This repository contains an implementation of this paper.
clustering.py - Contains the implementaion of the clustering algorithm.
demo.py - An example to demonstrate usage. To run this, you need to download the LFW data from here. For the face vectors, I used the results from Alfred Xiang Wu's Face Verification Experiment. Also evaluates clustering on the LFW dataset using evaluation.py.
evaluation.py - Script to calculate pairwise precision and recall as explained in the paper. TODO
server.py - Script to visualize the results.
You will need cmake for this installation.
Create a new virtual environment and clone the repository.
mkvirtualenv (env-name)
workon (env-name)
git clone https:github.com/varun-suresh/Clustering.git
Follow the instructions here to install pyflann.
For the demo, download the LFW data and the face vectors as mentioned above and run
cd Clustering
python demo.py --lfw_path path_to_lfw_dir -v vector_file
There is a very basic visualization script in place to examine the clusters. To
use the script, download the LFW images and store them in yourpath/Clustering/ directory.
Before you can run the visualization script, you must run the demo script to save the clusters. I have also uploaded the clusters file. You can download that and visualize the clusters as well.
python visualize.py --lfw_path lfw/
On your browser, open this link and you should see the clusters.
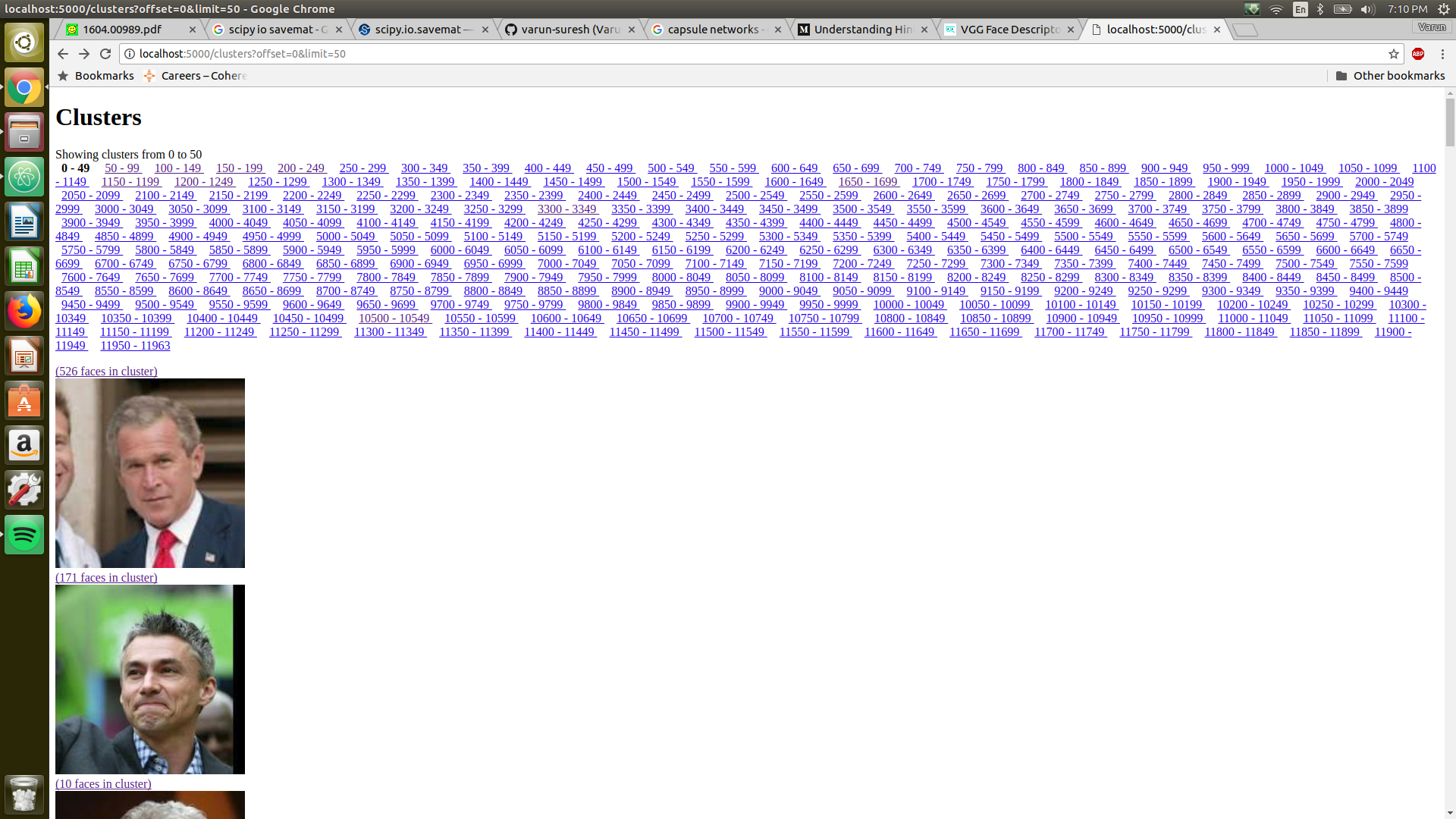
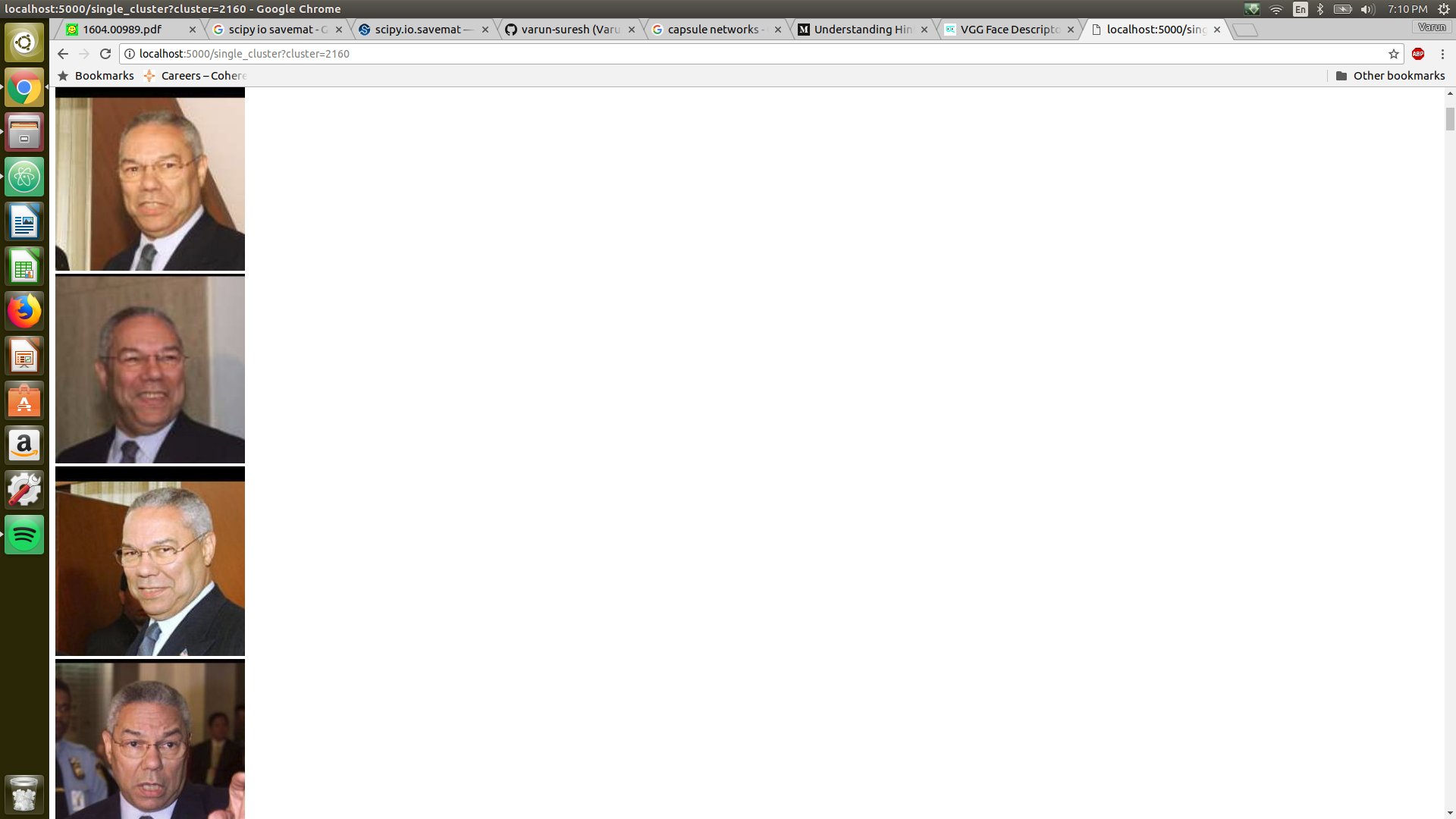
We get a f1 score of 0.88 ~ 0.9 on the LFW dataset.
Thanks Mengyue for looking closely at the precision drop and correcting the error.
Using python's multiprocessing module, clustering LFW faces took about ~40 seconds. I did this on an 8-core machine using 4 processes(Using all 8 does not improve it by much because some cores are needed for background processes). The same experiment took 7 seconds on a 20 core machine.
You should cite the following paper if you use the algorithm.
@ARTICLE{2016arXiv160400989O,
author = {{Otto}, C. and {Wang}, D. and {Jain}, A.~K.},
title = "{Clustering Millions of Faces by Identity}",
journal = {ArXiv e-prints},
archivePrefix = "arXiv",
eprint = {1604.00989},
Face verification experiment
@article{wulight,
title={A Light CNN for Deep Face Representation with Noisy Labels},
author={Wu, Xiang and He, Ran and Sun, Zhenan and Tan, Tieniu}
journal={arXiv preprint arXiv:1511.02683},
year={2015}
}
If you use this implementation, please consider citing this implementation and code repository.