本文内容参考网络,侵删
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
喜欢的话麻烦点下Star哈
本文也将同步到我的个人博客:
更多Java技术文章将陆续在微信公众号【Java技术江湖】更新,敬请关注。
该系列博文会告诉你什么是分布式系统,这对后端工程师来说是很重要的一门学问,我们会逐步了解常见的分布式技术、以及一些较为常见的分布式系统概念,同时也需要进一步了解zookeeper、分布式事务、分布式锁、负载均衡等技术,以便让你更完整地了解分布式技术的具体实战方法,为真正应用分布式技术做好准备。
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
用户使用网站的服务,需要使用浏览器与Web服务器进行多次交互。HTTP协议本身是无状态的,需要基于HTTP协议支持会话状态(Session State)的机制。具体的实现方式是:在会话开始时,分配一个
唯一的会话标识(SessionID),并通过Cookie将这个标识告诉浏览器,以后每次请求的时候,浏览器都会带上这个会话标识SessionID来告诉Web服务器这个请求是属于哪个会话的。在Web服务器上,各个会话都有独立的存储,保存不同会话的信息。如果遇到禁用Cookie的情况,一般的做法就是把这个会话标识放到URL的参数中。
当Web服务器从一台变为多台时,就会出现Session一致性问题。

如上图所示,当一个带有会话标识的HTTP请求到了Web服务器后,需要在HTTP请求的处理过程中找到对应的会话数据(Session)。但是,现在存在的问题就是:如果我第一次访问网站时请求落到了左边的服务器,那么我的Session就创建在左边的服务器上了,如果我们不做处理,就不能保证接下来的请求每次都落在同一边的服务器上了。这就是Session一致性问题。
在单机的情况下,会话保存在单机上,请求也是由这个机器处理,因此不会有问题。当Web服务器变为多台以后,如果保证同一个会话的请求都在同一个Web服务器上处理,则对该会话来说,与之前单机的情况是一样的。
如果要做到这样,就需要负载均衡器能够根据每次请求的会话标识SessionID来进行请求转发,如下图所示。这种方式称之为Session Stiky方式。

该方案本身非常简单,对于Web服务器来说,该方案和单机的情况是一样的,只是我们在负载均衡器上做了手脚。这个方案可以让同样Session的请求每次都发送到同一个Web服务器来处理,非常利于针对Session进行服务端本地的缓存。
其所存在的问题包括:
- 如果有一台Web服务器宕机或者重启,则该机器上的会话数据就会丢失。如果会话中有登录状态数据,则用户需要重新登陆。
- 会话标识是应用层的信息,则负载均衡器要将同一个会话的请求都保存到同一个Web服务器上的话,就需要进行应用层(七层)的解析,这个开销比第四层的交换要大。
- 负载均衡器变为了一个有状态的节点,要将会话保存到具体Web服务器的映射,因此内存消耗会更大,容灾会更麻烦。
