasks (list of Task): the tasks to benchmark
+ seeds (set of int): the seeds for the benchmark
+ experiment_config (ExperimentConfig): the experiment config
+ critic_model_config (ModelConfig, optional): the config of the critic model. Defaults to model_config
+
+ """
+
def __init__(
self,
algorithm_configs: Sequence[AlgorithmConfig],
@@ -36,9 +50,11 @@ def __init__(
@property
def n_experiments(self):
+ """The number of experiments in the benchmark."""
return len(self.algorithm_configs) * len(self.tasks) * len(self.seeds)
def get_experiments(self) -> Iterator[Experiment]:
+ """Yields one experiment at a time"""
for algorithm_config in self.algorithm_configs:
for task in self.tasks:
for seed in self.seeds:
@@ -52,6 +68,7 @@ def get_experiments(self) -> Iterator[Experiment]:
)
def run_sequential(self):
+ """Run all the experiments in the benchmark in a sequence."""
for i, experiment in enumerate(self.get_experiments()):
print(f"\nRunning experiment {i+1}/{self.n_experiments}.\n")
try:
diff --git a/benchmarl/environments/common.py b/benchmarl/environments/common.py
index c7f49605..fd4fc2a6 100644
--- a/benchmarl/environments/common.py
+++ b/benchmarl/environments/common.py
@@ -17,7 +17,7 @@
from torchrl.data import CompositeSpec
from torchrl.envs import EnvBase, RewardSum, Transform
-from benchmarl.utils import DEVICE_TYPING, read_yaml_config
+from benchmarl.utils import _read_yaml_config, DEVICE_TYPING
def _load_config(name: str, config: Dict[str, Any]):
@@ -255,7 +255,7 @@ def __str__(self):
@staticmethod
def _load_from_yaml(name: str) -> Dict[str, Any]:
yaml_path = Path(__file__).parent.parent / "conf" / "task" / f"{name}.yaml"
- return read_yaml_config(str(yaml_path.resolve()))
+ return _read_yaml_config(str(yaml_path.resolve()))
def get_from_yaml(self, path: Optional[str] = None) -> Task:
"""
@@ -273,4 +273,4 @@ def get_from_yaml(self, path: Optional[str] = None) -> Task:
Task._load_from_yaml(str(Path(self.env_name()) / Path(task_name)))
)
else:
- return self.update_config(**read_yaml_config(path))
+ return self.update_config(**_read_yaml_config(path))
diff --git a/benchmarl/environments/pettingzoo/common.py b/benchmarl/environments/pettingzoo/common.py
index 372616b8..fdc4eb61 100644
--- a/benchmarl/environments/pettingzoo/common.py
+++ b/benchmarl/environments/pettingzoo/common.py
@@ -15,6 +15,8 @@
class PettingZooTask(Task):
+ """Enum for PettingZoo tasks."""
+
MULTIWALKER = None
WATERWORLD = None
SIMPLE_ADVERSARY = None
diff --git a/benchmarl/environments/smacv2/common.py b/benchmarl/environments/smacv2/common.py
index f9dcc691..47043396 100644
--- a/benchmarl/environments/smacv2/common.py
+++ b/benchmarl/environments/smacv2/common.py
@@ -17,6 +17,8 @@
class Smacv2Task(Task):
+ """Enum for SMACv2 tasks."""
+
PROTOSS_5_VS_5 = None
PROTOSS_10_VS_10 = None
PROTOSS_10_VS_11 = None
diff --git a/benchmarl/environments/vmas/common.py b/benchmarl/environments/vmas/common.py
index ba00c94d..0ee22ac8 100644
--- a/benchmarl/environments/vmas/common.py
+++ b/benchmarl/environments/vmas/common.py
@@ -15,6 +15,8 @@
class VmasTask(Task):
+ """Enum for VMAS tasks."""
+
BALANCE = None
SAMPLING = None
NAVIGATION = None
diff --git a/benchmarl/eval_results.py b/benchmarl/eval_results.py
index 83f7a572..94f2174d 100644
--- a/benchmarl/eval_results.py
+++ b/benchmarl/eval_results.py
@@ -28,6 +28,24 @@
def get_raw_dict_from_multirun_folder(multirun_folder: str) -> Dict:
+ """Get the ``marl-eval`` input dictionary from the folder of a hydra multirun.
+
+ Examples:
+ .. code-block:: python
+
+ from benchmarl.eval_results import get_raw_dict_from_multirun_folder, Plotting
+ raw_dict = get_raw_dict_from_multirun_folder(
+ multirun_folder="some_prefix/multirun/2023-09-22/17-21-34"
+ )
+ processed_data = Plotting.process_data(raw_dict)
+
+ Args:
+ multirun_folder (str): the absolute path to the multirun folder
+
+ Returns:
+ the dict obtained by merging all the json files in the multirun
+
+ """
return load_and_merge_json_dicts(_get_json_files_from_multirun(multirun_folder))
@@ -43,6 +61,18 @@ def _get_json_files_from_multirun(multirun_folder: str) -> List[str]:
def load_and_merge_json_dicts(
json_input_files: List[str], json_output_file: Optional[str] = None
) -> Dict:
+ """Loads and merges json dictionaries to form the ``marl-eval`` input dictionary .
+
+ Args:
+ json_input_files (list of str): a list containing the absolute paths to the json files
+ json_output_file (str, optional): if specified, the merged dictionary will be also written
+ to the file in this absolute path
+
+ Returns:
+ the dict obtained by merging all the json files
+
+ """
+
def update(d, u):
for k, v in u.items():
if isinstance(v, collections.abc.Mapping):
@@ -67,13 +97,49 @@ def update(d, u):
class Plotting:
+ """Class containing static utilities for plotting in ``marl-eval``.
+
+ Examples:
+ >>> from benchmarl.eval_results import get_raw_dict_from_multirun_folder, Plotting
+ >>> raw_dict = get_raw_dict_from_multirun_folder(
+ ... multirun_folder="some_prefix/multirun/2023-09-22/17-21-34"
+ ... )
+ >>> processed_data = Plotting.process_data(raw_dict)
+ ... (
+ ... environment_comparison_matrix,
+ ... sample_efficiency_matrix,
+ ... ) = Plotting.create_matrices(processed_data, env_name="vmas")
+ >>> Plotting.performance_profile_figure(
+ ... environment_comparison_matrix=environment_comparison_matrix
+ ... )
+ >>> Plotting.aggregate_scores(
+ ... environment_comparison_matrix=environment_comparison_matrix
+ ... )
+ >>> Plotting.environemnt_sample_efficiency_curves(
+ ... sample_effeciency_matrix=sample_efficiency_matrix
+ ... )
+ >>> Plotting.task_sample_efficiency_curves(
+ ... processed_data=processed_data, env="vmas", task="navigation"
+ ... )
+ >>> plt.show()
+
+ """
METRICS_TO_NORMALIZE = ["return"]
METRIC_TO_PLOT = "return"
@staticmethod
- def process_data(raw_data: Dict):
- # Call data_process_pipeline to normalize the choosen metrics and to clean the data
+ def process_data(raw_data: Dict) -> Dict:
+ """Call ``data_process_pipeline`` to normalize the chosen metrics and to clean the data
+
+ Args:
+ raw_data (dict): the input data
+
+ Returns:
+ the processed dict
+
+ """
+
return data_process_pipeline(
raw_data=raw_data, metrics_to_normalize=Plotting.METRICS_TO_NORMALIZE
)
diff --git a/benchmarl/experiment/__init__.py b/benchmarl/experiment/__init__.py
index 0e954fb2..775bb0da 100644
--- a/benchmarl/experiment/__init__.py
+++ b/benchmarl/experiment/__init__.py
@@ -4,4 +4,5 @@
# LICENSE file in the root directory of this source tree.
#
+from .callback import Callback
from .experiment import Experiment, ExperimentConfig
diff --git a/benchmarl/experiment/callback.py b/benchmarl/experiment/callback.py
index c93b85d8..d5c32f13 100644
--- a/benchmarl/experiment/callback.py
+++ b/benchmarl/experiment/callback.py
@@ -76,11 +76,11 @@ def __init__(self, experiment, callbacks: List[Callback]):
for callback in self.callbacks:
callback.experiment = experiment
- def on_batch_collected(self, batch: TensorDictBase):
+ def _on_batch_collected(self, batch: TensorDictBase):
for callback in self.callbacks:
callback.on_batch_collected(batch)
- def on_train_step(self, batch: TensorDictBase, group: str) -> TensorDictBase:
+ def _on_train_step(self, batch: TensorDictBase, group: str) -> TensorDictBase:
train_td = None
for callback in self.callbacks:
td = callback.on_train_step(batch, group)
@@ -91,10 +91,10 @@ def on_train_step(self, batch: TensorDictBase, group: str) -> TensorDictBase:
train_td.update(td)
return train_td
- def on_train_end(self, training_td: TensorDictBase, group: str):
+ def _on_train_end(self, training_td: TensorDictBase, group: str):
for callback in self.callbacks:
callback.on_train_end(training_td, group)
- def on_evaluation_end(self, rollouts: List[TensorDictBase]):
+ def _on_evaluation_end(self, rollouts: List[TensorDictBase]):
for callback in self.callbacks:
callback.on_evaluation_end(rollouts)
diff --git a/benchmarl/experiment/experiment.py b/benchmarl/experiment/experiment.py
index ba43a3df..ba550fcd 100644
--- a/benchmarl/experiment/experiment.py
+++ b/benchmarl/experiment/experiment.py
@@ -30,7 +30,7 @@
from benchmarl.experiment.callback import Callback, CallbackNotifier
from benchmarl.experiment.logger import Logger
from benchmarl.models.common import ModelConfig
-from benchmarl.utils import read_yaml_config
+from benchmarl.utils import _read_yaml_config
_has_hydra = importlib.util.find_spec("hydra") is not None
if _has_hydra:
@@ -44,7 +44,7 @@ class ExperimentConfig:
This class acts as a schema for loading and validating yaml configurations.
Parameters in this class aim to be agnostic of the algorithm, task or model used.
- To know their meaning, please check out the descriptions in benchmarl/conf/experiment/base_experiment.yaml
+ To know their meaning, please check out the descriptions in ``benchmarl/conf/experiment/base_experiment.yaml``
"""
sampling_device: str = MISSING
@@ -111,7 +111,7 @@ def train_minibatch_size(self, on_policy: bool) -> int:
"""
The minibatch size of tensors used for training.
