diff --git a/docker/test/fuzzer/run-fuzzer.sh b/docker/test/fuzzer/run-fuzzer.sh
index 5cda0831a847..05cc92ee0408 100755
--- a/docker/test/fuzzer/run-fuzzer.sh
+++ b/docker/test/fuzzer/run-fuzzer.sh
@@ -122,6 +122,23 @@ EOL
$PWD
EOL
+
+ # Setup a cluster for logs export to ClickHouse Cloud
+ # Note: these variables are provided to the Docker run command by the Python script in tests/ci
+ if [ -n "${CLICKHOUSE_CI_LOGS_HOST}" ]
+ then
+ echo "
+remote_servers:
+ system_logs_export:
+ shard:
+ replica:
+ secure: 1
+ user: ci
+ host: '${CLICKHOUSE_CI_LOGS_HOST}'
+ port: 9440
+ password: '${CLICKHOUSE_CI_LOGS_PASSWORD}'
+" > db/config.d/system_logs_export.yaml
+ fi
}
function filter_exists_and_template
@@ -223,7 +240,22 @@ quit
done
clickhouse-client --query "select 1" # This checks that the server is responding
kill -0 $server_pid # This checks that it is our server that is started and not some other one
- echo Server started and responded
+ echo 'Server started and responded'
+
+ # Initialize export of system logs to ClickHouse Cloud
+ if [ -n "${CLICKHOUSE_CI_LOGS_HOST}" ]
+ then
+ export EXTRA_COLUMNS_EXPRESSION="$PR_TO_TEST AS pull_request_number, '$SHA_TO_TEST' AS commit_sha, '$CHECK_START_TIME' AS check_start_time, '$CHECK_NAME' AS check_name, '$INSTANCE_TYPE' AS instance_type"
+ # TODO: Check if the password will appear in the logs.
+ export CONNECTION_PARAMETERS="--secure --user ci --host ${CLICKHOUSE_CI_LOGS_HOST} --password ${CLICKHOUSE_CI_LOGS_PASSWORD}"
+
+ /setup_export_logs.sh
+
+ # Unset variables after use
+ export CONNECTION_PARAMETERS=''
+ export CLICKHOUSE_CI_LOGS_HOST=''
+ export CLICKHOUSE_CI_LOGS_PASSWORD=''
+ fi
# SC2012: Use find instead of ls to better handle non-alphanumeric filenames. They are all alphanumeric.
# SC2046: Quote this to prevent word splitting. Actually I need word splitting.
diff --git a/docker/test/install/deb/Dockerfile b/docker/test/install/deb/Dockerfile
index 9614473c69b4..e9c928b1fe7e 100644
--- a/docker/test/install/deb/Dockerfile
+++ b/docker/test/install/deb/Dockerfile
@@ -12,6 +12,7 @@ ENV \
# install systemd packages
RUN apt-get update && \
apt-get install -y --no-install-recommends \
+ sudo \
systemd \
&& \
apt-get clean && \
diff --git a/docs/_includes/install/universal.sh b/docs/_includes/install/universal.sh
index 5d4571aed9ea..0ae77f464eba 100755
--- a/docs/_includes/install/universal.sh
+++ b/docs/_includes/install/universal.sh
@@ -36,6 +36,9 @@ then
elif [ "${ARCH}" = "riscv64" ]
then
DIR="riscv64"
+ elif [ "${ARCH}" = "s390x" ]
+ then
+ DIR="s390x"
fi
elif [ "${OS}" = "FreeBSD" ]
then
diff --git a/docs/en/engines/database-engines/materialized-mysql.md b/docs/en/engines/database-engines/materialized-mysql.md
index f7cc52e622e5..b7e567c7b6cd 100644
--- a/docs/en/engines/database-engines/materialized-mysql.md
+++ b/docs/en/engines/database-engines/materialized-mysql.md
@@ -190,7 +190,7 @@ These are the schema conversion manipulations you can do with table overrides fo
* Modify [column TTL](/docs/en/engines/table-engines/mergetree-family/mergetree.md/#mergetree-column-ttl).
* Modify [column compression codec](/docs/en/sql-reference/statements/create/table.md/#codecs).
* Add [ALIAS columns](/docs/en/sql-reference/statements/create/table.md/#alias).
- * Add [skipping indexes](/docs/en/engines/table-engines/mergetree-family/mergetree.md/#table_engine-mergetree-data_skipping-indexes)
+ * Add [skipping indexes](/docs/en/engines/table-engines/mergetree-family/mergetree.md/#table_engine-mergetree-data_skipping-indexes). Note that you need to enable `use_skip_indexes_if_final` setting to make them work (MaterializedMySQL is using `SELECT ... FINAL` by default)
* Add [projections](/docs/en/engines/table-engines/mergetree-family/mergetree.md/#projections). Note that projection optimizations are
disabled when using `SELECT ... FINAL` (which MaterializedMySQL does by default), so their utility is limited here.
`INDEX ... TYPE hypothesis` as [described in the v21.12 blog post]](https://clickhouse.com/blog/en/2021/clickhouse-v21.12-released/)
diff --git a/docs/en/engines/table-engines/mergetree-family/annindexes.md b/docs/en/engines/table-engines/mergetree-family/annindexes.md
index 5944048f6c37..81c69215472a 100644
--- a/docs/en/engines/table-engines/mergetree-family/annindexes.md
+++ b/docs/en/engines/table-engines/mergetree-family/annindexes.md
@@ -1,4 +1,4 @@
-# Approximate Nearest Neighbor Search Indexes [experimental] {#table_engines-ANNIndex}
+# Approximate Nearest Neighbor Search Indexes [experimental]
Nearest neighborhood search is the problem of finding the M closest points for a given point in an N-dimensional vector space. The most
straightforward approach to solve this problem is a brute force search where the distance between all points in the vector space and the
@@ -17,7 +17,7 @@ In terms of SQL, the nearest neighborhood problem can be expressed as follows:
``` sql
SELECT *
-FROM table
+FROM table_with_ann_index
ORDER BY Distance(vectors, Point)
LIMIT N
```
@@ -32,7 +32,7 @@ An alternative formulation of the nearest neighborhood search problem looks as f
``` sql
SELECT *
-FROM table
+FROM table_with_ann_index
WHERE Distance(vectors, Point) < MaxDistance
LIMIT N
```
@@ -45,12 +45,12 @@ With brute force search, both queries are expensive (linear in the number of poi
`Point` must be computed. To speed this process up, Approximate Nearest Neighbor Search Indexes (ANN indexes) store a compact representation
of the search space (using clustering, search trees, etc.) which allows to compute an approximate answer much quicker (in sub-linear time).
-# Creating and Using ANN Indexes
+# Creating and Using ANN Indexes {#creating_using_ann_indexes}
Syntax to create an ANN index over an [Array](../../../sql-reference/data-types/array.md) column:
```sql
-CREATE TABLE table
+CREATE TABLE table_with_ann_index
(
`id` Int64,
`vectors` Array(Float32),
@@ -63,7 +63,7 @@ ORDER BY id;
Syntax to create an ANN index over a [Tuple](../../../sql-reference/data-types/tuple.md) column:
```sql
-CREATE TABLE table
+CREATE TABLE table_with_ann_index
(
`id` Int64,
`vectors` Tuple(Float32[, Float32[, ...]]),
@@ -83,7 +83,7 @@ ANN indexes support two types of queries:
``` sql
SELECT *
- FROM table
+ FROM table_with_ann_index
[WHERE ...]
ORDER BY Distance(vectors, Point)
LIMIT N
@@ -93,7 +93,7 @@ ANN indexes support two types of queries:
``` sql
SELECT *
- FROM table
+ FROM table_with_ann_index
WHERE Distance(vectors, Point) < MaxDistance
LIMIT N
```
@@ -103,7 +103,7 @@ To avoid writing out large vectors, you can use [query
parameters](/docs/en/interfaces/cli.md#queries-with-parameters-cli-queries-with-parameters), e.g.
```bash
-clickhouse-client --param_vec='hello' --query="SELECT * FROM table WHERE L2Distance(vectors, {vec: Array(Float32)}) < 1.0"
+clickhouse-client --param_vec='hello' --query="SELECT * FROM table_with_ann_index WHERE L2Distance(vectors, {vec: Array(Float32)}) < 1.0"
```
:::
@@ -138,7 +138,7 @@ back to a smaller `GRANULARITY` values only in case of problems like excessive m
was specified for ANN indexes, the default value is 100 million.
-# Available ANN Indexes
+# Available ANN Indexes {#available_ann_indexes}
- [Annoy](/docs/en/engines/table-engines/mergetree-family/annindexes.md#annoy-annoy)
@@ -165,7 +165,7 @@ space in random linear surfaces (lines in 2D, planes in 3D etc.).
Syntax to create an Annoy index over an [Array](../../../sql-reference/data-types/array.md) column:
```sql
-CREATE TABLE table
+CREATE TABLE table_with_annoy_index
(
id Int64,
vectors Array(Float32),
@@ -178,7 +178,7 @@ ORDER BY id;
Syntax to create an ANN index over a [Tuple](../../../sql-reference/data-types/tuple.md) column:
```sql
-CREATE TABLE table
+CREATE TABLE table_with_annoy_index
(
id Int64,
vectors Tuple(Float32[, Float32[, ...]]),
@@ -188,23 +188,17 @@ ENGINE = MergeTree
ORDER BY id;
```
-Annoy currently supports `L2Distance` and `cosineDistance` as distance function `Distance`. If no distance function was specified during
-index creation, `L2Distance` is used as default. Parameter `NumTrees` is the number of trees which the algorithm creates (default if not
-specified: 100). Higher values of `NumTree` mean more accurate search results but slower index creation / query times (approximately
-linearly) as well as larger index sizes.
+Annoy currently supports two distance functions:
+- `L2Distance`, also called Euclidean distance, is the length of a line segment between two points in Euclidean space
+ ([Wikipedia](https://en.wikipedia.org/wiki/Euclidean_distance)).
+- `cosineDistance`, also called cosine similarity, is the cosine of the angle between two (non-zero) vectors
+ ([Wikipedia](https://en.wikipedia.org/wiki/Cosine_similarity)).
-`L2Distance` is also called Euclidean distance, the Euclidean distance between two points in Euclidean space is the length of a line segment between the two points.
-For example: If we have point P(p1,p2), Q(q1,q2), their distance will be d(p,q)
-
+For normalized data, `L2Distance` is usually a better choice, otherwise `cosineDistance` is recommended to compensate for scale. If no
+distance function was specified during index creation, `L2Distance` is used as default.
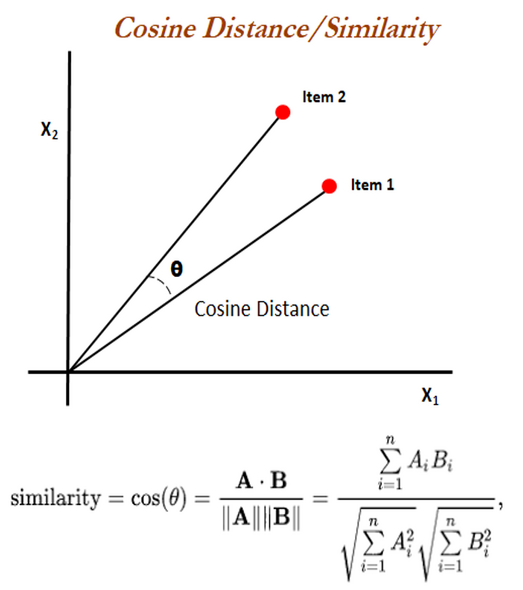
-`cosineDistance` also called cosine similarity is a measure of similarity between two non-zero vectors defined in an inner product space. Cosine similarity is the cosine of the angle between the vectors; that is, it is the dot product of the vectors divided by the product of their lengths.
-
-
-The Euclidean distance corresponds to the L2-norm of a difference between vectors. The cosine similarity is proportional to the dot product of two vectors and inversely proportional to the product of their magnitudes.
-
-In one sentence: cosine similarity care only about the angle between them, but do not care about the "distance" we normally think.
-
-
+Parameter `NumTrees` is the number of trees which the algorithm creates (default if not specified: 100). Higher values of `NumTree` mean
+more accurate search results but slower index creation / query times (approximately linearly) as well as larger index sizes.
:::note
Indexes over columns of type `Array` will generally work faster than indexes on `Tuple` columns. All arrays **must** have same length. Use
diff --git a/docs/en/interfaces/formats.md b/docs/en/interfaces/formats.md
index 0d1308afc4db..e21223805106 100644
--- a/docs/en/interfaces/formats.md
+++ b/docs/en/interfaces/formats.md
@@ -11,82 +11,83 @@ results of a `SELECT`, and to perform `INSERT`s into a file-backed table.
The supported formats are:
| Format | Input | Output |
-|-------------------------------------------------------------------------------------------|------|--------|
-| [TabSeparated](#tabseparated) | ✔ | ✔ |
-| [TabSeparatedRaw](#tabseparatedraw) | ✔ | ✔ |
-| [TabSeparatedWithNames](#tabseparatedwithnames) | ✔ | ✔ |
-| [TabSeparatedWithNamesAndTypes](#tabseparatedwithnamesandtypes) | ✔ | ✔ |
-| [TabSeparatedRawWithNames](#tabseparatedrawwithnames) | ✔ | ✔ |
-| [TabSeparatedRawWithNamesAndTypes](#tabseparatedrawwithnamesandtypes) | ✔ | ✔ |
-| [Template](#format-template) | ✔ | ✔ |
-| [TemplateIgnoreSpaces](#templateignorespaces) | ✔ | ✗ |
-| [CSV](#csv) | ✔ | ✔ |
-| [CSVWithNames](#csvwithnames) | ✔ | ✔ |
-| [CSVWithNamesAndTypes](#csvwithnamesandtypes) | ✔ | ✔ |
-| [CustomSeparated](#format-customseparated) | ✔ | ✔ |
-| [CustomSeparatedWithNames](#customseparatedwithnames) | ✔ | ✔ |
-| [CustomSeparatedWithNamesAndTypes](#customseparatedwithnamesandtypes) | ✔ | ✔ |
-| [SQLInsert](#sqlinsert) | ✗ | ✔ |
-| [Values](#data-format-values) | ✔ | ✔ |
-| [Vertical](#vertical) | ✗ | ✔ |
-| [JSON](#json) | ✔ | ✔ |
-| [JSONAsString](#jsonasstring) | ✔ | ✗ |
-| [JSONStrings](#jsonstrings) | ✔ | ✔ |
-| [JSONColumns](#jsoncolumns) | ✔ | ✔ |
-| [JSONColumnsWithMetadata](#jsoncolumnsmonoblock)) | ✔ | ✔ |
-| [JSONCompact](#jsoncompact) | ✔ | ✔ |
-| [JSONCompactStrings](#jsoncompactstrings) | ✗ | ✔ |
-| [JSONCompactColumns](#jsoncompactcolumns) | ✔ | ✔ |
-| [JSONEachRow](#jsoneachrow) | ✔ | ✔ |
-| [PrettyJSONEachRow](#prettyjsoneachrow) | ✗ | ✔ |
-| [JSONEachRowWithProgress](#jsoneachrowwithprogress) | ✗ | ✔ |
-| [JSONStringsEachRow](#jsonstringseachrow) | ✔ | ✔ |
-| [JSONStringsEachRowWithProgress](#jsonstringseachrowwithprogress) | ✗ | ✔ |
-| [JSONCompactEachRow](#jsoncompacteachrow) | ✔ | ✔ |
-| [JSONCompactEachRowWithNames](#jsoncompacteachrowwithnames) | ✔ | ✔ |
-| [JSONCompactEachRowWithNamesAndTypes](#jsoncompacteachrowwithnamesandtypes) | ✔ | ✔ |
-| [JSONCompactStringsEachRow](#jsoncompactstringseachrow) | ✔ | ✔ |
-| [JSONCompactStringsEachRowWithNames](#jsoncompactstringseachrowwithnames) | ✔ | ✔ |
-| [JSONCompactStringsEachRowWithNamesAndTypes](#jsoncompactstringseachrowwithnamesandtypes) | ✔ | ✔ |
-| [JSONObjectEachRow](#jsonobjecteachrow) | ✔ | ✔ |
-| [BSONEachRow](#bsoneachrow) | ✔ | ✔ |
-| [TSKV](#tskv) | ✔ | ✔ |
-| [Pretty](#pretty) | ✗ | ✔ |
-| [PrettyNoEscapes](#prettynoescapes) | ✗ | ✔ |
-| [PrettyMonoBlock](#prettymonoblock) | ✗ | ✔ |
-| [PrettyNoEscapesMonoBlock](#prettynoescapesmonoblock) | ✗ | ✔ |
-| [PrettyCompact](#prettycompact) | ✗ | ✔ |
-| [PrettyCompactNoEscapes](#prettycompactnoescapes) | ✗ | ✔ |
-| [PrettyCompactMonoBlock](#prettycompactmonoblock) | ✗ | ✔ |
-| [PrettyCompactNoEscapesMonoBlock](#prettycompactnoescapesmonoblock) | ✗ | ✔ |
-| [PrettySpace](#prettyspace) | ✗ | ✔ |
-| [PrettySpaceNoEscapes](#prettyspacenoescapes) | ✗ | ✔ |
-| [PrettySpaceMonoBlock](#prettyspacemonoblock) | ✗ | ✔ |
-| [PrettySpaceNoEscapesMonoBlock](#prettyspacenoescapesmonoblock) | ✗ | ✔ |
-| [Prometheus](#prometheus) | ✗ | ✔ |
-| [Protobuf](#protobuf) | ✔ | ✔ |
-| [ProtobufSingle](#protobufsingle) | ✔ | ✔ |
-| [Avro](#data-format-avro) | ✔ | ✔ |
-| [AvroConfluent](#data-format-avro-confluent) | ✔ | ✗ |
-| [Parquet](#data-format-parquet) | ✔ | ✔ |
-| [ParquetMetadata](#data-format-parquet-metadata) | ✔ | ✗ |
-| [Arrow](#data-format-arrow) | ✔ | ✔ |
-| [ArrowStream](#data-format-arrow-stream) | ✔ | ✔ |
-| [ORC](#data-format-orc) | ✔ | ✔ |
-| [RowBinary](#rowbinary) | ✔ | ✔ |
-| [RowBinaryWithNames](#rowbinarywithnamesandtypes) | ✔ | ✔ |
-| [RowBinaryWithNamesAndTypes](#rowbinarywithnamesandtypes) | ✔ | ✔ |
-| [RowBinaryWithDefaults](#rowbinarywithdefaults) | ✔ | ✔ |
-| [Native](#native) | ✔ | ✔ |
-| [Null](#null) | ✗ | ✔ |
-| [XML](#xml) | ✗ | ✔ |
-| [CapnProto](#capnproto) | ✔ | ✔ |
-| [LineAsString](#lineasstring) | ✔ | ✔ |
-| [Regexp](#data-format-regexp) | ✔ | ✗ |
-| [RawBLOB](#rawblob) | ✔ | ✔ |
-| [MsgPack](#msgpack) | ✔ | ✔ |
-| [MySQLDump](#mysqldump) | ✔ | ✗ |
-| [Markdown](#markdown) | ✗ | ✔ |
+|-------------------------------------------------------------------------------------------|------|-------|
+| [TabSeparated](#tabseparated) | ✔ | ✔ |
+| [TabSeparatedRaw](#tabseparatedraw) | ✔ | ✔ |
+| [TabSeparatedWithNames](#tabseparatedwithnames) | ✔ | ✔ |
+| [TabSeparatedWithNamesAndTypes](#tabseparatedwithnamesandtypes) | ✔ | ✔ |
+| [TabSeparatedRawWithNames](#tabseparatedrawwithnames) | ✔ | ✔ |
+| [TabSeparatedRawWithNamesAndTypes](#tabseparatedrawwithnamesandtypes) | ✔ | ✔ |
+| [Template](#format-template) | ✔ | ✔ |
+| [TemplateIgnoreSpaces](#templateignorespaces) | ✔ | ✗ |
+| [CSV](#csv) | ✔ | ✔ |
+| [CSVWithNames](#csvwithnames) | ✔ | ✔ |
+| [CSVWithNamesAndTypes](#csvwithnamesandtypes) | ✔ | ✔ |
+| [CustomSeparated](#format-customseparated) | ✔ | ✔ |
+| [CustomSeparatedWithNames](#customseparatedwithnames) | ✔ | ✔ |
+| [CustomSeparatedWithNamesAndTypes](#customseparatedwithnamesandtypes) | ✔ | ✔ |
+| [SQLInsert](#sqlinsert) | ✗ | ✔ |
+| [Values](#data-format-values) | ✔ | ✔ |
+| [Vertical](#vertical) | ✗ | ✔ |
+| [JSON](#json) | ✔ | ✔ |
+| [JSONAsString](#jsonasstring) | ✔ | ✗ |
+| [JSONStrings](#jsonstrings) | ✔ | ✔ |
+| [JSONColumns](#jsoncolumns) | ✔ | ✔ |
+| [JSONColumnsWithMetadata](#jsoncolumnsmonoblock)) | ✔ | ✔ |
+| [JSONCompact](#jsoncompact) | ✔ | ✔ |
+| [JSONCompactStrings](#jsoncompactstrings) | ✗ | ✔ |
+| [JSONCompactColumns](#jsoncompactcolumns) | ✔ | ✔ |
+| [JSONEachRow](#jsoneachrow) | ✔ | ✔ |
+| [PrettyJSONEachRow](#prettyjsoneachrow) | ✗ | ✔ |
+| [JSONEachRowWithProgress](#jsoneachrowwithprogress) | ✗ | ✔ |
+| [JSONStringsEachRow](#jsonstringseachrow) | ✔ | ✔ |
+| [JSONStringsEachRowWithProgress](#jsonstringseachrowwithprogress) | ✗ | ✔ |
+| [JSONCompactEachRow](#jsoncompacteachrow) | ✔ | ✔ |
+| [JSONCompactEachRowWithNames](#jsoncompacteachrowwithnames) | ✔ | ✔ |
+| [JSONCompactEachRowWithNamesAndTypes](#jsoncompacteachrowwithnamesandtypes) | ✔ | ✔ |
+| [JSONCompactStringsEachRow](#jsoncompactstringseachrow) | ✔ | ✔ |
+| [JSONCompactStringsEachRowWithNames](#jsoncompactstringseachrowwithnames) | ✔ | ✔ |
+| [JSONCompactStringsEachRowWithNamesAndTypes](#jsoncompactstringseachrowwithnamesandtypes) | ✔ | ✔ |
+| [JSONObjectEachRow](#jsonobjecteachrow) | ✔ | ✔ |
+| [BSONEachRow](#bsoneachrow) | ✔ | ✔ |
+| [TSKV](#tskv) | ✔ | ✔ |
+| [Pretty](#pretty) | ✗ | ✔ |
+| [PrettyNoEscapes](#prettynoescapes) | ✗ | ✔ |
+| [PrettyMonoBlock](#prettymonoblock) | ✗ | ✔ |
+| [PrettyNoEscapesMonoBlock](#prettynoescapesmonoblock) | ✗ | ✔ |
+| [PrettyCompact](#prettycompact) | ✗ | ✔ |
+| [PrettyCompactNoEscapes](#prettycompactnoescapes) | ✗ | ✔ |
+| [PrettyCompactMonoBlock](#prettycompactmonoblock) | ✗ | ✔ |
+| [PrettyCompactNoEscapesMonoBlock](#prettycompactnoescapesmonoblock) | ✗ | ✔ |
+| [PrettySpace](#prettyspace) | ✗ | ✔ |
+| [PrettySpaceNoEscapes](#prettyspacenoescapes) | ✗ | ✔ |
+| [PrettySpaceMonoBlock](#prettyspacemonoblock) | ✗ | ✔ |
+| [PrettySpaceNoEscapesMonoBlock](#prettyspacenoescapesmonoblock) | ✗ | ✔ |
+| [Prometheus](#prometheus) | ✗ | ✔ |
+| [Protobuf](#protobuf) | ✔ | ✔ |
+| [ProtobufSingle](#protobufsingle) | ✔ | ✔ |
+| [Avro](#data-format-avro) | ✔ | ✔ |
+| [AvroConfluent](#data-format-avro-confluent) | ✔ | ✗ |
+| [Parquet](#data-format-parquet) | ✔ | ✔ |
+| [ParquetMetadata](#data-format-parquet-metadata) | ✔ | ✗ |
+| [Arrow](#data-format-arrow) | ✔ | ✔ |
+| [ArrowStream](#data-format-arrow-stream) | ✔ | ✔ |
+| [ORC](#data-format-orc) | ✔ | ✔ |
+| [One](#data-format-one) | ✔ | ✗ |
+| [RowBinary](#rowbinary) | ✔ | ✔ |
+| [RowBinaryWithNames](#rowbinarywithnamesandtypes) | ✔ | ✔ |
+| [RowBinaryWithNamesAndTypes](#rowbinarywithnamesandtypes) | ✔ | ✔ |
+| [RowBinaryWithDefaults](#rowbinarywithdefaults) | ✔ | ✔ |
+| [Native](#native) | ✔ | ✔ |
+| [Null](#null) | ✗ | ✔ |
+| [XML](#xml) | ✗ | ✔ |
+| [CapnProto](#capnproto) | ✔ | ✔ |
+| [LineAsString](#lineasstring) | ✔ | ✔ |
+| [Regexp](#data-format-regexp) | ✔ | ✗ |
+| [RawBLOB](#rawblob) | ✔ | ✔ |
+| [MsgPack](#msgpack) | ✔ | ✔ |
+| [MySQLDump](#mysqldump) | ✔ | ✗ |
+| [Markdown](#markdown) | ✗ | ✔ |
You can control some format processing parameters with the ClickHouse settings. For more information read the [Settings](/docs/en/operations/settings/settings-formats.md) section.
@@ -2131,6 +2132,7 @@ To exchange data with Hadoop, you can use [HDFS table engine](/docs/en/engines/t
- [output_format_parquet_row_group_size](/docs/en/operations/settings/settings-formats.md/#output_format_parquet_row_group_size) - row group size in rows while data output. Default value - `1000000`.
- [output_format_parquet_string_as_string](/docs/en/operations/settings/settings-formats.md/#output_format_parquet_string_as_string) - use Parquet String type instead of Binary for String columns. Default value - `false`.
+- [input_format_parquet_import_nested](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_import_nested) - allow inserting array of structs into [Nested](/docs/en/sql-reference/data-types/nested-data-structures/index.md) table in Parquet input format. Default value - `false`.
- [input_format_parquet_case_insensitive_column_matching](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_case_insensitive_column_matching) - ignore case when matching Parquet columns with ClickHouse columns. Default value - `false`.
- [input_format_parquet_allow_missing_columns](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_allow_missing_columns) - allow missing columns while reading Parquet data. Default value - `false`.
- [input_format_parquet_skip_columns_with_unsupported_types_in_schema_inference](/docs/en/operations/settings/settings-formats.md/#input_format_parquet_skip_columns_with_unsupported_types_in_schema_inference) - allow skipping columns with unsupported types while schema inference for Parquet format. Default value - `false`.
@@ -2407,6 +2409,34 @@ $ clickhouse-client --query="SELECT * FROM {some_table} FORMAT ORC" > {filename.
To exchange data with Hadoop, you can use [HDFS table engine](/docs/en/engines/table-engines/integrations/hdfs.md).
+## One {#data-format-one}
+
+Special input format that doesn't read any data from file and returns only one row with column of type `UInt8`, name `dummy` and value `0` (like `system.one` table).
+Can be used with virtual columns `_file/_path` to list all files without reading actual data.
+
+Example:
+
+Query:
+```sql
+SELECT _file FROM file('path/to/files/data*', One);
+```
+
+Result:
+```text
+┌─_file────┐
+│ data.csv │
+└──────────┘
+┌─_file──────┐
+│ data.jsonl │
+└────────────┘
+┌─_file────┐
+│ data.tsv │
+└──────────┘
+┌─_file────────┐
+│ data.parquet │
+└──────────────┘
+```
+
## LineAsString {#lineasstring}
In this format, every line of input data is interpreted as a single string value. This format can only be parsed for table with a single field of type [String](/docs/en/sql-reference/data-types/string.md). The remaining columns must be set to [DEFAULT](/docs/en/sql-reference/statements/create/table.md/#default) or [MATERIALIZED](/docs/en/sql-reference/statements/create/table.md/#materialized), or omitted.
diff --git a/docs/en/interfaces/third-party/integrations.md b/docs/en/interfaces/third-party/integrations.md
index 3e1b1e84f5d4..a9f1af93495b 100644
--- a/docs/en/interfaces/third-party/integrations.md
+++ b/docs/en/interfaces/third-party/integrations.md
@@ -83,8 +83,8 @@ ClickHouse, Inc. does **not** maintain the tools and libraries listed below and
- Python
- [SQLAlchemy](https://www.sqlalchemy.org)
- [sqlalchemy-clickhouse](https://github.com/cloudflare/sqlalchemy-clickhouse) (uses [infi.clickhouse_orm](https://github.com/Infinidat/infi.clickhouse_orm))
- - [pandas](https://pandas.pydata.org)
- - [pandahouse](https://github.com/kszucs/pandahouse)
+ - [PyArrow/Pandas](https://pandas.pydata.org)
+ - [Ibis](https://github.com/ibis-project/ibis)
- PHP
- [Doctrine](https://www.doctrine-project.org/)
- [dbal-clickhouse](https://packagist.org/packages/friendsofdoctrine/dbal-clickhouse)
diff --git a/docs/en/sql-reference/statements/insert-into.md b/docs/en/sql-reference/statements/insert-into.md
index d6e30827f9bb..e0cc98c2351f 100644
--- a/docs/en/sql-reference/statements/insert-into.md
+++ b/docs/en/sql-reference/statements/insert-into.md
@@ -11,7 +11,7 @@ Inserts data into a table.
**Syntax**
``` sql
-INSERT INTO [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
+INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
```
You can specify a list of columns to insert using the `(c1, c2, c3)`. You can also use an expression with column [matcher](../../sql-reference/statements/select/index.md#asterisk) such as `*` and/or [modifiers](../../sql-reference/statements/select/index.md#select-modifiers) such as [APPLY](../../sql-reference/statements/select/index.md#apply-modifier), [EXCEPT](../../sql-reference/statements/select/index.md#except-modifier), [REPLACE](../../sql-reference/statements/select/index.md#replace-modifier).
@@ -107,7 +107,7 @@ If table has [constraints](../../sql-reference/statements/create/table.md#constr
**Syntax**
``` sql
-INSERT INTO [db.]table [(c1, c2, c3)] SELECT ...
+INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] SELECT ...
```
Columns are mapped according to their position in the SELECT clause. However, their names in the SELECT expression and the table for INSERT may differ. If necessary, type casting is performed.
@@ -126,7 +126,7 @@ To insert a default value instead of `NULL` into a column with not nullable data
**Syntax**
``` sql
-INSERT INTO [db.]table [(c1, c2, c3)] FROM INFILE file_name [COMPRESSION type] FORMAT format_name
+INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] FROM INFILE file_name [COMPRESSION type] FORMAT format_name
```
Use the syntax above to insert data from a file, or files, stored on the **client** side. `file_name` and `type` are string literals. Input file [format](../../interfaces/formats.md) must be set in the `FORMAT` clause.
diff --git a/docs/ru/sql-reference/statements/insert-into.md b/docs/ru/sql-reference/statements/insert-into.md
index 4fa6ac4ce660..747e36b88098 100644
--- a/docs/ru/sql-reference/statements/insert-into.md
+++ b/docs/ru/sql-reference/statements/insert-into.md
@@ -11,7 +11,7 @@ sidebar_label: INSERT INTO
**Синтаксис**
``` sql
-INSERT INTO [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
+INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
```
Вы можете указать список столбцов для вставки, используя синтаксис `(c1, c2, c3)`. Также можно использовать выражение cо [звездочкой](../../sql-reference/statements/select/index.md#asterisk) и/или модификаторами, такими как [APPLY](../../sql-reference/statements/select/index.md#apply-modifier), [EXCEPT](../../sql-reference/statements/select/index.md#except-modifier), [REPLACE](../../sql-reference/statements/select/index.md#replace-modifier).
@@ -100,7 +100,7 @@ INSERT INTO t FORMAT TabSeparated
**Синтаксис**
``` sql
-INSERT INTO [db.]table [(c1, c2, c3)] SELECT ...
+INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] SELECT ...
```
Соответствие столбцов определяется их позицией в секции SELECT. При этом, их имена в выражении SELECT и в таблице для INSERT, могут отличаться. При необходимости выполняется приведение типов данных, эквивалентное соответствующему оператору CAST.
@@ -120,7 +120,7 @@ INSERT INTO [db.]table [(c1, c2, c3)] SELECT ...
**Синтаксис**
``` sql
-INSERT INTO [db.]table [(c1, c2, c3)] FROM INFILE file_name [COMPRESSION type] FORMAT format_name
+INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] FROM INFILE file_name [COMPRESSION type] FORMAT format_name
```
Используйте этот синтаксис, чтобы вставить данные из файла, который хранится на стороне **клиента**. `file_name` и `type` задаются в виде строковых литералов. [Формат](../../interfaces/formats.md) входного файла должен быть задан в секции `FORMAT`.
diff --git a/docs/zh/guides/improving-query-performance/sparse-primary-indexes.md b/docs/zh/guides/improving-query-performance/sparse-primary-indexes.md
index eedc913cf82f..3f42f3f8da4b 100644
--- a/docs/zh/guides/improving-query-performance/sparse-primary-indexes.md
+++ b/docs/zh/guides/improving-query-performance/sparse-primary-indexes.md
@@ -346,9 +346,7 @@ UserID.bin,URL.bin,和EventTime.bin是UserID
- 我们将主键列(UserID, URL)中的一些列值标记为橙色。
- 这些橙色标记的列值是每个颗粒中每个主键列的最小值。这里的例外是最后一个颗粒(上图中的颗粒1082),最后一个颗粒我们标记的是最大的值。
-
- 正如我们将在下面看到的,这些橙色标记的列值将是表主索引中的条目。
+ 这些橙色标记的列值是每个颗粒中第一行的主键列值。正如我们将在下面看到的,这些橙色标记的列值将是表主索引中的条目。
- 我们从0开始对行进行编号,以便与ClickHouse内部行编号方案对齐,该方案也用于记录消息。
:::
@@ -1071,13 +1069,6 @@ ClickHouse服务器日志文件中相应的跟踪日志确认了ClickHouse正在
## 通过projections使用联合主键索引
-Projections目前是一个实验性的功能,因此我们需要告诉ClickHouse:
-
-```sql
-SET optimize_use_projections = 1;
-```
-
-
在原表上创建projection:
```sql
ALTER TABLE hits_UserID_URL
@@ -1096,10 +1087,12 @@ ALTER TABLE hits_UserID_URL
:::note
- 该projection正在创建一个隐藏表,该表的行顺序和主索引基于该projection的给定order BY子句
-- 我们使用MATERIALIZE关键字,以便立即用源表hits_UserID_URL的所有887万行导入隐藏表
+- `SHOW TABLES` 语句查询是不会列出这个隐藏表的
+- 我们使用`MATERIALIZE`关键字,以便立即用源表hits_UserID_URL的所有887万行导入隐藏表
- 如果在源表hits_UserID_URL中插入了新行,那么这些行也会自动插入到隐藏表中
- 查询总是(从语法上)针对源表hits_UserID_URL,但是如果隐藏表的行顺序和主索引允许更有效地执行查询,那么将使用该隐藏表
-- 实际上,隐式创建的隐藏表的行顺序和主索引与我们显式创建的辅助表相同:
+- 请注意,投影(projections)不会使 `ORDER BY` 查询语句的效率更高,即使 `ORDER BY` 匹配上了 projection 的 `ORDER BY` 语句(请参阅:https://github.com/ClickHouse/ClickHouse/issues/47333)
+- 实际上,隐式创建的隐藏表的行顺序和主索引与我们显式创建的辅助表相同:
.default}) @@ -1163,7 +1156,7 @@ ClickHouse服务器日志文件中跟踪日志确认了ClickHouse正在对索引
```
-## 移除无效的主键列
+## 小结
带有联合主键(UserID, URL)的表的主索引对于加快UserID的查询过滤非常有用。但是,尽管URL列是联合主键的一部分,但该索引在加速URL查询过滤方面并没有提供显著的帮助。
@@ -1176,4 +1169,12 @@ ClickHouse服务器日志文件中跟踪日志确认了ClickHouse正在对索引
但是,如果复合主键中的键列在基数上有很大的差异,那么查询按基数升序对主键列进行排序是有益的。
-主键键列之间的基数差越大,主键键列的顺序越重要。我们将在以后的文章中对此进行演示。请继续关注。
+主键键列之间的基数差得越大,主键中的列的顺序越重要。我们将在下一章节对此进行演示。
+
+# 高效地为键列排序
+
+TODO
+
+# 高效地识别单行
+
+TODO
diff --git a/docs/zh/sql-reference/statements/insert-into.md b/docs/zh/sql-reference/statements/insert-into.md
index 9acc1655f9a2..f80c0a8a8eae 100644
--- a/docs/zh/sql-reference/statements/insert-into.md
+++ b/docs/zh/sql-reference/statements/insert-into.md
@@ -8,7 +8,7 @@ INSERT INTO 语句主要用于向系统中添加数据.
查询的基本格式:
``` sql
-INSERT INTO [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
+INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
```
您可以在查询中指定要插入的列的列表,如:`[(c1, c2, c3)]`。您还可以使用列[匹配器](../../sql-reference/statements/select/index.md#asterisk)的表达式,例如`*`和/或[修饰符](../../sql-reference/statements/select/index.md#select-modifiers),例如 [APPLY](../../sql-reference/statements/select/index.md#apply-modifier), [EXCEPT](../../sql-reference/statements/select/index.md#apply-modifier), [REPLACE](../../sql-reference/statements/select/index.md#replace-modifier)。
@@ -71,7 +71,7 @@ INSERT INTO [db.]table [(c1, c2, c3)] FORMAT format_name data_set
例如,下面的查询所使用的输入格式就与上面INSERT … VALUES的中使用的输入格式相同:
``` sql
-INSERT INTO [db.]table [(c1, c2, c3)] FORMAT Values (v11, v12, v13), (v21, v22, v23), ...
+INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] FORMAT Values (v11, v12, v13), (v21, v22, v23), ...
```
ClickHouse会清除数据前所有的空白字符与一个换行符(如果有换行符的话)。所以在进行查询时,我们建议您将数据放入到输入输出格式名称后的新的一行中去(如果数据是以空白字符开始的,这将非常重要)。
@@ -93,7 +93,7 @@ INSERT INTO t FORMAT TabSeparated
### 使用`SELECT`的结果写入 {#inserting-the-results-of-select}
``` sql
-INSERT INTO [db.]table [(c1, c2, c3)] SELECT ...
+INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] SELECT ...
```
写入与SELECT的列的对应关系是使用位置来进行对应的,尽管它们在SELECT表达式与INSERT中的名称可能是不同的。如果需要,会对它们执行对应的类型转换。
diff --git a/programs/install/Install.cpp b/programs/install/Install.cpp
index d7086c95bebf..e10a9fea86bf 100644
--- a/programs/install/Install.cpp
+++ b/programs/install/Install.cpp
@@ -997,7 +997,9 @@ namespace
{
/// sudo respects limits in /etc/security/limits.conf e.g. open files,
/// that's why we are using it instead of the 'clickhouse su' tool.
- command = fmt::format("sudo -u '{}' {}", user, command);
+ /// by default, sudo resets all the ENV variables, but we should preserve
+ /// the values /etc/default/clickhouse in /etc/init.d/clickhouse file
+ command = fmt::format("sudo --preserve-env -u '{}' {}", user, command);
}
fmt::print("Will run {}\n", command);
diff --git a/src/AggregateFunctions/UniquesHashSet.h b/src/AggregateFunctions/UniquesHashSet.h
index ca6d31a716d9..3e501b294148 100644
--- a/src/AggregateFunctions/UniquesHashSet.h
+++ b/src/AggregateFunctions/UniquesHashSet.h
@@ -108,7 +108,14 @@ class UniquesHashSet : private HashTableAllocatorWithStackMemory<(1ULL << UNIQUE
inline size_t buf_size() const { return 1ULL << size_degree; } /// NOLINT
inline size_t max_fill() const { return 1ULL << (size_degree - 1); } /// NOLINT
inline size_t mask() const { return buf_size() - 1; }
- inline size_t place(HashValue x) const { return (x >> UNIQUES_HASH_BITS_FOR_SKIP) & mask(); }
+
+ inline size_t place(HashValue x) const
+ {
+ if constexpr (std::endian::native == std::endian::little)
+ return (x >> UNIQUES_HASH_BITS_FOR_SKIP) & mask();
+ else
+ return (std::byteswap(x) >> UNIQUES_HASH_BITS_FOR_SKIP) & mask();
+ }
/// The value is divided by 2 ^ skip_degree
inline bool good(HashValue hash) const
diff --git a/src/Client/ClientBase.cpp b/src/Client/ClientBase.cpp
index c7288d4793a4..9ad6a46866f1 100644
--- a/src/Client/ClientBase.cpp
+++ b/src/Client/ClientBase.cpp
@@ -105,6 +105,7 @@ namespace ErrorCodes
extern const int LOGICAL_ERROR;
extern const int CANNOT_OPEN_FILE;
extern const int FILE_ALREADY_EXISTS;
+ extern const int USER_SESSION_LIMIT_EXCEEDED;
}
}
@@ -2408,6 +2409,13 @@ void ClientBase::runInteractive()
}
}
+ if (suggest && suggest->getLastError() == ErrorCodes::USER_SESSION_LIMIT_EXCEEDED)
+ {
+ // If a separate connection loading suggestions failed to open a new session,
+ // use the main session to receive them.
+ suggest->load(*connection, connection_parameters.timeouts, config().getInt("suggestion_limit"));
+ }
+
try
{
if (!processQueryText(input))
diff --git a/src/Client/Suggest.cpp b/src/Client/Suggest.cpp
index 00e0ebd8b918..c854d471fae8 100644
--- a/src/Client/Suggest.cpp
+++ b/src/Client/Suggest.cpp
@@ -22,9 +22,11 @@ namespace DB
{
namespace ErrorCodes
{
+ extern const int OK;
extern const int LOGICAL_ERROR;
extern const int UNKNOWN_PACKET_FROM_SERVER;
extern const int DEADLOCK_AVOIDED;
+ extern const int USER_SESSION_LIMIT_EXCEEDED;
}
Suggest::Suggest()
@@ -121,21 +123,24 @@ void Suggest::load(ContextPtr context, const ConnectionParameters & connection_p
}
catch (const Exception & e)
{
+ last_error = e.code();
if (e.code() == ErrorCodes::DEADLOCK_AVOIDED)
continue;
-
- /// Client can successfully connect to the server and
- /// get ErrorCodes::USER_SESSION_LIMIT_EXCEEDED for suggestion connection.
-
- /// We should not use std::cerr here, because this method works concurrently with the main thread.
- /// WriteBufferFromFileDescriptor will write directly to the file descriptor, avoiding data race on std::cerr.
-
- WriteBufferFromFileDescriptor out(STDERR_FILENO, 4096);
- out << "Cannot load data for command line suggestions: " << getCurrentExceptionMessage(false, true) << "\n";
- out.next();
+ else if (e.code() != ErrorCodes::USER_SESSION_LIMIT_EXCEEDED)
+ {
+ /// We should not use std::cerr here, because this method works concurrently with the main thread.
+ /// WriteBufferFromFileDescriptor will write directly to the file descriptor, avoiding data race on std::cerr.
+ ///
+ /// USER_SESSION_LIMIT_EXCEEDED is ignored here. The client will try to receive
+ /// suggestions using the main connection later.
+ WriteBufferFromFileDescriptor out(STDERR_FILENO, 4096);
+ out << "Cannot load data for command line suggestions: " << getCurrentExceptionMessage(false, true) << "\n";
+ out.next();
+ }
}
catch (...)
{
+ last_error = getCurrentExceptionCode();
WriteBufferFromFileDescriptor out(STDERR_FILENO, 4096);
out << "Cannot load data for command line suggestions: " << getCurrentExceptionMessage(false, true) << "\n";
out.next();
@@ -148,6 +153,21 @@ void Suggest::load(ContextPtr context, const ConnectionParameters & connection_p
});
}
+void Suggest::load(IServerConnection & connection,
+ const ConnectionTimeouts & timeouts,
+ Int32 suggestion_limit)
+{
+ try
+ {
+ fetch(connection, timeouts, getLoadSuggestionQuery(suggestion_limit, true));
+ }
+ catch (...)
+ {
+ std::cerr << "Suggestions loading exception: " << getCurrentExceptionMessage(false, true) << std::endl;
+ last_error = getCurrentExceptionCode();
+ }
+}
+
void Suggest::fetch(IServerConnection & connection, const ConnectionTimeouts & timeouts, const std::string & query)
{
connection.sendQuery(
@@ -176,6 +196,7 @@ void Suggest::fetch(IServerConnection & connection, const ConnectionTimeouts & t
return;
case Protocol::Server::EndOfStream:
+ last_error = ErrorCodes::OK;
return;
default:
diff --git a/src/Client/Suggest.h b/src/Client/Suggest.h
index cfe9315879cc..5cecdc4501b0 100644
--- a/src/Client/Suggest.h
+++ b/src/Client/Suggest.h
@@ -7,6 +7,7 @@
#include
#include
#include
+#include
#include
@@ -28,9 +29,15 @@ class Suggest : public LineReader::Suggest, boost::noncopyable
template
void load(ContextPtr context, const ConnectionParameters & connection_parameters, Int32 suggestion_limit);
+ void load(IServerConnection & connection,
+ const ConnectionTimeouts & timeouts,
+ Int32 suggestion_limit);
+
/// Older server versions cannot execute the query loading suggestions.
static constexpr int MIN_SERVER_REVISION = DBMS_MIN_PROTOCOL_VERSION_WITH_VIEW_IF_PERMITTED;
+ int getLastError() const { return last_error.load(); }
+
private:
void fetch(IServerConnection & connection, const ConnectionTimeouts & timeouts, const std::string & query);
@@ -38,6 +45,8 @@ class Suggest : public LineReader::Suggest, boost::noncopyable
/// Words are fetched asynchronously.
std::thread loading_thread;
+
+ std::atomic last_error { -1 };
};
}
diff --git a/src/Columns/ColumnAggregateFunction.cpp b/src/Columns/ColumnAggregateFunction.cpp
index 62ec324455e2..3ebb30df87e9 100644
--- a/src/Columns/ColumnAggregateFunction.cpp
+++ b/src/Columns/ColumnAggregateFunction.cpp
@@ -524,7 +524,7 @@ void ColumnAggregateFunction::insertDefault()
pushBackAndCreateState(data, arena, func.get());
}
-StringRef ColumnAggregateFunction::serializeValueIntoArena(size_t n, Arena & arena, const char *& begin) const
+StringRef ColumnAggregateFunction::serializeValueIntoArena(size_t n, Arena & arena, const char *& begin, const UInt8 *) const
{
WriteBufferFromArena out(arena, begin);
func->serialize(data[n], out, version);
diff --git a/src/Columns/ColumnAggregateFunction.h b/src/Columns/ColumnAggregateFunction.h
index f9ce45708c90..7c7201e585a6 100644
--- a/src/Columns/ColumnAggregateFunction.h
+++ b/src/Columns/ColumnAggregateFunction.h
@@ -162,7 +162,7 @@ class ColumnAggregateFunction final : public COWHelper
StringRef getDataAt(size_t n) const override;
bool isDefaultAt(size_t n) const override;
void insertData(const char * pos, size_t length) override;
- StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const override;
+ StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const override;
const char * deserializeAndInsertFromArena(const char * pos) override;
const char * skipSerializedInArena(const char * pos) const override;
void updateHashWithValue(size_t n, SipHash & hash) const override;
diff --git a/src/Columns/ColumnCompressed.h b/src/Columns/ColumnCompressed.h
index bfe7cdb4924a..b780fbbf37a2 100644
--- a/src/Columns/ColumnCompressed.h
+++ b/src/Columns/ColumnCompressed.h
@@ -88,7 +88,7 @@ class ColumnCompressed : public COWHelper
void insertData(const char *, size_t) override { throwMustBeDecompressed(); }
void insertDefault() override { throwMustBeDecompressed(); }
void popBack(size_t) override { throwMustBeDecompressed(); }
- StringRef serializeValueIntoArena(size_t, Arena &, char const *&) const override { throwMustBeDecompressed(); }
+ StringRef serializeValueIntoArena(size_t, Arena &, char const *&, const UInt8 *) const override { throwMustBeDecompressed(); }
const char * deserializeAndInsertFromArena(const char *) override { throwMustBeDecompressed(); }
const char * skipSerializedInArena(const char *) const override { throwMustBeDecompressed(); }
void updateHashWithValue(size_t, SipHash &) const override { throwMustBeDecompressed(); }
diff --git a/src/Columns/ColumnConst.h b/src/Columns/ColumnConst.h
index f769dd6cc2ac..dc84e0c24029 100644
--- a/src/Columns/ColumnConst.h
+++ b/src/Columns/ColumnConst.h
@@ -151,7 +151,7 @@ class ColumnConst final : public COWHelper
s -= n;
}
- StringRef serializeValueIntoArena(size_t, Arena & arena, char const *& begin) const override
+ StringRef serializeValueIntoArena(size_t, Arena & arena, char const *& begin, const UInt8 *) const override
{
return data->serializeValueIntoArena(0, arena, begin);
}
diff --git a/src/Columns/ColumnDecimal.cpp b/src/Columns/ColumnDecimal.cpp
index 8e5792934cf6..142ee6c271da 100644
--- a/src/Columns/ColumnDecimal.cpp
+++ b/src/Columns/ColumnDecimal.cpp
@@ -59,9 +59,26 @@ bool ColumnDecimal::hasEqualValues() const
}
template
-StringRef ColumnDecimal::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const
+StringRef ColumnDecimal::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 * null_bit) const
{
- auto * pos = arena.allocContinue(sizeof(T), begin);
+ constexpr size_t null_bit_size = sizeof(UInt8);
+ StringRef res;
+ char * pos;
+ if (null_bit)
+ {
+ res.size = * null_bit ? null_bit_size : null_bit_size + sizeof(T);
+ pos = arena.allocContinue(res.size, begin);
+ res.data = pos;
+ memcpy(pos, null_bit, null_bit_size);
+ if (*null_bit) return res;
+ pos += null_bit_size;
+ }
+ else
+ {
+ res.size = sizeof(T);
+ pos = arena.allocContinue(res.size, begin);
+ res.data = pos;
+ }
memcpy(pos, &data[n], sizeof(T));
return StringRef(pos, sizeof(T));
}
diff --git a/src/Columns/ColumnDecimal.h b/src/Columns/ColumnDecimal.h
index 03e0b9be5588..fb24ae4554b9 100644
--- a/src/Columns/ColumnDecimal.h
+++ b/src/Columns/ColumnDecimal.h
@@ -80,7 +80,7 @@ class ColumnDecimal final : public COWHelper(data[n], scale); }
- StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const override;
+ StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 * null_bit) const override;
const char * deserializeAndInsertFromArena(const char * pos) override;
const char * skipSerializedInArena(const char * pos) const override;
void updateHashWithValue(size_t n, SipHash & hash) const override;
diff --git a/src/Columns/ColumnFixedString.cpp b/src/Columns/ColumnFixedString.cpp
index 24b5c435ecdc..a18e5c522a1d 100644
--- a/src/Columns/ColumnFixedString.cpp
+++ b/src/Columns/ColumnFixedString.cpp
@@ -86,11 +86,28 @@ void ColumnFixedString::insertData(const char * pos, size_t length)
memset(chars.data() + old_size + length, 0, n - length);
}
-StringRef ColumnFixedString::serializeValueIntoArena(size_t index, Arena & arena, char const *& begin) const
+StringRef ColumnFixedString::serializeValueIntoArena(size_t index, Arena & arena, char const *& begin, const UInt8 * null_bit) const
{
- auto * pos = arena.allocContinue(n, begin);
+ constexpr size_t null_bit_size = sizeof(UInt8);
+ StringRef res;
+ char * pos;
+ if (null_bit)
+ {
+ res.size = * null_bit ? null_bit_size : null_bit_size + n;
+ pos = arena.allocContinue(res.size, begin);
+ res.data = pos;
+ memcpy(pos, null_bit, null_bit_size);
+ if (*null_bit) return res;
+ pos += null_bit_size;
+ }
+ else
+ {
+ res.size = n;
+ pos = arena.allocContinue(res.size, begin);
+ res.data = pos;
+ }
memcpy(pos, &chars[n * index], n);
- return StringRef(pos, n);
+ return res;
}
const char * ColumnFixedString::deserializeAndInsertFromArena(const char * pos)
diff --git a/src/Columns/ColumnFixedString.h b/src/Columns/ColumnFixedString.h
index 39497e3403ed..445432b7b285 100644
--- a/src/Columns/ColumnFixedString.h
+++ b/src/Columns/ColumnFixedString.h
@@ -115,7 +115,7 @@ class ColumnFixedString final : public COWHelper
throw Exception(ErrorCodes::NOT_IMPLEMENTED, "Cannot insert into {}", getName());
}
- StringRef serializeValueIntoArena(size_t, Arena &, char const *&) const override
+ StringRef serializeValueIntoArena(size_t, Arena &, char const *&, const UInt8 *) const override
{
throw Exception(ErrorCodes::NOT_IMPLEMENTED, "Cannot serialize from {}", getName());
}
diff --git a/src/Columns/ColumnLowCardinality.cpp b/src/Columns/ColumnLowCardinality.cpp
index 9269ea4ee4d8..41358a4e5385 100644
--- a/src/Columns/ColumnLowCardinality.cpp
+++ b/src/Columns/ColumnLowCardinality.cpp
@@ -255,7 +255,7 @@ void ColumnLowCardinality::insertData(const char * pos, size_t length)
idx.insertPosition(dictionary.getColumnUnique().uniqueInsertData(pos, length));
}
-StringRef ColumnLowCardinality::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const
+StringRef ColumnLowCardinality::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const
{
return getDictionary().serializeValueIntoArena(getIndexes().getUInt(n), arena, begin);
}
diff --git a/src/Columns/ColumnLowCardinality.h b/src/Columns/ColumnLowCardinality.h
index dcd07ff3b348..91bd5945fd91 100644
--- a/src/Columns/ColumnLowCardinality.h
+++ b/src/Columns/ColumnLowCardinality.h
@@ -87,7 +87,7 @@ class ColumnLowCardinality final : public COWHelperpopBack(n);
}
-StringRef ColumnMap::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const
+StringRef ColumnMap::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const
{
return nested->serializeValueIntoArena(n, arena, begin);
}
diff --git a/src/Columns/ColumnMap.h b/src/Columns/ColumnMap.h
index e5bc26127df9..fde8a7e0e678 100644
--- a/src/Columns/ColumnMap.h
+++ b/src/Columns/ColumnMap.h
@@ -58,7 +58,7 @@ class ColumnMap final : public COWHelper
void insert(const Field & x) override;
void insertDefault() override;
void popBack(size_t n) override;
- StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const override;
+ StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const override;
const char * deserializeAndInsertFromArena(const char * pos) override;
const char * skipSerializedInArena(const char * pos) const override;
void updateHashWithValue(size_t n, SipHash & hash) const override;
diff --git a/src/Columns/ColumnNullable.cpp b/src/Columns/ColumnNullable.cpp
index 2eb2ff0bf69e..fcd95e5c9637 100644
--- a/src/Columns/ColumnNullable.cpp
+++ b/src/Columns/ColumnNullable.cpp
@@ -4,6 +4,10 @@
#include
#include
#include
+#include
+#include
+#include
+#include
#include
#include
#include
@@ -34,6 +38,7 @@ ColumnNullable::ColumnNullable(MutableColumnPtr && nested_column_, MutableColumn
{
/// ColumnNullable cannot have constant nested column. But constant argument could be passed. Materialize it.
nested_column = getNestedColumn().convertToFullColumnIfConst();
+ nested_type = nested_column->getDataType();
if (!getNestedColumn().canBeInsideNullable())
throw Exception(ErrorCodes::ILLEGAL_COLUMN, "{} cannot be inside Nullable column", getNestedColumn().getName());
@@ -134,21 +139,77 @@ void ColumnNullable::insertData(const char * pos, size_t length)
}
}
-StringRef ColumnNullable::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const
+StringRef ColumnNullable::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const
{
const auto & arr = getNullMapData();
static constexpr auto s = sizeof(arr[0]);
+ char * pos;
- auto * pos = arena.allocContinue(s, begin);
- memcpy(pos, &arr[n], s);
-
- if (arr[n])
- return StringRef(pos, s);
-
- auto nested_ref = getNestedColumn().serializeValueIntoArena(n, arena, begin);
-
- /// serializeValueIntoArena may reallocate memory. Have to use ptr from nested_ref.data and move it back.
- return StringRef(nested_ref.data - s, nested_ref.size + s);
+ switch (nested_type)
+ {
+ case TypeIndex::UInt8:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::UInt16:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::UInt32:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::UInt64:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::UInt128:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::UInt256:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Int8:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Int16:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Int32:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Int64:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Int128:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Int256:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Float32:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Float64:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Date:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Date32:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::DateTime:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::DateTime64:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::String:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::FixedString:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Decimal32:
+ return static_cast *>(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Decimal64:
+ return static_cast *>(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Decimal128:
+ return static_cast *>(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Decimal256:
+ return static_cast *>(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::UUID:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::IPv4:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::IPv6:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ default:
+ pos = arena.allocContinue(s, begin);
+ memcpy(pos, &arr[n], s);
+ if (arr[n])
+ return StringRef(pos, s);
+ auto nested_ref = getNestedColumn().serializeValueIntoArena(n, arena, begin);
+ /// serializeValueIntoArena may reallocate memory. Have to use ptr from nested_ref.data and move it back.
