Reconciliation makes more moves than necessary? #168
Replies: 19 comments 2 replies
-
|
For the record, I ignored the |
Beta Was this translation helpful? Give feedback.
-
|
I adapted my approach to accept old/new lists of children and use a https://jsfiddle.net/mindplay/v8drqtn1/ I had to use I noticed you use empty By the way, this approach gets good results for all the common use-cases demonstrated here, except for the "Shuffle" operation - it does not get good results when you reorder the entire list of elements, so this would be slower for cases like changing the sorting of a list or table, where it'll actually end up redundantly moving some of the elements more than once. This might be considered a "good enough" approach for most UI, but it almost definitely won't win any benchmarks for the case where 20K table rows get reordered. 😉 |
Beta Was this translation helpful? Give feedback.
-
|
I believe the choice to use Text over Comment is primarily for bundle size - there's already code to create Text nodes so it's easier to reuse that by passing an empty string instead of writing a different function. Here's castNode() which does the node creation: https://www.github.com/luwes/sinuous/tree/master/packages%2Fsinuous%2Fh%2Fsrc%2Fadd.js I can't comment (hah) on the diff algorithm but good luck! |
Beta Was this translation helpful? Give feedback.
-
|
My doodles aside, I do think there's a small problem with I've opened an issue to clear it up. |
Beta Was this translation helpful? Give feedback.
-
|
@mindplay-dk thanks for the deep investigation, I didn't know it did that in more steps than needed. Nice list of the fastest algo's compared maybe a good time to bring up krausest/js-framework-benchmark#858 (comment) Sinuous used to use the stage0 algo which turns out to be faster but the tradeoff is a bigger bundle size. I'm a little thorn on to put this back or not. @heyheyhello @mindplay-dk what would you consider most valuable to your projects? |
Beta Was this translation helpful? Give feedback.
-
|
I ran that benchmark last night - results are probably outdated, most of these libs take about the same time. I've been writing my own - and actually just got it passing all the tests last night. I'm using mocks and spies to ensure it completes a number of diff operations in the least possible moves. I've no idea how it performs yet though. It's probably larger too, around 600B minified atm. We'll see when it's done if it was at all worth while 😄 |
Beta Was this translation helpful? Give feedback.
-
|
(I will probably try to enhance that benchmark with mocks and spies, so we can compare algos on accuracy too...) |
Beta Was this translation helpful? Give feedback.
-
|
Oh, the sizes in your benchmark are gzipped! I'm at 600B just minified, so I've got some wiggleroom still! 😉 |
Beta Was this translation helpful? Give feedback.
-
|
I'll admit that I have a fear that reconciliation is very expensive and I stay away from any of those algorithms regardless of bundle size. For small lists, I'm more likely to not import sinuous/map at all and just drop/recreate the list instead. If I had a metric like "after N list recreations for M items, you've performed more operations than if you had loaded/used map" then I'd import it, even if it was large like 5kb. I care more that reconciliation is correct and efficient, not so much the bundle size. |
Beta Was this translation helpful? Give feedback.
-
|
@mindplay-dk Great job working on another implementation! Always important to have options :) |
Beta Was this translation helpful? Give feedback.
-
💯🙂✌ Though in the case of Sinuous and This is one of my selling points when I advertise Sinuous to friends 😊 - reconciliation is possible, but it's not the default, and (with almost no exceptions) recursive reconciliation is largely unnecessary work that doesn't produce any result. That said, I believe it's very important for a framework to have this option - it would be a huge detractor for me, personally, if this feature wasn't something Sinuous offered at all. You can't always design around this need. |
Beta Was this translation helpful? Give feedback.
-
|
There's more work to do (tests, optimizations) before I publish this, but feel free to take a look: https://bitbucket.org/mindplaydk/diff/src/master/ EDIT: now it's public 😉 By now, it passes the tests and completes every operation with the fewest possible calls to It's at ~420 bytes minzipped - I've made no attempt to benchmark or optimize for size/speed yet. 🙂 |
Beta Was this translation helpful? Give feedback.
-
|
I fixed some bugs and added mine to your benchmark.
