分析Jaeger源码主要有以下原因:
- 公司正在使用Jaeger,通过了解其源码,可以更好的把控这套系统。
- 了解分布式系统的设计
- 提升对golang的理解
- 提升个人英语
分析的版本为最新版本0.10.0,时间2017-11-23
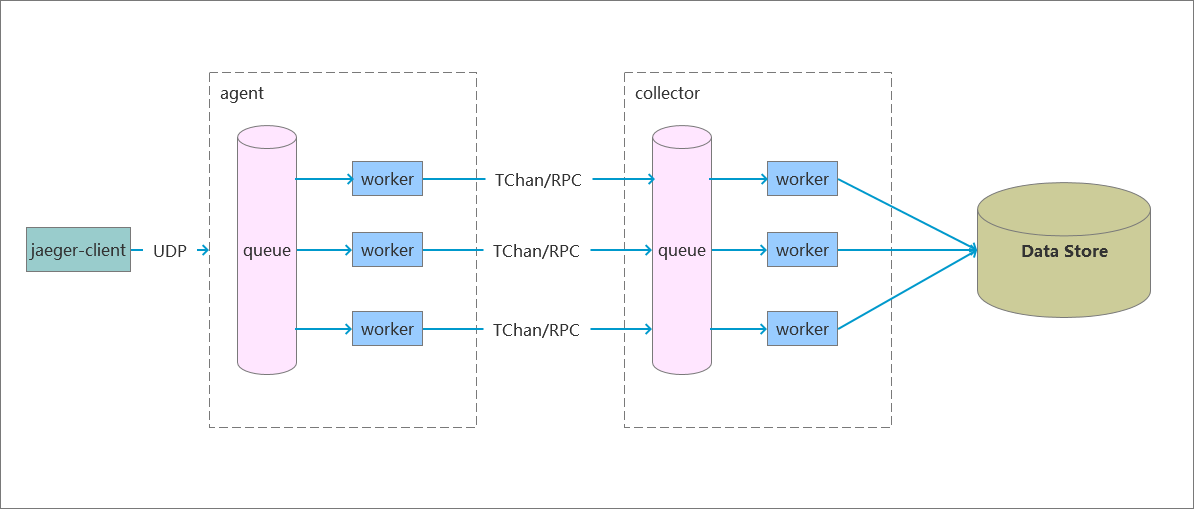
Agent处于jaeger-client和collector之间,属于代理的作用,主要是把client发送过来的数据从thrift转为Batch,并通过RPC批量提交到collector。
github.com/jaegertracing/jaeger/cmd/agent/app/flags.go #35
var defaultProcessors = []struct {
model model
protocol protocol
hostPort string
}{
{model: "zipkin", protocol: "compact", hostPort: ":5775"},
{model: "jaeger", protocol: "compact", hostPort: ":6831"},
{model: "jaeger", protocol: "binary", hostPort: ":6832"},
}-
在agent开启时初始化了3个UDP服务
-
每个服务对应处理不同的数据格式
-
官方推荐使用6831端口接收数据
github.com/jaegertracing/jaeger/cmd/agent/app/servers/tbuffered_server.go #80
func (s *TBufferedServer) Serve() {
atomic.StoreUint32(&s.serving, 1)
for s.IsServing() {
readBuf := s.readBufPool.Get().(*ReadBuf)
n, err := s.transport.Read(readBuf.bytes)
if err == nil {
readBuf.n = n
s.metrics.PacketSize.Update(int64(n))
select {
case s.dataChan <- readBuf:
s.metrics.PacketsProcessed.Inc(1)
s.updateQueueSize(1)
default:
//这里需要注意,如果写比处理快,agent将会扔掉超出的部分数据
s.metrics.PacketsDropped.Inc(1)
}
} else {
s.metrics.ReadError.Inc(1)
}
}
}每一个UDP服务端都有自己单独的队列和worker,每个队列(长度默认1000)都会有50个(协成)worker消费队列的数据,也可以根据系统负载调节队列和worker的大小。
- 增加队列长度(default 1000) --processor.jaeger-compact.server-queue-size
- 增加worker数 (default 50) --processor.jaeger-compact.workers
go初始化一个服务很简单,使用for{}的形式就能实现。但是启动了就要考虑如何关闭,总不能直接强制关闭吧?请求处理了一半被中断,导致脏数据出现,显然不是我们想要的结果,所以有优雅关闭方式。实现优雅关闭的方式大致是:主服务接收信号,然后通知子服务执行完当前操作就不要再执行。
- NSQ
github.com/nsqio/nsq/nsqd/topic.go #215
func (t *Topic) messagePump() {
......
for {
select {
case msg = <-memoryMsgChan:
......
case <-t.exitChan:
goto exit
}
......