+ return StringRef(nested_ref.data - s, nested_ref.size + s);
+ }
}
const char * ColumnNullable::deserializeAndInsertFromArena(const char * pos)
diff --git a/src/Columns/ColumnNullable.h b/src/Columns/ColumnNullable.h
index bc95eca69b94..b57fdf3064db 100644
--- a/src/Columns/ColumnNullable.h
+++ b/src/Columns/ColumnNullable.h
@@ -6,6 +6,7 @@
#include
#include
+#include "Core/TypeId.h"
#include "config.h"
@@ -62,7 +63,7 @@ class ColumnNullable final : public COWHelper
StringRef getDataAt(size_t) const override;
/// Will insert null value if pos=nullptr
void insertData(const char * pos, size_t length) override;
- StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const override;
+ StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 * null_bit) const override;
const char * deserializeAndInsertFromArena(const char * pos) override;
const char * skipSerializedInArena(const char * pos) const override;
void insertRangeFrom(const IColumn & src, size_t start, size_t length) override;
@@ -212,6 +213,8 @@ class ColumnNullable final : public COWHelper
private:
WrappedPtr nested_column;
WrappedPtr null_map;
+ // optimize serializeValueIntoArena
+ TypeIndex nested_type;
template
void applyNullMapImpl(const NullMap & map);
diff --git a/src/Columns/ColumnObject.h b/src/Columns/ColumnObject.h
index bc5a6b69bb0b..36a33a8f10fa 100644
--- a/src/Columns/ColumnObject.h
+++ b/src/Columns/ColumnObject.h
@@ -244,7 +244,7 @@ class ColumnObject final : public COWHelper
StringRef getDataAt(size_t) const override { throwMustBeConcrete(); }
bool isDefaultAt(size_t) const override { throwMustBeConcrete(); }
void insertData(const char *, size_t) override { throwMustBeConcrete(); }
- StringRef serializeValueIntoArena(size_t, Arena &, char const *&) const override { throwMustBeConcrete(); }
+ StringRef serializeValueIntoArena(size_t, Arena &, char const *&, const UInt8 *) const override { throwMustBeConcrete(); }
const char * deserializeAndInsertFromArena(const char *) override { throwMustBeConcrete(); }
const char * skipSerializedInArena(const char *) const override { throwMustBeConcrete(); }
void updateHashWithValue(size_t, SipHash &) const override { throwMustBeConcrete(); }
diff --git a/src/Columns/ColumnSparse.cpp b/src/Columns/ColumnSparse.cpp
index 4f76a9be4b9e..057c0cd71122 100644
--- a/src/Columns/ColumnSparse.cpp
+++ b/src/Columns/ColumnSparse.cpp
@@ -150,7 +150,7 @@ void ColumnSparse::insertData(const char * pos, size_t length)
insertSingleValue([&](IColumn & column) { column.insertData(pos, length); });
}
-StringRef ColumnSparse::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const
+StringRef ColumnSparse::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const
{
return values->serializeValueIntoArena(getValueIndex(n), arena, begin);
}
diff --git a/src/Columns/ColumnSparse.h b/src/Columns/ColumnSparse.h
index 26e05655f602..48c7422dd27b 100644
--- a/src/Columns/ColumnSparse.h
+++ b/src/Columns/ColumnSparse.h
@@ -78,7 +78,7 @@ class ColumnSparse final : public COWHelper
/// Will insert null value if pos=nullptr
void insertData(const char * pos, size_t length) override;
- StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const override;
+ StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const override;
const char * deserializeAndInsertFromArena(const char * pos) override;
const char * skipSerializedInArena(const char *) const override;
void insertRangeFrom(const IColumn & src, size_t start, size_t length) override;
diff --git a/src/Columns/ColumnString.cpp b/src/Columns/ColumnString.cpp
index 38c7b2c0dd6b..50fe90ad8ef4 100644
--- a/src/Columns/ColumnString.cpp
+++ b/src/Columns/ColumnString.cpp
@@ -213,17 +213,30 @@ ColumnPtr ColumnString::permute(const Permutation & perm, size_t limit) const
}
-StringRef ColumnString::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const
+StringRef ColumnString::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 * null_bit) const
{
size_t string_size = sizeAt(n);
size_t offset = offsetAt(n);
-
+ constexpr size_t null_bit_size = sizeof(UInt8);
StringRef res;
- res.size = sizeof(string_size) + string_size;
- char * pos = arena.allocContinue(res.size, begin);
+ char * pos;
+ if (null_bit)
+ {
+ res.size = * null_bit ? null_bit_size : null_bit_size + sizeof(string_size) + string_size;
+ pos = arena.allocContinue(res.size, begin);
+ res.data = pos;
+ memcpy(pos, null_bit, null_bit_size);
+ if (*null_bit) return res;
+ pos += null_bit_size;
+ }
+ else
+ {
+ res.size = sizeof(string_size) + string_size;
+ pos = arena.allocContinue(res.size, begin);
+ res.data = pos;
+ }
memcpy(pos, &string_size, sizeof(string_size));
memcpy(pos + sizeof(string_size), &chars[offset], string_size);
- res.data = pos;
return res;
}
diff --git a/src/Columns/ColumnString.h b/src/Columns/ColumnString.h
index 08c876a803d8..e8e5ebbcbf92 100644
--- a/src/Columns/ColumnString.h
+++ b/src/Columns/ColumnString.h
@@ -11,6 +11,7 @@
#include
#include
#include
+#include
class Collator;
@@ -168,7 +169,7 @@ class ColumnString final : public COWHelper
offsets.resize_assume_reserved(offsets.size() - n);
}
- StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const override;
+ StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 * null_bit) const override;
const char * deserializeAndInsertFromArena(const char * pos) override;
diff --git a/src/Columns/ColumnTuple.cpp b/src/Columns/ColumnTuple.cpp
index 9702d2751147..d8992125be45 100644
--- a/src/Columns/ColumnTuple.cpp
+++ b/src/Columns/ColumnTuple.cpp
@@ -171,7 +171,7 @@ void ColumnTuple::popBack(size_t n)
column->popBack(n);
}
-StringRef ColumnTuple::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const
+StringRef ColumnTuple::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const
{
StringRef res(begin, 0);
for (const auto & column : columns)
diff --git a/src/Columns/ColumnTuple.h b/src/Columns/ColumnTuple.h
index e7dee9b8ff9b..79099f4c098e 100644
--- a/src/Columns/ColumnTuple.h
+++ b/src/Columns/ColumnTuple.h
@@ -61,7 +61,7 @@ class ColumnTuple final : public COWHelper
void insertFrom(const IColumn & src_, size_t n) override;
void insertDefault() override;
void popBack(size_t n) override;
- StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const override;
+ StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const override;
const char * deserializeAndInsertFromArena(const char * pos) override;
const char * skipSerializedInArena(const char * pos) const override;
void updateHashWithValue(size_t n, SipHash & hash) const override;
diff --git a/src/Columns/ColumnUnique.h b/src/Columns/ColumnUnique.h
index 377255d80c7d..882d17b1649c 100644
--- a/src/Columns/ColumnUnique.h
+++ b/src/Columns/ColumnUnique.h
@@ -79,7 +79,7 @@ class ColumnUnique final : public COWHelpergetFloat32(n); }
bool getBool(size_t n) const override { return getNestedColumn()->getBool(n); }
bool isNullAt(size_t n) const override { return is_nullable && n == getNullValueIndex(); }
- StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const override;
+ StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 * null_bit) const override;
const char * skipSerializedInArena(const char * pos) const override;
void updateHashWithValue(size_t n, SipHash & hash_func) const override
{
@@ -373,7 +373,7 @@ size_t ColumnUnique::uniqueInsertData(const char * pos, size_t lengt
}
template
-StringRef ColumnUnique::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const
+StringRef ColumnUnique::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const
{
if (is_nullable)
{
diff --git a/src/Columns/ColumnVector.cpp b/src/Columns/ColumnVector.cpp
index f2fe343a3716..a9b8c0ccacb3 100644
--- a/src/Columns/ColumnVector.cpp
+++ b/src/Columns/ColumnVector.cpp
@@ -49,11 +49,28 @@ namespace ErrorCodes
}
template
-StringRef ColumnVector::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const
+StringRef ColumnVector::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 * null_bit) const
{
- auto * pos = arena.allocContinue(sizeof(T), begin);
+ constexpr size_t null_bit_size = sizeof(UInt8);
+ StringRef res;
+ char * pos;
+ if (null_bit)
+ {
+ res.size = * null_bit ? null_bit_size : null_bit_size + sizeof(T);
+ pos = arena.allocContinue(res.size, begin);
+ res.data = pos;
+ memcpy(pos, null_bit, null_bit_size);
+ if (*null_bit) return res;
+ pos += null_bit_size;
+ }
+ else
+ {
+ res.size = sizeof(T);
+ pos = arena.allocContinue(res.size, begin);
+ res.data = pos;
+ }
unalignedStore(pos, data[n]);
- return StringRef(pos, sizeof(T));
+ return res;
}
template
diff --git a/src/Columns/ColumnVector.h b/src/Columns/ColumnVector.h
index b8ebff2a5d50..7bb69656c5ac 100644
--- a/src/Columns/ColumnVector.h
+++ b/src/Columns/ColumnVector.h
@@ -174,7 +174,7 @@ class ColumnVector final : public COWHelper>
data.resize_assume_reserved(data.size() - n);
}
- StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const override;
+ StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 * null_bit) const override;
const char * deserializeAndInsertFromArena(const char * pos) override;
diff --git a/src/Columns/IColumn.h b/src/Columns/IColumn.h
index b4eaf5c28f59..12ac1102efde 100644
--- a/src/Columns/IColumn.h
+++ b/src/Columns/IColumn.h
@@ -218,7 +218,7 @@ class IColumn : public COW
* For example, to obtain unambiguous representation of Array of strings, strings data should be interleaved with their sizes.
* Parameter begin should be used with Arena::allocContinue.
*/
- virtual StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const = 0;
+ virtual StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 * null_bit = nullptr) const = 0;
/// Deserializes a value that was serialized using IColumn::serializeValueIntoArena method.
/// Returns pointer to the position after the read data.
diff --git a/src/Columns/IColumnDummy.h b/src/Columns/IColumnDummy.h
index 82d4c857b29b..4cadae2bc3d9 100644
--- a/src/Columns/IColumnDummy.h
+++ b/src/Columns/IColumnDummy.h
@@ -57,7 +57,7 @@ class IColumnDummy : public IColumn
++s;
}
- StringRef serializeValueIntoArena(size_t /*n*/, Arena & arena, char const *& begin) const override
+ StringRef serializeValueIntoArena(size_t /*n*/, Arena & arena, char const *& begin, const UInt8 *) const override
{
/// Has to put one useless byte into Arena, because serialization into zero number of bytes is ambiguous.
char * res = arena.allocContinue(1, begin);
diff --git a/src/Columns/tests/gtest_column_unique.cpp b/src/Columns/tests/gtest_column_unique.cpp
index 15208da70fb2..ab2cb42b6038 100644
--- a/src/Columns/tests/gtest_column_unique.cpp
+++ b/src/Columns/tests/gtest_column_unique.cpp
@@ -117,7 +117,7 @@ void column_unique_unique_deserialize_from_arena_impl(ColumnType & column, const
const char * pos = nullptr;
for (size_t i = 0; i < num_values; ++i)
{
- auto ref = column_unique_pattern->serializeValueIntoArena(idx->getUInt(i), arena, pos);
+ auto ref = column_unique_pattern->serializeValueIntoArena(idx->getUInt(i), arena, pos, nullptr);
const char * new_pos;
column_unique->uniqueDeserializeAndInsertFromArena(ref.data, new_pos);
ASSERT_EQ(new_pos - ref.data, ref.size) << "Deserialized data has different sizes at position " << i;
@@ -140,8 +140,8 @@ void column_unique_unique_deserialize_from_arena_impl(ColumnType & column, const
const char * pos_lc = nullptr;
for (size_t i = 0; i < num_values; ++i)
{
- auto ref_string = column.serializeValueIntoArena(i, arena_string, pos_string);
- auto ref_lc = column_unique->serializeValueIntoArena(idx->getUInt(i), arena_lc, pos_lc);
+ auto ref_string = column.serializeValueIntoArena(i, arena_string, pos_string, nullptr);
+ auto ref_lc = column_unique->serializeValueIntoArena(idx->getUInt(i), arena_lc, pos_lc, nullptr);
ASSERT_EQ(ref_string, ref_lc) << "Serialized data is different from pattern at position " << i;
}
}
diff --git a/src/Common/TransformEndianness.hpp b/src/Common/TransformEndianness.hpp
index 0a9055dde15a..05f7778a12e3 100644
--- a/src/Common/TransformEndianness.hpp
+++ b/src/Common/TransformEndianness.hpp
@@ -3,23 +3,25 @@
#include
#include
+#include
+
#include
namespace DB
{
-template
+template
requires std::is_integral_v
inline void transformEndianness(T & value)
{
- if constexpr (endian != std::endian::native)
+ if constexpr (ToEndian != FromEndian)
value = std::byteswap(value);
}
-template
+template
requires is_big_int_v
inline void transformEndianness(T & x)
{
- if constexpr (std::endian::native != endian)
+ if constexpr (ToEndian != FromEndian)
{
auto & items = x.items;
std::transform(std::begin(items), std::end(items), std::begin(items), [](auto & item) { return std::byteswap(item); });
@@ -27,42 +29,49 @@ inline void transformEndianness(T & x)
}
}
-template
+template
requires is_decimal
inline void transformEndianness(T & x)
{
- transformEndianness(x.value);
+ transformEndianness(x.value);
}
-template
+template
requires std::is_floating_point_v
inline void transformEndianness(T & value)
{
- if constexpr (std::endian::native != endian)
+ if constexpr (ToEndian != FromEndian)
{
auto * start = reinterpret_cast(&value);
std::reverse(start, start + sizeof(T));
}
}
-template
+template
requires std::is_scoped_enum_v
inline void transformEndianness(T & x)
{
using UnderlyingType = std::underlying_type_t;
- transformEndianness(reinterpret_cast(x));
+ transformEndianness(reinterpret_cast(x));
}
-template
+template
inline void transformEndianness(std::pair & pair)
{
- transformEndianness(pair.first);
- transformEndianness(pair.second);
+ transformEndianness(pair.first);
+ transformEndianness(pair.second);
}
-template
+template
inline void transformEndianness(StrongTypedef & x)
{
- transformEndianness(x.toUnderType());
+ transformEndianness(x.toUnderType());
+}
+
+template
+inline void transformEndianness(CityHash_v1_0_2::uint128 & x)
+{
+ transformEndianness(x.low64);
+ transformEndianness(x.high64);
}
}
diff --git a/src/Common/ZooKeeper/ZooKeeper.cpp b/src/Common/ZooKeeper/ZooKeeper.cpp
index 0fe536b1a084..10331a4e4100 100644
--- a/src/Common/ZooKeeper/ZooKeeper.cpp
+++ b/src/Common/ZooKeeper/ZooKeeper.cpp
@@ -152,7 +152,7 @@ void ZooKeeper::init(ZooKeeperArgs args_)
throw KeeperException(code, "/");
if (code == Coordination::Error::ZNONODE)
- throw KeeperException("ZooKeeper root doesn't exist. You should create root node " + args.chroot + " before start.", Coordination::Error::ZNONODE);
+ throw KeeperException(Coordination::Error::ZNONODE, "ZooKeeper root doesn't exist. You should create root node {} before start.", args.chroot);
}
}
@@ -491,7 +491,7 @@ std::string ZooKeeper::get(const std::string & path, Coordination::Stat * stat,
if (tryGet(path, res, stat, watch, &code))
return res;
else
- throw KeeperException("Can't get data for node " + path + ": node doesn't exist", code);
+ throw KeeperException(code, "Can't get data for node '{}': node doesn't exist", path);
}
std::string ZooKeeper::getWatch(const std::string & path, Coordination::Stat * stat, Coordination::WatchCallback watch_callback)
@@ -501,7 +501,7 @@ std::string ZooKeeper::getWatch(const std::string & path, Coordination::Stat * s
if (tryGetWatch(path, res, stat, watch_callback, &code))
return res;
else
- throw KeeperException("Can't get data for node " + path + ": node doesn't exist", code);
+ throw KeeperException(code, "Can't get data for node '{}': node doesn't exist", path);
}
bool ZooKeeper::tryGet(
diff --git a/src/Common/ZooKeeper/ZooKeeperArgs.cpp b/src/Common/ZooKeeper/ZooKeeperArgs.cpp
index 198d4ccdea76..4c73b9ffc6d4 100644
--- a/src/Common/ZooKeeper/ZooKeeperArgs.cpp
+++ b/src/Common/ZooKeeper/ZooKeeperArgs.cpp
@@ -213,7 +213,7 @@ void ZooKeeperArgs::initFromKeeperSection(const Poco::Util::AbstractConfiguratio
};
}
else
- throw KeeperException(std::string("Unknown key ") + key + " in config file", Coordination::Error::ZBADARGUMENTS);
+ throw KeeperException(Coordination::Error::ZBADARGUMENTS, "Unknown key {} in config file", key);
}
}
diff --git a/src/DataTypes/Serializations/SerializationNumber.cpp b/src/DataTypes/Serializations/SerializationNumber.cpp
index 0294a1c8a67e..df6c0848bbe4 100644
--- a/src/DataTypes/Serializations/SerializationNumber.cpp
+++ b/src/DataTypes/Serializations/SerializationNumber.cpp
@@ -10,6 +10,8 @@
#include
#include
+#include
+
namespace DB
{
@@ -135,13 +137,25 @@ template
void SerializationNumber::serializeBinaryBulk(const IColumn & column, WriteBuffer & ostr, size_t offset, size_t limit) const
{
const typename ColumnVector::Container & x = typeid_cast &>(column).getData();
+ if (const size_t size = x.size(); limit == 0 || offset + limit > size)
+ limit = size - offset;
- size_t size = x.size();
+ if (limit == 0)
+ return;
- if (limit == 0 || offset + limit > size)
- limit = size - offset;
+ if constexpr (std::endian::native == std::endian::big && sizeof(T) >= 2)
+ {
+ static constexpr auto to_little_endian = [](auto i)
+ {
+ transformEndianness(i);
+ return i;
+ };
- if (limit)
+ std::ranges::for_each(
+ x | std::views::drop(offset) | std::views::take(limit) | std::views::transform(to_little_endian),
+ [&ostr](const auto & i) { ostr.write(reinterpret_cast(&i), sizeof(typename ColumnVector::ValueType)); });
+ }
+ else
ostr.write(reinterpret_cast(&x[offset]), sizeof(typename ColumnVector::ValueType) * limit);
}
@@ -149,10 +163,13 @@ template
void SerializationNumber::deserializeBinaryBulk(IColumn & column, ReadBuffer & istr, size_t limit, double /*avg_value_size_hint*/) const
{
typename ColumnVector::Container & x = typeid_cast &>(column).getData();
- size_t initial_size = x.size();
+ const size_t initial_size = x.size();
x.resize(initial_size + limit);
- size_t size = istr.readBig(reinterpret_cast(&x[initial_size]), sizeof(typename ColumnVector::ValueType) * limit);
+ const size_t size = istr.readBig(reinterpret_cast(&x[initial_size]), sizeof(typename ColumnVector::ValueType) * limit);
x.resize(initial_size + size / sizeof(typename ColumnVector::ValueType));
+
+ if constexpr (std::endian::native == std::endian::big && sizeof(T) >= 2)
+ std::ranges::for_each(x | std::views::drop(initial_size), [](auto & i) { transformEndianness(i); });
}
template class SerializationNumber;
diff --git a/src/Formats/registerFormats.cpp b/src/Formats/registerFormats.cpp
index 29ef46f330f4..580db61edde4 100644
--- a/src/Formats/registerFormats.cpp
+++ b/src/Formats/registerFormats.cpp
@@ -101,6 +101,7 @@ void registerInputFormatJSONAsObject(FormatFactory & factory);
void registerInputFormatLineAsString(FormatFactory & factory);
void registerInputFormatMySQLDump(FormatFactory & factory);
void registerInputFormatParquetMetadata(FormatFactory & factory);
+void registerInputFormatOne(FormatFactory & factory);
#if USE_HIVE
void registerInputFormatHiveText(FormatFactory & factory);
@@ -142,6 +143,7 @@ void registerTemplateSchemaReader(FormatFactory & factory);
void registerMySQLSchemaReader(FormatFactory & factory);
void registerBSONEachRowSchemaReader(FormatFactory & factory);
void registerParquetMetadataSchemaReader(FormatFactory & factory);
+void registerOneSchemaReader(FormatFactory & factory);
void registerFileExtensions(FormatFactory & factory);
@@ -243,6 +245,7 @@ void registerFormats()
registerInputFormatMySQLDump(factory);
registerInputFormatParquetMetadata(factory);
+ registerInputFormatOne(factory);
registerNonTrivialPrefixAndSuffixCheckerJSONEachRow(factory);
registerNonTrivialPrefixAndSuffixCheckerJSONAsString(factory);
@@ -279,6 +282,7 @@ void registerFormats()
registerMySQLSchemaReader(factory);
registerBSONEachRowSchemaReader(factory);
registerParquetMetadataSchemaReader(factory);
+ registerOneSchemaReader(factory);
}
}
diff --git a/src/Functions/FunctionFactory.h b/src/Functions/FunctionFactory.h
index deea41e66775..588cae64e169 100644
--- a/src/Functions/FunctionFactory.h
+++ b/src/Functions/FunctionFactory.h
@@ -20,8 +20,8 @@ using FunctionCreator = std::function;
using FunctionFactoryData = std::pair;
/** Creates function by name.
- * Function could use for initialization (take ownership of shared_ptr, for example)
- * some dictionaries from Context.
+ * The provided Context is guaranteed to outlive the created function. Functions may use it for
+ * things like settings, current database, permission checks, etc.
*/
class FunctionFactory : private boost::noncopyable, public IFactoryWithAliases
{
diff --git a/src/Functions/FunctionsExternalDictionaries.h b/src/Functions/FunctionsExternalDictionaries.h
index 1b2e2eb3bd68..db6529da73c1 100644
--- a/src/Functions/FunctionsExternalDictionaries.h
+++ b/src/Functions/FunctionsExternalDictionaries.h
@@ -62,13 +62,14 @@ namespace ErrorCodes
*/
-class FunctionDictHelper
+class FunctionDictHelper : WithContext
{
public:
- explicit FunctionDictHelper(ContextPtr context_) : current_context(context_) {}
+ explicit FunctionDictHelper(ContextPtr context_) : WithContext(context_) {}
std::shared_ptr getDictionary(const String & dictionary_name)
{
+ auto current_context = getContext();
auto dict = current_context->getExternalDictionariesLoader().getDictionary(dictionary_name, current_context);
if (!access_checked)
@@ -131,12 +132,10 @@ class FunctionDictHelper
DictionaryStructure getDictionaryStructure(const String & dictionary_name) const
{
- return current_context->getExternalDictionariesLoader().getDictionaryStructure(dictionary_name, current_context);
+ return getContext()->getExternalDictionariesLoader().getDictionaryStructure(dictionary_name, getContext());
}
private:
- ContextPtr current_context;
-
/// Access cannot be not granted, since in this case checkAccess() will throw and access_checked will not be updated.
std::atomic access_checked = false;
diff --git a/src/Functions/FunctionsHashing.h b/src/Functions/FunctionsHashing.h
index a6a04b4e3134..fb40c59fa8ae 100644
--- a/src/Functions/FunctionsHashing.h
+++ b/src/Functions/FunctionsHashing.h
@@ -1374,8 +1374,8 @@ class FunctionAnyHash : public IFunction
if constexpr (std::is_same_v) /// backward-compatible
{
- if (std::endian::native == std::endian::big)
- std::ranges::for_each(col_to->getData(), transformEndianness);
+ if constexpr (std::endian::native == std::endian::big)
+ std::ranges::for_each(col_to->getData(), transformEndianness);
auto col_to_fixed_string = ColumnFixedString::create(sizeof(UInt128));
const auto & data = col_to->getData();
diff --git a/src/Functions/FunctionsJSON.h b/src/Functions/FunctionsJSON.h
index ca797eed856d..094de0c27c2c 100644
--- a/src/Functions/FunctionsJSON.h
+++ b/src/Functions/FunctionsJSON.h
@@ -336,7 +336,7 @@ class FunctionJSONHelpers
template typename Impl>
-class ExecutableFunctionJSON : public IExecutableFunction, WithContext
+class ExecutableFunctionJSON : public IExecutableFunction
{
public:
diff --git a/src/Functions/transform.cpp b/src/Functions/transform.cpp
index 16326dd5a44b..62ab51abd765 100644
--- a/src/Functions/transform.cpp
+++ b/src/Functions/transform.cpp
@@ -776,8 +776,12 @@ namespace
UInt64 key = 0;
auto * dst = reinterpret_cast(&key);
const auto ref = cache.from_column->getDataAt(i);
+
+#pragma clang diagnostic push
+#pragma clang diagnostic ignored "-Wunreachable-code"
if constexpr (std::endian::native == std::endian::big)
dst += sizeof(key) - ref.size;
+#pragma clang diagnostic pop
memcpy(dst, ref.data, ref.size);
table[key] = i;
diff --git a/src/IO/S3/Client.cpp b/src/IO/S3/Client.cpp
index 51c7ee325794..7e251dc415af 100644
--- a/src/IO/S3/Client.cpp
+++ b/src/IO/S3/Client.cpp
@@ -188,7 +188,7 @@ Client::Client(
}
}
- LOG_TRACE(log, "API mode: {}", toString(api_mode));
+ LOG_TRACE(log, "API mode of the S3 client: {}", api_mode);
detect_region = provider_type == ProviderType::AWS && explicit_region == Aws::Region::AWS_GLOBAL;
diff --git a/src/Interpreters/ClusterProxy/SelectStreamFactory.h b/src/Interpreters/ClusterProxy/SelectStreamFactory.h
index 1cc5a3b1a77e..ca07fd5dedaf 100644
--- a/src/Interpreters/ClusterProxy/SelectStreamFactory.h
+++ b/src/Interpreters/ClusterProxy/SelectStreamFactory.h
@@ -60,9 +60,6 @@ class SelectStreamFactory
/// (When there is a local replica with big delay).
bool lazy = false;
time_t local_delay = 0;
-
- /// Set only if parallel reading from replicas is used.
- std::shared_ptr coordinator;
};
using Shards = std::vector;
diff --git a/src/Interpreters/ClusterProxy/executeQuery.cpp b/src/Interpreters/ClusterProxy/executeQuery.cpp
index 2fed626ffb7e..f2d7132b1743 100644
--- a/src/Interpreters/ClusterProxy/executeQuery.cpp
+++ b/src/Interpreters/ClusterProxy/executeQuery.cpp
@@ -28,7 +28,6 @@ namespace DB
namespace ErrorCodes
{
extern const int TOO_LARGE_DISTRIBUTED_DEPTH;
- extern const int LOGICAL_ERROR;
extern const int SUPPORT_IS_DISABLED;
}
@@ -281,7 +280,6 @@ void executeQueryWithParallelReplicas(
auto all_replicas_count = std::min(static_cast(settings.max_parallel_replicas), new_cluster->getShardCount());
auto coordinator = std::make_shared(all_replicas_count);
auto remote_plan = std::make_unique();
- auto plans = std::vector();
/// This is a little bit weird, but we construct an "empty" coordinator without
/// any specified reading/coordination method (like Default, InOrder, InReverseOrder)
@@ -309,20 +307,7 @@ void executeQueryWithParallelReplicas(
&Poco::Logger::get("ReadFromParallelRemoteReplicasStep"),
query_info.storage_limits);
- remote_plan->addStep(std::move(read_from_remote));
- remote_plan->addInterpreterContext(context);
- plans.emplace_back(std::move(remote_plan));
-
- if (std::all_of(plans.begin(), plans.end(), [](const QueryPlanPtr & plan) { return !plan; }))
- throw Exception(ErrorCodes::LOGICAL_ERROR, "No plans were generated for reading from shard. This is a bug");
-
- DataStreams input_streams;
- input_streams.reserve(plans.size());
- for (const auto & plan : plans)
- input_streams.emplace_back(plan->getCurrentDataStream());
-
- auto union_step = std::make_unique(std::move(input_streams));
- query_plan.unitePlans(std::move(union_step), std::move(plans));
+ query_plan.addStep(std::move(read_from_remote));
}
}
diff --git a/src/Interpreters/InterpreterExplainQuery.cpp b/src/Interpreters/InterpreterExplainQuery.cpp
index 3a381cd8dab5..39cc4df5c2d0 100644
--- a/src/Interpreters/InterpreterExplainQuery.cpp
+++ b/src/Interpreters/InterpreterExplainQuery.cpp
@@ -541,13 +541,13 @@ QueryPipeline InterpreterExplainQuery::executeImpl()
InterpreterSelectWithUnionQuery interpreter(ast.getExplainedQuery(), getContext(), SelectQueryOptions());
interpreter.buildQueryPlan(plan);
context = interpreter.getContext();
- // collect the selected marks, rows, parts during build query pipeline.
- plan.buildQueryPipeline(
+ // Collect the selected marks, rows, parts during build query pipeline.
+ // Hold on to the returned QueryPipelineBuilderPtr because `plan` may have pointers into
+ // it (through QueryPlanResourceHolder).
+ auto builder = plan.buildQueryPipeline(
QueryPlanOptimizationSettings::fromContext(context),
BuildQueryPipelineSettings::fromContext(context));
- if (settings.optimize)
- plan.optimize(QueryPlanOptimizationSettings::fromContext(context));
plan.explainEstimate(res_columns);
insert_buf = false;
break;
diff --git a/src/Interpreters/InterpreterSelectQueryAnalyzer.cpp b/src/Interpreters/InterpreterSelectQueryAnalyzer.cpp
index 8db1d27c073a..b8cace5e0ad9 100644
--- a/src/Interpreters/InterpreterSelectQueryAnalyzer.cpp
+++ b/src/Interpreters/InterpreterSelectQueryAnalyzer.cpp
@@ -184,7 +184,7 @@ InterpreterSelectQueryAnalyzer::InterpreterSelectQueryAnalyzer(
, context(buildContext(context_, select_query_options_))
, select_query_options(select_query_options_)
, query_tree(query_tree_)
- , planner(query_tree_, select_query_options_)
+ , planner(query_tree_, select_query_options)
{
}
diff --git a/src/Interpreters/Session.cpp b/src/Interpreters/Session.cpp
index f8bd70afdb63..bcfaae40a039 100644
--- a/src/Interpreters/Session.cpp
+++ b/src/Interpreters/Session.cpp
@@ -299,6 +299,7 @@ Session::~Session()
if (notified_session_log_about_login)
{
+ LOG_DEBUG(log, "{} Logout, user_id: {}", toString(auth_id), toString(*user_id));
if (auto session_log = getSessionLog())
{
/// TODO: We have to ensure that the same info is added to the session log on a LoginSuccess event and on the corresponding Logout event.
@@ -320,6 +321,7 @@ AuthenticationType Session::getAuthenticationTypeOrLogInFailure(const String & u
}
catch (const Exception & e)
{
+ LOG_ERROR(log, "{} Authentication failed with error: {}", toString(auth_id), e.what());
if (auto session_log = getSessionLog())
session_log->addLoginFailure(auth_id, getClientInfo(), user_name, e);
diff --git a/src/Interpreters/executeQuery.cpp b/src/Interpreters/executeQuery.cpp
index 578ca3b41f9f..a56007375f43 100644
--- a/src/Interpreters/executeQuery.cpp
+++ b/src/Interpreters/executeQuery.cpp
@@ -45,6 +45,7 @@
#include
#include
#include
+#include
#include
#include
#include
@@ -1033,6 +1034,11 @@ static std::tuple executeQueryImpl(
}
+ // InterpreterSelectQueryAnalyzer does not build QueryPlan in the constructor.
+ // We need to force to build it here to check if we need to ignore quota.
+ if (auto * interpreter_with_analyzer = dynamic_cast(interpreter.get()))
+ interpreter_with_analyzer->getQueryPlan();
+
if (!interpreter->ignoreQuota() && !quota_checked)
{
quota = context->getQuota();
diff --git a/src/Planner/Planner.cpp b/src/Planner/Planner.cpp
index 9f6c22f90f39..7cce495dfb85 100644
--- a/src/Planner/Planner.cpp
+++ b/src/Planner/Planner.cpp
@@ -1047,7 +1047,7 @@ PlannerContextPtr buildPlannerContext(const QueryTreeNodePtr & query_tree_node,
}
Planner::Planner(const QueryTreeNodePtr & query_tree_,
- const SelectQueryOptions & select_query_options_)
+ SelectQueryOptions & select_query_options_)
: query_tree(query_tree_)
, select_query_options(select_query_options_)
, planner_context(buildPlannerContext(query_tree, select_query_options, std::make_shared()))
@@ -1055,7 +1055,7 @@ Planner::Planner(const QueryTreeNodePtr & query_tree_,
}
Planner::Planner(const QueryTreeNodePtr & query_tree_,
- const SelectQueryOptions & select_query_options_,
+ SelectQueryOptions & select_query_options_,
GlobalPlannerContextPtr global_planner_context_)
: query_tree(query_tree_)
, select_query_options(select_query_options_)
@@ -1064,7 +1064,7 @@ Planner::Planner(const QueryTreeNodePtr & query_tree_,
}
Planner::Planner(const QueryTreeNodePtr & query_tree_,
- const SelectQueryOptions & select_query_options_,
+ SelectQueryOptions & select_query_options_,
PlannerContextPtr planner_context_)
: query_tree(query_tree_)
, select_query_options(select_query_options_)
diff --git a/src/Planner/Planner.h b/src/Planner/Planner.h
index 783a07f6e997..f8d151365cfb 100644
--- a/src/Planner/Planner.h
+++ b/src/Planner/Planner.h
@@ -22,16 +22,16 @@ class Planner
public:
/// Initialize planner with query tree after analysis phase
Planner(const QueryTreeNodePtr & query_tree_,
- const SelectQueryOptions & select_query_options_);
+ SelectQueryOptions & select_query_options_);
/// Initialize planner with query tree after query analysis phase and global planner context
Planner(const QueryTreeNodePtr & query_tree_,
- const SelectQueryOptions & select_query_options_,
+ SelectQueryOptions & select_query_options_,
GlobalPlannerContextPtr global_planner_context_);
/// Initialize planner with query tree after query analysis phase and planner context
Planner(const QueryTreeNodePtr & query_tree_,
- const SelectQueryOptions & select_query_options_,
+ SelectQueryOptions & select_query_options_,
PlannerContextPtr planner_context_);
const QueryPlan & getQueryPlan() const
@@ -66,7 +66,7 @@ class Planner
void buildPlanForQueryNode();
QueryTreeNodePtr query_tree;
- SelectQueryOptions select_query_options;
+ SelectQueryOptions & select_query_options;
PlannerContextPtr planner_context;
QueryPlan query_plan;
StorageLimitsList storage_limits;
diff --git a/src/Planner/PlannerJoinTree.cpp b/src/Planner/PlannerJoinTree.cpp
index 56a48ce83282..f6ce029a2950 100644
--- a/src/Planner/PlannerJoinTree.cpp
+++ b/src/Planner/PlannerJoinTree.cpp
@@ -113,6 +113,20 @@ void checkAccessRights(const TableNode & table_node, const Names & column_names,
query_context->checkAccess(AccessType::SELECT, storage_id, column_names);
}
+bool shouldIgnoreQuotaAndLimits(const TableNode & table_node)
+{
+ const auto & storage_id = table_node.getStorageID();
+ if (!storage_id.hasDatabase())
+ return false;
+ if (storage_id.database_name == DatabaseCatalog::SYSTEM_DATABASE)
+ {
+ static const boost::container::flat_set tables_ignoring_quota{"quotas", "quota_limits", "quota_usage", "quotas_usage", "one"};
+ if (tables_ignoring_quota.count(storage_id.table_name))
+ return true;
+ }
+ return false;
+}
+
NameAndTypePair chooseSmallestColumnToReadFromStorage(const StoragePtr & storage, const StorageSnapshotPtr & storage_snapshot)
{
/** We need to read at least one column to find the number of rows.
@@ -828,8 +842,9 @@ JoinTreeQueryPlan buildQueryPlanForTableExpression(QueryTreeNodePtr table_expres
}
else
{
+ SelectQueryOptions analyze_query_options = SelectQueryOptions(from_stage).analyze();
Planner planner(select_query_info.query_tree,
- SelectQueryOptions(from_stage).analyze(),
+ analyze_query_options,
select_query_info.planner_context);
planner.buildQueryPlanIfNeeded();
@@ -1375,7 +1390,7 @@ JoinTreeQueryPlan buildQueryPlanForArrayJoinNode(const QueryTreeNodePtr & array_
JoinTreeQueryPlan buildJoinTreeQueryPlan(const QueryTreeNodePtr & query_node,
const SelectQueryInfo & select_query_info,
- const SelectQueryOptions & select_query_options,
+ SelectQueryOptions & select_query_options,
const ColumnIdentifierSet & outer_scope_columns,
PlannerContextPtr & planner_context)
{
@@ -1386,6 +1401,16 @@ JoinTreeQueryPlan buildJoinTreeQueryPlan(const QueryTreeNodePtr & query_node,
std::vector table_expressions_outer_scope_columns(table_expressions_stack_size);
ColumnIdentifierSet current_outer_scope_columns = outer_scope_columns;
+ if (is_single_table_expression)
+ {
+ auto * table_node = table_expressions_stack[0]->as();
+ if (table_node && shouldIgnoreQuotaAndLimits(*table_node))
+ {
+ select_query_options.ignore_quota = true;
+ select_query_options.ignore_limits = true;
+ }
+ }
+
/// For each table, table function, query, union table expressions prepare before query plan build
for (size_t i = 0; i < table_expressions_stack_size; ++i)
{
diff --git a/src/Planner/PlannerJoinTree.h b/src/Planner/PlannerJoinTree.h
index acbc96ddae0f..9d3b98175d09 100644
--- a/src/Planner/PlannerJoinTree.h
+++ b/src/Planner/PlannerJoinTree.h
@@ -20,7 +20,7 @@ struct JoinTreeQueryPlan
/// Build JOIN TREE query plan for query node
JoinTreeQueryPlan buildJoinTreeQueryPlan(const QueryTreeNodePtr & query_node,
const SelectQueryInfo & select_query_info,
- const SelectQueryOptions & select_query_options,
+ SelectQueryOptions & select_query_options,
const ColumnIdentifierSet & outer_scope_columns,
PlannerContextPtr & planner_context);
diff --git a/src/Processors/Formats/Impl/OneFormat.cpp b/src/Processors/Formats/Impl/OneFormat.cpp
new file mode 100644
index 000000000000..4a9c8caebf35
--- /dev/null
+++ b/src/Processors/Formats/Impl/OneFormat.cpp
@@ -0,0 +1,57 @@
+#include
+#include
+#include
+
+namespace DB
+{
+
+namespace ErrorCodes
+{
+ extern const int BAD_ARGUMENTS;
+}
+
+OneInputFormat::OneInputFormat(const Block & header, ReadBuffer & in_) : IInputFormat(header, &in_)
+{
+ if (header.columns() != 1)
+ throw Exception(ErrorCodes::BAD_ARGUMENTS,
+ "One input format is only suitable for tables with a single column of type UInt8 but the number of columns is {}",
+ header.columns());
+
+ if (!WhichDataType(header.getByPosition(0).type).isUInt8())
+ throw Exception(ErrorCodes::BAD_ARGUMENTS,
+ "One input format is only suitable for tables with a single column of type String but the column type is {}",
+ header.getByPosition(0).type->getName());
+}
+
+Chunk OneInputFormat::generate()
+{
+ if (done)
+ return {};
+
+ done = true;
+ auto column = ColumnUInt8::create();
+ column->insertDefault();
+ return Chunk(Columns{std::move(column)}, 1);
+}
+
+void registerInputFormatOne(FormatFactory & factory)
+{
+ factory.registerInputFormat("One", [](
+ ReadBuffer & buf,
+ const Block & sample,
+ const RowInputFormatParams &,
+ const FormatSettings &)
+ {
+ return std::make_shared(sample, buf);
+ });
+}
+
+void registerOneSchemaReader(FormatFactory & factory)
+{
+ factory.registerExternalSchemaReader("One", [](const FormatSettings &)
+ {
+ return std::make_shared();
+ });
+}
+
+}
diff --git a/src/Processors/Formats/Impl/OneFormat.h b/src/Processors/Formats/Impl/OneFormat.h
new file mode 100644
index 000000000000..f73b2dab66ac
--- /dev/null
+++ b/src/Processors/Formats/Impl/OneFormat.h
@@ -0,0 +1,32 @@
+#pragma once
+#include
+#include
+#include
+
+namespace DB
+{
+
+class OneInputFormat final : public IInputFormat
+{
+public:
+ OneInputFormat(const Block & header, ReadBuffer & in_);
+
+ String getName() const override { return "One"; }
+
+protected:
+ Chunk generate() override;
+
+private:
+ bool done = false;
+};
+
+class OneSchemaReader: public IExternalSchemaReader
+{
+public:
+ NamesAndTypesList readSchema() override
+ {
+ return {{"dummy", std::make_shared()}};
+ }
+};
+
+}
diff --git a/src/Processors/QueryPlan/Optimizations/Optimizations.h b/src/Processors/QueryPlan/Optimizations/Optimizations.h
index 6ecec1359c54..2230e50425c1 100644
--- a/src/Processors/QueryPlan/Optimizations/Optimizations.h
+++ b/src/Processors/QueryPlan/Optimizations/Optimizations.h
@@ -16,7 +16,7 @@ void optimizeTreeFirstPass(const QueryPlanOptimizationSettings & settings, Query
void optimizeTreeSecondPass(const QueryPlanOptimizationSettings & optimization_settings, QueryPlan::Node & root, QueryPlan::Nodes & nodes);
/// Third pass is used to apply filters such as key conditions and skip indexes to the storages that support them.
/// After that it add CreateSetsStep for the subqueries that has not be used in the filters.
-void optimizeTreeThirdPass(QueryPlan::Node & root, QueryPlan::Nodes & nodes);
+void optimizeTreeThirdPass(QueryPlan & plan, QueryPlan::Node & root, QueryPlan::Nodes & nodes);
/// Optimization (first pass) is a function applied to QueryPlan::Node.
/// It can read and update subtree of specified node.
@@ -113,7 +113,7 @@ void optimizeReadInOrder(QueryPlan::Node & node, QueryPlan::Nodes & nodes);
void optimizeAggregationInOrder(QueryPlan::Node & node, QueryPlan::Nodes &);
bool optimizeUseAggregateProjections(QueryPlan::Node & node, QueryPlan::Nodes & nodes, bool allow_implicit_projections);
bool optimizeUseNormalProjections(Stack & stack, QueryPlan::Nodes & nodes);
-bool addPlansForSets(QueryPlan::Node & node, QueryPlan::Nodes & nodes);
+bool addPlansForSets(QueryPlan & plan, QueryPlan::Node & node, QueryPlan::Nodes & nodes);
/// Enable memory bound merging of aggregation states for remote queries
/// in case it was enabled for local plan
diff --git a/src/Processors/QueryPlan/Optimizations/addPlansForSets.cpp b/src/Processors/QueryPlan/Optimizations/addPlansForSets.cpp
index e9100ae9d023..47df05301c95 100644
--- a/src/Processors/QueryPlan/Optimizations/addPlansForSets.cpp
+++ b/src/Processors/QueryPlan/Optimizations/addPlansForSets.cpp
@@ -6,7 +6,7 @@
namespace DB::QueryPlanOptimizations
{
-bool addPlansForSets(QueryPlan::Node & node, QueryPlan::Nodes & nodes)
+bool addPlansForSets(QueryPlan & root_plan, QueryPlan::Node & node, QueryPlan::Nodes & nodes)
{
auto * delayed = typeid_cast(node.step.get());
if (!delayed)
@@ -23,7 +23,9 @@ bool addPlansForSets(QueryPlan::Node & node, QueryPlan::Nodes & nodes)
{
input_streams.push_back(plan->getCurrentDataStream());
node.children.push_back(plan->getRootNode());
- nodes.splice(nodes.end(), QueryPlan::detachNodes(std::move(*plan)));
+ auto [add_nodes, add_resources] = QueryPlan::detachNodesAndResources(std::move(*plan));
+ nodes.splice(nodes.end(), std::move(add_nodes));
+ root_plan.addResources(std::move(add_resources));
}
auto creating_sets = std::make_unique(std::move(input_streams));
diff --git a/src/Processors/QueryPlan/Optimizations/optimizeTree.cpp b/src/Processors/QueryPlan/Optimizations/optimizeTree.cpp
index b13dda9a8f00..0caedff67a5d 100644
--- a/src/Processors/QueryPlan/Optimizations/optimizeTree.cpp
+++ b/src/Processors/QueryPlan/Optimizations/optimizeTree.cpp
@@ -181,7 +181,7 @@ void optimizeTreeSecondPass(const QueryPlanOptimizationSettings & optimization_s
"No projection is used when optimize_use_projections = 1 and force_optimize_projection = 1");
}
-void optimizeTreeThirdPass(QueryPlan::Node & root, QueryPlan::Nodes & nodes)
+void optimizeTreeThirdPass(QueryPlan & plan, QueryPlan::Node & root, QueryPlan::Nodes & nodes)
{
Stack stack;
stack.push_back({.node = &root});
@@ -205,7 +205,7 @@ void optimizeTreeThirdPass(QueryPlan::Node & root, QueryPlan::Nodes & nodes)
source_step_with_filter->applyFilters();
}
- addPlansForSets(*frame.node, nodes);
+ addPlansForSets(plan, *frame.node, nodes);
stack.pop_back();
}
diff --git a/src/Processors/QueryPlan/QueryPlan.cpp b/src/Processors/QueryPlan/QueryPlan.cpp
index 687260441ff3..ceda9f97babc 100644
--- a/src/Processors/QueryPlan/QueryPlan.cpp
+++ b/src/Processors/QueryPlan/QueryPlan.cpp
@@ -482,7 +482,7 @@ void QueryPlan::optimize(const QueryPlanOptimizationSettings & optimization_sett
QueryPlanOptimizations::optimizeTreeFirstPass(optimization_settings, *root, nodes);
QueryPlanOptimizations::optimizeTreeSecondPass(optimization_settings, *root, nodes);
- QueryPlanOptimizations::optimizeTreeThirdPass(*root, nodes);
+ QueryPlanOptimizations::optimizeTreeThirdPass(*this, *root, nodes);
updateDataStreams(*root);
}
@@ -542,9 +542,9 @@ void QueryPlan::explainEstimate(MutableColumns & columns)
}
}
-QueryPlan::Nodes QueryPlan::detachNodes(QueryPlan && plan)
+std::pair QueryPlan::detachNodesAndResources(QueryPlan && plan)
{
- return std::move(plan.nodes);
+ return {std::move(plan.nodes), std::move(plan.resources)};
}
}
diff --git a/src/Processors/QueryPlan/QueryPlan.h b/src/Processors/QueryPlan/QueryPlan.h
index d89bdc534be0..f4a6c9097f2f 100644
--- a/src/Processors/QueryPlan/QueryPlan.h
+++ b/src/Processors/QueryPlan/QueryPlan.h
@@ -108,7 +108,7 @@ class QueryPlan
using Nodes = std::list;
Node * getRootNode() const { return root; }
- static Nodes detachNodes(QueryPlan && plan);
+ static std::pair detachNodesAndResources(QueryPlan && plan);
private:
QueryPlanResourceHolder resources;
diff --git a/src/Storages/MergeTree/IMergeTreeDataPart.cpp b/src/Storages/MergeTree/IMergeTreeDataPart.cpp
index 1bbec3f1948b..fe6d1a6e6582 100644
--- a/src/Storages/MergeTree/IMergeTreeDataPart.cpp
+++ b/src/Storages/MergeTree/IMergeTreeDataPart.cpp
@@ -1780,7 +1780,8 @@ void IMergeTreeDataPart::renameToDetached(const String & prefix)
part_is_probably_removed_from_disk = true;
}
-DataPartStoragePtr IMergeTreeDataPart::makeCloneInDetached(const String & prefix, const StorageMetadataPtr & /*metadata_snapshot*/) const
+DataPartStoragePtr IMergeTreeDataPart::makeCloneInDetached(const String & prefix, const StorageMetadataPtr & /*metadata_snapshot*/,
+ const DiskTransactionPtr & disk_transaction) const
{
/// Avoid unneeded duplicates of broken parts if we try to detach the same broken part multiple times.
/// Otherwise it may pollute detached/ with dirs with _tryN suffix and we will fail to remove broken part after 10 attempts.
@@ -1795,7 +1796,8 @@ DataPartStoragePtr IMergeTreeDataPart::makeCloneInDetached(const String & prefix
IDataPartStorage::ClonePartParams params
{
.copy_instead_of_hardlink = isStoredOnRemoteDiskWithZeroCopySupport() && storage.supportsReplication() && storage_settings->allow_remote_fs_zero_copy_replication,
- .make_source_readonly = true
+ .make_source_readonly = true,
+ .external_transaction = disk_transaction
};
return getDataPartStorage().freeze(
storage.relative_data_path,
diff --git a/src/Storages/MergeTree/IMergeTreeDataPart.h b/src/Storages/MergeTree/IMergeTreeDataPart.h
index 07f977799de7..a8e053a9c7bf 100644
--- a/src/Storages/MergeTree/IMergeTreeDataPart.h
+++ b/src/Storages/MergeTree/IMergeTreeDataPart.h
@@ -371,7 +371,8 @@ class IMergeTreeDataPart : public std::enable_shared_from_this time_t
+ {
+ auto path = fs::path(relative_data_path) / "detached" / part_info.dir_name;
+ time_t last_change_time = part_info.disk->getLastChanged(path);
+ time_t last_modification_time = part_info.disk->getLastModified(path).epochTime();
+ return std::max(last_change_time, last_modification_time);
+ };
+ time_t ttl_seconds = getSettings()->merge_tree_clear_old_broken_detached_parts_ttl_timeout_seconds;
+
+ size_t unfinished_deleting_parts = 0;
+ time_t current_time = time(nullptr);
+ for (const auto & part_info : detached_parts)
+ {
+ if (!part_info.dir_name.starts_with("deleting_"))
+ continue;
+
+ time_t startup_time = current_time - static_cast(Context::getGlobalContextInstance()->getUptimeSeconds());
+ time_t last_touch_time = get_last_touched_time(part_info);
+
+ /// Maybe it's being deleted right now (for example, in ALTER DROP DETACHED)
+ bool had_restart = last_touch_time < startup_time;
+ bool ttl_expired = last_touch_time + ttl_seconds <= current_time;
+ if (!had_restart && !ttl_expired)
+ continue;
+
+ /// We were trying to delete this detached part but did not finish deleting, probably because the server crashed
+ LOG_INFO(log, "Removing detached part {} that we failed to remove previously", part_info.dir_name);
+ try
+ {
+ removeDetachedPart(part_info.disk, fs::path(relative_data_path) / "detached" / part_info.dir_name / "", part_info.dir_name);
+ ++unfinished_deleting_parts;
+ }
+ catch (...)