On-policy algorithms are trained by splitting the train_batch_size (equal to the collected frames) into minibatches.
- Off-policy algorithms do not go through this process and thus have the train_minibatch_size==train_batch_size
+ Off-policy algorithms do not go through this process and thus have the ``train_minibatch_size==train_batch_size``
Args:
on_policy (bool): is the algorithms on_policy
@@ -168,8 +168,8 @@ def n_envs_per_worker(self, on_policy: bool) -> int:
"""
Number of environments used for collection
- In vectorized environments, this will be the vectorized batch_size.
- In other environments, this will be emulated by running them sequentially.
+ - In vectorized environments, this will be the vectorized batch_size.
+ - In other environments, this will be emulated by running them sequentially.
Args:
on_policy (bool): is the algorithms on_policy
@@ -233,9 +233,10 @@ def get_from_yaml(path: Optional[str] = None):
Args:
path (str, optional): The full path of the yaml file to load from.
If None, it will default to
- benchmarl/conf/experiment/base_experiment.yaml
+ ``benchmarl/conf/experiment/base_experiment.yaml``
- Returns: the loaded ExperimentConfig
+ Returns:
+ the loaded :class:`~benchmarl.experiment.ExperimentConfig`
"""
if path is None:
yaml_path = (
@@ -244,9 +245,9 @@ def get_from_yaml(path: Optional[str] = None):
/ "experiment"
/ "base_experiment.yaml"
)
- return ExperimentConfig(**read_yaml_config(str(yaml_path.resolve())))
+ return ExperimentConfig(**_read_yaml_config(str(yaml_path.resolve())))
else:
- return ExperimentConfig(**read_yaml_config(path))
+ return ExperimentConfig(**_read_yaml_config(path))
def validate(self, on_policy: bool):
"""
@@ -282,16 +283,15 @@ class Experiment(CallbackNotifier):
"""
Main experiment class in BenchMARL.
-
Args:
task (Task): the task configuration
algorithm_config (AlgorithmConfig): the algorithm configuration
model_config (ModelConfig): the policy model configuration
seed (int): the seed for the experiment
- config (ExperimentConfig):
+ config (ExperimentConfig): the experiment config
critic_model_config (ModelConfig, optional): the policy model configuration.
If None, it defaults to model_config
- callbacks (list of Callback, optional): list of benchmarl.experiment.callbacks.Callback for this experiment
+ callbacks (list of Callback, optional): callbacks for this experiment
"""
def __init__(
@@ -330,7 +330,7 @@ def __init__(
@property
def on_policy(self) -> bool:
- """Weather the algorithm has to be run on policy"""
+ """Whether the algorithm has to be run on policy."""
return self.algorithm_config.on_policy()
def _setup(self):
@@ -538,7 +538,7 @@ def _collection_loop(self):
pbar.set_description(f"mean return = {self.mean_return}", refresh=False)
# Callback
- self.on_batch_collected(batch)
+ self._on_batch_collected(batch)
# Loop over groups
training_start = time.time()
@@ -561,7 +561,7 @@ def _collection_loop(self):
)
# Callback
- self.on_train_end(training_td, group)
+ self._on_train_end(training_td, group)
# Exploration update
if isinstance(self.group_policies[group], TensorDictSequential):
@@ -651,7 +651,7 @@ def _optimizer_loop(self, group: str) -> TensorDictBase:
if self.target_updaters[group] is not None:
self.target_updaters[group].step()
- callback_loss = self.on_train_step(subdata, group)
+ callback_loss = self._on_train_step(subdata, group)
if callback_loss is not None:
training_td.update(callback_loss)
@@ -720,11 +720,11 @@ def callback(env, td):
total_frames=self.total_frames,
)
# Callback
- self.on_evaluation_end(rollouts)
+ self._on_evaluation_end(rollouts)
# Saving experiment state
def state_dict(self) -> OrderedDict:
- """Get the state_dict for the experiment"""
+ """Get the state_dict for the experiment."""
state = OrderedDict(
total_time=self.total_time,
total_frames=self.total_frames,
@@ -743,7 +743,12 @@ def state_dict(self) -> OrderedDict:
return state_dict
def load_state_dict(self, state_dict: Dict) -> None:
- """Load the state_dict for the experiment"""
+ """Load the state_dict for the experiment.
+
+ Args:
+ state_dict (dict): the state dict
+
+ """
for group in self.group_map.keys():
self.losses[group].load_state_dict(state_dict[f"loss_{group}"])
self.replay_buffers[group].load_state_dict(state_dict[f"buffer_{group}"])
diff --git a/benchmarl/hydra_config.py b/benchmarl/hydra_config.py
index e1465e2a..3f9cb100 100644
--- a/benchmarl/hydra_config.py
+++ b/benchmarl/hydra_config.py
@@ -3,8 +3,7 @@
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
#
-
-from omegaconf import DictConfig, OmegaConf
+import importlib
from benchmarl.algorithms.common import AlgorithmConfig
from benchmarl.environments import Task, task_config_registry
@@ -12,8 +11,23 @@
from benchmarl.models import model_config_registry
from benchmarl.models.common import ModelConfig, parse_model_config, SequenceModelConfig
+_has_hydra = importlib.util.find_spec("hydra") is not None
+
+if _has_hydra:
+ from omegaconf import DictConfig, OmegaConf
+
def load_experiment_from_hydra(cfg: DictConfig, task_name: str) -> Experiment:
+ """Creates an :class:`~benchmarl.experiment.Experiment` from hydra config.
+
+ Args:
+ cfg (DictConfig): the config dictionary from hydra main
+ task_name (str): the name of the task to load
+
+ Returns:
+ :class:`~benchmarl.experiment.Experiment`
+
+ """
algorithm_config = load_algorithm_config_from_hydra(cfg.algorithm)
experiment_config = load_experiment_config_from_hydra(cfg.experiment)
task_config = load_task_config_from_hydra(cfg.task, task_name)
@@ -31,20 +45,57 @@ def load_experiment_from_hydra(cfg: DictConfig, task_name: str) -> Experiment:
def load_task_config_from_hydra(cfg: DictConfig, task_name: str) -> Task:
+ """Returns a :class:`~benchmarl.environments.Task` from hydra config.
+
+ Args:
+ cfg (DictConfig): the task config dictionary from hydra
+ task_name (str): the name of the task to load
+
+ Returns:
+ :class:`~benchmarl.environments.Task`
+
+ """
return task_config_registry[task_name].update_config(
OmegaConf.to_container(cfg, resolve=True, throw_on_missing=True)
)
def load_experiment_config_from_hydra(cfg: DictConfig) -> ExperimentConfig:
+ """Returns a :class:`~benchmarl.experiment.ExperimentConfig` from hydra config.
+
+ Args:
+ cfg (DictConfig): the experiment config dictionary from hydra
+
+ Returns:
+ :class:`~benchmarl.experiment.ExperimentConfig`
+
+ """
return OmegaConf.to_object(cfg)
def load_algorithm_config_from_hydra(cfg: DictConfig) -> AlgorithmConfig:
+ """Returns a :class:`~benchmarl.algorithms.AlgorithmConfig` from hydra config.
+
+ Args:
+ cfg (DictConfig): the algorithm config dictionary from hydra
+
+ Returns:
+ :class:`~benchmarl.algorithms.AlgorithmConfig`
+
+ """
return OmegaConf.to_object(cfg)
def load_model_config_from_hydra(cfg: DictConfig) -> ModelConfig:
+ """Returns a :class:`~benchmarl.models.ModelConfig` from hydra config.
+
+ Args:
+ cfg (DictConfig): the model config dictionary from hydra
+
+ Returns:
+ :class:`~benchmarl.models.ModelConfig`
+
+ """
if "layers" in cfg.keys():
model_configs = [
load_model_config_from_hydra(cfg.layers[f"l{i}"])
diff --git a/benchmarl/models/__init__.py b/benchmarl/models/__init__.py
index b437626a..fa71cc1b 100644
--- a/benchmarl/models/__init__.py
+++ b/benchmarl/models/__init__.py
@@ -4,6 +4,12 @@
# LICENSE file in the root directory of this source tree.
#
-from .mlp import MlpConfig
+from .common import Model, ModelConfig, SequenceModel, SequenceModelConfig
+from .mlp import Mlp, MlpConfig
+
+classes = [
+ "Mlp",
+ "MlpConfig",
+]
model_config_registry = {"mlp": MlpConfig}
diff --git a/benchmarl/models/common.py b/benchmarl/models/common.py
index 7110005d..a0ec5b43 100644
--- a/benchmarl/models/common.py
+++ b/benchmarl/models/common.py
@@ -15,7 +15,7 @@
from torchrl.data import CompositeSpec, UnboundedContinuousTensorSpec
from torchrl.envs import EnvBase
-from benchmarl.utils import class_from_name, DEVICE_TYPING, read_yaml_config
+from benchmarl.utils import _class_from_name, _read_yaml_config, DEVICE_TYPING
def _check_spec(tensordict, spec):
@@ -28,7 +28,7 @@ def parse_model_config(cfg: Dict[str, Any]) -> Dict[str, Any]:
kwargs = {}
for key, value in cfg.items():
if key.endswith("class") and value is not None:
- value = class_from_name(cfg[key])
+ value = _class_from_name(cfg[key])
kwargs.update({key: value})
return kwargs
@@ -60,12 +60,12 @@ class Model(TensorDictModuleBase, ABC):
output_spec (CompositeSpec): the output spec of the model
agent_group (str): the name of the agent group the model is for
n_agents (int): the number of agents this module is for
- device (str): the mdoel's device
+ device (str): the model's device
input_has_agent_dim (bool): This tells the model if the input will have a multi-agent dimension or not.
For example, the input of policies will always have this set to true,
but critics that use a global state have this set to false as the state is shared by all agents
centralised (bool): This tells the model if it has full observability.
- This will always be true when self.input_has_agent_dim==False,
+ This will always be true when ``self.input_has_agent_dim==False``,
but in cases where the input has the agent dimension, this parameter is
used to distinguish between a decentralised model (where each agent's data
is processed separately) and a centralized model, where the model pools all data together
@@ -114,8 +114,8 @@ def __init__(
def output_has_agent_dim(self) -> bool:
"""
This is a dynamically computed attribute that indicates if the output will have the agent dimension.
- This will be false when share_params==True and centralised==True, and true in all other cases.
