1/25 Mon.
- Multi-Agent Reinforcement Learning 자료 정리
- Multi-Agent Reinforcement Learning
- Shared Experience Actor-Critic for Multi-Agent Reinforcement Learning - link
: 서로 다른 policy의 결과를 모아 학습하는 Shared Experience Actor-Critic(SEAC)를 활용하여 Multi-Agent RL 문제를 해결
: Level-Based Foraging, Multi-Robot Warehouse 환경과 그 환경에 대한 SEAC 적용 방법이 있는 코드 공유 - 코드 link
: local gradient를 공유하고 동시에 비슷한 policy를 학습하여 기존 RL 알고리즘(IAC, SNAC)보다 학습 속도가 빠르고 최대 보상값이 큼
: 기존에는 하나의 기기에 대해서만, 혹은 알고리즘을 활용하여 Robotic mobile fullfillment system(RMFS)를 해결하였는데 이를 multi-agent에 대해 해결함
- Shared Experience Actor-Critic for Multi-Agent Reinforcement Learning - link
- Multi-Agent Reinforcement Learning
1/26 Tue.
- 다뤄볼만한 RMFS 문제
- 하나의 agent에 대해 알고리즘 방식과 강화학습 방식을 실행해보고 비교
- SEAC에 curriculum learning, Hierarchical Deep Reinforcement Learning 등 다른 방법을 적용하여 단계적으로 학습하게 함
- jetbot을 활용해 충돌하지 않고 짐 옮기는 과정 실행 (가상 환경, 실제 환경) - 위아래양옆뿐만 아니라 다양한 방향으로 이동?
- 개발 목표
- jetbot simulation 환경에서 RMFS 환경 구성 후 배포
- SEAC 논문 코드를 보고, 학습 과정을 이해하고 학습 이후 동작 모습을 rendering
-
Shared Experience Actor-Critic for Multi-Agent Reinforcement Learning - 코드 link
: robotic_warehouse/robotic_warehouse/에서 python3 warehouse.py로 학습 과정 확인
: robotic_warehouse/tests/의 test_movement.py로 이동 시 거리, 초기값 등 확인 -
DeepSoccer - github link
: 강화학습을 할 수 있는 가상 환경 참고- Gazebo error
dusty-nv 레퍼지토리 맨 아래 해보기
- 12: build jetson-inference git clone 뒤부터, deepsoccer git clone 한 후 catkin_make, source하기
- Gazebo error
1/27 Wed.
-
DeepSoccer
- Gazebo error
- Jetbot model 불러오기 (dusty-nv repository)
mkdir .gazebo/models , gazebo model editor에서 링크 추가하여 해결
- Deepsoccer CMake error
gazebo-ros 관련 문제가 있어 issue를 올려두었다.
- Gazebo error
-
Isaac Sim
- 권한 설정 문제 해결 : 이전에 파일이 만들어지지 않는 문제가 발생하였는데, Devtalk Community에 같은 문제에 대한 해결방법이 나와 있어 참고하여 해결하였다.
- 아래 사진과 같이 강화 학습 예제가 잘 동작함을 확인하였다. 내일은 코드를 구체적으로 살펴보고 RMFS 가상 환경을 구현할 방법을 구체화할 예정이다.

1/28 Thur, 1/29 Fri.
- 연구 진행 상황 중간 보고 자료 제출 (앞으로의 연구 주제 및 방향 확정)
2/1 Mon.
- Isaac Sim 공부
- youtube
- Isaac Sim 2020: Deep Dive : AWS로 Isaac Sim을 실행하는 방법과 외부 로봇을 import, 조작할 수 있는 방법 소개
- Isaac Sim 2020.2 Omniverse Robotics App : Isaac Sim tutorial 내용 소개
- 공식 tutorial - link
- Sample Applications
- CAD에서 Sample을 불러오고 stage, layer를 활용해 센서 부착, 물리 효과 추가 등을 하는 방법
- Simple Robot Navigation
setup: _create_robot()으로 환경 구성, _on_setup_fn()으로 로봇 컨트롤러 구성
update: 명령에 따라 목적지로 이동
- Rigging a Robot : CAD에서 부품을 불러온 후 결합하는 방법
- Assets
- warehouse sample 환경

