This file is the main script responsible for all the "magic". It checks if the words from the wordfile exist in the textfile.
This file needs to be created once with this command:
touch wordfile
Important: Please make sure that this file has no file extension such as '.txt' or similar!
This file needs to be created once as well. To do so, use this command:
touch textfile
Important: Please make sure that this file has no file extension such as '.txt' or similar!
This is a little tool (two lines actually) which helps clearing both the textfile and the wordfile. If you just want to clear the content of one file use this syntax:
echo "" > [filename]
- This script needs to be executed in a Linux environment. This can either be a server (VPS) or similar or - what I would recommend - Linux WSL (Windows Subsystem for Linux). Learn how to install WSL.
- Git installed in your environment. (If not installed, install it with
apt install git -y
Install/download the script with this command:
git clone https://github.com/officialrealTM/ct_keyword_checker.git
If neccessary, make the two scripts executeable with these commands:
chmod +x check.sh
chmod +x clear.sh
Before running the script make sure that both files - wordfile and textfile exist and got content in it. Important: Each keyword or keyphrase in the wordfile needs to be in their own line!
Now execute the script following this syntax:
./check.sh [true/false]
The parameter "true" or "false" define if the keyword check should be case-sensitive.
If you don't want the search to be case-sensitive use the parameter false when executing the script.
A sample output could look like this:
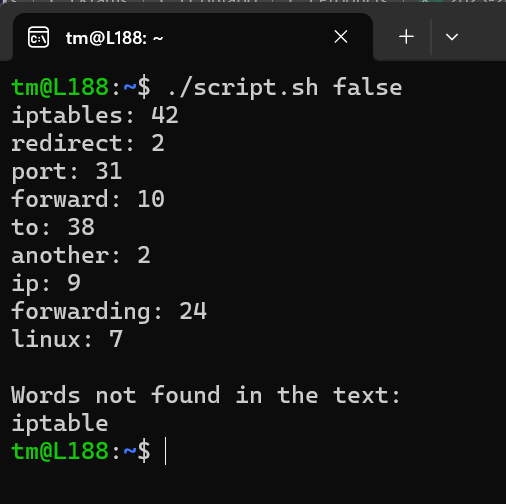
The first part of the output shows the respective keyword and the number of times it was found.
The second part shows all keywords that weren't found in the text.