前言
上篇文章讲到了消息在 Partition 上的存储形式,本来准备接着来聊聊生产中的一些使用方式,想了想还有些很重要的工作组件原理没有讲清楚,比如一个 Topic 由 N 个 Partition 组成,那么这些 Partition 是如何均匀的分布在不同的 Broker 上?再比如当一个 Broker 宕机后,其上负责读写请求的主 Partition 无法正常访问,如何让从 Partition 转变成主 Partition 来继续提供正常的读写服务?想要解决这些问题,就必须先要了解一下 Kafka 集群内部的管理机制,其中一个非常重要的控制器就是 KafkaController。本文我们就来讲讲 KafkaController 是如何来解决上面提到的那些问题的。
- KafkaController 是什么及其选举策略。
- KafkaController 监控 ZK 的目录分布。
- Partition 分布算法。
- Partition 的状态转移。
- Kafka 集群的负载均衡处理流程解析。
Kafka 集群由多台 Broker 构成,每台 Broker 都有一个 KafkaController 用于管理当前的 Broker。试想一下,如果一个集群没有一个“领导者”,那么谁去和“外界”(比如 ZK)沟通呢?谁去协调 Partition 应该如何分布在集群中的不同 Broker 上呢?谁去处理 Broker 宕机后,在其 Broker 上的主 Partition 无法正常提供读写服务后,将对应的从 Partition 转变成主 Partition 继续正常对外提供服务呢?那么由哪个 Broker 的 KafkaController 来担当“领导者”这个角色呢?
Kafka 的设计者很聪明,Zookeeper 既然是分布式应用协调服务,那么干脆就让它来帮 Kafka 集群选举一个“领导者”出来,这个“领导者”对应的 KafkaController 称为 Leader,其他的 KafkaController 被称为 Follower,在同一时刻,一个 Kafka 集群只能有一个 Leader 和 N 个 Follower。
稍微熟悉 Zookeeper 的小伙伴应该都比较清楚,Zookeeper 是通过监控目录(zNode)的变化,从而做出一些相应的动作。
Zookeeper 的目录分为四种,第一种是永久的,被称作为 Persistent;
第二种是顺序且永久的,被称作为 Persistent_Sequential;
第三种是临时的,被称为 Ephemeral;
第四种是顺序且临时的,被称作为 Ephemeral_Sequential。
KafkaController 正是利用了临时的这一特性来完成选主的,在 Broker 启动时,每个 Broker 的 KafkaController 都会向 ZK 的 /controller 目录写入 BrokerId,谁先写入谁就是 Leader,剩余的 KafkaController 是 Follower,当 Leader 在周期内没有向 ZK 发送报告的话,则认为 Leader 挂了,此时 ZK 删除临时的 /controller 目录,Kafka 集群中的其他 KafkaController 开始新的一轮争主操作,流程和上面一样。下面是选 Leader 的流程图。
