在商用系统中经常使用一类通用的数据结构,统称为 B 树。其中最常使用的是 B+ 树(B 树的变体),接下来我们针对 B+ 树的具体细节进行介绍。
B+ 树将存储块组织成一棵树的形状,每个结点是一个存储块,这棵树是平衡的,即从树根到树叶的所有路径都一样长。通常 B+ 树有三层:根、中间层和叶,但也可以是任意多层。
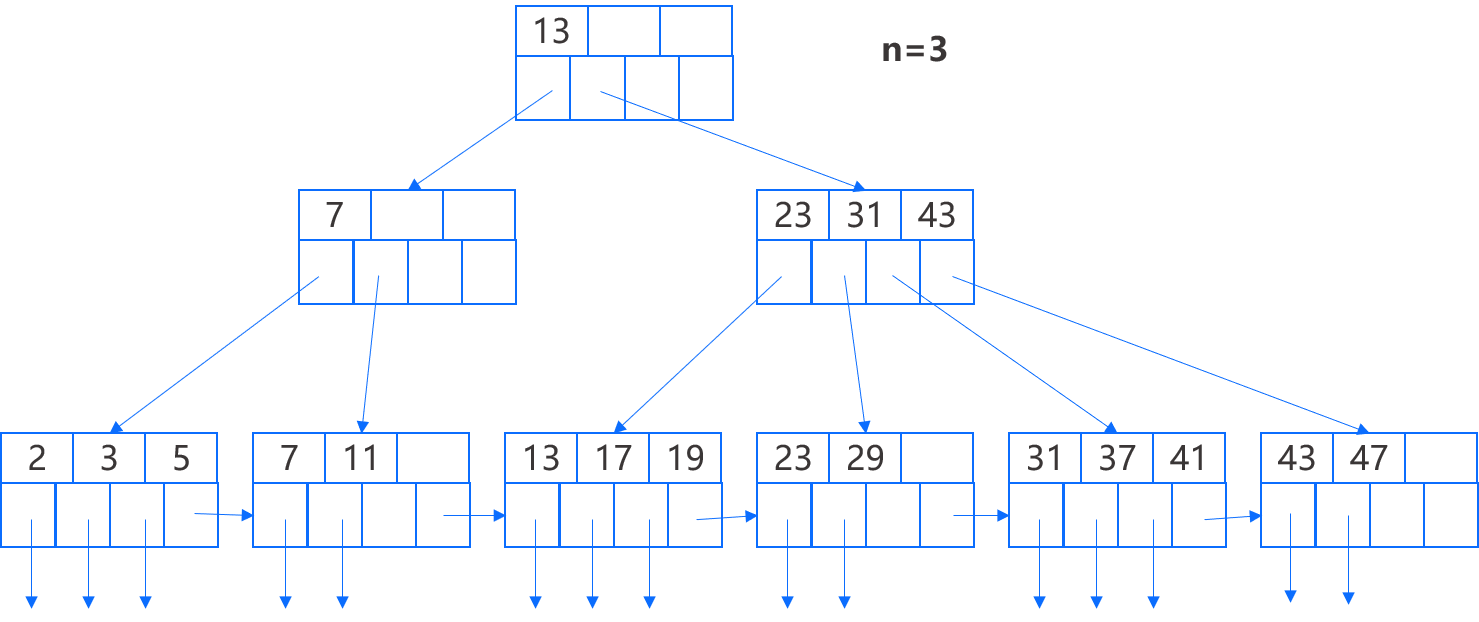
如图所示,对于每个 B+ 树都有一个参数 n 来决定 B+ 树所有存储块的布局,每个存储块存放 n 个查找键和 n+1 个指针,我们希望在存储块能够容纳的前提下 n 取值尽可能大,从而使得树的层数尽可能少,来减少每次访问叶结点所需要访问的存储块。
接下来介绍几个 B+ 树的常用基础规则,这些限制并不适用于所有 B+ 树,比如叶结点通常存放键值对,而不是指向数据的指针。但无论具体实现如何,通常都需要保证树是平衡的。