- When output_has_agent_dim is true, your model's output should contain the multiagent dimension,
+ This will be false when ``share_params==True and centralised==True``, and true in all other cases.
+ When output_has_agent_dim is true, your model's output should contain the multi-agent dimension,
and the dimension should be absent otherwise
"""
return output_has_agent_dim(self.share_params, self.centralised)
@@ -170,6 +170,12 @@ def _forward(self, tensordict: TensorDictBase) -> TensorDictBase:
class SequenceModel(Model):
+ """A sequence of :class:`~benchmarl.models.Model`
+
+ Args:
+ models (list of Model): the models in the sequence
+ """
+
def __init__(
self,
models: List[Model],
@@ -194,11 +200,13 @@ def _forward(self, tensordict: TensorDictBase) -> TensorDictBase:
@dataclass
class ModelConfig(ABC):
"""
- Dataclass representing an model configuration.
+ Dataclass representing a :class:`~benchmarl.models.Model` configuration.
This should be overridden by implemented models.
Implementors should:
- 1. add configuration parameters for their algorithm
- 2. implement all abstract methods
+
+ 1. add configuration parameters for their algorithm
+ 2. implement all abstract methods
+
"""
def get_model(
@@ -280,7 +288,7 @@ def _load_from_yaml(name: str) -> Dict[str, Any]:
/ "layers"
/ f"{name.lower()}.yaml"
)
- cfg = read_yaml_config(str(yaml_path.resolve()))
+ cfg = _read_yaml_config(str(yaml_path.resolve()))
return parse_model_config(cfg)
@classmethod
@@ -302,11 +310,13 @@ def get_from_yaml(cls, path: Optional[str] = None):
)
)
else:
- return cls(**parse_model_config(read_yaml_config(path)))
+ return cls(**parse_model_config(_read_yaml_config(path)))
@dataclass
class SequenceModelConfig(ModelConfig):
+ """Dataclass for a :class:`~benchmarl.models.SequenceModel`."""
+
model_configs: Sequence[ModelConfig]
intermediate_sizes: Sequence[int]
diff --git a/benchmarl/models/mlp.py b/benchmarl/models/mlp.py
index 76e25eef..dfd49131 100644
--- a/benchmarl/models/mlp.py
+++ b/benchmarl/models/mlp.py
@@ -18,6 +18,20 @@
class Mlp(Model):
+ """Multi layer perceptron model.
+
+ Args:
+ num_cells (int or Sequence[int], optional): number of cells of every layer in between the input and output. If
+ an integer is provided, every layer will have the same number of cells. If an iterable is provided,
+ the linear layers out_features will match the content of num_cells.
+ layer_class (Type[nn.Module]): class to be used for the linear layers;
+ activation_class (Type[nn.Module]): activation class to be used.
+ activation_kwargs (dict, optional): kwargs to be used with the activation class;
+ norm_class (Type, optional): normalization class, if any.
+ norm_kwargs (dict, optional): kwargs to be used with the normalization layers;
+
+ """
+
def __init__(
self,
**kwargs,
@@ -106,6 +120,8 @@ def _forward(self, tensordict: TensorDictBase) -> TensorDictBase:
@dataclass
class MlpConfig(ModelConfig):
+ """Dataclass config for a :class:`~benchmarl.models.Mlp`."""
+
num_cells: Sequence[int] = MISSING
layer_class: Type[nn.Module] = MISSING
diff --git a/benchmarl/run.py b/benchmarl/run.py
index a2cfb299..459b8f6f 100644
--- a/benchmarl/run.py
+++ b/benchmarl/run.py
@@ -13,6 +13,19 @@
@hydra.main(version_base=None, config_path="conf", config_name="config")
def hydra_experiment(cfg: DictConfig) -> None:
+ """Runs an experiment loading its config from hydra.
+
+ This function is decorated as ``@hydra.main`` and is called by running
+
+ .. code-block:: console
+
+ python benchmarl/run.py algorithm=mappo task=vmas/balance
+
+
+ Args:
+ cfg (DictConfig): the hydra config dictionary
+
+ """
hydra_choices = HydraConfig.get().runtime.choices
task_name = hydra_choices.task
algorithm_name = hydra_choices.algorithm
diff --git a/benchmarl/utils.py b/benchmarl/utils.py
index 3e3fcacc..b1f80141 100644
--- a/benchmarl/utils.py
+++ b/benchmarl/utils.py
@@ -13,7 +13,7 @@
DEVICE_TYPING = Union[torch.device, str, int]
-def read_yaml_config(config_file: str) -> Dict[str, Any]:
+def _read_yaml_config(config_file: str) -> Dict[str, Any]:
with open(config_file) as config:
yaml_string = config.read()
config_dict = yaml.safe_load(yaml_string)
@@ -22,7 +22,7 @@ def read_yaml_config(config_file: str) -> Dict[str, Any]:
return config_dict
-def class_from_name(name: str):
+def _class_from_name(name: str):
name_split = name.split(".")
module_name = ".".join(name_split[:-1])
class_name = name_split[-1]
diff --git a/docs/Makefile b/docs/Makefile
new file mode 100644
index 00000000..d0c3cbf1
--- /dev/null
+++ b/docs/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = source
+BUILDDIR = build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/docs/make.bat b/docs/make.bat
new file mode 100644
index 00000000..9534b018
--- /dev/null
+++ b/docs/make.bat
@@ -0,0 +1,35 @@
+@ECHO OFF
+
+pushd %~dp0
+
+REM Command file for Sphinx documentation
+
+if "%SPHINXBUILD%" == "" (
+ set SPHINXBUILD=sphinx-build
+)
+set SOURCEDIR=source
+set BUILDDIR=build
+
+if "%1" == "" goto help
+
+%SPHINXBUILD% >NUL 2>NUL
+if errorlevel 9009 (
+ echo.
+ echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
+ echo.installed, then set the SPHINXBUILD environment variable to point
+ echo.to the full path of the 'sphinx-build' executable. Alternatively you
+ echo.may add the Sphinx directory to PATH.
+ echo.
+ echo.If you don't have Sphinx installed, grab it from
+ echo.http://sphinx-doc.org/
+ exit /b 1
+)
+
+%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+goto end
+
+:help
+%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+
+:end
+popd
diff --git a/docs/requirements.txt b/docs/requirements.txt
new file mode 100644
index 00000000..897e4720
--- /dev/null
+++ b/docs/requirements.txt
@@ -0,0 +1,6 @@
+git+https://github.com/matteobettini/benchmarl_sphinx_theme.git
+torchrl>=0.2.0
+torch
+tqdm
+hydra-core
+vmas>=1.2.10
diff --git a/docs/source/_templates/autosummary/class.rst b/docs/source/_templates/autosummary/class.rst
new file mode 100644
index 00000000..139e7c16
--- /dev/null
+++ b/docs/source/_templates/autosummary/class.rst
@@ -0,0 +1,9 @@
+{{ fullname | escape | underline }}
+
+.. currentmodule:: {{ module }}
+
+.. autoclass:: {{ objname }}
+ :show-inheritance:
+ :members:
+ :undoc-members:
+ :inherited-members:
diff --git a/docs/source/_templates/autosummary/class_no_inherit.rst b/docs/source/_templates/autosummary/class_no_inherit.rst
new file mode 100644
index 00000000..08b5ed83
--- /dev/null
+++ b/docs/source/_templates/autosummary/class_no_inherit.rst
@@ -0,0 +1,8 @@
+{{ fullname | escape | underline }}
+
+.. currentmodule:: {{ module }}
+
+.. autoclass:: {{ objname }}
+ :show-inheritance:
+ :members:
+ :undoc-members:
diff --git a/docs/source/_templates/autosummary/class_private.rst b/docs/source/_templates/autosummary/class_private.rst
new file mode 100644
index 00000000..e9f2f9de
--- /dev/null
+++ b/docs/source/_templates/autosummary/class_private.rst
@@ -0,0 +1,9 @@
+{{ fullname | escape | underline }}
+
+.. currentmodule:: {{ module }}
+
+.. autoclass:: {{ objname }}
+ :show-inheritance:
+ :members:
+ :undoc-members:
+ :private-members:
diff --git a/docs/source/_templates/autosummary/class_private_no_undoc.rst b/docs/source/_templates/autosummary/class_private_no_undoc.rst
new file mode 100644
index 00000000..191ccbcf
--- /dev/null
+++ b/docs/source/_templates/autosummary/class_private_no_undoc.rst
@@ -0,0 +1,8 @@
+{{ fullname | escape | underline }}
+
+.. currentmodule:: {{ module }}
+
+.. autoclass:: {{ objname }}
+ :show-inheritance:
+ :members:
+ :private-members:
diff --git a/docs/source/_templates/breadcrumbs.html b/docs/source/_templates/breadcrumbs.html
new file mode 100644
index 00000000..4ecb013f
--- /dev/null
+++ b/docs/source/_templates/breadcrumbs.html
@@ -0,0 +1,4 @@
+{%- extends "sphinx_rtd_theme/breadcrumbs.html" %}
+
+{% block breadcrumbs_aside %}
+{% endblock %}
diff --git a/docs/source/concepts/benchmarks.rst b/docs/source/concepts/benchmarks.rst
new file mode 100644
index 00000000..d7eca9e0
--- /dev/null
+++ b/docs/source/concepts/benchmarks.rst
@@ -0,0 +1,25 @@
+Public benchmarks
+=================
+
+.. warning::
+ This section is under a work in progress. We are constantly working on fine-tuning
+ our experiments to enable our users to have access to state-of-the-art benchmarks.
+ If you would like to collaborate in this effort, please reach out to us.
+
+In the `fine_tuned `__
+folder we are collecting some tested hyperparameters for
+specific environments to enable users to bootstrap their benchmarking.
+You can just run the scripts in this folder to automatically use the proposed hyperparameters.
+
+We will tune benchmarks for you and publish the config and benchmarking plots on
+:wandb:`null` `Wandb `__ publicly.
+
+Currently available ones are:
+
+VMAS
+----
+`Conf `__ | :wandb:`null` `Wandb `__
+
+.. raw:: html
+
+
|
## Reporting and plotting
@@ -295,9 +296,9 @@ your benchmarks. No more struggling with matplotlib and latex!
[](examples/plotting)
-
-
-
+
+
+
## Extending
@@ -322,7 +323,6 @@ in the script itself or via [hydra](https://hydra.cc/docs/intro/).
We suggest to read the hydra documentation
to get familiar with all its functionalities.
