Machine learning is about identifying patterns in data and based on that patterns perform reasoning on unseen data. Caputring maximum patterns for reasing we need to have population instead of sampling. Since we are living in the era where Data is increasing exponentially, analyzing that data on single machine is not an easy game. We have deployed Sparkling water (Killer Application) that uses storage capacity of hadoop, processing power of spark and Machine learning capabilities of h2o.The typical workflow includes hdfs as its data sotrage system, over that spark is used for data processing and h2o is used as Machine Learning engine for predicitve modelling shown as below:

we have used amazon data set for testing purpose on 3 systems(cluster). The data is stored in hdfs(hadoop distributed file system) and then processed with spark finally Machine Learning Model is learned with h2o.
The detail description of each of the step is given below:
[note: we are in developing phase and using three systems as in initial steps and planing to include 60 system in our clusters. Further below is analysis on single machine which we are deploying on the sparkling water cluster we have made]
We have used three machines of i5 machines with 16GB of RAM and 100GB HDD for our cluster. In hadoop cluster one of machines is working as master node, and other two are working as slave nodes. The datanodes have ~100 GB of capacity that combines to ~190GB of storage space. Then we made Spark cluster that works above yarn. All three Machines are included in worker machines to have all capacity of machine for data processing and machine learning process that combine together give ~45GB RAM and 12 core processing speed. The sample images of the configuration can be seen below:
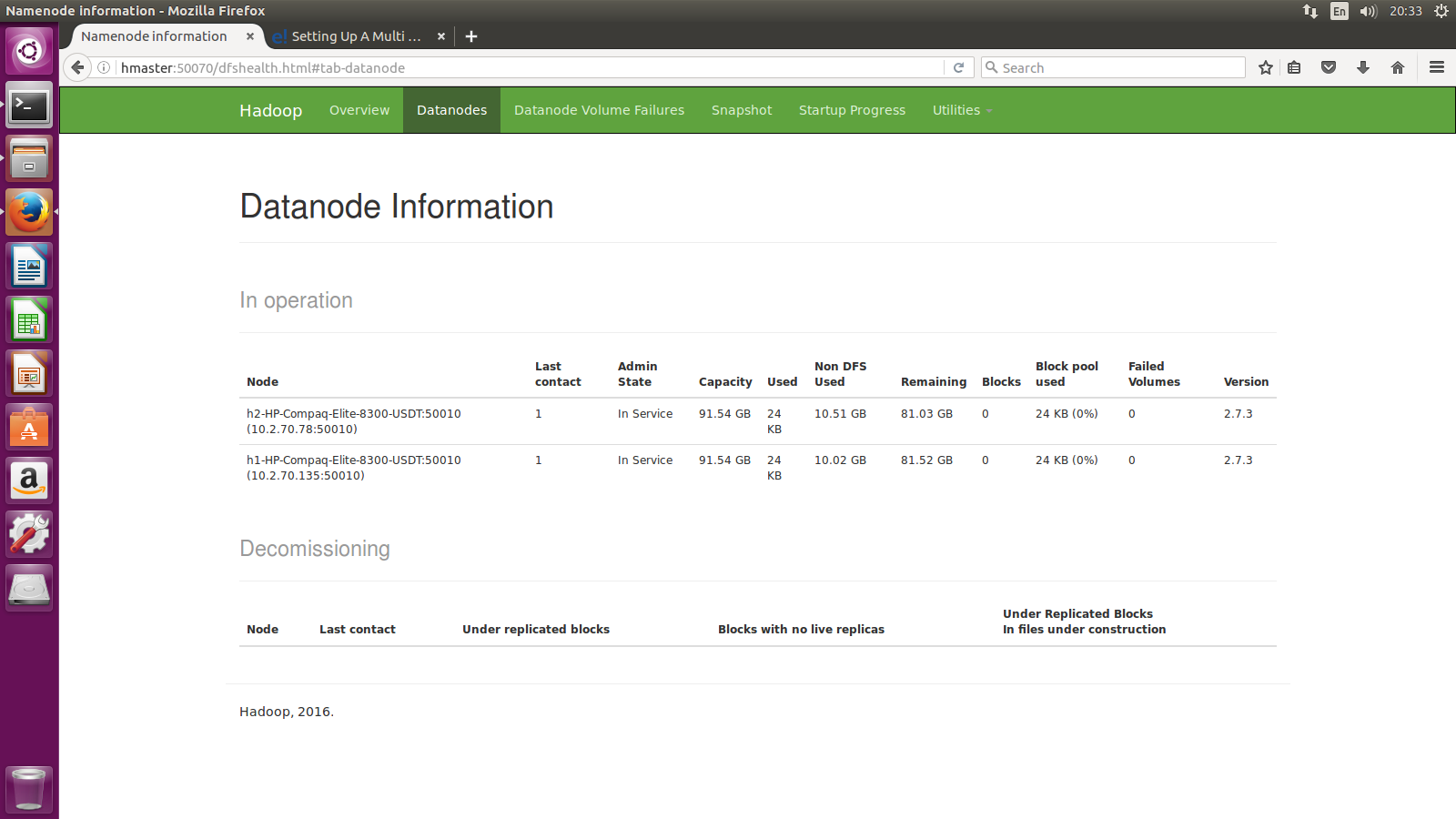
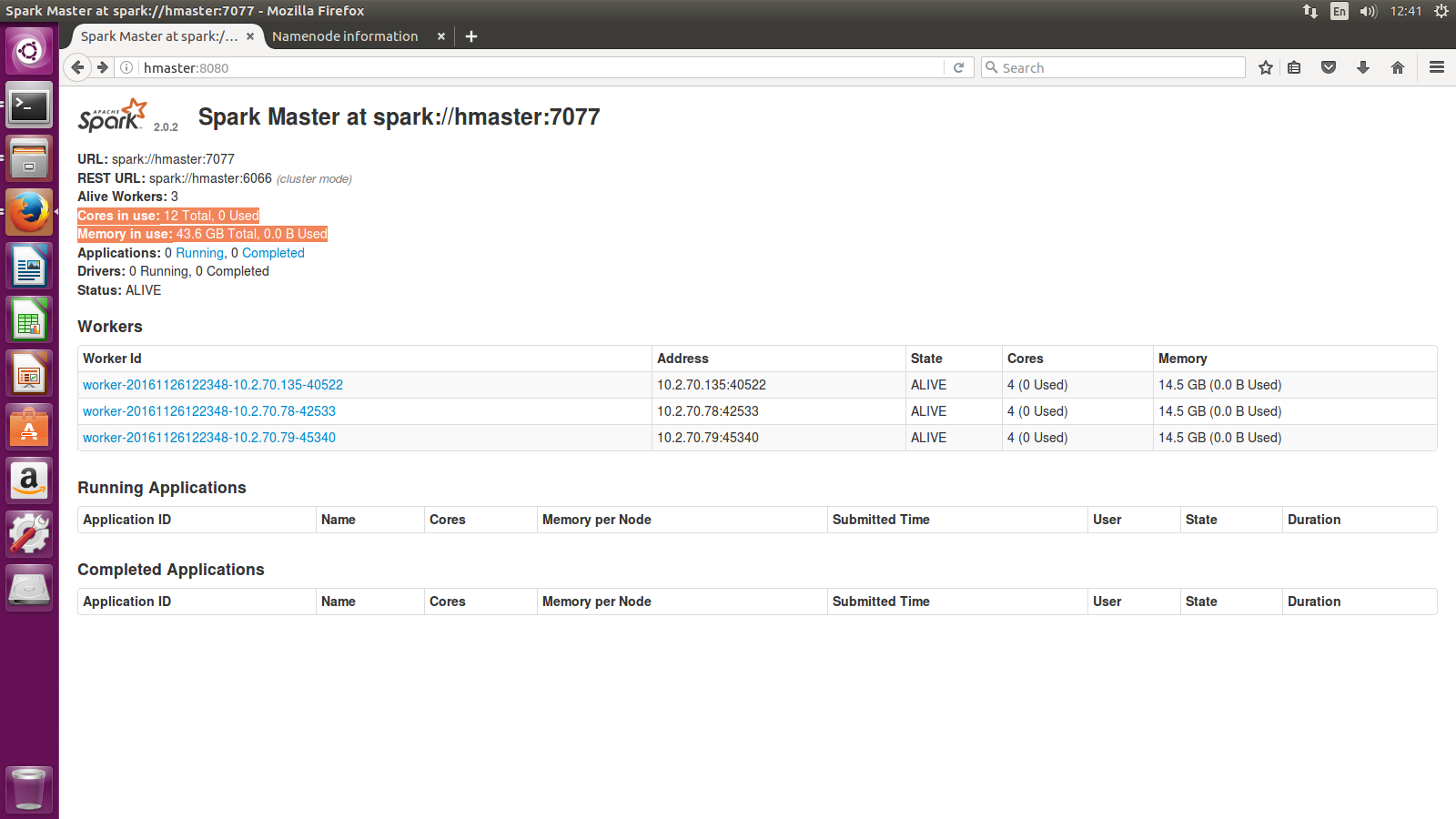
We have used Amazon dataset hosted at kaggle for demon purpose of the above framework. The further analytics can be seen on the link below: https://github.com/hamzafar/machine_learning_at_scale/blob/master/Kaggle/Kaggle.md