diff --git a/ReadMe.md b/ReadMe.md
index dc53ae6..1a6c3a5 100644
--- a/ReadMe.md
+++ b/ReadMe.md
@@ -204,11 +204,11 @@ todo
* [深入理解JVM虚拟机:JNDI,OSGI,Tomcat类加载器实现](docs/java/jvm/深入理解JVM虚拟机:JNDI,OSGI,Tomcat类加载器实现.md)
* [深入了解JVM虚拟机:Java的编译期优化与运行期优化](docs/java/jvm/深入理解JVM虚拟机:Java的编译期优化与运行期优化.md)
* [深入理解JVM虚拟机:JVM监控工具与诊断实践](docs/java/jvm/深入理解JVM虚拟机:JVM监控工具与诊断实践.md)
-* [深入理解JVM虚拟机:JVM常用参数以及调优实践](docs/java/jvm/深入理解JVM虚拟机:JVM常用参数以及调优实践.md)
+* [深入理解JVM虚拟机:JVM常用参数以及调优实践](docs/java/jvm/temp/深入理解JVM虚拟机:JVM常用参数以及调优实践.md)
* [深入理解JVM虚拟机:Java内存异常原理与实践](docs/java/jvm/深入理解JVM虚拟机:Java内存异常原理与实践.md)
* [深入理解JVM虚拟机:JVM性能管理神器VisualVM介绍与实战](docs/java/jvm/深入理解JVM虚拟机:JVM性能管理神器VisualVM介绍与实战.md)
* [深入理解JVM虚拟机:再谈四种引用及GC实践](docs/java/jvm/深入理解JVM虚拟机:再谈四种引用及GC实践.md)
-* [深入理解JVM虚拟机:GC调优思路与常用工具](docs/java/jvm/深入理解JVM虚拟机:GC调优思路与常用工具.md)
+* [深入理解JVM虚拟机:GC调优思路与常用工具](docs/java/jvm/temp/深入理解JVM虚拟机:GC调优思路与常用工具.md)
### Java网络编程
diff --git "a/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\210\357\274\232\347\231\275\350\257\235\350\231\232\346\213\237\345\214\226\346\212\200\346\234\257.md" "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\210\357\274\232\347\231\275\350\257\235\350\231\232\346\213\237\345\214\226\346\212\200\346\234\257.md"
index ec768cb..7896eb0 100644
--- "a/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\210\357\274\232\347\231\275\350\257\235\350\231\232\346\213\237\345\214\226\346\212\200\346\234\257.md"
+++ "b/docs/big-backEnd/\345\220\216\347\253\257\346\212\200\346\234\257\346\235\202\350\260\210\357\274\232\347\231\275\350\257\235\350\231\232\346\213\237\345\214\226\346\212\200\346\234\257.md"
@@ -103,7 +103,7 @@
对于虚拟机内核来讲,只要将标志位设为虚拟机状态,则可以直接在CPU上执行大部分的指令,不需要虚拟化软件在中间转述,除非遇到特别敏感的指令,才需要将标志位设为物理机内核态运行,这样大大提高了效率。
-所以安装虚拟机的时候,务必要将物理CPU的这个标志位打开,是否打开对于Intel可以查看grep "vmx" /proc/cpuinfo,对于AMD可以查看grep "svm" /proc/cpuinfo
+所以安装虚拟机的时候,务必要将物理CPU的这个标志位打开,是否打开对于Intel可以查看grep"vmx" /proc/cpuinfo,对于AMD可以查看grep "svm" /proc/cpuinfo
这叫做硬件辅助虚拟化。
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232Redis \347\232\204\345\237\272\347\241\200\346\225\260\346\215\256\347\273\223\346\236\204\346\246\202\350\247\210.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232Redis \347\232\204\345\237\272\347\241\200\346\225\260\346\215\256\347\273\223\346\236\204\346\246\202\350\247\210.md"
index 9102d4d..9d78bed 100644
--- "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232Redis \347\232\204\345\237\272\347\241\200\346\225\260\346\215\256\347\273\223\346\236\204\346\246\202\350\247\210.md"
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232Redis \347\232\204\345\237\272\347\241\200\346\225\260\346\215\256\347\273\223\346\236\204\346\246\202\350\247\210.md"
@@ -114,7 +114,7 @@ Redis的字典由三个基础的数据结构组成。最底层的单位是哈希
union { void *val; uint64_t u64; int64_t s64; } v; // 指向下个哈希表节点,形成链表
struct dictEntry *next; } dictEntry;
````
-实际上哈希表节点就是一个单项列表的节点。保存了一下下一个节点的指针。 key 就是节点的键,v是这个节点的值。这个 v 既可以是一个指针,也可以是一个 `uint64_t`或者 `int64_t` 整数。*next 指向下一个节点。
+实际上哈希表节点就是一个单项列表的节点。保存了一下下一个节点的指针。 key 就是节点的键,v是这个节点的值。这个 v 既可以是一个指针,也可以是一个`uint64_t`或者`int64_t`整数。*next 指向下一个节点。
通过一个哈希表的数组把各个节点链接起来:
````
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224intset.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224intset.md"
index 95204c4..b8ffc6e 100644
--- "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224intset.md"
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224intset.md"
@@ -84,7 +84,7 @@ typedef struct intset {
* `encoding`: 数据编码,表示intset中的每个数据元素用几个字节来存储。它有三种可能的取值:INTSET_ENC_INT16表示每个元素用2个字节存储,INTSET_ENC_INT32表示每个元素用4个字节存储,INTSET_ENC_INT64表示每个元素用8个字节存储。因此,intset中存储的整数最多只能占用64bit。
* `length`: 表示intset中的元素个数。`encoding`和`length`两个字段构成了intset的头部(header)。
-* `contents`: 是一个柔性数组([flexible array member](https://en.wikipedia.org/wiki/Flexible_array_member)),表示intset的header后面紧跟着数据元素。这个数组的总长度(即总字节数)等于`encoding * length`。柔性数组在Redis的很多数据结构的定义中都出现过(例如[sds](http://zhangtielei.com/posts/blog-redis-sds.html), [quicklist](http://zhangtielei.com/posts/blog-redis-quicklist.html), [skiplist](http://zhangtielei.com/posts/blog-redis-skiplist.html)),用于表达一个偏移量。`contents`需要单独为其分配空间,这部分内存不包含在intset结构当中。
+* `contents`: 是一个柔性数组([flexible array member](https://en.wikipedia.org/wiki/Flexible_array_member)),表示intset的header后面紧跟着数据元素。这个数组的总长度(即总字节数)等于`encoding * length`。柔性数组在Redis的很多数据结构的定义中都出现过(例如[sds](http://zhangtielei.com/posts/blog-redis-sds.html),[quicklist](http://zhangtielei.com/posts/blog-redis-quicklist.html),[skiplist](http://zhangtielei.com/posts/blog-redis-skiplist.html)),用于表达一个偏移量。`contents`需要单独为其分配空间,这部分内存不包含在intset结构当中。
其中需要注意的是,intset可能会随着数据的添加而改变它的数据编码:
@@ -97,7 +97,7 @@ typedef struct intset {
在上图中:
-* 新创建的intset只有一个header,总共8个字节。其中`encoding` = 2, `length` = 0。
+* 新创建的intset只有一个header,总共8个字节。其中`encoding`= 2,`length`= 0。
* 添加13, 5两个元素之后,因为它们是比较小的整数,都能使用2个字节表示,所以`encoding`不变,值还是2。
* 当添加32768的时候,它不再能用2个字节来表示了(2个字节能表达的数据范围是-215~215-1,而32768等于215,超出范围了),因此`encoding`必须升级到INTSET_ENC_INT32(值为4),即用4个字节表示一个元素。
* 在添加每个元素的过程中,intset始终保持从小到大有序。
@@ -247,11 +247,11 @@ intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
* `sadd`用于分别向集合`s1`和`s2`中添加元素。添加的元素既有数字,也有非数字(”a”和”b”)。
* `sismember`用于判断指定的元素是否在集合内存在。
-* `sinter`, `sunion`和`sdiff`分别用于计算集合的交集、并集和差集。
+* `sinter`,`sunion`和`sdiff`分别用于计算集合的交集、并集和差集。
我们前面提到过,set的底层实现,随着元素类型是否是整型以及添加的元素的数目多少,而有所变化。例如,具体到上述命令的执行过程中,集合`s1`的底层数据结构会发生如下变化:
-* 在开始执行完`sadd s1 13 5`之后,由于添加的都是比较小的整数,所以`s1`底层是一个intset,其数据编码`encoding` = 2。
+* 在开始执行完`sadd s1 13 5`之后,由于添加的都是比较小的整数,所以`s1`底层是一个intset,其数据编码`encoding`= 2。
* 在执行完`sadd s1 32768 10 100000`之后,`s1`底层仍然是一个intset,但其数据编码`encoding`从2升级到了4。
* 在执行完`sadd s1 a b`之后,由于添加的元素不再是数字,`s1`底层的实现会转成一个dict。
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224ziplist.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224ziplist.md"
index ea7ce4b..85e3de6 100644
--- "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224ziplist.md"
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232Redis\345\206\205\351\203\250\346\225\260\346\215\256\347\273\223\346\236\204\350\257\246\350\247\243\342\200\224\342\200\224ziplist.md"
@@ -69,7 +69,7 @@ ziplist的数据结构组成是本文要讨论的重点。实际上,ziplist还
* ``: 表示真正存放数据的数据项,长度不定。一个数据项(entry)也有它自己的内部结构,这个稍后再解释。
* ``: ziplist最后1个字节,是一个结束标记,值固定等于255。
-上面的定义中还值得注意的一点是:``, ``, ``既然占据多个字节,那么在存储的时候就有大端(big endian)和小端(little endian)的区别。ziplist采取的是小端模式来存储,这在下面我们介绍具体例子的时候还会再详细解释。
+上面的定义中还值得注意的一点是:``,``,``既然占据多个字节,那么在存储的时候就有大端(big endian)和小端(little endian)的区别。ziplist采取的是小端模式来存储,这在下面我们介绍具体例子的时候还会再详细解释。
我们再来看一下每一个数据项``的构成:
@@ -207,7 +207,7 @@ static unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsig
* 这个函数是在指定的位置p插入一段新的数据,待插入数据的地址指针是s,长度为slen。插入后形成一个新的数据项,占据原来p的配置,原来位于p位置的数据项以及后面的所有数据项,需要统一向后移动,给新插入的数据项留出空间。参数p指向的是ziplist中某一个数据项的起始位置,或者在向尾端插入的时候,它指向ziplist的结束标记``。
* 函数开始先计算出待插入位置前一个数据项的长度`prevlen`。这个长度要存入新插入的数据项的``字段。
-* 然后计算当前数据项占用的总字节数`reqlen`,它包含三部分:``, ``和真正的数据。其中的数据部分会通过调用`zipTryEncoding`先来尝试转成整数。
+* 然后计算当前数据项占用的总字节数`reqlen`,它包含三部分:``,``和真正的数据。其中的数据部分会通过调用`zipTryEncoding`先来尝试转成整数。
* 由于插入导致的ziplist对于内存的新增需求,除了待插入数据项占用的`reqlen`之外,还要考虑原来p位置的数据项(现在要排在待插入数据项之后)的``字段的变化。本来它保存的是前一项的总长度,现在变成了保存当前插入的数据项的总长度。这样它的``字段本身需要的存储空间也可能发生变化,这个变化可能是变大也可能是变小。这个变化了多少的值`nextdiff`,是调用`zipPrevLenByteDiff`计算出来的。如果变大了,`nextdiff`是正值,否则是负值。
* 现在很容易算出来插入后新的ziplist需要多少字节了,然后调用`ziplistResize`来重新调整大小。ziplistResize的实现里会调用allocator的`zrealloc`,它有可能会造成数据拷贝。
* 现在额外的空间有了,接下来就是将原来p位置的数据项以及后面的所有数据都向后挪动,并为它设置新的``字段。此外,还可能需要调整ziplist的``字段。
@@ -223,7 +223,7 @@ hash是Redis中可以用来存储一个对象结构的比较理想的数据类
实际上,hash随着数据的增大,其底层数据结构的实现是会发生变化的,当然存储效率也就不同。在field比较少,各个value值也比较小的时候,hash采用ziplist来实现;而随着field增多和value值增大,hash可能会变成dict来实现。当hash底层变成dict来实现的时候,它的存储效率就没法跟那些序列化方式相比了。
-当我们为某个key第一次执行 `hset key field value` 命令的时候,Redis会创建一个hash结构,这个新创建的hash底层就是一个ziplist。
+当我们为某个key第一次执行`hset key field value`命令的时候,Redis会创建一个hash结构,这个新创建的hash底层就是一个ziplist。
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232Redis\345\210\206\345\270\203\345\274\217\351\224\201\350\277\233\345\214\226\345\217\262.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232Redis\345\210\206\345\270\203\345\274\217\351\224\201\350\277\233\345\214\226\345\217\262.md"
index 628426d..4a2ea7d 100644
--- "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232Redis\345\210\206\345\270\203\345\274\217\351\224\201\350\277\233\345\214\226\345\217\262.md"
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232Redis\345\210\206\345\270\203\345\274\217\351\224\201\350\277\233\345\214\226\345\217\262.md"
@@ -101,7 +101,7 @@ release(){
tryLock(){ SETNX Key 1 Seconds}release(){ DELETE Key}
```
-Redis 2.6.12版本后SETNX增加过期时间参数,这样就解决了两条命令无法保证原子性的问题。但是设想下面一个场景:
+Redis 2.6.12版本后SETNX增加过期时间参数,这样就解决了两条命令无法保证原子性的问题。但是设想下面一个场景:
1\. C1成功获取到了锁,之后C1因为GC进入等待或者未知原因导致任务执行过长,最后在锁失效前C1没有主动释放锁
@@ -167,7 +167,7 @@ release(){
```
-Redis 2.6.12后[SET](https://redis.io/commands/set)同样提供了一个NX参数,等同于SETNX命令,官方文档上提醒后面的版本有可能去掉[SETNX](https://redis.io/commands/setnx), [SETEX](https://redis.io/commands/setex), [PSETEX](https://redis.io/commands/psetex),并用SET命令代替,另外一个优化是使用一个自增的唯一UniqId代替时间戳来规避V3.0提到的时钟问题。
+Redis 2.6.12后[SET](https://redis.io/commands/set)同样提供了一个NX参数,等同于SETNX命令,官方文档上提醒后面的版本有可能去掉[SETNX](https://redis.io/commands/setnx),[SETEX](https://redis.io/commands/setex),[PSETEX](https://redis.io/commands/psetex),并用SET命令代替,另外一个优化是使用一个自增的唯一UniqId代替时间戳来规避V3.0提到的时钟问题。
这个方案是目前最优的分布式锁方案,但是如果在Redis集群环境下依然存在问题:
@@ -175,7 +175,7 @@ Redis 2.6.12后[SET](https://redis.io/commands/set)同样提供了一个NX参数
### 分布式Redis锁:Redlock
-V3.1的版本仅在单实例的场景下是安全的,针对如何实现分布式Redis的锁,国外的分布式专家有过激烈的讨论, antirez提出了分布式锁算法Redlock,在[distlock](https://redis.io/topics/distlock)话题下可以看到对Redlock的详细说明,下面是Redlock算法的一个中文说明(引用)
+V3.1的版本仅在单实例的场景下是安全的,针对如何实现分布式Redis的锁,国外的分布式专家有过激烈的讨论,antirez提出了分布式锁算法Redlock,在[distlock](https://redis.io/topics/distlock)话题下可以看到对Redlock的详细说明,下面是Redlock算法的一个中文说明(引用)
假设有N个独立的Redis节点
diff --git "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232\344\275\277\347\224\250\345\277\253\347\205\247\345\222\214AOF\345\260\206Redis\346\225\260\346\215\256\346\214\201\344\271\205\345\214\226\345\210\260\347\241\254\347\233\230\344\270\255.md" "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232\344\275\277\347\224\250\345\277\253\347\205\247\345\222\214AOF\345\260\206Redis\346\225\260\346\215\256\346\214\201\344\271\205\345\214\226\345\210\260\347\241\254\347\233\230\344\270\255.md"
index 92e1875..b239d06 100644
--- "a/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232\344\275\277\347\224\250\345\277\253\347\205\247\345\222\214AOF\345\260\206Redis\346\225\260\346\215\256\346\214\201\344\271\205\345\214\226\345\210\260\347\241\254\347\233\230\344\270\255.md"
+++ "b/docs/cache/\346\216\242\347\264\242Redis\350\256\276\350\256\241\344\270\216\345\256\236\347\216\260\357\274\232\344\275\277\347\224\250\345\277\253\347\205\247\345\222\214AOF\345\260\206Redis\346\225\260\346\215\256\346\214\201\344\271\205\345\214\226\345\210\260\347\241\254\347\233\230\344\270\255.md"
@@ -39,7 +39,7 @@
```
-Redis给我们提供了两种不同方式的持久化方法:快照(Snapshotting) 和 只追加文件(append-only-file)。
