
gdscrapeR is an R package that scrapes company reviews from Glassdoor using a single function: get_reviews. It returns a data frame structure for holding the text data, which can be further prepped for text analytics learning projects.
The latest version from GitHub:
install.packages("devtools")
devtools::install_github("mguideng/gdscrapeR")
library(gdscrapeR)The URL to scrape the awesome SpaceX company will be: www.glassdoor.com/Reviews/SpaceX-Reviews-E40371.htm.
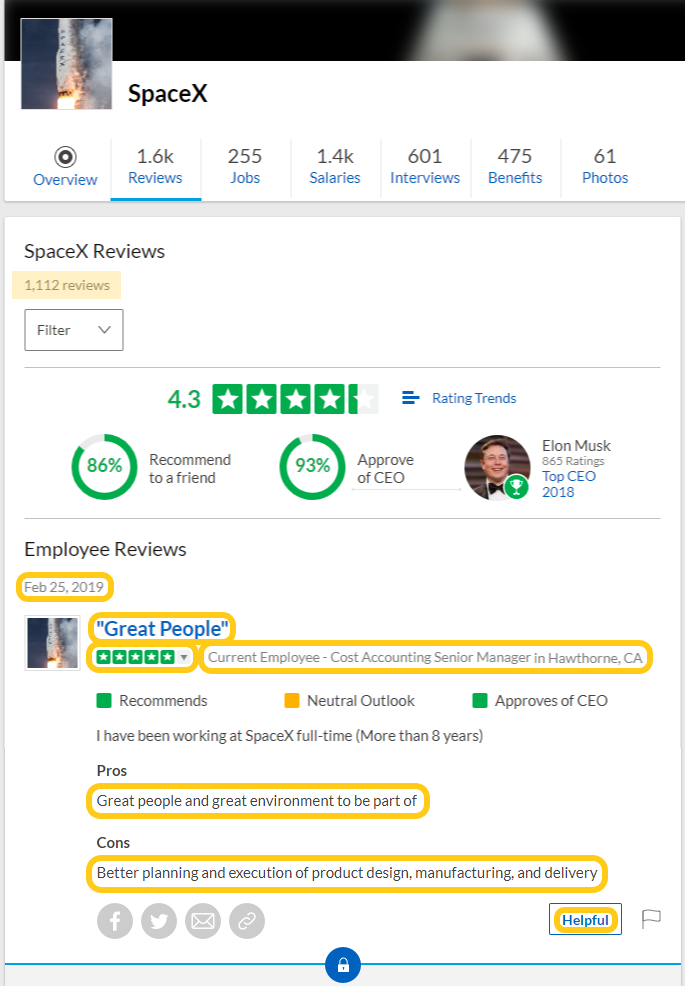
Pass the company number through the get_reviews function. The company number is a string representing a company's unique ID number. Identified by navigating to a company's Glassdoor reviews web page and reviewing the URL for characters between "Reviews-" and ".htm" (usually starts with an "E" and followed by digits).
# Create data frame of: Date, Summary, Rating, Title, Pros, Cons, Helpful
df <- get_reviews(companyNum = "E40371")This will scrape the following variables:
- Date - of when review was posted
- Summary - e.g., "Great People"
- Rating - star rating between 1.0 and 5.0
- Title - e.g., "Current Employee - Manager in Hawthorne, CA"
- Pros - upsides of the workplace
- Cons - downsides of the workplace
- Helpful - count marked as being helpful, if any
- (and other info related to the source link)
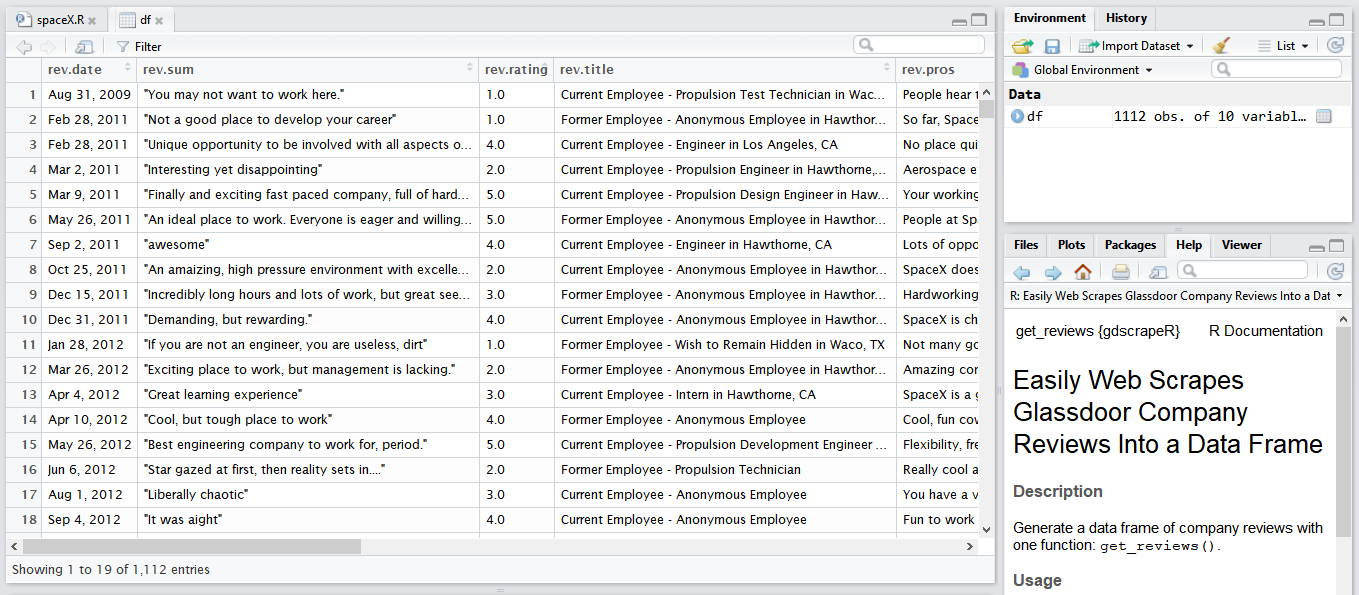
Use regular expressions to clean and extract additional variables and then export:
#### REGEX ####
# Package
library(stringr) # pattern matching functions
# Add: PriKey (uniquely identify rows 1 to N, sorted from first to last review by date)
df$rev.pk <- as.numeric(rownames(df))
# Extract: Year, Status, Position, Location
df$rev.year <- as.numeric(sub(".*, ","", df$rev.date))
df$rev.stat <- str_match(df$rev.title, ".+?(?= Employee -)")
df$rev.pos <- str_replace_all(df$rev.title, ".* Employee - |\\sin .*|\\s$", "")
df$rev.loc <- sub(".*\\sin ", "", df$rev.title)
df$rev.loc <- ifelse(df$rev.loc %in%
