![]()
As of 7 March 2024 Google has released a new official Bayesian MMM version called Meridian. Meridian is currently under limited availability for selected advertisers. Please visit this site or contact your Google representative for more information. LMMM version will be sunset once Meridian has reached general availability.
LMMM is a python library that helps organisations understand and optimise marketing spend across media channels.



Docs • Introduction • Theory • Getting Started • References • Community Spotlight
Marketing Mix Modeling (MMM) is used by advertisers to measure advertising effectiveness and inform budget allocation decisions across media channels. Measurement based on aggregated data allows comparison across online and offline channels in addition to being unaffected by recent ecosystem changes (some related to privacy) which may affect attribution modelling. MMM allows you to:
- Estimate the optimal budget allocation across media channels.
- Understand how media channels perform with a change in spend.
- Investigate effects on your target KPI (such as sales) by media channel.
Taking a Bayesian approach to MMM allows an advertiser to integrate prior information into modelling, allowing you to:
- Utilise information from industry experience or previous media mix models using Bayesian priors.
- Report on both parameter and model uncertainty and propagate it to your budget optimisation.
- Construct hierarchical models, with generally tighter credible intervals, using breakout dimensions such as geography.
The LightweightMMM package (built using Numpyro and JAX) helps advertisers easily build Bayesian MMM models by providing the functionality to appropriately scale data, evaluate models, optimise budget allocations and plot common graphs used in the field.
An MMM quantifies the relationship between media channel activity and sales, while controlling for other factors. A simplified model overview is shown below and the full model is set out in the model documentation. An MMM is typically run using weekly level observations (e.g. the KPI could be sales per week), however, it can also be run at the daily level.
Where kpi is typically the volume or value of sales per time period,
The LightweightMMM can either be run using data aggregated at the national level (standard approach) or using data aggregated at a geo level (sub-national hierarchical approach).
-
National level (standard approach). This approach is appropriate if the data available is only aggregated at the national level (e.g. The KPI could be national sales per time period). This is the most common format used in MMMs.
-
Geo level (sub-national hierarchical approach). This approach is appropriate if the data can be aggregated at a sub-national level (e.g. the KPI could be sales per time period for each state within a country). This approach can yield more accurate results compared to the standard approach because it uses more data points to fit the model. We recommend using a sub-national level model for larger countries such as the US if possible.
It is likely that the effect of a media channel on sales could have a lagged effect which tapers off slowly over time. Our powerful Bayesian MMM model architecture is designed to capture this effect and offers three different approaches. We recommend users compare all three approaches and use the approach that works the best. The approach that works the best will typically be the one which has the best out-of-sample fit (which is one of the generated outputs). The functional forms of these three approaches are briefly described below and are fully expressed in our model documentation.
- Adstock: Applies an infinite lag that decreases its weight as time passes.
- Hill-Adstock: Applies a sigmoid like function for diminishing returns to the output of the adstock function.
- Carryover: Applies a causal convolution giving more weight to the near values than distant ones.
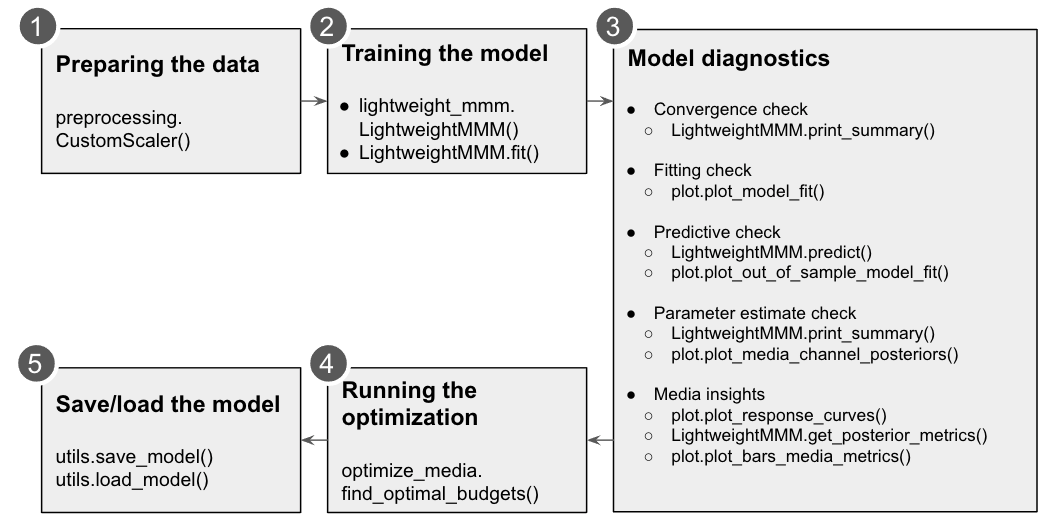
The recommended way of installing lightweight_mmm is through PyPi:
pip install --upgrade pip
pip install lightweight_mmmIf you want to use the most recent and slightly less stable version you can install it from github:
pip install --upgrade git+https://github.com/google/lightweight_mmm.git
If you are using Google Colab, make sure you restart the runtime after installing.