+ {
+ tryLogCurrentException(log);
+ }
+ }
+
+ if (!getSettings()->merge_tree_enable_clear_old_broken_detached)
+ return unfinished_deleting_parts;
+
+ const auto full_path = fs::path(relative_data_path) / "detached";
+ size_t removed_count = 0;
for (const auto & part_info : detached_parts)
{
if (!part_info.valid_name || part_info.prefix.empty())
@@ -2635,31 +2677,24 @@ size_t MergeTreeData::clearOldBrokenPartsFromDetachedDirectory()
if (!can_be_removed_by_timeout)
continue;
- time_t current_time = time(nullptr);
- ssize_t threshold = current_time - getSettings()->merge_tree_clear_old_broken_detached_parts_ttl_timeout_seconds;
- auto path = fs::path(relative_data_path) / "detached" / part_info.dir_name;
- time_t last_change_time = part_info.disk->getLastChanged(path);
- time_t last_modification_time = part_info.disk->getLastModified(path).epochTime();
- time_t last_touch_time = std::max(last_change_time, last_modification_time);
+ ssize_t threshold = current_time - ttl_seconds;
+ time_t last_touch_time = get_last_touched_time(part_info);
if (last_touch_time == 0 || last_touch_time >= threshold)
continue;
- renamed_parts.addPart(part_info.dir_name, "deleting_" + part_info.dir_name, part_info.disk);
- }
-
- LOG_INFO(log, "Will clean up {} detached parts", renamed_parts.old_and_new_names.size());
+ const String & old_name = part_info.dir_name;
+ String new_name = "deleting_" + part_info.dir_name;
+ part_info.disk->moveFile(fs::path(full_path) / old_name, fs::path(full_path) / new_name);
- renamed_parts.tryRenameAll();
-
- for (auto & [old_name, new_name, disk] : renamed_parts.old_and_new_names)
- {
- removeDetachedPart(disk, fs::path(relative_data_path) / "detached" / new_name / "", old_name);
+ removeDetachedPart(part_info.disk, fs::path(relative_data_path) / "detached" / new_name / "", old_name);
LOG_WARNING(log, "Removed broken detached part {} due to a timeout for broken detached parts", old_name);
- old_name.clear();
+ ++removed_count;
}
- return renamed_parts.old_and_new_names.size();
+ LOG_INFO(log, "Cleaned up {} detached parts", removed_count);
+
+ return removed_count + unfinished_deleting_parts;
}
size_t MergeTreeData::clearOldWriteAheadLogs()
@@ -4035,7 +4070,7 @@ void MergeTreeData::restoreAndActivatePart(const DataPartPtr & part, DataPartsLo
void MergeTreeData::outdateUnexpectedPartAndCloneToDetached(const DataPartPtr & part_to_detach)
{
LOG_INFO(log, "Cloning part {} to unexpected_{} and making it obsolete.", part_to_detach->getDataPartStorage().getPartDirectory(), part_to_detach->name);
- part_to_detach->makeCloneInDetached("unexpected", getInMemoryMetadataPtr());
+ part_to_detach->makeCloneInDetached("unexpected", getInMemoryMetadataPtr(), /*disk_transaction*/ {});
DataPartsLock lock = lockParts();
part_to_detach->is_unexpected_local_part = true;
@@ -5797,18 +5832,21 @@ MergeTreeData::MutableDataPartsVector MergeTreeData::tryLoadPartsToAttach(const
{
const String source_dir = "detached/";
- std::map name_to_disk;
-
/// Let's compose a list of parts that should be added.
if (attach_part)
{
const String part_id = partition->as().value.safeGet();
validateDetachedPartName(part_id);
- auto disk = getDiskForDetachedPart(part_id);
- renamed_parts.addPart(part_id, "attaching_" + part_id, disk);
-
- if (MergeTreePartInfo::tryParsePartName(part_id, format_version))
- name_to_disk[part_id] = getDiskForDetachedPart(part_id);
+ if (temporary_parts.contains(String(DETACHED_DIR_NAME) + "/" + part_id))
+ {
+ LOG_WARNING(log, "Will not try to attach part {} because its directory is temporary, "
+ "probably it's being detached right now", part_id);
+ }
+ else
+ {
+ auto disk = getDiskForDetachedPart(part_id);
+ renamed_parts.addPart(part_id, "attaching_" + part_id, disk);
+ }
}
else
{
@@ -5825,6 +5863,12 @@ MergeTreeData::MutableDataPartsVector MergeTreeData::tryLoadPartsToAttach(const
for (const auto & part_info : detached_parts)
{
+ if (temporary_parts.contains(String(DETACHED_DIR_NAME) + "/" + part_info.dir_name))
+ {
+ LOG_WARNING(log, "Will not try to attach part {} because its directory is temporary, "
+ "probably it's being detached right now", part_info.dir_name);
+ continue;
+ }
LOG_DEBUG(log, "Found part {}", part_info.dir_name);
active_parts.add(part_info.dir_name);
}
@@ -5835,6 +5879,8 @@ MergeTreeData::MutableDataPartsVector MergeTreeData::tryLoadPartsToAttach(const
for (const auto & part_info : detached_parts)
{
const String containing_part = active_parts.getContainingPart(part_info.dir_name);
+ if (containing_part.empty())
+ continue;
LOG_DEBUG(log, "Found containing part {} for part {}", containing_part, part_info.dir_name);
@@ -8435,7 +8481,7 @@ void MergeTreeData::incrementMergedPartsProfileEvent(MergeTreeDataPartType type)
}
}
-MergeTreeData::MutableDataPartPtr MergeTreeData::createEmptyPart(
+std::pair MergeTreeData::createEmptyPart(
MergeTreePartInfo & new_part_info, const MergeTreePartition & partition, const String & new_part_name,
const MergeTreeTransactionPtr & txn)
{
@@ -8454,6 +8500,7 @@ MergeTreeData::MutableDataPartPtr MergeTreeData::createEmptyPart(
ReservationPtr reservation = reserveSpacePreferringTTLRules(metadata_snapshot, 0, move_ttl_infos, time(nullptr), 0, true);
VolumePtr data_part_volume = createVolumeFromReservation(reservation, volume);
+ auto tmp_dir_holder = getTemporaryPartDirectoryHolder(EMPTY_PART_TMP_PREFIX + new_part_name);
auto new_data_part = getDataPartBuilder(new_part_name, data_part_volume, EMPTY_PART_TMP_PREFIX + new_part_name)
.withBytesAndRowsOnDisk(0, 0)
.withPartInfo(new_part_info)
@@ -8513,7 +8560,7 @@ MergeTreeData::MutableDataPartPtr MergeTreeData::createEmptyPart(
out.finalizePart(new_data_part, sync_on_insert);
new_data_part_storage->precommitTransaction();
- return new_data_part;
+ return std::make_pair(std::move(new_data_part), std::move(tmp_dir_holder));
}
bool MergeTreeData::allowRemoveStaleMovingParts() const
diff --git a/src/Storages/MergeTree/MergeTreeData.h b/src/Storages/MergeTree/MergeTreeData.h
index 9ee611347403..e4801cffa36a 100644
--- a/src/Storages/MergeTree/MergeTreeData.h
+++ b/src/Storages/MergeTree/MergeTreeData.h
@@ -936,7 +936,9 @@ class MergeTreeData : public IStorage, public WithMutableContext
WriteAheadLogPtr getWriteAheadLog();
constexpr static auto EMPTY_PART_TMP_PREFIX = "tmp_empty_";
- MergeTreeData::MutableDataPartPtr createEmptyPart(MergeTreePartInfo & new_part_info, const MergeTreePartition & partition, const String & new_part_name, const MergeTreeTransactionPtr & txn);
+ std::pair createEmptyPart(
+ MergeTreePartInfo & new_part_info, const MergeTreePartition & partition,
+ const String & new_part_name, const MergeTreeTransactionPtr & txn);
MergeTreeDataFormatVersion format_version;
diff --git a/src/Storages/MergeTree/MergeTreeDataPartChecksum.cpp b/src/Storages/MergeTree/MergeTreeDataPartChecksum.cpp
index 6628cd68eaf5..5a7b2dfbca8d 100644
--- a/src/Storages/MergeTree/MergeTreeDataPartChecksum.cpp
+++ b/src/Storages/MergeTree/MergeTreeDataPartChecksum.cpp
@@ -187,15 +187,15 @@ bool MergeTreeDataPartChecksums::readV3(ReadBuffer & in)
String name;
Checksum sum;
- readBinary(name, in);
+ readStringBinary(name, in);
readVarUInt(sum.file_size, in);
- readPODBinary(sum.file_hash, in);
- readBinary(sum.is_compressed, in);
+ readBinaryLittleEndian(sum.file_hash, in);
+ readBinaryLittleEndian(sum.is_compressed, in);
if (sum.is_compressed)
{
readVarUInt(sum.uncompressed_size, in);
- readPODBinary(sum.uncompressed_hash, in);
+ readBinaryLittleEndian(sum.uncompressed_hash, in);
}
files.emplace(std::move(name), sum);
@@ -223,15 +223,15 @@ void MergeTreeDataPartChecksums::write(WriteBuffer & to) const
const String & name = it.first;
const Checksum & sum = it.second;
- writeBinary(name, out);
+ writeStringBinary(name, out);
writeVarUInt(sum.file_size, out);
- writePODBinary(sum.file_hash, out);
- writeBinary(sum.is_compressed, out);
+ writeBinaryLittleEndian(sum.file_hash, out);
+ writeBinaryLittleEndian(sum.is_compressed, out);
if (sum.is_compressed)
{
writeVarUInt(sum.uncompressed_size, out);
- writePODBinary(sum.uncompressed_hash, out);
+ writeBinaryLittleEndian(sum.uncompressed_hash, out);
}
}
}
@@ -339,9 +339,9 @@ void MinimalisticDataPartChecksums::serializeWithoutHeader(WriteBuffer & to) con
writeVarUInt(num_compressed_files, to);
writeVarUInt(num_uncompressed_files, to);
- writePODBinary(hash_of_all_files, to);
- writePODBinary(hash_of_uncompressed_files, to);
- writePODBinary(uncompressed_hash_of_compressed_files, to);
+ writeBinaryLittleEndian(hash_of_all_files, to);
+ writeBinaryLittleEndian(hash_of_uncompressed_files, to);
+ writeBinaryLittleEndian(uncompressed_hash_of_compressed_files, to);
}
String MinimalisticDataPartChecksums::getSerializedString() const
@@ -382,9 +382,9 @@ void MinimalisticDataPartChecksums::deserializeWithoutHeader(ReadBuffer & in)
readVarUInt(num_compressed_files, in);
readVarUInt(num_uncompressed_files, in);
- readPODBinary(hash_of_all_files, in);
- readPODBinary(hash_of_uncompressed_files, in);
- readPODBinary(uncompressed_hash_of_compressed_files, in);
+ readBinaryLittleEndian(hash_of_all_files, in);
+ readBinaryLittleEndian(hash_of_uncompressed_files, in);
+ readBinaryLittleEndian(uncompressed_hash_of_compressed_files, in);
}
void MinimalisticDataPartChecksums::computeTotalChecksums(const MergeTreeDataPartChecksums & full_checksums_)
diff --git a/src/Storages/MergeTree/MergeTreeDataPartInMemory.cpp b/src/Storages/MergeTree/MergeTreeDataPartInMemory.cpp
index ba300b110d78..d8034e62802e 100644
--- a/src/Storages/MergeTree/MergeTreeDataPartInMemory.cpp
+++ b/src/Storages/MergeTree/MergeTreeDataPartInMemory.cpp
@@ -17,6 +17,7 @@ namespace DB
namespace ErrorCodes
{
extern const int DIRECTORY_ALREADY_EXISTS;
+ extern const int NOT_IMPLEMENTED;
}
MergeTreeDataPartInMemory::MergeTreeDataPartInMemory(
@@ -138,8 +139,12 @@ MutableDataPartStoragePtr MergeTreeDataPartInMemory::flushToDisk(const String &
return new_data_part_storage;
}
-DataPartStoragePtr MergeTreeDataPartInMemory::makeCloneInDetached(const String & prefix, const StorageMetadataPtr & metadata_snapshot) const
+DataPartStoragePtr MergeTreeDataPartInMemory::makeCloneInDetached(const String & prefix,
+ const StorageMetadataPtr & metadata_snapshot,
+ const DiskTransactionPtr & disk_transaction) const
{
+ if (disk_transaction)
+ throw Exception(ErrorCodes::NOT_IMPLEMENTED, "InMemory parts are not compatible with disk transactions");
String detached_path = *getRelativePathForDetachedPart(prefix, /* broken */ false);
return flushToDisk(detached_path, metadata_snapshot);
}
diff --git a/src/Storages/MergeTree/MergeTreeDataPartInMemory.h b/src/Storages/MergeTree/MergeTreeDataPartInMemory.h
index 81549eeed3ee..95f7b796f9ad 100644
--- a/src/Storages/MergeTree/MergeTreeDataPartInMemory.h
+++ b/src/Storages/MergeTree/MergeTreeDataPartInMemory.h
@@ -42,7 +42,8 @@ class MergeTreeDataPartInMemory : public IMergeTreeDataPart
bool hasColumnFiles(const NameAndTypePair & column) const override { return !!getColumnPosition(column.getNameInStorage()); }
String getFileNameForColumn(const NameAndTypePair & /* column */) const override { return ""; }
void renameTo(const String & new_relative_path, bool remove_new_dir_if_exists) override;
- DataPartStoragePtr makeCloneInDetached(const String & prefix, const StorageMetadataPtr & metadata_snapshot) const override;
+ DataPartStoragePtr makeCloneInDetached(const String & prefix, const StorageMetadataPtr & metadata_snapshot,
+ const DiskTransactionPtr & disk_transaction) const override;
std::optional getColumnModificationTime(const String & /* column_name */) const override { return {}; }
MutableDataPartStoragePtr flushToDisk(const String & new_relative_path, const StorageMetadataPtr & metadata_snapshot) const;
diff --git a/src/Storages/MergeTree/MergeTreeDataPartWriterCompact.cpp b/src/Storages/MergeTree/MergeTreeDataPartWriterCompact.cpp
index 5e1da21da5ba..75e6aca07937 100644
--- a/src/Storages/MergeTree/MergeTreeDataPartWriterCompact.cpp
+++ b/src/Storages/MergeTree/MergeTreeDataPartWriterCompact.cpp
@@ -365,8 +365,9 @@ void MergeTreeDataPartWriterCompact::addToChecksums(MergeTreeDataPartChecksums &
{
uncompressed_size += stream->hashing_buf.count();
auto stream_hash = stream->hashing_buf.getHash();
+ transformEndianness(stream_hash);
uncompressed_hash = CityHash_v1_0_2::CityHash128WithSeed(
- reinterpret_cast(&stream_hash), sizeof(stream_hash), uncompressed_hash);
+ reinterpret_cast(&stream_hash), sizeof(stream_hash), uncompressed_hash);
}
checksums.files[data_file_name].is_compressed = true;
diff --git a/src/Storages/MergeTree/ReplicatedMergeTreeCleanupThread.cpp b/src/Storages/MergeTree/ReplicatedMergeTreeCleanupThread.cpp
index 07cfced8362e..b72c148a4e8a 100644
--- a/src/Storages/MergeTree/ReplicatedMergeTreeCleanupThread.cpp
+++ b/src/Storages/MergeTree/ReplicatedMergeTreeCleanupThread.cpp
@@ -149,8 +149,7 @@ Float32 ReplicatedMergeTreeCleanupThread::iterate()
/// do it under share lock
cleaned_other += storage.clearOldWriteAheadLogs();
cleaned_part_like += storage.clearOldTemporaryDirectories(storage.getSettings()->temporary_directories_lifetime.totalSeconds());
- if (storage.getSettings()->merge_tree_enable_clear_old_broken_detached)
- cleaned_part_like += storage.clearOldBrokenPartsFromDetachedDirectory();
+ cleaned_part_like += storage.clearOldBrokenPartsFromDetachedDirectory();
}
/// This is loose condition: no problem if we actually had lost leadership at this moment
diff --git a/src/Storages/MergeTree/ReplicatedMergeTreeSink.cpp b/src/Storages/MergeTree/ReplicatedMergeTreeSink.cpp
index 0db3464a6371..fa5a40cf27a5 100644
--- a/src/Storages/MergeTree/ReplicatedMergeTreeSink.cpp
+++ b/src/Storages/MergeTree/ReplicatedMergeTreeSink.cpp
@@ -633,8 +633,8 @@ void ReplicatedMergeTreeSinkImpl::finishDelayedChunk(const ZooKeeperWithFa
delayed_chunk.reset();
}
-template
-void ReplicatedMergeTreeSinkImpl::writeExistingPart(MergeTreeData::MutableDataPartPtr & part)
+template<>
+bool ReplicatedMergeTreeSinkImpl::writeExistingPart(MergeTreeData::MutableDataPartPtr & part)
{
/// NOTE: No delay in this case. That's Ok.
auto origin_zookeeper = storage.getZooKeeper();
@@ -649,8 +649,13 @@ void ReplicatedMergeTreeSinkImpl::writeExistingPart(MergeTreeData:
try
{
part->version.setCreationTID(Tx::PrehistoricTID, nullptr);
- commitPart(zookeeper, part, BlockIDsType(), replicas_num, true);
- PartLog::addNewPart(storage.getContext(), PartLog::PartLogEntry(part, watch.elapsed(), profile_events_scope.getSnapshot()));
+ String block_id = deduplicate ? fmt::format("{}_{}", part->info.partition_id, part->checksums.getTotalChecksumHex()) : "";
+ bool deduplicated = commitPart(zookeeper, part, block_id, replicas_num, /* writing_existing_part */ true).second;
+
+ /// Set a special error code if the block is duplicate
+ int error = (deduplicate && deduplicated) ? ErrorCodes::INSERT_WAS_DEDUPLICATED : 0;
+ PartLog::addNewPart(storage.getContext(), PartLog::PartLogEntry(part, watch.elapsed(), profile_events_scope.getSnapshot()), ExecutionStatus(error));
+ return deduplicated;
}
catch (...)
{
diff --git a/src/Storages/MergeTree/ReplicatedMergeTreeSink.h b/src/Storages/MergeTree/ReplicatedMergeTreeSink.h
index 868590efa257..4a192a822f5b 100644
--- a/src/Storages/MergeTree/ReplicatedMergeTreeSink.h
+++ b/src/Storages/MergeTree/ReplicatedMergeTreeSink.h
@@ -56,7 +56,7 @@ class ReplicatedMergeTreeSinkImpl : public SinkToStorage
String getName() const override { return "ReplicatedMergeTreeSink"; }
/// For ATTACHing existing data on filesystem.
- void writeExistingPart(MergeTreeData::MutableDataPartPtr & part);
+ bool writeExistingPart(MergeTreeData::MutableDataPartPtr & part);
/// For proper deduplication in MaterializedViews
bool lastBlockIsDuplicate() const override
diff --git a/src/Storages/StorageDistributed.cpp b/src/Storages/StorageDistributed.cpp
index a7aeb11e2d85..f80e498efa86 100644
--- a/src/Storages/StorageDistributed.cpp
+++ b/src/Storages/StorageDistributed.cpp
@@ -691,7 +691,11 @@ QueryTreeNodePtr buildQueryTreeDistributed(SelectQueryInfo & query_info,
if (remote_storage_id.hasDatabase())
resolved_remote_storage_id = query_context->resolveStorageID(remote_storage_id);
- auto storage = std::make_shared(resolved_remote_storage_id, distributed_storage_snapshot->metadata->getColumns(), distributed_storage_snapshot->object_columns);
+ auto get_column_options = GetColumnsOptions(GetColumnsOptions::All).withExtendedObjects().withVirtuals();
+
+ auto column_names_and_types = distributed_storage_snapshot->getColumns(get_column_options);
+
+ auto storage = std::make_shared(resolved_remote_storage_id, ColumnsDescription{column_names_and_types});
auto table_node = std::make_shared(std::move(storage), query_context);
if (table_expression_modifiers)
diff --git a/src/Storages/StorageMergeTree.cpp b/src/Storages/StorageMergeTree.cpp
index ad9013d9f131..3a9449ba51f0 100644
--- a/src/Storages/StorageMergeTree.cpp
+++ b/src/Storages/StorageMergeTree.cpp
@@ -1379,8 +1379,7 @@ bool StorageMergeTree::scheduleDataProcessingJob(BackgroundJobsAssignee & assign
cleared_count += clearOldWriteAheadLogs();
cleared_count += clearOldMutations();
cleared_count += clearEmptyParts();
- if (getSettings()->merge_tree_enable_clear_old_broken_detached)
- cleared_count += clearOldBrokenPartsFromDetachedDirectory();
+ cleared_count += clearOldBrokenPartsFromDetachedDirectory();
return cleared_count;
/// TODO maybe take into account number of cleared objects when calculating backoff
}, common_assignee_trigger, getStorageID()), /* need_trigger */ false);
@@ -1653,11 +1652,7 @@ struct FutureNewEmptyPart
MergeTreePartition partition;
std::string part_name;
- scope_guard tmp_dir_guard;
-
StorageMergeTree::MutableDataPartPtr data_part;
-
- std::string getDirName() const { return StorageMergeTree::EMPTY_PART_TMP_PREFIX + part_name; }
};
using FutureNewEmptyParts = std::vector;
@@ -1688,19 +1683,19 @@ FutureNewEmptyParts initCoverageWithNewEmptyParts(const DataPartsVector & old_pa
return future_parts;
}
-StorageMergeTree::MutableDataPartsVector createEmptyDataParts(MergeTreeData & data, FutureNewEmptyParts & future_parts, const MergeTreeTransactionPtr & txn)
+std::pair> createEmptyDataParts(
+ MergeTreeData & data, FutureNewEmptyParts & future_parts, const MergeTreeTransactionPtr & txn)
{
- StorageMergeTree::MutableDataPartsVector data_parts;
+ std::pair> data_parts;
for (auto & part: future_parts)
- data_parts.push_back(data.createEmptyPart(part.part_info, part.partition, part.part_name, txn));
+ {
+ auto [new_data_part, tmp_dir_holder] = data.createEmptyPart(part.part_info, part.partition, part.part_name, txn);
+ data_parts.first.emplace_back(std::move(new_data_part));
+ data_parts.second.emplace_back(std::move(tmp_dir_holder));
+ }
return data_parts;
}
-void captureTmpDirectoryHolders(MergeTreeData & data, FutureNewEmptyParts & future_parts)
-{
- for (auto & part : future_parts)
- part.tmp_dir_guard = data.getTemporaryPartDirectoryHolder(part.getDirName());
-}
void StorageMergeTree::renameAndCommitEmptyParts(MutableDataPartsVector & new_parts, Transaction & transaction)
{
@@ -1767,9 +1762,7 @@ void StorageMergeTree::truncate(const ASTPtr &, const StorageMetadataPtr &, Cont
fmt::join(getPartsNames(future_parts), ", "), fmt::join(getPartsNames(parts), ", "),
transaction.getTID());
- captureTmpDirectoryHolders(*this, future_parts);
-
- auto new_data_parts = createEmptyDataParts(*this, future_parts, txn);
+ auto [new_data_parts, tmp_dir_holders] = createEmptyDataParts(*this, future_parts, txn);
renameAndCommitEmptyParts(new_data_parts, transaction);
PartLog::addNewParts(query_context, PartLog::createPartLogEntries(new_data_parts, watch.elapsed(), profile_events_scope.getSnapshot()));
@@ -1817,8 +1810,10 @@ void StorageMergeTree::dropPart(const String & part_name, bool detach, ContextPt
if (detach)
{
auto metadata_snapshot = getInMemoryMetadataPtr();
- LOG_INFO(log, "Detaching {}", part->getDataPartStorage().getPartDirectory());
- part->makeCloneInDetached("", metadata_snapshot);
+ String part_dir = part->getDataPartStorage().getPartDirectory();
+ LOG_INFO(log, "Detaching {}", part_dir);
+ auto holder = getTemporaryPartDirectoryHolder(String(DETACHED_DIR_NAME) + "/" + part_dir);
+ part->makeCloneInDetached("", metadata_snapshot, /*disk_transaction*/ {});
}
{
@@ -1828,9 +1823,7 @@ void StorageMergeTree::dropPart(const String & part_name, bool detach, ContextPt
fmt::join(getPartsNames(future_parts), ", "), fmt::join(getPartsNames({part}), ", "),
transaction.getTID());
- captureTmpDirectoryHolders(*this, future_parts);
-
- auto new_data_parts = createEmptyDataParts(*this, future_parts, txn);
+ auto [new_data_parts, tmp_dir_holders] = createEmptyDataParts(*this, future_parts, txn);
renameAndCommitEmptyParts(new_data_parts, transaction);
PartLog::addNewParts(query_context, PartLog::createPartLogEntries(new_data_parts, watch.elapsed(), profile_events_scope.getSnapshot()));
@@ -1902,8 +1895,10 @@ void StorageMergeTree::dropPartition(const ASTPtr & partition, bool detach, Cont
for (const auto & part : parts)
{
auto metadata_snapshot = getInMemoryMetadataPtr();
- LOG_INFO(log, "Detaching {}", part->getDataPartStorage().getPartDirectory());
- part->makeCloneInDetached("", metadata_snapshot);
+ String part_dir = part->getDataPartStorage().getPartDirectory();
+ LOG_INFO(log, "Detaching {}", part_dir);
+ auto holder = getTemporaryPartDirectoryHolder(String(DETACHED_DIR_NAME) + "/" + part_dir);
+ part->makeCloneInDetached("", metadata_snapshot, /*disk_transaction*/ {});
}
}
@@ -1914,9 +1909,8 @@ void StorageMergeTree::dropPartition(const ASTPtr & partition, bool detach, Cont
fmt::join(getPartsNames(future_parts), ", "), fmt::join(getPartsNames(parts), ", "),
transaction.getTID());
- captureTmpDirectoryHolders(*this, future_parts);
- auto new_data_parts = createEmptyDataParts(*this, future_parts, txn);
+ auto [new_data_parts, tmp_dir_holders] = createEmptyDataParts(*this, future_parts, txn);
renameAndCommitEmptyParts(new_data_parts, transaction);
PartLog::addNewParts(query_context, PartLog::createPartLogEntries(new_data_parts, watch.elapsed(), profile_events_scope.getSnapshot()));
@@ -1944,8 +1938,10 @@ void StorageMergeTree::dropPartsImpl(DataPartsVector && parts_to_remove, bool de
/// NOTE: no race with background cleanup until we hold pointers to parts
for (const auto & part : parts_to_remove)
{
- LOG_INFO(log, "Detaching {}", part->getDataPartStorage().getPartDirectory());
- part->makeCloneInDetached("", metadata_snapshot);
+ String part_dir = part->getDataPartStorage().getPartDirectory();
+ LOG_INFO(log, "Detaching {}", part_dir);
+ auto holder = getTemporaryPartDirectoryHolder(String(DETACHED_DIR_NAME) + "/" + part_dir);
+ part->makeCloneInDetached("", metadata_snapshot, /*disk_transaction*/ {});
}
}
diff --git a/src/Storages/StorageReplicatedMergeTree.cpp b/src/Storages/StorageReplicatedMergeTree.cpp
index 7fce373e26bc..5b7b36a1de36 100644
--- a/src/Storages/StorageReplicatedMergeTree.cpp
+++ b/src/Storages/StorageReplicatedMergeTree.cpp
@@ -2097,8 +2097,10 @@ void StorageReplicatedMergeTree::executeDropRange(const LogEntry & entry)
{
if (auto part_to_detach = part.getPartIfItWasActive())
{
- LOG_INFO(log, "Detaching {}", part_to_detach->getDataPartStorage().getPartDirectory());
- part_to_detach->makeCloneInDetached("", metadata_snapshot);
+ String part_dir = part_to_detach->getDataPartStorage().getPartDirectory();
+ LOG_INFO(log, "Detaching {}", part_dir);
+ auto holder = getTemporaryPartDirectoryHolder(String(DETACHED_DIR_NAME) + "/" + part_dir);
+ part_to_detach->makeCloneInDetached("", metadata_snapshot, /*disk_transaction*/ {});
}
}
}
@@ -2828,7 +2830,7 @@ void StorageReplicatedMergeTree::cloneReplica(const String & source_replica, Coo
for (const auto & part : parts_to_remove_from_working_set)
{
LOG_INFO(log, "Detaching {}", part->getDataPartStorage().getPartDirectory());
- part->makeCloneInDetached("clone", metadata_snapshot);
+ part->makeCloneInDetached("clone", metadata_snapshot, /*disk_transaction*/ {});
}
}
@@ -3794,12 +3796,12 @@ void StorageReplicatedMergeTree::removePartAndEnqueueFetch(const String & part_n
chassert(!broken_part);
chassert(!storage_init);
part->was_removed_as_broken = true;
- part->makeCloneInDetached("broken", getInMemoryMetadataPtr());
+ part->makeCloneInDetached("broken", getInMemoryMetadataPtr(), /*disk_transaction*/ {});
broken_part = part;
}
else
{
- part->makeCloneInDetached("covered-by-broken", getInMemoryMetadataPtr());
+ part->makeCloneInDetached("covered-by-broken", getInMemoryMetadataPtr(), /*disk_transaction*/ {});
}
detached_parts.push_back(part->name);
}
@@ -6133,8 +6135,9 @@ PartitionCommandsResultInfo StorageReplicatedMergeTree::attachPartition(
MutableDataPartsVector loaded_parts = tryLoadPartsToAttach(partition, attach_part, query_context, renamed_parts);
/// TODO Allow to use quorum here.
- ReplicatedMergeTreeSink output(*this, metadata_snapshot, 0, 0, 0, false, false, false, query_context,
- /*is_attach*/true);
+ ReplicatedMergeTreeSink output(*this, metadata_snapshot, /* quorum */ 0, /* quorum_timeout_ms */ 0, /* max_parts_per_block */ 0,
+ /* quorum_parallel */ false, query_context->getSettingsRef().insert_deduplicate,
+ /* majority_quorum */ false, query_context, /*is_attach*/true);
for (size_t i = 0; i < loaded_parts.size(); ++i)
{
@@ -9509,7 +9512,7 @@ bool StorageReplicatedMergeTree::createEmptyPartInsteadOfLost(zkutil::ZooKeeperP
}
}
- MergeTreeData::MutableDataPartPtr new_data_part = createEmptyPart(new_part_info, partition, lost_part_name, NO_TRANSACTION_PTR);
+ auto [new_data_part, tmp_dir_holder] = createEmptyPart(new_part_info, partition, lost_part_name, NO_TRANSACTION_PTR);
new_data_part->setName(lost_part_name);
try
diff --git a/src/Storages/System/StorageSystemTables.cpp b/src/Storages/System/StorageSystemTables.cpp
index 60dfc3a75e8b..715c98ee92a3 100644
--- a/src/Storages/System/StorageSystemTables.cpp
+++ b/src/Storages/System/StorageSystemTables.cpp
@@ -108,6 +108,22 @@ static ColumnPtr getFilteredTables(const ASTPtr & query, const ColumnPtr & filte
return block.getByPosition(0).column;
}
+/// Avoid heavy operation on tables if we only queried columns that we can get without table object.
+/// Otherwise it will require table initialization for Lazy database.
+static bool needTable(const DatabasePtr & database, const Block & header)
+{
+ if (database->getEngineName() != "Lazy")
+ return true;
+
+ static const std::set columns_without_table = { "database", "name", "uuid", "metadata_modification_time" };
+ for (const auto & column : header.getColumnsWithTypeAndName())
+ {
+ if (columns_without_table.find(column.name) == columns_without_table.end())
+ return true;
+ }
+ return false;
+}
+
class TablesBlockSource : public ISource
{
@@ -266,6 +282,8 @@ class TablesBlockSource : public ISource
if (!tables_it || !tables_it->isValid())
tables_it = database->getTablesIterator(context);
+ const bool need_table = needTable(database, getPort().getHeader());
+
for (; rows_count < max_block_size && tables_it->isValid(); tables_it->next())
{
auto table_name = tables_it->name();
@@ -275,23 +293,27 @@ class TablesBlockSource : public ISource
if (check_access_for_tables && !access->isGranted(AccessType::SHOW_TABLES, database_name, table_name))
continue;
- StoragePtr table = tables_it->table();
- if (!table)
- // Table might have just been removed or detached for Lazy engine (see DatabaseLazy::tryGetTable())
- continue;
-
+ StoragePtr table = nullptr;
TableLockHolder lock;
- /// The only column that requires us to hold a shared lock is data_paths as rename might alter them (on ordinary tables)
- /// and it's not protected internally by other mutexes
- static const size_t DATA_PATHS_INDEX = 5;
- if (columns_mask[DATA_PATHS_INDEX])
+ if (need_table)
{
- lock = table->tryLockForShare(context->getCurrentQueryId(), context->getSettingsRef().lock_acquire_timeout);
- if (!lock)
- // Table was dropped while acquiring the lock, skipping table
+ table = tables_it->table();
+ if (!table)
+ // Table might have just been removed or detached for Lazy engine (see DatabaseLazy::tryGetTable())
continue;
- }
+ /// The only column that requires us to hold a shared lock is data_paths as rename might alter them (on ordinary tables)
+ /// and it's not protected internally by other mutexes
+ static const size_t DATA_PATHS_INDEX = 5;
+ if (columns_mask[DATA_PATHS_INDEX])
+ {
+ lock = table->tryLockForShare(context->getCurrentQueryId(),
+ context->getSettingsRef().lock_acquire_timeout);
+ if (!lock)
+ // Table was dropped while acquiring the lock, skipping table
+ continue;
+ }
+ }
++rows_count;
size_t src_index = 0;
@@ -308,6 +330,7 @@ class TablesBlockSource : public ISource
if (columns_mask[src_index++])
{
+ chassert(table != nullptr);
res_columns[res_index++]->insert(table->getName());
}
@@ -397,7 +420,9 @@ class TablesBlockSource : public ISource
else
src_index += 3;
- StorageMetadataPtr metadata_snapshot = table->getInMemoryMetadataPtr();
+ StorageMetadataPtr metadata_snapshot;
+ if (table)
+ metadata_snapshot = table->getInMemoryMetadataPtr();
ASTPtr expression_ptr;
if (columns_mask[src_index++])
@@ -434,7 +459,7 @@ class TablesBlockSource : public ISource
if (columns_mask[src_index++])
{
- auto policy = table->getStoragePolicy();
+ auto policy = table ? table->getStoragePolicy() : nullptr;
if (policy)
res_columns[res_index++]->insert(policy->getName());
else
@@ -445,7 +470,7 @@ class TablesBlockSource : public ISource
settings.select_sequential_consistency = 0;
if (columns_mask[src_index++])
{
- auto total_rows = table->totalRows(settings);
+ auto total_rows = table ? table->totalRows(settings) : std::nullopt;
if (total_rows)
res_columns[res_index++]->insert(*total_rows);
else
@@ -490,7 +515,7 @@ class TablesBlockSource : public ISource
if (columns_mask[src_index++])
{
- auto lifetime_rows = table->lifetimeRows();
+ auto lifetime_rows = table ? table->lifetimeRows() : std::nullopt;
if (lifetime_rows)
res_columns[res_index++]->insert(*lifetime_rows);
else
@@ -499,7 +524,7 @@ class TablesBlockSource : public ISource
if (columns_mask[src_index++])
{
- auto lifetime_bytes = table->lifetimeBytes();
+ auto lifetime_bytes = table ? table->lifetimeBytes() : std::nullopt;
if (lifetime_bytes)
res_columns[res_index++]->insert(*lifetime_bytes);
else
diff --git a/tests/analyzer_integration_broken_tests.txt b/tests/analyzer_integration_broken_tests.txt
index 68822fbf311d..20ea31efa70f 100644
--- a/tests/analyzer_integration_broken_tests.txt
+++ b/tests/analyzer_integration_broken_tests.txt
@@ -5,24 +5,6 @@ test_distributed_ddl/test.py::test_default_database[configs_secure]
test_distributed_ddl/test.py::test_on_server_fail[configs]
test_distributed_ddl/test.py::test_on_server_fail[configs_secure]
test_distributed_insert_backward_compatibility/test.py::test_distributed_in_tuple
-test_distributed_inter_server_secret/test.py::test_per_user_inline_settings_secure_cluster[default-]
-test_distributed_inter_server_secret/test.py::test_per_user_inline_settings_secure_cluster[nopass-]
-test_distributed_inter_server_secret/test.py::test_per_user_inline_settings_secure_cluster[pass-foo]
-test_distributed_inter_server_secret/test.py::test_per_user_protocol_settings_secure_cluster[default-]
-test_distributed_inter_server_secret/test.py::test_per_user_protocol_settings_secure_cluster[nopass-]
-test_distributed_inter_server_secret/test.py::test_per_user_protocol_settings_secure_cluster[pass-foo]
-test_distributed_inter_server_secret/test.py::test_user_insecure_cluster[default-]
-test_distributed_inter_server_secret/test.py::test_user_insecure_cluster[nopass-]
-test_distributed_inter_server_secret/test.py::test_user_insecure_cluster[pass-foo]
-test_distributed_inter_server_secret/test.py::test_user_secure_cluster[default-]
-test_distributed_inter_server_secret/test.py::test_user_secure_cluster[nopass-]
-test_distributed_inter_server_secret/test.py::test_user_secure_cluster[pass-foo]
-test_distributed_inter_server_secret/test.py::test_user_secure_cluster_from_backward[default-]
-test_distributed_inter_server_secret/test.py::test_user_secure_cluster_from_backward[nopass-]
-test_distributed_inter_server_secret/test.py::test_user_secure_cluster_from_backward[pass-foo]
-test_distributed_inter_server_secret/test.py::test_user_secure_cluster_with_backward[default-]
-test_distributed_inter_server_secret/test.py::test_user_secure_cluster_with_backward[nopass-]
-test_distributed_inter_server_secret/test.py::test_user_secure_cluster_with_backward[pass-foo]
test_distributed_load_balancing/test.py::test_distributed_replica_max_ignored_errors
test_distributed_load_balancing/test.py::test_load_balancing_default
test_distributed_load_balancing/test.py::test_load_balancing_priority_round_robin[dist_priority]
@@ -96,22 +78,6 @@ test_executable_table_function/test.py::test_executable_function_input_python
test_settings_profile/test.py::test_show_profiles
test_sql_user_defined_functions_on_cluster/test.py::test_sql_user_defined_functions_on_cluster
test_postgresql_protocol/test.py::test_python_client
-test_quota/test.py::test_add_remove_interval
-test_quota/test.py::test_add_remove_quota
-test_quota/test.py::test_consumption_of_show_clusters
-test_quota/test.py::test_consumption_of_show_databases
-test_quota/test.py::test_consumption_of_show_privileges
-test_quota/test.py::test_consumption_of_show_processlist
-test_quota/test.py::test_consumption_of_show_tables
-test_quota/test.py::test_dcl_introspection
-test_quota/test.py::test_dcl_management
-test_quota/test.py::test_exceed_quota
-test_quota/test.py::test_query_inserts
-test_quota/test.py::test_quota_from_users_xml
-test_quota/test.py::test_reload_users_xml_by_timer
-test_quota/test.py::test_simpliest_quota
-test_quota/test.py::test_tracking_quota
-test_quota/test.py::test_users_xml_is_readonly
test_mysql_database_engine/test.py::test_mysql_ddl_for_mysql_database
test_profile_events_s3/test.py::test_profile_events
test_user_defined_object_persistence/test.py::test_persistence
@@ -121,22 +87,6 @@ test_select_access_rights/test_main.py::test_alias_columns
test_select_access_rights/test_main.py::test_select_count
test_select_access_rights/test_main.py::test_select_join
test_postgresql_protocol/test.py::test_python_client
-test_quota/test.py::test_add_remove_interval
-test_quota/test.py::test_add_remove_quota
-test_quota/test.py::test_consumption_of_show_clusters
-test_quota/test.py::test_consumption_of_show_databases
-test_quota/test.py::test_consumption_of_show_privileges
-test_quota/test.py::test_consumption_of_show_processlist
-test_quota/test.py::test_consumption_of_show_tables
-test_quota/test.py::test_dcl_introspection
-test_quota/test.py::test_dcl_management
-test_quota/test.py::test_exceed_quota
-test_quota/test.py::test_query_inserts
-test_quota/test.py::test_quota_from_users_xml
-test_quota/test.py::test_reload_users_xml_by_timer
-test_quota/test.py::test_simpliest_quota
-test_quota/test.py::test_tracking_quota
-test_quota/test.py::test_users_xml_is_readonly
test_replicating_constants/test.py::test_different_versions
test_merge_tree_s3/test.py::test_heavy_insert_select_check_memory[node]
test_wrong_db_or_table_name/test.py::test_wrong_table_name
diff --git a/tests/ci/ast_fuzzer_check.py b/tests/ci/ast_fuzzer_check.py
index 74b875c23be4..fecf207589e5 100644
--- a/tests/ci/ast_fuzzer_check.py
+++ b/tests/ci/ast_fuzzer_check.py
@@ -8,7 +8,11 @@
from github import Github
from build_download_helper import get_build_name_for_check, read_build_urls
-from clickhouse_helper import ClickHouseHelper, prepare_tests_results_for_clickhouse
+from clickhouse_helper import (
+ ClickHouseHelper,
+ prepare_tests_results_for_clickhouse,
+ get_instance_type,
+)
from commit_status_helper import (
RerunHelper,
format_description,
@@ -30,15 +34,32 @@
IMAGE_NAME = "clickhouse/fuzzer"
-def get_run_command(pr_number, sha, download_url, workspace_path, image):
+def get_run_command(
+ check_start_time, check_name, pr_number, sha, download_url, workspace_path, image
+):
+ instance_type = get_instance_type()
+
+ envs = [
+ "-e CLICKHOUSE_CI_LOGS_HOST",
+ "-e CLICKHOUSE_CI_LOGS_PASSWORD",
+ f"-e CHECK_START_TIME='{check_start_time}'",
+ f"-e CHECK_NAME='{check_name}'",
+ f"-e INSTANCE_TYPE='{instance_type}'",
+ f"-e PR_TO_TEST={pr_number}",
+ f"-e SHA_TO_TEST={sha}",
+ f"-e BINARY_URL_TO_DOWNLOAD='{download_url}'",
+ ]
+
+ env_str = " ".join(envs)
+
return (
f"docker run "
# For sysctl
"--privileged "
"--network=host "
f"--volume={workspace_path}:/workspace "
+ f"{env_str} "
"--cap-add syslog --cap-add sys_admin --cap-add=SYS_PTRACE "
- f'-e PR_TO_TEST={pr_number} -e SHA_TO_TEST={sha} -e BINARY_URL_TO_DOWNLOAD="{download_url}" '
f"{image}"
)
@@ -88,11 +109,19 @@ def main():
os.makedirs(workspace_path)
run_command = get_run_command(
- pr_info.number, pr_info.sha, build_url, workspace_path, docker_image
+ stopwatch.start_time_str,
+ check_name,
+ pr_info.number,
+ pr_info.sha,
+ build_url,
+ workspace_path,
+ docker_image,
)
logging.info("Going to run %s", run_command)
run_log_path = os.path.join(temp_path, "run.log")
+ main_log_path = os.path.join(workspace_path, "main.log")
+
with open(run_log_path, "w", encoding="utf-8") as log:
with subprocess.Popen(
run_command, shell=True, stderr=log, stdout=log
@@ -105,20 +134,47 @@ def main():
subprocess.check_call(f"sudo chown -R ubuntu:ubuntu {temp_path}", shell=True)
+ # Cleanup run log from the credentials of CI logs database.
+ # Note: a malicious user can still print them by splitting the value into parts.
+ # But we will be warned when a malicious user modifies CI script.
+ # Although they can also print them from inside tests.
+ # Nevertheless, the credentials of the CI logs have limited scope
+ # and does not provide access to sensitive info.
+
+ ci_logs_host = os.getenv("CLICKHOUSE_CI_LOGS_HOST", "CLICKHOUSE_CI_LOGS_HOST")
+ ci_logs_password = os.getenv(
+ "CLICKHOUSE_CI_LOGS_PASSWORD", "CLICKHOUSE_CI_LOGS_PASSWORD"
+ )
+
+ if ci_logs_host not in ("CLICKHOUSE_CI_LOGS_HOST", ""):
+ subprocess.check_call(
+ f"sed -i -r -e 's!{ci_logs_host}!CLICKHOUSE_CI_LOGS_HOST!g; s!{ci_logs_password}!CLICKHOUSE_CI_LOGS_PASSWORD!g;' '{run_log_path}' '{main_log_path}'",
+ shell=True,
+ )
+
check_name_lower = (
check_name.lower().replace("(", "").replace(")", "").replace(" ", "")
)
s3_prefix = f"{pr_info.number}/{pr_info.sha}/fuzzer_{check_name_lower}/"
paths = {
"run.log": run_log_path,
- "main.log": os.path.join(workspace_path, "main.log"),
- "server.log.zst": os.path.join(workspace_path, "server.log.zst"),
+ "main.log": main_log_path,
"fuzzer.log": os.path.join(workspace_path, "fuzzer.log"),
"report.html": os.path.join(workspace_path, "report.html"),
"core.zst": os.path.join(workspace_path, "core.zst"),
"dmesg.log": os.path.join(workspace_path, "dmesg.log"),
}
+ compressed_server_log_path = os.path.join(workspace_path, "server.log.zst")
+ if os.path.exists(compressed_server_log_path):
+ paths["server.log.zst"] = compressed_server_log_path
+
+ # The script can fail before the invocation of `zstd`, but we are still interested in its log:
+
+ not_compressed_server_log_path = os.path.join(workspace_path, "server.log")
+ if os.path.exists(not_compressed_server_log_path):
+ paths["server.log"] = not_compressed_server_log_path
+
s3_helper = S3Helper()
for f in paths:
try:
diff --git a/tests/ci/functional_test_check.py b/tests/ci/functional_test_check.py
index d06da94d0f00..2bab330bd663 100644
--- a/tests/ci/functional_test_check.py
+++ b/tests/ci/functional_test_check.py
@@ -394,10 +394,11 @@ def main():
ci_logs_password = os.getenv(
"CLICKHOUSE_CI_LOGS_PASSWORD", "CLICKHOUSE_CI_LOGS_PASSWORD"
)
- subprocess.check_call(
- f"sed -i -r -e 's!{ci_logs_host}!CLICKHOUSE_CI_LOGS_HOST!g; s!{ci_logs_password}!CLICKHOUSE_CI_LOGS_PASSWORD!g;' '{run_log_path}'",
- shell=True,
- )
+ if ci_logs_host not in ("CLICKHOUSE_CI_LOGS_HOST", ""):
+ subprocess.check_call(
+ f"sed -i -r -e 's!{ci_logs_host}!CLICKHOUSE_CI_LOGS_HOST!g; s!{ci_logs_password}!CLICKHOUSE_CI_LOGS_PASSWORD!g;' '{run_log_path}'",
+ shell=True,
+ )
report_url = upload_results(
s3_helper,
diff --git a/tests/ci/install_check.py b/tests/ci/install_check.py
index 010b0dab408c..a5788e2af3fd 100644
--- a/tests/ci/install_check.py
+++ b/tests/ci/install_check.py
@@ -50,8 +50,19 @@ def prepare_test_scripts():
server_test = r"""#!/bin/bash
set -e
trap "bash -ex /packages/preserve_logs.sh" ERR
+test_env='TEST_THE_DEFAULT_PARAMETER=15'
+echo "$test_env" >> /etc/default/clickhouse
systemctl start clickhouse-server
-clickhouse-client -q 'SELECT version()'"""
+clickhouse-client -q 'SELECT version()'
+grep "$test_env" /proc/$(cat /var/run/clickhouse-server/clickhouse-server.pid)/environ"""
+ initd_test = r"""#!/bin/bash
+set -e
+trap "bash -ex /packages/preserve_logs.sh" ERR
+test_env='TEST_THE_DEFAULT_PARAMETER=15'
+echo "$test_env" >> /etc/default/clickhouse
+/etc/init.d/clickhouse-server start
+clickhouse-client -q 'SELECT version()'
+grep "$test_env" /proc/$(cat /var/run/clickhouse-server/clickhouse-server.pid)/environ"""
keeper_test = r"""#!/bin/bash
set -e
trap "bash -ex /packages/preserve_logs.sh" ERR
@@ -102,6 +113,7 @@ def prepare_test_scripts():
exit 1
"""
(TEMP_PATH / "server_test.sh").write_text(server_test, encoding="utf-8")
+ (TEMP_PATH / "initd_test.sh").write_text(initd_test, encoding="utf-8")
(TEMP_PATH / "keeper_test.sh").write_text(keeper_test, encoding="utf-8")
(TEMP_PATH / "binary_test.sh").write_text(binary_test, encoding="utf-8")
(TEMP_PATH / "preserve_logs.sh").write_text(preserve_logs, encoding="utf-8")
@@ -112,6 +124,9 @@ def test_install_deb(image: DockerImage) -> TestResults:
"Install server deb": r"""#!/bin/bash -ex
apt-get install /packages/clickhouse-{server,client,common}*deb
bash -ex /packages/server_test.sh""",
+ "Run server init.d": r"""#!/bin/bash -ex
+apt-get install /packages/clickhouse-{server,client,common}*deb
+bash -ex /packages/initd_test.sh""",
"Install keeper deb": r"""#!/bin/bash -ex
apt-get install /packages/clickhouse-keeper*deb
bash -ex /packages/keeper_test.sh""",
@@ -191,6 +206,9 @@ def test_install(image: DockerImage, tests: Dict[str, str]) -> TestResults:
retcode = process.wait()
if retcode == 0:
status = OK
+ subprocess.check_call(
+ f"docker kill -s 9 {container_id}", shell=True
+ )
break
status = FAIL
@@ -198,8 +216,8 @@ def test_install(image: DockerImage, tests: Dict[str, str]) -> TestResults:
archive_path = TEMP_PATH / f"{container_name}-{retry}.tar.gz"
compress_fast(LOGS_PATH, archive_path)
logs.append(archive_path)
+ subprocess.check_call(f"docker kill -s 9 {container_id}", shell=True)
- subprocess.check_call(f"docker kill -s 9 {container_id}", shell=True)
test_results.append(TestResult(name, status, stopwatch.duration_seconds, logs))
return test_results
@@ -276,7 +294,7 @@ def main():
sys.exit(0)
docker_images = {
- name: get_image_with_version(REPORTS_PATH, name)
+ name: get_image_with_version(REPORTS_PATH, name, args.download)
for name in (RPM_IMAGE, DEB_IMAGE)
}
prepare_test_scripts()
@@ -293,6 +311,8 @@ def filter_artifacts(path: str) -> bool:
is_match = is_match or path.endswith(".rpm")
if args.tgz:
is_match = is_match or path.endswith(".tgz")
+ # We don't need debug packages, so let's filter them out
+ is_match = is_match and "-dbg" not in path
return is_match
download_builds_filter(
diff --git a/tests/ci/pr_info.py b/tests/ci/pr_info.py
index 86d4985c6b27..dee71b726dfe 100644
--- a/tests/ci/pr_info.py
+++ b/tests/ci/pr_info.py
@@ -279,7 +279,7 @@ def get_dict(self):
"user_orgs": self.user_orgs,
}
- def has_changes_in_documentation(self):
+ def has_changes_in_documentation(self) -> bool:
# If the list wasn't built yet the best we can do is to
# assume that there were changes.
if self.changed_files is None or not self.changed_files:
@@ -287,10 +287,9 @@ def has_changes_in_documentation(self):
for f in self.changed_files:
_, ext = os.path.splitext(f)
- path_in_docs = "docs" in f
- path_in_website = "website" in f
+ path_in_docs = f.startswith("docs/")
if (
- ext in DIFF_IN_DOCUMENTATION_EXT and (path_in_docs or path_in_website)
+ ext in DIFF_IN_DOCUMENTATION_EXT and path_in_docs
) or "docker/docs" in f:
return True
return False
diff --git a/tests/ci/run_check.py b/tests/ci/run_check.py
index 4f022b6c0a5c..db98a2c1ab5d 100644
--- a/tests/ci/run_check.py
+++ b/tests/ci/run_check.py
@@ -137,17 +137,20 @@ def main():
if pr_labels_to_remove:
remove_labels(gh, pr_info, pr_labels_to_remove)
- if FEATURE_LABEL in pr_info.labels:
- print(f"The '{FEATURE_LABEL}' in the labels, expect the 'Docs Check' status")
+ if FEATURE_LABEL in pr_info.labels and not pr_info.has_changes_in_documentation():
+ print(
+ f"The '{FEATURE_LABEL}' in the labels, "
+ "but there's no changed documentation"
+ )
post_commit_status( # do not pass pr_info here intentionally
commit,
- "pending",
+ "failure",
NotSet,
f"expect adding docs for {FEATURE_LABEL}",
DOCS_NAME,
+ pr_info,
)
- elif not description_error:
- set_mergeable_check(commit, "skipped")
+ sys.exit(1)
if description_error:
print(
@@ -173,6 +176,7 @@ def main():
)
sys.exit(1)
+ set_mergeable_check(commit, "skipped")
ci_report_url = create_ci_report(pr_info, [])
if not can_run:
print("::notice ::Cannot run")
diff --git a/tests/ci/s3_helper.py b/tests/ci/s3_helper.py
index e21e03cc8b63..2bfe639739b4 100644
--- a/tests/ci/s3_helper.py
+++ b/tests/ci/s3_helper.py
@@ -92,7 +92,7 @@ def _upload_file_to_s3(self, bucket_name: str, file_path: str, s3_path: str) ->
file_path,
)
else:
- logging.info("No content type provied for %s", file_path)
+ logging.info("No content type provided for %s", file_path)
else:
if re.search(r"\.(txt|log|err|out)$", s3_path) or re.search(
r"\.log\..*(?
logging.info("File is too large, do not provide content type")
self.client.upload_file(file_path, bucket_name, s3_path, ExtraArgs=metadata)
- logging.info("Upload %s to %s. Meta: %s", file_path, s3_path, metadata)
# last two replacements are specifics of AWS urls:
# https://jamesd3142.wordpress.com/2018/02/28/amazon-s3-and-the-plus-symbol/
url = f"{self.download_host}/{bucket_name}/{s3_path}"
- return url.replace("+", "%2B").replace(" ", "%20")
+ url = url.replace("+", "%2B").replace(" ", "%20")
+ logging.info("Upload %s to %s. Meta: %s", file_path, url, metadata)
+ return url
def upload_test_report_to_s3(self, file_path: str, s3_path: str) -> str:
if CI:
diff --git a/tests/ci/stress_check.py b/tests/ci/stress_check.py
index 42d372efb5d3..21c3178faab1 100644
--- a/tests/ci/stress_check.py
+++ b/tests/ci/stress_check.py
@@ -209,10 +209,11 @@ def run_stress_test(docker_image_name):
ci_logs_password = os.getenv(
"CLICKHOUSE_CI_LOGS_PASSWORD", "CLICKHOUSE_CI_LOGS_PASSWORD"
)
- subprocess.check_call(
- f"sed -i -r -e 's!{ci_logs_host}!CLICKHOUSE_CI_LOGS_HOST!g; s!{ci_logs_password}!CLICKHOUSE_CI_LOGS_PASSWORD!g;' '{run_log_path}'",
- shell=True,
- )
+ if ci_logs_host not in ("CLICKHOUSE_CI_LOGS_HOST", ""):
+ subprocess.check_call(
+ f"sed -i -r -e 's!{ci_logs_host}!CLICKHOUSE_CI_LOGS_HOST!g; s!{ci_logs_password}!CLICKHOUSE_CI_LOGS_PASSWORD!g;' '{run_log_path}'",
+ shell=True,
+ )
report_url = upload_results(
s3_helper,
diff --git a/tests/ci/workflow_approve_rerun_lambda/app.py b/tests/ci/workflow_approve_rerun_lambda/app.py
index 5e2331ece3cb..e511d773577f 100644
--- a/tests/ci/workflow_approve_rerun_lambda/app.py
+++ b/tests/ci/workflow_approve_rerun_lambda/app.py
@@ -64,6 +64,7 @@
"DocsCheck",
"MasterCI",
"NightlyBuilds",
+ "PublishedReleaseCI",
"PullRequestCI",
"ReleaseBranchCI",
}
diff --git a/tests/clickhouse-test b/tests/clickhouse-test
index fc175f2a05a3..1ce5ad981ad8 100755
--- a/tests/clickhouse-test
+++ b/tests/clickhouse-test
@@ -2152,7 +2152,7 @@ def reportLogStats(args):
print("\n")
query = """
- SELECT message_format_string, count(), substr(any(message), 1, 120) AS any_message
+ SELECT message_format_string, count(), any(message) AS any_message
FROM system.text_log
WHERE (now() - toIntervalMinute(240)) < event_time
AND (message NOT LIKE (replaceRegexpAll(message_format_string, '{[:.0-9dfx]*}', '%') AS s))
diff --git a/tests/integration/parallel_skip.json b/tests/integration/parallel_skip.json
index dec51396c510..d056225fee45 100644
--- a/tests/integration/parallel_skip.json
+++ b/tests/integration/parallel_skip.json
@@ -91,5 +91,6 @@
"test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_http_named_session",
"test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_grpc",
"test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_tcp_and_others",
- "test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_setting_in_query"
+ "test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_setting_in_query",
+ "test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_client_suggestions_load"
]
diff --git a/tests/integration/test_broken_detached_part_clean_up/test.py b/tests/integration/test_broken_detached_part_clean_up/test.py
index 9a70ebe0d482..bdf993ddedfe 100644
--- a/tests/integration/test_broken_detached_part_clean_up/test.py
+++ b/tests/integration/test_broken_detached_part_clean_up/test.py
@@ -57,27 +57,30 @@ def remove_broken_detached_part_impl(table, node, expect_broken_prefix):
]
)
- node.exec_in_container(["mkdir", f"{path_to_detached}../unexpected_all_42_1337_5"])
- node.exec_in_container(
- [
- "touch",
- "-t",
- "1312031429.30",
- f"{path_to_detached}../unexpected_all_42_1337_5",
- ]
- )
- result = node.exec_in_container(
- ["stat", f"{path_to_detached}../unexpected_all_42_1337_5"]
- )
- print(result)
- assert "Modify: 2013-12-03" in result
- node.exec_in_container(
- [
- "mv",
- f"{path_to_detached}../unexpected_all_42_1337_5",
- f"{path_to_detached}unexpected_all_42_1337_5",
- ]
- )
+ for name in [
+ "unexpected_all_42_1337_5",
+ "deleting_all_123_456_7",
+ "covered-by-broken_all_12_34_5",
+ ]:
+ node.exec_in_container(["mkdir", f"{path_to_detached}../{name}"])
+ node.exec_in_container(
+ [
+ "touch",
+ "-t",
+ "1312031429.30",
+ f"{path_to_detached}../{name}",
+ ]
+ )
+ result = node.exec_in_container(["stat", f"{path_to_detached}../{name}"])
+ print(result)
+ assert "Modify: 2013-12-03" in result
+ node.exec_in_container(
+ [
+ "mv",
+ f"{path_to_detached}../{name}",
+ f"{path_to_detached}{name}",
+ ]
+ )
result = node.query(
f"CHECK TABLE {table}", settings={"check_query_single_value_result": 0}
@@ -87,17 +90,20 @@ def remove_broken_detached_part_impl(table, node, expect_broken_prefix):
node.query(f"DETACH TABLE {table}")
node.query(f"ATTACH TABLE {table}")
- result = node.exec_in_container(["ls", path_to_detached])
- print(result)
- assert f"{expect_broken_prefix}_all_3_3_0" in result
- assert "all_1_1_0" in result
- assert "trash" in result
- assert "broken_all_fake" in result
- assert "unexpected_all_42_1337_5" in result
-
- time.sleep(15)
- assert node.contains_in_log(
- "Removed broken detached part unexpected_all_42_1337_5 due to a timeout"
+ node.wait_for_log_line(
+ "Removing detached part deleting_all_123_456_7",
+ timeout=90,
+ look_behind_lines=1000000,
+ )
+ node.wait_for_log_line(
+ f"Removed broken detached part {expect_broken_prefix}_all_3_3_0 due to a timeout",
+ timeout=10,
+ look_behind_lines=1000000,
+ )
+ node.wait_for_log_line(
+ "Removed broken detached part unexpected_all_42_1337_5 due to a timeout",
+ timeout=10,
+ look_behind_lines=1000000,
)
result = node.exec_in_container(["ls", path_to_detached])
@@ -106,7 +112,16 @@ def remove_broken_detached_part_impl(table, node, expect_broken_prefix):
assert "all_1_1_0" in result
assert "trash" in result
assert "broken_all_fake" in result
+ assert "covered-by-broken_all_12_34_5" in result
assert "unexpected_all_42_1337_5" not in result
+ assert "deleting_all_123_456_7" not in result
+
+ node.query(
+ f"ALTER TABLE {table} DROP DETACHED PART 'covered-by-broken_all_12_34_5'",
+ settings={"allow_drop_detached": 1},
+ )
+ result = node.exec_in_container(["ls", path_to_detached])
+ assert "covered-by-broken_all_12_34_5" not in result
node.query(f"DROP TABLE {table} SYNC")
diff --git a/tests/integration/test_distributed_inter_server_secret/test.py b/tests/integration/test_distributed_inter_server_secret/test.py
index 36ac07a550a7..1aeaddcf3c5a 100644
--- a/tests/integration/test_distributed_inter_server_secret/test.py
+++ b/tests/integration/test_distributed_inter_server_secret/test.py
@@ -110,10 +110,6 @@ def start_cluster():
cluster.shutdown()
-def query_with_id(node, id_, query, **kwargs):
- return node.query("WITH '{}' AS __id {}".format(id_, query), **kwargs)
-
-
# @return -- [user, initial_user]
def get_query_user_info(node, query_pattern):
node.query("SYSTEM FLUSH LOGS")
@@ -334,7 +330,7 @@ def test_secure_disagree_insert():
@users
def test_user_insecure_cluster(user, password):
id_ = "query-dist_insecure-" + user
- query_with_id(n1, id_, "SELECT * FROM dist_insecure", user=user, password=password)
+ n1.query(f"SELECT *, '{id_}' FROM dist_insecure", user=user, password=password)
assert get_query_user_info(n1, id_) == [
user,
user,
@@ -345,7 +341,7 @@ def test_user_insecure_cluster(user, password):
@users
def test_user_secure_cluster(user, password):
id_ = "query-dist_secure-" + user
- query_with_id(n1, id_, "SELECT * FROM dist_secure", user=user, password=password)
+ n1.query(f"SELECT *, '{id_}' FROM dist_secure", user=user, password=password)
assert get_query_user_info(n1, id_) == [user, user]
assert get_query_user_info(n2, id_) == [user, user]
@@ -353,16 +349,14 @@ def test_user_secure_cluster(user, password):
@users
def test_per_user_inline_settings_insecure_cluster(user, password):
id_ = "query-ddl-settings-dist_insecure-" + user
- query_with_id(
- n1,
- id_,
- """
- SELECT * FROM dist_insecure
- SETTINGS
- prefer_localhost_replica=0,
- max_memory_usage_for_user=1e9,
- max_untracked_memory=0
- """,
+ n1.query(
+ f"""
+ SELECT *, '{id_}' FROM dist_insecure
+ SETTINGS
+ prefer_localhost_replica=0,
+ max_memory_usage_for_user=1e9,
+ max_untracked_memory=0
+ """,
user=user,
password=password,
)
@@ -372,16 +366,14 @@ def test_per_user_inline_settings_insecure_cluster(user, password):
@users
def test_per_user_inline_settings_secure_cluster(user, password):
id_ = "query-ddl-settings-dist_secure-" + user
- query_with_id(
- n1,
- id_,
- """
- SELECT * FROM dist_secure
- SETTINGS
- prefer_localhost_replica=0,
- max_memory_usage_for_user=1e9,
- max_untracked_memory=0
- """,
+ n1.query(
+ f"""
+ SELECT *, '{id_}' FROM dist_secure
+ SETTINGS
+ prefer_localhost_replica=0,
+ max_memory_usage_for_user=1e9,
+ max_untracked_memory=0
+ """,
user=user,
password=password,
)
@@ -393,10 +385,8 @@ def test_per_user_inline_settings_secure_cluster(user, password):
@users
def test_per_user_protocol_settings_insecure_cluster(user, password):
id_ = "query-protocol-settings-dist_insecure-" + user
- query_with_id(
- n1,
- id_,
- "SELECT * FROM dist_insecure",
+ n1.query(
+ f"SELECT *, '{id_}' FROM dist_insecure",
user=user,
password=password,
settings={
@@ -411,10 +401,8 @@ def test_per_user_protocol_settings_insecure_cluster(user, password):
@users
def test_per_user_protocol_settings_secure_cluster(user, password):
id_ = "query-protocol-settings-dist_secure-" + user
- query_with_id(
- n1,
- id_,
- "SELECT * FROM dist_secure",
+ n1.query(
+ f"SELECT *, '{id_}' FROM dist_secure",
user=user,
password=password,
settings={
@@ -431,8 +419,8 @@ def test_per_user_protocol_settings_secure_cluster(user, password):
@users
def test_user_secure_cluster_with_backward(user, password):
id_ = "with-backward-query-dist_secure-" + user
- query_with_id(
- n1, id_, "SELECT * FROM dist_secure_backward", user=user, password=password
+ n1.query(
+ f"SELECT *, '{id_}' FROM dist_secure_backward", user=user, password=password
)
assert get_query_user_info(n1, id_) == [user, user]
assert get_query_user_info(backward, id_) == [user, user]
@@ -441,13 +429,7 @@ def test_user_secure_cluster_with_backward(user, password):
@users
def test_user_secure_cluster_from_backward(user, password):
id_ = "from-backward-query-dist_secure-" + user
- query_with_id(
- backward,
- id_,
- "SELECT * FROM dist_secure_backward",
- user=user,
- password=password,
- )
+ backward.query(f"SELECT *, '{id_}' FROM dist_secure", user=user, password=password)
assert get_query_user_info(n1, id_) == [user, user]
assert get_query_user_info(backward, id_) == [user, user]
diff --git a/tests/integration/test_profile_max_sessions_for_user/test.py b/tests/integration/test_profile_max_sessions_for_user/test.py
index 2930262f63ec..5eaef09bf6d4 100755
--- a/tests/integration/test_profile_max_sessions_for_user/test.py
+++ b/tests/integration/test_profile_max_sessions_for_user/test.py
@@ -10,6 +10,7 @@
from helpers.cluster import ClickHouseCluster, run_and_check
from helpers.test_tools import assert_logs_contain_with_retry
+from helpers.uclient import client, prompt
MAX_SESSIONS_FOR_USER = 2
POSTGRES_SERVER_PORT = 5433
@@ -27,10 +28,7 @@
gen_dir = os.path.join(SCRIPT_DIR, "./_gen")
os.makedirs(gen_dir, exist_ok=True)
run_and_check(
- "python3 -m grpc_tools.protoc -I{proto_dir} --python_out={gen_dir} --grpc_python_out={gen_dir} \
- {proto_dir}/clickhouse_grpc.proto".format(
- proto_dir=proto_dir, gen_dir=gen_dir
- ),
+ f"python3 -m grpc_tools.protoc -I{proto_dir} --python_out={gen_dir} --grpc_python_out={gen_dir} {proto_dir}/clickhouse_grpc.proto",
shell=True,
)
@@ -209,3 +207,36 @@ def test_profile_max_sessions_for_user_tcp_and_others(started_cluster):
def test_profile_max_sessions_for_user_setting_in_query(started_cluster):
instance.query_and_get_error("SET max_sessions_for_user = 10")
+
+
+def test_profile_max_sessions_for_user_client_suggestions_connection(started_cluster):
+ command_text = f"{started_cluster.get_client_cmd()} --host {instance.ip_address} --port 9000 -u {TEST_USER} --password {TEST_PASSWORD}"
+ command_text_without_suggestions = command_text + " --disable_suggestion"
+
+ # Launch client1 without suggestions to avoid a race condition:
+ # Client1 opens a session.
