The Spring AI library is a set of APIs and components that allow Java developers to integrate artificial intelligence (AI) into their Spring Boot applications. The library is based on the Spring Framework and provides a unified API to access a variety of AI technologies, including machine learning, deep learning, natural language processing, and computer vision.
Spring AI provides a number of features to make it easy to integrate AI into Spring Boot applications. These features include:
Support for a variety of AI technologies: Spring AI supports a variety of AI technologies, including machine learning, deep learning, natural language processing, and computer vision. This allows developers to choose the AI technology that best meets their needs. Unified API: Spring AI provides a unified API to access all AI technologies. This simplifies the development of Spring Boot applications that integrate AI. Ease of use: Spring AI is designed to be easy to use. Developers can start using the library quickly, without the need to learn a new API. Spring AI can be used for a variety of purposes, including:
Recommendations: Spring AI can be used to generate personalized recommendations for users, based on their historical data. Data analysis: Spring AI can be used to analyze data and identify patterns and trends. Anomaly detection: Spring AI can be used to detect anomalies in data, such as fraud or cyber attacks. Natural language processing: Spring AI can be used to process natural language, such as translation, summarization, and text generation. Computer vision: Spring AI can be used to process images and videos, such as object identification, image classification, and facial recognition. Spring AI is a powerful tool that can help developers integrate AI into their Spring Boot applications. The library is easy to use and provides support for a variety of AI technologies like: Embedding, Prompts, ETL pipeline Vector Database.
Here are some additional details about the Spring AI library:
- The library is still under development, but it has already been used in a variety of production applications.
- The library is open source and available on GitHub.
- The library documentation is available on the Spring website.
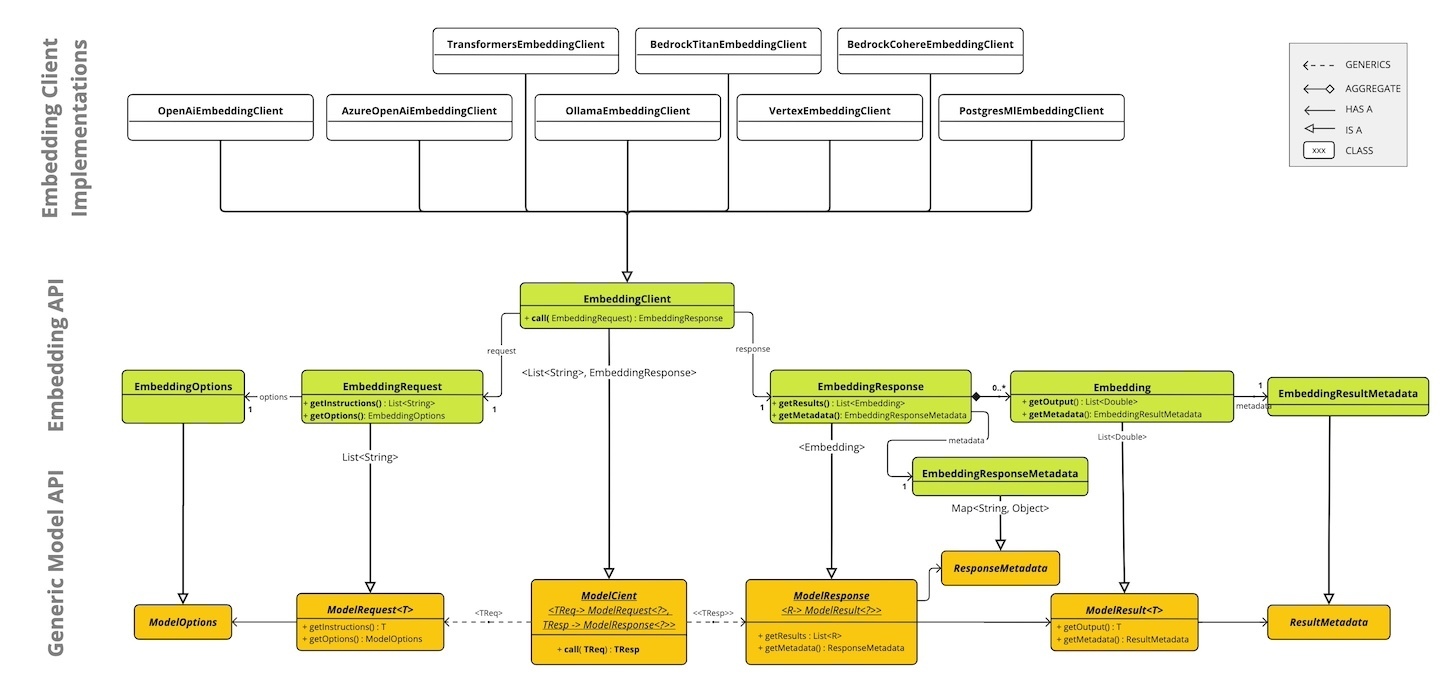
As a software engineer, when you're working with the Embeddings API, think of the EmbeddingClient interface as a bridge connecting your application to the power of AI-based text analysis. Its main role is to transform textual information into a format that machines can understand - numerical vectors, known as embeddings. These vectors are instrumental in tasks like understanding the meaning of text (semantic analysis) and sorting text into categories (text classification).
From a software engineering perspective, the EmbeddingClient interface is built with two key objectives:
Portability: The design of this interface is like a universal adapter in the world of embedding models. It's crafted to fit seamlessly with various embedding techniques. This means, as a developer, you can easily switch from one embedding model to another without having to overhaul your code. This flexibility is in sync with the principles of modularity and interchangeability, much like how Spring framework operates. Simplicity: With methods like embed(String text) and embed(Document document), EmbeddingClient takes the heavy lifting off your shoulders. It converts text to embeddings without requiring you to get tangled in the complexities of text processing and embedding algorithms. This is particularly beneficial for those who are new to the AI field, allowing them to leverage the power of embeddings in their applications without needing a deep dive into the technicalities. In essence, as a software engineer, when you use EmbeddingClient, you're leveraging a tool that not only simplifies the integration of advanced AI capabilities into your applications but also ensures that your code remains agile and adaptable to various embedding models.
Working with Spring AI, you can prompts can be thought of as the steering wheel for AI models, guiding them to produce specific outputs. The way these prompts are crafted plays a critical role in shaping the responses you get from the AI.
To draw a parallel with familiar concepts in software development, handling prompts in Spring AI is akin to how you manage the "View" component in the Spring MVC framework. In this scenario, creating a prompt is much like constructing an elaborate text template, complete with placeholders for dynamic elements. These placeholders are then substituted with actual data based on user input or other operations within your application, similar to how you might use placeholders in SQL queries.
As Spring AI continues to evolve, it aims to introduce more sophisticated methods for interacting with AI models. At its core, the current classes and functionalities in Spring AI could be compared to JDBC in terms of their fundamental role. For example, the ChatClient class in Spring AI can be likened to the essential JDBC library provided in the Java Development Kit (JDK).
Building on this foundation, just as JDBC is enhanced with utilities like JdbcTemplate and Spring Data Repositories, Spring AI is expected to offer analogous helper classes. These would streamline interactions with AI models, much like how JdbcTemplate simplifies JDBC operations.
Looking further ahead, Spring AI is poised to introduce even more advanced constructs. These might include elements like ChatEngines and Agents that are capable of considering the history of interactions with the AI model. This progression mirrors the way that software development has evolved from direct JDBC usage to more abstract and powerful tools like ORM frameworks.
In summary, as a software engineer working with Spring AI, you are at the forefront of integrating AI capabilities into applications, using familiar paradigms and patterns from traditional software development, but applied to the cutting-edge field of AI and machine learning.
Extract, Transform, and Load (ETL) framework is crucial in managing data processes in the Retrieval Augmented Generation (RAG) scenario. Essentially, the ETL pipeline is the mechanism that streamlines the journey of data from its raw state to a more organized vector store. This process is vital for preparing the data in a way that makes it easily retrievable and usable by the AI model.