Here we use simulated data but it is assumed you have your data cleaned at this point. The necessary data will be:
- Media data: Containing the metric per channel and time span (eg. impressions per time period). Media values must not contain negative values.
- Extra features: Any other features that one might want to add to the analysis. These features need to be known ahead of time for optimization or you would need another model to estimate them.
- Target: Target KPI for the model to predict. For example, revenue amount, number of app installs. This will also be the metric optimized during the optimization phase.
- Costs: The total cost per media unit per channel.
# Let's assume we have the following datasets with the following shapes (we use
the `simulate_dummy_data` function in utils for this example):
media_data, extra_features, target, costs = utils.simulate_dummy_data(
data_size=160,
n_media_channels=3,
n_extra_features=2,
geos=5) # Or geos=1 for national modelScaling is a bit of an art, Bayesian techniques work well if the input data is small scale. We should not center variables at 0. Sales and media should have a lower bound of 0.
ycan be scaled asy / jnp.mean(y).mediacan be scaled asX_m / jnp.mean(X_m, axis=0), which means the new column mean will be 1.
We provide a CustomScaler which can apply multiplications and division scaling
in case the wider used scalers don't fit your use case. Scale your data
accordingly before fitting the model.
Below is an example of usage of this CustomScaler:
# Simple split of the data based on time.
split_point = data_size - data_size // 10
media_data_train = media_data[:split_point, :]
target_train = target[:split_point]
extra_features_train = extra_features[:split_point, :]
extra_features_test = extra_features[split_point:, :]
# Scale data
media_scaler = preprocessing.CustomScaler(divide_operation=jnp.mean)
extra_features_scaler = preprocessing.CustomScaler(divide_operation=jnp.mean)
target_scaler = preprocessing.CustomScaler(
divide_operation=jnp.mean)
# scale cost up by N since fit() will divide it by number of time periods
cost_scaler = preprocessing.CustomScaler(divide_operation=jnp.mean)
media_data_train = media_scaler.fit_transform(media_data_train)
extra_features_train = extra_features_scaler.fit_transform(
extra_features_train)
target_train = target_scaler.fit_transform(target_train)
costs = cost_scaler.fit_transform(unscaled_costs)In case you have a variable that has a lot of 0s you can also scale by the mean
of non zero values. For instance you can use a lambda function to do this:
lambda x: jnp.mean(x[x > 0]). The same applies for cost scaling.
The model requires the media data, the extra features, the costs of each media unit per channel and the target. You can also pass how many samples you would like to use as well as the number of chains.
For running multiple chains in parallel the user would need to set
numpyro.set_host_device_count to either the number of chains or the number of
CPUs available.
See an example below:
# Fit model.
mmm = lightweight_mmm.LightweightMMM()
mmm.fit(media=media_data,
extra_features=extra_features,
media_prior=costs,
target=target,
number_warmup=1000,
number_samples=1000,
number_chains=2)If you want to change any prior in the model (besides the media prior which you
are already specifying always), you can do so with custom_priors:
# See detailed explanation on custom priors in our documentation.
custom_priors = {"intercept": numpyro.distributions.Uniform(1, 5)}
# Fit model.
mmm = lightweight_mmm.LightweightMMM()
mmm.fit(media=media_data,
extra_features=extra_features,
media_prior=costs,
target=target,
number_warmup=1000,
number_samples=1000,
number_chains=2,
custom_priors=custom_priors)Please refer to our documentation on custom_priors for more details.
You can switch between daily and weekly data by enabling
weekday_seasonality=True and seasonality_frequency=365 or
weekday_seasonality=False and seasonality_frequency=52 (default). In case
of daily data we have two types of seasonality: discrete weekday and smooth
annual.
Users can check convergence metrics of the parameters as follows:
mmm.print_summary()The rule of thumb is that r_hat values for all parameters are less than 1.1.