-
根结点至少有两个指针被使用,所有指针指向位于下一层的存储块。
-
叶结点中,最后一个指针指向它右边的下一个叶结点存储块。其他 n 个指针中,至少有 ⌊(n+1)/2⌋ 个指针被使用且指向数据记录。
-
在内层结点中,所有的 n+1 个指针都可以用来指向下一层的块。其中至少 ⌈(n+1)/2⌉ 个指针被使用,如果 j 个指针被使用,那该块中将有 j-1 个键。
-
所有被使用的键和指针通常都存放在数据块开头位置,除了叶结点的第 (n+1) 个指针。
在上图示例中 n=3,也就是说,块中可存放 3 个键值和 4 个指针。
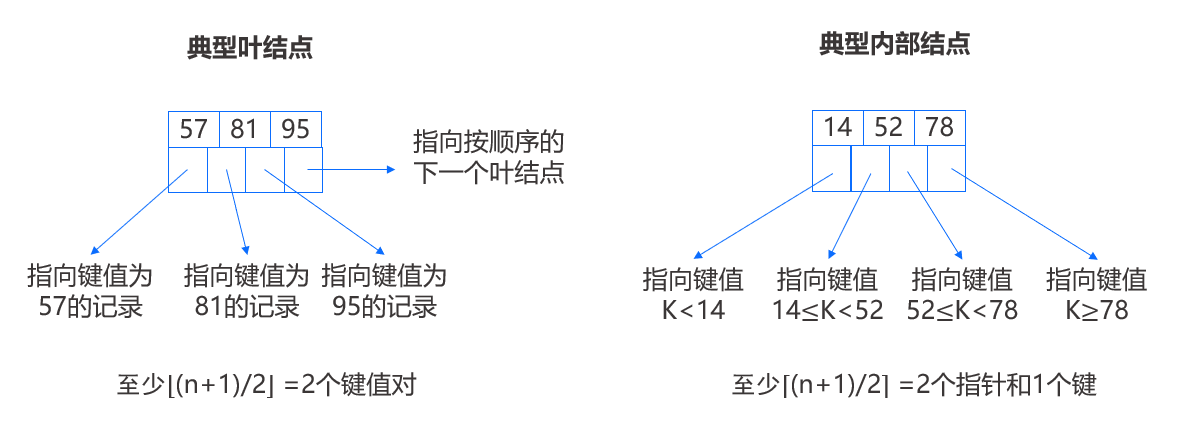
上图所示这两个分别是这棵树的典型叶结点和内部结点。结点不必全部充满,但叶结点至少要有两个键-指针对,内部结点至少要有一个键和两个指针。
