-
Notifications
You must be signed in to change notification settings - Fork 0
/
LCAnalytics.Rmd
328 lines (232 loc) · 16.4 KB
/
LCAnalytics.Rmd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
---
title: "Approaching Lending Club Data with R"
output: github_document
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = TRUE)
```
## Introduction
Lending Club is the largest p2p lending platform. Other than helping diversify personal investment, LC provides a perfect dataset to get started with data analysis: data maniupuation, data visualization and predictive analysis using machine learning techniques. I've always wanted to take a deeper look and analyze the dataset myself, as it might provide some unintuitive insight. Hopefully the insight could also be invaluable to my lending decision.
With a quick google search, you can find there are many data hobbyist who have done similar work:
* My very original inspiration is from Kevin Davenport: http://kldavenport.com/lending-club-data-analysis-revisted-with-python/
* Kaggle: https://www.kaggle.com/ashokn30/d/wendykan/lending-club-loan-data/lending-club-data-some-insights
There's no need to repeat the good work that they have done. To be different and provide some new idea to the community, I want to use my own approach to answer my own questions.
## What's different?
I personally went through mortgage application twice. Throughout the process I've had a strong impression that mortgage lenders reiterate on the following 3 factors whether to approve a loan:
1. Annual income
2. DTI ratio
3. FICO score (One score that summarises credit conditions: credity history, open credit lines, credit utilitization, etc.)
Lenders must have done a lot of work and have evidence that these are the most critical things to focus on. So, how about we use them as granted that they will also be the most influential factors for personal lending as well? How do they display in lending club's dataset? Can we use them to predict bad/good loan?
## Walk through
Lending Club's public loan data can be downloaded from [here](https://www.lendingclub.com/info/download-data.action). I am using 2016Q3 data which is the most recent.
The R implementation mainly requires the following two pacakges.
```{r message=FALSE}
# for data manipulation
library(dplyr)
# for data visualization
library(ggplot2)
```
The first row and last two rows of the csv file are irrelevant but screws up the headers which display on the second row. We use read.csv(.., skip = 1) to ignore first row. Then further remove the last two rows.
```{r}
data <- read.csv('LoanStats_2016Q3.csv', stringsAsFactors = F, skip = 1)
data <- head(data, -2)
```
As always, we need to have a peek of what's in the dataset.
```{r}
dim(data)
names(data)
```
We use dplyr's select function to extract the columns that we want that are related to the 4 factors I mentioned earlier.
Select loan related fields:
* _grade_
* _sub_grade_
* _loan_status_
* _funded_amnt_
* _term_
* _int_rate_
* _installment_
Annual Income
* _annual_inc_
DTI Ratio
* _dti_
However I am not able to find FICO score field anymore. Reason 'seems' to be that LC removed this field somewhere along the road before they went public (see reference [here](http://www.lendacademy.com/lending-club-removes-data-fields/)). If I take a guess, FICO has been proven highly correlated to LC's algorithm, as a result of that, to reduce transparency LC decided to cut it out. Instead, LC releases the FICO attributes such as
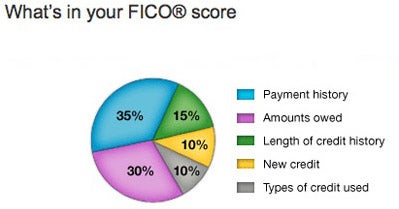
which means, unfortunately for me, I need more work. To mimic the FICO score, we can use this

as a reference, and include relevant fields into the final data frame.
FICO related
* _earliest_cr_line_
* _revol_util_
* _inq_last_12m_
* _total_bal_ex_mort_
and various other fields for future analysis (_purpose_, _emp_title_, _emp_length_, _state of address_)
I have now formed the data.frame for analysis.