+Redis给我们提供了两种不同方式的持久化方法:快照(Snapshotting)和只追加文件(append-only-file)。
(1)名词简介
@@ -71,17 +71,17 @@ appendonly no #是否使用AOF持久化appendfsync everysec #多久执行一
一、创建快照的方式:
-(1)客户端通过向Redis发送`BGSAVE` 命令来创建快照。
+(1)客户端通过向Redis发送`BGSAVE`命令来创建快照。
使用BGSAVE的时候,Redis会调用fork来创建一个子进程,然后子进程负责将快照写到硬盘中,而父进程则继续处理命令请求。
使用场景:
-如果用户使用了save设置,例如:`save 60 1000` ,那么从Redis最近一次创建快照之后开始计算,当“60秒之内有1000次写入操作”这个条件满足的时候,Redis就会自动触发BGSAVE命令。
+如果用户使用了save设置,例如:`save 60 1000`,那么从Redis最近一次创建快照之后开始计算,当“60秒之内有1000次写入操作”这个条件满足的时候,Redis就会自动触发BGSAVE命令。
如果用户使用了多个save设置,那么当任意一个save配置满足条件的时候,Redis都会触发一次BGSAVE命令。
-(2)客户端通过向Redis发送`SAVE` 命令来创建快照。
+(2)客户端通过向Redis发送`SAVE`命令来创建快照。
接收到SAVE命令的Redis服务器在快照创建完毕之前将不再响应任何其他命令的请求。SAVE命令并不常用,我们通常只在没有足够的内存去执行BGSAVE命令的时候才会使用SAVE命令,或者即使等待持久化操作执行完毕也无所谓的情况下,才会使用这个命令;
@@ -149,7 +149,7 @@ Redis以每秒同步一次AOF文件的性能和不使用任何持久化特性时
三、重写/压缩AOF文件
-随着数据量的增大,AOF的文件可能会很大,这样在每次进行数据恢复的时候就会进行很长的时间,为了解决日益增大的AOF文件,用户可以向Redis发送`BGREWRITEAOF` 命令,这个命令会通过移除AOF文件中的冗余命令来重写AOF文件,是AOF文件的体检变得尽可能的小。
+随着数据量的增大,AOF的文件可能会很大,这样在每次进行数据恢复的时候就会进行很长的时间,为了解决日益增大的AOF文件,用户可以向Redis发送`BGREWRITEAOF`命令,这个命令会通过移除AOF文件中的冗余命令来重写AOF文件,是AOF文件的体检变得尽可能的小。
BGREWRITEAOF的工作原理和BGSAVE的原理很像:Redis会创建一个子进程,然后由子进程负责对AOF文件的重写操作。
@@ -157,7 +157,7 @@ BGREWRITEAOF的工作原理和BGSAVE的原理很像:Redis会创建一个子进
四、触发重写/压缩AOF文件条件设定
-AOF通过设置`auto-aof-rewrite-percentage` 和 `auto-aof-rewrite-min-size` 选项来自动执行BGREWRITEAOF。
+AOF通过设置`auto-aof-rewrite-percentage`和`auto-aof-rewrite-min-size`选项来自动执行BGREWRITEAOF。
其具体含义,通过实例可以看出,如下配置:
@@ -167,7 +167,7 @@ auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb
表示当前AOF的文件体积大于64MB,并且AOF文件的体积比上一次重写之后的体积变大了至少一倍(100%)的时候,Redis将执行重写BGREWRITEAOF命令。
-如果AOF重写执行的过于频繁的话,可以将`auto-aof-rewrite-percentage` 选项的值设置为100以上,这种最偶发就可以让Redis在AOF文件的体积变得更大之后才执行重写操作,不过,这也使得在进行数据恢复的时候执行的时间变得更加长一些。
+如果AOF重写执行的过于频繁的话,可以将`auto-aof-rewrite-percentage`选项的值设置为100以上,这种最偶发就可以让Redis在AOF文件的体积变得更大之后才执行重写操作,不过,这也使得在进行数据恢复的时候执行的时间变得更加长一些。
## 验证快照文件和AOF文件
@@ -179,7 +179,7 @@ redis-check-aofredis-check-dump
他们可以再系统发生故障的时候,检查快照和AOF文件的状态,并对有需要的情况对文件进行修复。
-如果用户在运行redis-check-aof命令的时候,指定了`--fix` 参数,那么程序将对AOF文件进行修复。
+如果用户在运行redis-check-aof命令的时候,指定了`--fix`参数,那么程序将对AOF文件进行修复。
程序修复AOF文件的方法很简单:他会扫描给定的AOF文件,寻找不正确或者不完整的命令,当发现第一个出现错误命令的时候,程序会删除出错命令以及出错命令之后的所有命令,只保留那些位于出错命令之前的正确命令。大部分情况,被删除的都是AOF文件末尾的不完整的写命令。
diff --git "a/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\223\357\274\232MySQL\351\207\214\347\232\204\351\202\243\344\272\233\346\227\245\345\277\227\344\273\254.md" "b/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\223\357\274\232MySQL\351\207\214\347\232\204\351\202\243\344\272\233\346\227\245\345\277\227\344\273\254.md"
index 6f69233..347ecee 100644
--- "a/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\223\357\274\232MySQL\351\207\214\347\232\204\351\202\243\344\272\233\346\227\245\345\277\227\344\273\254.md"
+++ "b/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\223\357\274\232MySQL\351\207\214\347\232\204\351\202\243\344\272\233\346\227\245\345\277\227\344\273\254.md"
@@ -1,15 +1,3 @@
-# 目录
-
-* [目录](#目录)
- * [重新学习MySQL数据库10:MySQL里的那些日志们](#重新学习mysql数据库10:mysql里的那些日志们)
- * [1.MySQL日志文件系统的组成](#1mysql日志文件系统的组成)
- * [2.错误日志](#2错误日志)
- * [3.InnoDB中的日志](#3innodb中的日志)
- * [4- 慢查询日志](#4--慢查询日志)
- * [5.二进制日志](#5二进制日志)
- * [总结](#总结)
-
-
# 目录
* [重新学习MySQL数据库10:MySQL里的那些日志们](#重新学习mysql数据库10:mysql里的那些日志们)
* [1.MySQL日志文件系统的组成](#1mysql日志文件系统的组成)
diff --git "a/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\223\357\274\232Mysql\347\264\242\345\274\225\345\256\236\347\216\260\345\216\237\347\220\206\345\222\214\347\233\270\345\205\263\346\225\260\346\215\256\347\273\223\346\236\204\347\256\227\346\263\225.md" "b/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\223\357\274\232Mysql\347\264\242\345\274\225\345\256\236\347\216\260\345\216\237\347\220\206\345\222\214\347\233\270\345\205\263\346\225\260\346\215\256\347\273\223\346\236\204\347\256\227\346\263\225.md"
index 7bd83de..b522104 100644
--- "a/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\223\357\274\232Mysql\347\264\242\345\274\225\345\256\236\347\216\260\345\216\237\347\220\206\345\222\214\347\233\270\345\205\263\346\225\260\346\215\256\347\273\223\346\236\204\347\256\227\346\263\225.md"
+++ "b/docs/database/\351\207\215\346\226\260\345\255\246\344\271\240MySQL\346\225\260\346\215\256\345\272\223\357\274\232Mysql\347\264\242\345\274\225\345\256\236\347\216\260\345\216\237\347\220\206\345\222\214\347\233\270\345\205\263\346\225\260\346\215\256\347\273\223\346\236\204\347\256\227\346\263\225.md"
@@ -905,4 +905,4 @@ title的选择性不足0.0001(精确值为0.00001579),所以实在没有
[5] Codd, E. F. (1970). "A relational model of data for large shared data banks". Communications of the ACM, , Vol. 13, No. 6, pp. 377-387
-[6] MySQL5.1参考手册 - [http://dev.mysql.com/doc/refman/5.1/zh/index.html](http://dev.mysql.com/doc/refman/5.1/zh/index.html "http://dev.mysql.com/doc/refman/5.1/zh/index.html")
+[6] MySQL5.1参考手册 -[http://dev.mysql.com/doc/refman/5.1/zh/index.html](http://dev.mysql.com/doc/refman/5.1/zh/index.html "http://dev.mysql.com/doc/refman/5.1/zh/index.html")
diff --git "a/docs/distributed/practice/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\257\357\274\232\347\274\223\345\255\230\346\233\264\346\226\260\347\232\204\345\245\227\350\267\257.md" "b/docs/distributed/practice/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\257\357\274\232\347\274\223\345\255\230\346\233\264\346\226\260\347\232\204\345\245\227\350\267\257.md"
index 77fc50a..22c4550 100644
--- "a/docs/distributed/practice/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\257\357\274\232\347\274\223\345\255\230\346\233\264\346\226\260\347\232\204\345\245\227\350\267\257.md"
+++ "b/docs/distributed/practice/\346\220\236\346\207\202\345\210\206\345\270\203\345\274\217\346\212\200\346\234\257\357\274\232\347\274\223\345\255\230\346\233\264\346\226\260\347\232\204\345\245\227\350\267\257.md"
@@ -105,6 +105,6 @@ Write Back套路,一句说就是,在更新数据的时候,只更新缓存
3)在软件开发或设计中,我非常建议在之前先去参考一下已有的设计和思路,**看看相应的guideline,best practice或design pattern,吃透了已有的这些东西,再决定是否要重新发明轮子**。千万不要似是而非地,想当然的做软件设计。
-4)上面,我们没有考虑缓存(Cache)和持久层(Repository)的整体事务的问题。比如,更新Cache成功,更新数据库失败了怎么吗?或是反过来。关于这个事,如果你需要强一致性,你需要使用“两阶段提交协议”——prepare, commit/rollback,比如Java 7 的[XAResource](http://docs.oracle.com/javaee/7/api/javax/transaction/xa/XAResource.html),还有MySQL 5.7的 [XA Transaction](http://dev.mysql.com/doc/refman/5.7/en/xa.html),有些cache也支持XA,比如[EhCache](http://www.ehcache.org/documentation/3.0/xa.html)。当然,XA这样的强一致性的玩法会导致性能下降,关于分布式的事务的相关话题,你可以看看《[分布式系统的事务处理](https://coolshell.cn/articles/10910.html)》一文。
+4)上面,我们没有考虑缓存(Cache)和持久层(Repository)的整体事务的问题。比如,更新Cache成功,更新数据库失败了怎么吗?或是反过来。关于这个事,如果你需要强一致性,你需要使用“两阶段提交协议”——prepare, commit/rollback,比如Java 7 的[XAResource](http://docs.oracle.com/javaee/7/api/javax/transaction/xa/XAResource.html),还有MySQL 5.7的[XA Transaction](http://dev.mysql.com/doc/refman/5.7/en/xa.html),有些cache也支持XA,比如[EhCache](http://www.ehcache.org/documentation/3.0/xa.html)。当然,XA这样的强一致性的玩法会导致性能下降,关于分布式的事务的相关话题,你可以看看《[分布式系统的事务处理](https://coolshell.cn/articles/10910.html)》一文。
(全文完)
diff --git "a/docs/hxx/java/Java\345\267\245\347\250\213\345\270\210\344\277\256\347\202\274\344\271\213\350\267\257\357\274\210\346\240\241\346\213\233\346\200\273\347\273\223\357\274\211.md" "b/docs/hxx/java/Java\345\267\245\347\250\213\345\270\210\344\277\256\347\202\274\344\271\213\350\267\257\357\274\210\346\240\241\346\213\233\346\200\273\347\273\223\357\274\211.md"
index 221cd8f..cd1bd87 100644
--- "a/docs/hxx/java/Java\345\267\245\347\250\213\345\270\210\344\277\256\347\202\274\344\271\213\350\267\257\357\274\210\346\240\241\346\213\233\346\200\273\347\273\223\357\274\211.md"
+++ "b/docs/hxx/java/Java\345\267\245\347\250\213\345\270\210\344\277\256\347\202\274\344\271\213\350\267\257\357\274\210\346\240\241\346\213\233\346\200\273\347\273\223\357\274\211.md"
@@ -173,7 +173,7 @@
具体的面经都比较长,这里大概介绍一下面试的情况,然后我会放上面经的链接供大家查阅。
-**1 阿里面经**
+**1 阿里面经**
[阿里中间件研发面经](http://mp.weixin.qq.com/s?__biz=MzUyMDc5MTYxNA==&mid=2247483852&idx=1&sn=9ec90620478b35d63a4a971a2222095d&chksm=f9e5b29dce923b8b2b080151e4b6b78373ee3f3e6f75b69252fc00b1a009d85c6f96944ed6e6&scene=21#wechat_redirect)
@@ -189,7 +189,7 @@
阿里的面试体验还是比较好的,至少不要求手写算法,但是非常注重Java基础,中间件部门还会特别安排Java基础笔试。
-**2 腾讯面经**
+**2 腾讯面经**
[腾讯研发面经](http://mp.weixin.qq.com/s?__biz=MzUyMDc5MTYxNA==&mid=2247483849&idx=1&sn=f81fd42954589fb2deaf128026ddd856&chksm=f9e5b298ce923b8ef02ae36f7e9029fef0ddb7d5ae456dfa9d64c0073bebaacfb78fac4c8035&scene=21#wechat_redirect)
@@ -201,7 +201,7 @@ SNG的部门捞了我的简历,开始了面试,他们的技术栈主要是Ja
腾讯的面试一如既往地注重考查网络和操作系统,并且喜欢问Linux底层的一些知识,在这方面我还是有很多不足的。
-**3 百度面经**
+**3 百度面经**
[百度研发面经](http://mp.weixin.qq.com/s?__biz=MzUyMDc5MTYxNA==&mid=2247483857&idx=1&sn=214b0f93db93407a7ac5a5149778cbad&chksm=f9e5b280ce923b96fcd535b2ef639fee2de78f12aa961d525b21760b11a3b95c0879113c2944&scene=21#wechat_redirect)
@@ -213,7 +213,7 @@ SNG的部门捞了我的简历,开始了面试,他们的技术栈主要是Ja
百度的面试风格非常统一,每次面试基本都要到电脑上写算法,所以那段时间写算法写的头皮发麻。
-**4 网易面经**
+**4 网易面经**
[网易研发面经](http://mp.weixin.qq.com/s?__biz=MzUyMDc5MTYxNA==&mid=2247483875&idx=1&sn=fa9eaedd9cc3da172ad71d360c46a054&chksm=f9e5b2b2ce923ba443b91d56b24486d22b15bea16a4788e5ed3421906e84f8edd9ee10b2b306&scene=21#wechat_redirect)
@@ -225,7 +225,7 @@ SNG的部门捞了我的简历,开始了面试,他们的技术栈主要是Ja
网易的面试比我想象中的要难,面试官会问的问题都比较深,并且会让你写一些结合实践的代码。
-**5 头条面经**
+**5 头条面经**
[今日头条研发面经](http://mp.weixin.qq.com/s?__biz=MzUyMDc5MTYxNA==&mid=2247483869&idx=1&sn=eedb7aebcb90cf3d4fe2450ef2d99947&chksm=f9e5b28cce923b9a9b0852a1c998ec014eb1aeb0442916c9028da276be8db0b2934c92292961&scene=21#wechat_redirect)
diff --git "a/docs/hxx/java/\344\275\240\344\270\215\345\217\257\351\224\231\350\277\207\347\232\204Java\345\255\246\344\271\240\350\265\204\346\272\220\346\270\205\345\215\225.md" "b/docs/hxx/java/\344\275\240\344\270\215\345\217\257\351\224\231\350\277\207\347\232\204Java\345\255\246\344\271\240\350\265\204\346\272\220\346\270\205\345\215\225.md"
index 0b41820..2885cab 100644
--- "a/docs/hxx/java/\344\275\240\344\270\215\345\217\257\351\224\231\350\277\207\347\232\204Java\345\255\246\344\271\240\350\265\204\346\272\220\346\270\205\345\215\225.md"
+++ "b/docs/hxx/java/\344\275\240\344\270\215\345\217\257\351\224\231\350\277\207\347\232\204Java\345\255\246\344\271\240\350\265\204\346\272\220\346\270\205\345\215\225.md"
@@ -38,25 +38,25 @@ https://blog.csdn.net/a724888
总的来说算是比较全面了,做后端方向的同学可以参考一下。
-深入浅出Java核心技术
+深入浅出Java核心技术
https://blog.csdn.net/column/details/21930.html
本专栏主要介绍Java基础,并且会结合实现原理以及具体实例来讲解。同时还介绍了Java集合类,设计模式以及Java8的相关知识。
-深入理解JVM虚拟机
+深入理解JVM虚拟机
https://blog.csdn.net/column/details/21960.html
带你走进JVM的世界,整合高质量文章以阐述虚拟机的原理及相关技术,让开发者更好地了解Java的底层运行原理以及相应的调优方法。
-Java并发指南
+Java并发指南
https://blog.csdn.net/column/details/21961.html
本专栏主要介绍Java并发编程相关的基本原理以及进阶知识。主要包括Java多线程基础,Java并发编程基本原理以及JUC并发包的使用和源码解析。
-Java网络编程与NIO
+Java网络编程与NIO
https://blog.csdn.net/column/details/21963.html
@@ -64,7 +64,7 @@ Java网络编程一直是很重要的一部分内容,其中涉及了socket的
了解这部分知识对于理解网络编程有很多帮助。另外还补充了两个涉及NIO的重要技术:Tomcat和Netty。
-JavaWeb技术世界
+JavaWeb技术世界
https://blog.csdn.net/column/details/21850.html
@@ -72,7 +72,7 @@ https://blog.csdn.net/column/details/21850.html