+ # Client1 opens a session for suggestion connection.
+ # Client2 fails to open a session and gets the USER_SESSION_LIMIT_EXCEEDED error.
+ #
+ # Expected order:
+ # Client1 opens a session.
+ # Client2 opens a session.
+ # Client2 fails to open a session for suggestions and with USER_SESSION_LIMIT_EXCEEDED (No error printed).
+ # Client3 fails to open a session.
+ # Client1 executes the query.
+ # Client2 loads suggestions from the server using the main connection and executes a query.
+ with client(
+ name="client1>", log=None, command=command_text_without_suggestions
+ ) as client1:
+ client1.expect(prompt)
+ with client(name="client2>", log=None, command=command_text) as client2:
+ client2.expect(prompt)
+ with client(name="client3>", log=None, command=command_text) as client3:
+ client3.expect("USER_SESSION_LIMIT_EXCEEDED")
+
+ client1.send("SELECT 'CLIENT_1_SELECT' FORMAT CSV")
+ client1.expect("CLIENT_1_SELECT")
+ client1.expect(prompt)
+ client2.send("SELECT 'CLIENT_2_SELECT' FORMAT CSV")
+ client2.expect("CLIENT_2_SELECT")
+ client2.expect(prompt)
diff --git a/tests/integration/test_session_log/.gitignore b/tests/integration/test_session_log/.gitignore
new file mode 100644
index 000000000000..edf565ec6329
--- /dev/null
+++ b/tests/integration/test_session_log/.gitignore
@@ -0,0 +1 @@
+_gen
diff --git a/tests/integration/test_session_log/__init__.py b/tests/integration/test_session_log/__init__.py
new file mode 100644
index 000000000000..e69de29bb2d1
diff --git a/tests/integration/test_session_log/configs/log.xml b/tests/integration/test_session_log/configs/log.xml
new file mode 100644
index 000000000000..7a079b81e693
--- /dev/null
+++ b/tests/integration/test_session_log/configs/log.xml
@@ -0,0 +1,9 @@
+
+
+ trace
+ /var/log/clickhouse-server/clickhouse-server.log
+ /var/log/clickhouse-server/clickhouse-server.err.log
+ 1000M
+ 10
+
+
\ No newline at end of file
diff --git a/tests/integration/test_session_log/configs/ports.xml b/tests/integration/test_session_log/configs/ports.xml
new file mode 100644
index 000000000000..fbaefc16b3a8
--- /dev/null
+++ b/tests/integration/test_session_log/configs/ports.xml
@@ -0,0 +1,9 @@
+
+ 5433
+ 9001
+ 9100
+
+
+ false
+
+
\ No newline at end of file
diff --git a/tests/integration/test_session_log/configs/session_log.xml b/tests/integration/test_session_log/configs/session_log.xml
new file mode 100644
index 000000000000..a0e4e3e2216b
--- /dev/null
+++ b/tests/integration/test_session_log/configs/session_log.xml
@@ -0,0 +1,9 @@
+
+
+ system
+
+
+ toYYYYMM(event_date)
+ 7500
+
+
diff --git a/tests/integration/test_session_log/configs/users.xml b/tests/integration/test_session_log/configs/users.xml
new file mode 100644
index 000000000000..0416dfadc8ae
--- /dev/null
+++ b/tests/integration/test_session_log/configs/users.xml
@@ -0,0 +1,23 @@
+
+
+
+ 0
+
+
+
+
+
+
+ pass
+
+
+ pass
+
+
+ pass
+
+
+ pass
+
+
+
\ No newline at end of file
diff --git a/tests/integration/test_session_log/protos/clickhouse_grpc.proto b/tests/integration/test_session_log/protos/clickhouse_grpc.proto
new file mode 120000
index 000000000000..25d15f11e3bd
--- /dev/null
+++ b/tests/integration/test_session_log/protos/clickhouse_grpc.proto
@@ -0,0 +1 @@
+../../../../src/Server/grpc_protos/clickhouse_grpc.proto
\ No newline at end of file
diff --git a/tests/integration/test_session_log/test.py b/tests/integration/test_session_log/test.py
new file mode 100644
index 000000000000..bb7cafa4ee61
--- /dev/null
+++ b/tests/integration/test_session_log/test.py
@@ -0,0 +1,292 @@
+import os
+
+import grpc
+import pymysql.connections
+import pytest
+import random
+import sys
+import threading
+
+from helpers.cluster import ClickHouseCluster, run_and_check
+
+POSTGRES_SERVER_PORT = 5433
+MYSQL_SERVER_PORT = 9001
+GRPC_PORT = 9100
+SESSION_LOG_MATCHING_FIELDS = "auth_id, auth_type, client_version_major, client_version_minor, client_version_patch, interface"
+
+SCRIPT_DIR = os.path.dirname(os.path.realpath(__file__))
+DEFAULT_ENCODING = "utf-8"
+
+# Use grpcio-tools to generate *pb2.py files from *.proto.
+proto_dir = os.path.join(SCRIPT_DIR, "./protos")
+gen_dir = os.path.join(SCRIPT_DIR, "./_gen")
+os.makedirs(gen_dir, exist_ok=True)
+run_and_check(
+ f"python3 -m grpc_tools.protoc -I{proto_dir} --python_out={gen_dir} --grpc_python_out={gen_dir} {proto_dir}/clickhouse_grpc.proto",
+ shell=True,
+)
+
+sys.path.append(gen_dir)
+
+import clickhouse_grpc_pb2
+import clickhouse_grpc_pb2_grpc
+
+cluster = ClickHouseCluster(__file__)
+instance = cluster.add_instance(
+ "node",
+ main_configs=[
+ "configs/ports.xml",
+ "configs/log.xml",
+ "configs/session_log.xml",
+ ],
+ user_configs=["configs/users.xml"],
+ # Bug in TSAN reproduces in this test https://github.com/grpc/grpc/issues/29550#issuecomment-1188085387
+ env_variables={
+ "TSAN_OPTIONS": "report_atomic_races=0 " + os.getenv("TSAN_OPTIONS", default="")
+ },
+ with_postgres=True,
+)
+
+
+def grpc_get_url():
+ return f"{instance.ip_address}:{GRPC_PORT}"
+
+
+def grpc_create_insecure_channel():
+ channel = grpc.insecure_channel(grpc_get_url())
+ grpc.channel_ready_future(channel).result(timeout=2)
+ return channel
+
+
+session_id_counter = 0
+
+
+def next_session_id():
+ global session_id_counter
+ session_id = session_id_counter
+ session_id_counter += 1
+ return str(session_id)
+
+
+def grpc_query(query, user_, pass_, raise_exception):
+ try:
+ query_info = clickhouse_grpc_pb2.QueryInfo(
+ query=query,
+ session_id=next_session_id(),
+ user_name=user_,
+ password=pass_,
+ )
+ channel = grpc_create_insecure_channel()
+ stub = clickhouse_grpc_pb2_grpc.ClickHouseStub(channel)
+ result = stub.ExecuteQuery(query_info)
+ if result and result.HasField("exception"):
+ raise Exception(result.exception.display_text)
+
+ return result.output.decode(DEFAULT_ENCODING)
+ except Exception:
+ assert raise_exception
+
+
+def postgres_query(query, user_, pass_, raise_exception):
+ try:
+ connection_string = f"host={instance.hostname} port={POSTGRES_SERVER_PORT} dbname=default user={user_} password={pass_}"
+ cluster.exec_in_container(
+ cluster.postgres_id,
+ [
+ "/usr/bin/psql",
+ connection_string,
+ "--no-align",
+ "--field-separator=' '",
+ "-c",
+ query,
+ ],
+ shell=True,
+ )
+ except Exception:
+ assert raise_exception
+
+
+def mysql_query(query, user_, pass_, raise_exception):
+ try:
+ client = pymysql.connections.Connection(
+ host=instance.ip_address,
+ user=user_,
+ password=pass_,
+ database="default",
+ port=MYSQL_SERVER_PORT,
+ )
+ cursor = client.cursor(pymysql.cursors.DictCursor)
+ if raise_exception:
+ with pytest.raises(Exception):
+ cursor.execute(query)
+ else:
+ cursor.execute(query)
+ cursor.fetchall()
+ except Exception:
+ assert raise_exception
+
+
+@pytest.fixture(scope="module")
+def started_cluster():
+ try:
+ cluster.start()
+ yield cluster
+ finally:
+ cluster.shutdown()
+
+
+def test_grpc_session(started_cluster):
+ grpc_query("SELECT 1", "grpc_user", "pass", False)
+ grpc_query("SELECT 2", "grpc_user", "wrong_pass", True)
+ grpc_query("SELECT 3", "wrong_grpc_user", "pass", True)
+
+ instance.query("SYSTEM FLUSH LOGS")
+ login_success_records = instance.query(
+ "SELECT user, client_port <> 0, client_address <> toIPv6('::') FROM system.session_log WHERE user='grpc_user' AND type = 'LoginSuccess'"
+ )
+ assert login_success_records == "grpc_user\t1\t1\n"
+ logout_records = instance.query(
+ "SELECT user, client_port <> 0, client_address <> toIPv6('::') FROM system.session_log WHERE user='grpc_user' AND type = 'Logout'"
+ )
+ assert logout_records == "grpc_user\t1\t1\n"
+ login_failure_records = instance.query(
+ "SELECT user, client_port <> 0, client_address <> toIPv6('::') FROM system.session_log WHERE user='grpc_user' AND type = 'LoginFailure'"
+ )
+ assert login_failure_records == "grpc_user\t1\t1\n"
+ logins_and_logouts = instance.query(
+ f"SELECT COUNT(*) FROM (SELECT {SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = 'grpc_user' AND type = 'LoginSuccess' INTERSECT SELECT {SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = 'grpc_user' AND type = 'Logout')"
+ )
+ assert logins_and_logouts == "1\n"
+
+
+def test_mysql_session(started_cluster):
+ mysql_query("SELECT 1", "mysql_user", "pass", False)
+ mysql_query("SELECT 2", "mysql_user", "wrong_pass", True)
+ mysql_query("SELECT 3", "wrong_mysql_user", "pass", True)
+
+ instance.query("SYSTEM FLUSH LOGS")
+ login_success_records = instance.query(
+ "SELECT user, client_port <> 0, client_address <> toIPv6('::') FROM system.session_log WHERE user='mysql_user' AND type = 'LoginSuccess'"
+ )
+ assert login_success_records == "mysql_user\t1\t1\n"
+ logout_records = instance.query(
+ "SELECT user, client_port <> 0, client_address <> toIPv6('::') FROM system.session_log WHERE user='mysql_user' AND type = 'Logout'"
+ )
+ assert logout_records == "mysql_user\t1\t1\n"
+ login_failure_records = instance.query(
+ "SELECT user, client_port <> 0, client_address <> toIPv6('::') FROM system.session_log WHERE user='mysql_user' AND type = 'LoginFailure'"
+ )
+ assert login_failure_records == "mysql_user\t1\t1\n"
+ logins_and_logouts = instance.query(
+ f"SELECT COUNT(*) FROM (SELECT {SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = 'mysql_user' AND type = 'LoginSuccess' INTERSECT SELECT {SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = 'mysql_user' AND type = 'Logout')"
+ )
+ assert logins_and_logouts == "1\n"
+
+
+def test_postgres_session(started_cluster):
+ postgres_query("SELECT 1", "postgres_user", "pass", False)
+ postgres_query("SELECT 2", "postgres_user", "wrong_pass", True)
+ postgres_query("SELECT 3", "wrong_postgres_user", "pass", True)
+
+ instance.query("SYSTEM FLUSH LOGS")
+ login_success_records = instance.query(
+ "SELECT user, client_port <> 0, client_address <> toIPv6('::') FROM system.session_log WHERE user='postgres_user' AND type = 'LoginSuccess'"
+ )
+ assert login_success_records == "postgres_user\t1\t1\n"
+ logout_records = instance.query(
+ "SELECT user, client_port <> 0, client_address <> toIPv6('::') FROM system.session_log WHERE user='postgres_user' AND type = 'Logout'"
+ )
+ assert logout_records == "postgres_user\t1\t1\n"
+ login_failure_records = instance.query(
+ "SELECT user, client_port <> 0, client_address <> toIPv6('::') FROM system.session_log WHERE user='postgres_user' AND type = 'LoginFailure'"
+ )
+ assert login_failure_records == "postgres_user\t1\t1\n"
+ logins_and_logouts = instance.query(
+ f"SELECT COUNT(*) FROM (SELECT {SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = 'postgres_user' AND type = 'LoginSuccess' INTERSECT SELECT {SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = 'postgres_user' AND type = 'Logout')"
+ )
+ assert logins_and_logouts == "1\n"
+
+
+def test_parallel_sessions(started_cluster):
+ thread_list = []
+ for _ in range(10):
+ # Sleep time does not significantly matter here,
+ # test should pass even without sleeping.
+ for function in [postgres_query, grpc_query, mysql_query]:
+ thread = threading.Thread(
+ target=function,
+ args=(
+ f"SELECT sleep({random.uniform(0.03, 0.04)})",
+ "parallel_user",
+ "pass",
+ False,
+ ),
+ )
+ thread.start()
+ thread_list.append(thread)
+ thread = threading.Thread(
+ target=function,
+ args=(
+ f"SELECT sleep({random.uniform(0.03, 0.04)})",
+ "parallel_user",
+ "wrong_pass",
+ True,
+ ),
+ )
+ thread.start()
+ thread_list.append(thread)
+ thread = threading.Thread(
+ target=function,
+ args=(
+ f"SELECT sleep({random.uniform(0.03, 0.04)})",
+ "wrong_parallel_user",
+ "pass",
+ True,
+ ),
+ )
+ thread.start()
+ thread_list.append(thread)
+
+ for thread in thread_list:
+ thread.join()
+
+ instance.query("SYSTEM FLUSH LOGS")
+ port_0_sessions = instance.query(
+ f"SELECT COUNT(*) FROM system.session_log WHERE user = 'parallel_user'"
+ )
+ assert port_0_sessions == "90\n"
+
+ port_0_sessions = instance.query(
+ f"SELECT COUNT(*) FROM system.session_log WHERE user = 'parallel_user' AND client_port = 0"
+ )
+ assert port_0_sessions == "0\n"
+
+ address_0_sessions = instance.query(
+ f"SELECT COUNT(*) FROM system.session_log WHERE user = 'parallel_user' AND client_address = toIPv6('::')"
+ )
+ assert address_0_sessions == "0\n"
+
+ grpc_sessions = instance.query(
+ f"SELECT COUNT(*) FROM system.session_log WHERE user = 'parallel_user' AND interface = 'gRPC'"
+ )
+ assert grpc_sessions == "30\n"
+
+ mysql_sessions = instance.query(
+ f"SELECT COUNT(*) FROM system.session_log WHERE user = 'parallel_user' AND interface = 'MySQL'"
+ )
+ assert mysql_sessions == "30\n"
+
+ postgres_sessions = instance.query(
+ f"SELECT COUNT(*) FROM system.session_log WHERE user = 'parallel_user' AND interface = 'PostgreSQL'"
+ )
+ assert postgres_sessions == "30\n"
+
+ logins_and_logouts = instance.query(
+ f"SELECT COUNT(*) FROM (SELECT {SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = 'parallel_user' AND type = 'LoginSuccess' INTERSECT SELECT {SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = 'parallel_user' AND type = 'Logout')"
+ )
+ assert logins_and_logouts == "30\n"
+
+ logout_failure_sessions = instance.query(
+ f"SELECT COUNT(*) FROM system.session_log WHERE user = 'parallel_user' AND type = 'LoginFailure'"
+ )
+ assert logout_failure_sessions == "30\n"
diff --git a/tests/performance/aggregate_with_serialized_method.xml b/tests/performance/aggregate_with_serialized_method.xml
new file mode 100644
index 000000000000..91763c69bb94
--- /dev/null
+++ b/tests/performance/aggregate_with_serialized_method.xml
@@ -0,0 +1,32 @@
+
+
+ 8
+ 0
+ 4
+
+
+
+ CREATE TABLE t_nullable
+ (
+ key_string1 Nullable(String),
+ key_string2 Nullable(String),
+ key_string3 Nullable(String),
+ key_int64_1 Nullable(Int64),
+ key_int64_2 Nullable(Int64),
+ key_int64_3 Nullable(Int64),
+ key_int64_4 Nullable(Int64),
+ key_int64_5 Nullable(Int64),
+ m1 Int64,
+ m2 Int64
+ )
+ ENGINE = Memory
+
+ insert into t_nullable select ['aaaaaa','bbaaaa','ccaaaa','ddaaaa'][number % 101 + 1], ['aa','bb','cc','dd'][number % 100 + 1], ['aa','bb','cc','dd'][number % 102 + 1], number%10+1, number%10+2, number%10+3, number%10+4,number%10+5, number%6000+1, number%5000+2 from numbers_mt(20000000)
+ select key_string1,key_string2,key_string3, min(m1) from t_nullable group by key_string1,key_string2,key_string3
+ select key_string3,key_int64_1,key_int64_2, min(m1) from t_nullable group by key_string3,key_int64_1,key_int64_2
+ select key_int64_1,key_int64_2,key_int64_3,key_int64_4,key_int64_5, min(m1) from t_nullable group by key_int64_1,key_int64_2,key_int64_3,key_int64_4,key_int64_5
+ select toFloat64(key_int64_1),toFloat64(key_int64_2),toFloat64(key_int64_3),toFloat64(key_int64_4),toFloat64(key_int64_5), min(m1) from t_nullable group by toFloat64(key_int64_1),toFloat64(key_int64_2),toFloat64(key_int64_3),toFloat64(key_int64_4),toFloat64(key_int64_5) limit 10
+ select toDecimal64(key_int64_1, 3),toDecimal64(key_int64_2, 3),toDecimal64(key_int64_3, 3),toDecimal64(key_int64_4, 3),toDecimal64(key_int64_5, 3), min(m1) from t_nullable group by toDecimal64(key_int64_1, 3),toDecimal64(key_int64_2, 3),toDecimal64(key_int64_3, 3),toDecimal64(key_int64_4, 3),toDecimal64(key_int64_5, 3) limit 10
+
+ drop table if exists t_nullable
+
\ No newline at end of file
diff --git a/tests/queries/0_stateless/00002_log_and_exception_messages_formatting.sql b/tests/queries/0_stateless/00002_log_and_exception_messages_formatting.sql
index eb8e9826eff8..c1acc763d6f6 100644
--- a/tests/queries/0_stateless/00002_log_and_exception_messages_formatting.sql
+++ b/tests/queries/0_stateless/00002_log_and_exception_messages_formatting.sql
@@ -9,10 +9,10 @@ create view logs as select * from system.text_log where now() - toIntervalMinute
-- Check that we don't have too many messages formatted with fmt::runtime or strings concatenation.
-- 0.001 threshold should be always enough, the value was about 0.00025
-select 'runtime messages', max2(coalesce(sum(length(message_format_string) = 0) / countOrNull(), 0), 0.001) from logs;
+select 'runtime messages', greatest(coalesce(sum(length(message_format_string) = 0) / countOrNull(), 0), 0.001) from logs;
-- Check the same for exceptions. The value was 0.03
-select 'runtime exceptions', max2(coalesce(sum(length(message_format_string) = 0) / countOrNull(), 0), 0.05) from logs where message like '%DB::Exception%';
+select 'runtime exceptions', greatest(coalesce(sum(length(message_format_string) = 0) / countOrNull(), 0), 0.05) from logs where message like '%DB::Exception%';
-- FIXME some of the following messages are not informative and it has to be fixed
create temporary table known_short_messages (s String) as select * from (select
@@ -36,7 +36,7 @@ create temporary table known_short_messages (s String) as select * from (select
'Database {} does not exist', 'Dictionary ({}) not found', 'Unknown table function {}',
'Unknown format {}', 'Unknown explain kind ''{}''', 'Unknown setting {}', 'Unknown input format {}',
'Unknown identifier: ''{}''', 'User name is empty', 'Expected function, got: {}',
-'Attempt to read after eof', 'String size is too big ({}), maximum: {}', 'API mode: {}',
+'Attempt to read after eof', 'String size is too big ({}), maximum: {}',
'Processed: {}%', 'Creating {}: {}', 'Table {}.{} doesn''t exist', 'Invalid cache key hex: {}',
'User has been dropped', 'Illegal type {} of argument of function {}. Should be DateTime or DateTime64'
] as arr) array join arr;
diff --git a/tests/queries/0_stateless/00284_external_aggregation.sql b/tests/queries/0_stateless/00284_external_aggregation.sql
index d19f9f5aee8f..c1140faaa282 100644
--- a/tests/queries/0_stateless/00284_external_aggregation.sql
+++ b/tests/queries/0_stateless/00284_external_aggregation.sql
@@ -13,13 +13,13 @@ SET group_by_two_level_threshold = 100000;
SET max_bytes_before_external_group_by = '1Mi';
-- method: key_string & key_string_two_level
-CREATE TABLE t_00284_str(s String) ENGINE = MergeTree() ORDER BY tuple();
+CREATE TABLE t_00284_str(s String) ENGINE = MergeTree() ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t_00284_str SELECT toString(number) FROM numbers_mt(1e6);
INSERT INTO t_00284_str SELECT toString(number) FROM numbers_mt(1e6);
SELECT s, count() FROM t_00284_str GROUP BY s ORDER BY s LIMIT 10 OFFSET 42;
-- method: low_cardinality_key_string & low_cardinality_key_string_two_level
-CREATE TABLE t_00284_lc_str(s LowCardinality(String)) ENGINE = MergeTree() ORDER BY tuple();
+CREATE TABLE t_00284_lc_str(s LowCardinality(String)) ENGINE = MergeTree() ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t_00284_lc_str SELECT toString(number) FROM numbers_mt(1e6);
INSERT INTO t_00284_lc_str SELECT toString(number) FROM numbers_mt(1e6);
SELECT s, count() FROM t_00284_lc_str GROUP BY s ORDER BY s LIMIT 10 OFFSET 42;
diff --git a/tests/queries/0_stateless/00522_multidimensional.sql b/tests/queries/0_stateless/00522_multidimensional.sql
index c3c41257ab93..ea9881c612af 100644
--- a/tests/queries/0_stateless/00522_multidimensional.sql
+++ b/tests/queries/0_stateless/00522_multidimensional.sql
@@ -1,5 +1,5 @@
DROP TABLE IF EXISTS multidimensional;
-CREATE TABLE multidimensional ENGINE = MergeTree ORDER BY number AS SELECT number, arrayMap(x -> (x, [x], [[x]], (x, toString(x))), arrayMap(x -> range(x), range(number % 10))) AS value FROM system.numbers LIMIT 100000;
+CREATE TABLE multidimensional ENGINE = MergeTree ORDER BY number SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi' AS SELECT number, arrayMap(x -> (x, [x], [[x]], (x, toString(x))), arrayMap(x -> range(x), range(number % 10))) AS value FROM system.numbers LIMIT 100000;
SELECT sum(cityHash64(toString(value))) FROM multidimensional;
diff --git a/tests/queries/0_stateless/00576_nested_and_prewhere.sql b/tests/queries/0_stateless/00576_nested_and_prewhere.sql
index b15af582a193..5916e679f1ed 100644
--- a/tests/queries/0_stateless/00576_nested_and_prewhere.sql
+++ b/tests/queries/0_stateless/00576_nested_and_prewhere.sql
@@ -1,6 +1,6 @@
DROP TABLE IF EXISTS nested;
-CREATE TABLE nested (x UInt64, filter UInt8, n Nested(a UInt64)) ENGINE = MergeTree ORDER BY x;
+CREATE TABLE nested (x UInt64, filter UInt8, n Nested(a UInt64)) ENGINE = MergeTree ORDER BY x SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO nested SELECT number, number % 2, range(number % 10) FROM system.numbers LIMIT 100000;
ALTER TABLE nested ADD COLUMN n.b Array(UInt64);
diff --git a/tests/queries/0_stateless/00612_count.sql b/tests/queries/0_stateless/00612_count.sql
index 5dd9c7707002..9c435bd97fe9 100644
--- a/tests/queries/0_stateless/00612_count.sql
+++ b/tests/queries/0_stateless/00612_count.sql
@@ -1,6 +1,6 @@
DROP TABLE IF EXISTS count;
-CREATE TABLE count (x UInt64) ENGINE = MergeTree ORDER BY tuple();
+CREATE TABLE count (x UInt64) ENGINE = MergeTree ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO count SELECT * FROM numbers(1234567);
SELECT count() FROM count;
diff --git a/tests/queries/0_stateless/00626_replace_partition_from_table_zookeeper.sh b/tests/queries/0_stateless/00626_replace_partition_from_table_zookeeper.sh
index c32b6d04a425..334025cba28d 100755
--- a/tests/queries/0_stateless/00626_replace_partition_from_table_zookeeper.sh
+++ b/tests/queries/0_stateless/00626_replace_partition_from_table_zookeeper.sh
@@ -11,26 +11,6 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
# shellcheck source=../shell_config.sh
. "$CURDIR"/../shell_config.sh
-function query_with_retry
-{
- local query="$1" && shift
-
- local retry=0
- until [ $retry -ge 5 ]
- do
- local result
- result="$($CLICKHOUSE_CLIENT "$@" --query="$query" 2>&1)"
- if [ "$?" == 0 ]; then
- echo -n "$result"
- return
- else
- retry=$((retry + 1))
- sleep 3
- fi
- done
- echo "Query '$query' failed with '$result'"
-}
-
$CLICKHOUSE_CLIENT --query="DROP TABLE IF EXISTS src;"
$CLICKHOUSE_CLIENT --query="DROP TABLE IF EXISTS dst_r1;"
$CLICKHOUSE_CLIENT --query="DROP TABLE IF EXISTS dst_r2;"
diff --git a/tests/queries/0_stateless/00688_low_cardinality_dictionary_deserialization.sql b/tests/queries/0_stateless/00688_low_cardinality_dictionary_deserialization.sql
index 5a1694038725..c4613acf5f31 100644
--- a/tests/queries/0_stateless/00688_low_cardinality_dictionary_deserialization.sql
+++ b/tests/queries/0_stateless/00688_low_cardinality_dictionary_deserialization.sql
@@ -1,6 +1,5 @@
drop table if exists lc_dict_reading;
-create table lc_dict_reading (val UInt64, str StringWithDictionary, pat String) engine = MergeTree order by val;
+create table lc_dict_reading (val UInt64, str StringWithDictionary, pat String) engine = MergeTree order by val SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into lc_dict_reading select number, if(number < 8192 * 4, number % 100, number) as s, s from system.numbers limit 1000000;
select sum(toUInt64(str)), sum(toUInt64(pat)) from lc_dict_reading where val < 8129 or val > 8192 * 4;
drop table if exists lc_dict_reading;
-
diff --git a/tests/queries/0_stateless/00688_low_cardinality_serialization.sql b/tests/queries/0_stateless/00688_low_cardinality_serialization.sql
index 3c0e64a96377..b4fe4b292004 100644
--- a/tests/queries/0_stateless/00688_low_cardinality_serialization.sql
+++ b/tests/queries/0_stateless/00688_low_cardinality_serialization.sql
@@ -8,8 +8,8 @@ select 'MergeTree';
drop table if exists lc_small_dict;
drop table if exists lc_big_dict;
-create table lc_small_dict (str StringWithDictionary) engine = MergeTree order by str;
-create table lc_big_dict (str StringWithDictionary) engine = MergeTree order by str;
+create table lc_small_dict (str StringWithDictionary) engine = MergeTree order by str SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
+create table lc_big_dict (str StringWithDictionary) engine = MergeTree order by str SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into lc_small_dict select toString(number % 1000) from system.numbers limit 1000000;
insert into lc_big_dict select toString(number) from system.numbers limit 1000000;
@@ -25,4 +25,3 @@ select sum(toUInt64OrZero(str)) from lc_big_dict;
drop table if exists lc_small_dict;
drop table if exists lc_big_dict;
-
diff --git a/tests/queries/0_stateless/00738_lock_for_inner_table.sh b/tests/queries/0_stateless/00738_lock_for_inner_table.sh
index 9a7ae92439df..b62a639d8f4b 100755
--- a/tests/queries/0_stateless/00738_lock_for_inner_table.sh
+++ b/tests/queries/0_stateless/00738_lock_for_inner_table.sh
@@ -13,7 +13,7 @@ uuid=$(${CLICKHOUSE_CLIENT} --query "SELECT reinterpretAsUUID(currentDatabase())
echo "DROP TABLE IF EXISTS tab_00738 SYNC;
DROP TABLE IF EXISTS mv SYNC;
-CREATE TABLE tab_00738(a Int) ENGINE = MergeTree() ORDER BY a;
+CREATE TABLE tab_00738(a Int) ENGINE = MergeTree() ORDER BY a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
-- The matview will take at least 2 seconds to be finished (10000000 * 0.0000002)
CREATE MATERIALIZED VIEW mv UUID '$uuid' ENGINE = Log AS SELECT sleepEachRow(0.0000002) FROM tab_00738;" | ${CLICKHOUSE_CLIENT} -n
@@ -63,4 +63,3 @@ drop_inner_id
wait
drop_at_exit
-
diff --git a/tests/queries/0_stateless/00933_ttl_replicated_zookeeper.sh b/tests/queries/0_stateless/00933_ttl_replicated_zookeeper.sh
index 22d9e0690b39..d06037fb8367 100755
--- a/tests/queries/0_stateless/00933_ttl_replicated_zookeeper.sh
+++ b/tests/queries/0_stateless/00933_ttl_replicated_zookeeper.sh
@@ -5,22 +5,6 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
# shellcheck source=../shell_config.sh
. "$CURDIR"/../shell_config.sh
-function query_with_retry
-{
- retry=0
- until [ $retry -ge 5 ]
- do
- result=$($CLICKHOUSE_CLIENT $2 --query="$1" 2>&1)
- if [ "$?" == 0 ]; then
- echo -n "$result"
- return
- else
- retry=$(($retry + 1))
- sleep 3
- fi
- done
- echo "Query '$1' failed with '$result'"
-}
$CLICKHOUSE_CLIENT --query="DROP TABLE IF EXISTS ttl_repl1"
$CLICKHOUSE_CLIENT --query="DROP TABLE IF EXISTS ttl_repl2"
diff --git a/tests/queries/0_stateless/00975_move_partition_merge_tree.sql b/tests/queries/0_stateless/00975_move_partition_merge_tree.sql
index 2fc82b964030..c17f7c57de08 100644
--- a/tests/queries/0_stateless/00975_move_partition_merge_tree.sql
+++ b/tests/queries/0_stateless/00975_move_partition_merge_tree.sql
@@ -6,14 +6,14 @@ CREATE TABLE IF NOT EXISTS test_move_partition_src (
val UInt32
) Engine = MergeTree()
PARTITION BY pk
- ORDER BY (pk, val);
+ ORDER BY (pk, val) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
CREATE TABLE IF NOT EXISTS test_move_partition_dest (
pk UInt8,
val UInt32
) Engine = MergeTree()
PARTITION BY pk
- ORDER BY (pk, val);
+ ORDER BY (pk, val) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO test_move_partition_src SELECT number % 2, number FROM system.numbers LIMIT 10000000;
diff --git a/tests/queries/0_stateless/00981_topK_topKWeighted_long.sql b/tests/queries/0_stateless/00981_topK_topKWeighted_long.sql
index 48d9dedc61c8..7ee38867b538 100644
--- a/tests/queries/0_stateless/00981_topK_topKWeighted_long.sql
+++ b/tests/queries/0_stateless/00981_topK_topKWeighted_long.sql
@@ -2,7 +2,7 @@
DROP TABLE IF EXISTS topk;
-CREATE TABLE topk (val1 String, val2 UInt32) ENGINE = MergeTree ORDER BY val1;
+CREATE TABLE topk (val1 String, val2 UInt32) ENGINE = MergeTree ORDER BY val1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO topk WITH number % 7 = 0 AS frequent SELECT toString(frequent ? number % 10 : number), frequent ? 999999999 : number FROM numbers(4000000);
diff --git a/tests/queries/0_stateless/00993_system_parts_race_condition_drop_zookeeper.sh b/tests/queries/0_stateless/00993_system_parts_race_condition_drop_zookeeper.sh
index 4205f231698b..6025279e5703 100755
--- a/tests/queries/0_stateless/00993_system_parts_race_condition_drop_zookeeper.sh
+++ b/tests/queries/0_stateless/00993_system_parts_race_condition_drop_zookeeper.sh
@@ -59,7 +59,8 @@ function thread6()
CREATE TABLE alter_table_$REPLICA (a UInt8, b Int16, c Float32, d String, e Array(UInt8), f Nullable(UUID), g Tuple(UInt8, UInt16))
ENGINE = ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/alter_table', 'r_$REPLICA') ORDER BY a PARTITION BY b % 10
SETTINGS old_parts_lifetime = 1, cleanup_delay_period = 0, cleanup_delay_period_random_add = 0,
- cleanup_thread_preferred_points_per_iteration=0, replicated_max_mutations_in_one_entry = $(($RANDOM / 50));";
+ cleanup_thread_preferred_points_per_iteration=0, replicated_max_mutations_in_one_entry = $(($RANDOM / 50)),
+ index_granularity = 8192, index_granularity_bytes = '10Mi';";
sleep 0.$RANDOM;
done
}
diff --git a/tests/queries/0_stateless/01034_move_partition_from_table_zookeeper.sh b/tests/queries/0_stateless/01034_move_partition_from_table_zookeeper.sh
index e0a84323dbd6..39c5742e7a72 100755
--- a/tests/queries/0_stateless/01034_move_partition_from_table_zookeeper.sh
+++ b/tests/queries/0_stateless/01034_move_partition_from_table_zookeeper.sh
@@ -7,23 +7,6 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
# shellcheck source=../shell_config.sh
. "$CURDIR"/../shell_config.sh
-function query_with_retry
-{
- retry=0
- until [ $retry -ge 5 ]
- do
- result=$($CLICKHOUSE_CLIENT $2 --query="$1" 2>&1)
- if [ "$?" == 0 ]; then
- echo -n "$result"
- return
- else
- retry=$(($retry + 1))
- sleep 3
- fi
- done
- echo "Query '$1' failed with '$result'"
-}
-
$CLICKHOUSE_CLIENT --query="DROP TABLE IF EXISTS src;"
$CLICKHOUSE_CLIENT --query="DROP TABLE IF EXISTS dst;"
diff --git a/tests/queries/0_stateless/01034_sample_final_distributed.sql b/tests/queries/0_stateless/01034_sample_final_distributed.sql
index a81fef645dbd..64bafd17b2d9 100644
--- a/tests/queries/0_stateless/01034_sample_final_distributed.sql
+++ b/tests/queries/0_stateless/01034_sample_final_distributed.sql
@@ -3,7 +3,7 @@
set allow_experimental_parallel_reading_from_replicas = 0;
drop table if exists sample_final;
-create table sample_final (CounterID UInt32, EventDate Date, EventTime DateTime, UserID UInt64, Sign Int8) engine = CollapsingMergeTree(Sign) order by (CounterID, EventDate, intHash32(UserID), EventTime) sample by intHash32(UserID);
+create table sample_final (CounterID UInt32, EventDate Date, EventTime DateTime, UserID UInt64, Sign Int8) engine = CollapsingMergeTree(Sign) order by (CounterID, EventDate, intHash32(UserID), EventTime) sample by intHash32(UserID) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into sample_final select number / (8192 * 4), toDate('2019-01-01'), toDateTime('2019-01-01 00:00:01') + number, number / (8192 * 2), number % 3 = 1 ? -1 : 1 from numbers(1000000);
select 'count';
diff --git a/tests/queries/0_stateless/01035_avg.sql b/tests/queries/0_stateless/01035_avg.sql
index d683ada0aec1..a3cb35a80ec1 100644
--- a/tests/queries/0_stateless/01035_avg.sql
+++ b/tests/queries/0_stateless/01035_avg.sql
@@ -22,7 +22,7 @@ CREATE TABLE IF NOT EXISTS test_01035_avg (
d64 Decimal64(18) DEFAULT toDecimal64(u64 / 1000000, 8),
d128 Decimal128(20) DEFAULT toDecimal128(i128 / 100000, 20),
d256 Decimal256(40) DEFAULT toDecimal256(i256 / 100000, 40)
-) ENGINE = MergeTree() ORDER BY i64;
+) ENGINE = MergeTree() ORDER BY i64 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
SELECT avg(i8), avg(i16), avg(i32), avg(i64), avg(i128), avg(i256),
avg(u8), avg(u16), avg(u32), avg(u64), avg(u128), avg(u256),
diff --git a/tests/queries/0_stateless/01045_zookeeper_system_mutations_with_parts_names.sh b/tests/queries/0_stateless/01045_zookeeper_system_mutations_with_parts_names.sh
index 68c511b80acd..cd6501bbebff 100755
--- a/tests/queries/0_stateless/01045_zookeeper_system_mutations_with_parts_names.sh
+++ b/tests/queries/0_stateless/01045_zookeeper_system_mutations_with_parts_names.sh
@@ -21,7 +21,7 @@ function wait_mutation_to_start()
${CLICKHOUSE_CLIENT} --query="DROP TABLE IF EXISTS table_for_mutations"
-${CLICKHOUSE_CLIENT} --query="CREATE TABLE table_for_mutations(k UInt32, v1 UInt64) ENGINE MergeTree ORDER BY k PARTITION BY modulo(k, 2)"
+${CLICKHOUSE_CLIENT} --query="CREATE TABLE table_for_mutations(k UInt32, v1 UInt64) ENGINE MergeTree ORDER BY k PARTITION BY modulo(k, 2) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'"
${CLICKHOUSE_CLIENT} --query="SYSTEM STOP MERGES table_for_mutations"
@@ -48,7 +48,7 @@ ${CLICKHOUSE_CLIENT} --query="DROP TABLE IF EXISTS table_for_mutations"
${CLICKHOUSE_CLIENT} --query="DROP TABLE IF EXISTS replicated_table_for_mutations"
-${CLICKHOUSE_CLIENT} --query="CREATE TABLE replicated_table_for_mutations(k UInt32, v1 UInt64) ENGINE ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/replicated_table_for_mutations', '1') ORDER BY k PARTITION BY modulo(k, 2)"
+${CLICKHOUSE_CLIENT} --query="CREATE TABLE replicated_table_for_mutations(k UInt32, v1 UInt64) ENGINE ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/replicated_table_for_mutations', '1') ORDER BY k PARTITION BY modulo(k, 2) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'"
${CLICKHOUSE_CLIENT} --query="SYSTEM STOP MERGES replicated_table_for_mutations"
diff --git a/tests/queries/0_stateless/01049_zookeeper_synchronous_mutations_long.sql b/tests/queries/0_stateless/01049_zookeeper_synchronous_mutations_long.sql
index c77ab50ab8bd..2458fe14981f 100644
--- a/tests/queries/0_stateless/01049_zookeeper_synchronous_mutations_long.sql
+++ b/tests/queries/0_stateless/01049_zookeeper_synchronous_mutations_long.sql
@@ -5,9 +5,9 @@ DROP TABLE IF EXISTS table_for_synchronous_mutations2;
SELECT 'Replicated';
-CREATE TABLE table_for_synchronous_mutations1(k UInt32, v1 UInt64) ENGINE ReplicatedMergeTree('/clickhouse/tables/{database}/test_01049/table_for_synchronous_mutations', '1') ORDER BY k;
+CREATE TABLE table_for_synchronous_mutations1(k UInt32, v1 UInt64) ENGINE ReplicatedMergeTree('/clickhouse/tables/{database}/test_01049/table_for_synchronous_mutations', '1') ORDER BY k SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
-CREATE TABLE table_for_synchronous_mutations2(k UInt32, v1 UInt64) ENGINE ReplicatedMergeTree('/clickhouse/tables/{database}/test_01049/table_for_synchronous_mutations', '2') ORDER BY k;
+CREATE TABLE table_for_synchronous_mutations2(k UInt32, v1 UInt64) ENGINE ReplicatedMergeTree('/clickhouse/tables/{database}/test_01049/table_for_synchronous_mutations', '2') ORDER BY k SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO table_for_synchronous_mutations1 select number, number from numbers(100000);
@@ -29,7 +29,7 @@ SELECT 'Normal';
DROP TABLE IF EXISTS table_for_synchronous_mutations_no_replication;
-CREATE TABLE table_for_synchronous_mutations_no_replication(k UInt32, v1 UInt64) ENGINE MergeTree ORDER BY k;
+CREATE TABLE table_for_synchronous_mutations_no_replication(k UInt32, v1 UInt64) ENGINE MergeTree ORDER BY k SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO table_for_synchronous_mutations_no_replication select number, number from numbers(100000);
diff --git a/tests/queries/0_stateless/01060_shutdown_table_after_detach.sql b/tests/queries/0_stateless/01060_shutdown_table_after_detach.sql
index bfe928d70033..7a853f32d0fa 100644
--- a/tests/queries/0_stateless/01060_shutdown_table_after_detach.sql
+++ b/tests/queries/0_stateless/01060_shutdown_table_after_detach.sql
@@ -1,7 +1,7 @@
-- Tags: no-parallel
DROP TABLE IF EXISTS test;
-CREATE TABLE test Engine = MergeTree ORDER BY number AS SELECT number, toString(rand()) x from numbers(10000000);
+CREATE TABLE test Engine = MergeTree ORDER BY number SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi' AS SELECT number, toString(rand()) x from numbers(10000000);
SELECT count() FROM test;
diff --git a/tests/queries/0_stateless/01077_mutations_index_consistency.sh b/tests/queries/0_stateless/01077_mutations_index_consistency.sh
index c41eab62ecb0..ffbe3692b649 100755
--- a/tests/queries/0_stateless/01077_mutations_index_consistency.sh
+++ b/tests/queries/0_stateless/01077_mutations_index_consistency.sh
@@ -7,7 +7,7 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
$CLICKHOUSE_CLIENT --query "DROP TABLE IF EXISTS movement"
-$CLICKHOUSE_CLIENT -n --query "CREATE TABLE movement (date DateTime('Asia/Istanbul')) Engine = MergeTree ORDER BY (toStartOfHour(date));"
+$CLICKHOUSE_CLIENT -n --query "CREATE TABLE movement (date DateTime('Asia/Istanbul')) Engine = MergeTree ORDER BY (toStartOfHour(date)) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';"
$CLICKHOUSE_CLIENT --query "insert into movement select toDateTime('2020-01-22 00:00:00', 'Asia/Istanbul') + number%(23*3600) from numbers(1000000);"
diff --git a/tests/queries/0_stateless/01079_order_by_pk.sql b/tests/queries/0_stateless/01079_order_by_pk.sql
index 78e304b3118b..0b442bf78c9b 100644
--- a/tests/queries/0_stateless/01079_order_by_pk.sql
+++ b/tests/queries/0_stateless/01079_order_by_pk.sql
@@ -1,6 +1,6 @@
DROP TABLE IF EXISTS mt_pk;
-CREATE TABLE mt_pk ENGINE = MergeTree PARTITION BY d ORDER BY x
+CREATE TABLE mt_pk ENGINE = MergeTree PARTITION BY d ORDER BY x SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'
AS SELECT toDate(number % 32) AS d, number AS x FROM system.numbers LIMIT 10000010;
SELECT x FROM mt_pk ORDER BY x ASC LIMIT 10000000, 1;
diff --git a/tests/queries/0_stateless/01079_parallel_alter_add_drop_column_zookeeper.sh b/tests/queries/0_stateless/01079_parallel_alter_add_drop_column_zookeeper.sh
index 26c2bf133ace..bfdea95fa9e4 100755
--- a/tests/queries/0_stateless/01079_parallel_alter_add_drop_column_zookeeper.sh
+++ b/tests/queries/0_stateless/01079_parallel_alter_add_drop_column_zookeeper.sh
@@ -15,7 +15,7 @@ done
for i in $(seq $REPLICAS); do
- $CLICKHOUSE_CLIENT --query "CREATE TABLE concurrent_alter_add_drop_$i (key UInt64, value0 UInt8) ENGINE = ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/concurrent_alter_add_drop_column', '$i') ORDER BY key SETTINGS max_replicated_mutations_in_queue=1000, number_of_free_entries_in_pool_to_execute_mutation=0,max_replicated_merges_in_queue=1000"
+ $CLICKHOUSE_CLIENT --query "CREATE TABLE concurrent_alter_add_drop_$i (key UInt64, value0 UInt8) ENGINE = ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/concurrent_alter_add_drop_column', '$i') ORDER BY key SETTINGS max_replicated_mutations_in_queue = 1000, number_of_free_entries_in_pool_to_execute_mutation = 0, max_replicated_merges_in_queue = 1000, index_granularity = 8192, index_granularity_bytes = '10Mi'"
done
$CLICKHOUSE_CLIENT --query "INSERT INTO concurrent_alter_add_drop_1 SELECT number, number + 10 from numbers(100000)"
diff --git a/tests/queries/0_stateless/01137_order_by_func.sql b/tests/queries/0_stateless/01137_order_by_func.sql
index 682b2d391cee..536f2d1c61dc 100644
--- a/tests/queries/0_stateless/01137_order_by_func.sql
+++ b/tests/queries/0_stateless/01137_order_by_func.sql
@@ -1,5 +1,5 @@
DROP TABLE IF EXISTS pk_func;
-CREATE TABLE pk_func(d DateTime, ui UInt32) ENGINE = MergeTree ORDER BY toDate(d);
+CREATE TABLE pk_func(d DateTime, ui UInt32) ENGINE = MergeTree ORDER BY toDate(d) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO pk_func SELECT '2020-05-05 01:00:00', number FROM numbers(1000000);
INSERT INTO pk_func SELECT '2020-05-06 01:00:00', number FROM numbers(1000000);
@@ -10,7 +10,7 @@ SELECT * FROM pk_func ORDER BY toDate(d), ui LIMIT 5;
DROP TABLE pk_func;
DROP TABLE IF EXISTS nORX;
-CREATE TABLE nORX (`A` Int64, `B` Int64, `V` Int64) ENGINE = MergeTree ORDER BY (A, negate(B));
+CREATE TABLE nORX (`A` Int64, `B` Int64, `V` Int64) ENGINE = MergeTree ORDER BY (A, negate(B)) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO nORX SELECT 111, number, number FROM numbers(10000000);
SELECT *
diff --git a/tests/queries/0_stateless/01184_long_insert_values_huge_strings.sh b/tests/queries/0_stateless/01184_long_insert_values_huge_strings.sh
index 09a43d13a428..5e115e6b3af8 100755
--- a/tests/queries/0_stateless/01184_long_insert_values_huge_strings.sh
+++ b/tests/queries/0_stateless/01184_long_insert_values_huge_strings.sh
@@ -6,7 +6,7 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
. "$CURDIR"/../shell_config.sh
$CLICKHOUSE_CLIENT -q "drop table if exists huge_strings"
-$CLICKHOUSE_CLIENT -q "create table huge_strings (n UInt64, l UInt64, s String, h UInt64) engine=MergeTree order by n"
+$CLICKHOUSE_CLIENT -q "create table huge_strings (n UInt64, l UInt64, s String, h UInt64) engine=MergeTree order by n SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'"
