| description |
|---|
DOA-GAN: Dual-Order Attentive Generative Adversarial Network for Image Copy-Move Forgery Detection and Localization |
Ashraful Islam, Chengjiang Long, Arslan Basharat, and Anthony Hoogs. 2020. DOA-GAN: Dual-Order Attentive Generative Adversarial Network for Image Copy-Move Forgery Detection and Localization. 2020 Ieee Cvf Conf Comput Vis Pattern Recognit Cvpr 00, (2020), 4675–4684. DOI:https://doi.org/10.1109/cvpr42600.2020.00473
Dual-order attentive Generative Adversarial Network, for the generator, using an end-to-end framework based on a deep convolutional neural network. Also, they design a dual-order attention module to produce the attention map, one is to explore the copy-move aware location information, another one is to capture more precise patch inter-dependency. Formulating with the two maps to get the final feature representation. Feed the feature to the detection and localization branch to get the final score and the segmentation mask of pristine(with souece, backgroudm target region), respectively. And the generator to check whether the predicted mask is identical to ground truth or not. The loss function used in this model, adversarial loss, cross-etropy loss, and the detection loss.
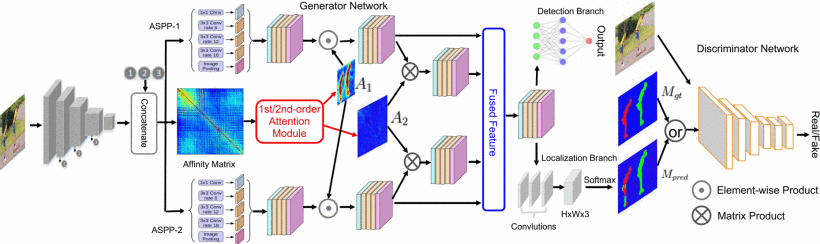
- Extract the feature representation by VGG-19 first. 根据VGG得到的特征表示会进入两个不同参数的空间空洞卷积(ASPP)
- Get the affinity matrix to explore the correlation between different parts of image.
- Leveraging the patch-matching strategy, calculate the likelihood that a patch in the i row matches j column in the affinity matrix after a Gaussian kernel to reduce the score.
- According to the likelihood, extract top-k value for each row, reshape to the h\times w\times k, then feed them into an attention module. Attention Module consist of three convolution blocks.
- 将空间空洞卷积得到的特征表示和经过注意力模块得到的注意力图结合,Fuse feature, 得到最终的特征表示。
- 判别器的机构来自于Patch-GAN的判别器。判别器也是全卷积的,包括5个卷积块。
- 最后的实验结果,他们在USC-ISC CMFD,CASIA CMFD, CoMoFoD的数据集上进行的评估,也做了一些ablation研究,最后也将自己的方法应用在了其他的一些图像篡改检测的任务上,包括向image splicing manipulation, video的CMFD,都取得了不错的结果,Loc和det的准确率最高是到了97, 96在USC-ISI的数据集上,在其他一些数据集上的表现可能,在loc上最高只有55%。因为其他的一些数据集没有提供gt mask来区分source和target。
当我们的图片是从一个统一的背景中选择了一块进行copy,然后move同样的一个统一的背景上,模型的表现要优化;第二个是当copy move的区域很小的时候,那其实有些人也会通过故意降低图片的分辨率来模糊这个已经被篡改了图片,但是其实这种很小的篡改去检测他是不是没有意义。