Kentaro Wada,
Edgar Sucar,
Stephen James,
Daniel Lenton,
Andrew J. Davison
Dyson Robotics Laboratory , Imperial College London
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020
Dyson Robotics Laboratory , Imperial College London
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020

MoreFusion is an object-level reconstruction system that builds a map with known-shaped objects, exploiting volumetric reconstruction of detected objects in a real-time, incremental scene reconstruction senario. The key components are:
- Occupancy-based volumetric reconstruction of detected objects for model alignment in the later stage;
- Volumetric pose prediction that exploits volumetric reconstruction and CNN feature extraction from the image observation;
- Joint pose refinement of objects based on geometric consistency among objects and impenetrable space.



There're several options for installation:
- Python project only: Python framework for pose estimation (e.g., training, inference, refinement).
- ROS project for camera demonstration: ROS framework for object-level mapping with live cameras.
- ROS project for robotic demonstration: ROS framework for robotic demonstration with object-level mapping.
NOTE: We have developed this project on Ubuntu 16.04 (and ROS Kinetic, CUDA 10.1), so several code changes may be needed to adapt to other OS (and ROS, CUDA versions).
make install
source .anaconda3/bin/activatecd ros/
make install
source ../.anaconda3/bin/activate
source devel/setup.shrobot-agent: A computer with CUDA and a GPU for visual processing.robot-node: A computer with a real-time OS for a Panda robot.
Same as above instruction: ROS project for camera demonstration.
cd ros/
catkin build morefusion_ros_panda
source devel/setup.sh
rosrun morefusion_ros_panda create_udev_rules.shPre-trained models are provided in the demos as following, so this process is optional to run the demos.
cd examples/ycb_video/instance_segm
./download_dataset.py
mpirun -n 4 python train_multi.py # 4-gpu training
./image_demo.py --model logs/XXX/XXX.npz# baseline model (point-cloud-based)
cd examples/ycb_video/singleview_pcd
./download_dataset.py
./train.py --gpu 0 --centerize-pcd --pretrained-resnet18 # 1-gpu
mpirun -n 4 ./train.py --multi-node --centerize-pcd --pretrained-resnet18 # 4-gpu
# volumetric prediction model (3D-CNN-based)
cd examples/ycb_video/singleview_3d
./download_dataset.py
./train.py --gpu 0 --pretrained-resnet18 --with-occupancy # 1-gpu
mpirun -n 4 ./train.py --multi-node --pretrained-resnet18 --with-occupancy # 4-gpu
mpirun -n 4 ./train.py --multi-node --pretrained-resnet18 # w/o occupancy
# inference
./download_pretrained_model.py # for downloading pretrained model
./demo.py logs/XXX/XXX.npz
./evaluate.py logs/XXXcd examples/ycb_video/pose_refinement
./check_icp_vs_icc.py # press [s] to start# using orb-slam2 for camera tracking
roslaunch morefusion_ros rs_rgbd.launch
roslaunch morefusion_ros rviz_static.desk.launch
roslaunch morefusion_ros setup_static.desk.launch
Figure 1. Static Scene Reconstruction with the Human Hand-mounted Camera.
# using robotic kinematics for camera tracking
roslaunch morefusion_ros rs_rgbd.robot.launch
roslaunch morefusion_ros rviz_static.robot.launch
roslaunch morefusion_ros setup_static.robot.launch
Figure 2. Static Scene Reconstruction with the Robotic Hand-mounted Camera.
roslaunch morefusion_ros rs_rgbd.launch
roslaunch morefusion_ros rviz_dynamic.desk.launch
roslaunch morefusion_ros setup_dynamic.desk.launch
roslaunch morefusion_ros rs_rgbd.robot.launch
roslaunch morefusion_ros rviz_dynamic.robot.launch
roslaunch morefusion_ros setup_dynamic.robot.launch
Figure 3. Dynamic Scene Reconstruction with the Human Hand-mounted Camera.
robot-agent $ sudo ntpdate 0.uk.pool.ntp.org # for time synchronization
robot-node $ sudo ntpdate 0.uk.pool.ntp.org # for time synchronization
robot-node $ roscore
robot-agent $ roslaunch morefusion_ros_panda panda.launch
robot-node $ roslaunch morefusion_ros rs_rgbd.robot.launch
robot-node $ roslaunch morefusion_ros rviz_static.launch
robot-node $ roslaunch morefusion_ros setup_static.robot.launch TARGET:=2
robot-node $ rosrun morefusion_ros robot_demo_node.py
>>> ri.run()


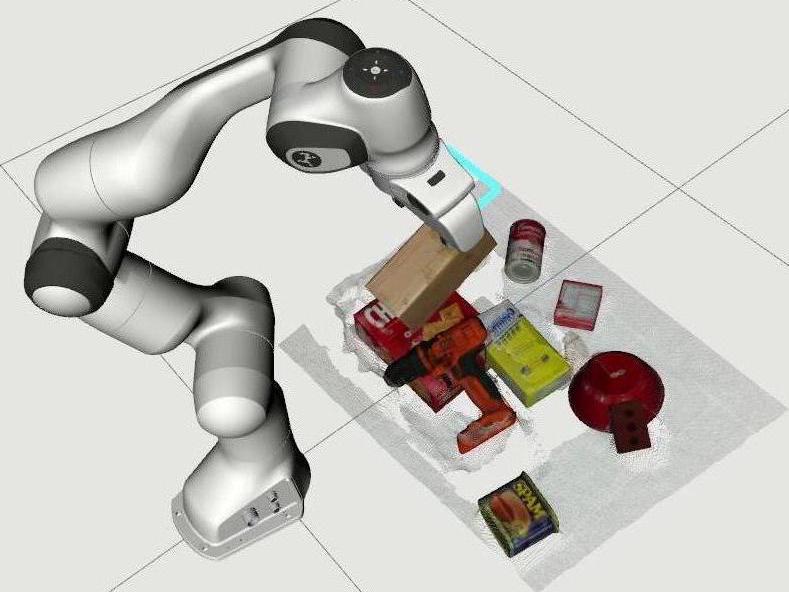
Figure 4. Targetted Object Pick-and-Place. (a) Scanning the Scene; (b) Removing Distractor Objects; (c) Picking Target Object.
If you find MoreFusion useful, please consider citing the paper as:
@inproceedings{Wada:etal:CVPR2020,
title={{MoreFusion}: Multi-object Reasoning for {6D} Pose Estimation from Volumetric Fusion},
author={Kentaro Wada and Edgar Sucar and Stephen James and Daniel Lenton and Andrew J. Davison},
booktitle={Proceedings of the {IEEE} Conference on Computer Vision and Pattern Recognition ({CVPR})},
year={2020},
}