B+ 树的查找是从根到叶的递归过程,若我们处于某个内部结点或根结点,则通过结点中的键范围找到下一层的结点;若我们处于叶结点,就在其中查找,如果第 i 个键是查找键,那么第 i 个指针就指向所查找的记录。
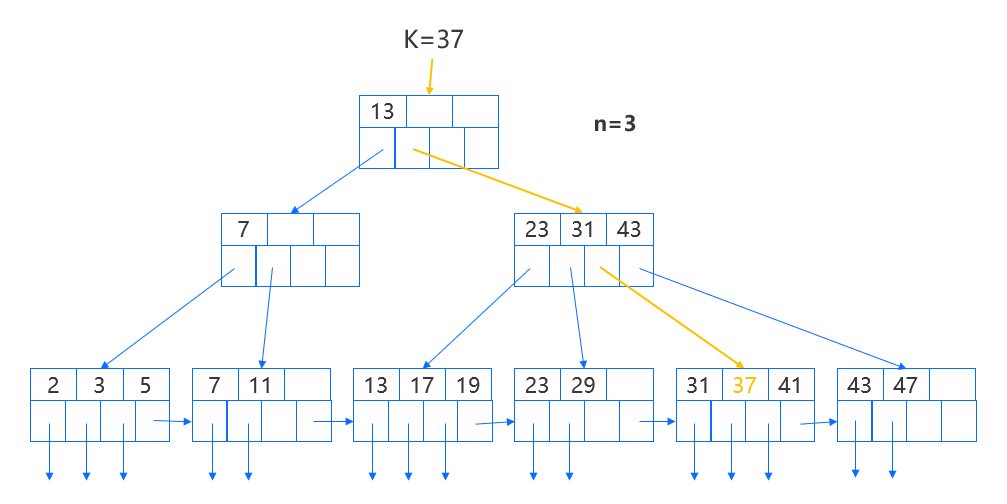
如上图所示,以查找键为 37 的记录为例,从根结点开始查找,其中有一个键 13,因为 13≤37,于是沿着第二个指针来到下一层的结点,在这个结点中我们发现 31≤37<43,因而我们沿着第三个指针来到叶结点,最后在叶结点中找到记录。如果查找键为 40,那么我们的查询路径是完全一样的,但是由于在叶结点中无法找到键 40,因此可以断定树中没有键为 40 的记录。
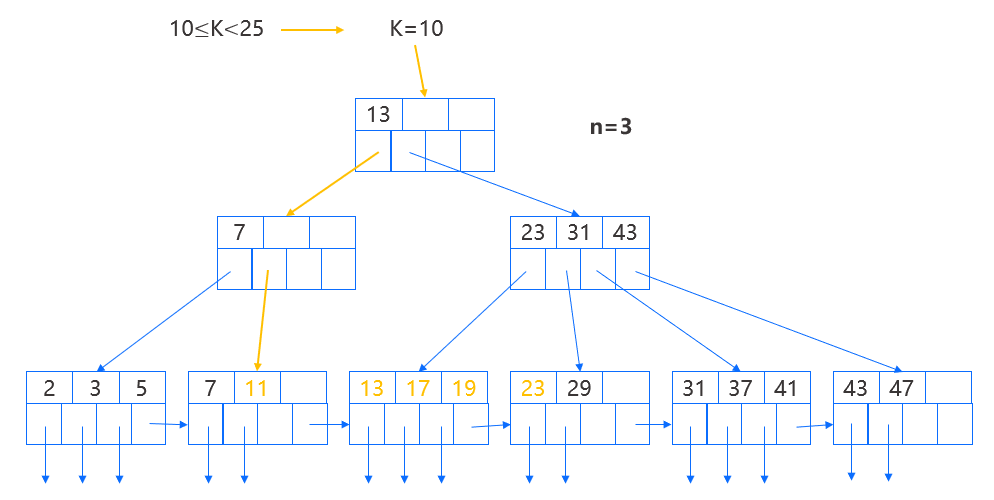