In the RAG use case, the core objective is to enhance the capabilities of generative AI models. This is achieved by integrating text-based data, which involves sourcing relevant information from a dataset to improve both the quality and the contextual relevance of the outputs generated by the model. The ETL framework plays a pivotal role in this process by ensuring that the data is not only accurately extracted and transformed but also efficiently loaded and stored for optimal retrieval by the AI system. This process enhances the AI's ability to produce more precise and contextually rich responses.
A vector databases is a specialized type of database that plays an essential role in AI applications. Vector databases are used to integrate your data with AI models. The first step in their usage is to load your data into a vector database. Then, when a user query is to be sent to the AI model, a set of similar documents is first retrieved. These documents then serve as the context for the user’s question and are sent to the AI model, along with the user’s query. This technique is known as Retrieval Augmented Generation (RAG).

We've developed a project that incorporates fundamental principles related to AI and the Spring library, focusing on concepts like Prompts, Embedding, ETL pipelines, and Vector Databases. Our aim is to provide a concise overview of each concept's functionality. The main goal is to integrate all these elements through a practical example and apply them to a routine solution.
The first step is to select a Vector Database for our use. Spring AI offers integration with various databases. In this instance, we've chosen to use pgvector
When configuring your Maven pom.xml for the Spring AI project, add the specified repository to access its dependencies. As Spring AI is currently in the experimental phase, only snapshot versions are available. Here is how you should include this in your pom.xml:
<repositories>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
In this project, I have selected OpenAI as the primary interface. However, it's important to note that Spring AI offers a variety of different ChatClient interfaces.
- OpenAI
- Azure OpenAI
- Hugging Face
- Ollama
OpenAI Library
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>${spring-ai.version}</version>
</dependency>
PDF Document Reader (ETL)
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
<version>${spring-ai.version}</version>
</dependency>
Vector Database(PGvector)
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store</artifactId>
<version>${spring-ai.version}</version>
</dependency>
The most recent version of this library is 1.0.0-SNAPSHOT.
After all setup, you need to create your account and API key in one of the chosen clients. In my case OpenAI Platform
This was just the first study with Generative AI and the Spring AI library. We will develop some other features using the library, and I hope you follow my journey with Spring and AI.
Part of this doc was generated with SpringAI and Model ChatGPT 4.0.
version: '3.7'
services:
postgres:
image: ankane/pgvector:v0.5.0
restart: always
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=admin
- POSTGRES_DB=vector_db
- PGPASSWORD=admin
logging:
options:
max-size: 10m
max-file: "3"
ports:
- '5433:5432'
healthcheck:
test: "pg_isready -U postgres -d vector_db"
interval: 2s
timeout: 20s
retries: 10
for running pgvector you will run
docker compose up -d
In the project for use all Spring IA functionalities you will need add some dependencies:
<spring-ai.version>1.0.0-SNAPSHOT</spring-ai.version>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store</artifactId>
<version>${spring-ai.version}</version>
</dependency>
We use latest version of library 1.0.0-SNAPSHOT.
We have divided our approach into two distinct parts: data handling and question processing.
Data Handling: This involves several key operations:
-
Loading: Importing data into our system. Transforming: Modifying or processing the data to fit our needs.
-
Inserting: Adding new data entries into our database.
-
Retrieving: Accessing data from the database as needed.
-
Deleting: Removing data entries that are no longer required.