我们不仅要了解怎么使用它们,更要去了解它们为什么出现,其中一些技术的实现原理是什么。
-Spring与SpringMVC源码解析
+Spring与SpringMVC源码解析
https://blog.csdn.net/column/details/21851.html
@@ -108,7 +108,7 @@ https://blog.csdn.net/column/details/25481.html
## Java工程师书单
-我之前专门写了一篇文章介绍了Java工程师的书单,可以这里重点列举一些好书,推荐给大家。
+我之前专门写了一篇文章介绍了Java工程师的书单,可以这里重点列举一些好书,推荐给大家。
完整内容可以参考这篇文章:
@@ -126,15 +126,15 @@ Java工程师必备书单
《Java核心技术卷一》 这本书还是比较适合入门的,当然,这种厚皮书要看完还是很有难度的,不过比起上面那本要简单一些
-《深入理解JVM虚拟机》 这本书是Java开发者必须看的书,很多jvm的文章都是提取这本书的内容。JVM是Java虚拟机,赋予了Java程序生命,所以好好看看把,我自己就已经看了三遍了。
+《深入理解JVM虚拟机》 这本书是Java开发者必须看的书,很多jvm的文章都是提取这本书的内容。JVM是Java虚拟机,赋予了Java程序生命,所以好好看看把,我自己就已经看了三遍了。
《Java并发编程艺术》 这本书是国内作者写的Java并发书籍,比上面那一本更简单易懂,适合作为并发编程的入门书籍,当然,学习并发原理之前,还是先把Java的多线程搞懂吧。
-《深入JavaWeb技术内幕》 这本书是Java Web的集大成之作,涵盖了大部分Java Web开发的知识点,不过一本书显然无法把所有细节都讲完,但是作为Java Web的入门或者进阶书籍来看的话还是很不错的。
+《深入JavaWeb技术内幕》 这本书是Java Web的集大成之作,涵盖了大部分Java Web开发的知识点,不过一本书显然无法把所有细节都讲完,但是作为Java Web的入门或者进阶书籍来看的话还是很不错的。
《Redis设计与实现》 该书全面而完整地讲解了 Redis 的内部运行机制,对 Redis 的大多数单机功能以及所有多机功能的实现原理进行了介绍。这本书把Redis的基本原理讲的一清二楚,包括数据结构,持久化,集群等内容,有空应该看看。
-《大型网站技术架构》 这本淘宝系技术指南还是非常值得推崇的,可以说是把大型网站的现代架构进行了一次简单的总结,内容涵盖了各方面,主要讲的是概念,很适合没接触过架构的同学入门。看完以后你会觉得后端技术原来这么博大精深。
+《大型网站技术架构》 这本淘宝系技术指南还是非常值得推崇的,可以说是把大型网站的现代架构进行了一次简单的总结,内容涵盖了各方面,主要讲的是概念,很适合没接触过架构的同学入门。看完以后你会觉得后端技术原来这么博大精深。
《分布式服务框架原理与实践》 上面那本书讲的是分布式架构的实践,而这本书更专注于分布式服务的原理讲解和对应实践,很好地讲述了分布式服务的基本概念,相关技术,以及解决方案等,对于想要学习分布式服务框架的同学来说是本好书。
@@ -176,9 +176,9 @@ https://www.zhihu.com/people/h2pl
## 技术大牛推荐
-1 江南白衣这位大大绝对是我的Java启蒙导师,他推荐的Java后端书架让我受益匪浅。
+1 江南白衣这位大大绝对是我的Java启蒙导师,他推荐的Java后端书架让我受益匪浅。
-2 码农翻身刘欣,一位工作15年的IBM架构师,用最浅显易懂的文章讲解技术的那些事,力荐,他的文章帮我解决了很多困惑。
+2 码农翻身刘欣,一位工作15年的IBM架构师,用最浅显易懂的文章讲解技术的那些事,力荐,他的文章帮我解决了很多困惑。
3 CoolShell陈皓老师的博客相信大家都看过,干货很多,酷壳应该算是国内最有影响力的个人博客了。
diff --git "a/docs/hxx/java/\346\210\221\347\232\204Java\347\247\213\346\213\233\351\235\242\347\273\217\345\244\247\345\220\210\351\233\206.md" "b/docs/hxx/java/\346\210\221\347\232\204Java\347\247\213\346\213\233\351\235\242\347\273\217\345\244\247\345\220\210\351\233\206.md"
index cbe57c4..ca3dce9 100644
--- "a/docs/hxx/java/\346\210\221\347\232\204Java\347\247\213\346\213\233\351\235\242\347\273\217\345\244\247\345\220\210\351\233\206.md"
+++ "b/docs/hxx/java/\346\210\221\347\232\204Java\347\247\213\346\213\233\351\235\242\347\273\217\345\244\247\345\220\210\351\233\206.md"
@@ -1,11 +1,11 @@
# 目录
-* [阿里面经 ](#阿里面经 )
-* [腾讯面经 ](#腾讯面经 )
-* [百度面经 ](#百度面经 )
-* [网易面经 ](#网易面经 )
-* [头条面经 ](#头条面经 )
-* [快手&拼多多面经 ](#快手拼多多面经 )
+* [阿里面经](#阿里面经)
+* [腾讯面经](#腾讯面经)
+* [百度面经](#百度面经)
+* [网易面经](#网易面经)
+* [头条面经](#头条面经)
+* [快手&拼多多面经](#快手拼多多面经)
* [京东&美团面经](#京东美团面经)
* [斗鱼面经](#斗鱼面经)
* [有赞面经](#有赞面经)
@@ -20,7 +20,7 @@

-# 阿里面经
+# 阿里面经
[阿里中间件研发面经](http://mp.weixin.qq.com/s?__biz=MzUyMDc5MTYxNA==&mid=2247483852&idx=1&sn=9ec90620478b35d63a4a971a2222095d&chksm=f9e5b29dce923b8b2b080151e4b6b78373ee3f3e6f75b69252fc00b1a009d85c6f96944ed6e6&scene=21#wechat_redirect)
@@ -36,7 +36,7 @@
阿里的面试体验还是比较好的,至少不要求手写算法,但是非常注重Java基础,中间件部门还会特别安排Java基础笔试。
-# 腾讯面经
+# 腾讯面经
[腾讯研发面经](http://mp.weixin.qq.com/s?__biz=MzUyMDc5MTYxNA==&mid=2247483849&idx=1&sn=f81fd42954589fb2deaf128026ddd856&chksm=f9e5b298ce923b8ef02ae36f7e9029fef0ddb7d5ae456dfa9d64c0073bebaacfb78fac4c8035&scene=21#wechat_redirect)
@@ -48,7 +48,7 @@ SNG的部门捞了我的简历,开始了面试,他们的技术栈主要是Ja
腾讯的面试一如既往地注重考查网络和操作系统,并且喜欢问Linux底层的一些知识,在这方面我还是有很多不足的。
-# 百度面经
+# 百度面经
[百度研发面经](http://mp.weixin.qq.com/s?__biz=MzUyMDc5MTYxNA==&mid=2247483857&idx=1&sn=214b0f93db93407a7ac5a5149778cbad&chksm=f9e5b280ce923b96fcd535b2ef639fee2de78f12aa961d525b21760b11a3b95c0879113c2944&scene=21#wechat_redirect)
@@ -60,7 +60,7 @@ SNG的部门捞了我的简历,开始了面试,他们的技术栈主要是Ja
百度的面试风格非常统一,每次面试基本都要到电脑上写算法,所以那段时间写算法写的头皮发麻。
-# 网易面经
+# 网易面经
[网易研发面经](http://mp.weixin.qq.com/s?__biz=MzUyMDc5MTYxNA==&mid=2247483875&idx=1&sn=fa9eaedd9cc3da172ad71d360c46a054&chksm=f9e5b2b2ce923ba443b91d56b24486d22b15bea16a4788e5ed3421906e84f8edd9ee10b2b306&scene=21#wechat_redirect)
@@ -72,7 +72,7 @@ SNG的部门捞了我的简历,开始了面试,他们的技术栈主要是Ja
网易的面试比我想象中的要难,面试官会问的问题都比较深,并且会让你写一些结合实践的代码。
-# 头条面经
+# 头条面经
[今日头条研发面经](http://mp.weixin.qq.com/s?__biz=MzUyMDc5MTYxNA==&mid=2247483869&idx=1&sn=eedb7aebcb90cf3d4fe2450ef2d99947&chksm=f9e5b28cce923b9a9b0852a1c998ec014eb1aeb0442916c9028da276be8db0b2934c92292961&scene=21#wechat_redirect)
@@ -82,7 +82,7 @@ SNG的部门捞了我的简历,开始了面试,他们的技术栈主要是Ja
然后就开始了一下午的视频面试,一共三轮技术面试,每一轮都要写代码,问问题的风格有点像腾讯,也喜欢问一些底层知识,让我有点懵逼。
-# 快手&拼多多面经
+# 快手&拼多多面经
[拼多多&快手研发面经](http://mp.weixin.qq.com/s?__biz=MzUyMDc5MTYxNA==&mid=2247483878&idx=1&sn=aaafff4b1171361ccd1d94708d2beaa0&chksm=f9e5b2b7ce923ba10140dff71dd3a0f9a20593434a32cec66929116bba196dc7496abf502884&scene=21#wechat_redirect)
diff --git "a/docs/hxx/\347\224\265\345\255\220\344\271\246.md" "b/docs/hxx/\347\224\265\345\255\220\344\271\246.md"
index b80bf2e..5908230 100644
--- "a/docs/hxx/\347\224\265\345\255\220\344\271\246.md"
+++ "b/docs/hxx/\347\224\265\345\255\220\344\271\246.md"
@@ -45,7 +45,7 @@
### 新手上路
- [用大白话告诉你 :Java 后端到底是在做什么?](http://mp.weixin.qq.com/s?__biz=MzUyOTk5NDQwOA==&mid=2247485885&idx=1&sn=0b3e02d09559ad0fe371ce915a77d7e0&chksm=fa59ce7acd2e476c501ca68b311de5abaf8021c5baa96fa24e0ca621acaaf4b1c64e2e16f3cb&scene=21#wechat_redirect)
+[用大白话告诉你 :Java 后端到底是在做什么?](http://mp.weixin.qq.com/s?__biz=MzUyOTk5NDQwOA==&mid=2247485885&idx=1&sn=0b3e02d09559ad0fe371ce915a77d7e0&chksm=fa59ce7acd2e476c501ca68b311de5abaf8021c5baa96fa24e0ca621acaaf4b1c64e2e16f3cb&scene=21#wechat_redirect)
[Java工程师学习指南(入门篇)](http://mp.weixin.qq.com/s?__biz=MzUyOTk5NDQwOA==&mid=2247484573&idx=2&sn=7baf8dfe36357264ab25010429644792&chksm=fa59c35acd2e4a4c24c5b55003136b6b8c5e778273714093b2df7a016d3bb0ed0c774573a7a4&scene=21#wechat_redirect)
@@ -198,15 +198,15 @@
[马云退隐前,在年会上说了最重要的三件事](http://mp.weixin.qq.com/s?__biz=MzUyOTk5NDQwOA==&mid=2247486268&idx=1&sn=dd13517634cd4f72f824278f93edebef&chksm=fa59ccfbcd2e45ed522c377ab3fa4554632f36c836e9b2e1490fb4748f4c0cdee9a4a99c91a6&scene=21#wechat_redirect)
- [那些拼命加班的程序员们,后来都怎么样了?](http://mp.weixin.qq.com/s?__biz=MzUyOTk5NDQwOA==&mid=2247485861&idx=1&sn=e90ac488593b4b7adb4ac46303e715be&chksm=fa59ce62cd2e477410c26233ed6518e34fdd772e27ea7538bddfac36a549a50cab29b27881f4&scene=21#wechat_redirect)
+[那些拼命加班的程序员们,后来都怎么样了?](http://mp.weixin.qq.com/s?__biz=MzUyOTk5NDQwOA==&mid=2247485861&idx=1&sn=e90ac488593b4b7adb4ac46303e715be&chksm=fa59ce62cd2e477410c26233ed6518e34fdd772e27ea7538bddfac36a549a50cab29b27881f4&scene=21#wechat_redirect)
- [互联网浪潮之下,聊聊 90 后所面临的困境](http://mp.weixin.qq.com/s?__biz=MzUyOTk5NDQwOA==&mid=2247485843&idx=1&sn=492c9d3f7c9e32de9da7d833013cb9b9&chksm=fa59ce54cd2e4742939a5eb42a470bf282dbc79cb6f38ac9ec0112af5282091a9f2cd3615104&scene=21#wechat_redirect)
+[互联网浪潮之下,聊聊 90 后所面临的困境](http://mp.weixin.qq.com/s?__biz=MzUyOTk5NDQwOA==&mid=2247485843&idx=1&sn=492c9d3f7c9e32de9da7d833013cb9b9&chksm=fa59ce54cd2e4742939a5eb42a470bf282dbc79cb6f38ac9ec0112af5282091a9f2cd3615104&scene=21#wechat_redirect)
- [程序员的工资到底花到哪里去了?](http://mp.weixin.qq.com/s?__biz=MzUyOTk5NDQwOA==&mid=2247485826&idx=1&sn=cc13da981115341666ae919dd2646cb4&chksm=fa59ce45cd2e475344776b1f7f52a6d281d96210e21229c5d2f300cfad585f712b636cf60427&scene=21#wechat_redirect)
+[程序员的工资到底花到哪里去了?](http://mp.weixin.qq.com/s?__biz=MzUyOTk5NDQwOA==&mid=2247485826&idx=1&sn=cc13da981115341666ae919dd2646cb4&chksm=fa59ce45cd2e475344776b1f7f52a6d281d96210e21229c5d2f300cfad585f712b636cf60427&scene=21#wechat_redirect)
- [互联网公司里都有哪些潜规则?](http://mp.weixin.qq.com/s?__biz=MzUyOTk5NDQwOA==&mid=2247485819&idx=1&sn=816e20fa37a2abd99fa714c1c13e0402&chksm=fa59cebccd2e47aa8572071dadbb301008cd425cf0de4d71978af82b44bd3554faacfa8ad462&scene=21#wechat_redirect)
+[互联网公司里都有哪些潜规则?](http://mp.weixin.qq.com/s?__biz=MzUyOTk5NDQwOA==&mid=2247485819&idx=1&sn=816e20fa37a2abd99fa714c1c13e0402&chksm=fa59cebccd2e47aa8572071dadbb301008cd425cf0de4d71978af82b44bd3554faacfa8ad462&scene=21#wechat_redirect)
- [大厂程序员的一天是如何度过的?](http://mp.weixin.qq.com/s?__biz=MzUyOTk5NDQwOA==&mid=2247485803&idx=1&sn=5814daaa71fb164d33d858311708f1c3&chksm=fa59ceaccd2e47baf573c73fcefbdc93e74becd8b9d4c533cf79404a3f90b2b6cdb46eee4e40&scene=21#wechat_redirect)
+[大厂程序员的一天是如何度过的?](http://mp.weixin.qq.com/s?__biz=MzUyOTk5NDQwOA==&mid=2247485803&idx=1&sn=5814daaa71fb164d33d858311708f1c3&chksm=fa59ceaccd2e47baf573c73fcefbdc93e74becd8b9d4c533cf79404a3f90b2b6cdb46eee4e40&scene=21#wechat_redirect)
### 职场心得:
diff --git "a/docs/java-web/springMVC/SpringMVC\346\272\220\347\240\201\345\210\206\346\236\220\357\274\232DispatcherServlet\347\232\204\345\210\235\345\247\213\345\214\226\344\270\216\350\257\267\346\261\202\350\275\254\345\217\221.md" "b/docs/java-web/springMVC/SpringMVC\346\272\220\347\240\201\345\210\206\346\236\220\357\274\232DispatcherServlet\347\232\204\345\210\235\345\247\213\345\214\226\344\270\216\350\257\267\346\261\202\350\275\254\345\217\221.md"
index df95f75..6390f87 100644
--- "a/docs/java-web/springMVC/SpringMVC\346\272\220\347\240\201\345\210\206\346\236\220\357\274\232DispatcherServlet\347\232\204\345\210\235\345\247\213\345\214\226\344\270\216\350\257\267\346\261\202\350\275\254\345\217\221.md"
+++ "b/docs/java-web/springMVC/SpringMVC\346\272\220\347\240\201\345\210\206\346\236\220\357\274\232DispatcherServlet\347\232\204\345\210\235\345\247\213\345\214\226\344\270\216\350\257\267\346\261\202\350\275\254\345\217\221.md"
@@ -160,12 +160,12 @@ initFrameworkServlet()方法是一个没有任何实现的空方法,除去一
this.webApplicationContext = initWebApplicationContext();
```
-这一句简单直白的代码,道破了FrameworkServlet这个类,在SpringMVC类体系中的设计目的,它是 用来抽离出建立 WebApplicationContext 上下文这个过程的。
+这一句简单直白的代码,道破了FrameworkServlet这个类,在SpringMVC类体系中的设计目的,它是用来抽离出建立WebApplicationContext上下文这个过程的。
initWebApplicationContext()方法,封装了建立Spring容器上下文的整个过程,方法内的逻辑如下:
1. 获取由ContextLoaderListener初始化并注册在ServletContext中的根上下文,记为rootContext
-2. 如果webApplicationContext已经不为空,表示这个Servlet类是通过编程式注册到容器中的(Servlet 3.0+中的ServletContext.addServlet() ),上下文也由编程式传入。若这个传入的上下文还没被初始化,将rootContext上下文设置为它的父上下文,然后将其初始化,否则直接使用。
+2. 如果webApplicationContext已经不为空,表示这个Servlet类是通过编程式注册到容器中的(Servlet 3.0+中的ServletContext.addServlet()),上下文也由编程式传入。若这个传入的上下文还没被初始化,将rootContext上下文设置为它的父上下文,然后将其初始化,否则直接使用。
3. 通过wac变量的引用是否为null,判断第2步中是否已经完成上下文的设置(即上下文是否已经用编程式方式传入),如果wac==null成立,说明该Servlet不是由编程式注册到容器中的。此时以contextAttribute属性的值为键,在ServletContext中查找上下文,查找得到,说明上下文已经以别的方式初始化并注册在contextAttribute下,直接使用。
4. 检查wac变量的引用是否为null,如果wac==null成立,说明2、3两步中的上下文初始化策略都没成功,此时调用createWebApplicationContext(rootContext),建立一个全新的以rootContext为父上下文的上下文,作为SpringMVC配置元素的容器上下文。大多数情况下我们所使用的上下文,就是这个新建的上下文。
5. 以上三种初始化上下文的策略,都会回调onRefresh(ApplicationContext context)方法(回调的方式根据不同策略有不同),onRefresh方法在DispatcherServlet类中被覆写,以上面得到的上下文为依托,完成SpringMVC中默认实现类的初始化。
diff --git "a/docs/java-web/springMVC/SpringMVC\346\272\220\347\240\201\345\210\206\346\236\220\357\274\232SpringMVC\350\256\276\350\256\241\347\220\206\345\277\265\344\270\216DispatcherServlet.md" "b/docs/java-web/springMVC/SpringMVC\346\272\220\347\240\201\345\210\206\346\236\220\357\274\232SpringMVC\350\256\276\350\256\241\347\220\206\345\277\265\344\270\216DispatcherServlet.md"
index 665ed2f..a33c502 100644
--- "a/docs/java-web/springMVC/SpringMVC\346\272\220\347\240\201\345\210\206\346\236\220\357\274\232SpringMVC\350\256\276\350\256\241\347\220\206\345\277\265\344\270\216DispatcherServlet.md"