打个比方来说,对于Session Stiky,如果说Web服务器是我们每次吃饭的饭店,会话数据就是我们吃饭用的碗筷。要保证每次吃饭都用自己的碗筷,我就把餐具存在某一家,并且每次都去这家店吃,这是个不错的主意。
如果我们继续以去饭店吃饭类比,那么除了前面的方式之外,如果我在每个店都存放一套自己的餐具,就可以更加自由地选择饭店。Session Replication就是这样一种方式,如下图所示。

可以看到,在Session Replication方案中,不再要求负载均衡器来保证同一个会话地多次请求必须到同一个Web服务器上了。而我们的Web服务器之间则增加了会话数据的同步。通过同步就保证了不同Web服务器之间的Session数据的一致。
但是,Session Replication方案也存在一些问题,包括:
-
同步Session数据造成了网络带宽的开销。只要Session数据有变化,就需要将数据同步到其他所有机器上,机器数越多,同步带来的网络带宽开销就越大。
-
每台Web服务器都要保存所有的Session数据,如果整个集群的Session数很多的话,每台机器用于保存Session数据的内容占用会很严重。
这就是Session Replication方案。这个方案是靠应用容器来完成Session的复制从而使得应用解决Session问题的,应用本身并不关心这个事情。不过,这个方案并不适合集群机器数多的场景。如果只有几台机器,用该方案是可以的。
同样是希望同一个会话的请求可以发到不同的Web服务器上,前面的Session Replication是一种方案,还有一种方案就是把Session数据集中存储起来,然后不同Web服务器从同样的地方来获取Session。其大概的结构如下图所示:

可以看到,与Session Replication方案一样的部分是,会话请求经过负载均衡器后,不会被固定在同样的Web服务器上。不同的地方是,Web服务器之间没有Session数据复制,并且Session数据也不是保存在本机了,而是放在了另一个集中存储的地方。这样,无论是哪台Web服务器,也无论修改的是哪个Session的数据,最终的修改都发生在这个集中存储的地方,而Web服务器使用Session数据时,也是从这个集中存储Session数据的地方来读取。对于Session数据存储的具体方式,可以使用数据库,也可以使用其他分布式存储系统。这个方案解决了Session Replication方案中内存的问题,而对于网络带宽,该方案也比Session Replication要好。
不过,该方案仍存在一些问题,包括:
- 读写Session数据引入了网络操作,这相对于本机的数据读取来说,问题就在于存在时延和不稳定性,不过由于通信基本发生在内网,问题不大。
- 如果集中存储Session的机器或者集群存在问题,这就会影响我们的应用。
相对于Session Replication,当Web服务器数量比较大时、Session数比较多的时候,集中存储方案的优势是非常明显的。
对于Cookie Based方案,它对同一个会话的不同请求也是不限制具体处理机器的。与Session Replication和Session数据集中管理的方案不同,这个方案是通过Cookie来传递Session数据的。具体如下图所示。