```{r}
mydata <- select(data,
grade, sub_grade, loan_status, funded_amnt, term, int_rate, installment,
annual_inc,
dti,
earliest_cr_line, revol_util, inq_last_12m, total_bal_ex_mort,
purpose, emp_title, emp_length, addr_state)
```
Let's see what type of data we have included in mydata
```{r}
str(mydata)
```
For numeric analysis purpose, we need to convert some of the chr object to numeric, e.g. interest rate displaying as a charactor '11.5%' need to be converted to 0.115 as a numeric value. _earliest_cr_line_ needs some special treatment. Currently it displays the first date when credit line was opened, but to me, I am more interested in the total length in **years** since it was open. So we need to apply some transformation there.
```{r warning=FALSE}
mydata$term <- as.numeric(substr(mydata$term, 1,3))
mydata$emp_length <- as.numeric(substr(mydata$emp_length, 1,2))
mydata$int_rate <- as.numeric(gsub("%", "", mydata$int_rate)) / 100
mydata$revol_util <- as.numeric(gsub("%", "", mydata$revol_util)) / 100
mydata$earliest_cr_line <- as.numeric(difftime(Sys.Date(), as.Date(paste("01-",mydata$earliest_cr_line,sep=''), format = "%d-%b-%Y")),units = 'days')/365
```
Let's check again
```{r}
str(mydata)
```
Data look good for analysis now. let's start with **Annual Income**.
### What is the range of salary? Do high income borrowers tend to get funded more?
```{r message = FALSE}
ggplot(mydata, aes(annual_inc, funded_amnt)) +
geom_point(aes(colour = grade)) +
labs(title = 'annual inc vs. funded amnt') +
geom_smooth()
```
It appears that there are some extremely high income borrowers still borrowing money! I am talking about super duper high income. This one guy has an annual income of
```{r}
max(mydata$annual_inc)
```
Unbelievable! An annual income of $8.4 million that's comparable to C level of top 10 public companies... who is this guy?
```{r}
mydata[which(mydata$annual_inc == max(mydata$annual_inc)),]$emp_title
```
What? a Mechanical Mobile Inspector??? I don't think this is a valid information. Apparantely LC didn't do a good job maintaining the data very well. Let's see what are other high income profile's loan data look like.
```{r}
mydata[which(mydata$annual_inc > 1000000),]$emp_title
```
Well, most of million dollar salaried people have legitimate titles such as managing director, svp, portfolio manager, partner but there are teacher? dietary? I hope these are really the handful cases of bad data. But to push forward with my analysis, I decide to get rid of profiles that have annual income of greater than $500k. Just a hard cut off line under my discretion.
```{r}
mydata <- filter(mydata, annual_inc < 500000)
```
Replot the annual income vs. funded amount chart.
```{r message = FALSE}
p <- ggplot(mydata, aes(annual_inc, funded_amnt)) +
geom_point(aes(colour = grade)) +
labs(title = 'annual inc vs. funded amnt') +
geom_smooth()
p
```
Much better! We know that LC cap the funding limit to $40k so we see no high funded amount greater than that. Overall we see a pretty linear relationship for annual income < $100k. Beyond that, we see the regression line going flat due to the hard cap of $40k. If we drill in to < $100k annual income borrowers, we will see a clearer linear relationship.
```{r warning=FALSE, message=FALSE}
p + xlim(0,100000) + facet_grid(. ~ grade) + geom_smooth()
```
The steepness of the regression line confirms that the more money borrowed relative to income, the higher risk (lower grade) the loan is. At this point, there is no doubt that annual income is one major factor to determine the grade of a loan. A better way to look at the slope is to use (installment / monthly income) ratio.
```{r warning=FALSE}
# Add a new column called lc_dti
mydata <- mutate(mydata, monthly_inc = annual_inc/12, lc_dti = installment/monthly_inc)
# lc_dti density by grade
ggplot(data = mydata, aes(lc_dti)) + xlim(0,0.5) +
geom_density(aes(fill = grade)) +
facet_grid(grade ~ .)