+++ "b/docs/java-web/springMVC/SpringMVC\346\272\220\347\240\201\345\210\206\346\236\220\357\274\232SpringMVC\350\256\276\350\256\241\347\220\206\345\277\265\344\270\216DispatcherServlet.md"
@@ -106,7 +106,7 @@ HandlerExecutionChain getHandler(HttpServletRequest request) throws Exception;
}
```
-是的,第一步处理就这么简单的完成了。一个web请求经过处理后,会得到一个HandlerExecutionChain对象,这就是SpringMVC对URl映射给出的回答。需要留意的是,HandlerMapping接口的getHandler方法参数是HttpServletRequest,这意味着,HandlerMapping的实现类可以利用HttpServletRequest中的 所有信息来做出这个HandlerExecutionChain对象的生成”决策“。这包括,请求头、url路径、cookie、session、参数等等一切你从一个web请求中可以得到的任何东西(最常用的是url路径)。
+是的,第一步处理就这么简单的完成了。一个web请求经过处理后,会得到一个HandlerExecutionChain对象,这就是SpringMVC对URl映射给出的回答。需要留意的是,HandlerMapping接口的getHandler方法参数是HttpServletRequest,这意味着,HandlerMapping的实现类可以利用HttpServletRequest中的所有信息来做出这个HandlerExecutionChain对象的生成”决策“。这包括,请求头、url路径、cookie、session、参数等等一切你从一个web请求中可以得到的任何东西(最常用的是url路径)。
SpirngMVC的第一个扩展点,就出现在这里。我们可以编写任意的HandlerMapping实现类,依据任何策略来决定一个web请求到HandlerExecutionChain对象的生成。可以说,从第一个核心接口的声明开始,SpringMVC就把自己的灵活性和野心暴露无疑:哥玩的就是”Open-Closed“。
diff --git "a/docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\214\357\274\232Mybatis\345\205\245\351\227\250.md" "b/docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\214\357\274\232Mybatis\345\205\245\351\227\250.md"
index 77b8926..fa50a2b 100644
--- "a/docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\214\357\274\232Mybatis\345\205\245\351\227\250.md"
+++ "b/docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\214\357\274\232Mybatis\345\205\245\351\227\250.md"
@@ -252,7 +252,7 @@ Mybatis通过执行器与Mappered Statement的结合实现与数据库的交互
## 测试工程搭建
-1. 新建maven工程
+1.新建maven工程
diff --git "a/docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\214\357\274\232\344\273\216\346\211\213\345\212\250\347\274\226\350\257\221\346\211\223\345\214\205\345\210\260\351\241\271\347\233\256\346\236\204\345\273\272\345\267\245\345\205\267Maven.md" "b/docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\214\357\274\232\344\273\216\346\211\213\345\212\250\347\274\226\350\257\221\346\211\223\345\214\205\345\210\260\351\241\271\347\233\256\346\236\204\345\273\272\345\267\245\345\205\267Maven.md"
index d04ef0d..7f80e4f 100644
--- "a/docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\214\357\274\232\344\273\216\346\211\213\345\212\250\347\274\226\350\257\221\346\211\223\345\214\205\345\210\260\351\241\271\347\233\256\346\236\204\345\273\272\345\267\245\345\205\267Maven.md"
+++ "b/docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\214\357\274\232\344\273\216\346\211\213\345\212\250\347\274\226\350\257\221\346\211\223\345\214\205\345\210\260\351\241\271\347\233\256\346\236\204\345\273\272\345\267\245\345\205\267Maven.md"
@@ -90,7 +90,7 @@ Maven不仅是构建工具,还是一个依赖管理工具和项目管理工具
[](http://upload-images.jianshu.io/upload_images/5811881-7482108a7ff71031.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240 "image.png")
-三:最后设置一下环境变量,将Maven安装配置到操作系统环境中,主要就是配置M2_HOME 和PATH两项,如图
+三:最后设置一下环境变量,将Maven安装配置到操作系统环境中,主要就是配置M2_HOME和PATH两项,如图
[](http://upload-images.jianshu.io/upload_images/5811881-ffdf167e64415703.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240 "image.png")
都搞定后,验证一下,打开doc输入 mvn -v如何得到下面信息就说明配置成功了
@@ -187,7 +187,7 @@ name元素生命了一个对于用户更为友好的项目名称,虽然这不
依赖范围就是用来控制依赖和三种classpath(编译classpath,测试classpath、运行classpath)的关系,Maven有如下几种依赖范围:
* compile:编译依赖范围。如果没有指定,就会默认使用该依赖范围。使用此依赖范围的Maven依赖,对于编译、测试、运行三种classpath都有效。典型的例子是spring-code,在编译、测试和运行的时候都需要使用该依赖。
-* test: 测试依赖范围。使用次依赖范围的Maven依赖,只对于测试classpath有效,在编译主代码或者运行项目的使用时将无法使用此依赖。典型的例子是Jnuit,它只有在编译测试代码及运行测试的时候才需要。
+* test:测试依赖范围。使用次依赖范围的Maven依赖,只对于测试classpath有效,在编译主代码或者运行项目的使用时将无法使用此依赖。典型的例子是Jnuit,它只有在编译测试代码及运行测试的时候才需要。
* provided:已提供依赖范围。使用此依赖范围的Maven依赖,对于编译和测试classpath有效,但在运行时候无效。典型的例子是servlet-api,编译和测试项目的时候需要该依赖,但在运行项目的时候,由于容器以及提供,就不需要Maven重复地引入一遍。
* runtime:运行时依赖范围。使用此依赖范围的Maven依赖,对于测试和运行classpath有效,但在编译主代码时无效。典型的例子是JDBC驱动实现,项目主代码的编译只需要JDK提供的JDBC接口,只有在执行测试或者运行项目的时候才需要实现上述接口的具体JDBC驱动。
* system:系统依赖范围。该依赖与三种classpath的关系,和provided依赖范围完全一致,但是,使用system范围的依赖时必须通过systemPath元素显示地指定依赖文件的路径。由于此类依赖不是通过Maven仓库解析的,而且往往与本机系统绑定,可能构成构建的不可移植,因此应该谨慎使用。systemPath元素可以引用环境变量,如:
diff --git "a/docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\214\357\274\232\346\236\201\347\256\200\351\205\215\347\275\256\347\232\204SpringBoot.md" "b/docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\214\357\274\232\346\236\201\347\256\200\351\205\215\347\275\256\347\232\204SpringBoot.md"
index 8384ba1..adaa923 100644
--- "a/docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\214\357\274\232\346\236\201\347\256\200\351\205\215\347\275\256\347\232\204SpringBoot.md"
+++ "b/docs/java-web/\350\265\260\350\277\233JavaWeb\346\212\200\346\234\257\344\270\226\347\225\214\357\274\232\346\236\201\347\256\200\351\205\215\347\275\256\347\232\204SpringBoot.md"
@@ -120,7 +120,7 @@ public class HelloController {
@RequestMapping("/hello") public String hello() { return "Hello Spring Boot!"; }}
```
-* **@RestController 注解:** 该注解是 @Controller 和 @ResponseBody 注解的合体版
+* **@RestController 注解:**该注解是 @Controller 和 @ResponseBody 注解的合体版
#### 第三步:利用 IDEA 启动 Spring Boot
@@ -163,7 +163,7 @@ public class HelloController {
org.springframework.boot spring-boot-maven-plugin
```
-我们可以看到一个比较陌生一些的标签 `` ,这个标签是在配置 Spring Boot 的父级依赖:
+我们可以看到一个比较陌生一些的标签``,这个标签是在配置 Spring Boot 的父级依赖:
```
@@ -176,12 +176,12 @@ public class HelloController {
#### 应用入口类
-Spring Boot 项目通常有一个名为 *Application 的入口类,入口类里有一个 main 方法, **这个 main 方法其实就是一个标准的 Javay 应用的入口方法。**
+Spring Boot 项目通常有一个名为 *Application 的入口类,入口类里有一个 main 方法,**这个 main 方法其实就是一个标准的 Javay 应用的入口方法。**
-**@SpringBootApplication** 是 Spring Boot 的核心注解,它是一个组合注解,该注解组合了:**@Configuration、@EnableAutoConfiguration、@ComponentScan;** 若不是用 @SpringBootApplication 注解也可以使用这三个注解代替。
+**@SpringBootApplication**是 Spring Boot 的核心注解,它是一个组合注解,该注解组合了:**@Configuration、@EnableAutoConfiguration、@ComponentScan;**若不是用 @SpringBootApplication 注解也可以使用这三个注解代替。
* 其中,**@EnableAutoConfiguration 让 Spring Boot 根据类路径中的 jar 包依赖为当前项目进行自动配置**,例如,添加了 spring-boot-starter-web 依赖,会自动添加 Tomcat 和 Spring MVC 的依赖,那么 Spring Boot 会对 Tomcat 和 Spring MVC 进行自动配置。
-* **Spring Boot 还会自动扫描 @SpringBootApplication 所在类的同级包以及下级包里的 Bean** ,所以入口类建议就配置在 grounpID + arctifactID 组合的包名下(这里为 cn.wmyskxz.springboot 包)
+* **Spring Boot 还会自动扫描 @SpringBootApplication 所在类的同级包以及下级包里的 Bean**,所以入口类建议就配置在 grounpID + arctifactID 组合的包名下(这里为 cn.wmyskxz.springboot 包)
#### Spring Boot 的配置文件
@@ -209,7 +209,7 @@ Spring Boot 的全局配置文件的作用是对一些默认配置的配置值

-* **注意:** 我们并没有在 yml 文件中注明属性的类型,而是在使用的时候定义的。
+* **注意:**我们并没有在 yml 文件中注明属性的类型,而是在使用的时候定义的。
你也可以在配置文件中使用当前配置:
@@ -219,7 +219,7 @@ Spring Boot 的全局配置文件的作用是对一些默认配置的配置值
-* **问题:** 这样写配置文件繁琐而且可能会造成类的臃肿,因为有许许多多的 @Value 注解。
+* **问题:**这样写配置文件繁琐而且可能会造成类的臃肿,因为有许许多多的 @Value 注解。
> * 封装配置信息
diff --git "a/docs/java/basic/javac\345\222\214javap.md" "b/docs/java/basic/javac\345\222\214javap.md"
index 5f85010..f797af7 100644
--- "a/docs/java/basic/javac\345\222\214javap.md"
+++ "b/docs/java/basic/javac\345\222\214javap.md"
@@ -18,14 +18,7 @@
* [-encoding](#-encoding)
* [-verbose](#-verbose)
* [其他命令](#其他命令)
- * [使用javac构建项目](#使用javac构建项目)
- * [](#)
-* [java文件列表目录](#java文件列表目录)
- * [放入列表文件中](#放入列表文件中)
- * [生成bin目录](#生成bin目录)
- * [列表](#列表)
- * [通过-cp指定所有的引用jar包,将src下的所有java文件进行编译](#通过-cp指定所有的引用jar包,将src下的所有java文件进行编译)
- * [通过-cp指定所有的引用jar包,指定入口函数运行](#通过-cp指定所有的引用jar包,指定入口函数运行)
+ * [使用javac构建项目](#使用javac构建项目)
* [javap 的使用](#javap-的使用)
* [参考文章](#参考文章)
diff --git "a/docs/java/basic/\344\273\243\347\240\201\345\235\227\345\222\214\344\273\243\347\240\201\346\211\247\350\241\214\351\241\272\345\272\217.md" "b/docs/java/basic/\344\273\243\347\240\201\345\235\227\345\222\214\344\273\243\347\240\201\346\211\247\350\241\214\351\241\272\345\272\217.md"
index 2e51bc0..7ebb784 100644
--- "a/docs/java/basic/\344\273\243\347\240\201\345\235\227\345\222\214\344\273\243\347\240\201\346\211\247\350\241\214\351\241\272\345\272\217.md"
+++ "b/docs/java/basic/\344\273\243\347\240\201\345\235\227\345\222\214\344\273\243\347\240\201\346\211\247\350\241\214\351\241\272\345\272\217.md"
@@ -38,7 +38,7 @@
## Java中的构造方法
### 构造方法简介
-构造方法是类的一种特殊方法,用来初始化类的一个新的对象。[Java](http://c.biancheng.net/java/) 中的每个类都有一个默认的构造方法,它必须具有和类名相同的名称,而且没有返回类型。构造方法的默认返回类型就是对象类型本身,并且构造方法不能被 static、final、synchronized、abstract 和 native 修饰。
+构造方法是类的一种特殊方法,用来初始化类的一个新的对象。[Java](http://c.biancheng.net/java/)中的每个类都有一个默认的构造方法,它必须具有和类名相同的名称,而且没有返回类型。构造方法的默认返回类型就是对象类型本身,并且构造方法不能被 static、final、synchronized、abstract 和 native 修饰。
提示:构造方法用于初始化一个新对象,所以用 static 修饰没有意义;构造方法不能被子类继承,所以用 final 和 abstract 修饰没有意义;多个线程不会同时创建内存地址相同的同一个对象,所以用 synchronized 修饰没有必要。
diff --git "a/docs/java/basic/\345\244\232\347\272\277\347\250\213.md" "b/docs/java/basic/\345\244\232\347\272\277\347\250\213.md"
index e40b5d0..35e3ada 100644
--- "a/docs/java/basic/\345\244\232\347\272\277\347\250\213.md"
+++ "b/docs/java/basic/\345\244\232\347\272\277\347\250\213.md"
@@ -80,7 +80,7 @@ Java 给多线程编程提供了内置的支持。 一条线程指的是进程
* **新建状态:**
- 使用 **new** 关键字和 **Thread** 类或其子类建立一个线程对象后,该线程对象就处于新建状态。它保持这个状态直到程序 **start()** 这个线程。
+ 使用**new**关键字和**Thread**类或其子类建立一个线程对象后,该线程对象就处于新建状态。它保持这个状态直到程序**start()**这个线程。
* **就绪状态:**
@@ -88,7 +88,7 @@ Java 给多线程编程提供了内置的支持。 一条线程指的是进程
* **运行状态:**
- 如果就绪状态的线程获取 CPU 资源,就可以执行 **run()**,此时线程便处于运行状态。处于运行状态的线程最为复杂,它可以变为阻塞状态、就绪状态和死亡状态。
+ 如果就绪状态的线程获取 CPU 资源,就可以执行**run()**,此时线程便处于运行状态。处于运行状态的线程最为复杂,它可以变为阻塞状态、就绪状态和死亡状态。
* **阻塞状态:**
diff --git "a/docs/java/basic/\350\247\243\350\257\273Java\344\270\255\347\232\204\345\233\236\350\260\203.md" "b/docs/java/basic/\350\247\243\350\257\273Java\344\270\255\347\232\204\345\233\236\350\260\203.md"
index 8a672ed..57e5237 100644
--- "a/docs/java/basic/\350\247\243\350\257\273Java\344\270\255\347\232\204\345\233\236\350\260\203.md"
+++ "b/docs/java/basic/\350\247\243\350\257\273Java\344\270\255\347\232\204\345\233\236\350\260\203.md"
@@ -3,9 +3,8 @@
* [多线程中的“回调”](#多线程中的回调)
* [Java回调机制实战](#java回调机制实战)
* [实例一 : 同步调用](#实例一-:-同步调用)
- * [1.1 同步调用代码](#11-同步调用代码)
- * [实例二:由浅入深](#实例二:由浅入深)
- * [实例三:Tom做题](#实例三:tom做题)
+ * [实例二:由浅入深](#实例二:由浅入深)
+ * [实例三:Tom做题](#实例三:tom做题)
* [参考文章](#参考文章)
diff --git "a/docs/java/collection/Java\351\233\206\345\220\210\350\257\246\350\247\243\357\274\232Iterator\357\274\214fail-fast\346\234\272\345\210\266\344\270\216\346\257\224\350\276\203\345\231\250.md" "b/docs/java/collection/Java\351\233\206\345\220\210\350\257\246\350\247\243\357\274\232Iterator\357\274\214fail-fast\346\234\272\345\210\266\344\270\216\346\257\224\350\276\203\345\231\250.md"
index c89b6ae..95169c6 100644
--- "a/docs/java/collection/Java\351\233\206\345\220\210\350\257\246\350\247\243\357\274\232Iterator\357\274\214fail-fast\346\234\272\345\210\266\344\270\216\346\257\224\350\276\203\345\231\250.md"
+++ "b/docs/java/collection/Java\351\233\206\345\220\210\350\257\246\350\247\243\357\274\232Iterator\357\274\214fail-fast\346\234\272\345\210\266\344\270\216\346\257\224\350\276\203\345\231\250.md"
@@ -6,12 +6,12 @@
* [fail-fast示例](#fail-fast示例)
* [fail-fast产生原因](#fail-fast产生原因)
