2.1 基于规则的方法(github上demo项目的多数方法)
2.2 基于信息抽取的方法(CCKS和NLPCC比赛中方法总结)
知识图谱(Knowledge Base / Knowledge Graph)中包括三类元素:实体(entity)、关系(relation),以及属性(literal)。实体代表一些人或事物,关系用于连接两个实体,表征它们之间的一些联系,如实体Michael Crichton与实体Chicago之间就可以由关系bornin连接,代表作家Michael Crichton出生于城市Chicago。同时,关系不仅可以用于连接两个实体,也可以连接实体和某属性,如关系area可用于连接Chicago和属性606km2,表明chicago面积为606km2。 用更形式化的语言来描述:KB可以表示为三元组的集合,三元组为(entity,relation,entity/literal)。
工业界的KBQA系统目的是为用户提供一个用自然语言来提问的界面,使用他们的自己的术语以及语言习惯,通过查询知识图谱得到一个简洁精确的答案。Introduction to Neural Network based Approaches for Question Answering over Knowledge Graphs
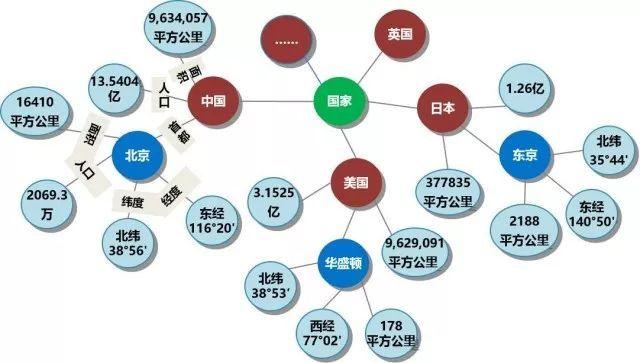
没有固定的工业界数据集,工业界的图谱都是通过自己领域内累积的业务数据或是自己建立的app数据进行整理,同时基于产品需求进行建立的,针对图谱的问题多来自企业客服或是app收集的问题,这部分来源未知。以下对工业界使用的知识图谱做一个总括说明,同时介绍两个权威的中文知识图谱问答比赛CCKS和NLPCC所用的知识库和数据集。
工业界的知识图谱有两种分类方式,第一种是根据领域的覆盖范围不同分为通用知识图谱和领域知识图谱。其中通用知识图谱注重知识广度,领域知识图谱注重知识深度。通用知识图谱常常覆盖生活中的各个领域,从衣食住行到专业知识都会涉及,但是在每个领域内部的知识体系构建不是很完善;而领域知识图谱则是专注于某个领域(金融、司法等),结合领域需求与规范构建合适的知识结构以便进行领域内精细化的知识存储和问答。代表的知识图谱分别有:
- 通用知识图谱
- Google Knowledge Graph
- Microsoft Satori & Probase
- 领域知识图谱
- Facebook 社交知识图谱
- Amazon 商品知识图谱
- 阿里巴巴商品知识图谱
- 上海交大学术知识图谱
第二种分类方式是按照回答问题需要的知识类别来定义的,分为常识知识图谱和百科全书知识图谱。针对常识性知识图谱,我们只会挖掘问题中的词之间的语义关系,一般而言比较关注的关系包括 isA Relation、isPropertyOf Relation,问题的答案可能根据情景不同而有不同,所以回答正确与否往往存在概率问题。而针对百科全书知识图谱,我们往往会定义很多谓词,例如DayOfbirth, LocatedIn, SpouseOf 等等。这些问题即使有多个答案,这些答案往往也都是确定的,所以构建这种图谱在做问答时最优先考虑的就是准确率。代表的知识图谱分别有:
- 常识知识图谱
- WordNet, KnowItAll, NELL, Microsoft Concept Graph
- 百科全书知识图谱
- Freebase, Yago, Google Knowledge Graph
- 问题类型:简单问题:复杂问题(多跳推理问题)=1:1
- 训练集:2298
- 验证集:766
- 测试集:766
- 资源地址:知识库 密码(huc8),问答集
| 名次 | 队伍 | F1 | 论文链接 | 参考解读/源代码 |
|---|---|---|---|---|
| 1 | jchl (百度智珠尹存祥团队) | 0.73545 | 混合语义相似度的中文知识图谱问答系统 | |
| 2 | hlt217 (SUDA-HUAWEI) | 0.73075 | Combining Neural Network Models with Rules for Chinese Knowledge Base Question Answering | |
| 3 | 网易互娱AIlab-陈垚鑫 | 0.72514 | ||
| 4 | baseline (平安人寿AI-FudanSDS) | 0.70448 | Multi-Module System for Open Domain Chinese Question Answering over Knowledge Base | https://zhuanlan.zhihu.com/p/92317079 |