```
The lending club obligation to monthly income displays interesting results. For high-grade loan, the majority of the borrowers will not commit more than 10% of the income on Lending club loan while low-grade borrowers do tend to exceed that threshold. My rule of thumb is that, if you are able to find the monthly repayment < 10% of the borrower's income, this would tend to be a good loan.
### Debt-to-Income Ratio (DTI)
In fact, I have just constructed a Lending Club specific DTI ratio above using LC's monthly payment divided by monthly income, in which we've found it useful in distinguishing grades. The DTI in the dataset is a more generally heard one that excludes mortgage but include all other debts such as credit card, car loan etc. So let's see what those reported DTI is telling.
```{r warning=FALSE}
d <- ggplot(data = mydata, aes(dti/100)) + xlim(0,1)
d <- d + geom_density(aes(fill = grade))
d + facet_grid(grade ~ .)
```
dti displays similar feature as lc_dti with high grade loan skew to the right and low grade to the left
### How about LC_DTI / DTI Ratio? This will answer how much LC Debt borrowers is willing to obligate in addition to existing debt.
```{r warning=FALSE}
mydata <- mutate(mydata, lcd_to_tot_debt = lc_dti / (dti/100))
ggplot(data = mydata, aes(lcd_to_tot_debt)) + xlim(0,1) +
geom_density(aes(fill = grade)) +
facet_grid(grade ~ .)
```
Even the majority of the worst grade (G) loan would not comprise more than 50% of the total debt. So, Lending Club is surely **NOT** the major lenders that most people take loan from. If someone took more debt on LC than anywhere else, he/she is likely have financial issue.
### Let's move on to the FICO attributes
```{r warning=FALSE}
ggplot(data = mydata, aes(earliest_cr_line)) +
geom_density(aes(fill = grade)) +
facet_grid(grade ~.) +
xlim(0,40) +
labs(title = 'Earliest credit line distribution by grade')
```
According to the distribution plots, you can generally tell that regardless of loan grade, most of the borrowers have credit history of approximately 12 years. Shapes of the distribution are similar as well with higher grade's having fatter tails towards longer history. On the opposite side, lower grade displays positive skew. A better plot would be to put all distributions under one pane overlaying each other. That is,
```{r warning=FALSE}
ggplot(data = mydata, aes(earliest_cr_line)) +
geom_density(aes(colour = grade)) +
xlim(0,40) +
labs(title = 'Earliest credit line distribution by grade')
```
Unlike what we've seen on funded amount and DTI factors, if you ask me which loan is a better loan solely by looking at the credit history, my answer is I can't tell. Because the margin (difference) between different distributions is so marginal especially between low grades.
Although a tendency that longer credit history indicates higher quality, the edge isn't as big as the previous plot shows. I personally don't think the length of credit history is a strong determining factor for grading. Let's move on to the other three attributes.
```{r warning=FALSE}
ggplot(data = mydata, aes(revol_util)) +
geom_density(aes(colour = grade)) +
labs(title = 'Revolving Utilization distribution by grade')
ggplot(data = mydata, aes(inq_last_12m)) +
geom_density(aes(colour = grade, fill = grade)) +
labs(title = 'Last 12m Inquiry by grade') + xlim(0,30) +
facet_wrap( ~ grade)
ggplot(data = mydata, aes(total_bal_ex_mort)) +
geom_density(aes(colour = grade)) +
labs(title = 'total balance excl. mortgage by grade') +
xlim(0,100000)
```
These three plots explains the other three FICO attributes.
* The revolving utilization among different grade displays a centralization at 0.5 but with one exception - Grade A loans that has significantly below 0.5, somewhere at 0.25. Again this isn't too good a indicative plot that anticipated to display smoother transition between grades. The only solid information is the low revovling utilization in Grade A holders.
* Last 12m credit inquiry is also indifferentiable. The number of inquiry between different grades generally cluster below 20. The only difference lies in the tails. Again this is minor.
* total balance excl mortgage. The difference above 25k is indifferentiable again. The less amount owed, the higher grade the loan is. That is reasonable but again this isn't a very strong differentiator.