-The project can be configured either the script itself or via hydra.
Each component in the project has a corresponding yaml configuration in the BenchMARL
[conf tree](benchmarl/conf).
Components' configurations are loaded from these files into python dataclasses that act
@@ -333,8 +333,7 @@ You can also directly load and validate configuration yaml files without using h
### Experiment
-Experiment configurations are in [`benchmarl/conf/config.yaml`](benchmarl/conf/config.yaml),
-with the experiment hyperparameters in [`benchmarl/conf/experiment`](benchmarl/conf/experiment).
+Experiment configurations are in [`benchmarl/conf/config.yaml`](benchmarl/conf/config.yaml).
Running custom experiments is extremely simplified by the [Hydra](https://hydra.cc/) configurations.
The default configuration for the library is contained in the [`benchmarl/conf`](benchmarl/conf) folder.
diff --git a/benchmarl/__init__.py b/benchmarl/__init__.py
index f953c5ca..96fd64ed 100644
--- a/benchmarl/__init__.py
+++ b/benchmarl/__init__.py
@@ -4,13 +4,22 @@
# LICENSE file in the root directory of this source tree.
#
+
+__version__ = "0.0.4"
+
import importlib
+import benchmarl.algorithms
+import benchmarl.benchmark
+import benchmarl.environments
+import benchmarl.experiment
+import benchmarl.models
+
_has_hydra = importlib.util.find_spec("hydra") is not None
if _has_hydra:
- def load_hydra_schemas():
+ def _load_hydra_schemas():
from hydra.core.config_store import ConfigStore
from benchmarl.algorithms import algorithm_config_registry
@@ -28,4 +37,4 @@ def load_hydra_schemas():
for task_schema_name, task_schema in _task_class_registry.items():
cs.store(name=task_schema_name, group="task", node=task_schema)
- load_hydra_schemas()
+ _load_hydra_schemas()
diff --git a/benchmarl/algorithms/__init__.py b/benchmarl/algorithms/__init__.py
index b9e18647..f0e2d20a 100644
--- a/benchmarl/algorithms/__init__.py
+++ b/benchmarl/algorithms/__init__.py
@@ -4,6 +4,7 @@
# LICENSE file in the root directory of this source tree.
#
+from .common import Algorithm, AlgorithmConfig
from .iddpg import Iddpg, IddpgConfig
from .ippo import Ippo, IppoConfig
from .iql import Iql, IqlConfig
@@ -14,6 +15,27 @@
from .qmix import Qmix, QmixConfig
from .vdn import Vdn, VdnConfig
+classes = [
+ "Iddpg",
+ "IddpgConfig",
+ "Ippo",
+ "IppoConfig",
+ "Iql",
+ "IqlConfig",
+ "Isac",
+ "IsacConfig",
+ "Maddpg",
+ "MaddpgConfig",
+ "Mappo",
+ "MappoConfig",
+ "Masac",
+ "MasacConfig",
+ "Qmix",
+ "QmixConfig",
+ "Vdn",
+ "VdnConfig",
+]
+
# A registry mapping "algoname" to its config dataclass
# This is used to aid loading of algorithms from yaml
algorithm_config_registry = {
diff --git a/benchmarl/algorithms/common.py b/benchmarl/algorithms/common.py
index 5e0b86f2..3702b75d 100644
--- a/benchmarl/algorithms/common.py
+++ b/benchmarl/algorithms/common.py
@@ -23,7 +23,7 @@
from torchrl.objectives.utils import HardUpdate, SoftUpdate, TargetNetUpdater
from benchmarl.models.common import ModelConfig
-from benchmarl.utils import DEVICE_TYPING, read_yaml_config
+from benchmarl.utils import _read_yaml_config, DEVICE_TYPING
class Algorithm(ABC):
@@ -32,7 +32,7 @@ class Algorithm(ABC):
This should be overridden by implemented algorithms
and all abstract methods should be implemented.
- Args:
+ Args:
experiment (Experiment): the experiment class
"""
@@ -104,14 +104,13 @@ def _check_specs(self):
def get_loss_and_updater(self, group: str) -> Tuple[LossModule, TargetNetUpdater]:
"""
Get the LossModule and TargetNetUpdater for a specific group.
- This function calls the abstract self._get_loss() which needs to be implemented.
+ This function calls the abstract :class:`~benchmarl.algorithms.Algorithm._get_loss()` which needs to be implemented.
The function will cache the output at the first call and return the cached values in future calls.
Args:
group (str): agent group of the loss and updater
Returns: LossModule and TargetNetUpdater for the group
-
"""
if group not in self._losses_and_updaters.keys():
action_space = self.action_spec[group, "action"]
@@ -144,7 +143,7 @@ def get_replay_buffer(
) -> ReplayBuffer:
"""
Get the ReplayBuffer for a specific group.
- This function will check self.on_policy and create the buffer accordingly
+ This function will check ``self.on_policy`` and create the buffer accordingly
Args:
group (str): agent group of the loss and updater
@@ -165,7 +164,7 @@ def get_replay_buffer(
def get_policy_for_loss(self, group: str) -> TensorDictModule:
"""
Get the non-explorative policy for a specific group loss.
- This function calls the abstract self._get_policy_for_loss() which needs to be implemented.
+ This function calls the abstract :class:`~benchmarl.algorithms.Algorithm._get_policy_for_loss()` which needs to be implemented.
The function will cache the output at the first call and return the cached values in future calls.
Args:
@@ -192,7 +191,7 @@ def get_policy_for_loss(self, group: str) -> TensorDictModule:
def get_policy_for_collection(self) -> TensorDictSequential:
"""
Get the explorative policy for all groups together.
- This function calls the abstract self._get_policy_for_collection() which needs to be implemented.
+ This function calls the abstract :class:`~benchmarl.algorithms.Algorithm._get_policy_for_collection()` which needs to be implemented.
The function will cache the output at the first call and return the cached values in future calls.
Returns: TensorDictSequential representing all explorative policies
@@ -217,7 +216,7 @@ def get_policy_for_collection(self) -> TensorDictSequential:
def get_parameters(self, group: str) -> Dict[str, Iterable]:
"""
Get the dictionary mapping loss names to the relative parameters to optimize for a given group.
- This function calls the abstract self._get_parameters() which needs to be implemented.
+ This function calls the abstract :class:`~benchmarl.algorithms.Algorithm._get_parameters()` which needs to be implemented.
Returns: a dictionary mapping loss names to a parameters' list
"""
@@ -323,13 +322,16 @@ class AlgorithmConfig:
Dataclass representing an algorithm configuration.
This should be overridden by implemented algorithms.
Implementors should:
- 1. add configuration parameters for their algorithm
- 2. implement all abstract methods
+
+ 1. add configuration parameters for their algorithm
+ 2. implement all abstract methods
+
"""
def get_algorithm(self, experiment) -> Algorithm:
"""
Main function to turn the config into the associated algorithm
+
Args:
experiment (Experiment): the experiment class
@@ -349,7 +351,7 @@ def _load_from_yaml(name: str) -> Dict[str, Any]:
/ "algorithm"
/ f"{name.lower()}.yaml"
)
- return read_yaml_config(str(yaml_path.resolve()))
+ return _read_yaml_config(str(yaml_path.resolve()))
@classmethod
def get_from_yaml(cls, path: Optional[str] = None):
@@ -359,7 +361,7 @@ def get_from_yaml(cls, path: Optional[str] = None):
Args:
path (str, optional): The full path of the yaml file to load from.
If None, it will default to
- benchmarl/conf/algorithm/self.associated_class().__name__
+ ``benchmarl/conf/algorithm/self.associated_class().__name__``
Returns: the loaded AlgorithmConfig
"""
@@ -370,7 +372,7 @@ def get_from_yaml(cls, path: Optional[str] = None):
)
)
else:
- return cls(**read_yaml_config(path))
+ return cls(**_read_yaml_config(path))
@staticmethod
@abstractmethod
diff --git a/benchmarl/algorithms/iddpg.py b/benchmarl/algorithms/iddpg.py
index 2bf1657c..742a49ef 100644
--- a/benchmarl/algorithms/iddpg.py
+++ b/benchmarl/algorithms/iddpg.py
@@ -19,6 +19,16 @@
class Iddpg(Algorithm):
+ """Same as :class:`~benchmarkl.algorithms.Maddpg` (from `https://arxiv.org/abs/1706.02275 `__) but with decentralized critics.
+
+ Args:
+ share_param_critic (bool): Whether to share the parameters of the critics withing agent groups
+ loss_function (str): loss function for the value discrepancy. Can be one of "l1", "l2" or "smooth_l1".
+ delay_value (bool): whether to separate the target value networks from the value networks used for
+ data collection.
+
+ """
+
def __init__(
self, share_param_critic: bool, loss_function: str, delay_value: bool, **kwargs
):
@@ -227,6 +237,8 @@ def get_value_module(self, group: str) -> TensorDictModule:
@dataclass
class IddpgConfig(AlgorithmConfig):
+ """Configuration dataclass for :class:`~benchmarl.algorithms.Iddpg`."""
+
share_param_critic: bool = MISSING
loss_function: str = MISSING
delay_value: bool = MISSING
diff --git a/benchmarl/algorithms/ippo.py b/benchmarl/algorithms/ippo.py
index f7190630..0dd9bfa2 100644
--- a/benchmarl/algorithms/ippo.py
+++ b/benchmarl/algorithms/ippo.py
@@ -22,6 +22,21 @@
class Ippo(Algorithm):
+ """Independent PPO (from `https://arxiv.org/abs/2011.09533 `__).
+
+ Args:
+ share_param_critic (bool): Whether to share the parameters of the critics withing agent groups
+ clip_epsilon (scalar): weight clipping threshold in the clipped PPO loss equation.
+ entropy_coef (scalar): entropy multiplier when computing the total loss.
+ critic_coef (scalar): critic loss multiplier when computing the total
+ loss_critic_type (str): loss function for the value discrepancy.
+ Can be one of "l1", "l2" or "smooth_l1".
+ lmbda (float): The GAE lambda
+ scale_mapping (str): positive mapping function to be used with the std.
+ choices: "softplus", "exp", "relu", "biased_softplus_1";
+
+ """
+
def __init__(
self,
share_param_critic: bool,
@@ -270,6 +285,8 @@ def get_critic(self, group: str) -> TensorDictModule:
@dataclass
class IppoConfig(AlgorithmConfig):
+ """Configuration dataclass for :class:`~benchmarl.algorithms.Ippo`."""