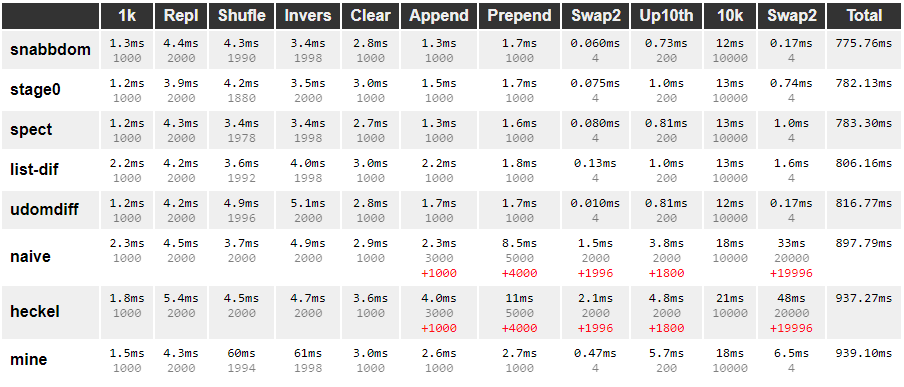
(Mine is just called It's pretty much the slowest. 🕺🎉 I haven't made any attempts to optimize it yet - it's basically brute-forcing the search for the target index in the inner loop, when it decides where to move a range of elements, I'm sure that could be optimized. I noticed the results would vary quite a lot between runs, and it seemed (in part) due to the fact that the "shuffle" operation generates a new workload for every run - the number of operations performed would vary between runs, making individual runs not really comparable, so I've seeded the RNG to make sure it's doing the same work on every run. I was certain my approach would do it in the theoretically fewest possible DOM operations, but it appears I didn't really trust the benchmark, so I went and mashed on that for a bit. It seems to yield very different results between runs - most likely, garbage collection and so on is affecting the results. Also, I tried swapping around the libs, running them in different order - running my own lib either first or last definitely changed the result, so I decided to put'em all thru the ringer. I ran the benchmark 200 times, in random order, collected all the data in So here's the average results from 200 randomized runs:
It was hard not to notice how most of these libraries come out practically with the top fastests ones randomly beating each other - 200 randomized runs gives us a little more clarity, and as you can see from my highlighting in green, at least five of those libraries should be considered "fast", with Ranking them by the sum total time to complete all the benchmarks seems rather meaningless though, since the slowest test (10k) will make up almost half of that result, and every use-case is meaningful - so I've also highlighted in green, for each test, the libraries I'd consider "fast" in each category. I've also highlighted the ones I'd consider "small", relative to the others. Note that the size of Based on my analysis, I'd say the performance difference between the top libraries here is largely insignificant - they each have their strong and weak points. I don't think it's possible for one library to win in all categories. Given that I will pull Sorry if this is overwhelming. Hopefully it's also useful. I've spent a ridiculous amount of time on this. 😂 |


Beta Was this translation helpful? Give feedback.
-
|
I put As for I put Finally, I gave I didn't bother testing I guess, based on this, you could go one of two ways:
My recommendation at this point would be The reason I set out on this expedition in the first place, was because I noticed the accuracy problem - and apparently, both of the smaller libraries trade off accuracy for size. In my opinion, we do DOM diffing to avoid focus and selection issues, to avoid randomly reloading iframes, and so on. That's the must have, in my opinion - whereas "small" and "fast" are nice to have, if possible. I mean, if size was the only priority, you could literally just do this, right? function diff(parent, oldChildren, newChildren, endMarker) {
let set = new Set();
for (let i=newChildren.length; i--;) {
set.add(newChildren[i]);
}
for (let i=oldChildren.length; i--;) {
let oldChild = oldChildren[i];
if (!set.has(oldChild)) {
parent.removeChild(oldChild);
}
}
for (let i=newChildren.length; i--;) {
parent.insertBefore(newChildren[i], newChildren[i+1] || endMarker);
}
return newChildren;
}That's 175 bytes, and actually faster than It's also totally daft and naive, but if you really didn't care about issue with focus, selections or iframes, it gets the job done. No, I would definitely go with |
{kind=link}
Beta Was this translation helpful? Give feedback.