# Timeouts are increased, because test can be slow with sanitizers and parallel runs.
diff --git a/tests/queries/0_stateless/01231_operator_null_in.sql b/tests/queries/0_stateless/01231_operator_null_in.sql
index 27ab0bbd8389..0424a995b3f0 100644
--- a/tests/queries/0_stateless/01231_operator_null_in.sql
+++ b/tests/queries/0_stateless/01231_operator_null_in.sql
@@ -1,5 +1,5 @@
DROP TABLE IF EXISTS null_in;
-CREATE TABLE null_in (dt DateTime, idx int, i Nullable(int), s Nullable(String)) ENGINE = MergeTree() PARTITION BY dt ORDER BY idx;
+CREATE TABLE null_in (dt DateTime, idx int, i Nullable(int), s Nullable(String)) ENGINE = MergeTree() PARTITION BY dt ORDER BY idx SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO null_in VALUES (1, 1, 1, '1') (2, 2, NULL, NULL) (3, 3, 3, '3') (4, 4, NULL, NULL) (5, 5, 5, '5');
@@ -81,7 +81,7 @@ DROP TABLE IF EXISTS null_in;
DROP TABLE IF EXISTS null_in_subquery;
-CREATE TABLE null_in_subquery (dt DateTime, idx int, i Nullable(UInt64)) ENGINE = MergeTree() PARTITION BY dt ORDER BY idx;
+CREATE TABLE null_in_subquery (dt DateTime, idx int, i Nullable(UInt64)) ENGINE = MergeTree() PARTITION BY dt ORDER BY idx SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO null_in_subquery SELECT number % 3, number, number FROM system.numbers LIMIT 99999;
SELECT count() == 33333 FROM null_in_subquery WHERE i in (SELECT i FROM null_in_subquery WHERE dt = 0);
@@ -111,7 +111,7 @@ DROP TABLE IF EXISTS null_in_subquery;
DROP TABLE IF EXISTS null_in_tuple;
-CREATE TABLE null_in_tuple (dt DateTime, idx int, t Tuple(Nullable(UInt64), Nullable(String))) ENGINE = MergeTree() PARTITION BY dt ORDER BY idx;
+CREATE TABLE null_in_tuple (dt DateTime, idx int, t Tuple(Nullable(UInt64), Nullable(String))) ENGINE = MergeTree() PARTITION BY dt ORDER BY idx SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO null_in_tuple VALUES (1, 1, (1, '1')) (2, 2, (2, NULL)) (3, 3, (NULL, '3')) (4, 4, (NULL, NULL))
SET transform_null_in = 0;
diff --git a/tests/queries/0_stateless/01289_min_execution_speed_not_too_early.sql b/tests/queries/0_stateless/01289_min_execution_speed_not_too_early.sql
index 222a85094d0c..1abe9bf8cd83 100644
--- a/tests/queries/0_stateless/01289_min_execution_speed_not_too_early.sql
+++ b/tests/queries/0_stateless/01289_min_execution_speed_not_too_early.sql
@@ -1,6 +1,6 @@
DROP TABLE IF EXISTS ES;
-create table ES(A String) Engine=MergeTree order by tuple();
+create table ES(A String) Engine=MergeTree order by tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into ES select toString(number) from numbers(10000000);
SET max_execution_time = 100,
diff --git a/tests/queries/0_stateless/01373_summing_merge_tree_exclude_partition_key.sql b/tests/queries/0_stateless/01373_summing_merge_tree_exclude_partition_key.sql
index c5a874efe09d..f1e1ab7c70f7 100644
--- a/tests/queries/0_stateless/01373_summing_merge_tree_exclude_partition_key.sql
+++ b/tests/queries/0_stateless/01373_summing_merge_tree_exclude_partition_key.sql
@@ -4,7 +4,7 @@ DROP TABLE IF EXISTS tt_01373;
CREATE TABLE tt_01373
(a Int64, d Int64, val Int64)
-ENGINE = SummingMergeTree PARTITION BY (a) ORDER BY (d);
+ENGINE = SummingMergeTree PARTITION BY (a) ORDER BY (d) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
SYSTEM STOP MERGES tt_01373;
diff --git a/tests/queries/0_stateless/01441_low_cardinality_array_index.sql b/tests/queries/0_stateless/01441_low_cardinality_array_index.sql
index 8febe8f2e446..4b31a86edfbc 100644
--- a/tests/queries/0_stateless/01441_low_cardinality_array_index.sql
+++ b/tests/queries/0_stateless/01441_low_cardinality_array_index.sql
@@ -4,7 +4,7 @@ CREATE TABLE t_01411(
str LowCardinality(String),
arr Array(LowCardinality(String)) default [str]
) ENGINE = MergeTree()
-ORDER BY tuple();
+ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t_01411 (str) SELECT concat('asdf', toString(number % 10000)) FROM numbers(1000000);
@@ -24,7 +24,7 @@ CREATE TABLE t_01411_num(
num UInt8,
arr Array(LowCardinality(Int64)) default [num]
) ENGINE = MergeTree()
-ORDER BY tuple();
+ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t_01411_num (num) SELECT number % 1000 FROM numbers(1000000);
diff --git a/tests/queries/0_stateless/01524_do_not_merge_across_partitions_select_final.sql b/tests/queries/0_stateless/01524_do_not_merge_across_partitions_select_final.sql
index e3bc8cf6e729..3ce1c3aa1319 100644
--- a/tests/queries/0_stateless/01524_do_not_merge_across_partitions_select_final.sql
+++ b/tests/queries/0_stateless/01524_do_not_merge_across_partitions_select_final.sql
@@ -4,7 +4,7 @@ SET allow_asynchronous_read_from_io_pool_for_merge_tree = 0;
SET do_not_merge_across_partitions_select_final = 1;
SET max_threads = 16;
-CREATE TABLE select_final (t DateTime, x Int32, string String) ENGINE = ReplacingMergeTree() PARTITION BY toYYYYMM(t) ORDER BY (x, t);
+CREATE TABLE select_final (t DateTime, x Int32, string String) ENGINE = ReplacingMergeTree() PARTITION BY toYYYYMM(t) ORDER BY (x, t) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO select_final SELECT toDate('2000-01-01'), number, '' FROM numbers(2);
INSERT INTO select_final SELECT toDate('2000-01-01'), number + 1, '' FROM numbers(2);
diff --git a/tests/queries/0_stateless/01550_create_map_type.sql b/tests/queries/0_stateless/01550_create_map_type.sql
index 26bbf3c7ddea..92362f5596bf 100644
--- a/tests/queries/0_stateless/01550_create_map_type.sql
+++ b/tests/queries/0_stateless/01550_create_map_type.sql
@@ -9,14 +9,14 @@ drop table if exists table_map;
drop table if exists table_map;
-create table table_map (a Map(String, UInt64)) engine = MergeTree() order by a;
+create table table_map (a Map(String, UInt64)) engine = MergeTree() order by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into table_map select map('key1', number, 'key2', number * 2) from numbers(1111, 3);
select a['key1'], a['key2'] from table_map;
drop table if exists table_map;
-- MergeTree Engine
drop table if exists table_map;
-create table table_map (a Map(String, String), b String) engine = MergeTree() order by a;
+create table table_map (a Map(String, String), b String) engine = MergeTree() order by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into table_map values ({'name':'zhangsan', 'gender':'male'}, 'name'), ({'name':'lisi', 'gender':'female'}, 'gender');
select a[b] from table_map;
select b from table_map where a = map('name','lisi', 'gender', 'female');
@@ -24,21 +24,21 @@ drop table if exists table_map;
-- Big Integer type
-create table table_map (d DATE, m Map(Int8, UInt256)) ENGINE = MergeTree() order by d;
+create table table_map (d DATE, m Map(Int8, UInt256)) ENGINE = MergeTree() order by d SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into table_map values ('2020-01-01', map(1, 0, 2, 1));
select * from table_map;
drop table table_map;
-- Integer type
-create table table_map (d DATE, m Map(Int8, Int8)) ENGINE = MergeTree() order by d;
+create table table_map (d DATE, m Map(Int8, Int8)) ENGINE = MergeTree() order by d SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into table_map values ('2020-01-01', map(1, 0, 2, -1));
select * from table_map;
drop table table_map;
-- Unsigned Int type
drop table if exists table_map;
-create table table_map(a Map(UInt8, UInt64), b UInt8) Engine = MergeTree() order by b;
+create table table_map(a Map(UInt8, UInt64), b UInt8) Engine = MergeTree() order by b SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into table_map select map(number, number+5), number from numbers(1111,4);
select a[b] from table_map;
drop table if exists table_map;
@@ -46,7 +46,7 @@ drop table if exists table_map;
-- Array Type
drop table if exists table_map;
-create table table_map(a Map(String, Array(UInt8))) Engine = MergeTree() order by a;
+create table table_map(a Map(String, Array(UInt8))) Engine = MergeTree() order by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into table_map values(map('k1', [1,2,3], 'k2', [4,5,6])), (map('k0', [], 'k1', [100,20,90]));
insert into table_map select map('k1', [number, number + 2, number * 2]) from numbers(6);
insert into table_map select map('k2', [number, number + 2, number * 2]) from numbers(6);
@@ -56,7 +56,7 @@ drop table if exists table_map;
SELECT CAST(([1, 2, 3], ['1', '2', 'foo']), 'Map(UInt8, String)') AS map, map[1];
CREATE TABLE table_map (n UInt32, m Map(String, Int))
-ENGINE = MergeTree ORDER BY n SETTINGS min_bytes_for_wide_part = 0;
+ENGINE = MergeTree ORDER BY n SETTINGS min_bytes_for_wide_part = 0, index_granularity = 8192, index_granularity_bytes = '10Mi';
-- coversion from Tuple(Array(K), Array(V))
INSERT INTO table_map SELECT number, (arrayMap(x -> toString(x), range(number % 10 + 2)), range(number % 10 + 2)) FROM numbers(100000);
@@ -67,7 +67,7 @@ SELECT sum(m['1']), sum(m['7']), sum(m['100']) FROM table_map;
DROP TABLE IF EXISTS table_map;
CREATE TABLE table_map (n UInt32, m Map(String, Int))
-ENGINE = MergeTree ORDER BY n;
+ENGINE = MergeTree ORDER BY n SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
-- coversion from Tuple(Array(K), Array(V))
INSERT INTO table_map SELECT number, (arrayMap(x -> toString(x), range(number % 10 + 2)), range(number % 10 + 2)) FROM numbers(100000);
diff --git a/tests/queries/0_stateless/01592_long_window_functions1.sql b/tests/queries/0_stateless/01592_long_window_functions1.sql
index 4911b7aa792b..c63c651fb0b8 100644
--- a/tests/queries/0_stateless/01592_long_window_functions1.sql
+++ b/tests/queries/0_stateless/01592_long_window_functions1.sql
@@ -7,7 +7,7 @@ set max_insert_threads = 4;
create table stack(item_id Int64, brand_id Int64, rack_id Int64, dt DateTime, expiration_dt DateTime, quantity UInt64)
Engine = MergeTree
partition by toYYYYMM(dt)
-order by (brand_id, toStartOfHour(dt));
+order by (brand_id, toStartOfHour(dt)) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into stack
select number%99991, number%11, number%1111, toDateTime('2020-01-01 00:00:00')+number/100,
diff --git a/tests/queries/0_stateless/01600_parts_types_metrics_long.sh b/tests/queries/0_stateless/01600_parts_types_metrics_long.sh
index 5f724e810422..6bc22f2e7942 100755
--- a/tests/queries/0_stateless/01600_parts_types_metrics_long.sh
+++ b/tests/queries/0_stateless/01600_parts_types_metrics_long.sh
@@ -35,7 +35,7 @@ $CLICKHOUSE_CLIENT --database_atomic_wait_for_drop_and_detach_synchronously=1 --
# InMemory - [0..5]
# Compact - (5..10]
# Wide - >10
-$CLICKHOUSE_CLIENT --query="CREATE TABLE data_01600 (part_type String, key Int) ENGINE = MergeTree PARTITION BY part_type ORDER BY key SETTINGS min_bytes_for_wide_part=0, min_rows_for_wide_part=10"
+$CLICKHOUSE_CLIENT --query="CREATE TABLE data_01600 (part_type String, key Int) ENGINE = MergeTree PARTITION BY part_type ORDER BY key SETTINGS min_bytes_for_wide_part=0, min_rows_for_wide_part=10, index_granularity = 8192, index_granularity_bytes = '10Mi'"
# InMemory
$CLICKHOUSE_CLIENT --query="INSERT INTO data_01600 SELECT 'InMemory', number FROM system.numbers LIMIT 1"
diff --git a/tests/queries/0_stateless/01603_read_with_backoff_bug.sql b/tests/queries/0_stateless/01603_read_with_backoff_bug.sql
index 569a92f3048d..1cf52c0288b1 100644
--- a/tests/queries/0_stateless/01603_read_with_backoff_bug.sql
+++ b/tests/queries/0_stateless/01603_read_with_backoff_bug.sql
@@ -5,7 +5,7 @@ set enable_filesystem_cache=0;
set enable_filesystem_cache_on_write_operations=0;
drop table if exists t;
-create table t (x UInt64, s String) engine = MergeTree order by x;
+create table t (x UInt64, s String) engine = MergeTree order by x SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t SELECT
number,
if(number < (8129 * 1024), arrayStringConcat(arrayMap(x -> toString(x), range(number % 128)), ' '), '')
diff --git a/tests/queries/0_stateless/01606_merge_from_wide_to_compact.sql b/tests/queries/0_stateless/01606_merge_from_wide_to_compact.sql
index 0f2fbcaa76d9..de3b79eec767 100644
--- a/tests/queries/0_stateless/01606_merge_from_wide_to_compact.sql
+++ b/tests/queries/0_stateless/01606_merge_from_wide_to_compact.sql
@@ -5,7 +5,8 @@ CREATE TABLE wide_to_comp (a Int, b Int, c Int)
settings vertical_merge_algorithm_min_rows_to_activate = 1,
vertical_merge_algorithm_min_columns_to_activate = 1,
min_bytes_for_wide_part = 0,
- min_rows_for_wide_part = 0;
+ min_rows_for_wide_part = 0,
+ index_granularity = 8192, index_granularity_bytes = '10Mi';
SYSTEM STOP merges wide_to_comp;
diff --git a/tests/queries/0_stateless/01739_index_hint.reference b/tests/queries/0_stateless/01739_index_hint.reference
index 766dff8c7b02..21673bf698bc 100644
--- a/tests/queries/0_stateless/01739_index_hint.reference
+++ b/tests/queries/0_stateless/01739_index_hint.reference
@@ -23,12 +23,12 @@ select * from tbl WHERE indexHint(p in (select toInt64(number) - 2 from numbers(
0 3 0
drop table tbl;
drop table if exists XXXX;
-create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=128;
+create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=128, index_granularity_bytes = '10Mi';
insert into XXXX select number*60, 0 from numbers(100000);
SELECT sum(t) FROM XXXX WHERE indexHint(t = 42);
487680
drop table if exists XXXX;
-create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=8192;
+create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=8192, index_granularity_bytes = '10Mi';
insert into XXXX select number*60, 0 from numbers(100000);
SELECT count() FROM XXXX WHERE indexHint(t = toDateTime(0)) SETTINGS optimize_use_implicit_projections = 1;
100000
diff --git a/tests/queries/0_stateless/01739_index_hint.sql b/tests/queries/0_stateless/01739_index_hint.sql
index 77c2760535dd..cde46a5a2bf9 100644
--- a/tests/queries/0_stateless/01739_index_hint.sql
+++ b/tests/queries/0_stateless/01739_index_hint.sql
@@ -18,7 +18,7 @@ drop table tbl;
drop table if exists XXXX;
-create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=128;
+create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=128, index_granularity_bytes = '10Mi';
insert into XXXX select number*60, 0 from numbers(100000);
@@ -26,7 +26,7 @@ SELECT sum(t) FROM XXXX WHERE indexHint(t = 42);
drop table if exists XXXX;
-create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=8192;
+create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=8192, index_granularity_bytes = '10Mi';
insert into XXXX select number*60, 0 from numbers(100000);
diff --git a/tests/queries/0_stateless/01746_test_for_tupleElement_must_be_constant_issue.sql b/tests/queries/0_stateless/01746_test_for_tupleElement_must_be_constant_issue.sql
index 72ba6a036dff..585640665d1a 100644
--- a/tests/queries/0_stateless/01746_test_for_tupleElement_must_be_constant_issue.sql
+++ b/tests/queries/0_stateless/01746_test_for_tupleElement_must_be_constant_issue.sql
@@ -1,5 +1,5 @@
DROP TABLE IF EXISTS ttt01746;
-CREATE TABLE ttt01746 (d Date, n UInt64) ENGINE = MergeTree() PARTITION BY toMonday(d) ORDER BY n;
+CREATE TABLE ttt01746 (d Date, n UInt64) ENGINE = MergeTree() PARTITION BY toMonday(d) ORDER BY n SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO ttt01746 SELECT toDate('2021-02-14') + (number % 30) AS d, number AS n FROM numbers(1500000);
set optimize_move_to_prewhere=0;
SELECT arraySort(x -> x.2, [tuple('a', 10)]) AS X FROM ttt01746 WHERE d >= toDate('2021-03-03') - 2 ORDER BY n LIMIT 1;
diff --git a/tests/queries/0_stateless/01763_filter_push_down_bugs.sql b/tests/queries/0_stateless/01763_filter_push_down_bugs.sql
index 8470b4a33792..367baef142ba 100644
--- a/tests/queries/0_stateless/01763_filter_push_down_bugs.sql
+++ b/tests/queries/0_stateless/01763_filter_push_down_bugs.sql
@@ -9,6 +9,7 @@ CREATE TABLE Test
ENGINE = MergeTree()
PRIMARY KEY (String1,String2)
ORDER BY (String1,String2)
+SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'
AS
SELECT
'String1_' || toString(number) as String1,
@@ -39,15 +40,15 @@ DROP TABLE IF EXISTS Test;
select x, y from (select [0, 1, 2] as y, 1 as a, 2 as b) array join y as x where a = 1 and b = 2 and (x = 1 or x != 1) and x = 1;
DROP TABLE IF EXISTS t;
-create table t(a UInt8) engine=MergeTree order by a;
+create table t(a UInt8) engine=MergeTree order by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t select * from numbers(2);
select a from t t1 join t t2 on t1.a = t2.a where t1.a;
DROP TABLE IF EXISTS t;
DROP TABLE IF EXISTS t1;
DROP TABLE IF EXISTS t2;
-CREATE TABLE t1 (id Int64, create_time DateTime) ENGINE = MergeTree ORDER BY id;
-CREATE TABLE t2 (delete_time DateTime) ENGINE = MergeTree ORDER BY delete_time;
+CREATE TABLE t1 (id Int64, create_time DateTime) ENGINE = MergeTree ORDER BY id SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
+CREATE TABLE t2 (delete_time DateTime) ENGINE = MergeTree ORDER BY delete_time SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t1 values (101, '2023-05-28 00:00:00'), (102, '2023-05-28 00:00:00');
insert into t2 values ('2023-05-31 00:00:00');
diff --git a/tests/queries/0_stateless/01771_bloom_filter_not_has.sql b/tests/queries/0_stateless/01771_bloom_filter_not_has.sql
index f945cbde56b9..00b71d6feeb8 100644
--- a/tests/queries/0_stateless/01771_bloom_filter_not_has.sql
+++ b/tests/queries/0_stateless/01771_bloom_filter_not_has.sql
@@ -1,6 +1,6 @@
-- Tags: no-parallel, long
DROP TABLE IF EXISTS bloom_filter_null_array;
-CREATE TABLE bloom_filter_null_array (v Array(Int32), INDEX idx v TYPE bloom_filter GRANULARITY 3) ENGINE = MergeTree() ORDER BY v;
+CREATE TABLE bloom_filter_null_array (v Array(Int32), INDEX idx v TYPE bloom_filter GRANULARITY 3) ENGINE = MergeTree() ORDER BY v SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO bloom_filter_null_array SELECT [number] FROM numbers(10000000);
SELECT COUNT() FROM bloom_filter_null_array;
SELECT COUNT() FROM bloom_filter_null_array WHERE has(v, 0);
diff --git a/tests/queries/0_stateless/01780_column_sparse_filter.sql b/tests/queries/0_stateless/01780_column_sparse_filter.sql
index 45958b5c4e00..f52beba50b05 100644
--- a/tests/queries/0_stateless/01780_column_sparse_filter.sql
+++ b/tests/queries/0_stateless/01780_column_sparse_filter.sql
@@ -2,7 +2,7 @@ DROP TABLE IF EXISTS t_sparse;
CREATE TABLE t_sparse (id UInt64, u UInt64, s String)
ENGINE = MergeTree ORDER BY id
-SETTINGS ratio_of_defaults_for_sparse_serialization = 0.9;
+SETTINGS ratio_of_defaults_for_sparse_serialization = 0.9, index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t_sparse SELECT
number,
diff --git a/tests/queries/0_stateless/01825_type_json_sparse.sql b/tests/queries/0_stateless/01825_type_json_sparse.sql
index 343013cb3da5..cc7c66382a36 100644
--- a/tests/queries/0_stateless/01825_type_json_sparse.sql
+++ b/tests/queries/0_stateless/01825_type_json_sparse.sql
@@ -7,7 +7,7 @@ SET allow_experimental_object_type = 1;
CREATE TABLE t_json_sparse (data JSON)
ENGINE = MergeTree ORDER BY tuple()
SETTINGS ratio_of_defaults_for_sparse_serialization = 0.1,
-min_bytes_for_wide_part = 0;
+min_bytes_for_wide_part = 0, index_granularity = 8192, index_granularity_bytes = '10Mi';
SYSTEM STOP MERGES t_json_sparse;
diff --git a/tests/queries/0_stateless/01861_explain_pipeline.sql b/tests/queries/0_stateless/01861_explain_pipeline.sql
index aafecf57af12..93c82b6e2651 100644
--- a/tests/queries/0_stateless/01861_explain_pipeline.sql
+++ b/tests/queries/0_stateless/01861_explain_pipeline.sql
@@ -1,5 +1,5 @@
DROP TABLE IF EXISTS test;
-CREATE TABLE test(a Int, b Int) Engine=ReplacingMergeTree order by a;
+CREATE TABLE test(a Int, b Int) Engine=ReplacingMergeTree order by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO test select number, number from numbers(5);
INSERT INTO test select number, number from numbers(5,2);
set max_threads =1;
diff --git a/tests/queries/0_stateless/01906_lc_in_bug.sql b/tests/queries/0_stateless/01906_lc_in_bug.sql
index 581053e14e19..035e1fa155f2 100644
--- a/tests/queries/0_stateless/01906_lc_in_bug.sql
+++ b/tests/queries/0_stateless/01906_lc_in_bug.sql
@@ -8,6 +8,6 @@ select count() as c, x in ('a', 'bb') as g from tab group by g order by c;
drop table if exists tab;
-- https://github.com/ClickHouse/ClickHouse/issues/44503
-CREATE TABLE test(key Int32) ENGINE = MergeTree ORDER BY (key);
+CREATE TABLE test(key Int32) ENGINE = MergeTree ORDER BY (key) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into test select intDiv(number,100) from numbers(10000000);
SELECT COUNT() FROM test WHERE key <= 100000 AND (NOT (toLowCardinality('') IN (SELECT '')));
diff --git a/tests/queries/0_stateless/01913_quantile_deterministic.sh b/tests/queries/0_stateless/01913_quantile_deterministic.sh
index 5a2c72796785..a9c57a61c337 100755
--- a/tests/queries/0_stateless/01913_quantile_deterministic.sh
+++ b/tests/queries/0_stateless/01913_quantile_deterministic.sh
@@ -5,7 +5,7 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
. "$CURDIR"/../shell_config.sh
${CLICKHOUSE_CLIENT} --query "DROP TABLE IF EXISTS d"
-${CLICKHOUSE_CLIENT} --query "CREATE TABLE d (oid UInt64) ENGINE = MergeTree ORDER BY oid"
+${CLICKHOUSE_CLIENT} --query "CREATE TABLE d (oid UInt64) ENGINE = MergeTree ORDER BY oid SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'"
${CLICKHOUSE_CLIENT} --min_insert_block_size_rows 0 --min_insert_block_size_bytes 0 --max_block_size 8192 --query "insert into d select * from numbers(1000000)"
# In previous ClickHouse versions there was a mistake that makes quantileDeterministic functions not really deterministic (in edge cases).
diff --git a/tests/queries/0_stateless/02067_lost_part_s3.sql b/tests/queries/0_stateless/02067_lost_part_s3.sql
index bfdf92500368..6fbde71ff982 100644
--- a/tests/queries/0_stateless/02067_lost_part_s3.sql
+++ b/tests/queries/0_stateless/02067_lost_part_s3.sql
@@ -6,15 +6,18 @@ DROP TABLE IF EXISTS partslost_2;
CREATE TABLE partslost_0 (x String) ENGINE=ReplicatedMergeTree('/clickhouse/table/{database}_02067_lost/partslost', '0') ORDER BY tuple()
SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0, old_parts_lifetime = 1,
- cleanup_delay_period = 1, cleanup_delay_period_random_add = 1, cleanup_thread_preferred_points_per_iteration=0;
+ cleanup_delay_period = 1, cleanup_delay_period_random_add = 1, cleanup_thread_preferred_points_per_iteration=0,
+ index_granularity = 8192, index_granularity_bytes = '10Mi';
CREATE TABLE partslost_1 (x String) ENGINE=ReplicatedMergeTree('/clickhouse/table/{database}_02067_lost/partslost', '1') ORDER BY tuple()
SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0, old_parts_lifetime = 1,
- cleanup_delay_period = 1, cleanup_delay_period_random_add = 1, cleanup_thread_preferred_points_per_iteration=0;
+ cleanup_delay_period = 1, cleanup_delay_period_random_add = 1, cleanup_thread_preferred_points_per_iteration=0,
+ index_granularity = 8192, index_granularity_bytes = '10Mi';
CREATE TABLE partslost_2 (x String) ENGINE=ReplicatedMergeTree('/clickhouse/table/{database}_02067_lost/partslost', '2') ORDER BY tuple()
SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0, old_parts_lifetime = 1,
- cleanup_delay_period = 1, cleanup_delay_period_random_add = 1, cleanup_thread_preferred_points_per_iteration=0;
+ cleanup_delay_period = 1, cleanup_delay_period_random_add = 1, cleanup_thread_preferred_points_per_iteration=0,
+ index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO partslost_0 SELECT toString(number) AS x from system.numbers LIMIT 10000;
diff --git a/tests/queries/0_stateless/02149_read_in_order_fixed_prefix.sql b/tests/queries/0_stateless/02149_read_in_order_fixed_prefix.sql
index 5e662bd78426..0834b76d4ec6 100644
--- a/tests/queries/0_stateless/02149_read_in_order_fixed_prefix.sql
+++ b/tests/queries/0_stateless/02149_read_in_order_fixed_prefix.sql
@@ -5,7 +5,7 @@ SET read_in_order_two_level_merge_threshold=100;
DROP TABLE IF EXISTS t_read_in_order;
CREATE TABLE t_read_in_order(date Date, i UInt64, v UInt64)
-ENGINE = MergeTree ORDER BY (date, i);
+ENGINE = MergeTree ORDER BY (date, i) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t_read_in_order SELECT '2020-10-10', number % 10, number FROM numbers(100000);
INSERT INTO t_read_in_order SELECT '2020-10-11', number % 10, number FROM numbers(100000);
@@ -55,7 +55,7 @@ SELECT a, b FROM t_read_in_order WHERE a = 1 ORDER BY b DESC SETTINGS read_in_or
DROP TABLE t_read_in_order;
CREATE TABLE t_read_in_order(dt DateTime, d Decimal64(5), v UInt64)
-ENGINE = MergeTree ORDER BY (toStartOfDay(dt), d);
+ENGINE = MergeTree ORDER BY (toStartOfDay(dt), d) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t_read_in_order SELECT toDateTime('2020-10-10 00:00:00') + number, 1 / (number % 100 + 1), number FROM numbers(1000);
diff --git a/tests/queries/0_stateless/02150_index_hypothesis_race_long.sh b/tests/queries/0_stateless/02150_index_hypothesis_race_long.sh
index da2dcd055eae..114f60cc3930 100755
--- a/tests/queries/0_stateless/02150_index_hypothesis_race_long.sh
+++ b/tests/queries/0_stateless/02150_index_hypothesis_race_long.sh
@@ -6,7 +6,7 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
$CLICKHOUSE_CLIENT -q "DROP TABLE IF EXISTS t_index_hypothesis"
-$CLICKHOUSE_CLIENT -q "CREATE TABLE t_index_hypothesis (a UInt32, b UInt32, INDEX t a != b TYPE hypothesis GRANULARITY 1) ENGINE = MergeTree ORDER BY a"
+$CLICKHOUSE_CLIENT -q "CREATE TABLE t_index_hypothesis (a UInt32, b UInt32, INDEX t a != b TYPE hypothesis GRANULARITY 1) ENGINE = MergeTree ORDER BY a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'"
$CLICKHOUSE_CLIENT -q "INSERT INTO t_index_hypothesis SELECT number, number + 1 FROM numbers(10000000)"
diff --git a/tests/queries/0_stateless/02151_hash_table_sizes_stats.sh b/tests/queries/0_stateless/02151_hash_table_sizes_stats.sh
index fd6e44577d99..bf79e5f769d6 100755
--- a/tests/queries/0_stateless/02151_hash_table_sizes_stats.sh
+++ b/tests/queries/0_stateless/02151_hash_table_sizes_stats.sh
@@ -17,9 +17,9 @@ prepare_table() {
table_name="t_hash_table_sizes_stats_$RANDOM$RANDOM"
$CLICKHOUSE_CLIENT -q "DROP TABLE IF EXISTS $table_name;"
if [ -z "$1" ]; then
- $CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY tuple();"
+ $CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';"
else
- $CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY $1;"
+ $CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY $1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';"
fi
$CLICKHOUSE_CLIENT -q "SYSTEM STOP MERGES $table_name;"
for ((i = 1; i <= max_threads; i++)); do
diff --git a/tests/queries/0_stateless/02151_hash_table_sizes_stats_distributed.sh b/tests/queries/0_stateless/02151_hash_table_sizes_stats_distributed.sh
index b23be4283b2f..77b9b2942c5a 100755
--- a/tests/queries/0_stateless/02151_hash_table_sizes_stats_distributed.sh
+++ b/tests/queries/0_stateless/02151_hash_table_sizes_stats_distributed.sh
@@ -19,9 +19,9 @@ prepare_table() {
table_name="t_hash_table_sizes_stats_$RANDOM$RANDOM"
$CLICKHOUSE_CLIENT -q "DROP TABLE IF EXISTS $table_name;"
if [ -z "$1" ]; then
- $CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY tuple();"
+ $CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';"
else
- $CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY $1;"
+ $CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY $1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';"
fi
$CLICKHOUSE_CLIENT -q "SYSTEM STOP MERGES $table_name;"
for ((i = 1; i <= max_threads; i++)); do
diff --git a/tests/queries/0_stateless/02151_lc_prefetch.sql b/tests/queries/0_stateless/02151_lc_prefetch.sql
index 83d8d23264ed..c2b972311450 100644
--- a/tests/queries/0_stateless/02151_lc_prefetch.sql
+++ b/tests/queries/0_stateless/02151_lc_prefetch.sql
@@ -1,6 +1,6 @@
-- Tags: no-tsan, no-asan, no-ubsan, no-msan, no-debug
drop table if exists tab_lc;
-CREATE TABLE tab_lc (x UInt64, y LowCardinality(String)) engine = MergeTree order by x;
+CREATE TABLE tab_lc (x UInt64, y LowCardinality(String)) engine = MergeTree order by x SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into tab_lc select number, toString(number % 10) from numbers(20000000);
optimize table tab_lc;
select count() from tab_lc where y == '0' settings local_filesystem_read_prefetch=1;
diff --git a/tests/queries/0_stateless/02177_issue_31009.sql b/tests/queries/0_stateless/02177_issue_31009.sql
index 280627954d9c..f25df59f4b4c 100644
--- a/tests/queries/0_stateless/02177_issue_31009.sql
+++ b/tests/queries/0_stateless/02177_issue_31009.sql
@@ -5,8 +5,8 @@ SET max_threads=0;
DROP TABLE IF EXISTS left;
DROP TABLE IF EXISTS right;
-CREATE TABLE left ( key UInt32, value String ) ENGINE = MergeTree ORDER BY key;
-CREATE TABLE right ( key UInt32, value String ) ENGINE = MergeTree ORDER BY tuple();
+CREATE TABLE left ( key UInt32, value String ) ENGINE = MergeTree ORDER BY key SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
+CREATE TABLE right ( key UInt32, value String ) ENGINE = MergeTree ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO left SELECT number, toString(number) FROM numbers(25367182);
INSERT INTO right SELECT number, toString(number) FROM numbers(23124707);
diff --git a/tests/queries/0_stateless/02233_set_enable_with_statement_cte_perf.sql b/tests/queries/0_stateless/02233_set_enable_with_statement_cte_perf.sql
index 71321b4dfe46..3b474369c982 100644
--- a/tests/queries/0_stateless/02233_set_enable_with_statement_cte_perf.sql
+++ b/tests/queries/0_stateless/02233_set_enable_with_statement_cte_perf.sql
@@ -1,8 +1,8 @@
DROP TABLE IF EXISTS ev;
DROP TABLE IF EXISTS idx;
-CREATE TABLE ev (a Int32, b Int32) Engine=MergeTree() ORDER BY a;
-CREATE TABLE idx (a Int32) Engine=MergeTree() ORDER BY a;
+CREATE TABLE ev (a Int32, b Int32) Engine=MergeTree() ORDER BY a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
+CREATE TABLE idx (a Int32) Engine=MergeTree() ORDER BY a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO ev SELECT number, number FROM numbers(10000000);
INSERT INTO idx SELECT number * 5 FROM numbers(1000);
diff --git a/tests/queries/0_stateless/02235_add_part_offset_virtual_column.sql b/tests/queries/0_stateless/02235_add_part_offset_virtual_column.sql
index 1de6447172d7..dc8fceddc523 100644
--- a/tests/queries/0_stateless/02235_add_part_offset_virtual_column.sql
+++ b/tests/queries/0_stateless/02235_add_part_offset_virtual_column.sql
@@ -12,7 +12,8 @@ CREATE TABLE t_1
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(p_time)
-ORDER BY order_0;
+ORDER BY order_0
+SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
CREATE TABLE t_random_1
(
diff --git a/tests/queries/0_stateless/02275_full_sort_join_long.sql.j2 b/tests/queries/0_stateless/02275_full_sort_join_long.sql.j2
index 621352f9c25a..53fab9d62712 100644
--- a/tests/queries/0_stateless/02275_full_sort_join_long.sql.j2
+++ b/tests/queries/0_stateless/02275_full_sort_join_long.sql.j2
@@ -2,8 +2,8 @@
DROP TABLE IF EXISTS t1;
DROP TABLE IF EXISTS t2;
-CREATE TABLE t1 (key UInt32, s String) ENGINE = MergeTree ORDER BY key;
-CREATE TABLE t2 (key UInt32, s String) ENGINE = MergeTree ORDER BY key;
+CREATE TABLE t1 (key UInt32, s String) ENGINE = MergeTree ORDER BY key SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
+CREATE TABLE t2 (key UInt32, s String) ENGINE = MergeTree ORDER BY key SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
{% set ltable_size = 10000000 -%}
{% set rtable_size = 1000000 -%}
diff --git a/tests/queries/0_stateless/02319_no_columns_in_row_level_filter.sql b/tests/queries/0_stateless/02319_no_columns_in_row_level_filter.sql
index e6bc475b0815..27f58dbff5ee 100644
--- a/tests/queries/0_stateless/02319_no_columns_in_row_level_filter.sql
+++ b/tests/queries/0_stateless/02319_no_columns_in_row_level_filter.sql
@@ -4,7 +4,7 @@ DROP TABLE IF EXISTS test_table;
CREATE TABLE test_table (`n` UInt64, `s` String)
ENGINE = MergeTree
-PRIMARY KEY n ORDER BY n;
+PRIMARY KEY n ORDER BY n SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO test_table SELECT number, concat('some string ', CAST(number, 'String')) FROM numbers(1000000);
diff --git a/tests/queries/0_stateless/02336_sparse_columns_s3.sql b/tests/queries/0_stateless/02336_sparse_columns_s3.sql
index 235123597282..bf4622adedc3 100644
--- a/tests/queries/0_stateless/02336_sparse_columns_s3.sql
+++ b/tests/queries/0_stateless/02336_sparse_columns_s3.sql
@@ -5,7 +5,8 @@ DROP TABLE IF EXISTS t_sparse_s3;
CREATE TABLE t_sparse_s3 (id UInt32, cond UInt8, s String)
engine = MergeTree ORDER BY id
settings ratio_of_defaults_for_sparse_serialization = 0.01, storage_policy = 's3_cache',
-min_bytes_for_wide_part = 0, min_compress_block_size = 1;
+min_bytes_for_wide_part = 0, min_compress_block_size = 1,
+index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t_sparse_s3 SELECT 1, number % 2, '' FROM numbers(8192);
INSERT INTO t_sparse_s3 SELECT 2, number % 2, '' FROM numbers(24576);
diff --git a/tests/queries/0_stateless/02344_distinct_limit_distiributed.sql b/tests/queries/0_stateless/02344_distinct_limit_distiributed.sql
index d0d9b130b7ed..c963199e05c2 100644
--- a/tests/queries/0_stateless/02344_distinct_limit_distiributed.sql
+++ b/tests/queries/0_stateless/02344_distinct_limit_distiributed.sql
@@ -1,7 +1,7 @@
drop table if exists t_distinct_limit;
create table t_distinct_limit (d Date, id Int64)
-engine = MergeTree partition by toYYYYMM(d) order by d;
+engine = MergeTree partition by toYYYYMM(d) order by d SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
set max_threads = 10;
diff --git a/tests/queries/0_stateless/02354_distributed_with_external_aggregation_memory_usage.sql b/tests/queries/0_stateless/02354_distributed_with_external_aggregation_memory_usage.sql
index c8ec40bb0a73..3e181a281a0d 100644
--- a/tests/queries/0_stateless/02354_distributed_with_external_aggregation_memory_usage.sql
+++ b/tests/queries/0_stateless/02354_distributed_with_external_aggregation_memory_usage.sql
@@ -2,7 +2,7 @@
DROP TABLE IF EXISTS t_2354_dist_with_external_aggr;
-create table t_2354_dist_with_external_aggr(a UInt64, b String, c FixedString(100)) engine = MergeTree order by tuple();
+create table t_2354_dist_with_external_aggr(a UInt64, b String, c FixedString(100)) engine = MergeTree order by tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t_2354_dist_with_external_aggr select number, toString(number) as s, toFixedString(s, 100) from numbers_mt(5e7);
diff --git a/tests/queries/0_stateless/02377_modify_column_from_lc.sql b/tests/queries/0_stateless/02377_modify_column_from_lc.sql
index a578e7cb03aa..efee323e88d0 100644
--- a/tests/queries/0_stateless/02377_modify_column_from_lc.sql
+++ b/tests/queries/0_stateless/02377_modify_column_from_lc.sql
@@ -9,7 +9,7 @@ CREATE TABLE t_modify_from_lc_1
a LowCardinality(UInt32) CODEC(NONE)
)
ENGINE = MergeTree ORDER BY tuple()
-SETTINGS min_bytes_for_wide_part = 0;
+SETTINGS min_bytes_for_wide_part = 0, index_granularity = 8192, index_granularity_bytes = '10Mi';
CREATE TABLE t_modify_from_lc_2
(
@@ -17,7 +17,7 @@ CREATE TABLE t_modify_from_lc_2
a LowCardinality(UInt32) CODEC(NONE)
)
ENGINE = MergeTree ORDER BY tuple()
-SETTINGS min_bytes_for_wide_part = 0;
+SETTINGS min_bytes_for_wide_part = 0, index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t_modify_from_lc_1 SELECT number, number FROM numbers(100000);
INSERT INTO t_modify_from_lc_2 SELECT number, number FROM numbers(100000);
diff --git a/tests/queries/0_stateless/02404_memory_bound_merging.reference b/tests/queries/0_stateless/02404_memory_bound_merging.reference
index d9fac433189a..41a3b6bf8ecf 100644
--- a/tests/queries/0_stateless/02404_memory_bound_merging.reference
+++ b/tests/queries/0_stateless/02404_memory_bound_merging.reference
@@ -118,8 +118,7 @@ ExpressionTransform
MergingAggregatedBucketTransform × 4
Resize 1 → 4
GroupingAggregatedTransform 3 → 1
- (Union)
- (ReadFromRemoteParallelReplicas)
+ (ReadFromRemoteParallelReplicas)
select a, count() from pr_t group by a order by a limit 5 offset 500;
500 1000
501 1000
diff --git a/tests/queries/0_stateless/02417_load_marks_async.sh b/tests/queries/0_stateless/02417_load_marks_async.sh
index a5cbcd08f757..72b35a565df5 100755
--- a/tests/queries/0_stateless/02417_load_marks_async.sh
+++ b/tests/queries/0_stateless/02417_load_marks_async.sh
@@ -21,7 +21,7 @@ n8 UInt64,
n9 UInt64
)
ENGINE = MergeTree
-ORDER BY n0 SETTINGS min_bytes_for_wide_part = 1;"
+ORDER BY n0 SETTINGS min_bytes_for_wide_part = 1, index_granularity = 8192, index_granularity_bytes = '10Mi';"
${CLICKHOUSE_CLIENT} -q "INSERT INTO test select number, number % 3, number % 5, number % 10, number % 13, number % 15, number % 17, number % 18, number % 22, number % 25 from numbers(1000000)"
${CLICKHOUSE_CLIENT} -q "SYSTEM STOP MERGES test"
diff --git a/tests/queries/0_stateless/02428_index_analysis_with_null_literal.sql b/tests/queries/0_stateless/02428_index_analysis_with_null_literal.sql
index 33b0ea4b8185..091fbbe17110 100644
--- a/tests/queries/0_stateless/02428_index_analysis_with_null_literal.sql
+++ b/tests/queries/0_stateless/02428_index_analysis_with_null_literal.sql
@@ -1,7 +1,7 @@
-- From https://github.com/ClickHouse/ClickHouse/issues/41814
drop table if exists test;
-create table test(a UInt64, m UInt64, d DateTime) engine MergeTree partition by toYYYYMM(d) order by (a, m, d);
+create table test(a UInt64, m UInt64, d DateTime) engine MergeTree partition by toYYYYMM(d) order by (a, m, d) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into test select number, number, '2022-01-01 00:00:00' from numbers(1000000);
@@ -12,7 +12,7 @@ drop table test;
-- From https://github.com/ClickHouse/ClickHouse/issues/34063
drop table if exists test_null_filter;
-create table test_null_filter(key UInt64, value UInt32) engine MergeTree order by key;
+create table test_null_filter(key UInt64, value UInt32) engine MergeTree order by key SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into test_null_filter select number, number from numbers(10000000);
diff --git a/tests/queries/0_stateless/02443_detach_attach_partition.reference b/tests/queries/0_stateless/02443_detach_attach_partition.reference
new file mode 100644
index 000000000000..77cfb77479d7
--- /dev/null
+++ b/tests/queries/0_stateless/02443_detach_attach_partition.reference
@@ -0,0 +1,4 @@
+default begin inserts
+default end inserts
+30 465
+30 465
diff --git a/tests/queries/0_stateless/02443_detach_attach_partition.sh b/tests/queries/0_stateless/02443_detach_attach_partition.sh
new file mode 100755
index 000000000000..ae104b833e35
--- /dev/null
+++ b/tests/queries/0_stateless/02443_detach_attach_partition.sh
@@ -0,0 +1,86 @@
+#!/usr/bin/env bash
+# Tags: race, zookeeper, long
+
+CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
+# shellcheck source=../shell_config.sh
+. "$CURDIR"/../shell_config.sh
+# shellcheck source=./replication.lib
+. "$CURDIR"/replication.lib
+
+
+$CLICKHOUSE_CLIENT -n -q "
+ DROP TABLE IF EXISTS alter_table0;
+ DROP TABLE IF EXISTS alter_table1;
+
+ CREATE TABLE alter_table0 (a UInt8, b Int16) ENGINE = ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/alter_table', 'r1') ORDER BY a;
+ CREATE TABLE alter_table1 (a UInt8, b Int16) ENGINE = ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/alter_table', 'r2') ORDER BY a;
+" || exit 1
+
+function thread_detach()
+{
+ while true; do
+ $CLICKHOUSE_CLIENT -mn -q "ALTER TABLE alter_table$(($RANDOM % 2)) DETACH PARTITION ID 'all'; SELECT sleep($RANDOM / 32000) format Null;" 2>/dev/null ||:
+ done
+}
+function thread_attach()
+{
+ while true; do
+ $CLICKHOUSE_CLIENT -mn -q "ALTER TABLE alter_table$(($RANDOM % 2)) ATTACH PARTITION ID 'all'; SELECT sleep($RANDOM / 32000) format Null;" 2>/dev/null ||:
+ done
+}
+
+insert_type=$(($RANDOM % 3))
+$CLICKHOUSE_CLIENT -q "SELECT '$CLICKHOUSE_DATABASE', 'insert_type $insert_type' FORMAT Null"
+
+function insert()
+{
+ # Fault injection may lead to duplicates
+ if [[ "$insert_type" -eq 0 ]]; then
+ $CLICKHOUSE_CLIENT --insert_deduplication_token=$1 -q "INSERT INTO alter_table$(($RANDOM % 2)) SELECT $RANDOM, $1" 2>/dev/null
+ elif [[ "$insert_type" -eq 1 ]]; then
+ $CLICKHOUSE_CLIENT -q "INSERT INTO alter_table$(($RANDOM % 2)) SELECT $1, $1" 2>/dev/null
+ else
+ $CLICKHOUSE_CLIENT --insert_keeper_fault_injection_probability=0 -q "INSERT INTO alter_table$(($RANDOM % 2)) SELECT $RANDOM, $1" 2>/dev/null
+ fi
+}
+
+thread_detach & PID_1=$!
+thread_attach & PID_2=$!
+thread_detach & PID_3=$!
+thread_attach & PID_4=$!
+
+function do_inserts()
+{
+ for i in {1..30}; do
+ while ! insert $i; do $CLICKHOUSE_CLIENT -q "SELECT '$CLICKHOUSE_DATABASE', 'retrying insert $i' FORMAT Null"; done
+ done
+}
+
+$CLICKHOUSE_CLIENT -q "SELECT '$CLICKHOUSE_DATABASE', 'begin inserts'"
+do_inserts 2>&1| grep -Fa "Exception: " | grep -Fv "was cancelled by concurrent ALTER PARTITION"
+$CLICKHOUSE_CLIENT -q "SELECT '$CLICKHOUSE_DATABASE', 'end inserts'"
+
+kill -TERM $PID_1 && kill -TERM $PID_2 && kill -TERM $PID_3 && kill -TERM $PID_4
+wait
+
+$CLICKHOUSE_CLIENT -q "SYSTEM SYNC REPLICA alter_table0"
+$CLICKHOUSE_CLIENT -q "SYSTEM SYNC REPLICA alter_table1"
+query_with_retry "ALTER TABLE alter_table0 ATTACH PARTITION ID 'all'" 2>/dev/null;
+$CLICKHOUSE_CLIENT -q "ALTER TABLE alter_table1 ATTACH PARTITION ID 'all'" 2>/dev/null
+$CLICKHOUSE_CLIENT -q "SYSTEM SYNC REPLICA alter_table1"
+$CLICKHOUSE_CLIENT -q "ALTER TABLE alter_table1 ATTACH PARTITION ID 'all'"
+$CLICKHOUSE_CLIENT -q "SYSTEM SYNC REPLICA alter_table0"
+$CLICKHOUSE_CLIENT -q "SYSTEM SYNC REPLICA alter_table1"
+
+engine=$($CLICKHOUSE_CLIENT -q "SELECT engine FROM system.tables WHERE database=currentDatabase() AND table='alter_table0'")
+if [[ "$engine" == "ReplicatedMergeTree" ]]; then
+ # ReplicatedMergeTree may duplicate data on ATTACH PARTITION (when one replica has a merged part and another replica has source parts only)
+ $CLICKHOUSE_CLIENT -q "OPTIMIZE TABLE alter_table0 FINAL DEDUPLICATE"
+ $CLICKHOUSE_CLIENT -q "SYSTEM SYNC REPLICA alter_table1"
+fi
+
+$CLICKHOUSE_CLIENT -q "SELECT count(), sum(b) FROM alter_table0"
+$CLICKHOUSE_CLIENT -q "SELECT count(), sum(b) FROM alter_table1"
+
+$CLICKHOUSE_CLIENT -q "DROP TABLE alter_table0"
+$CLICKHOUSE_CLIENT -q "DROP TABLE alter_table1"
diff --git a/tests/queries/0_stateless/02457_morton_coding.sql b/tests/queries/0_stateless/02457_morton_coding.sql
index 4fc26f255f42..955cb2e053bd 100644
--- a/tests/queries/0_stateless/02457_morton_coding.sql
+++ b/tests/queries/0_stateless/02457_morton_coding.sql
@@ -11,7 +11,7 @@ create table morton_numbers_02457(
n8 UInt8
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
SELECT '----- CONST -----';
select mortonEncode(1,2,3,4);
@@ -45,7 +45,7 @@ create table morton_numbers_1_02457(
n8 UInt64
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into morton_numbers_1_02457
select untuple(mortonDecode(8, mortonEncode(n1, n2, n3, n4, n5, n6, n7, n8)))
@@ -80,7 +80,7 @@ create table morton_numbers_2_02457(
n4 UInt64
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into morton_numbers_2_02457
select untuple(mortonDecode(4, mortonEncode(n1, n2, n3, n4)))
@@ -114,7 +114,7 @@ create table morton_numbers_3_02457(
n2 UInt64
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into morton_numbers_3_02457
select untuple(mortonDecode(2, mortonEncode(n1, n2)))
diff --git a/tests/queries/0_stateless/02457_morton_coding_with_mask.sql b/tests/queries/0_stateless/02457_morton_coding_with_mask.sql
index 5aeb1f380bea..c95205769d2a 100644
--- a/tests/queries/0_stateless/02457_morton_coding_with_mask.sql
+++ b/tests/queries/0_stateless/02457_morton_coding_with_mask.sql
@@ -20,7 +20,7 @@ create table morton_numbers_mask_02457(
n4 UInt8
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into morton_numbers_mask_02457
select n1.number, n2.number, n3.number, n4.number
@@ -37,7 +37,7 @@ create table morton_numbers_mask_1_02457(
n4 UInt64
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into morton_numbers_mask_1_02457
select untuple(mortonDecode((1,2,1,2), mortonEncode((1,2,1,2), n1, n2, n3, n4)))
@@ -64,7 +64,7 @@ create table morton_numbers_mask_02457(
n2 UInt8
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into morton_numbers_mask_02457
select n1.number, n2.number
@@ -77,7 +77,7 @@ create table morton_numbers_mask_2_02457(
n2 UInt64
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into morton_numbers_mask_2_02457
select untuple(mortonDecode((1,4), mortonEncode((1,4), n1, n2)))
@@ -105,7 +105,7 @@ create table morton_numbers_mask_02457(
n3 UInt8,
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into morton_numbers_mask_02457
select n1.number, n2.number, n3.number
@@ -120,7 +120,7 @@ create table morton_numbers_mask_3_02457(
n3 UInt64
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into morton_numbers_mask_3_02457
select untuple(mortonDecode((1,1,2), mortonEncode((1,1,2), n1, n2, n3)))
diff --git a/tests/queries/0_stateless/02481_merge_array_join_sample_by.sql b/tests/queries/0_stateless/02481_merge_array_join_sample_by.sql
index 39fc751f3313..1c2123a99d5b 100644
--- a/tests/queries/0_stateless/02481_merge_array_join_sample_by.sql
+++ b/tests/queries/0_stateless/02481_merge_array_join_sample_by.sql
@@ -1,7 +1,7 @@
DROP TABLE IF EXISTS 02481_mergetree;
DROP TABLE IF EXISTS 02481_merge;
-CREATE TABLE 02481_mergetree(x UInt64, y UInt64, arr Array(String)) ENGINE = MergeTree ORDER BY x SAMPLE BY x;
+CREATE TABLE 02481_mergetree(x UInt64, y UInt64, arr Array(String)) ENGINE = MergeTree ORDER BY x SAMPLE BY x SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
CREATE TABLE 02481_merge(x UInt64, y UInt64, arr Array(String)) ENGINE = Merge(currentDatabase(), '^(02481_mergetree)$');
diff --git a/tests/queries/0_stateless/02481_pk_analysis_with_enum_to_string.sql b/tests/queries/0_stateless/02481_pk_analysis_with_enum_to_string.sql
index 91402bbed603..021a55ef2e80 100644
--- a/tests/queries/0_stateless/02481_pk_analysis_with_enum_to_string.sql
+++ b/tests/queries/0_stateless/02481_pk_analysis_with_enum_to_string.sql
@@ -10,7 +10,7 @@ CREATE TABLE gen
)
ENGINE = GenerateRandom;
-CREATE TABLE github_events AS gen ENGINE=MergeTree ORDER BY (event_type, repo_name, created_at);
+CREATE TABLE github_events AS gen ENGINE=MergeTree ORDER BY (event_type, repo_name, created_at) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO github_events SELECT * FROM gen LIMIT 100000;
diff --git a/tests/queries/0_stateless/02482_load_parts_refcounts.sh b/tests/queries/0_stateless/02482_load_parts_refcounts.sh
index 4d588dabeb9e..fe3cee1359ef 100755
--- a/tests/queries/0_stateless/02482_load_parts_refcounts.sh
+++ b/tests/queries/0_stateless/02482_load_parts_refcounts.sh
@@ -5,23 +5,6 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
# shellcheck source=../shell_config.sh
. "$CURDIR"/../shell_config.sh
-function query_with_retry
-{
- retry=0
- until [ $retry -ge 5 ]
- do
- result=$($CLICKHOUSE_CLIENT $2 --query="$1" 2>&1)
- if [ "$?" == 0 ]; then
- echo -n "$result"
- return
- else
- retry=$(($retry + 1))
- sleep 3
- fi
- done
- echo "Query '$1' failed with '$result'"
-}
-
$CLICKHOUSE_CLIENT -n --query "
DROP TABLE IF EXISTS load_parts_refcounts SYNC;
diff --git a/tests/queries/0_stateless/02521_aggregation_by_partitions.sql b/tests/queries/0_stateless/02521_aggregation_by_partitions.sql
index b7d4a6ee93a6..73d58bb6d6cf 100644
--- a/tests/queries/0_stateless/02521_aggregation_by_partitions.sql
+++ b/tests/queries/0_stateless/02521_aggregation_by_partitions.sql
@@ -18,7 +18,7 @@ select count() from (select throwIf(count() != 2) from t1 group by a);
drop table t1;
-create table t2(a UInt32) engine=MergeTree order by tuple() partition by a % 8;
+create table t2(a UInt32) engine=MergeTree order by tuple() partition by a % 8 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
system stop merges t2;
@@ -31,7 +31,7 @@ select count() from (select throwIf(count() != 2) from t2 group by a);
drop table t2;
-create table t3(a UInt32) engine=MergeTree order by tuple() partition by a % 16;
+create table t3(a UInt32) engine=MergeTree order by tuple() partition by a % 16 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
system stop merges t3;
@@ -53,7 +53,7 @@ drop table t3;
set optimize_aggregation_in_order = 1;
-create table t4(a UInt32) engine=MergeTree order by a partition by a % 4;
+create table t4(a UInt32) engine=MergeTree order by a partition by a % 4 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
system stop merges t4;
@@ -66,7 +66,7 @@ select count() from (select throwIf(count() != 2) from t4 group by a);
drop table t4;
-create table t5(a UInt32) engine=MergeTree order by a partition by a % 8;
+create table t5(a UInt32) engine=MergeTree order by a partition by a % 8 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
system stop merges t5;
@@ -79,7 +79,7 @@ select count() from (select throwIf(count() != 2) from t5 group by a);
drop table t5;
-create table t6(a UInt32) engine=MergeTree order by a partition by a % 16;
+create table t6(a UInt32) engine=MergeTree order by a partition by a % 16 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
system stop merges t6;
@@ -94,7 +94,7 @@ drop table t6;
set optimize_aggregation_in_order = 0;
-create table t7(a UInt32) engine=MergeTree order by a partition by intDiv(a, 2);
+create table t7(a UInt32) engine=MergeTree order by a partition by intDiv(a, 2) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t7 select number from numbers_mt(100);
@@ -104,7 +104,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t7;
-create table t8(a UInt32) engine=MergeTree order by a partition by intDiv(a, 2) * 2 + 1;
+create table t8(a UInt32) engine=MergeTree order by a partition by intDiv(a, 2) * 2 + 1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t8 select number from numbers_mt(100);
@@ -114,7 +114,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t8;
-create table t9(a UInt32) engine=MergeTree order by a partition by intDiv(a, 2);
+create table t9(a UInt32) engine=MergeTree order by a partition by intDiv(a, 2) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t9 select number from numbers_mt(100);
@@ -124,7 +124,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t9;
-create table t10(a UInt32, b UInt32) engine=MergeTree order by a partition by (intDiv(a, 2), intDiv(b, 3));
+create table t10(a UInt32, b UInt32) engine=MergeTree order by a partition by (intDiv(a, 2), intDiv(b, 3)) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t10 select number, number from numbers_mt(100);
@@ -135,7 +135,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t10;
-- multiplication by 2 is not injective, so optimization is not applicable
-create table t11(a UInt32, b UInt32) engine=MergeTree order by a partition by (intDiv(a, 2), intDiv(b, 3));
+create table t11(a UInt32, b UInt32) engine=MergeTree order by a partition by (intDiv(a, 2), intDiv(b, 3)) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t11 select number, number from numbers_mt(100);
@@ -155,7 +155,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t12;
-create table t13(a UInt32, b UInt32) engine=MergeTree order by a partition by (intDiv(a, 2), intDiv(b, 3));
+create table t13(a UInt32, b UInt32) engine=MergeTree order by a partition by (intDiv(a, 2), intDiv(b, 3)) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t13 select number, number from numbers_mt(100);
@@ -165,7 +165,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t13;
-create table t14(a UInt32, b UInt32) engine=MergeTree order by a partition by intDiv(a, 2) + intDiv(b, 3);
+create table t14(a UInt32, b UInt32) engine=MergeTree order by a partition by intDiv(a, 2) + intDiv(b, 3) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t14 select number, number from numbers_mt(100);
@@ -176,7 +176,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t14;
-- to few partitions --
-create table t15(a UInt32, b UInt32) engine=MergeTree order by a partition by a < 90;
+create table t15(a UInt32, b UInt32) engine=MergeTree order by a partition by a < 90 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t15 select number, number from numbers_mt(100);
@@ -188,7 +188,7 @@ settings force_aggregate_partitions_independently = 0;
drop table t15;
-- to many partitions --
-create table t16(a UInt32, b UInt32) engine=MergeTree order by a partition by a % 16;
+create table t16(a UInt32, b UInt32) engine=MergeTree order by a partition by a % 16 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t16 select number, number from numbers_mt(100);
@@ -200,7 +200,7 @@ settings force_aggregate_partitions_independently = 0, max_number_of_partitions_
drop table t16;
-- to big skew --
-create table t17(a UInt32, b UInt32) engine=MergeTree order by a partition by a < 90;
+create table t17(a UInt32, b UInt32) engine=MergeTree order by a partition by a < 90 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t17 select number, number from numbers_mt(100);
@@ -211,7 +211,7 @@ settings force_aggregate_partitions_independently = 0, max_threads = 4;
drop table t17;
-create table t18(a UInt32, b UInt32) engine=MergeTree order by a partition by a;
+create table t18(a UInt32, b UInt32) engine=MergeTree order by a partition by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t18 select number, number from numbers_mt(50);
@@ -221,7 +221,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t18;
-create table t19(a UInt32, b UInt32) engine=MergeTree order by a partition by a;
+create table t19(a UInt32, b UInt32) engine=MergeTree order by a partition by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t19 select number, number from numbers_mt(50);
@@ -231,7 +231,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t19;
-create table t20(a UInt32, b UInt32) engine=MergeTree order by a partition by a;
+create table t20(a UInt32, b UInt32) engine=MergeTree order by a partition by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t20 select number, number from numbers_mt(50);
@@ -241,7 +241,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t20;
-create table t21(a UInt64, b UInt64) engine=MergeTree order by a partition by a % 16;
+create table t21(a UInt64, b UInt64) engine=MergeTree order by a partition by a % 16 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t21 select number, number from numbers_mt(1e6);
@@ -249,7 +249,7 @@ select a from t21 group by a limit 10 format Null;
drop table t21;
-create table t22(a UInt32, b UInt32) engine=SummingMergeTree order by a partition by a % 16;
+create table t22(a UInt32, b UInt32) engine=SummingMergeTree order by a partition by a % 16 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t22 select number, number from numbers_mt(1e6);
diff --git a/tests/queries/0_stateless/02521_lightweight_delete_and_ttl.sql b/tests/queries/0_stateless/02521_lightweight_delete_and_ttl.sql
index 1600761bb844..6bb8b5444e5c 100644
--- a/tests/queries/0_stateless/02521_lightweight_delete_and_ttl.sql
+++ b/tests/queries/0_stateless/02521_lightweight_delete_and_ttl.sql
@@ -3,7 +3,7 @@ DROP TABLE IF EXISTS lwd_test_02521;
CREATE TABLE lwd_test_02521 (id UInt64, value String, event_time DateTime)
ENGINE MergeTree()
ORDER BY id
-SETTINGS min_bytes_for_wide_part = 0;
+SETTINGS min_bytes_for_wide_part = 0, index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO lwd_test_02521 SELECT number, randomString(10), now() - INTERVAL 2 MONTH FROM numbers(50000);
INSERT INTO lwd_test_02521 SELECT number, randomString(10), now() FROM numbers(50000);
@@ -42,4 +42,4 @@ SELECT 'Count', count() FROM lwd_test_02521;
-- { echoOff }
-DROP TABLE lwd_test_02521;
\ No newline at end of file
+DROP TABLE lwd_test_02521;
diff --git a/tests/queries/0_stateless/02536_delta_gorilla_corruption.sql b/tests/queries/0_stateless/02536_delta_gorilla_corruption.sql
index 197a8ad72216..a4e0965e3295 100644
--- a/tests/queries/0_stateless/02536_delta_gorilla_corruption.sql
+++ b/tests/queries/0_stateless/02536_delta_gorilla_corruption.sql
@@ -11,7 +11,7 @@ drop table if exists bug_delta_gorilla;
create table bug_delta_gorilla
(value_bug UInt64 codec (Delta, Gorilla))
engine = MergeTree
-order by tuple()
+order by tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'
as (select 0 from numbers(30000000));
select count(*)
@@ -32,7 +32,7 @@ select 'The same issue in a much smaller repro happens also in Debug builds';
create table bug_delta_gorilla (val UInt64 codec (Delta, Gorilla))
engine = MergeTree
-order by val;
+order by val SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into bug_delta_gorilla values (0)(1)(3);
select * from bug_delta_gorilla;
diff --git a/tests/queries/0_stateless/02561_sorting_constants_and_distinct_crash.sql b/tests/queries/0_stateless/02561_sorting_constants_and_distinct_crash.sql
index 9b117773b9b4..93a47c6736a5 100644
--- a/tests/queries/0_stateless/02561_sorting_constants_and_distinct_crash.sql
+++ b/tests/queries/0_stateless/02561_sorting_constants_and_distinct_crash.sql
@@ -1,5 +1,5 @@
drop table if exists test_table;
-CREATE TABLE test_table (string_value String) ENGINE = MergeTree ORDER BY string_value;
+CREATE TABLE test_table (string_value String) ENGINE = MergeTree ORDER BY string_value SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
system stop merges test_table;
insert into test_table select * from (
select 'test_value_1'
diff --git a/tests/queries/0_stateless/02565_update_empty_nested.sql b/tests/queries/0_stateless/02565_update_empty_nested.sql
index ca1c1f5f36e2..333168476019 100644
--- a/tests/queries/0_stateless/02565_update_empty_nested.sql
+++ b/tests/queries/0_stateless/02565_update_empty_nested.sql
@@ -7,7 +7,7 @@ CREATE TABLE t_update_empty_nested
)
ENGINE = MergeTree
ORDER BY id
-SETTINGS min_bytes_for_wide_part = 0;
+SETTINGS min_bytes_for_wide_part = 0, index_granularity = 8192, index_granularity_bytes = '10Mi';
SET mutations_sync = 2;
diff --git a/tests/queries/0_stateless/02581_share_big_sets_between_mutation_tasks.sql b/tests/queries/0_stateless/02581_share_big_sets_between_mutation_tasks.sql
index 7b52a89b16fc..eff9e0fa8255 100644
--- a/tests/queries/0_stateless/02581_share_big_sets_between_mutation_tasks.sql
+++ b/tests/queries/0_stateless/02581_share_big_sets_between_mutation_tasks.sql
@@ -1,6 +1,6 @@
DROP TABLE IF EXISTS 02581_trips;
-CREATE TABLE 02581_trips(id UInt32, id2 UInt32, description String) ENGINE=MergeTree ORDER BY id;
+CREATE TABLE 02581_trips(id UInt32, id2 UInt32, description String) ENGINE=MergeTree ORDER BY id SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
-- Make multiple parts
INSERT INTO 02581_trips SELECT number, number, '' FROM numbers(10000);
diff --git a/tests/queries/0_stateless/02796_projection_date_filter_on_view.sql b/tests/queries/0_stateless/02796_projection_date_filter_on_view.sql
index 9d9d7a3abd54..cb26a6bce4fa 100644
--- a/tests/queries/0_stateless/02796_projection_date_filter_on_view.sql
+++ b/tests/queries/0_stateless/02796_projection_date_filter_on_view.sql
@@ -13,7 +13,7 @@ CREATE TABLE fx_1m (
)
ENGINE = MergeTree()
PARTITION BY toYear(dt_close)
-ORDER BY (symbol, dt_close);
+ORDER BY (symbol, dt_close) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
-- add projection
ALTER TABLE fx_1m
diff --git a/tests/queries/0_stateless/02832_alter_delete_indexes_projections.sql b/tests/queries/0_stateless/02832_alter_delete_indexes_projections.sql
index b87230e57d1d..399d0fba564a 100644
--- a/tests/queries/0_stateless/02832_alter_delete_indexes_projections.sql
+++ b/tests/queries/0_stateless/02832_alter_delete_indexes_projections.sql
@@ -2,7 +2,7 @@ set mutations_sync = 2;
drop table if exists t_delete_skip_index;
-create table t_delete_skip_index (x UInt32, y String, index i y type minmax granularity 3) engine = MergeTree order by tuple();
+create table t_delete_skip_index (x UInt32, y String, index i y type minmax granularity 3) engine = MergeTree order by tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t_delete_skip_index select number, toString(number) from numbers(8192 * 10);
select count() from t_delete_skip_index where y in (4, 5);
@@ -12,7 +12,7 @@ select count() from t_delete_skip_index where y in (4, 5);
drop table if exists t_delete_skip_index;
drop table if exists t_delete_projection;
-create table t_delete_projection (x UInt32, y UInt64, projection p (select sum(y))) engine = MergeTree order by tuple();
+create table t_delete_projection (x UInt32, y UInt64, projection p (select sum(y))) engine = MergeTree order by tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t_delete_projection select number, toString(number) from numbers(8192 * 10);
select sum(y) from t_delete_projection settings optimize_use_projections = 0;
diff --git a/tests/queries/0_stateless/02833_concurrrent_sessions.reference b/tests/queries/0_stateless/02833_concurrrent_sessions.reference
new file mode 100644
index 000000000000..bfe507e8eac0
--- /dev/null
+++ b/tests/queries/0_stateless/02833_concurrrent_sessions.reference
@@ -0,0 +1,34 @@
+sessions:
+150
+port_0_sessions:
+0
+address_0_sessions:
+0
+tcp_sessions
+60
+http_sessions
+30
+http_with_session_id_sessions
+30
+my_sql_sessions
+30
+Corresponding LoginSuccess/Logout
+10
+LoginFailure
+10
+Corresponding LoginSuccess/Logout
+10
+LoginFailure
+10
+Corresponding LoginSuccess/Logout
+10
+LoginFailure
+10
+Corresponding LoginSuccess/Logout
+10
+LoginFailure
+10
+Corresponding LoginSuccess/Logout
+10
+LoginFailure
+10
diff --git a/tests/queries/0_stateless/02833_concurrrent_sessions.sh b/tests/queries/0_stateless/02833_concurrrent_sessions.sh
new file mode 100755
index 000000000000..26b48462a760
--- /dev/null
+++ b/tests/queries/0_stateless/02833_concurrrent_sessions.sh
@@ -0,0 +1,138 @@
+#!/usr/bin/env bash
+# Tags: no-fasttest, no-debug
+
+CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
+# shellcheck source=../shell_config.sh
+. "$CURDIR"/../shell_config.sh
+
+readonly PID=$$
+
+# Each user uses a separate thread.