+
share_param_critic: bool = MISSING
clip_epsilon: float = MISSING
entropy_coef: float = MISSING
diff --git a/benchmarl/algorithms/iql.py b/benchmarl/algorithms/iql.py
index 8838c8fa..526c3d79 100644
--- a/benchmarl/algorithms/iql.py
+++ b/benchmarl/algorithms/iql.py
@@ -18,6 +18,15 @@
class Iql(Algorithm):
+ """Independent Q Learning (from `https://www.semanticscholar.org/paper/Multi-Agent-Reinforcement-Learning%3A-Independent-Tan/59de874c1e547399b695337bcff23070664fa66e `__).
+
+ Args:
+ loss_function (str): loss function for the value discrepancy. Can be one of "l1", "l2" or "smooth_l1".
+ delay_value (bool): whether to separate the target value networks from the value networks used for
+ data collection.
+
+ """
+
def __init__(self, delay_value: bool, loss_function: str, **kwargs):
super().__init__(**kwargs)
@@ -175,6 +184,8 @@ def process_batch(self, group: str, batch: TensorDictBase) -> TensorDictBase:
@dataclass
class IqlConfig(AlgorithmConfig):
+ """Configuration dataclass for :class:`~benchmarl.algorithms.Iql`."""
+
delay_value: bool = MISSING
loss_function: str = MISSING
diff --git a/benchmarl/algorithms/isac.py b/benchmarl/algorithms/isac.py
index 20df1ac1..972b762f 100644
--- a/benchmarl/algorithms/isac.py
+++ b/benchmarl/algorithms/isac.py
@@ -26,6 +26,30 @@
class Isac(Algorithm):
+ """Independent Soft Actor Critic.
+
+ Args:
+ share_param_critic (bool): Whether to share the parameters of the critics withing agent groups
+ num_qvalue_nets (integer): number of Q-Value networks used.
+ loss_function (str): loss function to be used with
+ the value function loss.
+ delay_qvalue (bool): Whether to separate the target Q value
+ networks from the Q value networks used for data collection.
+ target_entropy (float or str, optional): Target entropy for the
+ stochastic policy. Default is "auto", where target entropy is
+ computed as :obj:`-prod(n_actions)`.
+ discrete_target_entropy_weight (float): weight for the target entropy term when actions are discrete
+ alpha_init (float): initial entropy multiplier.
+ min_alpha (float): min value of alpha.
+ max_alpha (float): max value of alpha.
+ fixed_alpha (bool): if ``True``, alpha will be fixed to its
+ initial value. Otherwise, alpha will be optimized to
+ match the 'target_entropy' value.
+ scale_mapping (str): positive mapping function to be used with the std.
+ choices: "softplus", "exp", "relu", "biased_softplus_1";
+
+ """
+
def __init__(
self,
share_param_critic: bool,
@@ -358,6 +382,8 @@ def get_continuous_value_module(self, group: str) -> TensorDictModule:
@dataclass
class IsacConfig(AlgorithmConfig):
+ """Configuration dataclass for :class:`~benchmarl.algorithms.Isac`."""
+
share_param_critic: bool = MISSING
num_qvalue_nets: int = MISSING
diff --git a/benchmarl/algorithms/maddpg.py b/benchmarl/algorithms/maddpg.py
index df79de41..60501708 100644
--- a/benchmarl/algorithms/maddpg.py
+++ b/benchmarl/algorithms/maddpg.py
@@ -19,6 +19,15 @@
class Maddpg(Algorithm):
+ """Multi Agent DDPG (from `https://arxiv.org/abs/1706.02275 `__).
+
+ Args:
+ share_param_critic (bool): Whether to share the parameters of the critics withing agent groups
+ loss_function (str): loss function for the value discrepancy. Can be one of "l1", "l2" or "smooth_l1".
+ delay_value (bool): whether to separate the target value networks from the value networks used for
+ data collection.
+ """
+
def __init__(
self, share_param_critic: bool, loss_function: str, delay_value: bool, **kwargs
):
@@ -283,6 +292,8 @@ def get_value_module(self, group: str) -> TensorDictModule:
@dataclass
class MaddpgConfig(AlgorithmConfig):
+ """Configuration dataclass for :class:`~benchmarl.algorithms.Maddpg`."""
+
share_param_critic: bool = MISSING
loss_function: str = MISSING
diff --git a/benchmarl/algorithms/mappo.py b/benchmarl/algorithms/mappo.py
index cae735e9..c856642f 100644
--- a/benchmarl/algorithms/mappo.py
+++ b/benchmarl/algorithms/mappo.py
@@ -21,6 +21,21 @@
class Mappo(Algorithm):
+ """Multi Agent PPO (from `https://arxiv.org/abs/2103.01955 `__).
+
+ Args:
+ share_param_critic (bool): Whether to share the parameters of the critics withing agent groups
+ clip_epsilon (scalar): weight clipping threshold in the clipped PPO loss equation.
+ entropy_coef (scalar): entropy multiplier when computing the total loss.
+ critic_coef (scalar): critic loss multiplier when computing the total
+ loss_critic_type (str): loss function for the value discrepancy.
+ Can be one of "l1", "l2" or "smooth_l1".
+ lmbda (float): The GAE lambda
+ scale_mapping (str): positive mapping function to be used with the std.
+ choices: "softplus", "exp", "relu", "biased_softplus_1";
+
+ """
+
def __init__(
self,
share_param_critic: bool,
@@ -301,6 +316,8 @@ def get_critic(self, group: str) -> TensorDictModule:
@dataclass
class MappoConfig(AlgorithmConfig):
+ """Configuration dataclass for :class:`~benchmarl.algorithms.Mappo`."""
+
share_param_critic: bool = MISSING
clip_epsilon: float = MISSING
entropy_coef: float = MISSING
diff --git a/benchmarl/algorithms/masac.py b/benchmarl/algorithms/masac.py
index 95c67ae7..291a6588 100644
--- a/benchmarl/algorithms/masac.py
+++ b/benchmarl/algorithms/masac.py
@@ -20,6 +20,29 @@
class Masac(Algorithm):
+ """Multi Agent Soft Actor Critic.
+
+ Args:
+ share_param_critic (bool): Whether to share the parameters of the critics withing agent groups
+ num_qvalue_nets (integer): number of Q-Value networks used.
+ loss_function (str): loss function to be used with
+ the value function loss.
+ delay_qvalue (bool): Whether to separate the target Q value
+ networks from the Q value networks used for data collection.
+ target_entropy (float or str, optional): Target entropy for the
+ stochastic policy. Default is "auto", where target entropy is
+ computed as :obj:`-prod(n_actions)`.
+ discrete_target_entropy_weight (float): weight for the target entropy term when actions are discrete
+ alpha_init (float): initial entropy multiplier.
+ min_alpha (float): min value of alpha.
+ max_alpha (float): max value of alpha.
+ fixed_alpha (bool): if ``True``, alpha will be fixed to its
+ initial value. Otherwise, alpha will be optimized to
+ match the 'target_entropy' value.
+ scale_mapping (str): positive mapping function to be used with the std.
+ choices: "softplus", "exp", "relu", "biased_softplus_1";
+ """
+
def __init__(
self,
share_param_critic: bool,
@@ -434,6 +457,8 @@ def get_continuous_value_module(self, group: str) -> TensorDictModule:
@dataclass
class MasacConfig(AlgorithmConfig):
+ """Configuration dataclass for :class:`~benchmarl.algorithms.Masac`."""
+
share_param_critic: bool = MISSING
num_qvalue_nets: int = MISSING
diff --git a/benchmarl/algorithms/qmix.py b/benchmarl/algorithms/qmix.py
index fd3bd7cd..f4edc1fd 100644
--- a/benchmarl/algorithms/qmix.py
+++ b/benchmarl/algorithms/qmix.py
@@ -18,6 +18,16 @@
class Qmix(Algorithm):
+ """QMIX (from `https://arxiv.org/abs/1803.11485 `__).
+
+ Args:
+ mixing_embed_dim (int): hidden dimension of the mixing network
+ loss_function (str): loss function for the value discrepancy. Can be one of "l1", "l2" or "smooth_l1".
+ delay_value (bool): whether to separate the target value networks from the value networks used for
+ data collection.
+
+ """
+
def __init__(
self, mixing_embed_dim: int, delay_value: bool, loss_function: str, **kwargs
):
@@ -200,6 +210,8 @@ def get_mixer(self, group: str) -> TensorDictModule:
@dataclass
class QmixConfig(AlgorithmConfig):
+ """Configuration dataclass for :class:`~benchmarl.algorithms.Qmix`."""
+
mixing_embed_dim: int = MISSING
delay_value: bool = MISSING
loss_function: str = MISSING
diff --git a/benchmarl/algorithms/vdn.py b/benchmarl/algorithms/vdn.py
index 8e250f83..4ac77ab8 100644
--- a/benchmarl/algorithms/vdn.py
+++ b/benchmarl/algorithms/vdn.py
@@ -18,6 +18,15 @@
class Vdn(Algorithm):
+ """Vdn (from `https://arxiv.org/abs/1706.05296 `__).
+
+ Args:
+ loss_function (str): loss function for the value discrepancy. Can be one of "l1", "l2" or "smooth_l1".
+ delay_value (bool): whether to separate the target value networks from the value networks used for
+ data collection.
+
+ """
+
def __init__(self, delay_value: bool, loss_function: str, **kwargs):
super().__init__(**kwargs)
@@ -189,6 +198,8 @@ def get_mixer(self, group: str) -> TensorDictModule:
@dataclass
class VdnConfig(AlgorithmConfig):
+ """Configuration dataclass for :class:`~benchmarl.algorithms.Vdn`."""
+
delay_value: bool = MISSING
loss_function: str = MISSING
diff --git a/benchmarl/benchmark/__init__.py b/benchmarl/benchmark/__init__.py
new file mode 100644
index 00000000..0fca8b53
--- /dev/null
+++ b/benchmarl/benchmark/__init__.py
@@ -0,0 +1,7 @@
+# Copyright (c) Meta Platforms, Inc. and affiliates.
+#
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+#
+
+from .benchmark import Benchmark
diff --git a/benchmarl/benchmark.py b/benchmarl/benchmark/benchmark.py
similarity index 75%
rename from benchmarl/benchmark.py
rename to benchmarl/benchmark/benchmark.py
index a2a296a0..6d59eaff 100644
--- a/benchmarl/benchmark.py
+++ b/benchmarl/benchmark/benchmark.py
@@ -13,6 +13,20 @@
class Benchmark:
+ """A benchmark.