* [fail-fast解决办法](#fail-fast解决办法)
-* [Comparable 和 Comparator](#comparable-和-comparator)
- * [Comparable](#comparable)
- * [Comparator](#comparator)
- * [Java8中使用lambda实现比较器](#java8中使用lambda实现比较器)
- * [总结](#总结)
- * [参考文章](#参考文章)
+ * [Comparable 和 Comparator](#comparable-和-comparator)
+ * [Comparable](#comparable)
+ * [Comparator](#comparator)
+ * [Java8中使用lambda实现比较器](#java8中使用lambda实现比较器)
+ * [总结](#总结)
+ * [参考文章](#参考文章)
本文参考 cmsblogs.com/p=1185
diff --git "a/docs/java/collection/Java\351\233\206\345\220\210\350\257\246\350\247\243\357\274\232\344\270\200\346\226\207\350\257\273\346\207\202ArrayList,Vector\344\270\216Stack\344\275\277\347\224\250\346\226\271\346\263\225\345\222\214\345\256\236\347\216\260\345\216\237\347\220\206.md" "b/docs/java/collection/Java\351\233\206\345\220\210\350\257\246\350\247\243\357\274\232\344\270\200\346\226\207\350\257\273\346\207\202ArrayList,Vector\344\270\216Stack\344\275\277\347\224\250\346\226\271\346\263\225\345\222\214\345\256\236\347\216\260\345\216\237\347\220\206.md"
index e228969..ed04968 100644
--- "a/docs/java/collection/Java\351\233\206\345\220\210\350\257\246\350\247\243\357\274\232\344\270\200\346\226\207\350\257\273\346\207\202ArrayList,Vector\344\270\216Stack\344\275\277\347\224\250\346\226\271\346\263\225\345\222\214\345\256\236\347\216\260\345\216\237\347\220\206.md"
+++ "b/docs/java/collection/Java\351\233\206\345\220\210\350\257\246\350\247\243\357\274\232\344\270\200\346\226\207\350\257\273\346\207\202ArrayList,Vector\344\270\216Stack\344\275\277\347\224\250\346\226\271\346\263\225\345\222\214\345\256\236\347\216\260\345\216\237\347\220\206.md"
@@ -13,9 +13,8 @@
* [初始容量和扩容](#初始容量和扩容)
* [线程安全](#线程安全-1)
* [Stack](#stack)
-* [Stack](#stack-1)
- * [三个集合类之间的区别](#三个集合类之间的区别)
- * [参考文章](#参考文章)
+ * [三个集合类之间的区别](#三个集合类之间的区别)
+ * [参考文章](#参考文章)
本文参考多篇优质技术博客,参考文章请在文末查看
@@ -464,11 +463,11 @@ vector大部分方法都使用了synchronized修饰符,所以他是线层安
# Stack
- 如果我们去查jdk的文档,我们会发现stack是在java.util这个包里。它对应的一个大致的类关系图如下:
+ 如果我们去查jdk的文档,我们会发现stack是在java.util这个包里。它对应的一个大致的类关系图如下:

- 通过继承Vector类,Stack类可以很容易的实现他本身的功能。因为大部分的功能在Vector里面已经提供支持了。
+ 通过继承Vector类,Stack类可以很容易的实现他本身的功能。因为大部分的功能在Vector里面已经提供支持了。
在Java中Stack类表示后进先出(LIFO)的对象堆栈。栈是一种非常常见的数据结构,它采用典型的先进后出的操作方式完成的。
diff --git "a/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232AQS\344\270\255\347\232\204\345\205\254\345\271\263\351\224\201\344\270\216\351\235\236\345\205\254\345\271\263\351\224\201\357\274\214Condtion.md" "b/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232AQS\344\270\255\347\232\204\345\205\254\345\271\263\351\224\201\344\270\216\351\235\236\345\205\254\345\271\263\351\224\201\357\274\214Condtion.md"
index 7cacaae..eb10601 100644
--- "a/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232AQS\344\270\255\347\232\204\345\205\254\345\271\263\351\224\201\344\270\216\351\235\236\345\205\254\345\271\263\351\224\201\357\274\214Condtion.md"
+++ "b/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232AQS\344\270\255\347\232\204\345\205\254\345\271\263\351\224\201\344\270\216\351\235\236\345\205\254\345\271\263\351\224\201\357\274\214Condtion.md"
@@ -8,8 +8,8 @@
* [5\. 唤醒后检查中断状态](#5-唤醒后检查中断状态)
* [6\. 获取独占锁](#6-获取独占锁)
* [7\. 处理中断状态](#7-处理中断状态)
- * [* 带超时机制的 await](#-带超时机制的-await)
- * [* 不抛出 InterruptedException 的 await](#-不抛出-interruptedexception-的-await)
+ * [带超时机制的 await](#-带超时机制的-await)
+ * [不抛出 InterruptedException 的 await](#-不抛出-interruptedexception-的-await)
* [AbstractQueuedSynchronizer 独占锁的取消排队](#abstractqueuedsynchronizer-独占锁的取消排队)
* [再说 java 线程中断和 InterruptedException 异常](#再说-java-线程中断和-interruptedexception-异常)
* [线程中断](#线程中断)
diff --git "a/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232ForkJoin\345\271\266\345\217\221\346\241\206\346\236\266\344\270\216\345\267\245\344\275\234\347\252\203\345\217\226\347\256\227\346\263\225\345\211\226\346\236\220.md" "b/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232ForkJoin\345\271\266\345\217\221\346\241\206\346\236\266\344\270\216\345\267\245\344\275\234\347\252\203\345\217\226\347\256\227\346\263\225\345\211\226\346\236\220.md"
index ca072a2..74fa6a0 100644
--- "a/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232ForkJoin\345\271\266\345\217\221\346\241\206\346\236\266\344\270\216\345\267\245\344\275\234\347\252\203\345\217\226\347\256\227\346\263\225\345\211\226\346\236\220.md"
+++ "b/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232ForkJoin\345\271\266\345\217\221\346\241\206\346\236\266\344\270\216\345\267\245\344\275\234\347\252\203\345\217\226\347\256\227\346\263\225\345\211\226\346\236\220.md"
@@ -27,7 +27,7 @@ Fork/Join框架是Java7提供的一个用于并行执行任务的框架, 是
## 简介
-通常,使用Java来开发一个简单的并发应用程序时,会创建一些**Runnable**对象,然后创建对应的**Thread** 对象来控制程序中这些线程的创建、执行以及线程的状态。自从Java 5开始引入了**Executor**和**ExecutorService**接口以及实现这两个接口的类(比如**ThreadPoolExecutor**)之后,使得Java在并发支持上得到了进一步的提升。
+通常,使用Java来开发一个简单的并发应用程序时,会创建一些**Runnable**对象,然后创建对应的**Thread**对象来控制程序中这些线程的创建、执行以及线程的状态。自从Java 5开始引入了**Executor**和**ExecutorService**接口以及实现这两个接口的类(比如**ThreadPoolExecutor**)之后,使得Java在并发支持上得到了进一步的提升。
**执行器框架(Executor Framework)**将任务的创建和执行进行了分离,通过这个框架,只需要实现**Runnable**接口的对象和使用**Executor**对象,然后将**Runnable**对象发送给执行器。执行器再负责运行这些任务所需要的线程,包括线程的创建,线程的管理以及线程的结束。
@@ -37,7 +37,7 @@ Fork/Join框架是Java7提供的一个用于并行执行任务的框架, 是
-没有固定的公式来决定问题的**参考大小(Reference Size)**,从而决定一个任务是需要进行拆分或不需要拆分,拆分与否仍是依赖于任务本身的特性。可以使用在任务中将要处理的元素的数目和任务执行所需要的时间来决定参考大小。测试不同的参考大小来决定解决问题最好的一个方案,将**ForkJoinPool**类看作一个特殊的 **Executor** 执行器类型。这个框架基于以下两种操作。
+没有固定的公式来决定问题的**参考大小(Reference Size)**,从而决定一个任务是需要进行拆分或不需要拆分,拆分与否仍是依赖于任务本身的特性。可以使用在任务中将要处理的元素的数目和任务执行所需要的时间来决定参考大小。测试不同的参考大小来决定解决问题最好的一个方案,将**ForkJoinPool**类看作一个特殊的**Executor**执行器类型。这个框架基于以下两种操作。
* **分解(Fork)**操作:当需要将一个任务拆分成更小的多个任务时,在框架中执行这些任务;
* **合并(Join)**操作:当一个主任务等待其创建的多个子任务的完成执行。
@@ -46,7 +46,7 @@ Fork/Join框架是Java7提供的一个用于并行执行任务的框架, 是
为了达到这个目标,通过**Fork/Join框架**执行的任务有以下限制。
-* 任务只能使用**fork()**和**join()** 操作当作同步机制。如果使用其他的同步机制,工作者线程就不能执行其他任务,当然这些任务是在同步操作里时。比如,如果在**Fork/Join 框架**中将一个任务休眠,正在执行这个任务的工作者线程在休眠期内不能执行另一个任务。
+* 任务只能使用**fork()**和**join()**操作当作同步机制。如果使用其他的同步机制,工作者线程就不能执行其他任务,当然这些任务是在同步操作里时。比如,如果在**Fork/Join 框架**中将一个任务休眠,正在执行这个任务的工作者线程在休眠期内不能执行另一个任务。
* 任务不能执行I/O操作,比如文件数据的读取与写入。
* 任务不能抛出非运行时异常(Checked Exception),必须在代码中处理掉这些异常。
diff --git "a/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232JMM\344\270\255\347\232\204final\345\205\263\351\224\256\345\255\227\350\247\243\346\236\220.md" "b/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232JMM\344\270\255\347\232\204final\345\205\263\351\224\256\345\255\227\350\247\243\346\236\220.md"
index 2d825d4..f7fe31b 100644
--- "a/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232JMM\344\270\255\347\232\204final\345\205\263\351\224\256\345\255\227\350\247\243\346\236\220.md"
+++ "b/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232JMM\344\270\255\347\232\204final\345\205\263\351\224\256\345\255\227\350\247\243\346\236\220.md"
@@ -1,3 +1,12 @@
+# Table of Contents
+
+ * [一、properly constructed / this对象逸出](#一、properly-constructed--this对象逸出)
+ * [二、对象的安全发布](#二、对象的安全发布)
+ * [三、 final 关键字的内存语义](#三、-final-关键字的内存语义)
+ * [四、HotSpot VM中对final内存语义的实现](#四、hotspot-vm中对final内存语义的实现)
+* [参考文献](#参考文献)
+
+
**本文转载自互联网,侵删**
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
@@ -215,4 +224,4 @@ JSR 133 (Java Memory Model) FAQ
Java Concurrency in Practice
The JSR-133 Cookbook for Compiler Writers
-Intel® 64 and IA-32 ArchitecturesvSoftware Developer’s Manual Volume 3A: System Programming Guide, Part 1
\ No newline at end of file
+Intel® 64 and IA-32 ArchitecturesvSoftware Developer’s Manual Volume 3A: System Programming Guide, Part 1
diff --git "a/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232Java\344\270\255\347\232\204HashMap\345\222\214ConcurrentHashMap\345\205\250\350\247\243\346\236\220.md" "b/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232Java\344\270\255\347\232\204HashMap\345\222\214ConcurrentHashMap\345\205\250\350\247\243\346\236\220.md"
index 6314e77..dff6cc3 100644
--- "a/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232Java\344\270\255\347\232\204HashMap\345\222\214ConcurrentHashMap\345\205\250\350\247\243\346\236\220.md"
+++ "b/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232Java\344\270\255\347\232\204HashMap\345\222\214ConcurrentHashMap\345\205\250\350\247\243\346\236\220.md"
@@ -345,7 +345,7 @@ public V put(K key, V value) {
第一层皮很简单,根据 hash 值很快就能找到相应的 Segment,之后就是 Segment 内部的 put 操作了。
-Segment 内部是由 **数组+链表** 组成的。
+Segment 内部是由**数组+链表**组成的。
```
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
@@ -640,11 +640,11 @@ public V get(Object key) {
## Java8 HashMap
-Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由 **数组+链表+红黑树** 组成。
+Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由**数组+链表+红黑树**组成。
-根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为 **O(n)**。
+根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为**O(n)**。
-为了降低这部分的开销,在 Java8 中,当链表中的元素达到了 8 个时,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 **O(logN)**。
+为了降低这部分的开销,在 Java8 中,当链表中的元素达到了 8 个时,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为**O(logN)**。
来一张图简单示意一下吧:
@@ -654,7 +654,7 @@ Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑
下面,我们还是用代码来介绍吧,个人感觉,Java8 的源码可读性要差一些,不过精简一些。
-Java7 中使用 Entry 来代表每个 HashMap 中的数据节点,Java8 中使用 **Node**,基本没有区别,都是 key,value,hash 和 next 这四个属性,不过,Node 只能用于链表的情况,红黑树的情况需要使用 **TreeNode**。
+Java7 中使用 Entry 来代表每个 HashMap 中的数据节点,Java8 中使用**Node**,基本没有区别,都是 key,value,hash 和 next 这四个属性,不过,Node 只能用于链表的情况,红黑树的情况需要使用**TreeNode**。
我们根据数组元素中,第一个节点数据类型是 Node 还是 TreeNode 来判断该位置下是链表还是红黑树的。
@@ -1145,7 +1145,7 @@ private final void tryPresize(int size) {
这个方法的核心在于 sizeCtl 值的操作,首先将其设置为一个负数,然后执行 transfer(tab, null),再下一个循环将 sizeCtl 加 1,并执行 transfer(tab, nt),之后可能是继续 sizeCtl 加 1,并执行 transfer(tab, nt)。
-所以,可能的操作就是执行 **1 次 transfer(tab, null) + 多次 transfer(tab, nt)**,这里怎么结束循环的需要看完 transfer 源码才清楚。
+所以,可能的操作就是执行**1 次 transfer(tab, null) + 多次 transfer(tab, nt)**,这里怎么结束循环的需要看完 transfer 源码才清楚。
#### 数据迁移:transfer
diff --git "a/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232Java\350\257\273\345\206\231\351\224\201ReentrantReadWriteLock\346\272\220\347\240\201\345\210\206\346\236\220.md" "b/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232Java\350\257\273\345\206\231\351\224\201ReentrantReadWriteLock\346\272\220\347\240\201\345\210\206\346\236\220.md"
index 50c20d6..a357d88 100644
--- "a/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232Java\350\257\273\345\206\231\351\224\201ReentrantReadWriteLock\346\272\220\347\240\201\345\210\206\346\236\220.md"
+++ "b/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232Java\350\257\273\345\206\231\351\224\201ReentrantReadWriteLock\346\272\220\347\240\201\345\210\206\346\236\220.md"
@@ -91,7 +91,7 @@ ReentrantReadWriteLock 分为读锁和写锁两个实例,读锁是共享锁,
很清楚了,ReadLock 和 WriteLock 中的方法都是通过 Sync 这个类来实现的。Sync 是 AQS 的子类,然后再派生了公平模式和不公平模式。
-从它们调用的 Sync 方法,我们可以看到: **ReadLock 使用了共享模式,WriteLock 使用了独占模式**。
+从它们调用的 Sync 方法,我们可以看到:**ReadLock 使用了共享模式,WriteLock 使用了独占模式**。
等等,**同一个 AQS 实例怎么可以同时使用共享模式和独占模式**???