- STR 로봇
/Isaac/Robots/STR

- warehouse sample 환경
- Python Samples
- Basic Time Stepping : CONFIG로 env 불러오기 → kit.play (simulation 시작) → callback 정의 → kit.update
- Synthetic Data Generation
- 임의로 box 만들고 이미지 처리를 하여 보여줌

- 이미지 학습도 가능
- 임의로 box 만들고 이미지 처리를 하여 보여줌
- Reinforcement Training
- 기존의 gym과 비슷하게 동작한다. 하지만 기존 언어와 명령어가 다른 점이 많아 각각 어떤 내용인지 확인해야겠다.
- jetbot_train.py, jetracer_train.py의 학습 과정 이해하기 + robotic_warehouse의 warehouse.py 내용 적용하기

2/2 Tue.
- Isaac Sim 공부
- Reinforcement Training
- jetbot_train.py : 흰색 벽과의 거리가 0이 되도록 강화 학습

- jetracer_train.py : 주어진 선에서 벗어나지 않고 트랙을 돌도록 강화 학습

- jetbot_train.py : 흰색 벽과의 거리가 0이 되도록 강화 학습
- Simple Navigation RL: RFS 환경을 만들기에 앞서, 예제에 있는 Simple Navigation을 강화학습 형태로 구현해보려고 한다.
- 예제 코드 주소 : isaac-sim-2020.2.2007-linux-x86_64-release/_build/linux-x86_64/release/exts/omni.isaac.samples/omni/isaac/samples
- warehouse.py, jetbot_train.py, jetracer_train.py의 코드를 보고 각각 함수 내용을 정리하였다.


- Reinforcement Training
2/3 Wed.
- Isaac Sim으로 간단한 프로그램 만들기
: STR 로봇이 A 지점에서 B 지점으로 이동하면 보상을 주는 간단한 강화학습 프로그램을 만들어보았다.- Isaac Sim에서 데이터를 가져오는 방법


위와 같은 방식으로 Pose, linear_velocity, local_linear_velocity, angular_velocity를 얻는다. Pose의 p는 position, r는 rotation을 의미한다. - 간단한 강화학습 프로그램 제작
: jetbot, jetracer 예제를 바탕으로 코드 내용을 이해하고 바꾸어 아래와 같이 STR을 warehouse env에서 사용하는 프로그램을 제작하였다.

그런데 python에서 새로운 물체(warehouse의 짐)를 추가한다거나 옮길 수 있는 방법을 모르겠어서 현실적으로 RMFS를 구현하기는 어려워보인다. (Isaac Sim에서 사용할 수 있는 함수에 대한 설명이 부족하다.) Isaac Sim 대신 ROS를 활용하거나 jetbot에서 직접 사용하는 방법으로 바꿔야 할 것 같다.
- Isaac Sim에서 데이터를 가져오는 방법
2/4 Thu.
-
공항 등에서 활용되는 로봇 주차에 대해 조사 RMFS 환경과 유사하게, Jetbot을 활용해 로봇 주차 환경을 만들 수 있겠다는 생각이 들었다. Ray, stan이라는 공항 주차 로봇이 이미 있다고 한다. - link

-
openai ROS 공부
- DeepSoccer에서 사용한 openai ROS에 대해 찾아보고 tutorial을 해보았다. - tutorial
- training script와 env script가 서로 독립적(학습 방식, 학습 환경 따로)으로 되어있고 training script는 python으로 되어 있어 GPU를 사용한 강화학습이 가능하다.
- 아래 사진과 같이 벽 앞에서 부딪히지 않고 회피하는 예제를 해보고 있는데 에러가 발생하여 동작하지 않는 중이다.