}
exit:
t.ctx.nsqd.logf("TOPIC(%s): closing ... messagePump", t.name)
}- Jaeger
func (s *TBufferedServer) Serve() {
atomic.StoreUint32(&s.serving, 1)
for s.IsServing() {
......
}
}在通知子服务要停止执行的实现上,NSQ和Jaeger的子服务都是留出一个入口,主服务通过这个入口通知子服务。不同的是在停止这步上:
NSQ使用chan+goto,exitChan接收到信号,执行goto,跳出for循环。
Jaeger使用原子操作,通过原子操作把s.serving设为0,跳出for循环。
网上有篇博客对临时对象池介绍得挺详细的《GO并发编程实战》—— 临时对象池。临时对象池的作用是:存放可被复用值,减少垃圾回收。
要想发挥对象池的作用,先要确保池子非空。如果从空池子获取值,只会重新New一个值,达不到复用的效果。所以一般用法都是先Get,再Put。
readBuf := s.readBufPool.Get().(*ReadBuf)从上面代码中可以看出Agent是想通过对象池复用“*ReadBuf”,但是并没有看到Put这步,因为这步放在worker那边处理。
github.com/uber/jaeger/cmd/agent/app/servers/tbuffered_server.go #124
func (s *TBufferedServer) DataRecd(buf *ReadBuf) {
s.updateQueueSize(-1)
s.readBufPool.Put(buf)
}为什么不在数据放入队列的时候就把“*ReadBuf”Put到池子呢?这是由当前的场景决定的。 首先“*ReadBuf”是一个指针,第二指针会被放到 chan里,在这种情况下,如果chan出现了数据堆积(worker处理不完队列数据),当Agent接到client数据时,由于复用“*ReadBuf”,就造成了chan的所有数据和新数据一样的错乱问题,例子。所以要想复用值,只能在worker消费了队列数据后再Put回池子。
看完Agent的对象池使用,再来看看NSQ的对象池使用。
github.com/nsqio/nsq/nsqd/topic.go #197
func (t *Topic) put(m *Message) error {
select {
case t.memoryMsgChan <- m:
default:
b := bufferPoolGet()
//b => bp.Get().(*bytes.Buffer)
err := writeMessageToBackend(b, m, t.backend)
bufferPoolPut(b)
......
}
return nil
}这里的使用相对容易理解点,先Get“*bytes.Buffer”,再处理m数据,最后再把“*bytes.Buffer”Put到池中。和Agent不同,writeMessageToBackend不会堆积数据,出现数据错乱的情况。还有一个小细节,当把“*bytes.Buffer”Put到池子再Get出来,b还会保留上次处理的数据,所以NSQ会清空数据,使用一个干净的值。
Agent的服务队列是有长度限制(default 1000),如果堆积超过1000个,Agent就会毫不怜悯的把数据丢掉。当然在这里并没有不妥,Jaeger的定位就是一套日志系统,不太看重数据的可靠性。如果要想减少数据丢失的问题,可通过配置或增加Agent节点。因为Jaeger和NSQ对于数据的定位不一样,所以就不对比这部分功能。NSQ比较注重数据的可靠性。
github.com/jaegertracing/jaeger/cmd/agent/app/processors/thrift_processor.go #104
func (s *ThriftProcessor) processBuffer() {
for readBuf := range s.server.DataChan() {
protocol := s.protocolPool.Get().(thrift.TProtocol)
protocol.Transport().Write(readBuf.GetBytes())
//这步就是把“*ReadBuf”Put到池子
s.server.DataRecd(readBuf) // acknowledge receipt and release the buffer
//将数据从thrift解析成Batch并提交
if ok, _ := s.handler.Process(protocol, protocol); !ok {
// TODO log the error
s.metrics.HandlerProcessError.Inc(1)
}
s.protocolPool.Put(protocol)
}
s.processing.Done()
}这里是一个worker的实现,在启动Agent的时候就初始化了150个worker来处理队列数据。消耗队列使用for + range的方式,不是使用 select + chan的方式,关于这2种方式的使用介绍可以看Go中的Channel——range和select。这里Agent偷懒了,没有考虑到优雅关闭,如果队列堆积了数据,而Agent被重启队列的数据就会丢失。
github.com/jaegertracing/jaeger/thrift-gen/agent/agent.go #187
func (p *agentProcessorEmitBatch) Process(seqId int32, iprot, oprot thrift.TProtocol) (success bool, err thrift.TException) {
args := AgentEmitBatchArgs{}
if err = args.Read(iprot); err != nil {
iprot.ReadMessageEnd()
return false, err
}
iprot.ReadMessageEnd()
var err2 error
if err2 = p.handler.EmitBatch(args.Batch); err2 != nil {
return true, err2
}
return true, nil
}解析thrift是一件很麻烦的事,这种格式的数据是给机器看得,需要按照指定的格式一步一步解析出来,不像Json那么方便,但是thrift又确实能减少占用的空间。
github.com/jaegertracing/jaeger/thrift-gen/jaeger/tchan-jaeger.go #39
func (c *tchanCollectorClient) SubmitBatches(ctx thrift.Context, batches []*Batch) ([]*BatchSubmitResponse, error) {
var resp CollectorSubmitBatchesResult
args := CollectorSubmitBatchesArgs{
Batches: batches,
}