@@ -99,7 +99,7 @@ ReentrantReadWriteLock 分为读锁和写锁两个实例,读锁是共享锁,

-AQS 的精髓在于内部的属性 **state**:
+AQS 的精髓在于内部的属性**state**:
1. 对于独占模式来说,通常就是 0 代表可获取锁,1 代表锁被别人获取了,重入例外
2. 而共享模式下,每个线程都可以对 state 进行加减操作
@@ -168,9 +168,9 @@ abstract static class Sync extends AbstractQueuedSynchronizer {
1. state 的高 16 位代表读锁的获取次数,包括重入次数,获取到读锁一次加 1,释放掉读锁一次减 1
2. state 的低 16 位代表写锁的获取次数,因为写锁是独占锁,同时只能被一个线程获得,所以它代表重入次数
-3. 每个线程都需要维护自己的 HoldCounter,记录该线程获取的读锁次数,这样才能知道到底是不是读锁重入,用 ThreadLocal 属性 **readHolds** 维护
-4. **cachedHoldCounter** 有什么用?其实没什么用,但能提示性能。将最后一次获取读锁的线程的 HoldCounter 缓存到这里,这样比使用 ThreadLocal 性能要好一些,因为 ThreadLocal 内部是基于 map 来查询的。但是 cachedHoldCounter 这一个属性毕竟只能缓存一个线程,所以它要起提升性能作用的依据就是:通常读锁的获取紧随着就是该读锁的释放。我这里可能表达不太好,但是大家应该是懂的吧。
-5. **firstReader** 和 **firstReaderHoldCount** 有什么用?其实也没什么用,但是它也能提示性能。将"第一个"获取读锁的线程记录在 firstReader 属性中,这里的**第一个**不是全局的概念,等这个 firstReader 当前代表的线程释放掉读锁以后,会有后来的线程占用这个属性的。**firstReader 和 firstReaderHoldCount 使得在读锁不产生竞争的情况下,记录读锁重入次数非常方便快速**
+3. 每个线程都需要维护自己的 HoldCounter,记录该线程获取的读锁次数,这样才能知道到底是不是读锁重入,用 ThreadLocal 属性**readHolds**维护
+4. **cachedHoldCounter**有什么用?其实没什么用,但能提示性能。将最后一次获取读锁的线程的 HoldCounter 缓存到这里,这样比使用 ThreadLocal 性能要好一些,因为 ThreadLocal 内部是基于 map 来查询的。但是 cachedHoldCounter 这一个属性毕竟只能缓存一个线程,所以它要起提升性能作用的依据就是:通常读锁的获取紧随着就是该读锁的释放。我这里可能表达不太好,但是大家应该是懂的吧。
+5. **firstReader**和**firstReaderHoldCount**有什么用?其实也没什么用,但是它也能提示性能。将"第一个"获取读锁的线程记录在 firstReader 属性中,这里的**第一个**不是全局的概念,等这个 firstReader 当前代表的线程释放掉读锁以后,会有后来的线程占用这个属性的。**firstReader 和 firstReaderHoldCount 使得在读锁不产生竞争的情况下,记录读锁重入次数非常方便快速**
6. 如果一个线程使用了 firstReader,那么它就不需要占用 cachedHoldCounter
7. 个人认为,读写锁源码中最让初学者头疼的就是这几个用于提升性能的属性了,使得大家看得云里雾里的。主要是因为 ThreadLocal 内部是通过一个 ThreadLocalMap 来操作的,会增加检索时间。而很多场景下,执行 unlock 的线程往往就是刚刚最后一次执行 lock 的线程,中间可能没有其他线程进行 lock。还有就是很多不怎么会发生读锁竞争的场景。
@@ -498,7 +498,7 @@ protected final boolean tryAcquire(int acquires) {
}
```
-下面看一眼 **writerShouldBlock()** 的判定,然后你再回去看一篇写锁获取过程。
+下面看一眼**writerShouldBlock()**的判定,然后你再回去看一篇写锁获取过程。
```
static final class NonfairSync extends Sync {
diff --git "a/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232\345\271\266\345\217\221\344\270\211\345\244\247\351\227\256\351\242\230\344\270\216volatile\345\205\263\351\224\256\345\255\227\357\274\214CAS\346\223\215\344\275\234.md" "b/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232\345\271\266\345\217\221\344\270\211\345\244\247\351\227\256\351\242\230\344\270\216volatile\345\205\263\351\224\256\345\255\227\357\274\214CAS\346\223\215\344\275\234.md"
index 0abdbe8..60a9c3e 100644
--- "a/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232\345\271\266\345\217\221\344\270\211\345\244\247\351\227\256\351\242\230\344\270\216volatile\345\205\263\351\224\256\345\255\227\357\274\214CAS\346\223\215\344\275\234.md"
+++ "b/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232\345\271\266\345\217\221\344\270\211\345\244\247\351\227\256\351\242\230\344\270\216volatile\345\205\263\351\224\256\345\255\227\357\274\214CAS\346\223\215\344\275\234.md"
@@ -9,7 +9,6 @@
* [volatile写-读的内存语义](#volatile写-读的内存语义)
* [volatile内存语义的实现](#volatile内存语义的实现)
* [JSR-133为什么要增强volatile的内存语义](#jsr-133为什么要增强volatile的内存语义)
- * [](#)
* [引言](#引言)
* [术语定义](#术语定义)
* [3 处理器如何实现原子操作](#3-处理器如何实现原子操作)
diff --git "a/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232\346\267\261\345\205\245\347\220\206\350\247\243Java\345\206\205\345\255\230\346\250\241\345\236\213JMM.md" "b/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232\346\267\261\345\205\245\347\220\206\350\247\243Java\345\206\205\345\255\230\346\250\241\345\236\213JMM.md"
index 0856914..a9aad6e 100644
--- "a/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232\346\267\261\345\205\245\347\220\206\350\247\243Java\345\206\205\345\255\230\346\250\241\345\236\213JMM.md"
+++ "b/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232\346\267\261\345\205\245\347\220\206\350\247\243Java\345\206\205\345\255\230\346\250\241\345\236\213JMM.md"
@@ -176,7 +176,7 @@ Java 语言在遵循内存模型的基础上推出了 JMM 规范,目的是解
我们知道,Java程序是需要运行在Java虚拟机上面的,**Java内存模型(Java Memory Model ,JMM)就是一种符合内存模型规范的,屏蔽了各种硬件和操作系统的访问差异的,保证了Java程序在各种平台下对内存的访问都能保证效果一致的机制及规范。**
-提到Java内存模型,一般指的是JDK 5 开始使用的新的内存模型,主要由[JSR-133: JavaTM Memory Model and Thread Specification](http://www.cs.umd.edu/~pugh/java/memoryModel/jsr133.pdf) 描述。感兴趣的可以参看下这份PDF文档([http://www.cs.umd.edu/~pugh/java/memoryModel/jsr133.pdf](http://www.cs.umd.edu/~pugh/java/memoryModel/jsr133.pdf))
+提到Java内存模型,一般指的是JDK 5 开始使用的新的内存模型,主要由[JSR-133: JavaTM Memory Model and Thread Specification](http://www.cs.umd.edu/~pugh/java/memoryModel/jsr133.pdf)描述。感兴趣的可以参看下这份PDF文档([http://www.cs.umd.edu/~pugh/java/memoryModel/jsr133.pdf](http://www.cs.umd.edu/~pugh/java/memoryModel/jsr133.pdf))
Java内存模型规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存,线程的工作内存中保存了该线程中是用到的变量的主内存副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量的传递均需要自己的工作内存和主存之间进行数据同步进行。
diff --git "a/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232\346\267\261\345\272\246\350\247\243\350\257\273Java\347\272\277\347\250\213\346\261\240\350\256\276\350\256\241\346\200\235\346\203\263\345\217\212\346\272\220\347\240\201\345\256\236\347\216\260.md" "b/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232\346\267\261\345\272\246\350\247\243\350\257\273Java\347\272\277\347\250\213\346\261\240\350\256\276\350\256\241\346\200\235\346\203\263\345\217\212\346\272\220\347\240\201\345\256\236\347\216\260.md"
index b318132..aa025c9 100644
--- "a/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232\346\267\261\345\272\246\350\247\243\350\257\273Java\347\272\277\347\250\213\346\261\240\350\256\276\350\256\241\346\200\235\346\203\263\345\217\212\346\272\220\347\240\201\345\256\236\347\216\260.md"
+++ "b/docs/java/concurrency/Java\345\271\266\345\217\221\346\214\207\345\215\227\357\274\232\346\267\261\345\272\246\350\247\243\350\257\273Java\347\272\277\347\250\213\346\261\240\350\256\276\350\256\241\346\200\235\346\203\263\345\217\212\346\272\220\347\240\201\345\256\236\347\216\260.md"
@@ -92,7 +92,7 @@ public interface Executor {
}
```
-我们可以看到 Executor 接口非常简单,就一个 `void execute(Runnable command)` 方法,代表提交一个任务。为了让大家理解 java 线程池的整个设计方案,我会按照 Doug Lea 的设计思路来多说一些相关的东西。
+我们可以看到 Executor 接口非常简单,就一个`void execute(Runnable command)`方法,代表提交一个任务。为了让大家理解 java 线程池的整个设计方案,我会按照 Doug Lea 的设计思路来多说一些相关的东西。
我们经常这样启动一个线程:
@@ -171,7 +171,7 @@ class SerialExecutor implements Executor {
}
```
-当然了,Executor 这个接口只有提交任务的功能,太简单了,我们想要更丰富的功能,比如我们想知道执行结果、我们想知道当前线程池有多少个线程活着、已经完成了多少任务等等,这些都是这个接口的不足的地方。接下来我们要介绍的是继承自 `Executor` 接口的 `ExecutorService` 接口,这个接口提供了比较丰富的功能,也是我们最常使用到的接口。
+当然了,Executor 这个接口只有提交任务的功能,太简单了,我们想要更丰富的功能,比如我们想知道执行结果、我们想知道当前线程池有多少个线程活着、已经完成了多少任务等等,这些都是这个接口的不足的地方。接下来我们要介绍的是继承自`Executor`接口的`ExecutorService`接口,这个接口提供了比较丰富的功能,也是我们最常使用到的接口。
## ExecutorService
@@ -277,13 +277,13 @@ public interface Callable {
在这里,就不展开说 FutureTask 类了,因为本文篇幅本来就够大了,这里我们需要知道怎么用就行了。
-下面,我们来看看 `ExecutorService` 的抽象实现 `AbstractExecutorService` 。
+下面,我们来看看`ExecutorService`的抽象实现`AbstractExecutorService`。
## AbstractExecutorService
AbstractExecutorService 抽象类派生自 ExecutorService 接口,然后在其基础上实现了几个实用的方法,这些方法提供给子类进行调用。
-这个抽象类实现了 invokeAny 方法和 invokeAll 方法,这里的两个 newTaskFor 方法也比较有用,用于将任务包装成 FutureTask。定义于最上层接口 Executor中的 `void execute(Runnable command)` 由于不需要获取结果,不会进行 FutureTask 的包装。
+这个抽象类实现了 invokeAny 方法和 invokeAll 方法,这里的两个 newTaskFor 方法也比较有用,用于将任务包装成 FutureTask。定义于最上层接口 Executor中的`void execute(Runnable command)`由于不需要获取结果,不会进行 FutureTask 的包装。
> 需要获取结果(FutureTask),用 submit 方法,不需要获取结果,可以用 execute 方法。
@@ -600,7 +600,7 @@ public Future submit(Callable task) {
当然,上图没有考虑队列是否有界,提交任务时队列满了怎么办?什么情况下会创建新的线程?提交任务时线程池满了怎么办?空闲线程怎么关掉?这些问题下面我们会一一解决。
-我们经常会使用 `Executors` 这个工具类来快速构造一个线程池,对于初学者而言,这种工具类是很有用的,开发者不需要关注太多的细节,只要知道自己需要一个线程池,仅仅提供必需的参数就可以了,其他参数都采用作者提供的默认值。
+我们经常会使用`Executors`这个工具类来快速构造一个线程池,对于初学者而言,这种工具类是很有用的,开发者不需要关注太多的细节,只要知道自己需要一个线程池,仅仅提供必需的参数就可以了,其他参数都采用作者提供的默认值。
```
public static ExecutorService newFixedThreadPool(int nThreads) {
@@ -659,7 +659,7 @@ public static ExecutorService newCachedThreadPool() {
* keepAliveTime
- > 空闲线程的保活时间,如果某线程的空闲时间超过这个值都没有任务给它做,那么可以被关闭了。注意这个值并不会对所有线程起作用,如果线程池中的线程数少于等于核心线程数 corePoolSize,那么这些线程不会因为空闲太长时间而被关闭,当然,也可以通过调用 `allowCoreThreadTimeOut(true)`使核心线程数内的线程也可以被回收。
+ > 空闲线程的保活时间,如果某线程的空闲时间超过这个值都没有任务给它做,那么可以被关闭了。注意这个值并不会对所有线程起作用,如果线程池中的线程数少于等于核心线程数 corePoolSize,那么这些线程不会因为空闲太长时间而被关闭,当然,也可以通过调用`allowCoreThreadTimeOut(true)`使核心线程数内的线程也可以被回收。
* threadFactory
diff --git "a/docs/java/concurrency/Java\345\271\266\345\217\221\347\274\226\347\250\213\345\255\246\344\271\240\346\200\273\347\273\223.md" "b/docs/java/concurrency/Java\345\271\266\345\217\221\347\274\226\347\250\213\345\255\246\344\271\240\346\200\273\347\273\223.md"
index f5ab376..98f3e38 100644
--- "a/docs/java/concurrency/Java\345\271\266\345\217\221\347\274\226\347\250\213\345\255\246\344\271\240\346\200\273\347\273\223.md"
+++ "b/docs/java/concurrency/Java\345\271\266\345\217\221\347\274\226\347\250\213\345\255\246\344\271\240\346\200\273\347\273\223.md"
@@ -9,7 +9,6 @@
* [Lock类](#lock类)
* [AQS](#aqs)
* [锁Lock和Conditon](#锁lock和conditon)
- * [](#)
* [并发工具类](#并发工具类)
* [原子数据类型](#原子数据类型)
* [同步容器](#同步容器)
diff --git "a/docs/java/design-parttern/\345\210\235\346\216\242Java\350\256\276\350\256\241\346\250\241\345\274\217\357\274\232JDK\344\270\255\347\232\204\350\256\276\350\256\241\346\250\241\345\274\217.md" "b/docs/java/design-parttern/\345\210\235\346\216\242Java\350\256\276\350\256\241\346\250\241\345\274\217\357\274\232JDK\344\270\255\347\232\204\350\256\276\350\256\241\346\250\241\345\274\217.md"
index dc643c3..61748b1 100644
--- "a/docs/java/design-parttern/\345\210\235\346\216\242Java\350\256\276\350\256\241\346\250\241\345\274\217\357\274\232JDK\344\270\255\347\232\204\350\256\276\350\256\241\346\250\241\345\274\217.md"
+++ "b/docs/java/design-parttern/\345\210\235\346\216\242Java\350\256\276\350\256\241\346\250\241\345\274\217\357\274\232JDK\344\270\255\347\232\204\350\256\276\350\256\241\346\250\241\345\274\217.md"
@@ -1,3 +1,34 @@
+# Table of Contents
+
+ * [**一,结构型模式**](#一,结构型模式)
+ * [**1,适配器模式**](#1,适配器模式)
+ * [**2,桥接模式**](#2,桥接模式)
+ * [**3,组合模式**](#3,组合模式)
+ * [**4,装饰者模式**](#4,装饰者模式)
+ * [**5,门面模式**](#5,门面模式)
+ * [**6,享元模式**](#6,享元模式)
+ * [**7,代理模式**](#7,代理模式)
+ * [**二,创建模式**](#二,创建模式)
+ * [**1,抽象工厂模式**](#1,抽象工厂模式)
+ * [**2,建造模式(Builder)**](#2,建造模式builder)
+ * [**3,工厂方法**](#3,工厂方法)
+ * [**4,原型模式**](#4,原型模式)
+ * [**5,单例模式**](#5,单例模式)
+ * [**三,行为模式**](#三,行为模式)