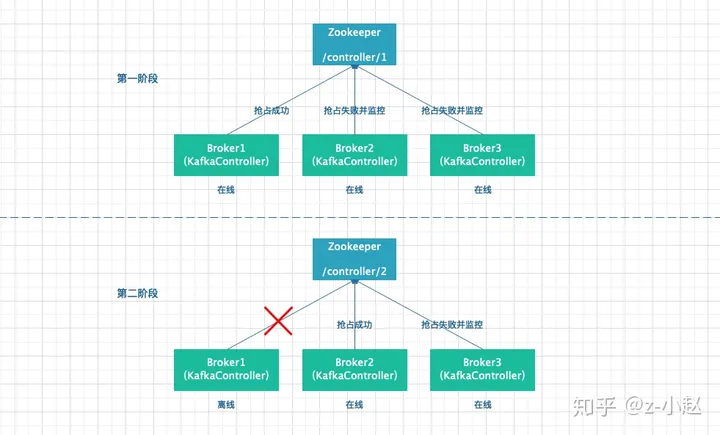
从上图可以看出,第一次,Broker1 成功抢先在 Zookeeper 的 /controller 目录上写入信息,所以 Broker1 的 KafkaController 为 Leader,其他两个为 Follower。第二次,Broker1 宕机或者下线,此时 Broker2 和 Broker3 检测到,于是开始新一轮的争抢将信息写入 Zookeeper,从图中可以看出,Broker2 争到了 Leader,所以 Broker3 是 Follower 状态。
正常情况下,上面这个流程没有问题,但是如果在 Broker1 离线的情况下,Zookeeper 准备删除 /controller 的临时 node 时,系统 hang 住没办法删除,改怎么办呢?这里留个小疑问供大家思考。后面会用一篇文章专门来解答 Kafka 相关的问题(包括面试题哦,敬请期待)。
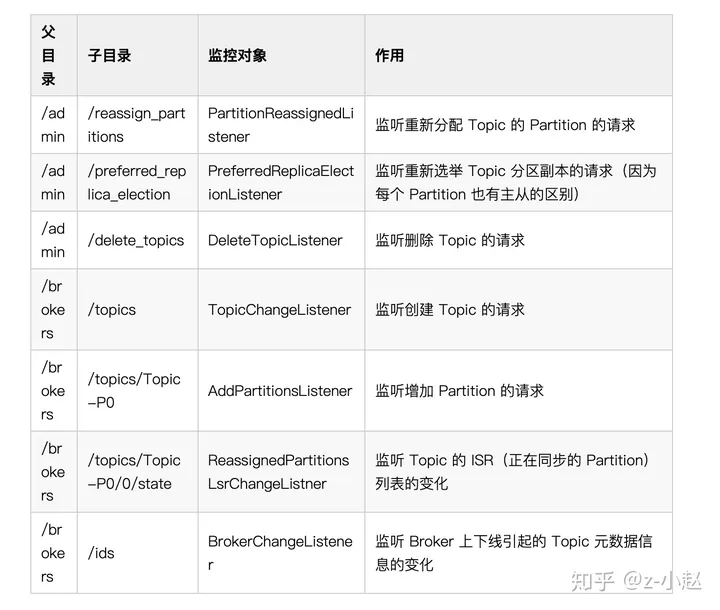
KafkaController 在初始化的时候,会针对不同的 zNode 注册各种各样的监听器,以便处理不同的用户请求或者系统内部变化请求。监控 ZK 的目录大概可以分为两部分,分别是 /admin 目录和 /brokers 目录。各目录及其对应的功能如下表所示,需要的朋友自提。
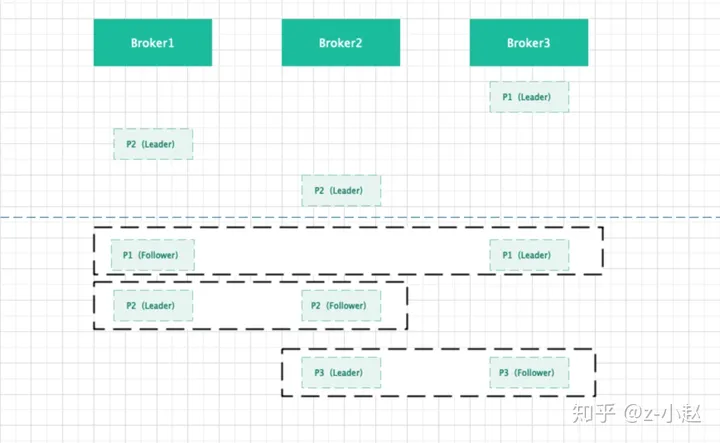
图解:假设集群有 3 个 Broker,Partition 因子为 2。
- 随机选取 Broker 集群中的一个 Broker 节点,然后以轮询的方式将主 Partition 均匀的分布到不同的 Broker 上。
- 主 Partition 分布完成后,将从 Partition 按照 AR 组内顺序以轮询的方式将 Partition 均匀的分布到不同的 Broker 上。
用户针对特定的 Topic 创建了相应的 Partition ,但是这些 Partition 不一定时刻都能够正常工作,所有 Partition 在同一时刻会对应 4 个状态中的某一个;其整个生命周期会经历如下状态的转移,分别是 NonExistentPartition、NewPartition、OnlinePartition、OfflinePartition,其对应的状态转移情况如下图所示。
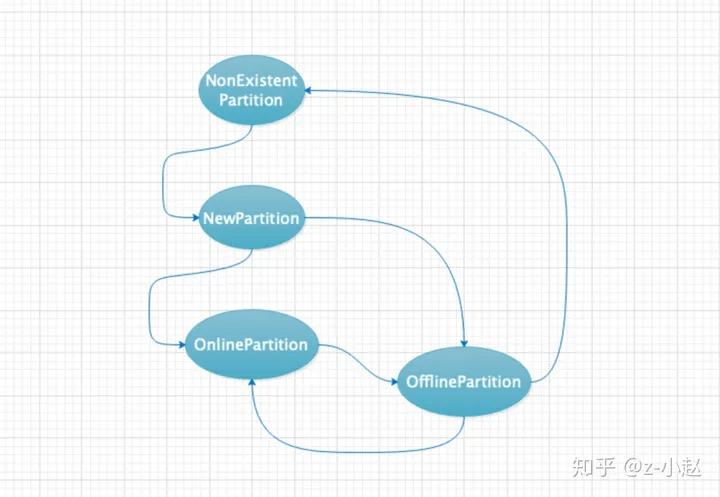
从上图可以看出,Partition 的状态会由前置状态才能够转移到目标状态的,而不是胡乱转移状态的。
NonExistentPartition:代表没有创建 Partition 时的状态,也有可能是离线的 Partition 被删除后的状态。
NewPartition:当 Partition 被创建时,此时只有 AR(Assigned Replica),还没有 ISR(In-Synic Replica),此时还不能接受数据的写入和读取。
OnlinePartition:由 NewPartition 状态转移为 OnlinePartition 状态,此时 Partition 的 Leader 已经被选举出来了,并且也有对应的 ISR 列表等。此时已经可以对外提供读写请求了。