| 5 | DUTIR | 0.67683 | DUTIR中文开放域知识库问答评测报告 | https://github.com/duterscmy/ccks2019-ckbqa-4th-codes |
| 名次 | 队伍 | F1 | 论文链接 | 参考解读/源代码 |
|---|---|---|---|---|
| 1 | Keenpower | 0.66609 | A QA search algorithm based on the fusion integration of text similarity and graph computation⋆ | https://github.com/songlei1994/ccks2018 |
| 2 | KPQA | 0.66359 | ||
| 3 | zhanghualiang | 0.57666 | ||
| 4 | LEQA | 0.57666 | A Joint Model of Entity Linking and Predicate Recognition for Knowledge Base Question Answering | |
| 5 | xiehe | 0.57266 | ||
| 6 | huawencai | 0.57051 | ||
| 7 | COINQA | 0.56930 | Semantic Parsing for Multiple-relation Chinese Question Answering |
这个企业内部没有具体写明,提到的都在学术界有使用,这里给出CCKS和NLPCC比赛的测评方法
-
Mean Reciprocal Rank (MRR)
- |Q|代表问题总数,rank_i代表第一个正确的答案在答案集合C_i中的位置
- 如果C_i中没有正确答案,
-
Accuracy@N
- 当答案集合C_i中至少有一个出现在gold answerA_i中,
,否则为0
- 当答案集合C_i中至少有一个出现在gold answerA_i中,
-
Averaged F1
- F_i是Q_i问题产生答案的F1值,如果A_i和C_i无交集F1为0
代表项目:豆瓣影评问答
- 实体识别
- 词表 ,字符串相似度(或BiLSTM-CRF)
- 属性链接
- 词表,字符串相似度 (或CNN等分类模型)
- 答案推理
- 规则模板转换得到SPARQL语句
- (或TransE表示学习的方法进行答案推理)
这种模型首先通过实体识别等方法获得问句中实体的 mention,再通过主办方提供的数据库中 mention2ent 及其他信息通过实体链接 mention 到数据库中对应实体列表,通过多种设计的打分函数最终选取一个或多个与问句最相关的实体作为核心实体,用于之后生成关系、查询语句等。
在获得中心实体后,此类系统先得到该实体在数据库中的邻居子图,并抽取出邻居子图中所有的关 系作为候选。对于这些关系,系统同样使用设计好的打分函数来评估每一者与问题的契合性(关系模型)
同时,此类模型也大多采用一个问题类型识别模块以提高表现。数据集中的问题可以分为单跳问 题与多跳问题,多跳问题在查询图结构上也有多种形式;通过训练,问题类型识别模型能够将问句分类到相应的查询图结构模板上。这些有了这些模板信息,便可以根据之前获得的关系取打分高的一个(如果问题类型为单跳)或多个(如果类型为多跳)作为结果,将其与中心实体对应的查询路径填入最终查询数据库得到答案。
与上一个模型类似,同样需要实体识别识别出问题的中心实体,通过问题类别识别确定问题的类型,同时通过实体链接将中心实体链接到知识图谱中的实体中。而在关系模型中,本方法并不直接选取最优关系,而是直接获取所有能匹配上问题类型模板的,在中心实体周边的查询路径;之后,通过各类基于问句与查询路径特征来给后者打分,并选取最优查询路径的模型,最终答案便可以求得。
按照上述的规则方法,实体与关系识别方法以及路径匹配方法同时进行回答,在答案选取的时候选择置信度高的进行回答。
-
实体识别
这部分主要由自定义的识别规则和神经网络训练的方法构成
- 规则
- 自定义字典(分词,词频,倒排索引)识别
- 建立停用词表删去无用词
- 分词后的词与知识图谱的实体的字符串匹配(jaccord,编辑距离)
- 辅助工具
- NER工具包识别问句中人名,地点,机构等
- 神经网络
- Bert/BiLSTM + CRF
- 规则
-
实体链接
主要方法是通过选用一部分特征作为特征参数(a1, a2, ..., an),使用线性打分排序(s=k1a1 + k2a1 + ... + knan)或者简单机器学习算法进行排序。
- 选用特征
- 实体名称和问题的字符串匹配度(char/word)
- 图谱子图与问题的匹配度
- 实体类型与问题的匹配度
- 实体长度
- 实体在图谱中关系个数/出现频率
- 实体与疑问词距离
- ...