+ * [**1,责任链模式**](#1,责任链模式)
+ * [**2,命令模式**](#2,命令模式)
+ * [**3,解释器模式**](#3,解释器模式)
+ * [**4,迭代器模式**](#4,迭代器模式)
+ * [**5,中介者模式**](#5,中介者模式)
+ * [**6,备忘录模式**](#6,备忘录模式)
+ * [**7,空对象模式**](#7,空对象模式)
+ * [**8,观察者模式**](#8,观察者模式)
+ * [**9,状态模式**](#9,状态模式)
+ * [**10,策略模式**](#10,策略模式)
+ * [**11,模板方法模式**](#11,模板方法模式)
+ * [**12,访问者模式**](#12,访问者模式)
+
+
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
@@ -12,9 +43,9 @@
本文转自https://www.cnblogs.com/LinkinPark/p/5233075.html
-**一,结构型模式**
+## **一,结构型模式**
-**1,适配器模式**
+### **1,适配器模式**
**用来把一个接口转化成另一个接口**
@@ -30,7 +61,7 @@
>
> **javax.xml.bind.annotation.adapters.XmlAdapter#unmarshal()**
-**2,桥接模式**
+### **2,桥接模式**
**这个模式将抽象和抽象操作的实现进行了解耦,这样使得抽象和实现可以独立地变化**
@@ -38,7 +69,7 @@
>
> **JDBC**
-**3,组合模式**
+### **3,组合模式**
**使得客户端看来单个对象和对象的组合是同等的。换句话说,某个类型的方法同时也接受自身类型作为参数**
@@ -52,7 +83,7 @@
>
> **java.util.Set#addAll(Collection)**
-**4,装饰者模式**
+### **4,装饰者模式**
**动态的给一个对象附加额外的功能,这也是子类的一种替代方式。可以看到,在创建一个类型的时候,同时也传入同一类型的对象。这在JDK里随处可见,你会发现它无处不在,所以下面这个列表只是一小部分**
@@ -64,9 +95,9 @@
>
> **java.util.zip.ZipOutputStream(OutputStream)**
>
-> **java.util.Collections#checked**
+> **java.util.Collections#checked**
-**5,门面模式**
+### **5,门面模式**
**给一组组件,接口,抽象,或者子系统提供一个简单的接口**
@@ -74,7 +105,7 @@
>
> **javax.faces.webapp.FacesServlet**
-**6,享元模式**
+### **6,享元模式**
**使用缓存来加速大量小对象的访问时间**
@@ -86,7 +117,7 @@
>
> **java.lang.Character#valueOf(char)**
-**7,代理模式**
+### **7,代理模式**
**代理模式是用一个简单的对象来代替一个复杂的或者创建耗时的对象。**
@@ -94,11 +125,11 @@
>
> **RMI**
-** **
+****
-**二,创建模式**
+## **二,创建模式**
-**1,抽象工厂模式**
+### **1,抽象工厂模式**
**抽象工厂模式提供了一个协议来生成一系列的相关或者独立的对象,而不用指定具体对象的类型。它使得应用程序能够和使用的框架的具体实现进行解耦。这在JDK或者许多框架比如Spring中都随处可见。它们也很容易识别,一个创建新对象的方法,返回的却是接口或者抽象类的,就是抽象工厂模式了**
@@ -118,7 +149,7 @@
>
> **javax.xml.transform.TransformerFactory#newInstance()**
-**2,建造模式(Builder)**
+### **2,建造模式(Builder)**
**定义了一个新的类来构建另一个类的实例,以简化复杂对象的创建。建造模式通常也使用方法链接来实现**
@@ -130,7 +161,7 @@
>
> **javax.swing.GroupLayout.Group#addComponent()**
-**3,工厂方法**
+### **3,工厂方法**
**就是一个返回具体对象的方法**
@@ -148,7 +179,7 @@
>
> **java.lang.Class#forName()**
-**4,原型模式**
+### **4,原型模式**
**使得类的实例能够生成自身的拷贝。如果创建一个对象的实例非常复杂且耗时时,就可以使用这种模式,而不重新创建一个新的实例,你可以拷贝一个对象并直接修改它**
@@ -156,7 +187,7 @@
>
> **java.lang.Cloneable**
-**5,单例模式**
+### **5,单例模式**
**用来确保类只有一个实例。Joshua Bloch在Effetive Java中建议到,还有一种方法就是使用枚举**
@@ -168,11 +199,11 @@
>
> **java.awt.Desktop#getDesktop()**
-** **
+****
-**三,行为模式**
+## **三,行为模式**
-**1,责任链模式**
+### **1,责任链模式**
**通过把请求从一个对象传递到链条中下一个对象的方式,直到请求被处理完毕,以实现对象间的解耦**
@@ -180,7 +211,7 @@
>
> **javax.servlet.Filter#doFilter()**
-**2,命令模式**
+### **2,命令模式**
**将操作封装到对象内,以便存储,传递和返回**
@@ -188,7 +219,7 @@
>
> **javax.swing.Action**
-**3,解释器模式**
+### **3,解释器模式**
**这个模式通常定义了一个语言的语法,然后解析相应语法的语句**
@@ -198,7 +229,7 @@
>
> **java.text.Format**
-**4,迭代器模式**
+### **4,迭代器模式**
**提供一个一致的方法来顺序访问集合中的对象,这个方法与底层的集合的具体实现无关**
@@ -206,7 +237,7 @@
>
> **java.util.Enumeration**
-**5,中介者模式**
+### **5,中介者模式**
**通过使用一个中间对象来进行消息分发以及减少类之间的直接依赖**
@@ -218,7 +249,7 @@
>
> **java.lang.reflect.Method#invoke()**
-**6,备忘录模式**
+### **6,备忘录模式**
**生成对象状态的一个快照,以便对象可以恢复原始状态而不用暴露自身的内容。Date对象通过自身内部的一个long值来实现备忘录模式**
@@ -226,7 +257,7 @@
>
> **java.io.Serializable**
-**7,空对象模式**
+### **7,空对象模式**
**这个模式通过一个无意义的对象来代替没有对象这个状态。它使得你不用额外对空对象进行处理**
@@ -236,7 +267,7 @@
>
> **java.util.Collections#emptySet()**
-**8,观察者模式**
+### **8,观察者模式**
**它使得一个对象可以灵活的将消息发送给感兴趣的对象**
@@ -248,7 +279,7 @@
>
> **javax.faces.event.PhaseListener**
-**9,状态模式**
+### **9,状态模式**
**通过改变对象内部的状态,使得你可以在运行时动态改变一个对象的行为**
@@ -256,7 +287,7 @@
>
> **javax.faces.lifecycle.LifeCycle#execute()**
-**10,策略模式**
+### **10,策略模式**
**使用这个模式来将一组算法封装成一系列对象。通过传递这些对象可以灵活的改变程序的功能**
@@ -266,7 +297,7 @@
>
> **javax.servlet.Filter#doFilter()**
-**11,模板方法模式**
+### **11,模板方法模式**
**让子类可以重写方法的一部分,而不是整个重写,你可以控制子类需要重写那些操作**
@@ -278,7 +309,7 @@
>
> **java.util.AbstractList#indexOf()**
-**12,访问者模式**
+### **12,访问者模式**
**提供一个方便的可维护的方式来操作一组对象。它使得你在不改变操作的对象前提下,可以修改或者扩展对象的行为**
diff --git "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232GC\350\260\203\344\274\230\346\200\235\350\267\257\344\270\216\345\270\270\347\224\250\345\267\245\345\205\267.md" "b/docs/java/jvm/temp/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232GC\350\260\203\344\274\230\346\200\235\350\267\257\344\270\216\345\270\270\347\224\250\345\267\245\345\205\267.md"
similarity index 98%
rename from "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232GC\350\260\203\344\274\230\346\200\235\350\267\257\344\270\216\345\270\270\347\224\250\345\267\245\345\205\267.md"
rename to "docs/java/jvm/temp/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232GC\350\260\203\344\274\230\346\200\235\350\267\257\344\270\216\345\270\270\347\224\250\345\267\245\345\205\267.md"
index 341f675..30d3350 100644
--- "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232GC\350\260\203\344\274\230\346\200\235\350\267\257\344\270\216\345\270\270\347\224\250\345\267\245\345\205\267.md"
+++ "b/docs/java/jvm/temp/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232GC\350\260\203\344\274\230\346\200\235\350\267\257\344\270\216\345\270\270\347\224\250\345\267\245\345\205\267.md"
@@ -1,4 +1,23 @@
-# 目录
+# Table of Contents
+
+* [核心概念(Core Concepts)](#核心概念core-concepts)
+ * [Latency(延迟)](#latency延迟)
+ * [Throughput(吞吐量)](#throughput吞吐量)
+ * [Capacity(系统容量)](#capacity系统容量)
+* [相关示例](#相关示例)
+ * [Tuning for Latency(调优延迟指标)](#tuning-for-latency调优延迟指标)
+ * [Tuning for Throughput(吞吐量调优)](#tuning-for-throughput吞吐量调优)
+ * [Tuning for Capacity(调优系统容量)](#tuning-for-capacity调优系统容量)
+ * [6\. GC 调优(工具篇) - GC参考手册](#6-gc-调优工具篇---gc参考手册)
+ * [JMX API](#jmx-api)
+ * [JVisualVM](#jvisualvm)
+ * [jstat](#jstat)
+ * [GC日志(GC logs)](#gc日志gc-logs)
+ * [GCViewer](#gcviewer)
+ * [分析器(Profilers)](#分析器profilers)
+ * [hprof](#hprof)
+ * [Java VisualVM](#java-visualvm)
+ * [AProf](#aprof)
* [参考文章](#参考文章)
@@ -18,8 +37,6 @@
-## 5\. GC 调优(基础篇) - GC参考手册
-
> **说明**:
>
> **Capacity**: 性能,能力,系统容量; 文中翻译为”**系统容量**“; 意为硬件配置。
diff --git "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\345\270\270\347\224\250\345\217\202\346\225\260\344\273\245\345\217\212\350\260\203\344\274\230\345\256\236\350\267\265.md" "b/docs/java/jvm/temp/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\345\270\270\347\224\250\345\217\202\346\225\260\344\273\245\345\217\212\350\260\203\344\274\230\345\256\236\350\267\265.md"
similarity index 98%
rename from "docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\345\270\270\347\224\250\345\217\202\346\225\260\344\273\245\345\217\212\350\260\203\344\274\230\345\256\236\350\267\265.md"
rename to "docs/java/jvm/temp/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\345\270\270\347\224\250\345\217\202\346\225\260\344\273\245\345\217\212\350\260\203\344\274\230\345\256\236\350\267\265.md"
index 987466f..5b7c03c 100644
--- "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\345\270\270\347\224\250\345\217\202\346\225\260\344\273\245\345\217\212\350\260\203\344\274\230\345\256\236\350\267\265.md"
+++ "b/docs/java/jvm/temp/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\345\270\270\347\224\250\345\217\202\346\225\260\344\273\245\345\217\212\350\260\203\344\274\230\345\256\236\350\267\265.md"
@@ -1,24 +1,21 @@
+# Table of Contents
+ * [JVM优化的必要性](#jvm优化的必要性)
+ * [JVM调优原则](#jvm调优原则)
+ * [JVM运行参数设置](#jvm运行参数设置)
+ * [JVM性能调优工具](#jvm性能调优工具)
+ * [常用调优策略](#常用调优策略)
+ * [六、JVM调优实例](#六、jvm调优实例)
+ * [七、一个具体的实战案例分析](#七、一个具体的实战案例分析)
+ * [参考资料](#参考资料)
+ * [参考文章](#参考文章)
-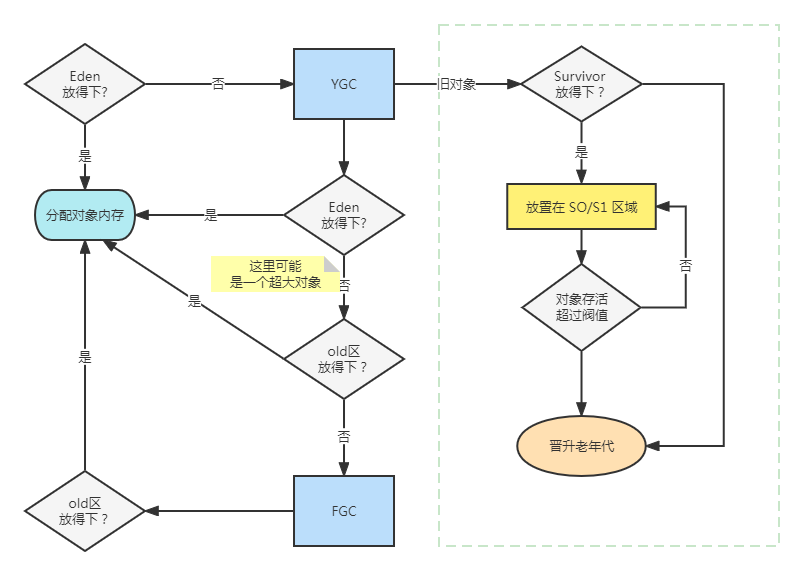
-
-**目录**
-
-一. JVM优化的必要性
-
-二. JVM调优原则
-三. JVM运行参数设置
-四. JVM性能调优工具
-五. 常用调优策略
-
-六. JVM调优实例
-
-七. 一个具体的实战案例分析
+
-### JVM优化的必要性
+## JVM优化的必要性
**1.1: 项目上线后,什么原因使得我们需要进行jvm调优**
@@ -58,7 +55,7 @@ Jvm堆内存不能设置太大,否则会导致寻址垃圾的时间过长,
* 系统吞吐量与响应性能不高或下降。
-### JVM调优原则
+## JVM调优原则
@@ -254,13 +251,13 @@ TLAB空间一般不会太大,当大对象无法在TLAB分配时,则会直接
-### 四.JVM性能调优工具
+## JVM性能调优工具
这个篇幅在这里就不过多介绍了,可以参照:
深入理解JVM虚拟机——Java虚拟机的监控及诊断工具大全
-### 五.常用调优策略
+## 常用调优策略
这里还是要提一下,及时确定要进行JVM调优,也不要陷入“知见障”,进行分析之后,发现可以通过优化程序提升性能,仍然首选优化程序。
@@ -410,7 +407,7 @@ CPU多核,关注用户停顿时间,JDK1.8及以上,JVM可用内存6G以上
> XX:MaxDirectMemorySize
-### 六、JVM调优实例
+## 六、JVM调优实例
整理的一些JVM调优实例:
@@ -533,7 +530,7 @@ CPU多核,关注用户停顿时间,JDK1.8及以上,JVM可用内存6G以上
系统对外提供各种账号鉴权服务,使用时发现系统经常服务不可用,通过 Zabbix 的监控平台监控发现系统频繁发生长时间 Full GC,且触发时老年代的堆内存通常并没有占满,发现原来是业务代码中调用了
-### 七、一个具体的实战案例分析
+## 七、一个具体的实战案例分析
**7.1 典型调优参数设置**
diff --git "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JNDI\357\274\214OSGI\357\274\214Tomcat\347\261\273\345\212\240\350\275\275\345\231\250\345\256\236\347\216\260.md" "b/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JNDI\357\274\214OSGI\357\274\214Tomcat\347\261\273\345\212\240\350\275\275\345\231\250\345\256\236\347\216\260.md"
index b48b79b..6c1b066 100644
--- "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JNDI\357\274\214OSGI\357\274\214Tomcat\347\261\273\345\212\240\350\275\275\345\231\250\345\256\236\347\216\260.md"
+++ "b/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JNDI\357\274\214OSGI\357\274\214Tomcat\347\261\273\345\212\240\350\275\275\345\231\250\345\256\236\347\216\260.md"
@@ -1,7 +1,7 @@
# 目录
* [打破双亲委派模型](#打破双亲委派模型)
* [JNDI](#jndi)
- * [[JNDI 的理解](https://yq.aliyun.com/go/articleRenderRedirect?url=https%3A%2F%2Fwww.cnblogs.com%2Fzhchoutai%2Fp%2F7389089.html)](#[jndi-的理解]httpsyqaliyuncomgoarticlerenderredirecturlhttps3a2f2fwwwcnblogscom2fzhchoutai2fp2f7389089html)
+ * [JNDI 的理解](#[jndi-的理解])
* [OSGI](#osgi)
* [1.如何正确的理解和认识OSGI技术?](#1如何正确的理解和认识osgi技术?)
* [Tomcat类加载器以及应用间class隔离与共享](#tomcat类加载器以及应用间class隔离与共享)
diff --git "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\345\236\203\345\234\276\345\233\236\346\224\266\345\237\272\346\234\254\345\216\237\347\220\206\345\222\214\347\256\227\346\263\225.md" "b/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\345\236\203\345\234\276\345\233\236\346\224\266\345\237\272\346\234\254\345\216\237\347\220\206\345\222\214\347\256\227\346\263\225.md"
index 65e4869..8048fb5 100644
--- "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\345\236\203\345\234\276\345\233\236\346\224\266\345\237\272\346\234\254\345\216\237\347\220\206\345\222\214\347\256\227\346\263\225.md"
+++ "b/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232JVM\345\236\203\345\234\276\345\233\236\346\224\266\345\237\272\346\234\254\345\216\237\347\220\206\345\222\214\347\256\227\346\263\225.md"
@@ -14,7 +14,7 @@
* [垃圾回收中实例的终结](#垃圾回收中实例的终结)
* [对象什么时候符合垃圾回收的条件?](#对象什么时候符合垃圾回收的条件?)