2/5 Fri.
-
openai ROS 공부
-
tutorial TurtleBot2Maze-v0 환경에서 로봇이 미로를 탈출하는 tutorial을 구현하였다. 환경을 불러오지 못하는 문제가 있었는데, 아래와 같이 코드를 작성해 환경 정보가 담긴 turtlebot_maze.py에 추가하여 해결하였다.
gym.error.UnregisteredEnv: No registered env with id: TurtleBot2Maze-v0
register( id='TurtleBot2Maze-v0', entry_point='openai_ros.task_envs.turtlebot2.turtlebot2_maze:TurtleBot2MazeEnv', )
결과: EP: 500 - [alpha: 0.1 - gamma: 0.7 - epsilon: 0.55] - Reward: -127 Time: 1:22:42 -
새로운 환경 만드는 방법
-
AI RL script : 학습 방법
- yaml config file에 task_and_robot_environment_name, ros_ws_abspath 입력
- AI RL script에 아래와 같이 입력
from openai_ros.openai_ros_common import StartOpenAI_ROS_Environment # Init OpenAI_ROS ENV task_and_robot_environment_name = rospy.get_param('/turtlebot2/task_and_robot_environment_name') env = StartOpenAI_ROS_Environment(task_and_robot_environment_name)
-
Task environment : 전체 학습 환경
- task_envs에 mkdir [환경 이름]/config/, parameter 내용이 저장된 yaml 파일을 config에 놓기
- World launch : 'task_env/your_task/your_task.py'를 생성하여 robot을 제외한 env을 불러온다. init에서 yaml의 params load, launch script
- Task environment registration : openai_ros_common.py에서 사용할 시뮬레이션 환경을 ‘git embedded files’로 입력, task_envs_list.py에서 환경 register
-
Robot Environment : 로봇
- 다른 코드를 참고하여 robot_envs 폴더에 YOUR_ROBOT.py 파일을 만들고 ROSLauncher로 spawn robot
- Task environment registration과 같이 openai_ros_common.py 변경
-
-
jetbot 환경 설치
jetbot_ros를 참고하여 로봇 환경을 설치하려 하였는데, jetson NvInfer.h를 찾지 못한다는 에러와 catkin_make가 되지 않는 에러가 발생하였다. TensorRT가 필요해보이는데, jetbot에서는 잘 동작하고 있기 때문에 데스크탑에서 설치하는 것은 포기하였다. jetbot 로봇 대신 임시적으로 turtlebot을 활용해 환경을 구현해야겠다.
2/8 Mon.
-
openai ROS 다른 환경 test 및 공부
-
-
Turtlebot3

-
error
- 예제에서 제공하는 환경들이 python 2에서 만들어져 대부분 에러가 발생한다. (turtlebot3만 python3로 실행 가능)
ImportError: dynamic module does not define module export function (PyInit__tf2)
- 아래 에러는 Task Environment 파일의 timestep_limit을 max_episode_steps로 바꾸어 해결하였다.
TypeError: init() got an unexpected keyword argument 'timestep_limit'
- 아래 에러를 해결하기 위해 config 파일에서 경로를 지정해주었다.
AssertionError: You forgot to set ros_ws_abspath in your yaml file of your main RL script. Set ros_ws_abspath: 'YOUR/SIM_WS/PATH'
task_and_robot_environment_name: 'TurtleBot2Maze-v0' ros_ws_abspath: "/home/jwk/catkin_ws"- re-register 문제: task_env안의 파일의 register 위에 코드 추가
gym.error.Error: Cannot re-register id: TurtleBot3World-v0
import gym env_dict = gym.envs.registration.registry.env_specs.copy() for env in env_dict: if 'TurtleBot3World-v0' in env: print("Remove {} from registry".format(env)) del gym.envs.registration.registry.env_specs[env]- 강제종료 후에도 gazebo가 실행되는 문제
alias killgazebo="killall -9 gazebo & killall -9 gzserver & killall -9 gzclient"
-
-
turtlebot2, turtlebot3의 환경과 학습 과정 공부
- 환경 정보 (turtlebot2_maze.py)