+readonly TCP_USERS=( "02833_TCP_USER_${PID}"_{1,2} ) # 2 concurrent TCP users
+readonly HTTP_USERS=( "02833_HTTP_USER_${PID}" )
+readonly HTTP_WITH_SESSION_ID_SESSION_USERS=( "02833_HTTP_WITH_SESSION_ID_USER_${PID}" )
+readonly MYSQL_USERS=( "02833_MYSQL_USER_${PID}")
+readonly ALL_USERS=( "${TCP_USERS[@]}" "${HTTP_USERS[@]}" "${HTTP_WITH_SESSION_ID_SESSION_USERS[@]}" "${MYSQL_USERS[@]}" )
+
+readonly TCP_USERS_SQL_COLLECTION_STRING="$( echo "${TCP_USERS[*]}" | sed "s/[^[:space:]]\+/'&'/g" | sed 's/[[:space:]]/,/g' )"
+readonly HTTP_USERS_SQL_COLLECTION_STRING="$( echo "${HTTP_USERS[*]}" | sed "s/[^[:space:]]\+/'&'/g" | sed 's/[[:space:]]/,/g' )"
+readonly HTTP_WITH_SESSION_ID_USERS_SQL_COLLECTION_STRING="$( echo "${HTTP_WITH_SESSION_ID_SESSION_USERS[*]}" | sed "s/[^[:space:]]\+/'&'/g" | sed 's/[[:space:]]/,/g' )"
+readonly MYSQL_USERS_SQL_COLLECTION_STRING="$( echo "${MYSQL_USERS[*]}" | sed "s/[^[:space:]]\+/'&'/g" | sed 's/[[:space:]]/,/g' )"
+readonly ALL_USERS_SQL_COLLECTION_STRING="$( echo "${ALL_USERS[*]}" | sed "s/[^[:space:]]\+/'&'/g" | sed 's/[[:space:]]/,/g' )"
+
+readonly SESSION_LOG_MATCHING_FIELDS="auth_id, auth_type, client_version_major, client_version_minor, client_version_patch, interface"
+
+for user in "${ALL_USERS[@]}"; do
+ ${CLICKHOUSE_CLIENT} -q "CREATE USER IF NOT EXISTS ${user} IDENTIFIED WITH plaintext_password BY 'pass'"
+ ${CLICKHOUSE_CLIENT} -q "GRANT SELECT ON system.* TO ${user}"
+ ${CLICKHOUSE_CLIENT} -q "GRANT SELECT ON INFORMATION_SCHEMA.* TO ${user}";
+done
+
+# All _session functions execute in separate threads.
+# These functions try to create a session with successful login and logout.
+# Sleep a small, random amount of time to make concurrency more intense.
+# and try to login with an invalid password.
+function tcp_session()
+{
+ local user=$1
+ local i=0
+ while (( (i++) < 10 )); do
+ # login logout
+ ${CLICKHOUSE_CLIENT} -q "SELECT 1, sleep(0.01${RANDOM})" --user="${user}" --password="pass"
+ # login failure
+ ${CLICKHOUSE_CLIENT} -q "SELECT 2" --user="${user}" --password 'invalid'
+ done
+}
+
+function http_session()
+{
+ local user=$1
+ local i=0
+ while (( (i++) < 10 )); do
+ # login logout
+ ${CLICKHOUSE_CURL} -sS "${CLICKHOUSE_URL}&user=${user}&password=pass" -d "SELECT 3, sleep(0.01${RANDOM})"
+
+ # login failure
+ ${CLICKHOUSE_CURL} -sS "${CLICKHOUSE_URL}&user=${user}&password=wrong" -d "SELECT 4"
+ done
+}
+
+function http_with_session_id_session()
+{
+ local user=$1
+ local i=0
+ while (( (i++) < 10 )); do
+ # login logout
+ ${CLICKHOUSE_CURL} -sS "${CLICKHOUSE_URL}&session_id=${user}&user=${user}&password=pass" -d "SELECT 5, sleep 0.01${RANDOM}"
+
+ # login failure
+ ${CLICKHOUSE_CURL} -sS "${CLICKHOUSE_URL}&session_id=${user}&user=${user}&password=wrong" -d "SELECT 6"
+ done
+}
+
+function mysql_session()
+{
+ local user=$1
+ local i=0
+ while (( (i++) < 10 )); do
+ # login logout
+ ${CLICKHOUSE_CLIENT} -q "SELECT 1, sleep(0.01${RANDOM}) FROM mysql('127.0.0.1:9004', 'system', 'one', '${user}', 'pass')"
+
+ # login failure
+ ${CLICKHOUSE_CLIENT} -q "SELECT 1 FROM mysql('127.0.0.1:9004', 'system', 'one', '${user}', 'wrong', SETTINGS connection_max_tries=1)"
+ done
+}
+
+${CLICKHOUSE_CLIENT} -q "SYSTEM FLUSH LOGS"
+${CLICKHOUSE_CLIENT} -q "DELETE FROM system.session_log WHERE user IN (${ALL_USERS_SQL_COLLECTION_STRING})"
+
+export -f tcp_session;
+export -f http_session;
+export -f http_with_session_id_session;
+export -f mysql_session;
+
+for user in "${TCP_USERS[@]}"; do
+ timeout 60s bash -c "tcp_session ${user}" >/dev/null 2>&1 &
+done
+
+for user in "${HTTP_USERS[@]}"; do
+ timeout 60s bash -c "http_session ${user}" >/dev/null 2>&1 &
+done
+
+for user in "${HTTP_WITH_SESSION_ID_SESSION_USERS[@]}"; do
+ timeout 60s bash -c "http_with_session_id_session ${user}" >/dev/null 2>&1 &
+done
+
+for user in "${MYSQL_USERS[@]}"; do
+ timeout 60s bash -c "mysql_session ${user}" >/dev/null 2>&1 &
+done
+
+wait
+
+${CLICKHOUSE_CLIENT} -q "SYSTEM FLUSH LOGS"
+
+echo "sessions:"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user IN (${ALL_USERS_SQL_COLLECTION_STRING})"
+
+echo "port_0_sessions:"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user IN (${ALL_USERS_SQL_COLLECTION_STRING}) AND client_port = 0"
+
+echo "address_0_sessions:"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user IN (${ALL_USERS_SQL_COLLECTION_STRING}) AND client_address = toIPv6('::')"
+
+echo "tcp_sessions"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user IN (${TCP_USERS_SQL_COLLECTION_STRING}) AND interface = 'TCP'"
+echo "http_sessions"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user IN (${HTTP_USERS_SQL_COLLECTION_STRING}) AND interface = 'HTTP'"
+echo "http_with_session_id_sessions"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user IN (${HTTP_WITH_SESSION_ID_USERS_SQL_COLLECTION_STRING}) AND interface = 'HTTP'"
+echo "my_sql_sessions"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user IN (${MYSQL_USERS_SQL_COLLECTION_STRING}) AND interface = 'MySQL'"
+
+for user in "${ALL_USERS[@]}"; do
+ ${CLICKHOUSE_CLIENT} -q "DROP USER ${user}"
+ echo "Corresponding LoginSuccess/Logout"
+ ${CLICKHOUSE_CLIENT} -q "SELECT COUNT(*) FROM (SELECT ${SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = '${user}' AND type = 'LoginSuccess' INTERSECT SELECT ${SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = '${user}' AND type = 'Logout')"
+ echo "LoginFailure"
+ ${CLICKHOUSE_CLIENT} -q "SELECT COUNT(*) FROM system.session_log WHERE user = '${user}' AND type = 'LoginFailure'"
+ done
diff --git a/tests/queries/0_stateless/02834_remote_session_log.reference b/tests/queries/0_stateless/02834_remote_session_log.reference
new file mode 100644
index 000000000000..e2680982ab0b
--- /dev/null
+++ b/tests/queries/0_stateless/02834_remote_session_log.reference
@@ -0,0 +1,13 @@
+0
+0
+0
+0
+client_port 0 connections:
+0
+client_address '::' connections:
+0
+login failures:
+0
+TCP Login and logout count is equal
+HTTP Login and logout count is equal
+MySQL Login and logout count is equal
diff --git a/tests/queries/0_stateless/02834_remote_session_log.sh b/tests/queries/0_stateless/02834_remote_session_log.sh
new file mode 100755
index 000000000000..3bedfb6c9eeb
--- /dev/null
+++ b/tests/queries/0_stateless/02834_remote_session_log.sh
@@ -0,0 +1,56 @@
+#!/usr/bin/env bash
+# Tags: no-fasttest
+
+CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
+# shellcheck source=../shell_config.sh
+. "$CURDIR"/../shell_config.sh
+
+readonly PID=$$
+readonly TEST_USER=$"02834_USER_${PID}"
+readonly SESSION_LOG_MATCHING_FIELDS="auth_id, auth_type, client_version_major, client_version_minor, client_version_patch, interface"
+
+${CLICKHOUSE_CLIENT} -q "CREATE USER IF NOT EXISTS ${TEST_USER} IDENTIFIED WITH plaintext_password BY 'pass'"
+${CLICKHOUSE_CLIENT} -q "GRANT SELECT ON INFORMATION_SCHEMA.* TO ${TEST_USER}"
+${CLICKHOUSE_CLIENT} -q "GRANT SELECT ON system.* TO ${TEST_USER}"
+${CLICKHOUSE_CLIENT} -q "GRANT CREATE TEMPORARY TABLE, MYSQL, REMOTE ON *.* TO ${TEST_USER}"
+
+${CLICKHOUSE_CLIENT} -q "SYSTEM FLUSH LOGS"
+${CLICKHOUSE_CLIENT} -q "DELETE FROM system.session_log WHERE user = '${TEST_USER}'"
+
+${CLICKHOUSE_CURL} -sS -X POST "${CLICKHOUSE_URL}&user=${TEST_USER}&password=pass" \
+ -d "SELECT * FROM remote('127.0.0.1:${CLICKHOUSE_PORT_TCP}', 'system', 'one', '${TEST_USER}', 'pass')"
+
+${CLICKHOUSE_CURL} -sS -X POST "${CLICKHOUSE_URL}&user=${TEST_USER}&password=pass" \
+ -d "SELECT * FROM mysql('127.0.0.1:9004', 'system', 'one', '${TEST_USER}', 'pass')"
+
+${CLICKHOUSE_CLIENT} -q "SELECT * FROM remote('127.0.0.1:${CLICKHOUSE_PORT_TCP}', 'system', 'one', '${TEST_USER}', 'pass')" -u "${TEST_USER}" --password "pass"
+${CLICKHOUSE_CLIENT} -q "SELECT * FROM mysql('127.0.0.1:9004', 'system', 'one', '${TEST_USER}', 'pass')" -u "${TEST_USER}" --password "pass"
+
+${CLICKHOUSE_CLIENT} -q "SYSTEM FLUSH LOGS"
+
+echo "client_port 0 connections:"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user = '${TEST_USER}' and client_port = 0"
+
+echo "client_address '::' connections:"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user = '${TEST_USER}' and client_address = toIPv6('::')"
+
+echo "login failures:"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user = '${TEST_USER}' and type = 'LoginFailure'"
+
+# remote(...) function sometimes reuses old cached sessions for query execution.
+# This makes LoginSuccess/Logout entries count unstable, but success and logouts must always match.
+
+for interface in 'TCP' 'HTTP' 'MySQL'
+do
+ LOGIN_COUNT=`${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user = '${TEST_USER}' AND type = 'LoginSuccess' AND interface = '${interface}'"`
+ CORRESPONDING_LOGOUT_RECORDS_COUNT=`${CLICKHOUSE_CLIENT} -q "SELECT COUNT(*) FROM (SELECT ${SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = '${TEST_USER}' AND type = 'LoginSuccess' AND interface = '${interface}' INTERSECT SELECT ${SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = '${TEST_USER}' AND type = 'Logout' AND interface = '${interface}')"`
+
+ if [ "$LOGIN_COUNT" == "$CORRESPONDING_LOGOUT_RECORDS_COUNT" ]; then
+ echo "${interface} Login and logout count is equal"
+ else
+ TOTAL_LOGOUT_COUNT=`${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user = '${TEST_USER}' AND type = 'Logout' AND interface = '${interface}'"`
+ echo "${interface} Login count ${LOGIN_COUNT} != corresponding logout count ${CORRESPONDING_LOGOUT_RECORDS_COUNT}. TOTAL_LOGOUT_COUNT ${TOTAL_LOGOUT_COUNT}"
+ fi
+done
+
+${CLICKHOUSE_CLIENT} -q "DROP USER ${TEST_USER}"
diff --git a/tests/queries/0_stateless/02835_drop_user_during_session.reference b/tests/queries/0_stateless/02835_drop_user_during_session.reference
new file mode 100644
index 000000000000..7252faab8c6c
--- /dev/null
+++ b/tests/queries/0_stateless/02835_drop_user_during_session.reference
@@ -0,0 +1,8 @@
+port_0_sessions:
+0
+address_0_sessions:
+0
+Corresponding LoginSuccess/Logout
+9
+LoginFailure
+0
diff --git a/tests/queries/0_stateless/02835_drop_user_during_session.sh b/tests/queries/0_stateless/02835_drop_user_during_session.sh
new file mode 100755
index 000000000000..347ebd22f96c
--- /dev/null
+++ b/tests/queries/0_stateless/02835_drop_user_during_session.sh
@@ -0,0 +1,114 @@
+#!/usr/bin/env bash
+# Tags: no-debug
+
+CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
+# shellcheck source=../shell_config.sh
+. "$CURDIR"/../shell_config.sh
+
+readonly PID=$$
+
+readonly TEST_USER="02835_USER_${PID}"
+readonly TEST_ROLE="02835_ROLE_${PID}"
+readonly TEST_PROFILE="02835_PROFILE_${PID}"
+readonly SESSION_LOG_MATCHING_FIELDS="auth_id, auth_type, client_version_major, client_version_minor, client_version_patch, interface"
+
+function tcp_session()
+{
+ local user=$1
+ ${CLICKHOUSE_CLIENT} -q "SELECT COUNT(*) FROM system.numbers" --user="${user}"
+}
+
+function http_session()
+{
+ local user=$1
+ ${CLICKHOUSE_CURL} -sS "${CLICKHOUSE_URL}&user=${user}&password=pass" -d "SELECT COUNT(*) FROM system.numbers"
+}
+
+function http_with_session_id_session()
+{
+ local user=$1
+ ${CLICKHOUSE_CURL} -sS "${CLICKHOUSE_URL}&user=${user}&password=pass" -d "SELECT COUNT(*) FROM system.numbers"
+}
+
+# Busy-waits until user $1, specified amount of queries ($2) will run simultaneously.
+function wait_for_queries_start()
+{
+ local user=$1
+ local queries_count=$2
+ # 10 seconds waiting
+ counter=0 retries=100
+ while [[ $counter -lt $retries ]]; do
+ result=$($CLICKHOUSE_CLIENT --query "SELECT COUNT(*) FROM system.processes WHERE user = '${user}'")
+ if [[ $result == "${queries_count}" ]]; then
+ break;
+ fi
+ sleep 0.1
+ ((++counter))
+ done
+}
+
+${CLICKHOUSE_CLIENT} -q "SYSTEM FLUSH LOGS"
+${CLICKHOUSE_CLIENT} -q "DELETE FROM system.session_log WHERE user = '${TEST_USER}'"
+
+# DROP USE CASE
+${CLICKHOUSE_CLIENT} -q "CREATE USER IF NOT EXISTS ${TEST_USER}"
+${CLICKHOUSE_CLIENT} -q "GRANT SELECT ON system.numbers TO ${TEST_USER}"
+
+export -f tcp_session;
+export -f http_session;
+export -f http_with_session_id_session;
+
+timeout 10s bash -c "tcp_session ${TEST_USER}" >/dev/null 2>&1 &
+timeout 10s bash -c "http_session ${TEST_USER}" >/dev/null 2>&1 &
+timeout 10s bash -c "http_with_session_id_session ${TEST_USER}" >/dev/null 2>&1 &
+
+wait_for_queries_start $TEST_USER 3
+${CLICKHOUSE_CLIENT} -q "DROP USER ${TEST_USER}"
+${CLICKHOUSE_CLIENT} -q "KILL QUERY WHERE user = '${TEST_USER}' SYNC" >/dev/null &
+
+wait
+
+# DROP ROLE CASE
+${CLICKHOUSE_CLIENT} -q "CREATE ROLE IF NOT EXISTS ${TEST_ROLE}"
+${CLICKHOUSE_CLIENT} -q "CREATE USER ${TEST_USER} DEFAULT ROLE ${TEST_ROLE}"
+${CLICKHOUSE_CLIENT} -q "GRANT SELECT ON system.numbers TO ${TEST_USER}"
+
+timeout 10s bash -c "tcp_session ${TEST_USER}" >/dev/null 2>&1 &
+timeout 10s bash -c "http_session ${TEST_USER}" >/dev/null 2>&1 &
+timeout 10s bash -c "http_with_session_id_session ${TEST_USER}" >/dev/null 2>&1 &
+
+wait_for_queries_start $TEST_USER 3
+${CLICKHOUSE_CLIENT} -q "DROP ROLE ${TEST_ROLE}"
+${CLICKHOUSE_CLIENT} -q "DROP USER ${TEST_USER}"
+
+${CLICKHOUSE_CLIENT} -q "KILL QUERY WHERE user = '${TEST_USER}' SYNC" >/dev/null &
+
+wait
+
+# DROP PROFILE CASE
+${CLICKHOUSE_CLIENT} -q "CREATE SETTINGS PROFILE IF NOT EXISTS '${TEST_PROFILE}'"
+${CLICKHOUSE_CLIENT} -q "CREATE USER ${TEST_USER} SETTINGS PROFILE '${TEST_PROFILE}'"
+${CLICKHOUSE_CLIENT} -q "GRANT SELECT ON system.numbers TO ${TEST_USER}"
+
+timeout 10s bash -c "tcp_session ${TEST_USER}" >/dev/null 2>&1 &
+timeout 10s bash -c "http_session ${TEST_USER}" >/dev/null 2>&1 &
+timeout 10s bash -c "http_with_session_id_session ${TEST_USER}" >/dev/null 2>&1 &
+
+wait_for_queries_start $TEST_USER 3
+${CLICKHOUSE_CLIENT} -q "DROP SETTINGS PROFILE '${TEST_PROFILE}'"
+${CLICKHOUSE_CLIENT} -q "DROP USER ${TEST_USER}"
+
+${CLICKHOUSE_CLIENT} -q "KILL QUERY WHERE user = '${TEST_USER}' SYNC" >/dev/null &
+
+wait
+
+${CLICKHOUSE_CLIENT} -q "SYSTEM FLUSH LOGS"
+
+echo "port_0_sessions:"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user = '${TEST_USER}' AND client_port = 0"
+echo "address_0_sessions:"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user = '${TEST_USER}' AND client_address = toIPv6('::')"
+echo "Corresponding LoginSuccess/Logout"
+${CLICKHOUSE_CLIENT} -q "SELECT COUNT(*) FROM (SELECT ${SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = '${TEST_USER}' AND type = 'LoginSuccess' INTERSECT SELECT ${SESSION_LOG_MATCHING_FIELDS}, FROM system.session_log WHERE user = '${TEST_USER}' AND type = 'Logout')"
+echo "LoginFailure"
+${CLICKHOUSE_CLIENT} -q "SELECT COUNT(*) FROM system.session_log WHERE user = '${TEST_USER}' AND type = 'LoginFailure'"
diff --git a/tests/queries/0_stateless/02842_one_input_format.reference b/tests/queries/0_stateless/02842_one_input_format.reference
new file mode 100644
index 000000000000..714df685535a
--- /dev/null
+++ b/tests/queries/0_stateless/02842_one_input_format.reference
@@ -0,0 +1,12 @@
+dummy UInt8
+0
+0
+0
+data.csv
+data.jsonl
+data.native
+0
+0
+0
+1
+1
diff --git a/tests/queries/0_stateless/02842_one_input_format.sh b/tests/queries/0_stateless/02842_one_input_format.sh
new file mode 100755
index 000000000000..f2199cbe2ce7
--- /dev/null
+++ b/tests/queries/0_stateless/02842_one_input_format.sh
@@ -0,0 +1,22 @@
+#!/usr/bin/env bash
+
+CUR_DIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
+# shellcheck source=../shell_config.sh
+. "$CUR_DIR"/../shell_config.sh
+
+FILE_DIR=$CLICKHOUSE_TEST_UNIQUE_NAME
+mkdir -p $FILE_DIR
+
+$CLICKHOUSE_LOCAL -q "select * from numbers(100000) format Native" > $FILE_DIR/data.native
+$CLICKHOUSE_LOCAL -q "select * from numbers(100000) format CSV" > $FILE_DIR/data.csv
+$CLICKHOUSE_LOCAL -q "select * from numbers(100000) format JSONEachRow" > $FILE_DIR/data.jsonl
+
+$CLICKHOUSE_LOCAL -q "desc file('$FILE_DIR/*', One)"
+$CLICKHOUSE_LOCAL -q "select * from file('$FILE_DIR/*', One)"
+$CLICKHOUSE_LOCAL -q "select _file from file('$FILE_DIR/*', One) order by _file"
+$CLICKHOUSE_LOCAL -q "select * from file('$FILE_DIR/*', One, 'x UInt8')"
+$CLICKHOUSE_LOCAL -q "select * from file('$FILE_DIR/*', One, 'x UInt64')" 2>&1 | grep "BAD_ARGUMENTS" -c
+$CLICKHOUSE_LOCAL -q "select * from file('$FILE_DIR/*', One, 'x UInt8, y UInt8')" 2>&1 | grep "BAD_ARGUMENTS" -c
+
+rm -rf $FILE_DIR
+
diff --git a/tests/queries/0_stateless/02843_context_has_expired.reference b/tests/queries/0_stateless/02843_context_has_expired.reference
index 573541ac9702..229972f29247 100644
--- a/tests/queries/0_stateless/02843_context_has_expired.reference
+++ b/tests/queries/0_stateless/02843_context_has_expired.reference
@@ -1 +1,5 @@
0
+0
+0
+0
+0
diff --git a/tests/queries/0_stateless/02843_context_has_expired.sql b/tests/queries/0_stateless/02843_context_has_expired.sql
index ccef3458ed70..8355ce2c18c2 100644
--- a/tests/queries/0_stateless/02843_context_has_expired.sql
+++ b/tests/queries/0_stateless/02843_context_has_expired.sql
@@ -1,23 +1,36 @@
-DROP DICTIONARY IF EXISTS dict;
-DROP TABLE IF EXISTS source;
+DROP DICTIONARY IF EXISTS 02843_dict;
+DROP TABLE IF EXISTS 02843_source;
+DROP TABLE IF EXISTS 02843_join;
-CREATE TABLE source
+CREATE TABLE 02843_source
(
id UInt64,
value String
)
ENGINE=Memory;
-CREATE DICTIONARY dict
+CREATE DICTIONARY 02843_dict
(
id UInt64,
value String
)
PRIMARY KEY id
-SOURCE(CLICKHOUSE(TABLE 'source'))
+SOURCE(CLICKHOUSE(TABLE '02843_source'))
LAYOUT(DIRECT());
-SELECT 1 IN (SELECT dictGet('dict', 'value', materialize('1')));
+SELECT 1 IN (SELECT dictGet('02843_dict', 'value', materialize('1')));
-DROP DICTIONARY dict;
-DROP TABLE source;
+CREATE TABLE 02843_join (id UInt8, value String) ENGINE Join(ANY, LEFT, id);
+SELECT 1 IN (SELECT joinGet(02843_join, 'value', materialize(1)));
+SELECT 1 IN (SELECT joinGetOrNull(02843_join, 'value', materialize(1)));
+
+SELECT 1 IN (SELECT materialize(connectionId()));
+SELECT 1000000 IN (SELECT materialize(getSetting('max_threads')));
+SELECT 1 in (SELECT file(materialize('a'))); -- { serverError 107 }
+
+EXPLAIN ESTIMATE SELECT 1 IN (SELECT dictGet('02843_dict', 'value', materialize('1')));
+EXPLAIN ESTIMATE SELECT 1 IN (SELECT joinGet(`02843_join`, 'value', materialize(1)));
+
+DROP DICTIONARY 02843_dict;
+DROP TABLE 02843_source;
+DROP TABLE 02843_join;
diff --git a/tests/queries/0_stateless/02844_distributed_virtual_columns.reference b/tests/queries/0_stateless/02844_distributed_virtual_columns.reference
new file mode 100644
index 000000000000..e69de29bb2d1
diff --git a/tests/queries/0_stateless/02844_distributed_virtual_columns.sql b/tests/queries/0_stateless/02844_distributed_virtual_columns.sql
new file mode 100644
index 000000000000..31a6780f19ed
--- /dev/null
+++ b/tests/queries/0_stateless/02844_distributed_virtual_columns.sql
@@ -0,0 +1,5 @@
+drop table if exists data_01072;
+drop table if exists dist_01072;
+create table data_01072 (key Int) Engine=MergeTree() ORDER BY key;
+create table dist_01072 (key Int) Engine=Distributed(test_cluster_two_shards, currentDatabase(), data_01072, key);
+select * from dist_01072 where key=0 and _part='0';
diff --git a/tests/queries/1_stateful/00072_compare_date_and_string_index.sql b/tests/queries/1_stateful/00072_compare_date_and_string_index.sql
index d652b1bc5599..424e6c2dfeee 100644
--- a/tests/queries/1_stateful/00072_compare_date_and_string_index.sql
+++ b/tests/queries/1_stateful/00072_compare_date_and_string_index.sql
@@ -15,8 +15,8 @@ SELECT count() FROM test.hits WHERE EventDate IN (toDate('2014-03-18'), toDate('
SELECT count() FROM test.hits WHERE EventDate = concat('2014-0', '3-18');
DROP TABLE IF EXISTS test.hits_indexed_by_time;
-CREATE TABLE test.hits_indexed_by_time (EventDate Date, EventTime DateTime('Asia/Dubai')) ENGINE = MergeTree ORDER BY (EventDate, EventTime);
-INSERT INTO test.hits_indexed_by_time SELECT EventDate, EventTime FROM test.hits;
+CREATE TABLE test.hits_indexed_by_time (EventDate Date, EventTime DateTime('Asia/Dubai')) ENGINE = MergeTree ORDER BY (EventDate, EventTime) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
+INSERT INTO test.hits_indexed_by_time SELECT EventDate, EventTime FROM test.hits SETTINGS max_block_size = 65000;
SELECT count() FROM test.hits_indexed_by_time WHERE EventTime = '2014-03-18 01:02:03';
SELECT count() FROM test.hits_indexed_by_time WHERE EventTime < '2014-03-18 01:02:03';
diff --git a/tests/queries/1_stateful/00162_mmap_compression_none.sql b/tests/queries/1_stateful/00162_mmap_compression_none.sql
index 2178644214ac..d2cbcea8aaa5 100644
--- a/tests/queries/1_stateful/00162_mmap_compression_none.sql
+++ b/tests/queries/1_stateful/00162_mmap_compression_none.sql
@@ -1,5 +1,5 @@
DROP TABLE IF EXISTS hits_none;
-CREATE TABLE hits_none (Title String CODEC(NONE)) ENGINE = MergeTree ORDER BY tuple();
+CREATE TABLE hits_none (Title String CODEC(NONE)) ENGINE = MergeTree ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO hits_none SELECT Title FROM test.hits;
SET min_bytes_to_use_mmap_io = 1;
diff --git a/tests/queries/1_stateful/00174_distinct_in_order.sql b/tests/queries/1_stateful/00174_distinct_in_order.sql
index aac54d461814..301ff36dd42c 100644
--- a/tests/queries/1_stateful/00174_distinct_in_order.sql
+++ b/tests/queries/1_stateful/00174_distinct_in_order.sql
@@ -4,9 +4,9 @@ drop table if exists distinct_in_order sync;
drop table if exists ordinary_distinct sync;
select '-- DISTINCT columns are the same as in ORDER BY';
-create table distinct_in_order (CounterID UInt32, EventDate Date) engine=MergeTree() order by (CounterID, EventDate);
+create table distinct_in_order (CounterID UInt32, EventDate Date) engine=MergeTree() order by (CounterID, EventDate) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into distinct_in_order select distinct CounterID, EventDate from test.hits order by CounterID, EventDate settings optimize_distinct_in_order=1;
-create table ordinary_distinct (CounterID UInt32, EventDate Date) engine=MergeTree() order by (CounterID, EventDate);
+create table ordinary_distinct (CounterID UInt32, EventDate Date) engine=MergeTree() order by (CounterID, EventDate) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into ordinary_distinct select distinct CounterID, EventDate from test.hits order by CounterID, EventDate settings optimize_distinct_in_order=0;
select distinct * from distinct_in_order except select * from ordinary_distinct;
@@ -14,9 +14,9 @@ drop table if exists distinct_in_order sync;
drop table if exists ordinary_distinct sync;
select '-- DISTINCT columns has prefix in ORDER BY columns';
-create table distinct_in_order (CounterID UInt32, EventDate Date) engine=MergeTree() order by (CounterID, EventDate);
+create table distinct_in_order (CounterID UInt32, EventDate Date) engine=MergeTree() order by (CounterID, EventDate) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into distinct_in_order select distinct CounterID, EventDate from test.hits order by CounterID settings optimize_distinct_in_order=1;
-create table ordinary_distinct (CounterID UInt32, EventDate Date) engine=MergeTree() order by (CounterID, EventDate);
+create table ordinary_distinct (CounterID UInt32, EventDate Date) engine=MergeTree() order by (CounterID, EventDate) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into ordinary_distinct select distinct CounterID, EventDate from test.hits order by CounterID settings optimize_distinct_in_order=0;
select distinct * from distinct_in_order except select * from ordinary_distinct;
diff --git a/tests/queries/shell_config.sh b/tests/queries/shell_config.sh
index ef70c82aefc8..12bc0002191a 100644
--- a/tests/queries/shell_config.sh
+++ b/tests/queries/shell_config.sh
@@ -155,3 +155,23 @@ function random_str()
local n=$1 && shift
tr -cd '[:lower:]' < /dev/urandom | head -c"$n"
}
+
+function query_with_retry
+{
+ local query="$1" && shift
+
+ local retry=0
+ until [ $retry -ge 5 ]
+ do
+ local result
+ result="$($CLICKHOUSE_CLIENT "$@" --query="$query" 2>&1)"
+ if [ "$?" == 0 ]; then
+ echo -n "$result"
+ return
+ else
+ retry=$((retry + 1))
+ sleep 3
+ fi
+ done
+ echo "Query '$query' failed with '$result'"
+}
diff --git a/utils/check-style/aspell-ignore/en/aspell-dict.txt b/utils/check-style/aspell-ignore/en/aspell-dict.txt
index 812908931ef1..2e231120e418 100644
--- a/utils/check-style/aspell-ignore/en/aspell-dict.txt
+++ b/utils/check-style/aspell-ignore/en/aspell-dict.txt
@@ -1892,7 +1892,6 @@ overfitting
packetpool
packetsize
pageviews
-pandahouse
parallelization
parallelize
parallelized
@@ -2001,6 +2000,7 @@ ptrs
pushdown
pwrite
py
+PyArrow
qryn
quantile
quantileBFloat
@@ -1163,7 +1156,7 @@ ClickHouse服务器日志文件中跟踪日志确认了ClickHouse正在对索引
```
-## 移除无效的主键列
+## 小结
带有联合主键(UserID, URL)的表的主索引对于加快UserID的查询过滤非常有用。但是,尽管URL列是联合主键的一部分,但该索引在加速URL查询过滤方面并没有提供显著的帮助。
@@ -1176,4 +1169,12 @@ ClickHouse服务器日志文件中跟踪日志确认了ClickHouse正在对索引
但是,如果复合主键中的键列在基数上有很大的差异,那么查询按基数升序对主键列进行排序是有益的。
-主键键列之间的基数差越大,主键键列的顺序越重要。我们将在以后的文章中对此进行演示。请继续关注。
+主键键列之间的基数差得越大,主键中的列的顺序越重要。我们将在下一章节对此进行演示。
+
+# 高效地为键列排序
+
+TODO
+
+# 高效地识别单行
+
+TODO
diff --git a/docs/zh/sql-reference/statements/insert-into.md b/docs/zh/sql-reference/statements/insert-into.md
index 9acc1655f9a2..f80c0a8a8eae 100644
--- a/docs/zh/sql-reference/statements/insert-into.md
+++ b/docs/zh/sql-reference/statements/insert-into.md
@@ -8,7 +8,7 @@ INSERT INTO 语句主要用于向系统中添加数据.
查询的基本格式:
``` sql
-INSERT INTO [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
+INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
```
您可以在查询中指定要插入的列的列表,如:`[(c1, c2, c3)]`。您还可以使用列[匹配器](../../sql-reference/statements/select/index.md#asterisk)的表达式,例如`*`和/或[修饰符](../../sql-reference/statements/select/index.md#select-modifiers),例如 [APPLY](../../sql-reference/statements/select/index.md#apply-modifier), [EXCEPT](../../sql-reference/statements/select/index.md#apply-modifier), [REPLACE](../../sql-reference/statements/select/index.md#replace-modifier)。
@@ -71,7 +71,7 @@ INSERT INTO [db.]table [(c1, c2, c3)] FORMAT format_name data_set
例如,下面的查询所使用的输入格式就与上面INSERT … VALUES的中使用的输入格式相同:
``` sql
-INSERT INTO [db.]table [(c1, c2, c3)] FORMAT Values (v11, v12, v13), (v21, v22, v23), ...
+INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] FORMAT Values (v11, v12, v13), (v21, v22, v23), ...
```
ClickHouse会清除数据前所有的空白字符与一个换行符(如果有换行符的话)。所以在进行查询时,我们建议您将数据放入到输入输出格式名称后的新的一行中去(如果数据是以空白字符开始的,这将非常重要)。
@@ -93,7 +93,7 @@ INSERT INTO t FORMAT TabSeparated
### 使用`SELECT`的结果写入 {#inserting-the-results-of-select}
``` sql
-INSERT INTO [db.]table [(c1, c2, c3)] SELECT ...
+INSERT INTO [TABLE] [db.]table [(c1, c2, c3)] SELECT ...
```
写入与SELECT的列的对应关系是使用位置来进行对应的,尽管它们在SELECT表达式与INSERT中的名称可能是不同的。如果需要,会对它们执行对应的类型转换。
diff --git a/programs/install/Install.cpp b/programs/install/Install.cpp
index d7086c95bebf..e10a9fea86bf 100644
--- a/programs/install/Install.cpp
+++ b/programs/install/Install.cpp
@@ -997,7 +997,9 @@ namespace
{
/// sudo respects limits in /etc/security/limits.conf e.g. open files,
/// that's why we are using it instead of the 'clickhouse su' tool.
- command = fmt::format("sudo -u '{}' {}", user, command);
+ /// by default, sudo resets all the ENV variables, but we should preserve
+ /// the values /etc/default/clickhouse in /etc/init.d/clickhouse file
+ command = fmt::format("sudo --preserve-env -u '{}' {}", user, command);
}
fmt::print("Will run {}\n", command);
diff --git a/src/AggregateFunctions/UniquesHashSet.h b/src/AggregateFunctions/UniquesHashSet.h
index ca6d31a716d9..3e501b294148 100644
--- a/src/AggregateFunctions/UniquesHashSet.h
+++ b/src/AggregateFunctions/UniquesHashSet.h
@@ -108,7 +108,14 @@ class UniquesHashSet : private HashTableAllocatorWithStackMemory<(1ULL << UNIQUE
inline size_t buf_size() const { return 1ULL << size_degree; } /// NOLINT
inline size_t max_fill() const { return 1ULL << (size_degree - 1); } /// NOLINT
inline size_t mask() const { return buf_size() - 1; }
- inline size_t place(HashValue x) const { return (x >> UNIQUES_HASH_BITS_FOR_SKIP) & mask(); }
+
+ inline size_t place(HashValue x) const
+ {
+ if constexpr (std::endian::native == std::endian::little)
+ return (x >> UNIQUES_HASH_BITS_FOR_SKIP) & mask();
+ else
+ return (std::byteswap(x) >> UNIQUES_HASH_BITS_FOR_SKIP) & mask();
+ }
/// The value is divided by 2 ^ skip_degree
inline bool good(HashValue hash) const
diff --git a/src/Client/ClientBase.cpp b/src/Client/ClientBase.cpp
index c7288d4793a4..9ad6a46866f1 100644
--- a/src/Client/ClientBase.cpp
+++ b/src/Client/ClientBase.cpp
@@ -105,6 +105,7 @@ namespace ErrorCodes
extern const int LOGICAL_ERROR;
extern const int CANNOT_OPEN_FILE;
extern const int FILE_ALREADY_EXISTS;
+ extern const int USER_SESSION_LIMIT_EXCEEDED;
}
}
@@ -2408,6 +2409,13 @@ void ClientBase::runInteractive()
}
}
+ if (suggest && suggest->getLastError() == ErrorCodes::USER_SESSION_LIMIT_EXCEEDED)
+ {
+ // If a separate connection loading suggestions failed to open a new session,
+ // use the main session to receive them.
+ suggest->load(*connection, connection_parameters.timeouts, config().getInt("suggestion_limit"));
+ }
+
try
{
if (!processQueryText(input))
diff --git a/src/Client/Suggest.cpp b/src/Client/Suggest.cpp
index 00e0ebd8b918..c854d471fae8 100644
--- a/src/Client/Suggest.cpp
+++ b/src/Client/Suggest.cpp
@@ -22,9 +22,11 @@ namespace DB
{
namespace ErrorCodes
{
+ extern const int OK;
extern const int LOGICAL_ERROR;
extern const int UNKNOWN_PACKET_FROM_SERVER;
extern const int DEADLOCK_AVOIDED;
+ extern const int USER_SESSION_LIMIT_EXCEEDED;
}
Suggest::Suggest()
@@ -121,21 +123,24 @@ void Suggest::load(ContextPtr context, const ConnectionParameters & connection_p
}
catch (const Exception & e)
{
+ last_error = e.code();
if (e.code() == ErrorCodes::DEADLOCK_AVOIDED)
continue;
-
- /// Client can successfully connect to the server and
- /// get ErrorCodes::USER_SESSION_LIMIT_EXCEEDED for suggestion connection.
-
- /// We should not use std::cerr here, because this method works concurrently with the main thread.
- /// WriteBufferFromFileDescriptor will write directly to the file descriptor, avoiding data race on std::cerr.
-
- WriteBufferFromFileDescriptor out(STDERR_FILENO, 4096);
- out << "Cannot load data for command line suggestions: " << getCurrentExceptionMessage(false, true) << "\n";
- out.next();
+ else if (e.code() != ErrorCodes::USER_SESSION_LIMIT_EXCEEDED)
+ {
+ /// We should not use std::cerr here, because this method works concurrently with the main thread.
+ /// WriteBufferFromFileDescriptor will write directly to the file descriptor, avoiding data race on std::cerr.
+ ///
+ /// USER_SESSION_LIMIT_EXCEEDED is ignored here. The client will try to receive
+ /// suggestions using the main connection later.
+ WriteBufferFromFileDescriptor out(STDERR_FILENO, 4096);
+ out << "Cannot load data for command line suggestions: " << getCurrentExceptionMessage(false, true) << "\n";
+ out.next();
+ }
}
catch (...)
{
+ last_error = getCurrentExceptionCode();
WriteBufferFromFileDescriptor out(STDERR_FILENO, 4096);
out << "Cannot load data for command line suggestions: " << getCurrentExceptionMessage(false, true) << "\n";
out.next();
@@ -148,6 +153,21 @@ void Suggest::load(ContextPtr context, const ConnectionParameters & connection_p
});
}
+void Suggest::load(IServerConnection & connection,
+ const ConnectionTimeouts & timeouts,
+ Int32 suggestion_limit)
+{
+ try
+ {
+ fetch(connection, timeouts, getLoadSuggestionQuery(suggestion_limit, true));
+ }
+ catch (...)
+ {
+ std::cerr << "Suggestions loading exception: " << getCurrentExceptionMessage(false, true) << std::endl;
+ last_error = getCurrentExceptionCode();
+ }
+}
+
void Suggest::fetch(IServerConnection & connection, const ConnectionTimeouts & timeouts, const std::string & query)
{
connection.sendQuery(
@@ -176,6 +196,7 @@ void Suggest::fetch(IServerConnection & connection, const ConnectionTimeouts & t
return;
case Protocol::Server::EndOfStream:
+ last_error = ErrorCodes::OK;
return;
default:
diff --git a/src/Client/Suggest.h b/src/Client/Suggest.h
index cfe9315879cc..5cecdc4501b0 100644
--- a/src/Client/Suggest.h
+++ b/src/Client/Suggest.h
@@ -7,6 +7,7 @@
#include
#include
#include
+#include
#include
@@ -28,9 +29,15 @@ class Suggest : public LineReader::Suggest, boost::noncopyable
template
void load(ContextPtr context, const ConnectionParameters & connection_parameters, Int32 suggestion_limit);
+ void load(IServerConnection & connection,
+ const ConnectionTimeouts & timeouts,
+ Int32 suggestion_limit);
+
/// Older server versions cannot execute the query loading suggestions.
static constexpr int MIN_SERVER_REVISION = DBMS_MIN_PROTOCOL_VERSION_WITH_VIEW_IF_PERMITTED;
+ int getLastError() const { return last_error.load(); }
+
private:
void fetch(IServerConnection & connection, const ConnectionTimeouts & timeouts, const std::string & query);
@@ -38,6 +45,8 @@ class Suggest : public LineReader::Suggest, boost::noncopyable
/// Words are fetched asynchronously.
std::thread loading_thread;
+
+ std::atomic last_error { -1 };
};
}
diff --git a/src/Columns/ColumnAggregateFunction.cpp b/src/Columns/ColumnAggregateFunction.cpp
index 62ec324455e2..3ebb30df87e9 100644
--- a/src/Columns/ColumnAggregateFunction.cpp
+++ b/src/Columns/ColumnAggregateFunction.cpp
@@ -524,7 +524,7 @@ void ColumnAggregateFunction::insertDefault()
pushBackAndCreateState(data, arena, func.get());
}
-StringRef ColumnAggregateFunction::serializeValueIntoArena(size_t n, Arena & arena, const char *& begin) const
+StringRef ColumnAggregateFunction::serializeValueIntoArena(size_t n, Arena & arena, const char *& begin, const UInt8 *) const
{
WriteBufferFromArena out(arena, begin);
func->serialize(data[n], out, version);
diff --git a/src/Columns/ColumnAggregateFunction.h b/src/Columns/ColumnAggregateFunction.h
index f9ce45708c90..7c7201e585a6 100644
--- a/src/Columns/ColumnAggregateFunction.h
+++ b/src/Columns/ColumnAggregateFunction.h
@@ -162,7 +162,7 @@ class ColumnAggregateFunction final : public COWHelper
StringRef getDataAt(size_t n) const override;
bool isDefaultAt(size_t n) const override;
void insertData(const char * pos, size_t length) override;
- StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const override;
+ StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const override;
const char * deserializeAndInsertFromArena(const char * pos) override;
const char * skipSerializedInArena(const char * pos) const override;
void updateHashWithValue(size_t n, SipHash & hash) const override;
diff --git a/src/Columns/ColumnCompressed.h b/src/Columns/ColumnCompressed.h
index bfe7cdb4924a..b780fbbf37a2 100644
--- a/src/Columns/ColumnCompressed.h
+++ b/src/Columns/ColumnCompressed.h
@@ -88,7 +88,7 @@ class ColumnCompressed : public COWHelper
void insertData(const char *, size_t) override { throwMustBeDecompressed(); }
void insertDefault() override { throwMustBeDecompressed(); }
void popBack(size_t) override { throwMustBeDecompressed(); }
- StringRef serializeValueIntoArena(size_t, Arena &, char const *&) const override { throwMustBeDecompressed(); }
+ StringRef serializeValueIntoArena(size_t, Arena &, char const *&, const UInt8 *) const override { throwMustBeDecompressed(); }
const char * deserializeAndInsertFromArena(const char *) override { throwMustBeDecompressed(); }
const char * skipSerializedInArena(const char *) const override { throwMustBeDecompressed(); }
void updateHashWithValue(size_t, SipHash &) const override { throwMustBeDecompressed(); }
diff --git a/src/Columns/ColumnConst.h b/src/Columns/ColumnConst.h
index f769dd6cc2ac..dc84e0c24029 100644
--- a/src/Columns/ColumnConst.h
+++ b/src/Columns/ColumnConst.h
@@ -151,7 +151,7 @@ class ColumnConst final : public COWHelper
s -= n;
}
- StringRef serializeValueIntoArena(size_t, Arena & arena, char const *& begin) const override
+ StringRef serializeValueIntoArena(size_t, Arena & arena, char const *& begin, const UInt8 *) const override
{
return data->serializeValueIntoArena(0, arena, begin);
}
diff --git a/src/Columns/ColumnDecimal.cpp b/src/Columns/ColumnDecimal.cpp
index 8e5792934cf6..142ee6c271da 100644
--- a/src/Columns/ColumnDecimal.cpp
+++ b/src/Columns/ColumnDecimal.cpp
@@ -59,9 +59,26 @@ bool ColumnDecimal::hasEqualValues() const
}
template
-StringRef ColumnDecimal::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const
+StringRef ColumnDecimal::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 * null_bit) const
{
- auto * pos = arena.allocContinue(sizeof(T), begin);
+ constexpr size_t null_bit_size = sizeof(UInt8);
+ StringRef res;
+ char * pos;
+ if (null_bit)
+ {
+ res.size = * null_bit ? null_bit_size : null_bit_size + sizeof(T);
+ pos = arena.allocContinue(res.size, begin);
+ res.data = pos;
+ memcpy(pos, null_bit, null_bit_size);
+ if (*null_bit) return res;
+ pos += null_bit_size;
+ }
+ else
+ {
+ res.size = sizeof(T);
+ pos = arena.allocContinue(res.size, begin);
+ res.data = pos;
+ }
memcpy(pos, &data[n], sizeof(T));
return StringRef(pos, sizeof(T));
}
diff --git a/src/Columns/ColumnDecimal.h b/src/Columns/ColumnDecimal.h
index 03e0b9be5588..fb24ae4554b9 100644
--- a/src/Columns/ColumnDecimal.h
+++ b/src/Columns/ColumnDecimal.h
@@ -80,7 +80,7 @@ class ColumnDecimal final : public COWHelper(data[n], scale); }
- StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const override;
+ StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 * null_bit) const override;
const char * deserializeAndInsertFromArena(const char * pos) override;
const char * skipSerializedInArena(const char * pos) const override;
void updateHashWithValue(size_t n, SipHash & hash) const override;
diff --git a/src/Columns/ColumnFixedString.cpp b/src/Columns/ColumnFixedString.cpp
index 24b5c435ecdc..a18e5c522a1d 100644
--- a/src/Columns/ColumnFixedString.cpp
+++ b/src/Columns/ColumnFixedString.cpp
@@ -86,11 +86,28 @@ void ColumnFixedString::insertData(const char * pos, size_t length)
memset(chars.data() + old_size + length, 0, n - length);
}
-StringRef ColumnFixedString::serializeValueIntoArena(size_t index, Arena & arena, char const *& begin) const
+StringRef ColumnFixedString::serializeValueIntoArena(size_t index, Arena & arena, char const *& begin, const UInt8 * null_bit) const
{
- auto * pos = arena.allocContinue(n, begin);
+ constexpr size_t null_bit_size = sizeof(UInt8);
+ StringRef res;
+ char * pos;
+ if (null_bit)
+ {
+ res.size = * null_bit ? null_bit_size : null_bit_size + n;
+ pos = arena.allocContinue(res.size, begin);
+ res.data = pos;
+ memcpy(pos, null_bit, null_bit_size);
+ if (*null_bit) return res;
+ pos += null_bit_size;
+ }
+ else
+ {
+ res.size = n;
+ pos = arena.allocContinue(res.size, begin);
+ res.data = pos;
+ }
memcpy(pos, &chars[n * index], n);
- return StringRef(pos, n);
+ return res;
}
const char * ColumnFixedString::deserializeAndInsertFromArena(const char * pos)
diff --git a/src/Columns/ColumnFixedString.h b/src/Columns/ColumnFixedString.h
index 39497e3403ed..445432b7b285 100644
--- a/src/Columns/ColumnFixedString.h
+++ b/src/Columns/ColumnFixedString.h
@@ -115,7 +115,7 @@ class ColumnFixedString final : public COWHelper
throw Exception(ErrorCodes::NOT_IMPLEMENTED, "Cannot insert into {}", getName());
}
- StringRef serializeValueIntoArena(size_t, Arena &, char const *&) const override
+ StringRef serializeValueIntoArena(size_t, Arena &, char const *&, const UInt8 *) const override
{
throw Exception(ErrorCodes::NOT_IMPLEMENTED, "Cannot serialize from {}", getName());
}
diff --git a/src/Columns/ColumnLowCardinality.cpp b/src/Columns/ColumnLowCardinality.cpp
index 9269ea4ee4d8..41358a4e5385 100644
--- a/src/Columns/ColumnLowCardinality.cpp
+++ b/src/Columns/ColumnLowCardinality.cpp
@@ -255,7 +255,7 @@ void ColumnLowCardinality::insertData(const char * pos, size_t length)
idx.insertPosition(dictionary.getColumnUnique().uniqueInsertData(pos, length));
}
-StringRef ColumnLowCardinality::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const
+StringRef ColumnLowCardinality::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const
{
return getDictionary().serializeValueIntoArena(getIndexes().getUInt(n), arena, begin);
}
diff --git a/src/Columns/ColumnLowCardinality.h b/src/Columns/ColumnLowCardinality.h
index dcd07ff3b348..91bd5945fd91 100644
--- a/src/Columns/ColumnLowCardinality.h
+++ b/src/Columns/ColumnLowCardinality.h
@@ -87,7 +87,7 @@ class ColumnLowCardinality final : public COWHelperpopBack(n);
}
-StringRef ColumnMap::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const
+StringRef ColumnMap::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const
{
return nested->serializeValueIntoArena(n, arena, begin);
}
diff --git a/src/Columns/ColumnMap.h b/src/Columns/ColumnMap.h
index e5bc26127df9..fde8a7e0e678 100644
--- a/src/Columns/ColumnMap.h
+++ b/src/Columns/ColumnMap.h
@@ -58,7 +58,7 @@ class ColumnMap final : public COWHelper
void insert(const Field & x) override;
void insertDefault() override;
void popBack(size_t n) override;
- StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const override;
+ StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const override;
const char * deserializeAndInsertFromArena(const char * pos) override;
const char * skipSerializedInArena(const char * pos) const override;
void updateHashWithValue(size_t n, SipHash & hash) const override;
diff --git a/src/Columns/ColumnNullable.cpp b/src/Columns/ColumnNullable.cpp
index 2eb2ff0bf69e..fcd95e5c9637 100644
--- a/src/Columns/ColumnNullable.cpp
+++ b/src/Columns/ColumnNullable.cpp
@@ -4,6 +4,10 @@
#include
#include
#include
+#include
+#include
+#include
+#include
#include
#include
#include
@@ -34,6 +38,7 @@ ColumnNullable::ColumnNullable(MutableColumnPtr && nested_column_, MutableColumn
{
/// ColumnNullable cannot have constant nested column. But constant argument could be passed. Materialize it.
nested_column = getNestedColumn().convertToFullColumnIfConst();
+ nested_type = nested_column->getDataType();
if (!getNestedColumn().canBeInsideNullable())
throw Exception(ErrorCodes::ILLEGAL_COLUMN, "{} cannot be inside Nullable column", getNestedColumn().getName());
@@ -134,21 +139,77 @@ void ColumnNullable::insertData(const char * pos, size_t length)
}
}
-StringRef ColumnNullable::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const
+StringRef ColumnNullable::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const
{
const auto & arr = getNullMapData();
static constexpr auto s = sizeof(arr[0]);
+ char * pos;
- auto * pos = arena.allocContinue(s, begin);
- memcpy(pos, &arr[n], s);
-
- if (arr[n])
- return StringRef(pos, s);
-
- auto nested_ref = getNestedColumn().serializeValueIntoArena(n, arena, begin);
-
- /// serializeValueIntoArena may reallocate memory. Have to use ptr from nested_ref.data and move it back.
- return StringRef(nested_ref.data - s, nested_ref.size + s);
+ switch (nested_type)
+ {
+ case TypeIndex::UInt8:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::UInt16:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::UInt32:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::UInt64:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::UInt128:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::UInt256:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Int8:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Int16:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Int32:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Int64:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Int128:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Int256:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Float32:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Float64:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Date:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Date32:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::DateTime:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::DateTime64:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::String:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::FixedString:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Decimal32:
+ return static_cast *>(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Decimal64:
+ return static_cast *>(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Decimal128:
+ return static_cast *>(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::Decimal256:
+ return static_cast *>(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::UUID:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::IPv4:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ case TypeIndex::IPv6:
+ return static_cast(nested_column.get())->serializeValueIntoArena(n, arena, begin, &arr[n]);
+ default:
+ pos = arena.allocContinue(s, begin);
+ memcpy(pos, &arr[n], s);
+ if (arr[n])
+ return StringRef(pos, s);
+ auto nested_ref = getNestedColumn().serializeValueIntoArena(n, arena, begin);
+ /// serializeValueIntoArena may reallocate memory. Have to use ptr from nested_ref.data and move it back.