- 模型
- lambdarank
- xgboost
- logistic regression
- 选用特征
-
关系模型1:关系识别与排序(1/2hop)
- 关系和问题的语义相似度(bert-bilstm-fc-cosine)
- 关系值和问题的语义相似度(bert-bilstm-fc-cosine)
- 关系和问题的字符覆盖率
-
关系模型2:路径排序
- 将链接到的实体和 实体的1/2跳关系 组成路径,通过bert-similarity模型进行训练
- 路径与问题的jaccard,编辑距离
- 自身定义的模板匹配度...
-
关系模型3:规则匹配排序
- 将问题分割为多个部分,参照word/phrases in the kb + existing word segmentation tools,将问题分为各部分都和kb中实体/属性/关系相似的部分,按分值高低与知识图谱对应部分进行链接。
- 将问题分为单跳,多跳类型(共8种),记录下各自的结构,与问题中分割出的问题结构进行相似度比较
-
问题类型识别
- bert/cnn/rnn分类模型确定单跳/多跳种类
[1] NLPCC2015 1st Ye Z, Jia Z, Yang Y, et al. Research on open domain question answering system[M]//Natural Language Processing and Chinese Computing. Springer, Cham, 2015: 527-540.
[2] NLPCC2016 1st Lai Y, Lin Y, Chen J, et al. Open domain question answering system based on knowledge base[M]//Natural Language Understanding and Intelligent Applications. Springer, Cham, 2016: 722-733.
[3] NLPCC2016 2nd Yang F, Gan L, Li A, et al. Combining deep learning with information retrieval for question answering[M]//Natural Language Understanding and Intelligent Applications. Springer, Cham, 2016: 917-925.
[4] NLPCC2016 3rd Xie Z, Zeng Z, Zhou G, et al. Knowledge base question answering based on deep learning models[M]//Natural Language Understanding and Intelligent Applications. Springer, Cham, 2016: 300-311.
[5] NLPCC2016 4th Wang L, Zhang Y, Liu T. A deep learning approach for question answering over knowledge base[M]//Natural Language Understanding and Intelligent Applications. Springer, Cham, 2016: 885-892.
[6] NLPCC2017 1st Lai Y, Jia Y, Lin Y, et al. A Chinese question answering system for single-relation factoid questions[C]//National CCF Conference on Natural Language Processing and Chinese Computing. Springer, Cham, 2017: 124-135.
[7] NLPCC2017 2nd Zhang H, Zhu M, Wang H. A Retrieval-Based Matching Approach to Open Domain Knowledge-Based Question Answering[C]//National CCF Conference on Natural Language Processing and Chinese Computing. Springer, Cham, 2017: 701-711.
[8] NLPCC2017 会议 周博通, 孙承杰, 林磊, et al. 基于LSTM的大规模知识库自动问答[J]. 北京大学学报:自然科学版, 2018.
[9] NLPCC2018 1st Ni H, Lin L, Xu G. A Relateness-Based Ranking Method for Knowledge-Based Question Answering[C]//CCF International Conference on Natural Language Processing and Chinese Computing. Springer, Cham, 2018: 393-400.
[10] CCKS2018 1st A QA Search Algorithm based on the Fusion Integration of Text Similarity and Graph Computation
[11] CCKS2018 2nd A Joint Model of Entity Linking and Predicate Recognition for Knowledge Base Question Answering
[12] CCKS2018 3rd Semantic Parsing for Multiple-relation Chinese Question Answering
[13] CCKS2019 1st 混合语义相似度的中文知识图谱问答系统
[14] CCKS2019 2nd Combining Neural Network Models with Rules for Chinese Knowledge Base Question Answering
[15] CCKS2019 3rd Multi-Module System for Open Domain Chinese Question Answering over Knowledge Base
[16] CCKS2019 4th DUTIR中文开放域知识库问答评测报告