Users can check fitting between true KPI and predicted KPI by:
plot.plot_model_fit(media_mix_model=mmm, target_scaler=target_scaler)If target_scaler used for preprocessing.CustomScaler() is given, the target
would be unscaled. Bayesian R-squared and MAPE are shown in the chart.
Users can get the prediction for the test data by:
prediction = mmm.predict(
media=media_data_test,
extra_features=extra_data_test,
target_scaler=target_scaler
)Returned prediction are distributions; if point estimates are desired, users
can calculate those based on the given distribution. For example, if data_size
of the test data is 20, number_samples is 1000 and number_of_chains is 2,
mmm.predict returns 2000 sets of predictions with 20 data points. Users can
compare the distributions with the true value of the test data and calculate
the metrics such as mean and median.
Users can get detail of the parameter estimation by:
mmm.print_summary()The above returns the mean, standard deviation, median and the credible interval for each parameter. The distribution charts are provided by:
plot.plot_media_channel_posteriors(media_mix_model=mmm, channel_names=media_names)channel_names specifies media names in each chart.
Response curves are provided as follows:
plot.plot_response_curves(media_mix_model=mmm, media_scaler=media_scaler, target_scaler=target_scaler)If media_scaler and target_scaler used for preprocessing.CustomScaler() are given, both the media and target values would be unscaled.
To extract the media effectiveness and ROI estimation, users can do the following:
media_effect_hat, roi_hat = mmm.get_posterior_metrics()media_effect_hat is the media effectiveness estimation and roi_hat is the ROI estimation. Then users can visualize the distribution of the estimation as follows:
plot.plot_bars_media_metrics(metric=media_effect_hat, channel_names=media_names)plot.plot_bars_media_metrics(metric=roi_hat, channel_names=media_names)For optimization we will maximize the sales changing the media inputs such that the summed cost of the media is constant. We can also allow reasonable bounds on each media input (eg +- x%). We only optimise across channels and not over time. For running the optimization one needs the following main parameters:
n_time_periods: The number of time periods you want to simulate (eg. Optimize for the next 10 weeks if you trained a model on weekly data).- The model that was trained.
- The
budgetyou want to allocate for the nextn_time_periods. - The extra features used for training for the following
n_time_periods. - Price per media unit per channel.
media_gaprefers to the media data gap between the end of training data and the start of the out of sample media given. Eg. if 100 weeks of data were used for training and prediction starts 2 months after training data finished we need to provide the 8 weeks missing between the training data and the prediction data so data transformations (adstock, carryover, ...) can take place correctly.
See below and example of optimization:
# Run media optimization.
budget = 40 # your budget here
prices = np.array([0.1, 0.11, 0.12])
extra_features_test = extra_features_scaler.transform(extra_features_test)
solution = optimize_media.find_optimal_budgets(
n_time_periods=extra_features_test.shape[0],
media_mix_model=mmm,
budget=budget,
extra_features=extra_features_test,
prices=prices)Users can save and load the model as follows:
utils.save_model(mmm, file_path='file_path')Users can specify file_path to save the model.
To load a saved MMM model:
utils.load_model(file_path: 'file_path')To cite this repository:
@software{lightweight_mmmgithub,
author = {Pablo Duque and Dirk Nachbar and Yuka Abe and Christiane Ahlheim and Mike Anderson and Yan Sun and Omri Goldstein and Tim Eck},
title = {LightweightMMM: Lightweight (Bayesian) Marketing Mix Modeling},
url = {https://github.com/google/lightweight_mmm},
version = {0.1.6},
year = {2022},
}
As LMMM is not an official Google product, the LMMM team can only offer limited support.
For questions about methodology, please refer to the References section or to the FAQ page.
For issues installing or using LMMM, feel free to post them in the Discussions or Issues tabs of the Github repository. The LMMM team responds to these questions in our free time, so we unfortunately cannot guarantee a timely response. We also encourage the community to share tips and advice with each other here!
For feature requests, please post them to the Discussions tab of the Github repository. We have an internal roadmap for LMMM development but do pay attention to feature requests and appreciate them!
For bug reports, please post them to the Issues tab of the Github repository. If/when we are able to address them, we will let you know in the comments to your issue.
Pull requests are appreciated but are very difficult for us to merge since the code in this repository is linked to Google internal systems and has to pass internal review. If you submit a pull request and we have resources to help merge it, we will reach out to you about this!
-
How To Create A Marketing Mix Model With LightweightMMM by Mario Filho.
-
How Google LightweightMMM Works and A walkthrough of Google’s LightweightMMM by Mike Taylor.