Se han hecho muchos esfuerzos para tratar de "desesgazar" los datos y crear un modelo "justo". Pero, ¿qué es la equidad? ¿Y cómo se puede traducir esto en aprendizaje automático?
Escrito por Sofia Kypraiou Publicado en 13 de septiembre de 2021.
La equidad en el aprendizaje automático ha atraído la atención de los investigadores de las comunidades de IA, ingeniería de software y derecho, con un aumento constante de trabajos relacionados en los últimos años. Se han hecho muchos esfuerzos para tratar de "desesgazar" los datos y crear un modelo "justo". Pero, ¿qué es la equidad? ¿Y cómo puede esto traducirse en aprendizaje automático?
Para empezar, empecemos por lo que no es. La equidad no es un concepto técnico o estadístico y nunca puede haber una herramienta o un software que pueda "eliminar completamente el sesgo" de los datos o hacer que un modelo sea "justo". La equidad es un concepto ético y por tanto contextual. En el mejor de los casos, podemos seleccionar algún ideal de lo que significa ser "justo" en un contexto específico, y luego avanzar hacia su satisfacción en nuestro contexto particular.
Podemos comenzar por examinar la ciencia y la investigación de datos a través de la lente del poder. Preguntar justo a quién, para quién, por quién y con cuyos intereses y metas están en el centro de los datos, el modelo y el sistema. Las respuestas a estas preguntas son contextuales tanto en la sociedad como en las matemáticas, y son el núcleo de un proceso de diseño básico y ético.
 |
 |
|---|---|
| Equidad e Igualdad en el Derecho Internacional de los Derechos Humanos. Ilustración de la Sección de Derechos de la Mujer y Género del ACNUDH. |
Existen diferentes escuelas de pensamiento acerca de la equidad y la toma de decisiones éticas. En la actualidad, existen más de 80 pautas éticas diferentes para la IA. En matemáticas, según el último recuento, hay 21 definiciones matemáticas de equidad. Así como no existe una definición única de equidad o ética, tampoco existen acuerdos claros sobre qué definición aplicar en cada situación individual. Estas definiciones pueden incluso anularse entre sí en lo que se denomina el teorema de la imposibilidad1, que establece que no más de una de las tres métricas de equidad (asignaciones de riesgo) de paridad demográfica, paridad predictiva y probabilidades igualadas pueden ser válidas al mismo tiempo para un bien. clasificador calibrado2. Por lo tanto, es necesario realizar compensaciones.
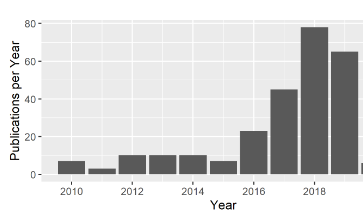 Number of publications related to fairness in ML3
Number of publications related to fairness in ML3
Pero, ¿por qué hay tantas definiciones? ¿Por qué un mismo caso puede ser considerado justo según unas definiciones e injusto según otras?
Para explorar, veamos tres métricas de equidad diferentes, dos para grupos y una para individuos, veamos dónde difieren conceptualmente, dónde funcionan y qué brechas crean.
Usaremos el ejemplo de las solicitudes de empleo entre grupos de candidatos masculinos y femeninos.
Una forma de ver la equidad es usar métricas de equidad de grupo (o propiedad estadística de grupo), donde "los grupos deben recibir tratamientos o resultados similares", lo que significa que grupos como hombres o mujeres deben recibir tasas de aceptación de trabajo similares.
Dos definiciones populares son la paridad demográfica y las probabilidades igualadas:4
Esto significa que las tasas de aceptación de los solicitantes de los dos grupos deben ser iguales (por ejemplo, el 50 % de los solicitantes masculinos y el 50 % de las femeninas obtienen el puesto).