success, err := c.client.Call(ctx, c.thriftService, "submitBatches", &args, &resp)
if err == nil && !success {
switch {
default:
err = fmt.Errorf("received no result or unknown exception for submitBatches")
}
}
return resp.GetSuccess(), err
}Agent把数据提交到Collector是通过RPC框架TChannel,框架由Uber开发,使用TChannel,Agent可以把数据批量提交到Collector。这个框架提供了一个很有用的特性:上下文传输。为什么呢?说说我们遇到的一个问题:RPC开发的接口,业务方按需传入函数的参数调用即可,这样的方式在前期业务不会产生问题。但是随着公司发展,版本的迭代,一个接口需要按照客户端版本进行兼容是很常见的事情,这样就存在一个问题,作为RPC的服务端和业务方的调用是跨进程,在上下文没有保持一致的时候,RPC服务端不知道客户端版本,很难对此进行兼容。是增加参数?还是增加另一个服务化接口?这些方法都不够友好,最好是在不需要业务方改动的情况下处理这个问题,这时上下文传输就体现它的作用了。
不怜悯数据在Jaeger随处可见,从上面代码可以看出,如果提交失败,数据也一样丢失,没有重试,没有重新放入队列等操作。
Collector收集数据,把数据保存进数据库,虽然职责不一样,但在程序设计上和Agent是一样的,可以从它们的实现上看出属于不同开发人员分工开发完成。下面我们也是分3步拆解Collector的实现。
Collector是使用TChannel实现的RPC服务端,在启动时就开启了2个基于TCP的RPC服务,一个用来接收Jaeger格式数据,一个接收Zipkin格式数据。
github.com/jaegertracing/jaeger/cmd/collector/main.go # 100
......
ch, err := tchannel.NewChannel(serviceName, &tchannel.ChannelOptions{})
if err != nil {
logger.Fatal("Unable to create new TChannel", zap.Error(err))
}
server := thrift.NewServer(ch)
zipkinSpansHandler, jaegerBatchesHandler := handlerBuilder.BuildHandlers()
server.Register(jc.NewTChanCollectorServer(jaegerBatchesHandler))
server.Register(zc.NewTChanZipkinCollectorServer(zipkinSpansHandler))
portStr := ":" + strconv.Itoa(builderOpts.CollectorPort)
listener, err := net.Listen("tcp", portStr)
if err != nil {
logger.Fatal("Unable to start listening on channel", zap.Error(err))
}
ch.Serve(listener)
......github.com/jaegertracing/jaeger/cmd/collector/app/span_handler.go #69
func (jbh *jaegerBatchesHandler) SubmitBatches(ctx thrift.Context, batches []*jaeger.Batch) ([]*jaeger.BatchSubmitResponse, error) {
responses := make([]*jaeger.BatchSubmitResponse, 0, len(batches))
for _, batch := range batches {
mSpans := make([]*model.Span, 0, len(batch.Spans))
for _, span := range batch.Spans {
mSpan := jConv.ToDomainSpan(span, batch.Process)
mSpans = append(mSpans, mSpan)
}
oks, err := jbh.modelProcessor.ProcessSpans(mSpans, JaegerFormatType)
if err != nil {
return nil, err
}
......
}
return responses, nil
}这里就是RPC服务端接收数据的地方,经过处理后数据会被放入到队列。
github.com/jaegertracing/jaeger/pkg/queue/bounded_queue.go #76
func (q *BoundedQueue) Produce(item interface{}) bool {
if atomic.LoadInt32(&q.stopped) != 0 {
q.onDroppedItem(item)
return false
}
select {
case q.items <- item:
atomic.AddInt32(&q.size, 1)
return true
default:
if q.onDroppedItem != nil {
q.onDroppedItem(item)
}
return false
}
}在这里Collector对队列的操作进行了抽象封装成BoundedQueue,对读代码带来了便利。BoundedQueue的实现基于 select + chan和Agent的队列有相同的功能,在生产和消费基础上实现了优雅停止队列和查看队列长度。Collector队列的数据堆积到2000条,也会毫不怜悯的把数据丢掉。当然这些也是可以调节的:
-
--collector.queue-size (default 2000)
-
--collector.num-workers (default 50)
github.com/jaegertracing/jaeger/pkg/queue/bounded_queue.go #53
func (q *BoundedQueue) StartConsumers(num int, consumer func(item interface{})) {
var startWG sync.WaitGroup
for i := 0; i < num; i++ {
q.stopWG.Add(1)
startWG.Add(1)
go func() {
startWG.Done()
defer q.stopWG.Done()
for {
select {
case item := <-q.items:
atomic.AddInt32(&q.size, -1)
consumer(item)
case <-q.stopCh:
return
}
}
}()
}
startWG.Wait()
}这里有一步不是很明白,为什么要使用”startWG“确认worker启动完成?不用会出现什么问题?