由于 B+ 树的叶结点前后存在链接,对于范围查询非常友好。以查询 10~25 范围的键为例,首先通过键等于左边界 10 进行查找,找到叶结点后按顺序向后依次判断键是否位于范围内,将位于范围内的记录取出即可。
B+ 树的插入在原则上是递归的:
-
首先设法在适当的叶结点为新键找到空闲空间,如果有的,就把键放在那里。
-
如果在适当的叶结点中没有空间,就把该叶结点分裂成两个,并且把其中的键分到这两个新结点中,使每个新结点有一半或刚好一半的键。
-
某一层的结点分裂在上一层看来,相当于要在这一较高层次上插入一个新的键-指针对。因此可以在这一较高层次上逆归上述插入策略。
-
例外的情况是,在试图插入键到根结点且其没有空间时,将分裂根结点成两个结点且在更上一层创建一个新的根结点,这个新的根结点有两个刚分裂成的结点作为它的子结点。
当我们分裂结点并在其父结点插入时,需要小心处理。我们结合实例来进行解读,向下图中的 B+ 树插入键 40,根据前述的查找过程我们将找到第 5 个叶结点进行插入,因为该叶结点已满,我们需要分裂这个叶结点。
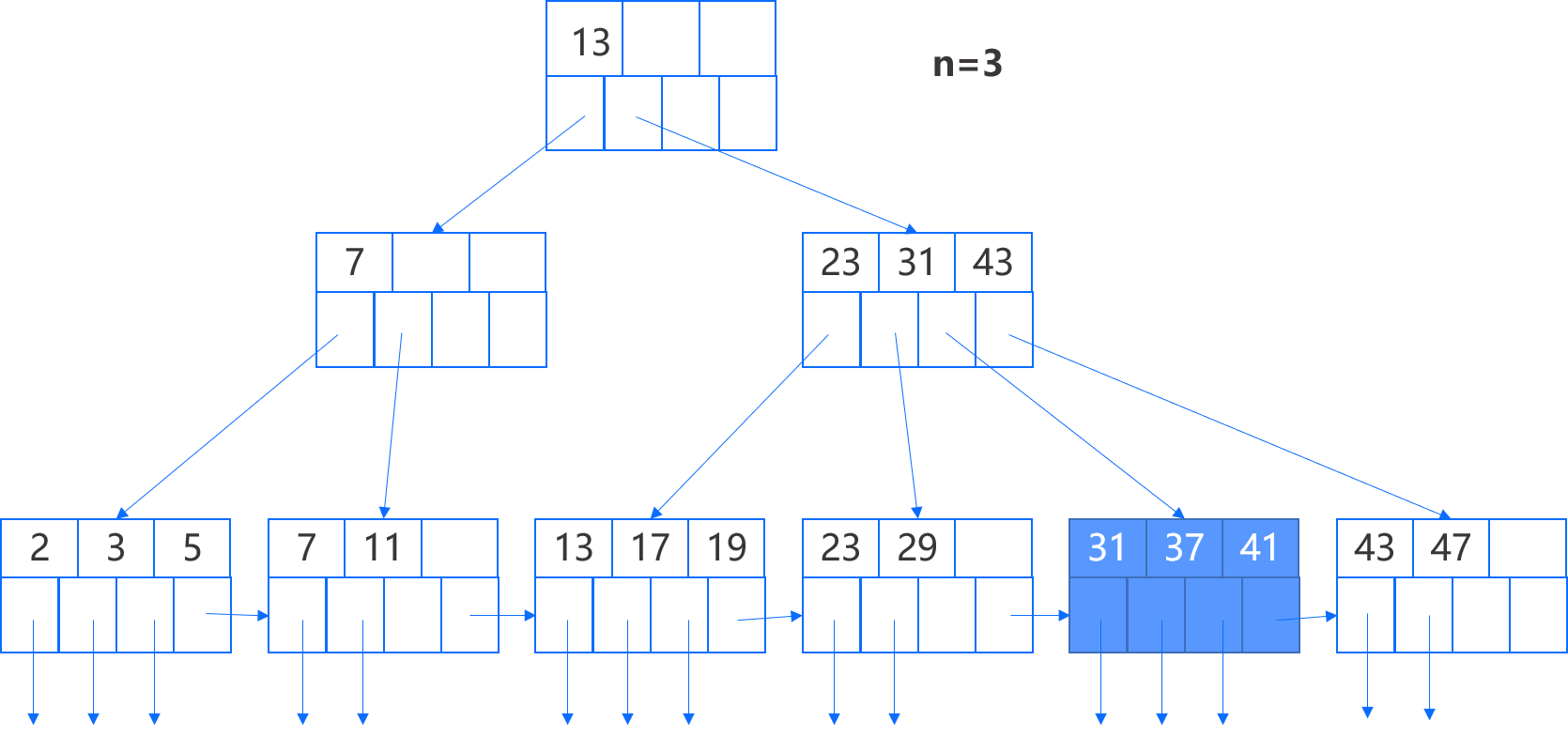
首先创建一个新结点,在原结点保留 2 个键-指针对,并把其他两个键-指针对移到新结点。
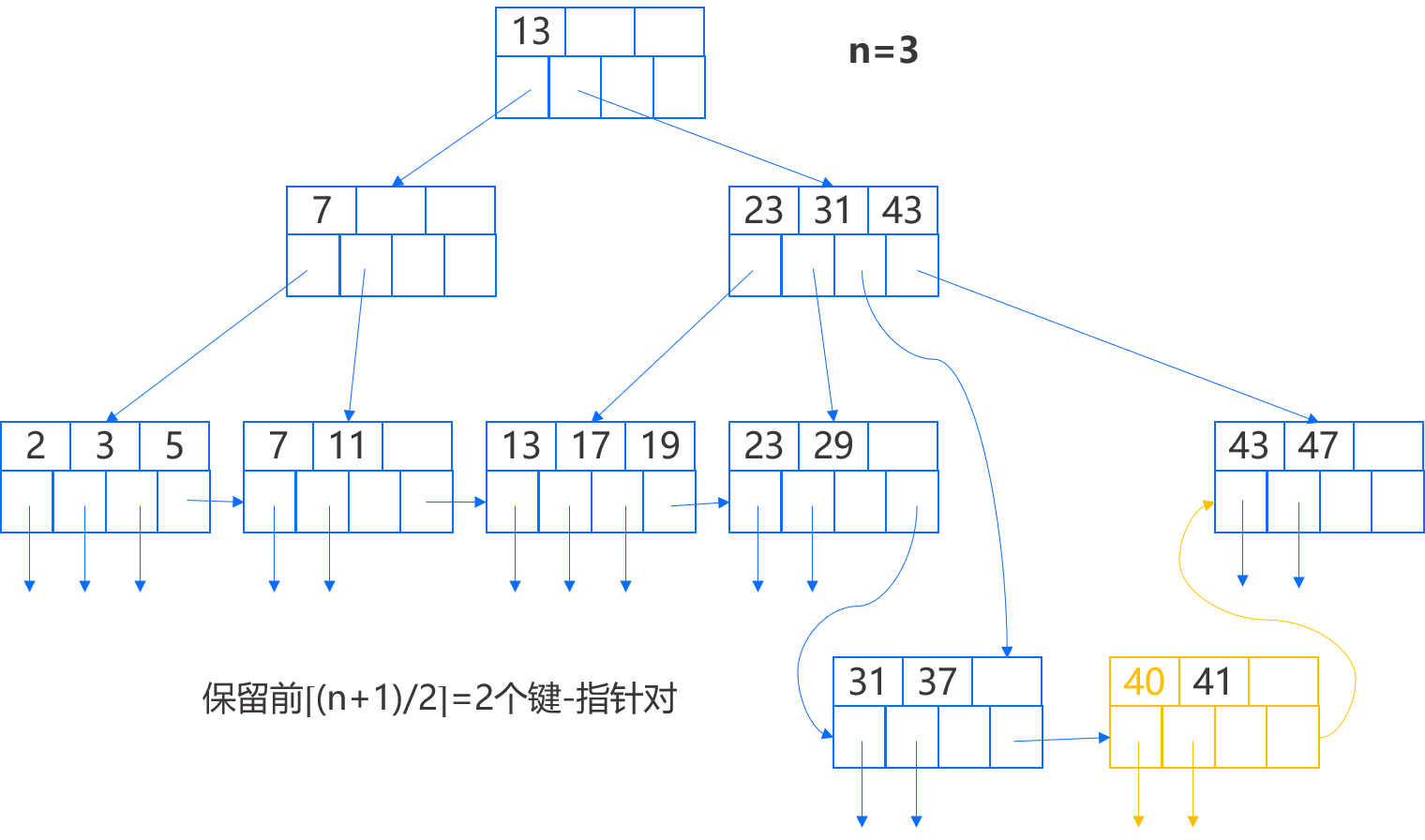
现在我们必须插入一个指向新叶结点的指针到它上一层的结点,并将该指针与键 40 关联起来,因为键 40 是通过新叶结点可访问到的最小键。同样该父结点已满,需要分裂。
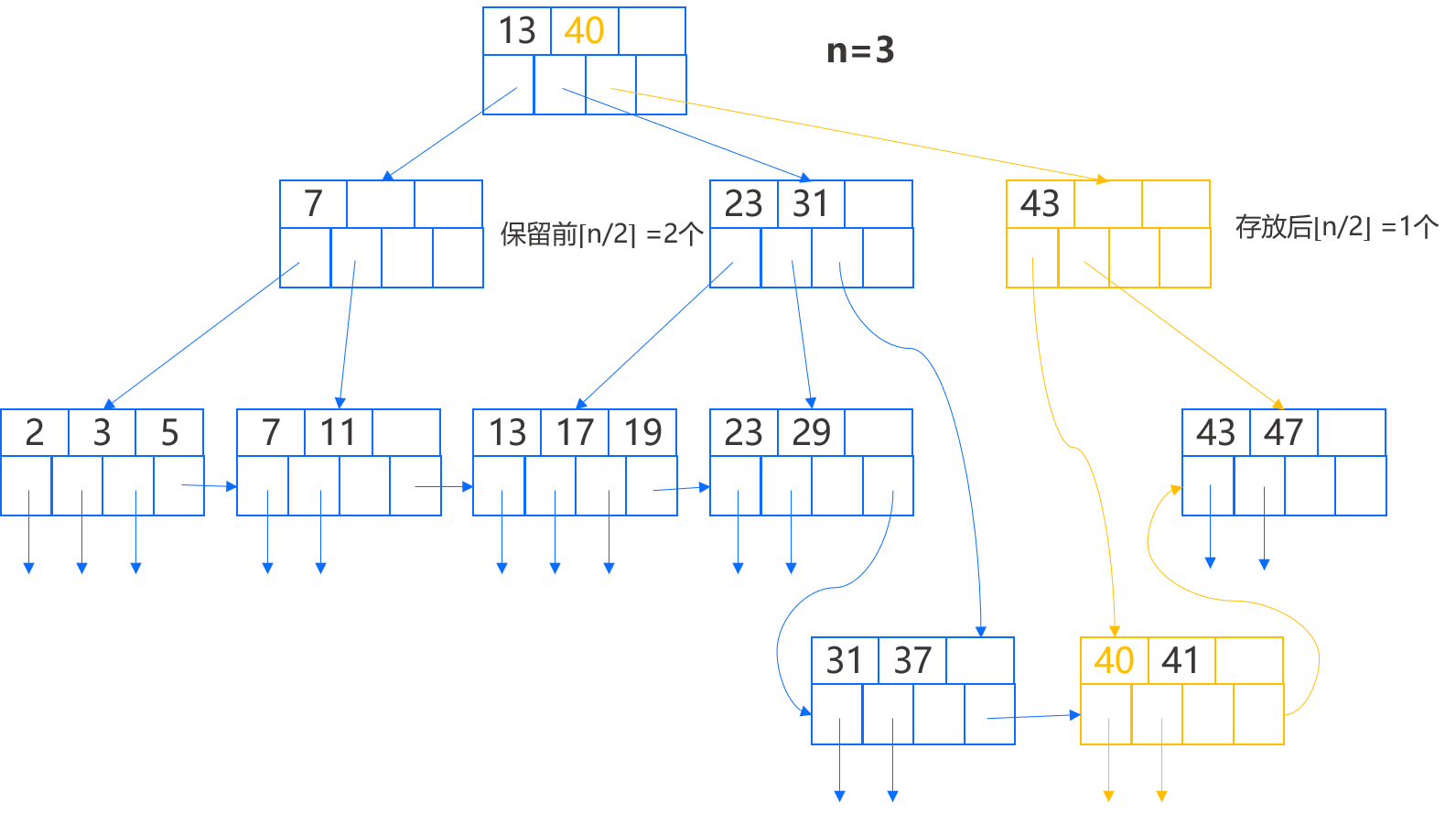