- 학습 과정 (start_training.py)

- 직접 만든 gazebo 환경을 my_turtlebot2_training에 적용

- 환경 : gazebo 실행 후 제작, worlds 파일에 .world로 저장
- 경로 지정 : turtlebot2_maze.py에서 roslaunch되는 start_world_maze_loop_brick.launch -> world_file 경로 수정
- 환경 정보 (turtlebot2_maze.py)
-
-
계획 변경
- gazebo 환경 제작 방법 공부 - tutorial
- 박스가 놓아져 있을 때 로봇이 빈 장소를 찾아 짐을 놓고 돌아오는 프로그램 제작 (가장 간단한 방법)
- (추가) 로봇 수 늘리기, 빈 자리 늘리기, 실제 로봇에 적용
-
시뮬레이터에서 학습한 모델을 실제 세상에서 활용하는 방법
- jetbot line tracing
isaac sim 안에서는 jetbot의 카메라 정보를 바탕으로 학습하고 모델을 저장한다. 이 모델을 사용하여 실제 세상에서도 카메라로 본 정보를 바탕으로 예측, 이동한다.
카메라 정보, 실제 세상 간에 카메라로 보이는 모습의 차이가 있기 때문에 VAE를 활용해 차이를 줄인다. - Deepsoccer: Lidar sensor 정보 이용, 원리는 같다.
- jetbot line tracing
2/9 Tue.
- Gazebo tutorial 내용
- Worlds 파일 만들기 → my_world.launch, empty_world.world 생성
- gazebo_models에서 공개된 모델 open source들을 이용할 수 있음, url 부분을 변경하여 추가 (include)
- static: 고정, false면 play했을 때 중력 영향
- size로 크기 변경
- model 폴더에 meshes/something.stl 추가 → mesh를 추가하면 물체의 근처에만 box가 생기게 됨
- texture 추가: materials 추가, 그 안에 scripts, textures 폴더 추가하고 scripts에 .material, textures에 .png 추가하면 모델에 색이 칠해짐.
- robot 정보 : urdf 파일, .xacro에 로봇 정보
- .urdf → robot name 지정 → link, joint로 구성
- .launch에서 초기 위치 지정, node 불러옴
- rviz에서 확인 가능, rviz 변경 사항을 save as config로 저장하고 경로 지정하면 반영됨
- child link로 물체 연결, node 안에서 use_gui를 true로 설정 → joint 위치 변경 가능
- sdf는 특정 모델의 내용을 담음 (ex. chair의 각 요소들) .world에서 sdf 파일을 가져와 실행 가능
2/15 Mon.
-
gazebo_models의 공개된 모델 중 사용할만한 모델 추리기
- robot
warehouse robot: ,
cart_front_steer:
,
cart_front_steer: 
- parking
parking_garage: ,
prius_hybrid:
,
prius_hybrid:  ,
,
hatchback: ,
suv:
,
suv: 
- ware
cardboard_box: ,
euro_pallet:
,
euro_pallet: 
- robot
-
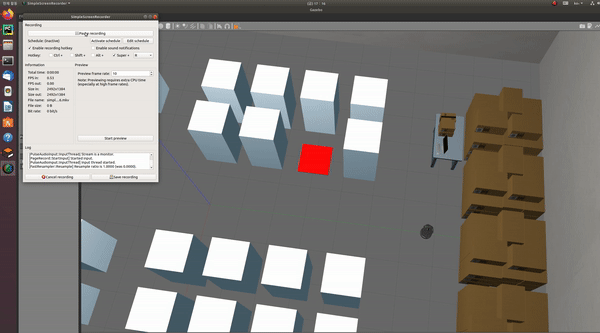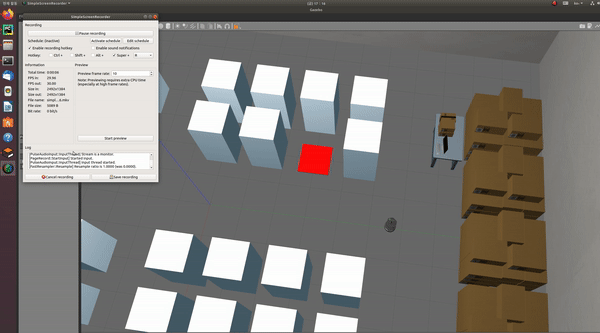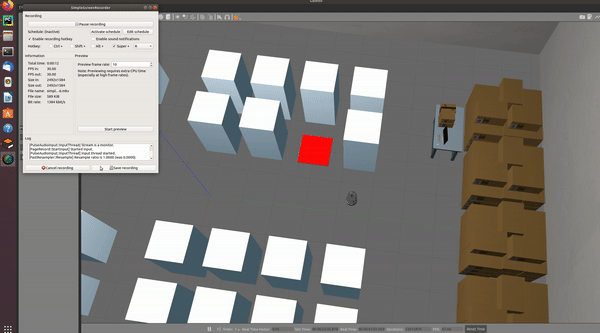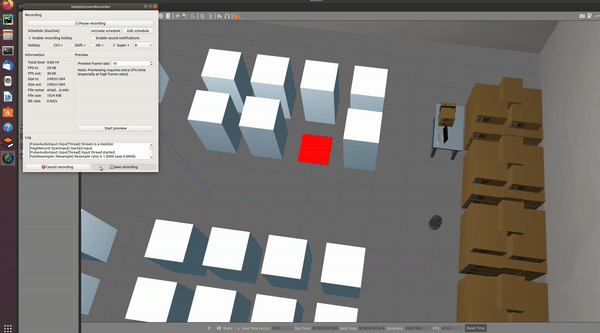
아래 사진과 같은 warehouse world 환경을 만들었다.