- Existe un precedente de directriz detrás de este razonamiento, llamado la regla de los cuatro quintos7: las mujeres que solicitan y son contratadas deben ser no menos de cuatro quintos de los hombres que obtienen el trabajo.
- Beneficios inmediatos y de largo plazo: la intervención reequilibra las cifras (en este caso) de contrataciones de mujeres y hombres. Esto puede tener beneficios a largo plazo también.8
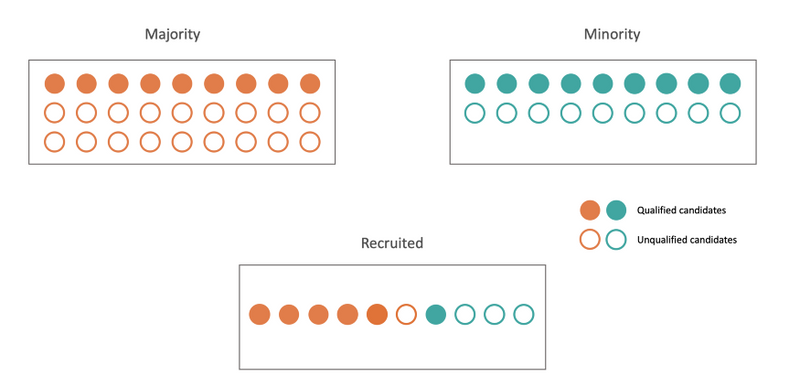 Paridad demográfica (con pereza)9
Paridad demográfica (con pereza)9
- La noción permite que un clasificador seleccione solicitantes calificados en el grupo demográfico A=0, pero no calificados en A=1, siempre que los porcentajes de aceptación coincidan. El escenario anterior puede surgir de forma natural cuando hay menos datos de entrenamiento disponibles sobre un grupo minoritario. Como resultado, la empresa que contrata podría tener una mejor comprensión de a quién contratar en el grupo mayoritario, mientras que en esencia adivina al azar dentro de la minoría. 10
- Somos conscientes del sesgo histórico que puede tener un impacto en nuestros datos y debemos tener un plan en acción para apoyar al grupo históricamente marginado.
Por ejemplo, la Universidad de Oxford tiene como objetivo mejorar la diversidad mediante la admisión de más estudiantes de entornos desfavorecidos. Su plan también incluye apoyo extra para estudiantes de entornos desfavorecidos antes de comenzar sus estudios de grado.
La probabilidad de que se contrate a un candidato calificado y la probabilidad de que no se contrate a un candidato no calificado debe ser la misma para hombres y mujeres.
- En comparación con el ejemplo de la paridad demográfica, si una gran cantidad de candidatos masculinos no calificados solicitan el puesto, la contratación de candidatas calificadas en otros grupos protegidos no se ve afectada. A diferencia de la paridad demográfica, donde simplemente contratamos 50-50 al azar y eso cuenta como equidad, esta definición selecciona entre las personas adecuadas de ambos grupos para contratar. Por lo tanto, penaliza la pereza, porque penaliza la contratación de candidatos no calificados.
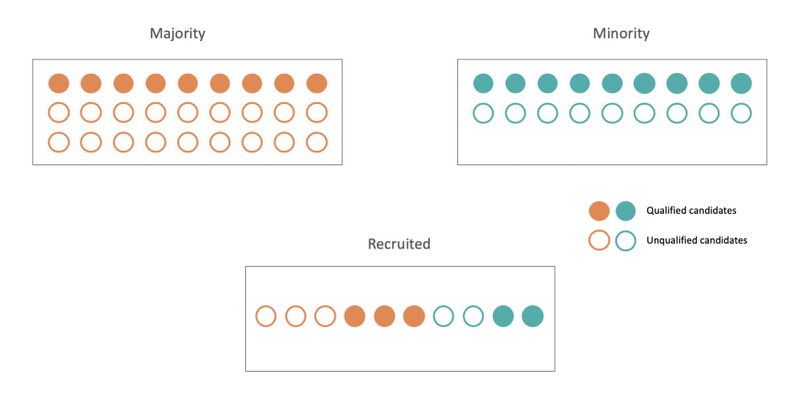 Equalized odds 13
Equalized odds 13
- Un clasificador de probabilidades equitativas debe clasificar a todos tan mal como el grupo más difícil, por lo que cuesta más del doble en este caso. Esto también conduce a una asignación de puestos de trabajo más conservadora, por lo que es un poco más difícil conseguir el trabajo para las personas de todos los grupos que se adaptan al trabajo.14
- Todavía podría no ayudar a cerrar la brecha entre los 2 grupos a largo plazo.