理论上我们将在父结点增加键 40,形成 23、31、40、43 的键序列,而该结点已满,因此我们将前 ⌈n/2⌉ 个键,即 23、31 保留在原父结点中,后 ⌊n/2⌋ 个键,即 43 移到新结点,而中间那个键将移动到更上一层的父结点,用来划分这两个结点之间的查找。
如果我们找到叶结点 N,并将键-指针对删除后,结点仍然满足充满度的最小约束,那么我们不需要再额外处理。但反之,我们需要为这个结点做以下两件事之一:
-
重构
-
如果与结点 N 相邻的左右兄弟中有一个的键-指针对数目超过最小约束,那么将其中的一个键-指针对移到结点 N 并保持键的顺序,并且按需调整这两个结点的父结点的键。
-
如果从右兄弟结点借键,需要保证借到最小键。
-
-
合并
-
如果两兄弟没有一个能够提供键值给结点 N 时,兄弟结点的键数必然为最小数目,那么我们把结点 N 和其中一个兄弟合并成一个新结点,即删除其中一个结点,此时新结点并不会超过最大约束。并且我们需要调整父结点中的键并删除其中一个键-指针对。
-
如果删除后父结点不再满足最小约束,那么我们需要在父结点上递归的运用这个删除算法。
-
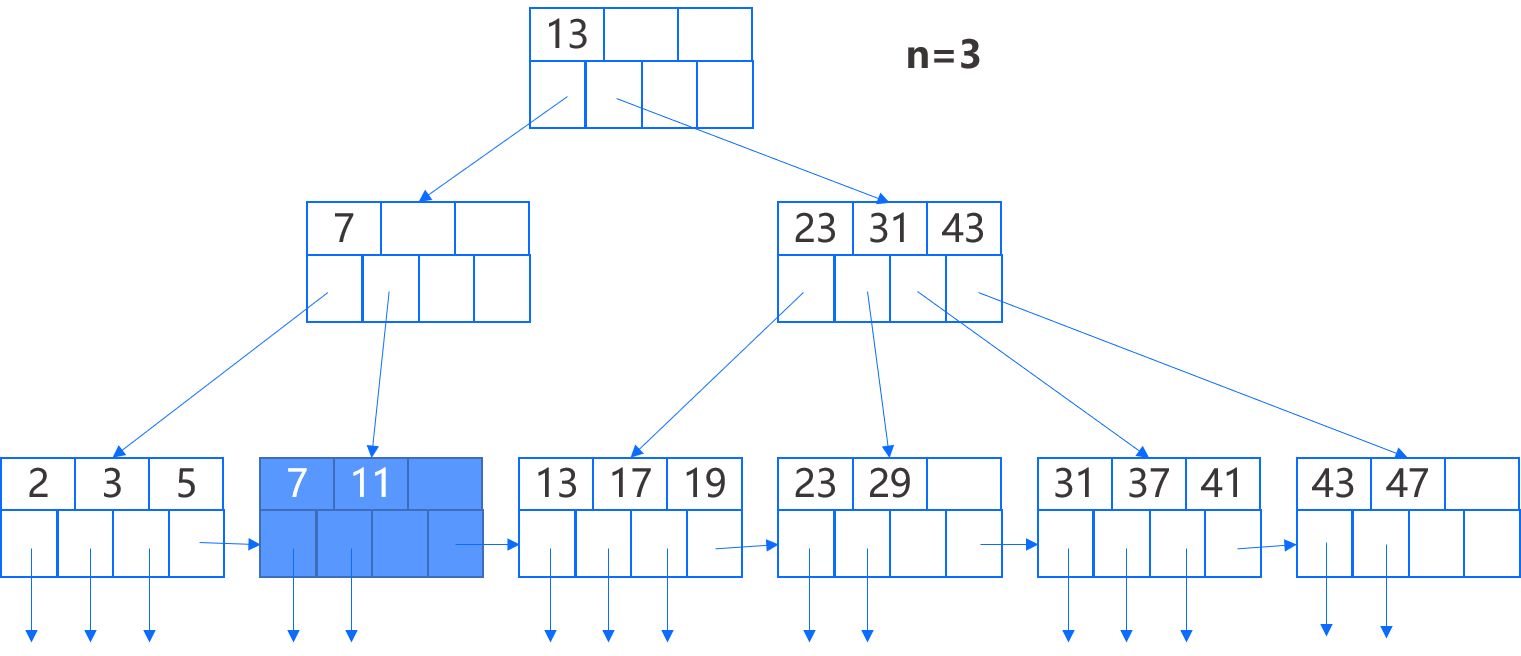
如上图 B+ 树,假设我们删除键 7,该键位于第二个叶结点,我们将其键-指针对以及指向的记录删除,此时结点只剩下一个键,而我们要求每个叶结点至少有两个键,因此我们从左兄弟移过来一个键-指针对,并将父结点的键从 7 改为 5。
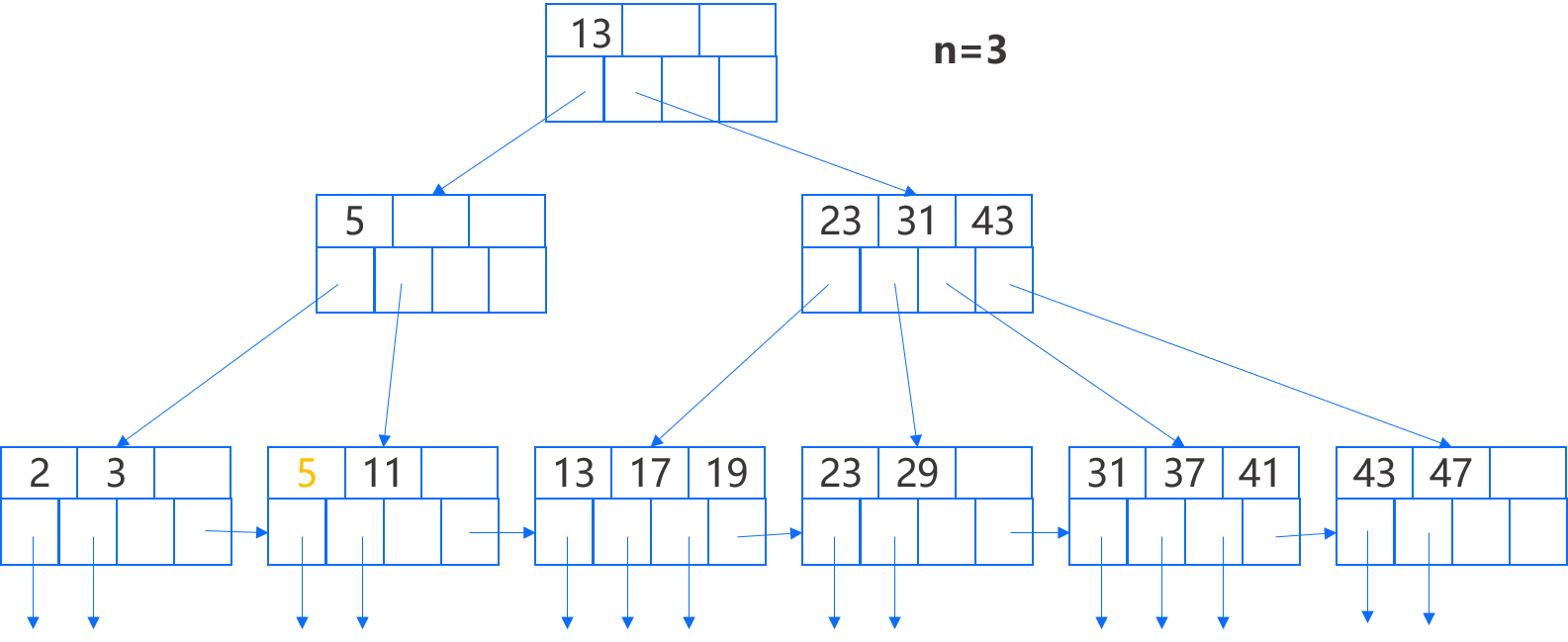
下一步,我们再删除键 11,这个删除对第二个叶结点产生同样的影响,但这次我们不能从第一个结点借键,因为后者的键数达到了最小数,另外,它的右边没有兄弟,因此我们需要合并第二个叶结点和它的兄弟,即第一个叶结点。合并后我们调整父结点,具体来说,它的两个指针被换成了一个指针,并且键 5 不再有用也被删除。