+
+ Benchmarks are collections of experiments to compare.
+
+ Args:
+ algorithm_configs (list of AlgorithmConfig): the algorithms to benchmark
+ model_config (ModelConfig): the config of the policy model
+ tasks (list of Task): the tasks to benchmark
+ seeds (set of int): the seeds for the benchmark
+ experiment_config (ExperimentConfig): the experiment config
+ critic_model_config (ModelConfig, optional): the config of the critic model. Defaults to model_config
+
+ """
+
def __init__(
self,
algorithm_configs: Sequence[AlgorithmConfig],
@@ -36,9 +50,11 @@ def __init__(
@property
def n_experiments(self):
+ """The number of experiments in the benchmark."""
return len(self.algorithm_configs) * len(self.tasks) * len(self.seeds)
def get_experiments(self) -> Iterator[Experiment]:
+ """Yields one experiment at a time"""
for algorithm_config in self.algorithm_configs:
for task in self.tasks:
for seed in self.seeds:
@@ -52,6 +68,7 @@ def get_experiments(self) -> Iterator[Experiment]:
)
def run_sequential(self):
+ """Run all the experiments in the benchmark in a sequence."""
for i, experiment in enumerate(self.get_experiments()):
print(f"\nRunning experiment {i+1}/{self.n_experiments}.\n")
try:
diff --git a/benchmarl/environments/common.py b/benchmarl/environments/common.py
index c7f49605..fd4fc2a6 100644
--- a/benchmarl/environments/common.py
+++ b/benchmarl/environments/common.py
@@ -17,7 +17,7 @@
from torchrl.data import CompositeSpec
from torchrl.envs import EnvBase, RewardSum, Transform
-from benchmarl.utils import DEVICE_TYPING, read_yaml_config
+from benchmarl.utils import _read_yaml_config, DEVICE_TYPING
def _load_config(name: str, config: Dict[str, Any]):
@@ -255,7 +255,7 @@ def __str__(self):
@staticmethod
def _load_from_yaml(name: str) -> Dict[str, Any]:
yaml_path = Path(__file__).parent.parent / "conf" / "task" / f"{name}.yaml"
- return read_yaml_config(str(yaml_path.resolve()))
+ return _read_yaml_config(str(yaml_path.resolve()))
def get_from_yaml(self, path: Optional[str] = None) -> Task:
"""
@@ -273,4 +273,4 @@ def get_from_yaml(self, path: Optional[str] = None) -> Task:
Task._load_from_yaml(str(Path(self.env_name()) / Path(task_name)))
)
else:
- return self.update_config(**read_yaml_config(path))
+ return self.update_config(**_read_yaml_config(path))
diff --git a/benchmarl/environments/pettingzoo/common.py b/benchmarl/environments/pettingzoo/common.py
index 372616b8..fdc4eb61 100644
--- a/benchmarl/environments/pettingzoo/common.py
+++ b/benchmarl/environments/pettingzoo/common.py
@@ -15,6 +15,8 @@
class PettingZooTask(Task):
+ """Enum for PettingZoo tasks."""
+
MULTIWALKER = None
WATERWORLD = None
SIMPLE_ADVERSARY = None
diff --git a/benchmarl/environments/smacv2/common.py b/benchmarl/environments/smacv2/common.py
index f9dcc691..47043396 100644
--- a/benchmarl/environments/smacv2/common.py
+++ b/benchmarl/environments/smacv2/common.py
@@ -17,6 +17,8 @@
class Smacv2Task(Task):
+ """Enum for SMACv2 tasks."""
+
PROTOSS_5_VS_5 = None
PROTOSS_10_VS_10 = None
PROTOSS_10_VS_11 = None
diff --git a/benchmarl/environments/vmas/common.py b/benchmarl/environments/vmas/common.py
index ba00c94d..0ee22ac8 100644
--- a/benchmarl/environments/vmas/common.py
+++ b/benchmarl/environments/vmas/common.py
@@ -15,6 +15,8 @@
class VmasTask(Task):
+ """Enum for VMAS tasks."""
+
BALANCE = None
SAMPLING = None
NAVIGATION = None
diff --git a/benchmarl/eval_results.py b/benchmarl/eval_results.py
index 83f7a572..94f2174d 100644
--- a/benchmarl/eval_results.py
+++ b/benchmarl/eval_results.py
@@ -28,6 +28,24 @@
def get_raw_dict_from_multirun_folder(multirun_folder: str) -> Dict:
+ """Get the ``marl-eval`` input dictionary from the folder of a hydra multirun.
+
+ Examples:
+ .. code-block:: python
+
+ from benchmarl.eval_results import get_raw_dict_from_multirun_folder, Plotting
+ raw_dict = get_raw_dict_from_multirun_folder(
+ multirun_folder="some_prefix/multirun/2023-09-22/17-21-34"
+ )
+ processed_data = Plotting.process_data(raw_dict)
+
+ Args:
+ multirun_folder (str): the absolute path to the multirun folder
+
+ Returns:
+ the dict obtained by merging all the json files in the multirun
+
+ """
return load_and_merge_json_dicts(_get_json_files_from_multirun(multirun_folder))
@@ -43,6 +61,18 @@ def _get_json_files_from_multirun(multirun_folder: str) -> List[str]:
def load_and_merge_json_dicts(
json_input_files: List[str], json_output_file: Optional[str] = None
) -> Dict:
+ """Loads and merges json dictionaries to form the ``marl-eval`` input dictionary .
+
+ Args:
+ json_input_files (list of str): a list containing the absolute paths to the json files
+ json_output_file (str, optional): if specified, the merged dictionary will be also written
+ to the file in this absolute path
+
+ Returns:
+ the dict obtained by merging all the json files
+
+ """
+
def update(d, u):
for k, v in u.items():
if isinstance(v, collections.abc.Mapping):
@@ -67,13 +97,49 @@ def update(d, u):
class Plotting:
+ """Class containing static utilities for plotting in ``marl-eval``.
+
+ Examples:
+ >>> from benchmarl.eval_results import get_raw_dict_from_multirun_folder, Plotting
+ >>> raw_dict = get_raw_dict_from_multirun_folder(
+ ... multirun_folder="some_prefix/multirun/2023-09-22/17-21-34"
+ ... )
+ >>> processed_data = Plotting.process_data(raw_dict)
+ ... (
+ ... environment_comparison_matrix,
+ ... sample_efficiency_matrix,
+ ... ) = Plotting.create_matrices(processed_data, env_name="vmas")
+ >>> Plotting.performance_profile_figure(
+ ... environment_comparison_matrix=environment_comparison_matrix
+ ... )
+ >>> Plotting.aggregate_scores(
+ ... environment_comparison_matrix=environment_comparison_matrix
+ ... )
+ >>> Plotting.environemnt_sample_efficiency_curves(
+ ... sample_effeciency_matrix=sample_efficiency_matrix
+ ... )
+ >>> Plotting.task_sample_efficiency_curves(
+ ... processed_data=processed_data, env="vmas", task="navigation"
+ ... )
+ >>> plt.show()
+
+ """
METRICS_TO_NORMALIZE = ["return"]
METRIC_TO_PLOT = "return"
@staticmethod
- def process_data(raw_data: Dict):
- # Call data_process_pipeline to normalize the choosen metrics and to clean the data
+ def process_data(raw_data: Dict) -> Dict:
+ """Call ``data_process_pipeline`` to normalize the chosen metrics and to clean the data
+
+ Args:
+ raw_data (dict): the input data
+
+ Returns:
+ the processed dict
+
+ """
+
return data_process_pipeline(
raw_data=raw_data, metrics_to_normalize=Plotting.METRICS_TO_NORMALIZE
)
diff --git a/benchmarl/experiment/__init__.py b/benchmarl/experiment/__init__.py
index 0e954fb2..775bb0da 100644
--- a/benchmarl/experiment/__init__.py
+++ b/benchmarl/experiment/__init__.py
@@ -4,4 +4,5 @@
# LICENSE file in the root directory of this source tree.
#
+from .callback import Callback
from .experiment import Experiment, ExperimentConfig
diff --git a/benchmarl/experiment/callback.py b/benchmarl/experiment/callback.py
index c93b85d8..d5c32f13 100644
--- a/benchmarl/experiment/callback.py
+++ b/benchmarl/experiment/callback.py
@@ -76,11 +76,11 @@ def __init__(self, experiment, callbacks: List[Callback]):
for callback in self.callbacks:
callback.experiment = experiment
- def on_batch_collected(self, batch: TensorDictBase):
+ def _on_batch_collected(self, batch: TensorDictBase):
for callback in self.callbacks:
callback.on_batch_collected(batch)
- def on_train_step(self, batch: TensorDictBase, group: str) -> TensorDictBase:
+ def _on_train_step(self, batch: TensorDictBase, group: str) -> TensorDictBase:
train_td = None
for callback in self.callbacks:
td = callback.on_train_step(batch, group)
@@ -91,10 +91,10 @@ def on_train_step(self, batch: TensorDictBase, group: str) -> TensorDictBase:
train_td.update(td)
return train_td
- def on_train_end(self, training_td: TensorDictBase, group: str):
+ def _on_train_end(self, training_td: TensorDictBase, group: str):
for callback in self.callbacks:
callback.on_train_end(training_td, group)
- def on_evaluation_end(self, rollouts: List[TensorDictBase]):
+ def _on_evaluation_end(self, rollouts: List[TensorDictBase]):
for callback in self.callbacks:
callback.on_evaluation_end(rollouts)
diff --git a/benchmarl/experiment/experiment.py b/benchmarl/experiment/experiment.py
index ba43a3df..ba550fcd 100644
--- a/benchmarl/experiment/experiment.py
+++ b/benchmarl/experiment/experiment.py
@@ -30,7 +30,7 @@
from benchmarl.experiment.callback import Callback, CallbackNotifier
from benchmarl.experiment.logger import Logger
from benchmarl.models.common import ModelConfig
-from benchmarl.utils import read_yaml_config
+from benchmarl.utils import _read_yaml_config
_has_hydra = importlib.util.find_spec("hydra") is not None
if _has_hydra:
@@ -44,7 +44,7 @@ class ExperimentConfig:
This class acts as a schema for loading and validating yaml configurations.
Parameters in this class aim to be agnostic of the algorithm, task or model used.