Suponga que el grupo A tiene 100 postulantes y 58 de ellos están calificados, mientras que el grupo B también tiene 100 postulantes pero solo 2 de ellos están calificados. Si la empresa decide aceptar 30 solicitantes y satisfacer la igualdad de oportunidades, se otorgarán 29 ofertas al grupo A mientras que solo se otorgará 1 oferta al grupo B.
Si el trabajo es un trabajo bien remunerado, el grupo A tenderá a tener mejores condiciones de vida y permitir una mejor educación para sus hijos, y así les permitirá estar calificados para esos trabajos bien remunerados cuando crezcan. La brecha entre el grupo A y el grupo B tenderá a agrandarse con el tiempo.
- Hay un fuerte énfasis en predecir correctamente el resultado positivo (por ejemplo: identificar correctamente quién debe obtener un préstamo, ya que genera ganancias para el banco).
- Nos preocupamos mucho por minimizar los falsos positivos costosos (por ejemplo, reducir la concesión de préstamos a personas que no podrían pagar)
Otra forma de definir las métricas de equidad es desde el punto de vista de las personas, denominadas métricas de equidad individuales, en las que “personas similares deben ser tratadas de manera similar”. Usaremos el índice de entropía generalizada, que es una medida de desigualdad (utilizado en economía para medir la distribución del ingreso y la desigualdad económica).
Índice de entropía generalizada 15
Mide qué tan uniformemente se distribuyen los miembros de los grupos de género dentro de las aplicaciones. Un valor de cero representa la igualdad perfecta y los valores más altos indican niveles crecientes de desigualdad.
- La equidad individual es más detallada que cualquier noción de equidad de grupo: impone restricciones en el tratamiento de cada par de individuos.
- Ha sido propuesta como una medida de la desigualdad de ingresos en una población.
- La equidad individual depende completamente de cómo defina la "similitud" entre los solicitantes, y puede correr el riesgo de introducir nuevos problemas de equidad si su métrica de similitud no incluye información importante. Es difícil determinar cuál es una función métrica apropiada para medir la similitud de dos entradas.
- Imagine tres solicitantes de empleo, A, B y C. A tiene una licenciatura y 1 año de experiencia laboral relacionada. B tiene una maestría y 1 año de experiencia laboral relacionada. C tiene una maestría pero no tiene experiencia laboral relacionada. ¿Está A más cerca de B que C? Si es así, por cuánto? Se vuelve aún peor cuando los atributos sensibles (como el género o la raza) entran en juego. ¿Si deberíamos y cómo contar la diferencia de pertenencia al grupo en nuestra función métrica?
Las métricas de equidad suelen enfatizar la equidad individual o grupal, pero no combinan ambas.