-
|
Amazing write up, thanks for all your research! Enjoyed learning about reconcilation and I'll consider snabbdom when I need to eventually integrate it into my apps/framework |
Beta Was this translation helpful? Give feedback.
-
|
@heyheyhello your "fork of Sinuous" looks interesting, though it looks more like a rewrite than a fork? I have a toy project along the same lines myself, for which I chose |
Beta Was this translation helpful? Give feedback.
-
|
Started as a fork. I love Sinuous a lot and I still keep most of sinuous/h but I was very into TSX and type hints/validation while Sinuous is more into tag templates. I originally ported sinuous/observable to TS but eventually wrote my own reactive library - I kept tripping on things like accidental subscriptions leading to infinite loops and the browser locking up... wanted more debuggability and explicitness. Just landing support for lazy-computeds now. I'll check out dipole. I wish there was a dircetory of reactive libraries. I've learned from too many to mention, but reactor.js, anod, derivablejs, and flyd are all worth checking out if you haven't yet; or take a look at haptic's wire when I'm done settling it :) |
Beta Was this translation helpful? Give feedback.
-
|
@mindplay-dk wow you went deep down the rabbit hole 😃 love it! @heyheyhello Haptic looks really cool, great name as well. lazy computeds makes sense, I think someone here needed this functionality as well |
Beta Was this translation helpful? Give feedback.
-
|
@luwes since this got moved to a discussion, you understand there's still an issue with diffing, right? As demonstrated, it makes too many moves - but in fact also had a bug, where an element would get dropped while diffing. My own conclusion from this exploration was My recommendation would be switch to that. I would try to help, but I don't fully understand the |
Beta Was this translation helpful? Give feedback.
-
|
thank you! sorry I missed this, I opened a separate issue to track the changes |
Beta Was this translation helpful? Give feedback.
-
|
kind of moved to #212 it seems (#174 was deleted.) |
Beta Was this translation helpful? Give feedback.
-
I've been interested in the reconciliation algo for a while, and I'm sort of an idiot when it comes to this stuff - it's really difficult for me to understand the reconciliation code in most of the libraries I've looked at, and frankly I didn't really trust that any of them were doing it optimally.
So I set up a use-case driven test bench with a bunch of
console.logstatements, so I can actually try various operations on a list, and see what sort of DOM operations result from those.Here it is, first for Sinuous - with diff.js from the
mapmodule:https://jsfiddle.net/mindplay/gdzrmshq/
Here, I noticed that "Rotate Up" moves 3 elements, while "Rotate Down" moves 2 elements - in either case, one move should be enough, since it's just the first/last element moving to the opposite end of the range.
I understand your code is derived from
udomdiff? So here's the same test-bench forudomdiff:https://jsfiddle.net/mindplay/o4gbaqw0/
Here, "Rotate Up" takes two moves (one of them a
replaceNode) which is still one too many - while "Rotate Down" does it accurately, in a single move.As said, I am an idiot at this stuff, but I decided to try my own naive approach - I simply remove old elements, append new elements, and then take two passes: first, I move only the nodes where moving them isn't going to break the order somewhere else - and then, I take a second pass, moving all remaining nodes that aren't already in the right place.
https://jsfiddle.net/mindplay/924xfvow/
Here, "Rotate Up" and "Rotate Down" both finish in one move.
As said, this approach is totally naive, and probably isn't blazing fast, since I'm using a two passes (and lots of comparisons with next/previous siblings) but I wanted something simple enough that I could understand it myself, being (as stated) an idiot.
Apparently, I'm not a complete idiot, because it works. 😂
I expect this simple algo could be optimized as well, because for most operations (all but "Shuffle") it doesn't actually need to do anything in the second pass - there's only one difference between the first and second pass, and it's this:
So, basically, if that second expression is ever
falseduring the first pass, you can return before the second pass, because it would be fully identical to the first pass.By the way, don't ask me why these loops are backwards. I've no idea if they need to be. I was just trying stuff, and it ended up this way, and it seems to work, so I didn't question it. (Might be good for micro perf anyway.)
I haven't benchmarked or optimized this at all, just throwing it up here for discussion.
Any thoughts? 🙂
Beta Was this translation helpful? Give feedback.
All reactions