+ return StringRef(nested_ref.data - s, nested_ref.size + s);
+ }
}
const char * ColumnNullable::deserializeAndInsertFromArena(const char * pos)
diff --git a/src/Columns/ColumnNullable.h b/src/Columns/ColumnNullable.h
index bc95eca69b94..b57fdf3064db 100644
--- a/src/Columns/ColumnNullable.h
+++ b/src/Columns/ColumnNullable.h
@@ -6,6 +6,7 @@
#include
#include
+#include "Core/TypeId.h"
#include "config.h"
@@ -62,7 +63,7 @@ class ColumnNullable final : public COWHelper
StringRef getDataAt(size_t) const override;
/// Will insert null value if pos=nullptr
void insertData(const char * pos, size_t length) override;
- StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const override;
+ StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 * null_bit) const override;
const char * deserializeAndInsertFromArena(const char * pos) override;
const char * skipSerializedInArena(const char * pos) const override;
void insertRangeFrom(const IColumn & src, size_t start, size_t length) override;
@@ -212,6 +213,8 @@ class ColumnNullable final : public COWHelper
private:
WrappedPtr nested_column;
WrappedPtr null_map;
+ // optimize serializeValueIntoArena
+ TypeIndex nested_type;
template
void applyNullMapImpl(const NullMap & map);
diff --git a/src/Columns/ColumnObject.h b/src/Columns/ColumnObject.h
index bc5a6b69bb0b..36a33a8f10fa 100644
--- a/src/Columns/ColumnObject.h
+++ b/src/Columns/ColumnObject.h
@@ -244,7 +244,7 @@ class ColumnObject final : public COWHelper
StringRef getDataAt(size_t) const override { throwMustBeConcrete(); }
bool isDefaultAt(size_t) const override { throwMustBeConcrete(); }
void insertData(const char *, size_t) override { throwMustBeConcrete(); }
- StringRef serializeValueIntoArena(size_t, Arena &, char const *&) const override { throwMustBeConcrete(); }
+ StringRef serializeValueIntoArena(size_t, Arena &, char const *&, const UInt8 *) const override { throwMustBeConcrete(); }
const char * deserializeAndInsertFromArena(const char *) override { throwMustBeConcrete(); }
const char * skipSerializedInArena(const char *) const override { throwMustBeConcrete(); }
void updateHashWithValue(size_t, SipHash &) const override { throwMustBeConcrete(); }
diff --git a/src/Columns/ColumnSparse.cpp b/src/Columns/ColumnSparse.cpp
index 4f76a9be4b9e..057c0cd71122 100644
--- a/src/Columns/ColumnSparse.cpp
+++ b/src/Columns/ColumnSparse.cpp
@@ -150,7 +150,7 @@ void ColumnSparse::insertData(const char * pos, size_t length)
insertSingleValue([&](IColumn & column) { column.insertData(pos, length); });
}
-StringRef ColumnSparse::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const
+StringRef ColumnSparse::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const
{
return values->serializeValueIntoArena(getValueIndex(n), arena, begin);
}
diff --git a/src/Columns/ColumnSparse.h b/src/Columns/ColumnSparse.h
index 26e05655f602..48c7422dd27b 100644
--- a/src/Columns/ColumnSparse.h
+++ b/src/Columns/ColumnSparse.h
@@ -78,7 +78,7 @@ class ColumnSparse final : public COWHelper
/// Will insert null value if pos=nullptr
void insertData(const char * pos, size_t length) override;
- StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const override;
+ StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const override;
const char * deserializeAndInsertFromArena(const char * pos) override;
const char * skipSerializedInArena(const char *) const override;
void insertRangeFrom(const IColumn & src, size_t start, size_t length) override;
diff --git a/src/Columns/ColumnString.cpp b/src/Columns/ColumnString.cpp
index 38c7b2c0dd6b..50fe90ad8ef4 100644
--- a/src/Columns/ColumnString.cpp
+++ b/src/Columns/ColumnString.cpp
@@ -213,17 +213,30 @@ ColumnPtr ColumnString::permute(const Permutation & perm, size_t limit) const
}
-StringRef ColumnString::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const
+StringRef ColumnString::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 * null_bit) const
{
size_t string_size = sizeAt(n);
size_t offset = offsetAt(n);
-
+ constexpr size_t null_bit_size = sizeof(UInt8);
StringRef res;
- res.size = sizeof(string_size) + string_size;
- char * pos = arena.allocContinue(res.size, begin);
+ char * pos;
+ if (null_bit)
+ {
+ res.size = * null_bit ? null_bit_size : null_bit_size + sizeof(string_size) + string_size;
+ pos = arena.allocContinue(res.size, begin);
+ res.data = pos;
+ memcpy(pos, null_bit, null_bit_size);
+ if (*null_bit) return res;
+ pos += null_bit_size;
+ }
+ else
+ {
+ res.size = sizeof(string_size) + string_size;
+ pos = arena.allocContinue(res.size, begin);
+ res.data = pos;
+ }
memcpy(pos, &string_size, sizeof(string_size));
memcpy(pos + sizeof(string_size), &chars[offset], string_size);
- res.data = pos;
return res;
}
diff --git a/src/Columns/ColumnString.h b/src/Columns/ColumnString.h
index 08c876a803d8..e8e5ebbcbf92 100644
--- a/src/Columns/ColumnString.h
+++ b/src/Columns/ColumnString.h
@@ -11,6 +11,7 @@
#include
#include
#include
+#include
class Collator;
@@ -168,7 +169,7 @@ class ColumnString final : public COWHelper
offsets.resize_assume_reserved(offsets.size() - n);
}
- StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const override;
+ StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 * null_bit) const override;
const char * deserializeAndInsertFromArena(const char * pos) override;
diff --git a/src/Columns/ColumnTuple.cpp b/src/Columns/ColumnTuple.cpp
index 9702d2751147..d8992125be45 100644
--- a/src/Columns/ColumnTuple.cpp
+++ b/src/Columns/ColumnTuple.cpp
@@ -171,7 +171,7 @@ void ColumnTuple::popBack(size_t n)
column->popBack(n);
}
-StringRef ColumnTuple::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const
+StringRef ColumnTuple::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const
{
StringRef res(begin, 0);
for (const auto & column : columns)
diff --git a/src/Columns/ColumnTuple.h b/src/Columns/ColumnTuple.h
index e7dee9b8ff9b..79099f4c098e 100644
--- a/src/Columns/ColumnTuple.h
+++ b/src/Columns/ColumnTuple.h
@@ -61,7 +61,7 @@ class ColumnTuple final : public COWHelper
void insertFrom(const IColumn & src_, size_t n) override;
void insertDefault() override;
void popBack(size_t n) override;
- StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const override;
+ StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const override;
const char * deserializeAndInsertFromArena(const char * pos) override;
const char * skipSerializedInArena(const char * pos) const override;
void updateHashWithValue(size_t n, SipHash & hash) const override;
diff --git a/src/Columns/ColumnUnique.h b/src/Columns/ColumnUnique.h
index 377255d80c7d..882d17b1649c 100644
--- a/src/Columns/ColumnUnique.h
+++ b/src/Columns/ColumnUnique.h
@@ -79,7 +79,7 @@ class ColumnUnique final : public COWHelpergetFloat32(n); }
bool getBool(size_t n) const override { return getNestedColumn()->getBool(n); }
bool isNullAt(size_t n) const override { return is_nullable && n == getNullValueIndex(); }
- StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const override;
+ StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 * null_bit) const override;
const char * skipSerializedInArena(const char * pos) const override;
void updateHashWithValue(size_t n, SipHash & hash_func) const override
{
@@ -373,7 +373,7 @@ size_t ColumnUnique::uniqueInsertData(const char * pos, size_t lengt
}
template
-StringRef ColumnUnique::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const
+StringRef ColumnUnique::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 *) const
{
if (is_nullable)
{
diff --git a/src/Columns/ColumnVector.cpp b/src/Columns/ColumnVector.cpp
index f2fe343a3716..a9b8c0ccacb3 100644
--- a/src/Columns/ColumnVector.cpp
+++ b/src/Columns/ColumnVector.cpp
@@ -49,11 +49,28 @@ namespace ErrorCodes
}
template
-StringRef ColumnVector::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const
+StringRef ColumnVector::serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 * null_bit) const
{
- auto * pos = arena.allocContinue(sizeof(T), begin);
+ constexpr size_t null_bit_size = sizeof(UInt8);
+ StringRef res;
+ char * pos;
+ if (null_bit)
+ {
+ res.size = * null_bit ? null_bit_size : null_bit_size + sizeof(T);
+ pos = arena.allocContinue(res.size, begin);
+ res.data = pos;
+ memcpy(pos, null_bit, null_bit_size);
+ if (*null_bit) return res;
+ pos += null_bit_size;
+ }
+ else
+ {
+ res.size = sizeof(T);
+ pos = arena.allocContinue(res.size, begin);
+ res.data = pos;
+ }
unalignedStore(pos, data[n]);
- return StringRef(pos, sizeof(T));
+ return res;
}
template
diff --git a/src/Columns/ColumnVector.h b/src/Columns/ColumnVector.h
index b8ebff2a5d50..7bb69656c5ac 100644
--- a/src/Columns/ColumnVector.h
+++ b/src/Columns/ColumnVector.h
@@ -174,7 +174,7 @@ class ColumnVector final : public COWHelper>
data.resize_assume_reserved(data.size() - n);
}
- StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const override;
+ StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 * null_bit) const override;
const char * deserializeAndInsertFromArena(const char * pos) override;
diff --git a/src/Columns/IColumn.h b/src/Columns/IColumn.h
index b4eaf5c28f59..12ac1102efde 100644
--- a/src/Columns/IColumn.h
+++ b/src/Columns/IColumn.h
@@ -218,7 +218,7 @@ class IColumn : public COW
* For example, to obtain unambiguous representation of Array of strings, strings data should be interleaved with their sizes.
* Parameter begin should be used with Arena::allocContinue.
*/
- virtual StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin) const = 0;
+ virtual StringRef serializeValueIntoArena(size_t n, Arena & arena, char const *& begin, const UInt8 * null_bit = nullptr) const = 0;
/// Deserializes a value that was serialized using IColumn::serializeValueIntoArena method.
/// Returns pointer to the position after the read data.
diff --git a/src/Columns/IColumnDummy.h b/src/Columns/IColumnDummy.h
index 82d4c857b29b..4cadae2bc3d9 100644
--- a/src/Columns/IColumnDummy.h
+++ b/src/Columns/IColumnDummy.h
@@ -57,7 +57,7 @@ class IColumnDummy : public IColumn
++s;
}
- StringRef serializeValueIntoArena(size_t /*n*/, Arena & arena, char const *& begin) const override
+ StringRef serializeValueIntoArena(size_t /*n*/, Arena & arena, char const *& begin, const UInt8 *) const override
{
/// Has to put one useless byte into Arena, because serialization into zero number of bytes is ambiguous.
char * res = arena.allocContinue(1, begin);
diff --git a/src/Columns/tests/gtest_column_unique.cpp b/src/Columns/tests/gtest_column_unique.cpp
index 15208da70fb2..ab2cb42b6038 100644
--- a/src/Columns/tests/gtest_column_unique.cpp
+++ b/src/Columns/tests/gtest_column_unique.cpp
@@ -117,7 +117,7 @@ void column_unique_unique_deserialize_from_arena_impl(ColumnType & column, const
const char * pos = nullptr;
for (size_t i = 0; i < num_values; ++i)
{
- auto ref = column_unique_pattern->serializeValueIntoArena(idx->getUInt(i), arena, pos);
+ auto ref = column_unique_pattern->serializeValueIntoArena(idx->getUInt(i), arena, pos, nullptr);
const char * new_pos;
column_unique->uniqueDeserializeAndInsertFromArena(ref.data, new_pos);
ASSERT_EQ(new_pos - ref.data, ref.size) << "Deserialized data has different sizes at position " << i;
@@ -140,8 +140,8 @@ void column_unique_unique_deserialize_from_arena_impl(ColumnType & column, const
const char * pos_lc = nullptr;
for (size_t i = 0; i < num_values; ++i)
{
- auto ref_string = column.serializeValueIntoArena(i, arena_string, pos_string);
- auto ref_lc = column_unique->serializeValueIntoArena(idx->getUInt(i), arena_lc, pos_lc);
+ auto ref_string = column.serializeValueIntoArena(i, arena_string, pos_string, nullptr);
+ auto ref_lc = column_unique->serializeValueIntoArena(idx->getUInt(i), arena_lc, pos_lc, nullptr);
ASSERT_EQ(ref_string, ref_lc) << "Serialized data is different from pattern at position " << i;
}
}
diff --git a/src/Common/TransformEndianness.hpp b/src/Common/TransformEndianness.hpp
index 0a9055dde15a..05f7778a12e3 100644
--- a/src/Common/TransformEndianness.hpp
+++ b/src/Common/TransformEndianness.hpp
@@ -3,23 +3,25 @@
#include
#include
+#include
+
#include
namespace DB
{
-template
+template
requires std::is_integral_v
inline void transformEndianness(T & value)
{
- if constexpr (endian != std::endian::native)
+ if constexpr (ToEndian != FromEndian)
value = std::byteswap(value);
}
-template
+template
requires is_big_int_v
inline void transformEndianness(T & x)
{
- if constexpr (std::endian::native != endian)
+ if constexpr (ToEndian != FromEndian)
{
auto & items = x.items;
std::transform(std::begin(items), std::end(items), std::begin(items), [](auto & item) { return std::byteswap(item); });
@@ -27,42 +29,49 @@ inline void transformEndianness(T & x)
}
}
-template
+template
requires is_decimal
inline void transformEndianness(T & x)
{
- transformEndianness(x.value);
+ transformEndianness(x.value);
}
-template
+template
requires std::is_floating_point_v
inline void transformEndianness(T & value)
{
- if constexpr (std::endian::native != endian)
+ if constexpr (ToEndian != FromEndian)
{
auto * start = reinterpret_cast(&value);
std::reverse(start, start + sizeof(T));
}
}
-template
+template
requires std::is_scoped_enum_v
inline void transformEndianness(T & x)
{
using UnderlyingType = std::underlying_type_t;
- transformEndianness(reinterpret_cast(x));
+ transformEndianness(reinterpret_cast(x));
}
-template
+template
inline void transformEndianness(std::pair & pair)
{
- transformEndianness(pair.first);
- transformEndianness(pair.second);
+ transformEndianness(pair.first);
+ transformEndianness(pair.second);
}
-template
+template
inline void transformEndianness(StrongTypedef & x)
{
- transformEndianness(x.toUnderType());
+ transformEndianness(x.toUnderType());
+}
+
+template
+inline void transformEndianness(CityHash_v1_0_2::uint128 & x)
+{
+ transformEndianness(x.low64);
+ transformEndianness(x.high64);
}
}
diff --git a/src/Common/ZooKeeper/ZooKeeper.cpp b/src/Common/ZooKeeper/ZooKeeper.cpp
index 0fe536b1a084..10331a4e4100 100644
--- a/src/Common/ZooKeeper/ZooKeeper.cpp
+++ b/src/Common/ZooKeeper/ZooKeeper.cpp
@@ -152,7 +152,7 @@ void ZooKeeper::init(ZooKeeperArgs args_)
throw KeeperException(code, "/");
if (code == Coordination::Error::ZNONODE)
- throw KeeperException("ZooKeeper root doesn't exist. You should create root node " + args.chroot + " before start.", Coordination::Error::ZNONODE);
+ throw KeeperException(Coordination::Error::ZNONODE, "ZooKeeper root doesn't exist. You should create root node {} before start.", args.chroot);
}
}
@@ -491,7 +491,7 @@ std::string ZooKeeper::get(const std::string & path, Coordination::Stat * stat,
if (tryGet(path, res, stat, watch, &code))
return res;
else
- throw KeeperException("Can't get data for node " + path + ": node doesn't exist", code);
+ throw KeeperException(code, "Can't get data for node '{}': node doesn't exist", path);
}
std::string ZooKeeper::getWatch(const std::string & path, Coordination::Stat * stat, Coordination::WatchCallback watch_callback)
@@ -501,7 +501,7 @@ std::string ZooKeeper::getWatch(const std::string & path, Coordination::Stat * s
if (tryGetWatch(path, res, stat, watch_callback, &code))
return res;
else
- throw KeeperException("Can't get data for node " + path + ": node doesn't exist", code);
+ throw KeeperException(code, "Can't get data for node '{}': node doesn't exist", path);
}
bool ZooKeeper::tryGet(
diff --git a/src/Common/ZooKeeper/ZooKeeperArgs.cpp b/src/Common/ZooKeeper/ZooKeeperArgs.cpp
index 198d4ccdea76..4c73b9ffc6d4 100644
--- a/src/Common/ZooKeeper/ZooKeeperArgs.cpp
+++ b/src/Common/ZooKeeper/ZooKeeperArgs.cpp
@@ -213,7 +213,7 @@ void ZooKeeperArgs::initFromKeeperSection(const Poco::Util::AbstractConfiguratio
};
}
else
- throw KeeperException(std::string("Unknown key ") + key + " in config file", Coordination::Error::ZBADARGUMENTS);
+ throw KeeperException(Coordination::Error::ZBADARGUMENTS, "Unknown key {} in config file", key);
}
}
diff --git a/src/DataTypes/Serializations/SerializationNumber.cpp b/src/DataTypes/Serializations/SerializationNumber.cpp
index 0294a1c8a67e..df6c0848bbe4 100644
--- a/src/DataTypes/Serializations/SerializationNumber.cpp
+++ b/src/DataTypes/Serializations/SerializationNumber.cpp
@@ -10,6 +10,8 @@
#include
#include
+#include
+
namespace DB
{
@@ -135,13 +137,25 @@ template
void SerializationNumber::serializeBinaryBulk(const IColumn & column, WriteBuffer & ostr, size_t offset, size_t limit) const
{
const typename ColumnVector::Container & x = typeid_cast &>(column).getData();
+ if (const size_t size = x.size(); limit == 0 || offset + limit > size)
+ limit = size - offset;
- size_t size = x.size();
+ if (limit == 0)
+ return;
- if (limit == 0 || offset + limit > size)
- limit = size - offset;
+ if constexpr (std::endian::native == std::endian::big && sizeof(T) >= 2)
+ {
+ static constexpr auto to_little_endian = [](auto i)
+ {
+ transformEndianness(i);
+ return i;
+ };
- if (limit)
+ std::ranges::for_each(
+ x | std::views::drop(offset) | std::views::take(limit) | std::views::transform(to_little_endian),
+ [&ostr](const auto & i) { ostr.write(reinterpret_cast(&i), sizeof(typename ColumnVector::ValueType)); });
+ }
+ else
ostr.write(reinterpret_cast(&x[offset]), sizeof(typename ColumnVector::ValueType) * limit);
}
@@ -149,10 +163,13 @@ template
void SerializationNumber::deserializeBinaryBulk(IColumn & column, ReadBuffer & istr, size_t limit, double /*avg_value_size_hint*/) const
{
typename ColumnVector::Container & x = typeid_cast &>(column).getData();
- size_t initial_size = x.size();
+ const size_t initial_size = x.size();
x.resize(initial_size + limit);
- size_t size = istr.readBig(reinterpret_cast(&x[initial_size]), sizeof(typename ColumnVector::ValueType) * limit);
+ const size_t size = istr.readBig(reinterpret_cast(&x[initial_size]), sizeof(typename ColumnVector::ValueType) * limit);
x.resize(initial_size + size / sizeof(typename ColumnVector::ValueType));
+
+ if constexpr (std::endian::native == std::endian::big && sizeof(T) >= 2)
+ std::ranges::for_each(x | std::views::drop(initial_size), [](auto & i) { transformEndianness(i); });
}
template class SerializationNumber;
diff --git a/src/Formats/registerFormats.cpp b/src/Formats/registerFormats.cpp
index 29ef46f330f4..580db61edde4 100644
--- a/src/Formats/registerFormats.cpp
+++ b/src/Formats/registerFormats.cpp
@@ -101,6 +101,7 @@ void registerInputFormatJSONAsObject(FormatFactory & factory);
void registerInputFormatLineAsString(FormatFactory & factory);
void registerInputFormatMySQLDump(FormatFactory & factory);
void registerInputFormatParquetMetadata(FormatFactory & factory);
+void registerInputFormatOne(FormatFactory & factory);
#if USE_HIVE
void registerInputFormatHiveText(FormatFactory & factory);
@@ -142,6 +143,7 @@ void registerTemplateSchemaReader(FormatFactory & factory);
void registerMySQLSchemaReader(FormatFactory & factory);
void registerBSONEachRowSchemaReader(FormatFactory & factory);
void registerParquetMetadataSchemaReader(FormatFactory & factory);
+void registerOneSchemaReader(FormatFactory & factory);
void registerFileExtensions(FormatFactory & factory);
@@ -243,6 +245,7 @@ void registerFormats()
registerInputFormatMySQLDump(factory);
registerInputFormatParquetMetadata(factory);
+ registerInputFormatOne(factory);
registerNonTrivialPrefixAndSuffixCheckerJSONEachRow(factory);
registerNonTrivialPrefixAndSuffixCheckerJSONAsString(factory);
@@ -279,6 +282,7 @@ void registerFormats()
registerMySQLSchemaReader(factory);
registerBSONEachRowSchemaReader(factory);
registerParquetMetadataSchemaReader(factory);
+ registerOneSchemaReader(factory);
}
}
diff --git a/src/Functions/FunctionFactory.h b/src/Functions/FunctionFactory.h
index deea41e66775..588cae64e169 100644
--- a/src/Functions/FunctionFactory.h
+++ b/src/Functions/FunctionFactory.h
@@ -20,8 +20,8 @@ using FunctionCreator = std::function;
using FunctionFactoryData = std::pair;
/** Creates function by name.
- * Function could use for initialization (take ownership of shared_ptr, for example)
- * some dictionaries from Context.
+ * The provided Context is guaranteed to outlive the created function. Functions may use it for
+ * things like settings, current database, permission checks, etc.
*/
class FunctionFactory : private boost::noncopyable, public IFactoryWithAliases
{
diff --git a/src/Functions/FunctionsExternalDictionaries.h b/src/Functions/FunctionsExternalDictionaries.h
index 1b2e2eb3bd68..db6529da73c1 100644
--- a/src/Functions/FunctionsExternalDictionaries.h
+++ b/src/Functions/FunctionsExternalDictionaries.h
@@ -62,13 +62,14 @@ namespace ErrorCodes
*/
-class FunctionDictHelper
+class FunctionDictHelper : WithContext
{
public:
- explicit FunctionDictHelper(ContextPtr context_) : current_context(context_) {}
+ explicit FunctionDictHelper(ContextPtr context_) : WithContext(context_) {}
std::shared_ptr getDictionary(const String & dictionary_name)
{
+ auto current_context = getContext();
auto dict = current_context->getExternalDictionariesLoader().getDictionary(dictionary_name, current_context);
if (!access_checked)
@@ -131,12 +132,10 @@ class FunctionDictHelper
DictionaryStructure getDictionaryStructure(const String & dictionary_name) const
{
- return current_context->getExternalDictionariesLoader().getDictionaryStructure(dictionary_name, current_context);
+ return getContext()->getExternalDictionariesLoader().getDictionaryStructure(dictionary_name, getContext());
}
private:
- ContextPtr current_context;
-
/// Access cannot be not granted, since in this case checkAccess() will throw and access_checked will not be updated.
std::atomic access_checked = false;
diff --git a/src/Functions/FunctionsHashing.h b/src/Functions/FunctionsHashing.h
index a6a04b4e3134..fb40c59fa8ae 100644
--- a/src/Functions/FunctionsHashing.h
+++ b/src/Functions/FunctionsHashing.h
@@ -1374,8 +1374,8 @@ class FunctionAnyHash : public IFunction
if constexpr (std::is_same_v) /// backward-compatible
{
- if (std::endian::native == std::endian::big)
- std::ranges::for_each(col_to->getData(), transformEndianness);
+ if constexpr (std::endian::native == std::endian::big)
+ std::ranges::for_each(col_to->getData(), transformEndianness);
auto col_to_fixed_string = ColumnFixedString::create(sizeof(UInt128));
const auto & data = col_to->getData();
diff --git a/src/Functions/FunctionsJSON.h b/src/Functions/FunctionsJSON.h
index ca797eed856d..094de0c27c2c 100644
--- a/src/Functions/FunctionsJSON.h
+++ b/src/Functions/FunctionsJSON.h
@@ -336,7 +336,7 @@ class FunctionJSONHelpers
template typename Impl>
-class ExecutableFunctionJSON : public IExecutableFunction, WithContext
+class ExecutableFunctionJSON : public IExecutableFunction
{
public:
diff --git a/src/Functions/transform.cpp b/src/Functions/transform.cpp
index 16326dd5a44b..62ab51abd765 100644
--- a/src/Functions/transform.cpp
+++ b/src/Functions/transform.cpp
@@ -776,8 +776,12 @@ namespace
UInt64 key = 0;
auto * dst = reinterpret_cast(&key);
const auto ref = cache.from_column->getDataAt(i);
+
+#pragma clang diagnostic push
+#pragma clang diagnostic ignored "-Wunreachable-code"
if constexpr (std::endian::native == std::endian::big)
dst += sizeof(key) - ref.size;
+#pragma clang diagnostic pop
memcpy(dst, ref.data, ref.size);
table[key] = i;
diff --git a/src/IO/S3/Client.cpp b/src/IO/S3/Client.cpp
index 51c7ee325794..7e251dc415af 100644
--- a/src/IO/S3/Client.cpp
+++ b/src/IO/S3/Client.cpp
@@ -188,7 +188,7 @@ Client::Client(
}
}
- LOG_TRACE(log, "API mode: {}", toString(api_mode));
+ LOG_TRACE(log, "API mode of the S3 client: {}", api_mode);
detect_region = provider_type == ProviderType::AWS && explicit_region == Aws::Region::AWS_GLOBAL;
diff --git a/src/Interpreters/ClusterProxy/SelectStreamFactory.h b/src/Interpreters/ClusterProxy/SelectStreamFactory.h
index 1cc5a3b1a77e..ca07fd5dedaf 100644
--- a/src/Interpreters/ClusterProxy/SelectStreamFactory.h
+++ b/src/Interpreters/ClusterProxy/SelectStreamFactory.h
@@ -60,9 +60,6 @@ class SelectStreamFactory
/// (When there is a local replica with big delay).
bool lazy = false;
time_t local_delay = 0;
-
- /// Set only if parallel reading from replicas is used.
- std::shared_ptr coordinator;
};
using Shards = std::vector;
diff --git a/src/Interpreters/ClusterProxy/executeQuery.cpp b/src/Interpreters/ClusterProxy/executeQuery.cpp
index 2fed626ffb7e..f2d7132b1743 100644
--- a/src/Interpreters/ClusterProxy/executeQuery.cpp
+++ b/src/Interpreters/ClusterProxy/executeQuery.cpp
@@ -28,7 +28,6 @@ namespace DB
namespace ErrorCodes
{
extern const int TOO_LARGE_DISTRIBUTED_DEPTH;
- extern const int LOGICAL_ERROR;
extern const int SUPPORT_IS_DISABLED;
}
@@ -281,7 +280,6 @@ void executeQueryWithParallelReplicas(
auto all_replicas_count = std::min(static_cast(settings.max_parallel_replicas), new_cluster->getShardCount());
auto coordinator = std::make_shared(all_replicas_count);
auto remote_plan = std::make_unique();
- auto plans = std::vector();
/// This is a little bit weird, but we construct an "empty" coordinator without
/// any specified reading/coordination method (like Default, InOrder, InReverseOrder)
@@ -309,20 +307,7 @@ void executeQueryWithParallelReplicas(
&Poco::Logger::get("ReadFromParallelRemoteReplicasStep"),
query_info.storage_limits);
- remote_plan->addStep(std::move(read_from_remote));
- remote_plan->addInterpreterContext(context);
- plans.emplace_back(std::move(remote_plan));
-
- if (std::all_of(plans.begin(), plans.end(), [](const QueryPlanPtr & plan) { return !plan; }))
- throw Exception(ErrorCodes::LOGICAL_ERROR, "No plans were generated for reading from shard. This is a bug");
-
- DataStreams input_streams;
- input_streams.reserve(plans.size());
- for (const auto & plan : plans)
- input_streams.emplace_back(plan->getCurrentDataStream());
-
- auto union_step = std::make_unique(std::move(input_streams));
- query_plan.unitePlans(std::move(union_step), std::move(plans));
+ query_plan.addStep(std::move(read_from_remote));
}
}
diff --git a/src/Interpreters/InterpreterExplainQuery.cpp b/src/Interpreters/InterpreterExplainQuery.cpp
index 3a381cd8dab5..39cc4df5c2d0 100644
--- a/src/Interpreters/InterpreterExplainQuery.cpp
+++ b/src/Interpreters/InterpreterExplainQuery.cpp
@@ -541,13 +541,13 @@ QueryPipeline InterpreterExplainQuery::executeImpl()
InterpreterSelectWithUnionQuery interpreter(ast.getExplainedQuery(), getContext(), SelectQueryOptions());
interpreter.buildQueryPlan(plan);
context = interpreter.getContext();
- // collect the selected marks, rows, parts during build query pipeline.
- plan.buildQueryPipeline(
+ // Collect the selected marks, rows, parts during build query pipeline.
+ // Hold on to the returned QueryPipelineBuilderPtr because `plan` may have pointers into
+ // it (through QueryPlanResourceHolder).
+ auto builder = plan.buildQueryPipeline(
QueryPlanOptimizationSettings::fromContext(context),
BuildQueryPipelineSettings::fromContext(context));
- if (settings.optimize)
- plan.optimize(QueryPlanOptimizationSettings::fromContext(context));
plan.explainEstimate(res_columns);
insert_buf = false;
break;
diff --git a/src/Interpreters/InterpreterSelectQueryAnalyzer.cpp b/src/Interpreters/InterpreterSelectQueryAnalyzer.cpp
index 8db1d27c073a..b8cace5e0ad9 100644
--- a/src/Interpreters/InterpreterSelectQueryAnalyzer.cpp
+++ b/src/Interpreters/InterpreterSelectQueryAnalyzer.cpp
@@ -184,7 +184,7 @@ InterpreterSelectQueryAnalyzer::InterpreterSelectQueryAnalyzer(
, context(buildContext(context_, select_query_options_))
, select_query_options(select_query_options_)
, query_tree(query_tree_)
- , planner(query_tree_, select_query_options_)
+ , planner(query_tree_, select_query_options)
{
}
diff --git a/src/Interpreters/Session.cpp b/src/Interpreters/Session.cpp
index f8bd70afdb63..bcfaae40a039 100644
--- a/src/Interpreters/Session.cpp
+++ b/src/Interpreters/Session.cpp
@@ -299,6 +299,7 @@ Session::~Session()
if (notified_session_log_about_login)
{
+ LOG_DEBUG(log, "{} Logout, user_id: {}", toString(auth_id), toString(*user_id));
if (auto session_log = getSessionLog())
{
/// TODO: We have to ensure that the same info is added to the session log on a LoginSuccess event and on the corresponding Logout event.
@@ -320,6 +321,7 @@ AuthenticationType Session::getAuthenticationTypeOrLogInFailure(const String & u
}
catch (const Exception & e)
{
+ LOG_ERROR(log, "{} Authentication failed with error: {}", toString(auth_id), e.what());
if (auto session_log = getSessionLog())
session_log->addLoginFailure(auth_id, getClientInfo(), user_name, e);
diff --git a/src/Interpreters/executeQuery.cpp b/src/Interpreters/executeQuery.cpp
index 578ca3b41f9f..a56007375f43 100644
--- a/src/Interpreters/executeQuery.cpp
+++ b/src/Interpreters/executeQuery.cpp
@@ -45,6 +45,7 @@
#include
#include
#include
+#include
#include
#include
#include
@@ -1033,6 +1034,11 @@ static std::tuple executeQueryImpl(
}
+ // InterpreterSelectQueryAnalyzer does not build QueryPlan in the constructor.
+ // We need to force to build it here to check if we need to ignore quota.
+ if (auto * interpreter_with_analyzer = dynamic_cast(interpreter.get()))
+ interpreter_with_analyzer->getQueryPlan();
+
if (!interpreter->ignoreQuota() && !quota_checked)
{
quota = context->getQuota();
diff --git a/src/Planner/Planner.cpp b/src/Planner/Planner.cpp
index 9f6c22f90f39..7cce495dfb85 100644
--- a/src/Planner/Planner.cpp
+++ b/src/Planner/Planner.cpp
@@ -1047,7 +1047,7 @@ PlannerContextPtr buildPlannerContext(const QueryTreeNodePtr & query_tree_node,
}
Planner::Planner(const QueryTreeNodePtr & query_tree_,
- const SelectQueryOptions & select_query_options_)
+ SelectQueryOptions & select_query_options_)
: query_tree(query_tree_)
, select_query_options(select_query_options_)
, planner_context(buildPlannerContext(query_tree, select_query_options, std::make_shared()))
@@ -1055,7 +1055,7 @@ Planner::Planner(const QueryTreeNodePtr & query_tree_,
}
Planner::Planner(const QueryTreeNodePtr & query_tree_,
- const SelectQueryOptions & select_query_options_,
+ SelectQueryOptions & select_query_options_,
GlobalPlannerContextPtr global_planner_context_)
: query_tree(query_tree_)
, select_query_options(select_query_options_)
@@ -1064,7 +1064,7 @@ Planner::Planner(const QueryTreeNodePtr & query_tree_,
}
Planner::Planner(const QueryTreeNodePtr & query_tree_,
- const SelectQueryOptions & select_query_options_,
+ SelectQueryOptions & select_query_options_,
PlannerContextPtr planner_context_)
: query_tree(query_tree_)
, select_query_options(select_query_options_)
diff --git a/src/Planner/Planner.h b/src/Planner/Planner.h
index 783a07f6e997..f8d151365cfb 100644
--- a/src/Planner/Planner.h
+++ b/src/Planner/Planner.h
@@ -22,16 +22,16 @@ class Planner
public:
/// Initialize planner with query tree after analysis phase
Planner(const QueryTreeNodePtr & query_tree_,
- const SelectQueryOptions & select_query_options_);
+ SelectQueryOptions & select_query_options_);
/// Initialize planner with query tree after query analysis phase and global planner context
Planner(const QueryTreeNodePtr & query_tree_,
- const SelectQueryOptions & select_query_options_,
+ SelectQueryOptions & select_query_options_,
GlobalPlannerContextPtr global_planner_context_);
/// Initialize planner with query tree after query analysis phase and planner context
Planner(const QueryTreeNodePtr & query_tree_,
- const SelectQueryOptions & select_query_options_,
+ SelectQueryOptions & select_query_options_,
PlannerContextPtr planner_context_);
const QueryPlan & getQueryPlan() const
@@ -66,7 +66,7 @@ class Planner
void buildPlanForQueryNode();
QueryTreeNodePtr query_tree;
- SelectQueryOptions select_query_options;
+ SelectQueryOptions & select_query_options;
PlannerContextPtr planner_context;
QueryPlan query_plan;
StorageLimitsList storage_limits;
diff --git a/src/Planner/PlannerJoinTree.cpp b/src/Planner/PlannerJoinTree.cpp
index 56a48ce83282..f6ce029a2950 100644
--- a/src/Planner/PlannerJoinTree.cpp
+++ b/src/Planner/PlannerJoinTree.cpp
@@ -113,6 +113,20 @@ void checkAccessRights(const TableNode & table_node, const Names & column_names,
query_context->checkAccess(AccessType::SELECT, storage_id, column_names);
}
+bool shouldIgnoreQuotaAndLimits(const TableNode & table_node)
+{
+ const auto & storage_id = table_node.getStorageID();
+ if (!storage_id.hasDatabase())
+ return false;
+ if (storage_id.database_name == DatabaseCatalog::SYSTEM_DATABASE)
+ {
+ static const boost::container::flat_set tables_ignoring_quota{"quotas", "quota_limits", "quota_usage", "quotas_usage", "one"};
+ if (tables_ignoring_quota.count(storage_id.table_name))
+ return true;
+ }
+ return false;
+}
+
NameAndTypePair chooseSmallestColumnToReadFromStorage(const StoragePtr & storage, const StorageSnapshotPtr & storage_snapshot)
{
/** We need to read at least one column to find the number of rows.
@@ -828,8 +842,9 @@ JoinTreeQueryPlan buildQueryPlanForTableExpression(QueryTreeNodePtr table_expres
}
else
{
+ SelectQueryOptions analyze_query_options = SelectQueryOptions(from_stage).analyze();
Planner planner(select_query_info.query_tree,
- SelectQueryOptions(from_stage).analyze(),
+ analyze_query_options,
select_query_info.planner_context);
planner.buildQueryPlanIfNeeded();
@@ -1375,7 +1390,7 @@ JoinTreeQueryPlan buildQueryPlanForArrayJoinNode(const QueryTreeNodePtr & array_
JoinTreeQueryPlan buildJoinTreeQueryPlan(const QueryTreeNodePtr & query_node,
const SelectQueryInfo & select_query_info,
- const SelectQueryOptions & select_query_options,
+ SelectQueryOptions & select_query_options,
const ColumnIdentifierSet & outer_scope_columns,
PlannerContextPtr & planner_context)
{
@@ -1386,6 +1401,16 @@ JoinTreeQueryPlan buildJoinTreeQueryPlan(const QueryTreeNodePtr & query_node,
std::vector table_expressions_outer_scope_columns(table_expressions_stack_size);
ColumnIdentifierSet current_outer_scope_columns = outer_scope_columns;
+ if (is_single_table_expression)
+ {
+ auto * table_node = table_expressions_stack[0]->as();
+ if (table_node && shouldIgnoreQuotaAndLimits(*table_node))
+ {
+ select_query_options.ignore_quota = true;
+ select_query_options.ignore_limits = true;
+ }
+ }
+
/// For each table, table function, query, union table expressions prepare before query plan build
for (size_t i = 0; i < table_expressions_stack_size; ++i)
{
diff --git a/src/Planner/PlannerJoinTree.h b/src/Planner/PlannerJoinTree.h
index acbc96ddae0f..9d3b98175d09 100644
--- a/src/Planner/PlannerJoinTree.h
+++ b/src/Planner/PlannerJoinTree.h
@@ -20,7 +20,7 @@ struct JoinTreeQueryPlan
/// Build JOIN TREE query plan for query node
JoinTreeQueryPlan buildJoinTreeQueryPlan(const QueryTreeNodePtr & query_node,
const SelectQueryInfo & select_query_info,
- const SelectQueryOptions & select_query_options,
+ SelectQueryOptions & select_query_options,
const ColumnIdentifierSet & outer_scope_columns,
PlannerContextPtr & planner_context);
diff --git a/src/Processors/Formats/Impl/OneFormat.cpp b/src/Processors/Formats/Impl/OneFormat.cpp
new file mode 100644
index 000000000000..4a9c8caebf35
--- /dev/null
+++ b/src/Processors/Formats/Impl/OneFormat.cpp
@@ -0,0 +1,57 @@
+#include
+#include
+#include
+
+namespace DB
+{
+
+namespace ErrorCodes
+{
+ extern const int BAD_ARGUMENTS;
+}
+
+OneInputFormat::OneInputFormat(const Block & header, ReadBuffer & in_) : IInputFormat(header, &in_)
+{
+ if (header.columns() != 1)
+ throw Exception(ErrorCodes::BAD_ARGUMENTS,
+ "One input format is only suitable for tables with a single column of type UInt8 but the number of columns is {}",
+ header.columns());
+
+ if (!WhichDataType(header.getByPosition(0).type).isUInt8())
+ throw Exception(ErrorCodes::BAD_ARGUMENTS,
+ "One input format is only suitable for tables with a single column of type String but the column type is {}",
+ header.getByPosition(0).type->getName());
+}
+
+Chunk OneInputFormat::generate()
+{
+ if (done)
+ return {};
+
+ done = true;
+ auto column = ColumnUInt8::create();
+ column->insertDefault();
+ return Chunk(Columns{std::move(column)}, 1);
+}
+
+void registerInputFormatOne(FormatFactory & factory)
+{
+ factory.registerInputFormat("One", [](
+ ReadBuffer & buf,
+ const Block & sample,
+ const RowInputFormatParams &,
+ const FormatSettings &)
+ {
+ return std::make_shared(sample, buf);
+ });
+}
+
+void registerOneSchemaReader(FormatFactory & factory)
+{
+ factory.registerExternalSchemaReader("One", [](const FormatSettings &)
+ {
+ return std::make_shared();
+ });
+}
+
+}
diff --git a/src/Processors/Formats/Impl/OneFormat.h b/src/Processors/Formats/Impl/OneFormat.h
new file mode 100644
index 000000000000..f73b2dab66ac
--- /dev/null
+++ b/src/Processors/Formats/Impl/OneFormat.h
@@ -0,0 +1,32 @@
+#pragma once
+#include
+#include
+#include
+
+namespace DB
+{
+
+class OneInputFormat final : public IInputFormat
+{
+public:
+ OneInputFormat(const Block & header, ReadBuffer & in_);
+
+ String getName() const override { return "One"; }
+
+protected:
+ Chunk generate() override;
+
+private:
+ bool done = false;
+};
+
+class OneSchemaReader: public IExternalSchemaReader
+{
+public:
+ NamesAndTypesList readSchema() override
+ {
+ return {{"dummy", std::make_shared()}};
+ }
+};
+
+}
diff --git a/src/Processors/QueryPlan/Optimizations/Optimizations.h b/src/Processors/QueryPlan/Optimizations/Optimizations.h
index 6ecec1359c54..2230e50425c1 100644
--- a/src/Processors/QueryPlan/Optimizations/Optimizations.h
+++ b/src/Processors/QueryPlan/Optimizations/Optimizations.h
@@ -16,7 +16,7 @@ void optimizeTreeFirstPass(const QueryPlanOptimizationSettings & settings, Query
void optimizeTreeSecondPass(const QueryPlanOptimizationSettings & optimization_settings, QueryPlan::Node & root, QueryPlan::Nodes & nodes);
/// Third pass is used to apply filters such as key conditions and skip indexes to the storages that support them.
/// After that it add CreateSetsStep for the subqueries that has not be used in the filters.
-void optimizeTreeThirdPass(QueryPlan::Node & root, QueryPlan::Nodes & nodes);
+void optimizeTreeThirdPass(QueryPlan & plan, QueryPlan::Node & root, QueryPlan::Nodes & nodes);
/// Optimization (first pass) is a function applied to QueryPlan::Node.
/// It can read and update subtree of specified node.
@@ -113,7 +113,7 @@ void optimizeReadInOrder(QueryPlan::Node & node, QueryPlan::Nodes & nodes);
void optimizeAggregationInOrder(QueryPlan::Node & node, QueryPlan::Nodes &);
bool optimizeUseAggregateProjections(QueryPlan::Node & node, QueryPlan::Nodes & nodes, bool allow_implicit_projections);
bool optimizeUseNormalProjections(Stack & stack, QueryPlan::Nodes & nodes);
-bool addPlansForSets(QueryPlan::Node & node, QueryPlan::Nodes & nodes);
+bool addPlansForSets(QueryPlan & plan, QueryPlan::Node & node, QueryPlan::Nodes & nodes);
/// Enable memory bound merging of aggregation states for remote queries
/// in case it was enabled for local plan
diff --git a/src/Processors/QueryPlan/Optimizations/addPlansForSets.cpp b/src/Processors/QueryPlan/Optimizations/addPlansForSets.cpp
index e9100ae9d023..47df05301c95 100644
--- a/src/Processors/QueryPlan/Optimizations/addPlansForSets.cpp
+++ b/src/Processors/QueryPlan/Optimizations/addPlansForSets.cpp
@@ -6,7 +6,7 @@
namespace DB::QueryPlanOptimizations
{
-bool addPlansForSets(QueryPlan::Node & node, QueryPlan::Nodes & nodes)
+bool addPlansForSets(QueryPlan & root_plan, QueryPlan::Node & node, QueryPlan::Nodes & nodes)
{
auto * delayed = typeid_cast(node.step.get());
if (!delayed)
@@ -23,7 +23,9 @@ bool addPlansForSets(QueryPlan::Node & node, QueryPlan::Nodes & nodes)
{
input_streams.push_back(plan->getCurrentDataStream());
node.children.push_back(plan->getRootNode());
- nodes.splice(nodes.end(), QueryPlan::detachNodes(std::move(*plan)));
+ auto [add_nodes, add_resources] = QueryPlan::detachNodesAndResources(std::move(*plan));
+ nodes.splice(nodes.end(), std::move(add_nodes));
+ root_plan.addResources(std::move(add_resources));
}
auto creating_sets = std::make_unique(std::move(input_streams));
diff --git a/src/Processors/QueryPlan/Optimizations/optimizeTree.cpp b/src/Processors/QueryPlan/Optimizations/optimizeTree.cpp
index b13dda9a8f00..0caedff67a5d 100644
--- a/src/Processors/QueryPlan/Optimizations/optimizeTree.cpp
+++ b/src/Processors/QueryPlan/Optimizations/optimizeTree.cpp
@@ -181,7 +181,7 @@ void optimizeTreeSecondPass(const QueryPlanOptimizationSettings & optimization_s
"No projection is used when optimize_use_projections = 1 and force_optimize_projection = 1");
}
-void optimizeTreeThirdPass(QueryPlan::Node & root, QueryPlan::Nodes & nodes)
+void optimizeTreeThirdPass(QueryPlan & plan, QueryPlan::Node & root, QueryPlan::Nodes & nodes)
{
Stack stack;
stack.push_back({.node = &root});
@@ -205,7 +205,7 @@ void optimizeTreeThirdPass(QueryPlan::Node & root, QueryPlan::Nodes & nodes)
source_step_with_filter->applyFilters();
}
- addPlansForSets(*frame.node, nodes);
+ addPlansForSets(plan, *frame.node, nodes);
stack.pop_back();
}
diff --git a/src/Processors/QueryPlan/QueryPlan.cpp b/src/Processors/QueryPlan/QueryPlan.cpp
index 687260441ff3..ceda9f97babc 100644
--- a/src/Processors/QueryPlan/QueryPlan.cpp
+++ b/src/Processors/QueryPlan/QueryPlan.cpp
@@ -482,7 +482,7 @@ void QueryPlan::optimize(const QueryPlanOptimizationSettings & optimization_sett
QueryPlanOptimizations::optimizeTreeFirstPass(optimization_settings, *root, nodes);
QueryPlanOptimizations::optimizeTreeSecondPass(optimization_settings, *root, nodes);
- QueryPlanOptimizations::optimizeTreeThirdPass(*root, nodes);
+ QueryPlanOptimizations::optimizeTreeThirdPass(*this, *root, nodes);
updateDataStreams(*root);
}
@@ -542,9 +542,9 @@ void QueryPlan::explainEstimate(MutableColumns & columns)
}
}
-QueryPlan::Nodes QueryPlan::detachNodes(QueryPlan && plan)
+std::pair QueryPlan::detachNodesAndResources(QueryPlan && plan)
{
- return std::move(plan.nodes);
+ return {std::move(plan.nodes), std::move(plan.resources)};
}
}
diff --git a/src/Processors/QueryPlan/QueryPlan.h b/src/Processors/QueryPlan/QueryPlan.h
index d89bdc534be0..f4a6c9097f2f 100644
--- a/src/Processors/QueryPlan/QueryPlan.h
+++ b/src/Processors/QueryPlan/QueryPlan.h
@@ -108,7 +108,7 @@ class QueryPlan
using Nodes = std::list;
Node * getRootNode() const { return root; }
- static Nodes detachNodes(QueryPlan && plan);
+ static std::pair detachNodesAndResources(QueryPlan && plan);
private:
QueryPlanResourceHolder resources;
diff --git a/src/Storages/MergeTree/IMergeTreeDataPart.cpp b/src/Storages/MergeTree/IMergeTreeDataPart.cpp
index 1bbec3f1948b..fe6d1a6e6582 100644
--- a/src/Storages/MergeTree/IMergeTreeDataPart.cpp
+++ b/src/Storages/MergeTree/IMergeTreeDataPart.cpp
@@ -1780,7 +1780,8 @@ void IMergeTreeDataPart::renameToDetached(const String & prefix)
part_is_probably_removed_from_disk = true;
}
-DataPartStoragePtr IMergeTreeDataPart::makeCloneInDetached(const String & prefix, const StorageMetadataPtr & /*metadata_snapshot*/) const
+DataPartStoragePtr IMergeTreeDataPart::makeCloneInDetached(const String & prefix, const StorageMetadataPtr & /*metadata_snapshot*/,
+ const DiskTransactionPtr & disk_transaction) const
{
/// Avoid unneeded duplicates of broken parts if we try to detach the same broken part multiple times.
/// Otherwise it may pollute detached/ with dirs with _tryN suffix and we will fail to remove broken part after 10 attempts.
@@ -1795,7 +1796,8 @@ DataPartStoragePtr IMergeTreeDataPart::makeCloneInDetached(const String & prefix
IDataPartStorage::ClonePartParams params
{
.copy_instead_of_hardlink = isStoredOnRemoteDiskWithZeroCopySupport() && storage.supportsReplication() && storage_settings->allow_remote_fs_zero_copy_replication,
- .make_source_readonly = true
+ .make_source_readonly = true,
+ .external_transaction = disk_transaction
};
return getDataPartStorage().freeze(
storage.relative_data_path,
diff --git a/src/Storages/MergeTree/IMergeTreeDataPart.h b/src/Storages/MergeTree/IMergeTreeDataPart.h
index 07f977799de7..a8e053a9c7bf 100644
--- a/src/Storages/MergeTree/IMergeTreeDataPart.h
+++ b/src/Storages/MergeTree/IMergeTreeDataPart.h
@@ -371,7 +371,8 @@ class IMergeTreeDataPart : public std::enable_shared_from_this time_t
+ {
+ auto path = fs::path(relative_data_path) / "detached" / part_info.dir_name;
+ time_t last_change_time = part_info.disk->getLastChanged(path);
+ time_t last_modification_time = part_info.disk->getLastModified(path).epochTime();
+ return std::max(last_change_time, last_modification_time);
+ };
+ time_t ttl_seconds = getSettings()->merge_tree_clear_old_broken_detached_parts_ttl_timeout_seconds;
+
+ size_t unfinished_deleting_parts = 0;
+ time_t current_time = time(nullptr);
+ for (const auto & part_info : detached_parts)
+ {
+ if (!part_info.dir_name.starts_with("deleting_"))
+ continue;
+
+ time_t startup_time = current_time - static_cast(Context::getGlobalContextInstance()->getUptimeSeconds());
+ time_t last_touch_time = get_last_touched_time(part_info);
+
+ /// Maybe it's being deleted right now (for example, in ALTER DROP DETACHED)
+ bool had_restart = last_touch_time < startup_time;
+ bool ttl_expired = last_touch_time + ttl_seconds <= current_time;
+ if (!had_restart && !ttl_expired)
+ continue;
+
+ /// We were trying to delete this detached part but did not finish deleting, probably because the server crashed
+ LOG_INFO(log, "Removing detached part {} that we failed to remove previously", part_info.dir_name);
+ try
+ {
+ removeDetachedPart(part_info.disk, fs::path(relative_data_path) / "detached" / part_info.dir_name / "", part_info.dir_name);
+ ++unfinished_deleting_parts;
+ }
+ catch (...)
+ {
+ tryLogCurrentException(log);
+ }
+ }
+
+ if (!getSettings()->merge_tree_enable_clear_old_broken_detached)
+ return unfinished_deleting_parts;
+
+ const auto full_path = fs::path(relative_data_path) / "detached";
+ size_t removed_count = 0;
for (const auto & part_info : detached_parts)
{
if (!part_info.valid_name || part_info.prefix.empty())
@@ -2635,31 +2677,24 @@ size_t MergeTreeData::clearOldBrokenPartsFromDetachedDirectory()
if (!can_be_removed_by_timeout)
continue;
- time_t current_time = time(nullptr);
- ssize_t threshold = current_time - getSettings()->merge_tree_clear_old_broken_detached_parts_ttl_timeout_seconds;
- auto path = fs::path(relative_data_path) / "detached" / part_info.dir_name;
- time_t last_change_time = part_info.disk->getLastChanged(path);
- time_t last_modification_time = part_info.disk->getLastModified(path).epochTime();
- time_t last_touch_time = std::max(last_change_time, last_modification_time);
+ ssize_t threshold = current_time - ttl_seconds;
+ time_t last_touch_time = get_last_touched_time(part_info);
if (last_touch_time == 0 || last_touch_time >= threshold)
continue;
- renamed_parts.addPart(part_info.dir_name, "deleting_" + part_info.dir_name, part_info.disk);
- }
-
- LOG_INFO(log, "Will clean up {} detached parts", renamed_parts.old_and_new_names.size());
+ const String & old_name = part_info.dir_name;
+ String new_name = "deleting_" + part_info.dir_name;
+ part_info.disk->moveFile(fs::path(full_path) / old_name, fs::path(full_path) / new_name);
- renamed_parts.tryRenameAll();
-
- for (auto & [old_name, new_name, disk] : renamed_parts.old_and_new_names)
- {
- removeDetachedPart(disk, fs::path(relative_data_path) / "detached" / new_name / "", old_name);
+ removeDetachedPart(part_info.disk, fs::path(relative_data_path) / "detached" / new_name / "", old_name);
LOG_WARNING(log, "Removed broken detached part {} due to a timeout for broken detached parts", old_name);
- old_name.clear();
+ ++removed_count;
}
- return renamed_parts.old_and_new_names.size();
+ LOG_INFO(log, "Cleaned up {} detached parts", removed_count);
+
+ return removed_count + unfinished_deleting_parts;
}
size_t MergeTreeData::clearOldWriteAheadLogs()
@@ -4035,7 +4070,7 @@ void MergeTreeData::restoreAndActivatePart(const DataPartPtr & part, DataPartsLo
void MergeTreeData::outdateUnexpectedPartAndCloneToDetached(const DataPartPtr & part_to_detach)
{
LOG_INFO(log, "Cloning part {} to unexpected_{} and making it obsolete.", part_to_detach->getDataPartStorage().getPartDirectory(), part_to_detach->name);
- part_to_detach->makeCloneInDetached("unexpected", getInMemoryMetadataPtr());
+ part_to_detach->makeCloneInDetached("unexpected", getInMemoryMetadataPtr(), /*disk_transaction*/ {});
DataPartsLock lock = lockParts();
part_to_detach->is_unexpected_local_part = true;
@@ -5797,18 +5832,21 @@ MergeTreeData::MutableDataPartsVector MergeTreeData::tryLoadPartsToAttach(const
{
const String source_dir = "detached/";
- std::map name_to_disk;
-
/// Let's compose a list of parts that should be added.
if (attach_part)
{
const String part_id = partition->as().value.safeGet();
validateDetachedPartName(part_id);
- auto disk = getDiskForDetachedPart(part_id);
- renamed_parts.addPart(part_id, "attaching_" + part_id, disk);
-
- if (MergeTreePartInfo::tryParsePartName(part_id, format_version))
- name_to_disk[part_id] = getDiskForDetachedPart(part_id);
+ if (temporary_parts.contains(String(DETACHED_DIR_NAME) + "/" + part_id))
+ {
+ LOG_WARNING(log, "Will not try to attach part {} because its directory is temporary, "
+ "probably it's being detached right now", part_id);
+ }
+ else
+ {
+ auto disk = getDiskForDetachedPart(part_id);
+ renamed_parts.addPart(part_id, "attaching_" + part_id, disk);
+ }
}
else
{
@@ -5825,6 +5863,12 @@ MergeTreeData::MutableDataPartsVector MergeTreeData::tryLoadPartsToAttach(const
for (const auto & part_info : detached_parts)
{
+ if (temporary_parts.contains(String(DETACHED_DIR_NAME) + "/" + part_info.dir_name))
+ {
+ LOG_WARNING(log, "Will not try to attach part {} because its directory is temporary, "
+ "probably it's being detached right now", part_info.dir_name);
+ continue;
+ }
LOG_DEBUG(log, "Found part {}", part_info.dir_name);
active_parts.add(part_info.dir_name);
}
@@ -5835,6 +5879,8 @@ MergeTreeData::MutableDataPartsVector MergeTreeData::tryLoadPartsToAttach(const
for (const auto & part_info : detached_parts)
{
const String containing_part = active_parts.getContainingPart(part_info.dir_name);
+ if (containing_part.empty())
+ continue;
LOG_DEBUG(log, "Found containing part {} for part {}", containing_part, part_info.dir_name);
@@ -8435,7 +8481,7 @@ void MergeTreeData::incrementMergedPartsProfileEvent(MergeTreeDataPartType type)
}
}
-MergeTreeData::MutableDataPartPtr MergeTreeData::createEmptyPart(
+std::pair MergeTreeData::createEmptyPart(
MergeTreePartInfo & new_part_info, const MergeTreePartition & partition, const String & new_part_name,
const MergeTreeTransactionPtr & txn)
{
@@ -8454,6 +8500,7 @@ MergeTreeData::MutableDataPartPtr MergeTreeData::createEmptyPart(
ReservationPtr reservation = reserveSpacePreferringTTLRules(metadata_snapshot, 0, move_ttl_infos, time(nullptr), 0, true);
VolumePtr data_part_volume = createVolumeFromReservation(reservation, volume);
+ auto tmp_dir_holder = getTemporaryPartDirectoryHolder(EMPTY_PART_TMP_PREFIX + new_part_name);
auto new_data_part = getDataPartBuilder(new_part_name, data_part_volume, EMPTY_PART_TMP_PREFIX + new_part_name)
.withBytesAndRowsOnDisk(0, 0)
.withPartInfo(new_part_info)
@@ -8513,7 +8560,7 @@ MergeTreeData::MutableDataPartPtr MergeTreeData::createEmptyPart(
out.finalizePart(new_data_part, sync_on_insert);
new_data_part_storage->precommitTransaction();
- return new_data_part;
+ return std::make_pair(std::move(new_data_part), std::move(tmp_dir_holder));
}
bool MergeTreeData::allowRemoveStaleMovingParts() const
diff --git a/src/Storages/MergeTree/MergeTreeData.h b/src/Storages/MergeTree/MergeTreeData.h
index 9ee611347403..e4801cffa36a 100644
--- a/src/Storages/MergeTree/MergeTreeData.h
+++ b/src/Storages/MergeTree/MergeTreeData.h
@@ -936,7 +936,9 @@ class MergeTreeData : public IStorage, public WithMutableContext
WriteAheadLogPtr getWriteAheadLog();
constexpr static auto EMPTY_PART_TMP_PREFIX = "tmp_empty_";
- MergeTreeData::MutableDataPartPtr createEmptyPart(MergeTreePartInfo & new_part_info, const MergeTreePartition & partition, const String & new_part_name, const MergeTreeTransactionPtr & txn);
+ std::pair createEmptyPart(
+ MergeTreePartInfo & new_part_info, const MergeTreePartition & partition,
+ const String & new_part_name, const MergeTreeTransactionPtr & txn);
MergeTreeDataFormatVersion format_version;
diff --git a/src/Storages/MergeTree/MergeTreeDataPartChecksum.cpp b/src/Storages/MergeTree/MergeTreeDataPartChecksum.cpp
index 6628cd68eaf5..5a7b2dfbca8d 100644
--- a/src/Storages/MergeTree/MergeTreeDataPartChecksum.cpp
+++ b/src/Storages/MergeTree/MergeTreeDataPartChecksum.cpp
@@ -187,15 +187,15 @@ bool MergeTreeDataPartChecksums::readV3(ReadBuffer & in)
String name;
Checksum sum;
- readBinary(name, in);
+ readStringBinary(name, in);
readVarUInt(sum.file_size, in);
- readPODBinary(sum.file_hash, in);
- readBinary(sum.is_compressed, in);
+ readBinaryLittleEndian(sum.file_hash, in);
+ readBinaryLittleEndian(sum.is_compressed, in);
if (sum.is_compressed)
{
readVarUInt(sum.uncompressed_size, in);
- readPODBinary(sum.uncompressed_hash, in);
+ readBinaryLittleEndian(sum.uncompressed_hash, in);
}
files.emplace(std::move(name), sum);
@@ -223,15 +223,15 @@ void MergeTreeDataPartChecksums::write(WriteBuffer & to) const
const String & name = it.first;
const Checksum & sum = it.second;
- writeBinary(name, out);
+ writeStringBinary(name, out);
writeVarUInt(sum.file_size, out);
- writePODBinary(sum.file_hash, out);
- writeBinary(sum.is_compressed, out);
+ writeBinaryLittleEndian(sum.file_hash, out);
+ writeBinaryLittleEndian(sum.is_compressed, out);
if (sum.is_compressed)
{
writeVarUInt(sum.uncompressed_size, out);
- writePODBinary(sum.uncompressed_hash, out);
+ writeBinaryLittleEndian(sum.uncompressed_hash, out);
}
}
}
@@ -339,9 +339,9 @@ void MinimalisticDataPartChecksums::serializeWithoutHeader(WriteBuffer & to) con
writeVarUInt(num_compressed_files, to);
writeVarUInt(num_uncompressed_files, to);
- writePODBinary(hash_of_all_files, to);
- writePODBinary(hash_of_uncompressed_files, to);
- writePODBinary(uncompressed_hash_of_compressed_files, to);
+ writeBinaryLittleEndian(hash_of_all_files, to);
+ writeBinaryLittleEndian(hash_of_uncompressed_files, to);
+ writeBinaryLittleEndian(uncompressed_hash_of_compressed_files, to);
}
String MinimalisticDataPartChecksums::getSerializedString() const
@@ -382,9 +382,9 @@ void MinimalisticDataPartChecksums::deserializeWithoutHeader(ReadBuffer & in)
readVarUInt(num_compressed_files, in);
readVarUInt(num_uncompressed_files, in);
- readPODBinary(hash_of_all_files, in);
- readPODBinary(hash_of_uncompressed_files, in);
- readPODBinary(uncompressed_hash_of_compressed_files, in);
+ readBinaryLittleEndian(hash_of_all_files, in);
+ readBinaryLittleEndian(hash_of_uncompressed_files, in);
+ readBinaryLittleEndian(uncompressed_hash_of_compressed_files, in);
}
void MinimalisticDataPartChecksums::computeTotalChecksums(const MergeTreeDataPartChecksums & full_checksums_)
diff --git a/src/Storages/MergeTree/MergeTreeDataPartInMemory.cpp b/src/Storages/MergeTree/MergeTreeDataPartInMemory.cpp
index ba300b110d78..d8034e62802e 100644
--- a/src/Storages/MergeTree/MergeTreeDataPartInMemory.cpp
+++ b/src/Storages/MergeTree/MergeTreeDataPartInMemory.cpp
@@ -17,6 +17,7 @@ namespace DB
namespace ErrorCodes
{
extern const int DIRECTORY_ALREADY_EXISTS;
+ extern const int NOT_IMPLEMENTED;
}
MergeTreeDataPartInMemory::MergeTreeDataPartInMemory(
@@ -138,8 +139,12 @@ MutableDataPartStoragePtr MergeTreeDataPartInMemory::flushToDisk(const String &
return new_data_part_storage;
}
-DataPartStoragePtr MergeTreeDataPartInMemory::makeCloneInDetached(const String & prefix, const StorageMetadataPtr & metadata_snapshot) const
+DataPartStoragePtr MergeTreeDataPartInMemory::makeCloneInDetached(const String & prefix,
+ const StorageMetadataPtr & metadata_snapshot,
+ const DiskTransactionPtr & disk_transaction) const
{
+ if (disk_transaction)
+ throw Exception(ErrorCodes::NOT_IMPLEMENTED, "InMemory parts are not compatible with disk transactions");
String detached_path = *getRelativePathForDetachedPart(prefix, /* broken */ false);
return flushToDisk(detached_path, metadata_snapshot);
}
diff --git a/src/Storages/MergeTree/MergeTreeDataPartInMemory.h b/src/Storages/MergeTree/MergeTreeDataPartInMemory.h
index 81549eeed3ee..95f7b796f9ad 100644
--- a/src/Storages/MergeTree/MergeTreeDataPartInMemory.h
+++ b/src/Storages/MergeTree/MergeTreeDataPartInMemory.h
@@ -42,7 +42,8 @@ class MergeTreeDataPartInMemory : public IMergeTreeDataPart
bool hasColumnFiles(const NameAndTypePair & column) const override { return !!getColumnPosition(column.getNameInStorage()); }
String getFileNameForColumn(const NameAndTypePair & /* column */) const override { return ""; }
void renameTo(const String & new_relative_path, bool remove_new_dir_if_exists) override;
- DataPartStoragePtr makeCloneInDetached(const String & prefix, const StorageMetadataPtr & metadata_snapshot) const override;
+ DataPartStoragePtr makeCloneInDetached(const String & prefix, const StorageMetadataPtr & metadata_snapshot,
+ const DiskTransactionPtr & disk_transaction) const override;
std::optional getColumnModificationTime(const String & /* column_name */) const override { return {}; }
MutableDataPartStoragePtr flushToDisk(const String & new_relative_path, const StorageMetadataPtr & metadata_snapshot) const;
diff --git a/src/Storages/MergeTree/MergeTreeDataPartWriterCompact.cpp b/src/Storages/MergeTree/MergeTreeDataPartWriterCompact.cpp
index 5e1da21da5ba..75e6aca07937 100644
--- a/src/Storages/MergeTree/MergeTreeDataPartWriterCompact.cpp
+++ b/src/Storages/MergeTree/MergeTreeDataPartWriterCompact.cpp
@@ -365,8 +365,9 @@ void MergeTreeDataPartWriterCompact::addToChecksums(MergeTreeDataPartChecksums &
{
uncompressed_size += stream->hashing_buf.count();
auto stream_hash = stream->hashing_buf.getHash();
+ transformEndianness(stream_hash);
uncompressed_hash = CityHash_v1_0_2::CityHash128WithSeed(
- reinterpret_cast(&stream_hash), sizeof(stream_hash), uncompressed_hash);
+ reinterpret_cast(&stream_hash), sizeof(stream_hash), uncompressed_hash);
}
checksums.files[data_file_name].is_compressed = true;
diff --git a/src/Storages/MergeTree/ReplicatedMergeTreeCleanupThread.cpp b/src/Storages/MergeTree/ReplicatedMergeTreeCleanupThread.cpp
index 07cfced8362e..b72c148a4e8a 100644
--- a/src/Storages/MergeTree/ReplicatedMergeTreeCleanupThread.cpp
+++ b/src/Storages/MergeTree/ReplicatedMergeTreeCleanupThread.cpp
@@ -149,8 +149,7 @@ Float32 ReplicatedMergeTreeCleanupThread::iterate()
/// do it under share lock
cleaned_other += storage.clearOldWriteAheadLogs();
cleaned_part_like += storage.clearOldTemporaryDirectories(storage.getSettings()->temporary_directories_lifetime.totalSeconds());
- if (storage.getSettings()->merge_tree_enable_clear_old_broken_detached)
- cleaned_part_like += storage.clearOldBrokenPartsFromDetachedDirectory();
+ cleaned_part_like += storage.clearOldBrokenPartsFromDetachedDirectory();
}
/// This is loose condition: no problem if we actually had lost leadership at this moment
diff --git a/src/Storages/MergeTree/ReplicatedMergeTreeSink.cpp b/src/Storages/MergeTree/ReplicatedMergeTreeSink.cpp
index 0db3464a6371..fa5a40cf27a5 100644
--- a/src/Storages/MergeTree/ReplicatedMergeTreeSink.cpp
+++ b/src/Storages/MergeTree/ReplicatedMergeTreeSink.cpp
@@ -633,8 +633,8 @@ void ReplicatedMergeTreeSinkImpl::finishDelayedChunk(const ZooKeeperWithFa
delayed_chunk.reset();
}
-template
-void ReplicatedMergeTreeSinkImpl::writeExistingPart(MergeTreeData::MutableDataPartPtr & part)
+template<>
+bool ReplicatedMergeTreeSinkImpl::writeExistingPart(MergeTreeData::MutableDataPartPtr & part)
{
/// NOTE: No delay in this case. That's Ok.
auto origin_zookeeper = storage.getZooKeeper();
@@ -649,8 +649,13 @@ void ReplicatedMergeTreeSinkImpl::writeExistingPart(MergeTreeData:
try
{
part->version.setCreationTID(Tx::PrehistoricTID, nullptr);
- commitPart(zookeeper, part, BlockIDsType(), replicas_num, true);
- PartLog::addNewPart(storage.getContext(), PartLog::PartLogEntry(part, watch.elapsed(), profile_events_scope.getSnapshot()));
+ String block_id = deduplicate ? fmt::format("{}_{}", part->info.partition_id, part->checksums.getTotalChecksumHex()) : "";
+ bool deduplicated = commitPart(zookeeper, part, block_id, replicas_num, /* writing_existing_part */ true).second;
+
+ /// Set a special error code if the block is duplicate
+ int error = (deduplicate && deduplicated) ? ErrorCodes::INSERT_WAS_DEDUPLICATED : 0;
+ PartLog::addNewPart(storage.getContext(), PartLog::PartLogEntry(part, watch.elapsed(), profile_events_scope.getSnapshot()), ExecutionStatus(error));
+ return deduplicated;
}
catch (...)