- To know their meaning, please check out the descriptions in benchmarl/conf/experiment/base_experiment.yaml
+ To know their meaning, please check out the descriptions in ``benchmarl/conf/experiment/base_experiment.yaml``
"""
sampling_device: str = MISSING
@@ -111,7 +111,7 @@ def train_minibatch_size(self, on_policy: bool) -> int:
"""
The minibatch size of tensors used for training.
On-policy algorithms are trained by splitting the train_batch_size (equal to the collected frames) into minibatches.
- Off-policy algorithms do not go through this process and thus have the train_minibatch_size==train_batch_size
+ Off-policy algorithms do not go through this process and thus have the ``train_minibatch_size==train_batch_size``
Args:
on_policy (bool): is the algorithms on_policy
@@ -168,8 +168,8 @@ def n_envs_per_worker(self, on_policy: bool) -> int:
"""
Number of environments used for collection
- In vectorized environments, this will be the vectorized batch_size.
- In other environments, this will be emulated by running them sequentially.
+ - In vectorized environments, this will be the vectorized batch_size.
+ - In other environments, this will be emulated by running them sequentially.
Args:
on_policy (bool): is the algorithms on_policy
@@ -233,9 +233,10 @@ def get_from_yaml(path: Optional[str] = None):
Args:
path (str, optional): The full path of the yaml file to load from.
If None, it will default to
- benchmarl/conf/experiment/base_experiment.yaml
+ ``benchmarl/conf/experiment/base_experiment.yaml``
- Returns: the loaded ExperimentConfig
+ Returns:
+ the loaded :class:`~benchmarl.experiment.ExperimentConfig`
"""
if path is None:
yaml_path = (
@@ -244,9 +245,9 @@ def get_from_yaml(path: Optional[str] = None):
/ "experiment"
/ "base_experiment.yaml"
)
- return ExperimentConfig(**read_yaml_config(str(yaml_path.resolve())))
+ return ExperimentConfig(**_read_yaml_config(str(yaml_path.resolve())))
else:
- return ExperimentConfig(**read_yaml_config(path))
+ return ExperimentConfig(**_read_yaml_config(path))
def validate(self, on_policy: bool):
"""
@@ -282,16 +283,15 @@ class Experiment(CallbackNotifier):
"""
Main experiment class in BenchMARL.
-
Args:
task (Task): the task configuration
algorithm_config (AlgorithmConfig): the algorithm configuration
model_config (ModelConfig): the policy model configuration
seed (int): the seed for the experiment
- config (ExperimentConfig):
+ config (ExperimentConfig): the experiment config
critic_model_config (ModelConfig, optional): the policy model configuration.
If None, it defaults to model_config
- callbacks (list of Callback, optional): list of benchmarl.experiment.callbacks.Callback for this experiment
+ callbacks (list of Callback, optional): callbacks for this experiment
"""
def __init__(
@@ -330,7 +330,7 @@ def __init__(
@property
def on_policy(self) -> bool:
- """Weather the algorithm has to be run on policy"""
+ """Whether the algorithm has to be run on policy."""
return self.algorithm_config.on_policy()
def _setup(self):
@@ -538,7 +538,7 @@ def _collection_loop(self):
pbar.set_description(f"mean return = {self.mean_return}", refresh=False)
# Callback
- self.on_batch_collected(batch)
+ self._on_batch_collected(batch)
# Loop over groups
training_start = time.time()
@@ -561,7 +561,7 @@ def _collection_loop(self):
)
# Callback
- self.on_train_end(training_td, group)
+ self._on_train_end(training_td, group)
# Exploration update
if isinstance(self.group_policies[group], TensorDictSequential):
@@ -651,7 +651,7 @@ def _optimizer_loop(self, group: str) -> TensorDictBase:
if self.target_updaters[group] is not None:
self.target_updaters[group].step()
- callback_loss = self.on_train_step(subdata, group)
+ callback_loss = self._on_train_step(subdata, group)
if callback_loss is not None:
training_td.update(callback_loss)
@@ -720,11 +720,11 @@ def callback(env, td):
total_frames=self.total_frames,
)
# Callback
- self.on_evaluation_end(rollouts)
+ self._on_evaluation_end(rollouts)
# Saving experiment state
def state_dict(self) -> OrderedDict:
- """Get the state_dict for the experiment"""
+ """Get the state_dict for the experiment."""
state = OrderedDict(
total_time=self.total_time,
total_frames=self.total_frames,
@@ -743,7 +743,12 @@ def state_dict(self) -> OrderedDict:
return state_dict
def load_state_dict(self, state_dict: Dict) -> None:
- """Load the state_dict for the experiment"""
+ """Load the state_dict for the experiment.
+
+ Args:
+ state_dict (dict): the state dict
+
+ """
for group in self.group_map.keys():
self.losses[group].load_state_dict(state_dict[f"loss_{group}"])
self.replay_buffers[group].load_state_dict(state_dict[f"buffer_{group}"])
diff --git a/benchmarl/hydra_config.py b/benchmarl/hydra_config.py
index e1465e2a..3f9cb100 100644
--- a/benchmarl/hydra_config.py
+++ b/benchmarl/hydra_config.py
@@ -3,8 +3,7 @@
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
#
-
-from omegaconf import DictConfig, OmegaConf
+import importlib
from benchmarl.algorithms.common import AlgorithmConfig
from benchmarl.environments import Task, task_config_registry
@@ -12,8 +11,23 @@
from benchmarl.models import model_config_registry
from benchmarl.models.common import ModelConfig, parse_model_config, SequenceModelConfig
+_has_hydra = importlib.util.find_spec("hydra") is not None
+
+if _has_hydra:
+ from omegaconf import DictConfig, OmegaConf
+
def load_experiment_from_hydra(cfg: DictConfig, task_name: str) -> Experiment:
+ """Creates an :class:`~benchmarl.experiment.Experiment` from hydra config.
+
+ Args:
+ cfg (DictConfig): the config dictionary from hydra main
+ task_name (str): the name of the task to load
+
+ Returns:
+ :class:`~benchmarl.experiment.Experiment`
+
+ """
algorithm_config = load_algorithm_config_from_hydra(cfg.algorithm)
experiment_config = load_experiment_config_from_hydra(cfg.experiment)
task_config = load_task_config_from_hydra(cfg.task, task_name)
@@ -31,20 +45,57 @@ def load_experiment_from_hydra(cfg: DictConfig, task_name: str) -> Experiment:
def load_task_config_from_hydra(cfg: DictConfig, task_name: str) -> Task:
+ """Returns a :class:`~benchmarl.environments.Task` from hydra config.
+
+ Args:
+ cfg (DictConfig): the task config dictionary from hydra
+ task_name (str): the name of the task to load
+
+ Returns:
+ :class:`~benchmarl.environments.Task`
+
+ """
return task_config_registry[task_name].update_config(
OmegaConf.to_container(cfg, resolve=True, throw_on_missing=True)
)
def load_experiment_config_from_hydra(cfg: DictConfig) -> ExperimentConfig:
+ """Returns a :class:`~benchmarl.experiment.ExperimentConfig` from hydra config.
+
+ Args:
+ cfg (DictConfig): the experiment config dictionary from hydra
+
+ Returns:
+ :class:`~benchmarl.experiment.ExperimentConfig`
+
+ """
return OmegaConf.to_object(cfg)
def load_algorithm_config_from_hydra(cfg: DictConfig) -> AlgorithmConfig:
+ """Returns a :class:`~benchmarl.algorithms.AlgorithmConfig` from hydra config.
+
+ Args:
+ cfg (DictConfig): the algorithm config dictionary from hydra
+
+ Returns:
+ :class:`~benchmarl.algorithms.AlgorithmConfig`
+
+ """
return OmegaConf.to_object(cfg)
def load_model_config_from_hydra(cfg: DictConfig) -> ModelConfig:
+ """Returns a :class:`~benchmarl.models.ModelConfig` from hydra config.
+
+ Args:
+ cfg (DictConfig): the model config dictionary from hydra
+
+ Returns:
+ :class:`~benchmarl.models.ModelConfig`
+
+ """
if "layers" in cfg.keys():
model_configs = [
load_model_config_from_hydra(cfg.layers[f"l{i}"])
diff --git a/benchmarl/models/__init__.py b/benchmarl/models/__init__.py
index b437626a..fa71cc1b 100644
--- a/benchmarl/models/__init__.py
+++ b/benchmarl/models/__init__.py
@@ -4,6 +4,12 @@
# LICENSE file in the root directory of this source tree.
#
-from .mlp import MlpConfig
+from .common import Model, ModelConfig, SequenceModel, SequenceModelConfig
+from .mlp import Mlp, MlpConfig
+
+classes = [
+ "Mlp",
+ "MlpConfig",
+]
model_config_registry = {"mlp": MlpConfig}
diff --git a/benchmarl/models/common.py b/benchmarl/models/common.py
index 7110005d..a0ec5b43 100644
--- a/benchmarl/models/common.py
+++ b/benchmarl/models/common.py
@@ -15,7 +15,7 @@
from torchrl.data import CompositeSpec, UnboundedContinuousTensorSpec
from torchrl.envs import EnvBase
-from benchmarl.utils import class_from_name, DEVICE_TYPING, read_yaml_config
+from benchmarl.utils import _class_from_name, _read_yaml_config, DEVICE_TYPING
def _check_spec(tensordict, spec):
@@ -28,7 +28,7 @@ def parse_model_config(cfg: Dict[str, Any]) -> Dict[str, Any]:
kwargs = {}
for key, value in cfg.items():
if key.endswith("class") and value is not None:
- value = class_from_name(cfg[key])
+ value = _class_from_name(cfg[key])
kwargs.update({key: value})
return kwargs
@@ -60,12 +60,12 @@ class Model(TensorDictModuleBase, ABC):
output_spec (CompositeSpec): the output spec of the model
agent_group (str): the name of the agent group the model is for
n_agents (int): the number of agents this module is for
- device (str): the mdoel's device
+ device (str): the model's device
input_has_agent_dim (bool): This tells the model if the input will have a multi-agent dimension or not.
For example, the input of policies will always have this set to true,
but critics that use a global state have this set to false as the state is shared by all agents
centralised (bool): This tells the model if it has full observability.