可以看出,我们的Session数据存放在Cookie中,然后在Web服务器上从Cookie中生成对应的Session数据。这就好比我每次都把自己的碗筷带在身上,这样我去哪家饭店吃饭就可以随意选择了。相对于前面的集中存储,这个方案不会依赖外部的一个存储系统,也就不存在从外部系统获取、写入Session数据的网络时延和不稳定性了。
不过,该方案依然存在不足,包括:
- Cookie长度限制。由于Cookie是有长度限制的,这也会限制Session数据的长度。
- 安全性。Session数据本来都是服务器端数据,而这个方案是让这些服务端数据到了外部外部网络及客户端,因此存在安全性的问题。
- 带宽消耗。这里指的不是内部Web服务器之间的带宽的消耗,而是我们数据中心的整体外部贷款的消耗。
- 性能消耗。每次HTTP请求和响应都带有Session数据,对Web服务器来说,在同样的处理情况下,响应的结果输出越少,支持的并发请求就会越多。
综合而言,上述所有方案都是解决session问题的方案,对于大型网站来说,Session Sticky和Session集中管理是比较好的方案。
在解决分布式系统中负载均衡的问题时候可以使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡的作用。
但是普通的余数hash(hash(比如用户id)%服务器机器数)算法伸缩性很差,当新增或者下线服务器机器时候,用户id与服务器的映射关系会大量失效。一致性hash则利用hash环对其进行了改进。
为了能直观的理解一致性hash原理,这里结合一个简单的例子来讲解,假设有4台服务器,地址为ip1,ip2,ip3,ip4。
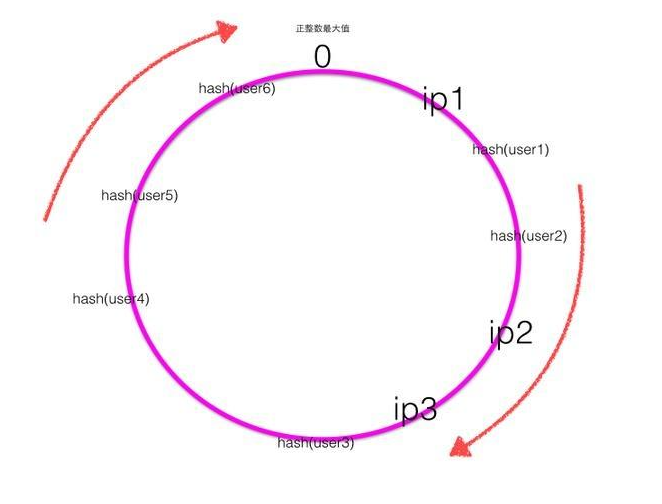
一致性hash是首先计算四个ip地址对应的hash值hash(ip1),hash(ip2),hash(ip3),hash(ip3),计算出来的hash值是0~最大正整数直接的一个值,这四个值在一致性hash环上呈现如下图:
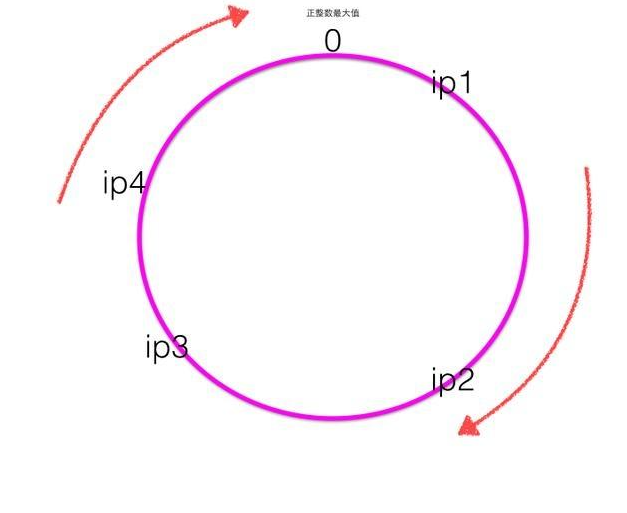
hash环上顺时针从整数0开始,一直到最大正整数,我们根据四个ip计算的hash值肯定会落到这个hash环上的某一个点,至此我们把服务器的四个ip映射到了一致性hash环当用户在客户端进行请求时候,首先根据hash(用户id)计算路由规则(hash值),然后看hash值落到了hash环的那个地方,根据hash值在hash环上的位置顺时针找距离最近的ip作为路由ip.
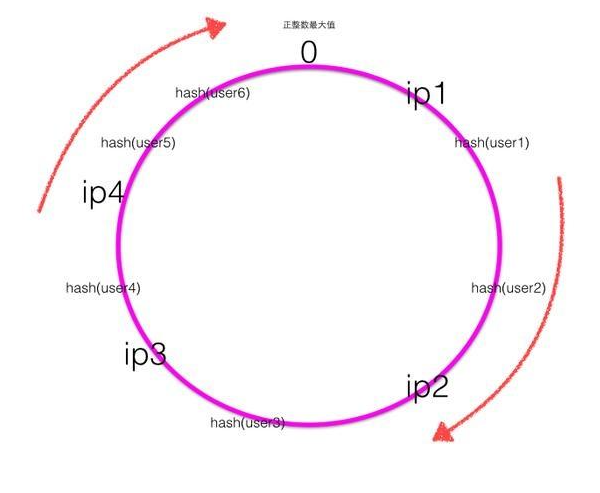
如上图可知user1,user2的请求会落到服务器ip2进行处理,User3的请求会落到服务器ip3进行处理,user4的请求会落到服务器ip4进行处理,user5,user6的请求会落到服务器ip1进行处理。
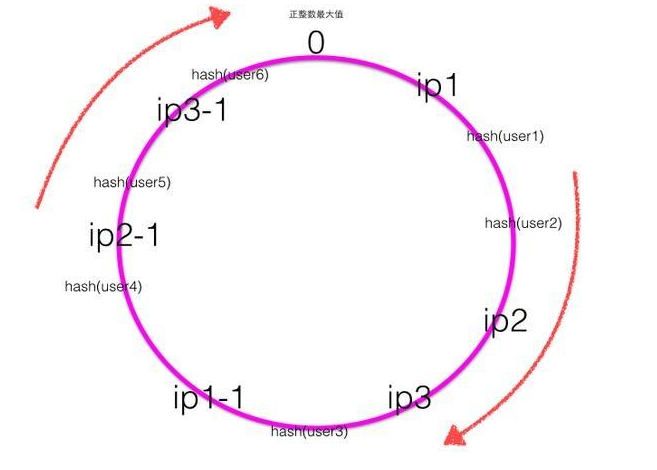
下面考虑当ip2的服务器挂了的时候会出现什么情况?