(grep("Former Employee|Current Employee|^+$", df$rev.loc, value = T)),
"Not Given", df$rev.loc)
# Clean: Pros, Cons, Helpful
df$rev.pros <- gsub("&", "&", df$rev.pros)
df$rev.cons <- gsub("&", "&", df$rev.cons)
df$rev.helpf <- as.numeric(gsub("\\D", "", df$rev.helpf))
#### EXPORT ####
write.csv(df, "df-results.csv", row.names = F)gdscrapeR was made for learning purposes. Analyze the unstructured text, extract relevant information, and transform it into useful insights.
- Apply Natural Language Processing (NLP) methods to show what is being written about the most.
- Sentiment analysis by categorizing the text data to determine whether a review is considered positive, negative, or neutral as a way of deriving the emotions and attitudes of employees. Here's a sample project: "Text Mining Company Reviews (in R) - Case of MBB Consulting".
- Create a metrics profile for a company to track how star rating distributions are changing over time.
- The "Text Mining with R" book by Julia Silge and David Robinson is highly recommended for further ideas.
If you find this package useful, feel free to star ⭐ it. Thanks for visiting ❤️ .
- Uses the
rvestandpurrrpackages to make it easy to scrape company reviews into a data frame. - A common issue with scraping is the need to keep up with changes made to a website's pages. The Glassdoor site will change. Errors due to CSS selector changes will be shown as "Could not scrape data from website.".
- Try it again later.
- It's straightforward to work around them if you know R and how
rvestandpurrrwork. For more on this, see the "Known limitations" section of the demo write-up: "Scrape Glassdoor Company Reviews in R Using the gdscraper Package".
- Be polite.
- A system sleeper is built in so there will be delays to slow down the scraper (expect ~1.5 minutes for every 100 reviews).
- Also, saving the data frame to avoid redundant scraping sessions is suggested.
- To contact maintainer:
[imlearningthethings at gmail].