Scenic is a codebase with a focus on research around attention-based models for computer vision. Scenic has been successfully used to develop classification, segmentation, and detection models for multiple modalities including images, video, audio, and multimodal combinations of them.
More precisely, Scenic is a (i) set of shared light-weight libraries solving tasks commonly encountered tasks when training large-scale (i.e. multi-device, multi-host) vision models; and (ii) several projects containing fully fleshed out problem-specific training and evaluation loops using these libraries.
Scenic is developed in JAX and uses Flax.
- What we offer
- SOTA models and baselines in Scenic
- Philosophy
- Getting started
- Scenic component design
- Citing Scenic
Among others Scenic provides
- Boilerplate code for launching experiments, summary writing, logging, profiling, etc;
- Optimized training and evaluation loops, losses, metrics, bi-partite matchers, etc;
- Input-pipelines for popular vision datasets;
- Baseline models, including strong non-attentional baselines.
There are some SOTA models and baselines in Scenic which were either developed using Scenic, or have been reimplemented in Scenic:
Projects that were developed in Scenic or used it for their experiments:
- ViViT: A Video Vision Transformer
- OmniNet: Omnidirectional Representations from Transformers
- Attention Bottlenecks for Multimodal Fusion
- TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?
- Exploring the Limits of Large Scale Pre-training
- The Efficiency Misnomer
- Discrete Representations Strengthen Vision Transformer Robustness
- Pyramid Adversarial Training Improves ViT Performance
- VUT: Versatile UI Transformer for Multi-Modal Multi-Task User Interface Modeling
- CLAY: Learning to Denoise Raw Mobile UI Layouts for Improving Datasets at Scale
- Zero-Shot Text-Guided Object Generation with Dream Fields
- Multiview Transformers for Video Recognition
- PolyViT: Co-training Vision Transformers on Images, Videos and Audio
- Simple Open-Vocabulary Object Detection with Vision Transformers
- Learning with Neighbor Consistency for Noisy Labels
- Token Turing Machines
- Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning
- AVATAR: Unconstrained Audiovisual Speech Recognition
- Adaptive Computation with Elastic Input Sequence
- Location-Aware Self-Supervised Transformers for Semantic Segmentation
- How can objects help action recognition?
- Verbs in Action: Improving verb understanding in video-language models
- Unified Visual Relationship Detection with Vision and Language Models
- UnLoc: A Unified Framework for Video Localization Tasks
- REVEAL: Retrieval-Augmented Visual-Language Pre-Training with Multi-Source Multimodal Knowledge Memory
- Audiovisual Masked Autoencoders
- MatFormer: Nested Transformer for Elastic Inference
- Pixel Aligned Language Models
- A Generative Approach for Wikipedia-Scale Visual Entity Recognition
- Streaming Dense Video Captioning
- Dense Video Object Captioning from Disjoint Supervision
More information can be found in projects.
Baselines that were reproduced in Scenic:
- (ViT) An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- (DETR) End-to-End Object Detection with Transformers
- Deformable DETR: Deformable Transformers for End-to-End Object Detection
- (CLIP) Learning Transferable Visual Models From Natural Language Supervision
- MLP-Mixer: An all-MLP Architecture for Vision
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers
- Big Transfer (BiT): General Visual Representation Learning
- Deep Residual Learning for Image Recognition
- U-Net: Convolutional Networks for Biomedical Image Segmentation
- PCT: Point Cloud Transformer
- Universal Transformers
- PonderNet
- Masked Autoencoders Are Scalable Vision Learners
- Rethinking Attention with Performers
- (CenterNet) Objects as Points
- (SAM) Segment Anything
More information can be found in baseline models.
Scenic aims to facilitate rapid prototyping of large-scale vision models. To keep the code simple to understand and extend we prefer forking and copy-pasting over adding complexity or increasing abstraction. Only when functionality proves to be widely useful across many models and tasks it may be upstreamed to Scenic's shared libraries.
- See
projects/baselines/README.mdfor a walk-through baseline models and instructions on how to run the code. - If you would like to contribute to Scenic, please check out the Philisophy, Code structure and Contributing sections. Should your contribution be a part of the shared libraries, please send us a pull request!
You will need Python 3.9 or later. Download the code from GitHub
$ git clone https://github.com/google-research/scenic.git
$ cd scenic
$ pip install .and run training for ViT on ImageNet:
$ python scenic/main.py -- \
--config=scenic/projects/baselines/configs/imagenet/imagenet_vit_config.py \
--workdir=./Note that for specific projects and baselines, you might need to install extra
packages that are mentioned in their README.md or requirements.txt files.
Here is also a minimal colab to train a simple feed-forward model using Scenic.
Scenic is designed to propose different levels of abstraction, to support
hosting projects that only require changing hyper-parameters by defining config
files, to those that need customization on the input pipeline, model
architecture, losses and metrics, and the training loop. To make this happen,
the code in Scenic is organized as either project-level code,
which refers to customized code for specific projects or baselines or
library-level code, which refers to common functionalities and general
patterns that are adapted by the majority of projects. The project-level
code lives in the projects directory.