当ip2的服务器挂了的时候,一致性hash环大致如下图:
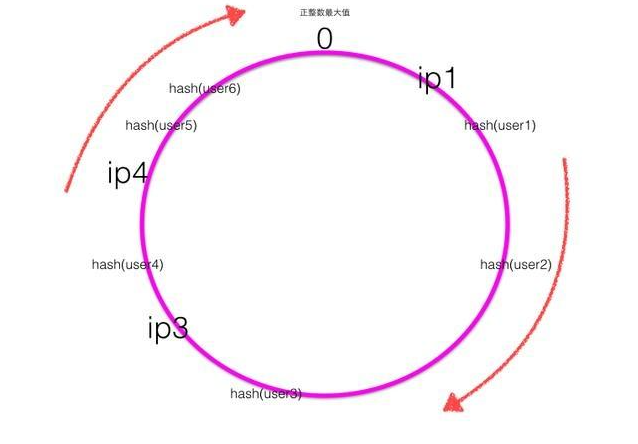
根据顺时针规则可知user1,user2的请求会被服务器ip3进行处理,而其它用户的请求对应的处理服务器不变,也就是只有之前被ip2处理的一部分用户的映射关系被破坏了,并且其负责处理的请求被顺时针下一个节点委托处理。
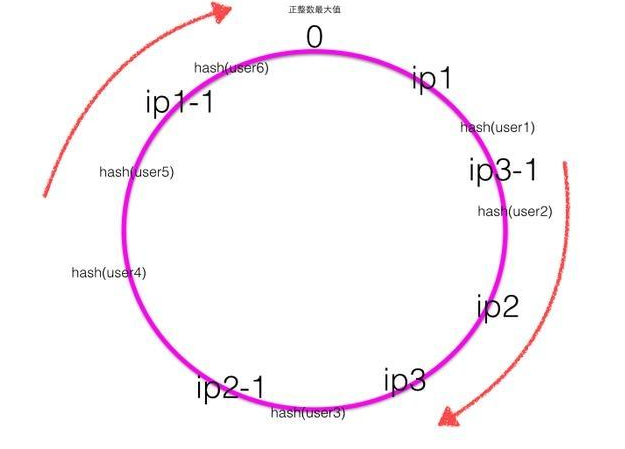
下面考虑当新增机器的时候会出现什么情况?
当新增一个ip5的服务器后,一致性hash环大致如下图:
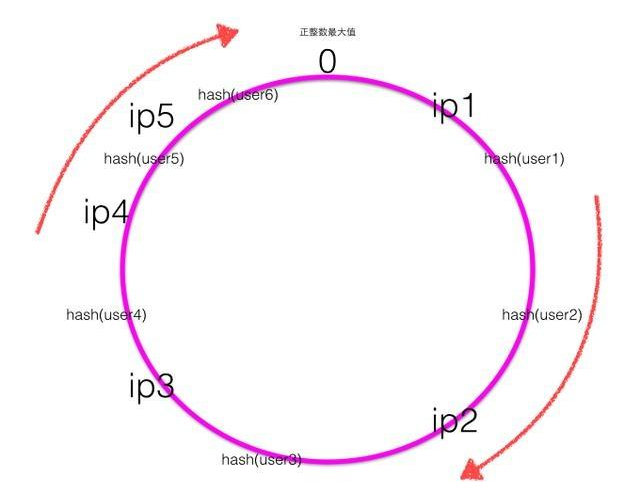
根据顺时针规则可知之前user1的请求应该被ip1服务器处理,现在被新增的ip5服务器处理,其他用户的请求处理服务器不变,也就是新增的服务器顺时针最近的服务器的一部分请求会被新增的服务器所替代。
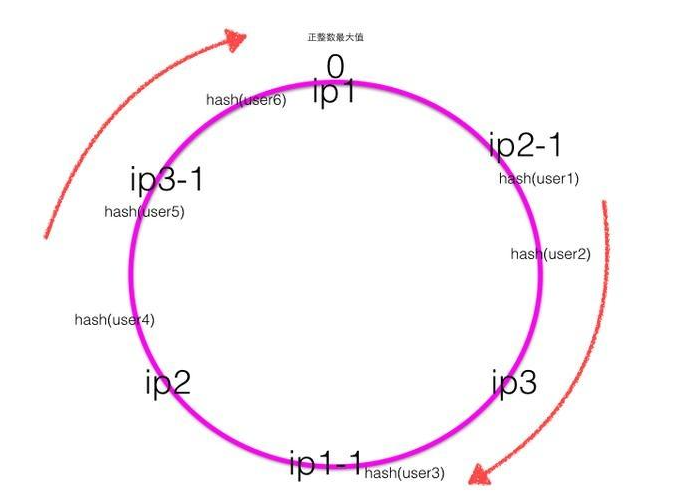
单调性(Monotonicity),单调性是指如果已经有一些请求通过哈希分派到了相应的服务器进行处理,又有新的服务器加入到系统中时候,应保证原有的请求可以被映射到原有的或者新的服务器中去,而不会被映射到原来的其它服务器上去。 这个通过上面新增服务器ip5可以证明,新增ip5后,原来被ip1处理的user6现在还是被ip1处理,原来被ip1处理的user5现在被新增的ip5处理。分散性(Spread):分布式环境中,客户端请求时候可能不知道所有服务器的存在,可能只知道其中一部分服务器,在客户端看来他看到的部分服务器会形成一个完整的hash环。如果多个客户端都把部分服务器作为一个完整hash环,那么可能会导致,同一个用户的请求被路由到不同的服务器进行处理。这种情况显然是应该避免的,因为它不能保证同一个用户的请求落到同一个服务器。