官方回复:
to ensure all consumer goroutines are running by the time we return from this function
优雅关闭队列方式:close(q.stopCh)
github.com/jaegertracing/jaeger/plugin/storage/cassandra/spanstore/writer.go #122
func (s *SpanWriter) WriteSpan(span *model.Span) error {
ds := dbmodel.FromDomain(span)
mainQuery := s.session.Query(
insertSpan,
ds.TraceID,
ds.SpanID,
ds.SpanHash,
ds.ParentID,
ds.OperationName,
ds.Flags,
ds.StartTime,
ds.Duration,
ds.Tags,
ds.Logs,
ds.Refs,
ds.Process,
)
if err := s.writerMetrics.traces.Exec(mainQuery, s.logger); err != nil {
return s.logError(ds, err, "Failed to insert span", s.logger)
}
if err := s.saveServiceNameAndOperationName(ds.ServiceName, ds.OperationName); err != nil {
// should this be a soft failure?
return s.logError(ds, err, "Failed to insert service name and operation name", s.logger)
}
......
return nil
}在把ServiceName和OperationName保存到cassandra的时候做了特别的操作,使用LRU算法进行缓存。这一步缓存应该是为了减少对cassandra查询,减少查询压力。
github.com/jaegertracing/jaeger/plugin/storage/cassandra/spanstore/service_names.go #69
func (s *ServiceNamesStorage) Write(serviceName string) error {
var err error
query := s.session.Query(s.InsertStmt)
if inCache := checkWriteCache(serviceName, s.serviceNames, s.writeCacheTTL); !inCache {
q := query.Bind(serviceName)
err2 := s.metrics.Exec(q, s.logger)
if err2 != nil {
err = err2
}
}
return err
}Collector在建立缓存的顺序上先放入缓存再放入数据库。查询方式:key/value。
既然是缓存就会有失效时间(default 12h),而Jaeger默认保存数据2天,所以是否会存在重复保存出错的情况?因为serviceName是主键索引。
CREATE TABLE IF NOT EXISTS jaeger_v1_dc.service_names (
service_name text,
PRIMARY KEY (service_name)
)这种情况出现在mysql必定会报错,但在cassandra就不会有这种情况。
- cassandra
cqlsh:jaeger_v1_dc> select * from service_names1;
service_name
--------------
test
(1 rows)
S lsh:jaeger_v1_dc> INSERT INTO service_names1 (service_name) VALUE
... ('test');
- mysql
mysql> select * from service_names1;
+--------------+
| service_name |
+--------------+
| test |
+--------------+
1 row in set (0.00 sec)
mysql> insert into service_names1 (service_name) values ('test');
ERROR 1062 (23000): Duplicate entry 'test' for key 'PRIMARY'
惊奇吧?虽然没有报错,但也会保证唯一性。有兴趣的同学可简单了解一下基本用法,语法和mysql很像。关于cassandra我们也是摸着石头过河,不做过多描述。
| NSQ | Jaeger | |
|---|---|---|
| 目录名 | 小写/下划线 | 小写/中横线 |
| 函数名 | 小驼峰 | 小驼峰 |
| 文件名 | 下划线 | 下划线 |
| 变量 | 小驼峰 | 小驼峰 |
| 常量 | 小驼峰 | 小驼峰 |
| 包名 | 当前目录名 | 当前目录名 |
| 请求地址 | 下划线 | *小写 |
| 请求参数 | *小写 | 小驼峰 |
| 返回参数 | 下划线 | 小驼峰 |
| 命令行参数 | 中横线 | 前缀+点+中横线 |
打”*“是由于没有找到足够多的参照例子。
Jaeger向我展示了很多东西:UDP使用,优雅关闭,临时对象池,LRU算法实现等。不单单是golang方面,还有程序设计、服务设计上,Agent、Collector、Query3个服务的职责都很单一,这应该是来源微服务思想的划分。有很多东西需要自行消化,也有很多东西我没有注意到,只看个人好奇的部分,但收获也挺多。总结就是:Get到知识了!!