Muchos enfoques de la equidad grupal a menudo abordan problemas entre grupos (por ejemplo, entre grupos de diferente género o raza), pero esto puede aumentar la injusticia dentro del grupo (entre miembros del mismo grupo). Reducir la injusticia entre grupos puede exacerbar la injusticia general/individual: de hecho, la injusticia general aumenta.16
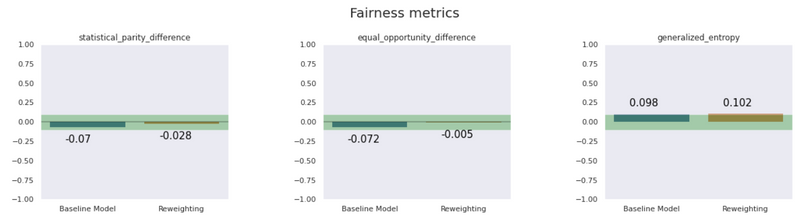 La barra azul presenta un modelo simple y la naranja presenta un modelo corregido por imparcialidad. Comprobamos que cuando mejoran las métricas de equidad grupal (paridad estadística, igualdad de oportunidades), las métricas de equidad individual se reducen17
La barra azul presenta un modelo simple y la naranja presenta un modelo corregido por imparcialidad. Comprobamos que cuando mejoran las métricas de equidad grupal (paridad estadística, igualdad de oportunidades), las métricas de equidad individual se reducen17
Footnotes
-
Kleinberg, Jon, Sendhil Mullainathan, and Manish Raghavan. ‘Inherent Trade-Offs in the Fair Determination of Risk Scores’. ArXiv:1609.05807 [Cs, Stat], 17 November 2016. ↩
-
If we are thinking in terms of potential differences between outcomes for men and women, this means requiring that a z fraction of men and a z fraction of women assigned a probability z should possess the property in question. - Kleinberg, Jon, et al. ‘Inherent Trade-Offs in the Fair Determination of Risk Scores’. ArXiv:1609.05807 [Cs, Stat], Nov. 2016. arXiv.org. ↩
-
Caton, Simon, and Christian Haas. ‘Fairness in Machine Learning: A Survey’. ArXiv:2010.04053 [Cs, Stat], 4 October 2020. ↩
-
Mathematical notation: X (features), A (protected attribute =sex), Y (label) A = 1 is female, A = 0 male ↩
-
Zafar, Muhammad Bilal, et al. ‘Fairness Constraints: Mechanisms for Fair Classification’. ArXiv:1507.05259 [Cs, Stat], Mar. 2017. arXiv.org. ↩
-
Definition: Classifier C satisfies demographic parity if the outcome to be independent of the protected attribute A. Mathematical formulation: P{Y|A=0} = P{Y|A=1} ↩
-
‘Adverse Impact Analysis / Four-Fifths Rule’. Prevue HR, 6 May 2009. ↩
-
Hu, Lily, and Yiling Chen. ‘A Short-Term Intervention for Long-Term Fairness in the Labor Market’. ArXiv:1712.00064 [Cs, q-Fin], Feb. 2018. arXiv.org. ↩
-
Landeau, Alexandre. ‘Measuring Fairness in Machine Learning Models’. Medium, 18 September 2020. ↩
-
Hardt, Moritz, et al. ‘Equality of Opportunity in Supervised Learning’. ArXiv:1610.02413 [Cs], Oct. 2016. arXiv.org. ↩
-
Requires the positive outcome to be independent of the protected class A , conditional on the actual Y Mathematical formulation: P{Y^=1|A=0,Y=y}=P{Y^=1|A=1,Y=y},y∈{0,1} ↩
-
Landeau, Alexandre. ‘Measuring Fairness in Machine Learning Models’. Medium, 18 September 2020. ↩
-
Hardt, Moritz, et al. ‘Equality of Opportunity in Supervised Learning’. ArXiv:1610.02413 [Cs], Oct. 2016. arXiv.org. ↩
-
"The Class of Additively Decomposable Inequality Measures". Econometrica. 48 (3): 613–625. ↩
-
Speicher, Till, et al. ‘A Unified Approach to Quantifying Algorithmic Unfairness: Measuring Individual & Group Unfairness via Inequality Indices’. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, July 2018, pp. 2239–48. arXiv.org. ↩
-
Example taken from the workshop <AI & Equality>: A Human Rights toolbox. ↩