- 물품을 놓는 부분을 box로 표시하였고 필요에 따라 붉은색, 초록색으로 변경할 수 있다.
- 물품이 쌓여 있는 앞 부분이 station으로, 로봇이 근처에 도달하면 보상을 주는 방식으로 만들 계획이다.
- 아래 사진과 같이 물품을 운반하는 로봇과 물품이 필요하다. 직접 만들어보고 안 될 경우 turtlebot을 사용할 것이다.
- 그 전에 먼저 RWARE 환경에서 어떻게 필요한 물품을 선택, 결정하여 운반하고 보상을 부여하는지 공부해야 한다.


2/16 Tue.
-
RWARE 환경의 action, reward 이해
- Direction, Action(앞,옆,이동x,연결)으로 구성되어 있다.
- 특정 지점에 가면 자동으로 물품과 연결되는 것이 아니라, action 중에 TOGGLE_LOAD라는 연결/해제하는 행동이 있다.
-
warehouse world 환경에서 로봇 동작시키기
-
기존 turtlebot2_training의 world를 warehouse world 환경으로 변경하였다.
- catkin_ws/src/turtlebot/turtlebot_gazebo에서 start_world_maze_loop_brick.launch파일의 world 지정 위치을 worlds의 maze_loop_brick에서 no_roof_small_warehouse로 바꿈
- no_roof_small_warehouse.world에 maze_loop_brick의 지면을 추가
-
아래 사진과 같이 warehouse world 환경에서 로봇이 동작하는 것을 확인하였다.

-
로봇이 타일 위에 올라갔을 때 색을 바꿀 수 있게 하는 기능이 필요하고, 물품을 운반하는 로봇과 물품을 만들지는 못할 것 같다.
-
gazebo service를 활용하여 모델의 특징을 변경하는 방법을 찾았는데, ROS에 대한 이해가 부족하여 남은 기간 동안 하지 못할 것 같다.
-
일단 간단한 형태로 물품이 쌓여있을 때 로봇을 출발 지점에서 32개의 지점 중 하나의 빈 지점으로 이동시키는 환경을 제작하고 학습시켜 보아야겠다.
- /home/jwk/catkin_ws/src/turtlebot/turtlebot_gazebo/worlds의 no_roof_small_warehouse.world 수정하기
- train의 reward 주는 방식
-
2/17 Wed.
- 간단한 warehouse 환경 완성