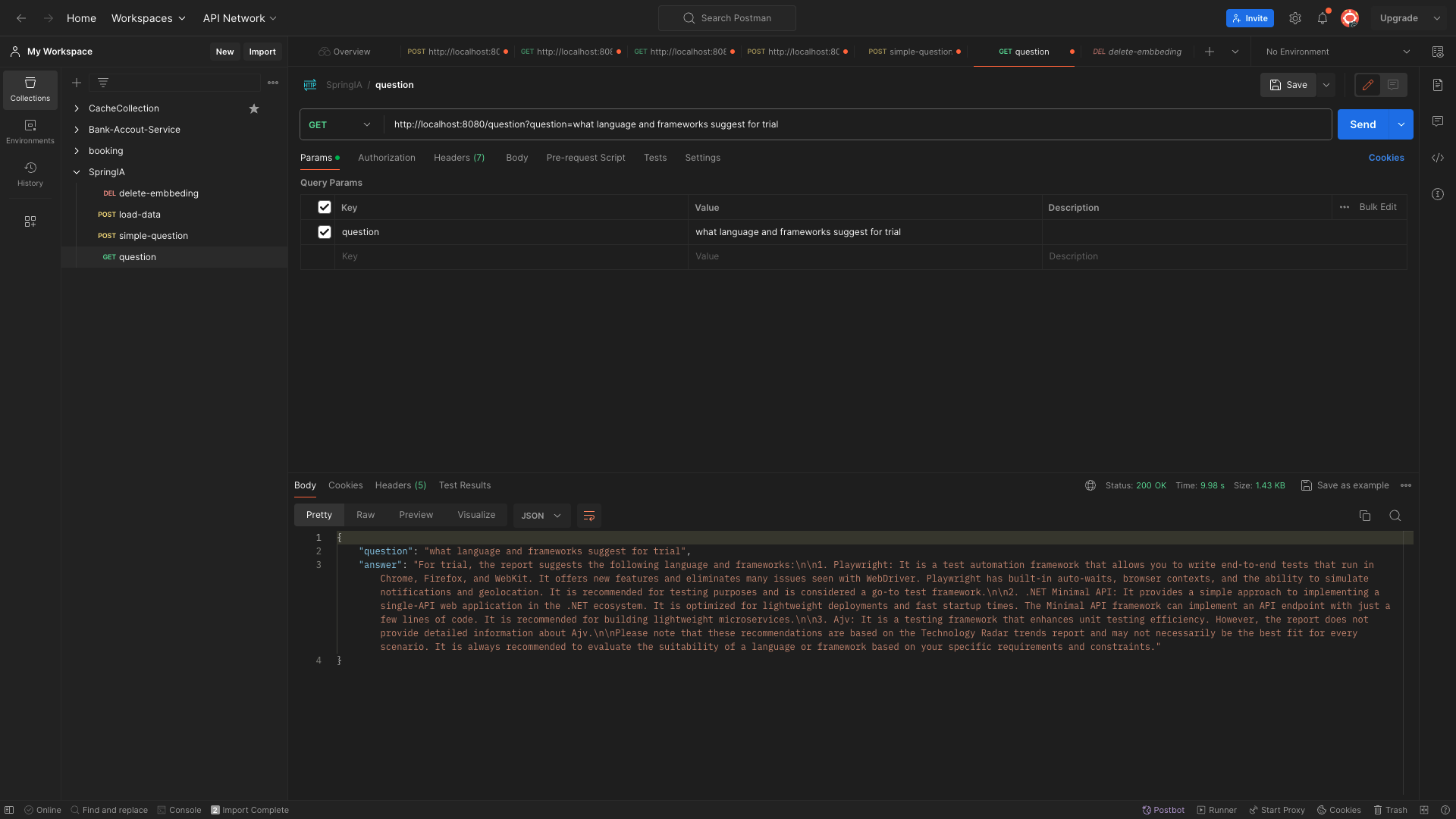
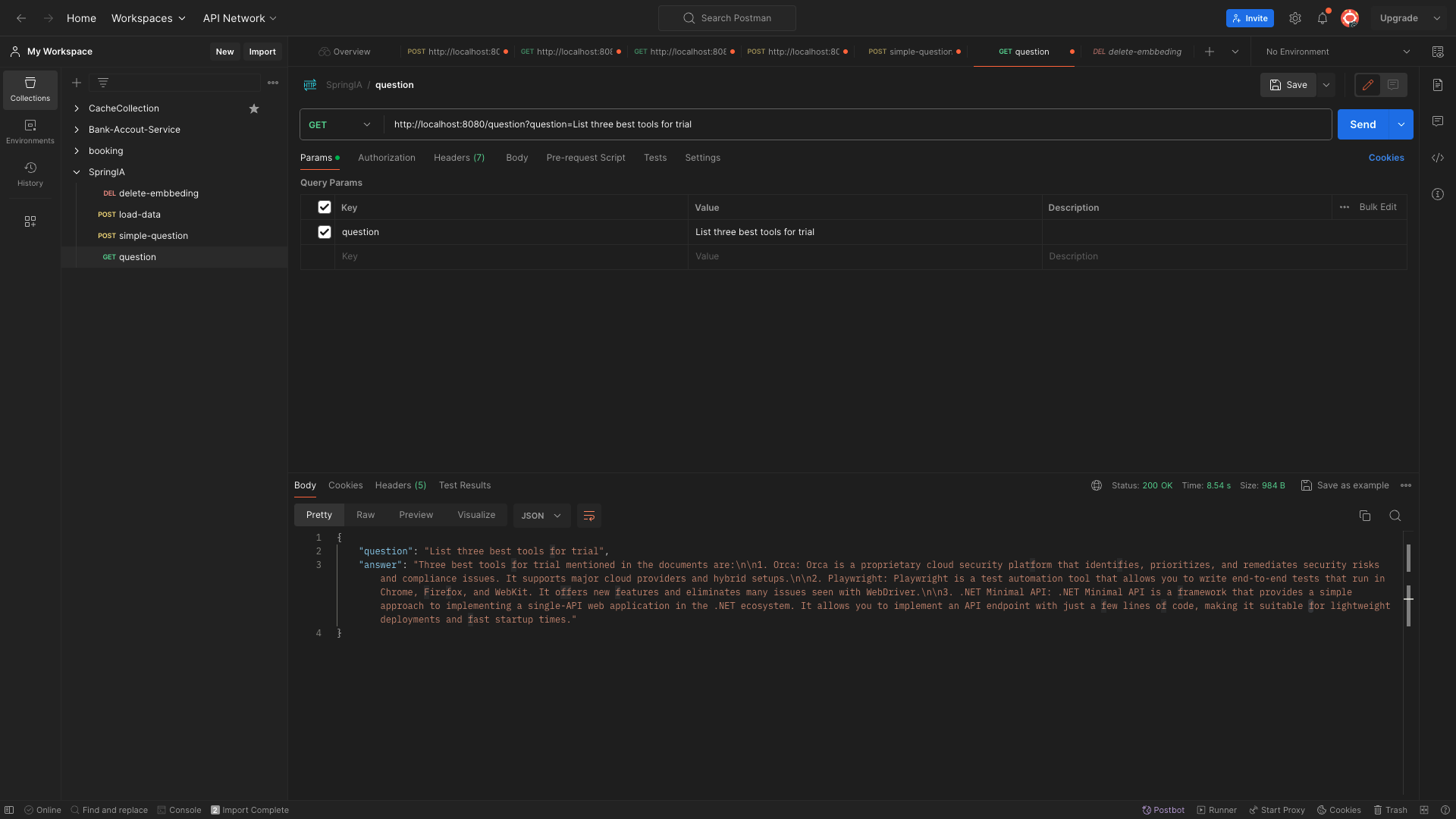
Question Processing: In this part, we utilize the data that has been loaded and processed. The aim here is to provide responses that are directly related to, and informed by, the data we have in our resources.
Regarding the data aspect, we have utilized a Technology Radar from ThoughtWorks as our primary data source."
About data, we used a Technology Radar from Thoughtwrorks
Command to run application
mvn spring-boot:run -Dspring-boot.run.profiles=openai
The Technology Radar is a snapshot of tools, techniques, platforms, languages and frameworks based on the practical experiences of Thoughtworkers around the world. Published twice a year, it provides insights on how the world builds software today. Use it to identify and evaluate what’s important to you.
Here the link from latest tech radar version
With the content from the ThoughtWorks Technology Radar as our reference, we are now equipped to utilize our API to recommend the best tools or offer insights and opinions on various technologies.