所谓分散性是指上述情况发生的严重程度。平衡性(Balance):平衡性也就是说负载均衡,是指客户端hash后的请求应该能够分散到不同的服务器上去。一致性hash可以做到每个服务器都进行处理请求,但是不能保证每个服务器处理的请求的数量大致相同,如下图
服务器ip1,ip2,ip3经过hash后落到了一致性hash环上,从图中hash值分布可知ip1会负责处理大概80%的请求,而ip2和ip3则只会负责处理大概20%的请求,虽然三个机器都在处理请求,但是明显每个机器的负载不均衡,这样称为一致性hash的倾斜,虚拟节点的出现就是为了解决这个问题。
当服务器节点比较少的时候会出现上节所说的一致性hash倾斜的问题,一个解决方法是多加机器,但是加机器是有成本的,那么就加虚拟节点,比如上面三个机器,每个机器引入1个虚拟节点后的一致性hash环的图如下:
其中ip1-1是ip1的虚拟节点,ip2-1是ip2的虚拟节点,ip3-1是ip3的虚拟节点。
可知当物理机器数目为M,虚拟节点为N的时候,实际hash环上节点个数为M*(N+1)。比如当客户端计算的hash值处于ip2和ip3或者处于ip2-1和ip3-1之间时候使用ip3服务器进行处理。
上节我们使用虚拟节点后的图看起来比较均衡,但是如果生成虚拟节点的算法不够好很可能会得到下面的环:
可知每个服务节点引入1个虚拟节点后,情况相比没有引入前均衡性有所改善,但是并不均衡。
均衡的一致性hash应该是如下图:
均匀一致性hash的目标是如果服务器有N台,客户端的hash值有M个,那么每个服务器应该处理大概M/N个用户的。也就是每台服务器负载尽量均衡。dubbo提供的一致性hash负载均衡算法就是不均匀的,我们自己实现了dubbo的spi扩展实现了均匀一致性hash.
在分布式系统中一致性hash起着不可忽略的地位,无论是分布式缓存,还是分布式Rpc框架的负载均衡策略都有所使用。