- This will always be true when self.input_has_agent_dim==False,
+ This will always be true when ``self.input_has_agent_dim==False``,
but in cases where the input has the agent dimension, this parameter is
used to distinguish between a decentralised model (where each agent's data
is processed separately) and a centralized model, where the model pools all data together
@@ -114,8 +114,8 @@ def __init__(
def output_has_agent_dim(self) -> bool:
"""
This is a dynamically computed attribute that indicates if the output will have the agent dimension.
- This will be false when share_params==True and centralised==True, and true in all other cases.
- When output_has_agent_dim is true, your model's output should contain the multiagent dimension,
+ This will be false when ``share_params==True and centralised==True``, and true in all other cases.
+ When output_has_agent_dim is true, your model's output should contain the multi-agent dimension,
and the dimension should be absent otherwise
"""
return output_has_agent_dim(self.share_params, self.centralised)
@@ -170,6 +170,12 @@ def _forward(self, tensordict: TensorDictBase) -> TensorDictBase:
class SequenceModel(Model):
+ """A sequence of :class:`~benchmarl.models.Model`
+
+ Args:
+ models (list of Model): the models in the sequence
+ """
+
def __init__(
self,
models: List[Model],
@@ -194,11 +200,13 @@ def _forward(self, tensordict: TensorDictBase) -> TensorDictBase:
@dataclass
class ModelConfig(ABC):
"""
- Dataclass representing an model configuration.
+ Dataclass representing a :class:`~benchmarl.models.Model` configuration.
This should be overridden by implemented models.
Implementors should:
- 1. add configuration parameters for their algorithm
- 2. implement all abstract methods
+
+ 1. add configuration parameters for their algorithm
+ 2. implement all abstract methods
+
"""
def get_model(
@@ -280,7 +288,7 @@ def _load_from_yaml(name: str) -> Dict[str, Any]:
/ "layers"
/ f"{name.lower()}.yaml"
)
- cfg = read_yaml_config(str(yaml_path.resolve()))
+ cfg = _read_yaml_config(str(yaml_path.resolve()))
return parse_model_config(cfg)
@classmethod
@@ -302,11 +310,13 @@ def get_from_yaml(cls, path: Optional[str] = None):
)
)
else:
- return cls(**parse_model_config(read_yaml_config(path)))
+ return cls(**parse_model_config(_read_yaml_config(path)))
@dataclass
class SequenceModelConfig(ModelConfig):
+ """Dataclass for a :class:`~benchmarl.models.SequenceModel`."""
+
model_configs: Sequence[ModelConfig]
intermediate_sizes: Sequence[int]
diff --git a/benchmarl/models/mlp.py b/benchmarl/models/mlp.py
index 76e25eef..dfd49131 100644
--- a/benchmarl/models/mlp.py
+++ b/benchmarl/models/mlp.py
@@ -18,6 +18,20 @@
class Mlp(Model):
+ """Multi layer perceptron model.
+
+ Args:
+ num_cells (int or Sequence[int], optional): number of cells of every layer in between the input and output. If
+ an integer is provided, every layer will have the same number of cells. If an iterable is provided,
+ the linear layers out_features will match the content of num_cells.
+ layer_class (Type[nn.Module]): class to be used for the linear layers;
+ activation_class (Type[nn.Module]): activation class to be used.
+ activation_kwargs (dict, optional): kwargs to be used with the activation class;
+ norm_class (Type, optional): normalization class, if any.
+ norm_kwargs (dict, optional): kwargs to be used with the normalization layers;
+
+ """
+
def __init__(
self,
**kwargs,
@@ -106,6 +120,8 @@ def _forward(self, tensordict: TensorDictBase) -> TensorDictBase:
@dataclass
class MlpConfig(ModelConfig):
+ """Dataclass config for a :class:`~benchmarl.models.Mlp`."""
+
num_cells: Sequence[int] = MISSING
layer_class: Type[nn.Module] = MISSING
diff --git a/benchmarl/run.py b/benchmarl/run.py
index a2cfb299..459b8f6f 100644
--- a/benchmarl/run.py
+++ b/benchmarl/run.py
@@ -13,6 +13,19 @@
@hydra.main(version_base=None, config_path="conf", config_name="config")
def hydra_experiment(cfg: DictConfig) -> None:
+ """Runs an experiment loading its config from hydra.
+
+ This function is decorated as ``@hydra.main`` and is called by running
+
+ .. code-block:: console
+
+ python benchmarl/run.py algorithm=mappo task=vmas/balance
+
+
+ Args:
+ cfg (DictConfig): the hydra config dictionary
+
+ """
hydra_choices = HydraConfig.get().runtime.choices
task_name = hydra_choices.task
algorithm_name = hydra_choices.algorithm
diff --git a/benchmarl/utils.py b/benchmarl/utils.py
index 3e3fcacc..b1f80141 100644
--- a/benchmarl/utils.py
+++ b/benchmarl/utils.py
@@ -13,7 +13,7 @@
DEVICE_TYPING = Union[torch.device, str, int]
-def read_yaml_config(config_file: str) -> Dict[str, Any]:
+def _read_yaml_config(config_file: str) -> Dict[str, Any]:
with open(config_file) as config:
yaml_string = config.read()
config_dict = yaml.safe_load(yaml_string)
@@ -22,7 +22,7 @@ def read_yaml_config(config_file: str) -> Dict[str, Any]:
return config_dict
-def class_from_name(name: str):
+def _class_from_name(name: str):
name_split = name.split(".")
module_name = ".".join(name_split[:-1])
class_name = name_split[-1]
diff --git a/docs/Makefile b/docs/Makefile
new file mode 100644
index 00000000..d0c3cbf1
--- /dev/null
+++ b/docs/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = source
+BUILDDIR = build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/docs/make.bat b/docs/make.bat
new file mode 100644
index 00000000..9534b018
--- /dev/null
+++ b/docs/make.bat
@@ -0,0 +1,35 @@
+@ECHO OFF
+
+pushd %~dp0
+
+REM Command file for Sphinx documentation
+
+if "%SPHINXBUILD%" == "" (
+ set SPHINXBUILD=sphinx-build
+)
+set SOURCEDIR=source
+set BUILDDIR=build
+
+if "%1" == "" goto help
+
+%SPHINXBUILD% >NUL 2>NUL
+if errorlevel 9009 (
+ echo.
+ echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
+ echo.installed, then set the SPHINXBUILD environment variable to point
+ echo.to the full path of the 'sphinx-build' executable. Alternatively you
+ echo.may add the Sphinx directory to PATH.
+ echo.
+ echo.If you don't have Sphinx installed, grab it from
+ echo.http://sphinx-doc.org/
+ exit /b 1
+)
+
+%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+goto end
+
+:help
+%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+
+:end
+popd
diff --git a/docs/requirements.txt b/docs/requirements.txt
new file mode 100644
index 00000000..897e4720
--- /dev/null
+++ b/docs/requirements.txt
@@ -0,0 +1,6 @@
+git+https://github.com/matteobettini/benchmarl_sphinx_theme.git
+torchrl>=0.2.0
+torch
+tqdm
+hydra-core
+vmas>=1.2.10
diff --git a/docs/source/_templates/autosummary/class.rst b/docs/source/_templates/autosummary/class.rst
new file mode 100644
index 00000000..139e7c16
--- /dev/null
+++ b/docs/source/_templates/autosummary/class.rst
@@ -0,0 +1,9 @@
+{{ fullname | escape | underline }}
+
+.. currentmodule:: {{ module }}
+
+.. autoclass:: {{ objname }}
+ :show-inheritance:
+ :members:
+ :undoc-members:
+ :inherited-members:
diff --git a/docs/source/_templates/autosummary/class_no_inherit.rst b/docs/source/_templates/autosummary/class_no_inherit.rst
new file mode 100644
index 00000000..08b5ed83
--- /dev/null
+++ b/docs/source/_templates/autosummary/class_no_inherit.rst
@@ -0,0 +1,8 @@
+{{ fullname | escape | underline }}
+
+.. currentmodule:: {{ module }}
+
+.. autoclass:: {{ objname }}
+ :show-inheritance:
+ :members:
+ :undoc-members:
diff --git a/docs/source/_templates/autosummary/class_private.rst b/docs/source/_templates/autosummary/class_private.rst
new file mode 100644
index 00000000..e9f2f9de
--- /dev/null
+++ b/docs/source/_templates/autosummary/class_private.rst
@@ -0,0 +1,9 @@
+{{ fullname | escape | underline }}
+
+.. currentmodule:: {{ module }}
+
+.. autoclass:: {{ objname }}
+ :show-inheritance:
+ :members:
+ :undoc-members:
+ :private-members:
diff --git a/docs/source/_templates/autosummary/class_private_no_undoc.rst b/docs/source/_templates/autosummary/class_private_no_undoc.rst
new file mode 100644
index 00000000..191ccbcf
--- /dev/null
+++ b/docs/source/_templates/autosummary/class_private_no_undoc.rst
@@ -0,0 +1,8 @@
+{{ fullname | escape | underline }}
+
+.. currentmodule:: {{ module }}
+
+.. autoclass:: {{ objname }}
+ :show-inheritance:
+ :members:
+ :private-members:
diff --git a/docs/source/_templates/breadcrumbs.html b/docs/source/_templates/breadcrumbs.html
new file mode 100644
index 00000000..4ecb013f
--- /dev/null
+++ b/docs/source/_templates/breadcrumbs.html
@@ -0,0 +1,4 @@
+{%- extends "sphinx_rtd_theme/breadcrumbs.html" %}
+
+{% block breadcrumbs_aside %}
+{% endblock %}
diff --git a/docs/source/concepts/benchmarks.rst b/docs/source/concepts/benchmarks.rst
new file mode 100644
index 00000000..d7eca9e0
--- /dev/null
+++ b/docs/source/concepts/benchmarks.rst
@@ -0,0 +1,25 @@
+Public benchmarks
+=================
+
+.. warning::
+ This section is under a work in progress. We are constantly working on fine-tuning
+ our experiments to enable our users to have access to state-of-the-art benchmarks.
+ If you would like to collaborate in this effort, please reach out to us.
+
+In the `fine_tuned `__
+folder we are collecting some tested hyperparameters for
+specific environments to enable users to bootstrap their benchmarking.
+You can just run the scripts in this folder to automatically use the proposed hyperparameters.
+
+We will tune benchmarks for you and publish the config and benchmarking plots on
+:wandb:`null` `Wandb `__ publicly.
+
+Currently available ones are:
+
+VMAS
+----
+`Conf `__ | :wandb:`null` `Wandb `__
+
+.. raw:: html
+
+