-
물품의 크기를 1,1,3으로 하고 light blue 색을 칠하였다. 빈 공간은 1,1,0.03의 크기로 하고 빨간색을 칠하였다.
- 색 변경 방법: RGB값을 255로 나눈 값을 형식으로 적어 넣었다. - 참고
- /home/jwk/catkin_ws/src/turtlebot/turtlebot_gazebo/launch의 put_robot_in_world.launch 파일에서 로봇의 초기 위치 변경함.
-
빨간색으로 칠한 부분까지 도착하는 것을 목표로 하는 task를 제작하였다.
-
Gazebo 위에서 모델의 위치를 GetModelState service로 얻었다. 상대적인 거리만 얻을 수 있어 지면과의 상대적 거리를 사용하였다. - 참고
from gazebo_msgs.srv import GetModelState self.model_coordinates = rospy.ServiceProxy('/gazebo/get_model_state', GetModelState) coordinates = self.model_coordinates('mobile_base', 'ground_plane') x_loc=coordinates.pose.position.x y_loc=coordinates.pose.position.y -
벽에 충돌하거나 목표 지점에 도착하면 train이 끝난다. 간단하게 goal과의 distance만 사용하는 방법으로는 잘 동작하지 않아 아래와 같이 Corner에 도착할 때마다 보상을 바꾸는 방식을 활용하였다.
distance_to_goal = (x_loc+3.5)**2+(y_loc+4.5)**2 distance_to_corner1 = (y_loc+1)**2 distance_to_corner2 = (x_loc+4.5)**2 if not done: if y_loc > 0: reward = math.exp(1/distance_to_corner1) elif y_loc <= 0 and x_loc > -3.5: reward = math.exp(1/distance_to_corner2) elif y_loc <= 0 and x_loc <= -3.5: reward = math.exp(1/distance_to_goal)
-
-
2/18 Thu.
-
총 step 수 늘리기
start_training.py의 n_episodes 변수를 변경. n_steps는 변경하였을 때 env reset이 되지 않는 에러가 발생한다. (초기 설정: nepisodes: 500, nsteps: 10000) -
training result 확인 방법
- wrappers.Monitor에서 훈련 결과를 training_results에 저장한다.

- wrappers.Monitor에 video_callable=lambda episode_id: True를 추가하여 episode 녹화를 하려고 하였는데, 'NameError: name 'open' is not defined'가 발생한다. 해결 방법을 모르겠어서 포기하였다.
- 그 대신, episode를 매우 크게(10000000000000) 하고 녹화하는 방식을 사용하기로 하였다.
- wrappers.Monitor에서 훈련 결과를 training_results에 저장한다.
-
회전하는 시간을 최소화하기 위해 앞으로 갈 경우 reward가 높아지게 함 (아래의 코드를 추가함)
if self.last_action == "FORWARDS": reward = reward * self.forwards_reward else: reward = reward * self.turn_reward -
Lidar 정보만으로는 학습이 되지 않아 observation에 위치 정보를 추가함
discretized_observations.append(x_loc) discretized_observations.append(y_loc)
2/19 Fri.
- 하루 동안 학습시켰는데, 초기와 거의 변화가 없다. Q-learning 대신 다른 알고리즘을 사용해야 하는 것으로 보인다.
- 목표지점을 좀 더 가까운 곳으로 설정하였고 완수한 시간이 빠를수록 보상을 높게 주는 조건을 추가하였다.

timepast = (time.time()-self.start_time)/5+1 if not done: reward = math.exp(1/distance_to_goal)/timepast else: if distance_to_goal < 1: reward = self.end_episode_points/timepast else: reward = -1*self.end_episode_points*timepast
학습 결과, 아래와 같이 목표 지점으로 이동하는 것을 확인하였다.