Overall, none of the FICO attributes provides a visually strong indication of the loan quality. Although there are a few observations that could be helpful in indentifying extremely good quality borrowers, for the majority of loans, these 4 attributes ain't very differentiable.
Since we can't visualize it, can we try the machine learning way?
## Machine Learning
### Multiclassification using Random Forest
Let's define our problem. Previously we've established a strong belief that Annual Income and DTI are two major factors of a high quality loan. But there are still many input variables that we have not investigated into, especially my hypothesis that the FICO attributes may also be a major identifiers of a good loan.
Let's set aside Annual Income and DTI, leaving the rest of the input variables as our focus going forward. Also, installment and funded_amnt are directly related to DTI, so can be excluded as well. I want to know, without the apparent factors, using the rest, can we also find some hidden relationship between them and the predictions which is the grade of the loan. Since "grade" has 7 levels, this will become a multiclassificaion problem.
```{r}
mydata_ex <- select(mydata, grade, term, int_rate, earliest_cr_line, revol_util, inq_last_12m, total_bal_ex_mort, purpose, emp_title, emp_length, addr_state)
# Convert chr columns to factors
mydata_ex[sapply(mydata_ex, is.character)] <- lapply(mydata_ex[sapply(mydata_ex, is.character)], as.factor)
str(mydata_ex)
```
Since int_rate are set according to grade, or vice versa. Due to high correlation by nature, this will dominate the predictor rank which are not helpful for us. I can drop this column.
emp_title contains 37370 levels, which would be highly independent (random) to the grade, I would not want to overcomplicate my problem, hence this can be dropped.
```{r}
mydata_ex <- select(mydata_ex, -int_rate, -emp_title)
```
Since randomForest doesn't take input containing NAs, I want to know if any of the input variables contain NAs, and how many of them.
```{r}
colSums(is.na(mydata_ex))
```
revol_util contains 59 NAs while emp_length seems to have a bigger problem which contains 13018 NAs. If removing all the observations that contain NAs, I will lose 14% of my samples. This is not too bad because after all we still have a pretty decent size of sample.
```{r}
mydata_ex <- na.omit(mydata_ex)
nrow(mydata_ex)
```
Now, I can throw in the Random Forest Classifier
```{r, message=FALSE}
library(randomForest)
# build a Random Forest
rf <- randomForest(data = mydata_ex, grade~., ntree = 100, mtry = 3, importance = T, keep.forest = T, na.action = na.omit)
rf
```
That's a pretty bad classifer isn't it. This is no surprise because we wasn't able to find patterns by visualizing the relationship. There is unlikely any predictive power in those factors. Additionally, and which I found most difficult to handle in many real cases is that the imbalanced of the classes in the dataset You can easily tell that, the majority of the loan grades lies in B, C and D, while the two ends are only a small fraction of the total loans.
```{r}
summarise(group_by(mydata_ex, grade), n = n())
```
This is where I can use my own in output re-engineering, instead of classifying into 7, with highly imbalanced dataset. Can I re-define the problem into a binary 2-class problem. Good loans for those in Grade A and B, while bad loans are the rest from Grade C to G?
This way of simplification might help my classifier do a better job with a much more balanced output variables.
A simple transformation can be done by:
```{r}
Good <- c('A','B')
mydata_ex <- mutate(mydata_ex, label = ifelse(grade %in% Good, 1,0))
mydata_ex$label <- factor(mydata_ex$label)
mydata_ex$grade <- NULL
rf2 <- randomForest(data = mydata_ex, label~., ntree = 100, mtry = 3, importance = T, keep.forest = T, na.action = na.omit)
rf2
```
after re-label the output variables still doesn't yield a better classifier. As you can see now the classifier is heavily biased to predicting loan as bad loan! This again suggests that none of the features is capable of distinguish bad/good loan. You would think that, employment length, revolcing utilization might intuitively show some potential. But, just as the same as what we did using visualizaion approach, there is no clear evidence.