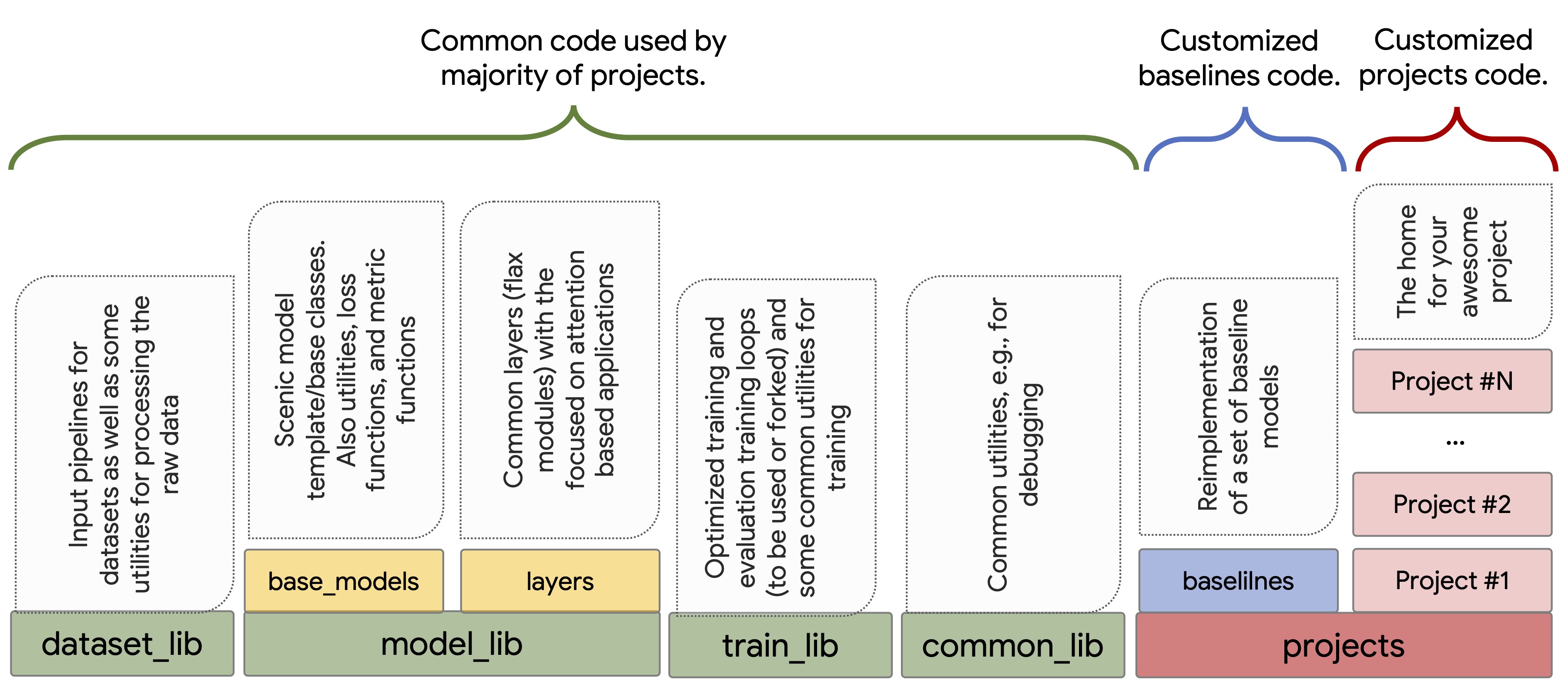
The goal is to keep the library-level code minimal and well-tested and to avoid introducing extra abstractions to support minor use-cases. Shared libraries provided by Scenic are split into:
dataset_lib: Implements IO pipelines for loading and pre-processing data for common Computer Vision tasks and benchmarks (see "Tasks and Datasets" section). All pipelines are designed to be scalable and support multi-host and multi-device setups, taking care dividing data among multiple hosts, incomplete batches, caching, pre-fetching, etc.model_lib: Provides- several abstract model interfaces (e.g.
ClassificationModelorSegmentationModelinmodel_lib.base_models) with task-specific losses and metrics; - neural network layers in
model_lib.layers, focusing on efficient implementation of attention and transformer layers; - accelerator-friendly implementations of bipartite matching
algorithms in
model_lib.matchers.
- several abstract model interfaces (e.g.
train_lib: Provides tools for constructing training loops and implements several optimized trainers (classification trainer and segmentation trainer) that can be forked for customization.common_lib: General utilities, like logging and debugging modules, functionalities for processing raw data, etc.
Scenic supports the development of customized solutions for customized tasks and data via the concept of "project". There is no one-fits-all recipe for how much code should be re-used by a project. Projects can consist of only configs and use the common models, trainers, task/data that live in library-level code, or they can simply fork any of the mentioned functionalities and redefine, layers, losses, metrics, logging methods, tasks, architectures, as well as training and evaluation loops. The modularity of library-level code makes it flexible for projects to fall placed on any spot in the "run-as-is" to "fully customized" spectrum.
Common baselines such as a ResNet and Vision Transformer (ViT) are implemented
in the projects/baselines
project. Forking models in this directory is a good starting point for new
projects.
If you use Scenic, you can cite our white paper. Here is an example BibTeX entry:
@InProceedings{dehghani2021scenic,
author = {Dehghani, Mostafa and Gritsenko, Alexey and Arnab, Anurag and Minderer, Matthias and Tay, Yi},
title = {Scenic: A JAX Library for Computer Vision Research and Beyond},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2022},
pages = {21393-21398}
}Disclaimer: This is not an official Google product.