* [GC Scope 示例程序](#gc-scope-示例程序)
- * [[JVM GC算法](https://www.cnblogs.com/wupeixuan/p/8670341.html)](#[jvm-gc算法]httpswwwcnblogscomwupeixuanp8670341html)
+ * [JVM GC算法](#JVM GC算法)
* [JVM垃圾判定算法](#jvm垃圾判定算法)
* [引用计数算法(Reference Counting)](#引用计数算法reference-counting)
* [可达性分析算法(根搜索算法)](#可达性分析算法(根搜索算法))
diff --git "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232Java\347\232\204\347\274\226\350\257\221\346\234\237\344\274\230\345\214\226\344\270\216\350\277\220\350\241\214\346\234\237\344\274\230\345\214\226.md" "b/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232Java\347\232\204\347\274\226\350\257\221\346\234\237\344\274\230\345\214\226\344\270\216\350\277\220\350\241\214\346\234\237\344\274\230\345\214\226.md"
index 0a1c3ac..58b8166 100644
--- "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232Java\347\232\204\347\274\226\350\257\221\346\234\237\344\274\230\345\214\226\344\270\216\350\277\220\350\241\214\346\234\237\344\274\230\345\214\226.md"
+++ "b/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232Java\347\232\204\347\274\226\350\257\221\346\234\237\344\274\230\345\214\226\344\270\216\350\277\220\350\241\214\346\234\237\344\274\230\345\214\226.md"
@@ -1,5 +1,5 @@
# 目录
- * [[java编译期优化](https://www.cnblogs.com/LeonNew/p/6187411.html)](#[java编译期优化]httpswwwcnblogscomleonnewp6187411html)
+ * [java编译期优化](#[java编译期优化])
* [早期(编译期)优化](#早期(编译期)优化)
* [泛型与类型擦除](#泛型与类型擦除)
* [自动装箱、拆箱与遍历循环](#自动装箱、拆箱与遍历循环)
@@ -41,7 +41,7 @@ java语言的编译期其实是一段不确定的操作过程,因为它可以
2.后端编译:把字节码转变为机器码
3.静态提前编译:直接把*.java文件编译成本地机器代码
从JDK1.3开始,虚拟机设计团队就把对性能的优化集中到了后端的即时编译中,这样可以让那些不是由Javac产生的Class文件(如JRuby、Groovy等语言的Class文件)也能享受到编译期优化所带来的好处
-**Java中即时编译在运行期的优化过程对于程序运行来说更重要,而前端编译期在编译期的优化过程对于程序编码来说关系更加密切 **
+**Java中即时编译在运行期的优化过程对于程序运行来说更重要,而前端编译期在编译期的优化过程对于程序编码来说关系更加密切**
### 早期(编译期)优化
@@ -102,7 +102,7 @@ public static void main(String[] args) {
##### 解释器与编译器
-Java程序最初是通过解释器进行解释执行的,当程序需要迅速启动和执行时,解释器可以首先发挥作用,省去编译时间,立即执行;当程序运行后,随着时间的推移,编译期逐渐发挥作用,把越来越多的代码编译成本地代码,获得更高的执行效率。**解释执行节约内存,编译执行提升效率。** 同时,解释器可以作为编译器激进优化时的一个“逃生门”,让编译器根据概率选择一些大多数时候都能提升运行速度的优化手段,当激进优化的假设不成立,则通过逆优化退回到解释状态继续执行。
+Java程序最初是通过解释器进行解释执行的,当程序需要迅速启动和执行时,解释器可以首先发挥作用,省去编译时间,立即执行;当程序运行后,随着时间的推移,编译期逐渐发挥作用,把越来越多的代码编译成本地代码,获得更高的执行效率。**解释执行节约内存,编译执行提升效率。**同时,解释器可以作为编译器激进优化时的一个“逃生门”,让编译器根据概率选择一些大多数时候都能提升运行速度的优化手段,当激进优化的假设不成立,则通过逆优化退回到解释状态继续执行。
HotSpot虚拟机中内置了两个即时编译器,分别称为Client Compiler(C1编译器)和Server Compiler(C2编译器),默认采用解释器与其中一个编译器直接配合的方式工作,使用哪个编译器取决于虚拟机运行的模式,也可以自己去指定。若强制虚拟机运行与“解释模式”,编译器完全不介入工作,若强制虚拟机运行于“编译模式”,则优先采用编译方式执行程序,解释器仍然要在编译无法进行的情况下介入执行过程。
diff --git "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232\345\206\215\350\260\210\345\233\233\347\247\215\345\274\225\347\224\250\345\217\212GC\345\256\236\350\267\265.md" "b/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232\345\206\215\350\260\210\345\233\233\347\247\215\345\274\225\347\224\250\345\217\212GC\345\256\236\350\267\265.md"
index 08cc449..cca62d4 100644
--- "a/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232\345\206\215\350\260\210\345\233\233\347\247\215\345\274\225\347\224\250\345\217\212GC\345\256\236\350\267\265.md"
+++ "b/docs/java/jvm/\346\267\261\345\205\245\347\220\206\350\247\243JVM\350\231\232\346\213\237\346\234\272\357\274\232\345\206\215\350\260\210\345\233\233\347\247\215\345\274\225\347\224\250\345\217\212GC\345\256\236\350\267\265.md"
@@ -32,7 +32,7 @@
## 一、背景
-Java的内存回收不需要程序员负责,JVM会在必要时启动Java GC完成垃圾回收。Java以便我们控制对象的生存周期,提供给了我们四种引用方式,引用强度从强到弱分别为:强引用、软引用、弱引用、虚引用。
+Java的内存回收不需要程序员负责,JVM会在必要时启动Java GC完成垃圾回收。Java以便我们控制对象的生存周期,提供给了我们四种引用方式,引用强度从强到弱分别为:强引用、软引用、弱引用、虚引用。
## 二、简介
diff --git "a/docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\344\270\216NIO\350\257\246\350\247\243\357\274\232IO\346\250\241\345\236\213\344\270\216Java\347\275\221\347\273\234\347\274\226\347\250\213\346\250\241\345\236\213.md" "b/docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\344\270\216NIO\350\257\246\350\247\243\357\274\232IO\346\250\241\345\236\213\344\270\216Java\347\275\221\347\273\234\347\274\226\347\250\213\346\250\241\345\236\213.md"
index 8bdf054..838c7d7 100644
--- "a/docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\344\270\216NIO\350\257\246\350\247\243\357\274\232IO\346\250\241\345\236\213\344\270\216Java\347\275\221\347\273\234\347\274\226\347\250\213\346\250\241\345\236\213.md"
+++ "b/docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\344\270\216NIO\350\257\246\350\247\243\357\274\232IO\346\250\241\345\236\213\344\270\216Java\347\275\221\347\273\234\347\274\226\347\250\213\346\250\241\345\236\213.md"
@@ -90,7 +90,7 @@ asynchronous IO
**_当一个read操作发生时,它会经历两个阶段:_**
-* 等待数据准备,比如accept(), recv()等待数据 `(Waiting for the data to be ready)`
+* 等待数据准备,比如accept(), recv()等待数据`(Waiting for the data to be ready)`
* 将数据从内核拷贝到进程中, 比如 accept()接受到请求,recv()接收连接发送的数据后需要复制到内核,再从内核复制到进程用户空间`(Copying the data from the kernel to the process)`
**_对于socket流而言,数据的流向经历两个阶段:_**
@@ -206,7 +206,7 @@ linux下的asynchronous IO其实用得很少。先看一下它的流程:
同步IO VS 异步IO:
概念:
-同步与异步同步和异步关注的是___消息通信机制 ___(synchronous communication/ asynchronous communication)所谓同步,就是在发出一个_调用_时,在没有得到结果之前,该_调用_就不返回。但是一旦调用返回,就得到返回值了。换句话说,就是由_调用者_主动等待这个_调用_的结果。而异步则是相反,_调用_在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在_调用_发出后,_被调用者_通过状态、通知来通知调用者,或通过回调函数处理这个调用。
+同步与异步同步和异步关注的是___消息通信机制___(synchronous communication/ asynchronous communication)所谓同步,就是在发出一个_调用_时,在没有得到结果之前,该_调用_就不返回。但是一旦调用返回,就得到返回值了。换句话说,就是由_调用者_主动等待这个_调用_的结果。而异步则是相反,_调用_在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在_调用_发出后,_被调用者_通过状态、通知来通知调用者,或通过回调函数处理这个调用。
典型的异步编程模型比如Node.js举个通俗的例子:你打电话问书店老板有没有《分布式系统》这本书,如果是同步通信机制,书店老板会说,你稍等,”我查一下",然后开始查啊查,等查好了(可能是5秒,也可能是一天)告诉你结果(返回结果)。而异步通信机制,书店老板直接告诉你我查一下啊,查好了打电话给你,然后直接挂电话了(不返回结果)。然后查好了,他会主动打电话给你。在这里老板通过“回电”这种方式来回调。
diff --git "a/docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\344\270\216NIO\350\257\246\350\247\243\357\274\232Java\351\235\236\351\230\273\345\241\236IO\345\222\214\345\274\202\346\255\245IO.md" "b/docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\344\270\216NIO\350\257\246\350\247\243\357\274\232Java\351\235\236\351\230\273\345\241\236IO\345\222\214\345\274\202\346\255\245IO.md"
index 4ec65bc..2837b73 100644
--- "a/docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\344\270\216NIO\350\257\246\350\247\243\357\274\232Java\351\235\236\351\230\273\345\241\236IO\345\222\214\345\274\202\346\255\245IO.md"
+++ "b/docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\344\270\216NIO\350\257\246\350\247\243\357\274\232Java\351\235\236\351\230\273\345\241\236IO\345\222\214\345\274\202\346\255\245IO.md"
@@ -32,7 +32,7 @@
上一篇文章介绍了 Java NIO 中 Buffer、Channel 和 Selector 的基本操作,主要是一些接口操作,比较简单。
-本文将介绍**非阻塞 IO** 和**异步 IO**,也就是大家耳熟能详的 NIO 和 AIO。很多初学者可能分不清楚异步和非阻塞的区别,只是在各种场合能听到**异步非阻塞**这个词。
+本文将介绍**非阻塞 IO**和**异步 IO**,也就是大家耳熟能详的 NIO 和 AIO。很多初学者可能分不清楚异步和非阻塞的区别,只是在各种场合能听到**异步非阻塞**这个词。
本文会先介绍并演示阻塞模式,然后引入非阻塞模式来对阻塞模式进行优化,最后再介绍 JDK7 引入的异步 IO,由于网上关于异步 IO 的介绍相对较少,所以这部分内容我会介绍得具体一些。
@@ -160,7 +160,7 @@ select 和 poll 都有一个共同的问题,那就是**它们都只会告诉
**epoll**:2002 年随 Linux 内核 2.5.44 发布,epoll 能直接返回具体的准备好的通道,时间复杂度 O(1)。
-除了 Linux 中的 epoll,2000 年 FreeBSD 出现了 **Kqueue**,还有就是,Solaris 中有 **/dev/poll**。
+除了 Linux 中的 epoll,2000 年 FreeBSD 出现了**Kqueue**,还有就是,Solaris 中有**/dev/poll**。
> 前面说了那么多实现,但是没有出现 Windows,Windows 平台的非阻塞 IO 使用 select,我们也不必觉得 Windows 很落后,在 Windows 中 IOCP 提供的异步 IO 是比较强大的。
@@ -239,13 +239,13 @@ More New IO,或称 NIO.2,随 JDK 1.7 发布,包括了引入异步 IO 接
**在 Unix/Linux 等系统中,JDK 使用了并发包中的线程池来管理任务**,具体可以查看 AsynchronousChannelGroup 的源码。
-在 Windows 操作系统中,提供了一个叫做 [I/O Completion Ports](https://msdn.microsoft.com/en-us/library/windows/desktop/aa365198.aspx) 的方案,通常简称为 **IOCP**,操作系统负责管理线程池,其性能非常优异,所以**在 Windows 中 JDK 直接采用了 IOCP 的支持**,使用系统支持,把更多的操作信息暴露给操作系统,也使得操作系统能够对我们的 IO 进行一定程度的优化。
+在 Windows 操作系统中,提供了一个叫做[I/O Completion Ports](https://msdn.microsoft.com/en-us/library/windows/desktop/aa365198.aspx)的方案,通常简称为**IOCP**,操作系统负责管理线程池,其性能非常优异,所以**在 Windows 中 JDK 直接采用了 IOCP 的支持**,使用系统支持,把更多的操作信息暴露给操作系统,也使得操作系统能够对我们的 IO 进行一定程度的优化。
> 在 Linux 中其实也是有异步 IO 系统实现的,但是限制比较多,性能也一般,所以 JDK 采用了自建线程池的方式。
本文还是以实用为主,想要了解更多信息请自行查找其他资料,下面对 Java 异步 IO 进行实践性的介绍。
-总共有三个类需要我们关注,分别是 **AsynchronousSocketChannel**,**AsynchronousServerSocketChannel** 和 **AsynchronousFileChannel**,只不过是在之前介绍的 FileChannel、SocketChannel 和 ServerSocketChannel 的类名上加了个前缀 **Asynchronous**。
+总共有三个类需要我们关注,分别是**AsynchronousSocketChannel**,**AsynchronousServerSocketChannel**和**AsynchronousFileChannel**,只不过是在之前介绍的 FileChannel、SocketChannel 和 ServerSocketChannel 的类名上加了个前缀**Asynchronous**。
Java 异步 IO 提供了两种使用方式,分别是返回 Future 实例和使用回调函数。
diff --git "a/docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\344\270\216NIO\350\257\246\350\247\243\357\274\232\345\237\272\344\272\216NIO\347\232\204\347\275\221\347\273\234\347\274\226\347\250\213\346\241\206\346\236\266Netty.md" "b/docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\344\270\216NIO\350\257\246\350\247\243\357\274\232\345\237\272\344\272\216NIO\347\232\204\347\275\221\347\273\234\347\274\226\347\250\213\346\241\206\346\236\266Netty.md"
index e21ceef..fd4cdf2 100644
--- "a/docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\344\270\216NIO\350\257\246\350\247\243\357\274\232\345\237\272\344\272\216NIO\347\232\204\347\275\221\347\273\234\347\274\226\347\250\213\346\241\206\346\236\266Netty.md"
+++ "b/docs/java/network-programming/Java\347\275\221\347\273\234\347\274\226\347\250\213\344\270\216NIO\350\257\246\350\247\243\357\274\232\345\237\272\344\272\216NIO\347\232\204\347\275\221\347\273\234\347\274\226\347\250\213\346\241\206\346\236\266Netty.md"
@@ -169,7 +169,7 @@ Encoders和Decoders
因为我们在网络传输时只能传输字节流,因此,在发送数据之前,我们必须把我们的message型转换为bytes,与之对应,我们在接收数据后,必须把接收到的bytes再转换成message。我们把bytes to message这个过程称作Decode(解码成我们可以理解的),把message to bytes这个过程成为Encode。
-Netty中提供了很多现成的编码/解码器,我们一般从他们的名字中便可知道他们的用途,如**ByteToMessageDecoder**、**MessageToByteEncoder**,如专门用来处理Google Protobuf协议的**ProtobufEncoder**、 **ProtobufDecoder**。
+Netty中提供了很多现成的编码/解码器,我们一般从他们的名字中便可知道他们的用途,如**ByteToMessageDecoder**、**MessageToByteEncoder**,如专门用来处理Google Protobuf协议的**ProtobufEncoder**、**ProtobufDecoder**。
我们前面说过,具体是哪种Handler就要看它们继承的是InboundAdapter还是OutboundAdapter,对于**Decoders**,很容易便可以知道它是继承自**ChannelInboundHandlerAdapter**或 ChannelInboundHandler,因为解码的意思是把ChannelPipeline**传入的bytes解码成我们可以理解的message**(即Java Object),而ChannelInboundHandler正是处理Inbound Event,而Inbound Event中传入的正是字节流。Decoder会覆盖其中的“ChannelRead()”方法,在这个方法中来调用具体的decode方法解码传递过来的字节流,然后通过调用ChannelHandlerContext.fireChannelRead(decodedMessage)方法把编码好的Message传递给下一个Handler。与之类似,Encoder就不必多少了。
diff --git a/src/main/java/md/mdToc.java b/src/main/java/md/mdToc.java
index f449fef..0cf8f98 100644
--- a/src/main/java/md/mdToc.java
+++ b/src/main/java/md/mdToc.java
@@ -4,7 +4,7 @@
public class mdToc {
public static void main(String[] args) {
- String path = "D:\\idea_project\\JavaTutorial\\docs\\distributed\\practice\\temp";
+ String path = "D:\\idea_project\\JavaTutorial\\docs\\java\\jvm\\temp";
AtxMarkdownToc.newInstance().genTocDir(path);
}
}