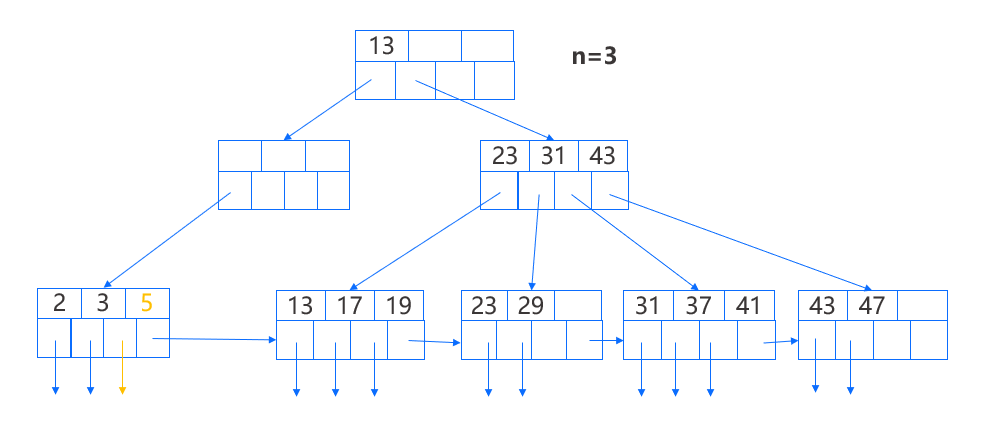
此时该父结点从右兄弟结点获得了一个指针,并更新该指针对应的键为 13,而键 13 原来位于根结点且表示通过那个被转移的指针可访问的最小键,因此根结点的键需要修改为 23,表示当前通过根结点第二个子结点可访问到的最小键。
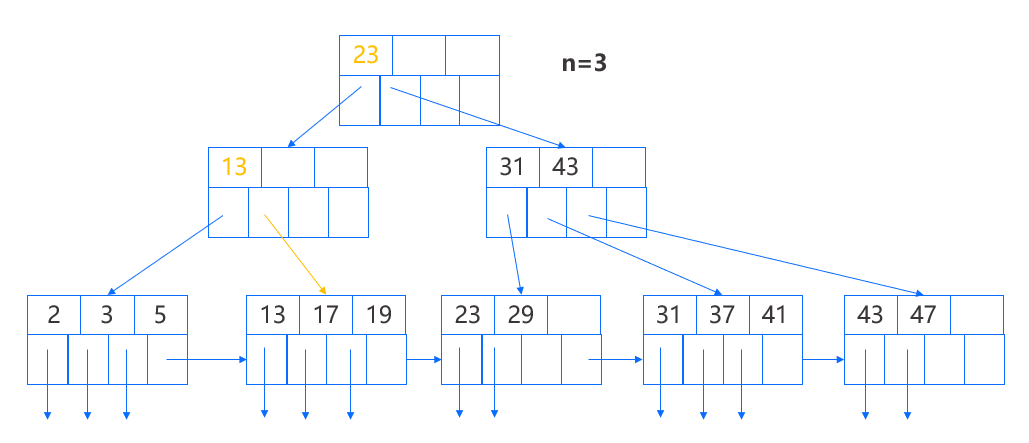
在插入和删除中的特殊操作本质上都是为了保证 B+ 树始终处于平衡状态。
这里我们提两点 B+ 树存在的主要问题:
-
随着数据量的增长,树的层数增加,叶结点的访问路径变长,开销会逐渐增大,但这通常发生在数据量足够大的场景下。
-
高速海量的数据更新下,容易发生结点的频繁分裂与合并,这种行为在树的多层之间迭代传递从而带来大量开销。