OfflinePartition:当 Partition 对应的 Broker 宕机或者网络异常等问题,由 OnlinePartition 转移到 OfflinePartition,此时的 Partition 已经不能在对外提供读写服务。当 Partition 被彻底删除后状态就转移成 NonExistentPartition,当网络恢复或者 Broker 恢复后,其状态又可以转移到 OnlinePartition,从而继续对外提供读写服务。
前面的文章讲到过,Partition 有 Leader Replica 和 Preferred Replica 两种角色,Leader Replica 负责对外提供读写服务 Preferred Replica 负责同步 Leader Replica 上的数据。现在集群中假设有 3 个 Broker,3 个 Partition,每个 Partition 有 3 个 Replica,当集群运行一段时候后,集群中某些 Broker 宕机,Leader Replica 进行转移,其过程如下图所示。

从上图可以看出,集群运行一段时间后,Broker1 挂掉了,在其上运行的 Partition0 对应的 Leader Replica 转移到了 Broker2 上。假设一段时间后 Broker3 也挂了,则 Broker3 上的 Partition3 对应的 Leader Replica 也转移到了 Broker2 上,集群中只有 Broker2 上的 Partition 在对外提供读写服务,从而造成 Broker2 上的服务压力比较大,之后 Broker1 和 Broker3 恢复后,其上只有 Preferred Replica 做备份操作。
针对以上这种随着时间的推移,集群不在像刚开始时那样平衡,需要通过后台线程将 Leader Replica 重新分配到不同 Broker 上,从而使得读写服务尽量均匀的分布在不同的节点上。
重平衡操作是由 partition-rebalance-thread 后台线程操作的,由于其优先级很低,所以只会在集群空闲的时候才会执行。集群的不平衡的评判标准是由leader.imbalance.per.broker.percentage配置决定的,当集群的不平衡度达到 10%(默认)时,会触发后台线程启动重平衡操作,其具体执行步骤如下:
- 对 Partition 的 AR 列表根据 Preferred Replica 进行分组操作。
- 遍历 Broker,对其上的 Partition 进行处理。
- 统计 Broker 上的 Leader Replica 和 Preferred Replica 不相等的 Partition 个数。
- 统计 Broker 上的 Partition 个数。
- Partition 个数 / 不相等的 Partition 个数,如果大于 10%,则触发重平衡操作;反之,则不做任何处理。
本文主要介绍了 Kafka 集群服务内部的一些工作机制,相信小伙伴们掌握了这部分内容后,对 Broker 服务端的工作流程有了进一步的理解,从而更好的把控整体集群服务。下篇文章我们来正式介绍一下Kafka 常用的命令行操作,敬请期待。
https://blog.csdn.net/cao131502 https://zhuanlan.zhihu.com/p/137811719