{
diff --git a/src/Storages/MergeTree/ReplicatedMergeTreeSink.h b/src/Storages/MergeTree/ReplicatedMergeTreeSink.h
index 868590efa257..4a192a822f5b 100644
--- a/src/Storages/MergeTree/ReplicatedMergeTreeSink.h
+++ b/src/Storages/MergeTree/ReplicatedMergeTreeSink.h
@@ -56,7 +56,7 @@ class ReplicatedMergeTreeSinkImpl : public SinkToStorage
String getName() const override { return "ReplicatedMergeTreeSink"; }
/// For ATTACHing existing data on filesystem.
- void writeExistingPart(MergeTreeData::MutableDataPartPtr & part);
+ bool writeExistingPart(MergeTreeData::MutableDataPartPtr & part);
/// For proper deduplication in MaterializedViews
bool lastBlockIsDuplicate() const override
diff --git a/src/Storages/StorageDistributed.cpp b/src/Storages/StorageDistributed.cpp
index a7aeb11e2d85..f80e498efa86 100644
--- a/src/Storages/StorageDistributed.cpp
+++ b/src/Storages/StorageDistributed.cpp
@@ -691,7 +691,11 @@ QueryTreeNodePtr buildQueryTreeDistributed(SelectQueryInfo & query_info,
if (remote_storage_id.hasDatabase())
resolved_remote_storage_id = query_context->resolveStorageID(remote_storage_id);
- auto storage = std::make_shared(resolved_remote_storage_id, distributed_storage_snapshot->metadata->getColumns(), distributed_storage_snapshot->object_columns);
+ auto get_column_options = GetColumnsOptions(GetColumnsOptions::All).withExtendedObjects().withVirtuals();
+
+ auto column_names_and_types = distributed_storage_snapshot->getColumns(get_column_options);
+
+ auto storage = std::make_shared(resolved_remote_storage_id, ColumnsDescription{column_names_and_types});
auto table_node = std::make_shared(std::move(storage), query_context);
if (table_expression_modifiers)
diff --git a/src/Storages/StorageMergeTree.cpp b/src/Storages/StorageMergeTree.cpp
index ad9013d9f131..3a9449ba51f0 100644
--- a/src/Storages/StorageMergeTree.cpp
+++ b/src/Storages/StorageMergeTree.cpp
@@ -1379,8 +1379,7 @@ bool StorageMergeTree::scheduleDataProcessingJob(BackgroundJobsAssignee & assign
cleared_count += clearOldWriteAheadLogs();
cleared_count += clearOldMutations();
cleared_count += clearEmptyParts();
- if (getSettings()->merge_tree_enable_clear_old_broken_detached)
- cleared_count += clearOldBrokenPartsFromDetachedDirectory();
+ cleared_count += clearOldBrokenPartsFromDetachedDirectory();
return cleared_count;
/// TODO maybe take into account number of cleared objects when calculating backoff
}, common_assignee_trigger, getStorageID()), /* need_trigger */ false);
@@ -1653,11 +1652,7 @@ struct FutureNewEmptyPart
MergeTreePartition partition;
std::string part_name;
- scope_guard tmp_dir_guard;
-
StorageMergeTree::MutableDataPartPtr data_part;
-
- std::string getDirName() const { return StorageMergeTree::EMPTY_PART_TMP_PREFIX + part_name; }
};
using FutureNewEmptyParts = std::vector;
@@ -1688,19 +1683,19 @@ FutureNewEmptyParts initCoverageWithNewEmptyParts(const DataPartsVector & old_pa
return future_parts;
}
-StorageMergeTree::MutableDataPartsVector createEmptyDataParts(MergeTreeData & data, FutureNewEmptyParts & future_parts, const MergeTreeTransactionPtr & txn)
+std::pair> createEmptyDataParts(
+ MergeTreeData & data, FutureNewEmptyParts & future_parts, const MergeTreeTransactionPtr & txn)
{
- StorageMergeTree::MutableDataPartsVector data_parts;
+ std::pair> data_parts;
for (auto & part: future_parts)
- data_parts.push_back(data.createEmptyPart(part.part_info, part.partition, part.part_name, txn));
+ {
+ auto [new_data_part, tmp_dir_holder] = data.createEmptyPart(part.part_info, part.partition, part.part_name, txn);
+ data_parts.first.emplace_back(std::move(new_data_part));
+ data_parts.second.emplace_back(std::move(tmp_dir_holder));
+ }
return data_parts;
}
-void captureTmpDirectoryHolders(MergeTreeData & data, FutureNewEmptyParts & future_parts)
-{
- for (auto & part : future_parts)
- part.tmp_dir_guard = data.getTemporaryPartDirectoryHolder(part.getDirName());
-}
void StorageMergeTree::renameAndCommitEmptyParts(MutableDataPartsVector & new_parts, Transaction & transaction)
{
@@ -1767,9 +1762,7 @@ void StorageMergeTree::truncate(const ASTPtr &, const StorageMetadataPtr &, Cont
fmt::join(getPartsNames(future_parts), ", "), fmt::join(getPartsNames(parts), ", "),
transaction.getTID());
- captureTmpDirectoryHolders(*this, future_parts);
-
- auto new_data_parts = createEmptyDataParts(*this, future_parts, txn);
+ auto [new_data_parts, tmp_dir_holders] = createEmptyDataParts(*this, future_parts, txn);
renameAndCommitEmptyParts(new_data_parts, transaction);
PartLog::addNewParts(query_context, PartLog::createPartLogEntries(new_data_parts, watch.elapsed(), profile_events_scope.getSnapshot()));
@@ -1817,8 +1810,10 @@ void StorageMergeTree::dropPart(const String & part_name, bool detach, ContextPt
if (detach)
{
auto metadata_snapshot = getInMemoryMetadataPtr();
- LOG_INFO(log, "Detaching {}", part->getDataPartStorage().getPartDirectory());
- part->makeCloneInDetached("", metadata_snapshot);
+ String part_dir = part->getDataPartStorage().getPartDirectory();
+ LOG_INFO(log, "Detaching {}", part_dir);
+ auto holder = getTemporaryPartDirectoryHolder(String(DETACHED_DIR_NAME) + "/" + part_dir);
+ part->makeCloneInDetached("", metadata_snapshot, /*disk_transaction*/ {});
}
{
@@ -1828,9 +1823,7 @@ void StorageMergeTree::dropPart(const String & part_name, bool detach, ContextPt
fmt::join(getPartsNames(future_parts), ", "), fmt::join(getPartsNames({part}), ", "),
transaction.getTID());
- captureTmpDirectoryHolders(*this, future_parts);
-
- auto new_data_parts = createEmptyDataParts(*this, future_parts, txn);
+ auto [new_data_parts, tmp_dir_holders] = createEmptyDataParts(*this, future_parts, txn);
renameAndCommitEmptyParts(new_data_parts, transaction);
PartLog::addNewParts(query_context, PartLog::createPartLogEntries(new_data_parts, watch.elapsed(), profile_events_scope.getSnapshot()));
@@ -1902,8 +1895,10 @@ void StorageMergeTree::dropPartition(const ASTPtr & partition, bool detach, Cont
for (const auto & part : parts)
{
auto metadata_snapshot = getInMemoryMetadataPtr();
- LOG_INFO(log, "Detaching {}", part->getDataPartStorage().getPartDirectory());
- part->makeCloneInDetached("", metadata_snapshot);
+ String part_dir = part->getDataPartStorage().getPartDirectory();
+ LOG_INFO(log, "Detaching {}", part_dir);
+ auto holder = getTemporaryPartDirectoryHolder(String(DETACHED_DIR_NAME) + "/" + part_dir);
+ part->makeCloneInDetached("", metadata_snapshot, /*disk_transaction*/ {});
}
}
@@ -1914,9 +1909,8 @@ void StorageMergeTree::dropPartition(const ASTPtr & partition, bool detach, Cont
fmt::join(getPartsNames(future_parts), ", "), fmt::join(getPartsNames(parts), ", "),
transaction.getTID());
- captureTmpDirectoryHolders(*this, future_parts);
- auto new_data_parts = createEmptyDataParts(*this, future_parts, txn);
+ auto [new_data_parts, tmp_dir_holders] = createEmptyDataParts(*this, future_parts, txn);
renameAndCommitEmptyParts(new_data_parts, transaction);
PartLog::addNewParts(query_context, PartLog::createPartLogEntries(new_data_parts, watch.elapsed(), profile_events_scope.getSnapshot()));
@@ -1944,8 +1938,10 @@ void StorageMergeTree::dropPartsImpl(DataPartsVector && parts_to_remove, bool de
/// NOTE: no race with background cleanup until we hold pointers to parts
for (const auto & part : parts_to_remove)
{
- LOG_INFO(log, "Detaching {}", part->getDataPartStorage().getPartDirectory());
- part->makeCloneInDetached("", metadata_snapshot);
+ String part_dir = part->getDataPartStorage().getPartDirectory();
+ LOG_INFO(log, "Detaching {}", part_dir);
+ auto holder = getTemporaryPartDirectoryHolder(String(DETACHED_DIR_NAME) + "/" + part_dir);
+ part->makeCloneInDetached("", metadata_snapshot, /*disk_transaction*/ {});
}
}
diff --git a/src/Storages/StorageReplicatedMergeTree.cpp b/src/Storages/StorageReplicatedMergeTree.cpp
index 7fce373e26bc..5b7b36a1de36 100644
--- a/src/Storages/StorageReplicatedMergeTree.cpp
+++ b/src/Storages/StorageReplicatedMergeTree.cpp
@@ -2097,8 +2097,10 @@ void StorageReplicatedMergeTree::executeDropRange(const LogEntry & entry)
{
if (auto part_to_detach = part.getPartIfItWasActive())
{
- LOG_INFO(log, "Detaching {}", part_to_detach->getDataPartStorage().getPartDirectory());
- part_to_detach->makeCloneInDetached("", metadata_snapshot);
+ String part_dir = part_to_detach->getDataPartStorage().getPartDirectory();
+ LOG_INFO(log, "Detaching {}", part_dir);
+ auto holder = getTemporaryPartDirectoryHolder(String(DETACHED_DIR_NAME) + "/" + part_dir);
+ part_to_detach->makeCloneInDetached("", metadata_snapshot, /*disk_transaction*/ {});
}
}
}
@@ -2828,7 +2830,7 @@ void StorageReplicatedMergeTree::cloneReplica(const String & source_replica, Coo
for (const auto & part : parts_to_remove_from_working_set)
{
LOG_INFO(log, "Detaching {}", part->getDataPartStorage().getPartDirectory());
- part->makeCloneInDetached("clone", metadata_snapshot);
+ part->makeCloneInDetached("clone", metadata_snapshot, /*disk_transaction*/ {});
}
}
@@ -3794,12 +3796,12 @@ void StorageReplicatedMergeTree::removePartAndEnqueueFetch(const String & part_n
chassert(!broken_part);
chassert(!storage_init);
part->was_removed_as_broken = true;
- part->makeCloneInDetached("broken", getInMemoryMetadataPtr());
+ part->makeCloneInDetached("broken", getInMemoryMetadataPtr(), /*disk_transaction*/ {});
broken_part = part;
}
else
{
- part->makeCloneInDetached("covered-by-broken", getInMemoryMetadataPtr());
+ part->makeCloneInDetached("covered-by-broken", getInMemoryMetadataPtr(), /*disk_transaction*/ {});
}
detached_parts.push_back(part->name);
}
@@ -6133,8 +6135,9 @@ PartitionCommandsResultInfo StorageReplicatedMergeTree::attachPartition(
MutableDataPartsVector loaded_parts = tryLoadPartsToAttach(partition, attach_part, query_context, renamed_parts);
/// TODO Allow to use quorum here.
- ReplicatedMergeTreeSink output(*this, metadata_snapshot, 0, 0, 0, false, false, false, query_context,
- /*is_attach*/true);
+ ReplicatedMergeTreeSink output(*this, metadata_snapshot, /* quorum */ 0, /* quorum_timeout_ms */ 0, /* max_parts_per_block */ 0,
+ /* quorum_parallel */ false, query_context->getSettingsRef().insert_deduplicate,
+ /* majority_quorum */ false, query_context, /*is_attach*/true);
for (size_t i = 0; i < loaded_parts.size(); ++i)
{
@@ -9509,7 +9512,7 @@ bool StorageReplicatedMergeTree::createEmptyPartInsteadOfLost(zkutil::ZooKeeperP
}
}
- MergeTreeData::MutableDataPartPtr new_data_part = createEmptyPart(new_part_info, partition, lost_part_name, NO_TRANSACTION_PTR);
+ auto [new_data_part, tmp_dir_holder] = createEmptyPart(new_part_info, partition, lost_part_name, NO_TRANSACTION_PTR);
new_data_part->setName(lost_part_name);
try
diff --git a/src/Storages/System/StorageSystemTables.cpp b/src/Storages/System/StorageSystemTables.cpp
index 60dfc3a75e8b..715c98ee92a3 100644
--- a/src/Storages/System/StorageSystemTables.cpp
+++ b/src/Storages/System/StorageSystemTables.cpp
@@ -108,6 +108,22 @@ static ColumnPtr getFilteredTables(const ASTPtr & query, const ColumnPtr & filte
return block.getByPosition(0).column;
}
+/// Avoid heavy operation on tables if we only queried columns that we can get without table object.
+/// Otherwise it will require table initialization for Lazy database.
+static bool needTable(const DatabasePtr & database, const Block & header)
+{
+ if (database->getEngineName() != "Lazy")
+ return true;
+
+ static const std::set columns_without_table = { "database", "name", "uuid", "metadata_modification_time" };
+ for (const auto & column : header.getColumnsWithTypeAndName())
+ {
+ if (columns_without_table.find(column.name) == columns_without_table.end())
+ return true;
+ }
+ return false;
+}
+
class TablesBlockSource : public ISource
{
@@ -266,6 +282,8 @@ class TablesBlockSource : public ISource
if (!tables_it || !tables_it->isValid())
tables_it = database->getTablesIterator(context);
+ const bool need_table = needTable(database, getPort().getHeader());
+
for (; rows_count < max_block_size && tables_it->isValid(); tables_it->next())
{
auto table_name = tables_it->name();
@@ -275,23 +293,27 @@ class TablesBlockSource : public ISource
if (check_access_for_tables && !access->isGranted(AccessType::SHOW_TABLES, database_name, table_name))
continue;
- StoragePtr table = tables_it->table();
- if (!table)
- // Table might have just been removed or detached for Lazy engine (see DatabaseLazy::tryGetTable())
- continue;
-
+ StoragePtr table = nullptr;
TableLockHolder lock;
- /// The only column that requires us to hold a shared lock is data_paths as rename might alter them (on ordinary tables)
- /// and it's not protected internally by other mutexes
- static const size_t DATA_PATHS_INDEX = 5;
- if (columns_mask[DATA_PATHS_INDEX])
+ if (need_table)
{
- lock = table->tryLockForShare(context->getCurrentQueryId(), context->getSettingsRef().lock_acquire_timeout);
- if (!lock)
- // Table was dropped while acquiring the lock, skipping table
+ table = tables_it->table();
+ if (!table)
+ // Table might have just been removed or detached for Lazy engine (see DatabaseLazy::tryGetTable())
continue;
- }
+ /// The only column that requires us to hold a shared lock is data_paths as rename might alter them (on ordinary tables)
+ /// and it's not protected internally by other mutexes
+ static const size_t DATA_PATHS_INDEX = 5;
+ if (columns_mask[DATA_PATHS_INDEX])
+ {
+ lock = table->tryLockForShare(context->getCurrentQueryId(),
+ context->getSettingsRef().lock_acquire_timeout);
+ if (!lock)
+ // Table was dropped while acquiring the lock, skipping table
+ continue;
+ }
+ }
++rows_count;
size_t src_index = 0;
@@ -308,6 +330,7 @@ class TablesBlockSource : public ISource
if (columns_mask[src_index++])
{
+ chassert(table != nullptr);
res_columns[res_index++]->insert(table->getName());
}
@@ -397,7 +420,9 @@ class TablesBlockSource : public ISource
else
src_index += 3;
- StorageMetadataPtr metadata_snapshot = table->getInMemoryMetadataPtr();
+ StorageMetadataPtr metadata_snapshot;
+ if (table)
+ metadata_snapshot = table->getInMemoryMetadataPtr();
ASTPtr expression_ptr;
if (columns_mask[src_index++])
@@ -434,7 +459,7 @@ class TablesBlockSource : public ISource
if (columns_mask[src_index++])
{
- auto policy = table->getStoragePolicy();
+ auto policy = table ? table->getStoragePolicy() : nullptr;
if (policy)
res_columns[res_index++]->insert(policy->getName());
else
@@ -445,7 +470,7 @@ class TablesBlockSource : public ISource
settings.select_sequential_consistency = 0;
if (columns_mask[src_index++])
{
- auto total_rows = table->totalRows(settings);
+ auto total_rows = table ? table->totalRows(settings) : std::nullopt;
if (total_rows)
res_columns[res_index++]->insert(*total_rows);
else
@@ -490,7 +515,7 @@ class TablesBlockSource : public ISource
if (columns_mask[src_index++])
{
- auto lifetime_rows = table->lifetimeRows();
+ auto lifetime_rows = table ? table->lifetimeRows() : std::nullopt;
if (lifetime_rows)
res_columns[res_index++]->insert(*lifetime_rows);
else
@@ -499,7 +524,7 @@ class TablesBlockSource : public ISource
if (columns_mask[src_index++])
{
- auto lifetime_bytes = table->lifetimeBytes();
+ auto lifetime_bytes = table ? table->lifetimeBytes() : std::nullopt;
if (lifetime_bytes)
res_columns[res_index++]->insert(*lifetime_bytes);
else
diff --git a/tests/analyzer_integration_broken_tests.txt b/tests/analyzer_integration_broken_tests.txt
index 68822fbf311d..20ea31efa70f 100644
--- a/tests/analyzer_integration_broken_tests.txt
+++ b/tests/analyzer_integration_broken_tests.txt
@@ -5,24 +5,6 @@ test_distributed_ddl/test.py::test_default_database[configs_secure]
test_distributed_ddl/test.py::test_on_server_fail[configs]
test_distributed_ddl/test.py::test_on_server_fail[configs_secure]
test_distributed_insert_backward_compatibility/test.py::test_distributed_in_tuple
-test_distributed_inter_server_secret/test.py::test_per_user_inline_settings_secure_cluster[default-]
-test_distributed_inter_server_secret/test.py::test_per_user_inline_settings_secure_cluster[nopass-]
-test_distributed_inter_server_secret/test.py::test_per_user_inline_settings_secure_cluster[pass-foo]
-test_distributed_inter_server_secret/test.py::test_per_user_protocol_settings_secure_cluster[default-]
-test_distributed_inter_server_secret/test.py::test_per_user_protocol_settings_secure_cluster[nopass-]
-test_distributed_inter_server_secret/test.py::test_per_user_protocol_settings_secure_cluster[pass-foo]
-test_distributed_inter_server_secret/test.py::test_user_insecure_cluster[default-]
-test_distributed_inter_server_secret/test.py::test_user_insecure_cluster[nopass-]
-test_distributed_inter_server_secret/test.py::test_user_insecure_cluster[pass-foo]
-test_distributed_inter_server_secret/test.py::test_user_secure_cluster[default-]
-test_distributed_inter_server_secret/test.py::test_user_secure_cluster[nopass-]
-test_distributed_inter_server_secret/test.py::test_user_secure_cluster[pass-foo]
-test_distributed_inter_server_secret/test.py::test_user_secure_cluster_from_backward[default-]
-test_distributed_inter_server_secret/test.py::test_user_secure_cluster_from_backward[nopass-]
-test_distributed_inter_server_secret/test.py::test_user_secure_cluster_from_backward[pass-foo]
-test_distributed_inter_server_secret/test.py::test_user_secure_cluster_with_backward[default-]
-test_distributed_inter_server_secret/test.py::test_user_secure_cluster_with_backward[nopass-]
-test_distributed_inter_server_secret/test.py::test_user_secure_cluster_with_backward[pass-foo]
test_distributed_load_balancing/test.py::test_distributed_replica_max_ignored_errors
test_distributed_load_balancing/test.py::test_load_balancing_default
test_distributed_load_balancing/test.py::test_load_balancing_priority_round_robin[dist_priority]
@@ -96,22 +78,6 @@ test_executable_table_function/test.py::test_executable_function_input_python
test_settings_profile/test.py::test_show_profiles
test_sql_user_defined_functions_on_cluster/test.py::test_sql_user_defined_functions_on_cluster
test_postgresql_protocol/test.py::test_python_client
-test_quota/test.py::test_add_remove_interval
-test_quota/test.py::test_add_remove_quota
-test_quota/test.py::test_consumption_of_show_clusters
-test_quota/test.py::test_consumption_of_show_databases
-test_quota/test.py::test_consumption_of_show_privileges
-test_quota/test.py::test_consumption_of_show_processlist
-test_quota/test.py::test_consumption_of_show_tables
-test_quota/test.py::test_dcl_introspection
-test_quota/test.py::test_dcl_management
-test_quota/test.py::test_exceed_quota
-test_quota/test.py::test_query_inserts
-test_quota/test.py::test_quota_from_users_xml
-test_quota/test.py::test_reload_users_xml_by_timer
-test_quota/test.py::test_simpliest_quota
-test_quota/test.py::test_tracking_quota
-test_quota/test.py::test_users_xml_is_readonly
test_mysql_database_engine/test.py::test_mysql_ddl_for_mysql_database
test_profile_events_s3/test.py::test_profile_events
test_user_defined_object_persistence/test.py::test_persistence
@@ -121,22 +87,6 @@ test_select_access_rights/test_main.py::test_alias_columns
test_select_access_rights/test_main.py::test_select_count
test_select_access_rights/test_main.py::test_select_join
test_postgresql_protocol/test.py::test_python_client
-test_quota/test.py::test_add_remove_interval
-test_quota/test.py::test_add_remove_quota
-test_quota/test.py::test_consumption_of_show_clusters
-test_quota/test.py::test_consumption_of_show_databases
-test_quota/test.py::test_consumption_of_show_privileges
-test_quota/test.py::test_consumption_of_show_processlist
-test_quota/test.py::test_consumption_of_show_tables
-test_quota/test.py::test_dcl_introspection
-test_quota/test.py::test_dcl_management
-test_quota/test.py::test_exceed_quota
-test_quota/test.py::test_query_inserts
-test_quota/test.py::test_quota_from_users_xml
-test_quota/test.py::test_reload_users_xml_by_timer
-test_quota/test.py::test_simpliest_quota
-test_quota/test.py::test_tracking_quota
-test_quota/test.py::test_users_xml_is_readonly
test_replicating_constants/test.py::test_different_versions
test_merge_tree_s3/test.py::test_heavy_insert_select_check_memory[node]
test_wrong_db_or_table_name/test.py::test_wrong_table_name
diff --git a/tests/ci/ast_fuzzer_check.py b/tests/ci/ast_fuzzer_check.py
index 74b875c23be4..fecf207589e5 100644
--- a/tests/ci/ast_fuzzer_check.py
+++ b/tests/ci/ast_fuzzer_check.py
@@ -8,7 +8,11 @@
from github import Github
from build_download_helper import get_build_name_for_check, read_build_urls
-from clickhouse_helper import ClickHouseHelper, prepare_tests_results_for_clickhouse
+from clickhouse_helper import (
+ ClickHouseHelper,
+ prepare_tests_results_for_clickhouse,
+ get_instance_type,
+)
from commit_status_helper import (
RerunHelper,
format_description,
@@ -30,15 +34,32 @@
IMAGE_NAME = "clickhouse/fuzzer"
-def get_run_command(pr_number, sha, download_url, workspace_path, image):
+def get_run_command(
+ check_start_time, check_name, pr_number, sha, download_url, workspace_path, image
+):
+ instance_type = get_instance_type()
+
+ envs = [
+ "-e CLICKHOUSE_CI_LOGS_HOST",
+ "-e CLICKHOUSE_CI_LOGS_PASSWORD",
+ f"-e CHECK_START_TIME='{check_start_time}'",
+ f"-e CHECK_NAME='{check_name}'",
+ f"-e INSTANCE_TYPE='{instance_type}'",
+ f"-e PR_TO_TEST={pr_number}",
+ f"-e SHA_TO_TEST={sha}",
+ f"-e BINARY_URL_TO_DOWNLOAD='{download_url}'",
+ ]
+
+ env_str = " ".join(envs)
+
return (
f"docker run "
# For sysctl
"--privileged "
"--network=host "
f"--volume={workspace_path}:/workspace "
+ f"{env_str} "
"--cap-add syslog --cap-add sys_admin --cap-add=SYS_PTRACE "
- f'-e PR_TO_TEST={pr_number} -e SHA_TO_TEST={sha} -e BINARY_URL_TO_DOWNLOAD="{download_url}" '
f"{image}"
)
@@ -88,11 +109,19 @@ def main():
os.makedirs(workspace_path)
run_command = get_run_command(
- pr_info.number, pr_info.sha, build_url, workspace_path, docker_image
+ stopwatch.start_time_str,
+ check_name,
+ pr_info.number,
+ pr_info.sha,
+ build_url,
+ workspace_path,
+ docker_image,
)
logging.info("Going to run %s", run_command)
run_log_path = os.path.join(temp_path, "run.log")
+ main_log_path = os.path.join(workspace_path, "main.log")
+
with open(run_log_path, "w", encoding="utf-8") as log:
with subprocess.Popen(
run_command, shell=True, stderr=log, stdout=log
@@ -105,20 +134,47 @@ def main():
subprocess.check_call(f"sudo chown -R ubuntu:ubuntu {temp_path}", shell=True)
+ # Cleanup run log from the credentials of CI logs database.
+ # Note: a malicious user can still print them by splitting the value into parts.
+ # But we will be warned when a malicious user modifies CI script.
+ # Although they can also print them from inside tests.
+ # Nevertheless, the credentials of the CI logs have limited scope
+ # and does not provide access to sensitive info.
+
+ ci_logs_host = os.getenv("CLICKHOUSE_CI_LOGS_HOST", "CLICKHOUSE_CI_LOGS_HOST")
+ ci_logs_password = os.getenv(
+ "CLICKHOUSE_CI_LOGS_PASSWORD", "CLICKHOUSE_CI_LOGS_PASSWORD"
+ )
+
+ if ci_logs_host not in ("CLICKHOUSE_CI_LOGS_HOST", ""):
+ subprocess.check_call(
+ f"sed -i -r -e 's!{ci_logs_host}!CLICKHOUSE_CI_LOGS_HOST!g; s!{ci_logs_password}!CLICKHOUSE_CI_LOGS_PASSWORD!g;' '{run_log_path}' '{main_log_path}'",
+ shell=True,
+ )
+
check_name_lower = (
check_name.lower().replace("(", "").replace(")", "").replace(" ", "")
)
s3_prefix = f"{pr_info.number}/{pr_info.sha}/fuzzer_{check_name_lower}/"
paths = {
"run.log": run_log_path,
- "main.log": os.path.join(workspace_path, "main.log"),
- "server.log.zst": os.path.join(workspace_path, "server.log.zst"),
+ "main.log": main_log_path,
"fuzzer.log": os.path.join(workspace_path, "fuzzer.log"),
"report.html": os.path.join(workspace_path, "report.html"),
"core.zst": os.path.join(workspace_path, "core.zst"),
"dmesg.log": os.path.join(workspace_path, "dmesg.log"),
}
+ compressed_server_log_path = os.path.join(workspace_path, "server.log.zst")
+ if os.path.exists(compressed_server_log_path):
+ paths["server.log.zst"] = compressed_server_log_path
+
+ # The script can fail before the invocation of `zstd`, but we are still interested in its log:
+
+ not_compressed_server_log_path = os.path.join(workspace_path, "server.log")
+ if os.path.exists(not_compressed_server_log_path):
+ paths["server.log"] = not_compressed_server_log_path
+
s3_helper = S3Helper()
for f in paths:
try:
diff --git a/tests/ci/functional_test_check.py b/tests/ci/functional_test_check.py
index d06da94d0f00..2bab330bd663 100644
--- a/tests/ci/functional_test_check.py
+++ b/tests/ci/functional_test_check.py
@@ -394,10 +394,11 @@ def main():
ci_logs_password = os.getenv(
"CLICKHOUSE_CI_LOGS_PASSWORD", "CLICKHOUSE_CI_LOGS_PASSWORD"
)
- subprocess.check_call(
- f"sed -i -r -e 's!{ci_logs_host}!CLICKHOUSE_CI_LOGS_HOST!g; s!{ci_logs_password}!CLICKHOUSE_CI_LOGS_PASSWORD!g;' '{run_log_path}'",
- shell=True,
- )
+ if ci_logs_host not in ("CLICKHOUSE_CI_LOGS_HOST", ""):
+ subprocess.check_call(
+ f"sed -i -r -e 's!{ci_logs_host}!CLICKHOUSE_CI_LOGS_HOST!g; s!{ci_logs_password}!CLICKHOUSE_CI_LOGS_PASSWORD!g;' '{run_log_path}'",
+ shell=True,
+ )
report_url = upload_results(
s3_helper,
diff --git a/tests/ci/install_check.py b/tests/ci/install_check.py
index 010b0dab408c..a5788e2af3fd 100644
--- a/tests/ci/install_check.py
+++ b/tests/ci/install_check.py
@@ -50,8 +50,19 @@ def prepare_test_scripts():
server_test = r"""#!/bin/bash
set -e
trap "bash -ex /packages/preserve_logs.sh" ERR
+test_env='TEST_THE_DEFAULT_PARAMETER=15'
+echo "$test_env" >> /etc/default/clickhouse
systemctl start clickhouse-server
-clickhouse-client -q 'SELECT version()'"""
+clickhouse-client -q 'SELECT version()'
+grep "$test_env" /proc/$(cat /var/run/clickhouse-server/clickhouse-server.pid)/environ"""
+ initd_test = r"""#!/bin/bash
+set -e
+trap "bash -ex /packages/preserve_logs.sh" ERR
+test_env='TEST_THE_DEFAULT_PARAMETER=15'
+echo "$test_env" >> /etc/default/clickhouse
+/etc/init.d/clickhouse-server start
+clickhouse-client -q 'SELECT version()'
+grep "$test_env" /proc/$(cat /var/run/clickhouse-server/clickhouse-server.pid)/environ"""
keeper_test = r"""#!/bin/bash
set -e
trap "bash -ex /packages/preserve_logs.sh" ERR
@@ -102,6 +113,7 @@ def prepare_test_scripts():
exit 1
"""
(TEMP_PATH / "server_test.sh").write_text(server_test, encoding="utf-8")
+ (TEMP_PATH / "initd_test.sh").write_text(initd_test, encoding="utf-8")
(TEMP_PATH / "keeper_test.sh").write_text(keeper_test, encoding="utf-8")
(TEMP_PATH / "binary_test.sh").write_text(binary_test, encoding="utf-8")
(TEMP_PATH / "preserve_logs.sh").write_text(preserve_logs, encoding="utf-8")
@@ -112,6 +124,9 @@ def test_install_deb(image: DockerImage) -> TestResults:
"Install server deb": r"""#!/bin/bash -ex
apt-get install /packages/clickhouse-{server,client,common}*deb
bash -ex /packages/server_test.sh""",
+ "Run server init.d": r"""#!/bin/bash -ex
+apt-get install /packages/clickhouse-{server,client,common}*deb
+bash -ex /packages/initd_test.sh""",
"Install keeper deb": r"""#!/bin/bash -ex
apt-get install /packages/clickhouse-keeper*deb
bash -ex /packages/keeper_test.sh""",
@@ -191,6 +206,9 @@ def test_install(image: DockerImage, tests: Dict[str, str]) -> TestResults:
retcode = process.wait()
if retcode == 0:
status = OK
+ subprocess.check_call(
+ f"docker kill -s 9 {container_id}", shell=True
+ )
break
status = FAIL
@@ -198,8 +216,8 @@ def test_install(image: DockerImage, tests: Dict[str, str]) -> TestResults:
archive_path = TEMP_PATH / f"{container_name}-{retry}.tar.gz"
compress_fast(LOGS_PATH, archive_path)
logs.append(archive_path)
+ subprocess.check_call(f"docker kill -s 9 {container_id}", shell=True)
- subprocess.check_call(f"docker kill -s 9 {container_id}", shell=True)
test_results.append(TestResult(name, status, stopwatch.duration_seconds, logs))
return test_results
@@ -276,7 +294,7 @@ def main():
sys.exit(0)
docker_images = {
- name: get_image_with_version(REPORTS_PATH, name)
+ name: get_image_with_version(REPORTS_PATH, name, args.download)
for name in (RPM_IMAGE, DEB_IMAGE)
}
prepare_test_scripts()
@@ -293,6 +311,8 @@ def filter_artifacts(path: str) -> bool:
is_match = is_match or path.endswith(".rpm")
if args.tgz:
is_match = is_match or path.endswith(".tgz")
+ # We don't need debug packages, so let's filter them out
+ is_match = is_match and "-dbg" not in path
return is_match
download_builds_filter(
diff --git a/tests/ci/pr_info.py b/tests/ci/pr_info.py
index 86d4985c6b27..dee71b726dfe 100644
--- a/tests/ci/pr_info.py
+++ b/tests/ci/pr_info.py
@@ -279,7 +279,7 @@ def get_dict(self):
"user_orgs": self.user_orgs,
}
- def has_changes_in_documentation(self):
+ def has_changes_in_documentation(self) -> bool:
# If the list wasn't built yet the best we can do is to
# assume that there were changes.
if self.changed_files is None or not self.changed_files:
@@ -287,10 +287,9 @@ def has_changes_in_documentation(self):
for f in self.changed_files:
_, ext = os.path.splitext(f)
- path_in_docs = "docs" in f
- path_in_website = "website" in f
+ path_in_docs = f.startswith("docs/")
if (
- ext in DIFF_IN_DOCUMENTATION_EXT and (path_in_docs or path_in_website)
+ ext in DIFF_IN_DOCUMENTATION_EXT and path_in_docs
) or "docker/docs" in f:
return True
return False
diff --git a/tests/ci/run_check.py b/tests/ci/run_check.py
index 4f022b6c0a5c..db98a2c1ab5d 100644
--- a/tests/ci/run_check.py
+++ b/tests/ci/run_check.py
@@ -137,17 +137,20 @@ def main():
if pr_labels_to_remove:
remove_labels(gh, pr_info, pr_labels_to_remove)
- if FEATURE_LABEL in pr_info.labels:
- print(f"The '{FEATURE_LABEL}' in the labels, expect the 'Docs Check' status")
+ if FEATURE_LABEL in pr_info.labels and not pr_info.has_changes_in_documentation():
+ print(
+ f"The '{FEATURE_LABEL}' in the labels, "
+ "but there's no changed documentation"
+ )
post_commit_status( # do not pass pr_info here intentionally
commit,
- "pending",
+ "failure",
NotSet,
f"expect adding docs for {FEATURE_LABEL}",
DOCS_NAME,
+ pr_info,
)
- elif not description_error:
- set_mergeable_check(commit, "skipped")
+ sys.exit(1)
if description_error:
print(
@@ -173,6 +176,7 @@ def main():
)
sys.exit(1)
+ set_mergeable_check(commit, "skipped")
ci_report_url = create_ci_report(pr_info, [])
if not can_run:
print("::notice ::Cannot run")
diff --git a/tests/ci/s3_helper.py b/tests/ci/s3_helper.py
index e21e03cc8b63..2bfe639739b4 100644
--- a/tests/ci/s3_helper.py
+++ b/tests/ci/s3_helper.py
@@ -92,7 +92,7 @@ def _upload_file_to_s3(self, bucket_name: str, file_path: str, s3_path: str) ->
file_path,
)
else:
- logging.info("No content type provied for %s", file_path)
+ logging.info("No content type provided for %s", file_path)
else:
if re.search(r"\.(txt|log|err|out)$", s3_path) or re.search(
r"\.log\..*(?
logging.info("File is too large, do not provide content type")
self.client.upload_file(file_path, bucket_name, s3_path, ExtraArgs=metadata)
- logging.info("Upload %s to %s. Meta: %s", file_path, s3_path, metadata)
# last two replacements are specifics of AWS urls:
# https://jamesd3142.wordpress.com/2018/02/28/amazon-s3-and-the-plus-symbol/
url = f"{self.download_host}/{bucket_name}/{s3_path}"
- return url.replace("+", "%2B").replace(" ", "%20")
+ url = url.replace("+", "%2B").replace(" ", "%20")
+ logging.info("Upload %s to %s. Meta: %s", file_path, url, metadata)
+ return url
def upload_test_report_to_s3(self, file_path: str, s3_path: str) -> str:
if CI:
diff --git a/tests/ci/stress_check.py b/tests/ci/stress_check.py
index 42d372efb5d3..21c3178faab1 100644
--- a/tests/ci/stress_check.py
+++ b/tests/ci/stress_check.py
@@ -209,10 +209,11 @@ def run_stress_test(docker_image_name):
ci_logs_password = os.getenv(
"CLICKHOUSE_CI_LOGS_PASSWORD", "CLICKHOUSE_CI_LOGS_PASSWORD"
)
- subprocess.check_call(
- f"sed -i -r -e 's!{ci_logs_host}!CLICKHOUSE_CI_LOGS_HOST!g; s!{ci_logs_password}!CLICKHOUSE_CI_LOGS_PASSWORD!g;' '{run_log_path}'",
- shell=True,
- )
+ if ci_logs_host not in ("CLICKHOUSE_CI_LOGS_HOST", ""):
+ subprocess.check_call(
+ f"sed -i -r -e 's!{ci_logs_host}!CLICKHOUSE_CI_LOGS_HOST!g; s!{ci_logs_password}!CLICKHOUSE_CI_LOGS_PASSWORD!g;' '{run_log_path}'",
+ shell=True,
+ )
report_url = upload_results(
s3_helper,
diff --git a/tests/ci/workflow_approve_rerun_lambda/app.py b/tests/ci/workflow_approve_rerun_lambda/app.py
index 5e2331ece3cb..e511d773577f 100644
--- a/tests/ci/workflow_approve_rerun_lambda/app.py
+++ b/tests/ci/workflow_approve_rerun_lambda/app.py
@@ -64,6 +64,7 @@
"DocsCheck",
"MasterCI",
"NightlyBuilds",
+ "PublishedReleaseCI",
"PullRequestCI",
"ReleaseBranchCI",
}
diff --git a/tests/clickhouse-test b/tests/clickhouse-test
index fc175f2a05a3..1ce5ad981ad8 100755
--- a/tests/clickhouse-test
+++ b/tests/clickhouse-test
@@ -2152,7 +2152,7 @@ def reportLogStats(args):
print("\n")
query = """
- SELECT message_format_string, count(), substr(any(message), 1, 120) AS any_message
+ SELECT message_format_string, count(), any(message) AS any_message
FROM system.text_log
WHERE (now() - toIntervalMinute(240)) < event_time
AND (message NOT LIKE (replaceRegexpAll(message_format_string, '{[:.0-9dfx]*}', '%') AS s))
diff --git a/tests/integration/parallel_skip.json b/tests/integration/parallel_skip.json
index dec51396c510..d056225fee45 100644
--- a/tests/integration/parallel_skip.json
+++ b/tests/integration/parallel_skip.json
@@ -91,5 +91,6 @@
"test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_http_named_session",
"test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_grpc",
"test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_tcp_and_others",
- "test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_setting_in_query"
+ "test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_setting_in_query",
+ "test_profile_max_sessions_for_user/test.py::test_profile_max_sessions_for_user_client_suggestions_load"
]
diff --git a/tests/integration/test_broken_detached_part_clean_up/test.py b/tests/integration/test_broken_detached_part_clean_up/test.py
index 9a70ebe0d482..bdf993ddedfe 100644
--- a/tests/integration/test_broken_detached_part_clean_up/test.py
+++ b/tests/integration/test_broken_detached_part_clean_up/test.py
@@ -57,27 +57,30 @@ def remove_broken_detached_part_impl(table, node, expect_broken_prefix):
]
)
- node.exec_in_container(["mkdir", f"{path_to_detached}../unexpected_all_42_1337_5"])
- node.exec_in_container(
- [
- "touch",
- "-t",
- "1312031429.30",
- f"{path_to_detached}../unexpected_all_42_1337_5",
- ]
- )
- result = node.exec_in_container(
- ["stat", f"{path_to_detached}../unexpected_all_42_1337_5"]
- )
- print(result)
- assert "Modify: 2013-12-03" in result
- node.exec_in_container(
- [
- "mv",
- f"{path_to_detached}../unexpected_all_42_1337_5",
- f"{path_to_detached}unexpected_all_42_1337_5",
- ]
- )
+ for name in [
+ "unexpected_all_42_1337_5",
+ "deleting_all_123_456_7",
+ "covered-by-broken_all_12_34_5",
+ ]:
+ node.exec_in_container(["mkdir", f"{path_to_detached}../{name}"])
+ node.exec_in_container(
+ [
+ "touch",
+ "-t",
+ "1312031429.30",
+ f"{path_to_detached}../{name}",
+ ]
+ )
+ result = node.exec_in_container(["stat", f"{path_to_detached}../{name}"])
+ print(result)
+ assert "Modify: 2013-12-03" in result
+ node.exec_in_container(
+ [
+ "mv",
+ f"{path_to_detached}../{name}",
+ f"{path_to_detached}{name}",
+ ]
+ )
result = node.query(
f"CHECK TABLE {table}", settings={"check_query_single_value_result": 0}
@@ -87,17 +90,20 @@ def remove_broken_detached_part_impl(table, node, expect_broken_prefix):
node.query(f"DETACH TABLE {table}")
node.query(f"ATTACH TABLE {table}")
- result = node.exec_in_container(["ls", path_to_detached])
- print(result)
- assert f"{expect_broken_prefix}_all_3_3_0" in result
- assert "all_1_1_0" in result
- assert "trash" in result
- assert "broken_all_fake" in result
- assert "unexpected_all_42_1337_5" in result
-
- time.sleep(15)
- assert node.contains_in_log(
- "Removed broken detached part unexpected_all_42_1337_5 due to a timeout"
+ node.wait_for_log_line(
+ "Removing detached part deleting_all_123_456_7",
+ timeout=90,
+ look_behind_lines=1000000,
+ )
+ node.wait_for_log_line(
+ f"Removed broken detached part {expect_broken_prefix}_all_3_3_0 due to a timeout",
+ timeout=10,
+ look_behind_lines=1000000,
+ )
+ node.wait_for_log_line(
+ "Removed broken detached part unexpected_all_42_1337_5 due to a timeout",
+ timeout=10,
+ look_behind_lines=1000000,
)
result = node.exec_in_container(["ls", path_to_detached])
@@ -106,7 +112,16 @@ def remove_broken_detached_part_impl(table, node, expect_broken_prefix):
assert "all_1_1_0" in result
assert "trash" in result
assert "broken_all_fake" in result
+ assert "covered-by-broken_all_12_34_5" in result
assert "unexpected_all_42_1337_5" not in result
+ assert "deleting_all_123_456_7" not in result
+
+ node.query(
+ f"ALTER TABLE {table} DROP DETACHED PART 'covered-by-broken_all_12_34_5'",
+ settings={"allow_drop_detached": 1},
+ )
+ result = node.exec_in_container(["ls", path_to_detached])
+ assert "covered-by-broken_all_12_34_5" not in result
node.query(f"DROP TABLE {table} SYNC")
diff --git a/tests/integration/test_distributed_inter_server_secret/test.py b/tests/integration/test_distributed_inter_server_secret/test.py
index 36ac07a550a7..1aeaddcf3c5a 100644
--- a/tests/integration/test_distributed_inter_server_secret/test.py
+++ b/tests/integration/test_distributed_inter_server_secret/test.py
@@ -110,10 +110,6 @@ def start_cluster():
cluster.shutdown()
-def query_with_id(node, id_, query, **kwargs):
- return node.query("WITH '{}' AS __id {}".format(id_, query), **kwargs)
-
-
# @return -- [user, initial_user]
def get_query_user_info(node, query_pattern):
node.query("SYSTEM FLUSH LOGS")
@@ -334,7 +330,7 @@ def test_secure_disagree_insert():
@users
def test_user_insecure_cluster(user, password):
id_ = "query-dist_insecure-" + user
- query_with_id(n1, id_, "SELECT * FROM dist_insecure", user=user, password=password)
+ n1.query(f"SELECT *, '{id_}' FROM dist_insecure", user=user, password=password)
assert get_query_user_info(n1, id_) == [
user,
user,
@@ -345,7 +341,7 @@ def test_user_insecure_cluster(user, password):
@users
def test_user_secure_cluster(user, password):
id_ = "query-dist_secure-" + user
- query_with_id(n1, id_, "SELECT * FROM dist_secure", user=user, password=password)
+ n1.query(f"SELECT *, '{id_}' FROM dist_secure", user=user, password=password)
assert get_query_user_info(n1, id_) == [user, user]
assert get_query_user_info(n2, id_) == [user, user]
@@ -353,16 +349,14 @@ def test_user_secure_cluster(user, password):
@users
def test_per_user_inline_settings_insecure_cluster(user, password):
id_ = "query-ddl-settings-dist_insecure-" + user
- query_with_id(
- n1,
- id_,
- """
- SELECT * FROM dist_insecure
- SETTINGS
- prefer_localhost_replica=0,
- max_memory_usage_for_user=1e9,
- max_untracked_memory=0
- """,
+ n1.query(
+ f"""
+ SELECT *, '{id_}' FROM dist_insecure
+ SETTINGS
+ prefer_localhost_replica=0,
+ max_memory_usage_for_user=1e9,
+ max_untracked_memory=0
+ """,
user=user,
password=password,
)
@@ -372,16 +366,14 @@ def test_per_user_inline_settings_insecure_cluster(user, password):
@users
def test_per_user_inline_settings_secure_cluster(user, password):
id_ = "query-ddl-settings-dist_secure-" + user
- query_with_id(
- n1,
- id_,
- """
- SELECT * FROM dist_secure
- SETTINGS
- prefer_localhost_replica=0,
- max_memory_usage_for_user=1e9,
- max_untracked_memory=0
- """,
+ n1.query(
+ f"""
+ SELECT *, '{id_}' FROM dist_secure
+ SETTINGS
+ prefer_localhost_replica=0,
+ max_memory_usage_for_user=1e9,
+ max_untracked_memory=0
+ """,
user=user,
password=password,
)
@@ -393,10 +385,8 @@ def test_per_user_inline_settings_secure_cluster(user, password):
@users
def test_per_user_protocol_settings_insecure_cluster(user, password):
id_ = "query-protocol-settings-dist_insecure-" + user
- query_with_id(
- n1,
- id_,
- "SELECT * FROM dist_insecure",
+ n1.query(
+ f"SELECT *, '{id_}' FROM dist_insecure",
user=user,
password=password,
settings={
@@ -411,10 +401,8 @@ def test_per_user_protocol_settings_insecure_cluster(user, password):
@users
def test_per_user_protocol_settings_secure_cluster(user, password):
id_ = "query-protocol-settings-dist_secure-" + user
- query_with_id(
- n1,
- id_,
- "SELECT * FROM dist_secure",
+ n1.query(
+ f"SELECT *, '{id_}' FROM dist_secure",
user=user,
password=password,
settings={
@@ -431,8 +419,8 @@ def test_per_user_protocol_settings_secure_cluster(user, password):
@users
def test_user_secure_cluster_with_backward(user, password):
id_ = "with-backward-query-dist_secure-" + user
- query_with_id(
- n1, id_, "SELECT * FROM dist_secure_backward", user=user, password=password
+ n1.query(
+ f"SELECT *, '{id_}' FROM dist_secure_backward", user=user, password=password
)
assert get_query_user_info(n1, id_) == [user, user]
assert get_query_user_info(backward, id_) == [user, user]
@@ -441,13 +429,7 @@ def test_user_secure_cluster_with_backward(user, password):
@users
def test_user_secure_cluster_from_backward(user, password):
id_ = "from-backward-query-dist_secure-" + user
- query_with_id(
- backward,
- id_,
- "SELECT * FROM dist_secure_backward",
- user=user,
- password=password,
- )
+ backward.query(f"SELECT *, '{id_}' FROM dist_secure", user=user, password=password)
assert get_query_user_info(n1, id_) == [user, user]
assert get_query_user_info(backward, id_) == [user, user]
diff --git a/tests/integration/test_profile_max_sessions_for_user/test.py b/tests/integration/test_profile_max_sessions_for_user/test.py
index 2930262f63ec..5eaef09bf6d4 100755
--- a/tests/integration/test_profile_max_sessions_for_user/test.py
+++ b/tests/integration/test_profile_max_sessions_for_user/test.py
@@ -10,6 +10,7 @@
from helpers.cluster import ClickHouseCluster, run_and_check
from helpers.test_tools import assert_logs_contain_with_retry
+from helpers.uclient import client, prompt
MAX_SESSIONS_FOR_USER = 2
POSTGRES_SERVER_PORT = 5433
@@ -27,10 +28,7 @@
gen_dir = os.path.join(SCRIPT_DIR, "./_gen")
os.makedirs(gen_dir, exist_ok=True)
run_and_check(
- "python3 -m grpc_tools.protoc -I{proto_dir} --python_out={gen_dir} --grpc_python_out={gen_dir} \
- {proto_dir}/clickhouse_grpc.proto".format(
- proto_dir=proto_dir, gen_dir=gen_dir
- ),
+ f"python3 -m grpc_tools.protoc -I{proto_dir} --python_out={gen_dir} --grpc_python_out={gen_dir} {proto_dir}/clickhouse_grpc.proto",
shell=True,
)
@@ -209,3 +207,36 @@ def test_profile_max_sessions_for_user_tcp_and_others(started_cluster):
def test_profile_max_sessions_for_user_setting_in_query(started_cluster):
instance.query_and_get_error("SET max_sessions_for_user = 10")
+
+
+def test_profile_max_sessions_for_user_client_suggestions_connection(started_cluster):
+ command_text = f"{started_cluster.get_client_cmd()} --host {instance.ip_address} --port 9000 -u {TEST_USER} --password {TEST_PASSWORD}"
+ command_text_without_suggestions = command_text + " --disable_suggestion"
+
+ # Launch client1 without suggestions to avoid a race condition:
+ # Client1 opens a session.
+ # Client1 opens a session for suggestion connection.
+ # Client2 fails to open a session and gets the USER_SESSION_LIMIT_EXCEEDED error.
+ #
+ # Expected order:
+ # Client1 opens a session.
+ # Client2 opens a session.
+ # Client2 fails to open a session for suggestions and with USER_SESSION_LIMIT_EXCEEDED (No error printed).
+ # Client3 fails to open a session.
+ # Client1 executes the query.
+ # Client2 loads suggestions from the server using the main connection and executes a query.
+ with client(
+ name="client1>", log=None, command=command_text_without_suggestions
+ ) as client1:
+ client1.expect(prompt)
+ with client(name="client2>", log=None, command=command_text) as client2:
+ client2.expect(prompt)
+ with client(name="client3>", log=None, command=command_text) as client3:
+ client3.expect("USER_SESSION_LIMIT_EXCEEDED")
+
+ client1.send("SELECT 'CLIENT_1_SELECT' FORMAT CSV")
+ client1.expect("CLIENT_1_SELECT")
+ client1.expect(prompt)
+ client2.send("SELECT 'CLIENT_2_SELECT' FORMAT CSV")
+ client2.expect("CLIENT_2_SELECT")
+ client2.expect(prompt)
diff --git a/tests/integration/test_session_log/.gitignore b/tests/integration/test_session_log/.gitignore
new file mode 100644
index 000000000000..edf565ec6329
--- /dev/null
+++ b/tests/integration/test_session_log/.gitignore
@@ -0,0 +1 @@
+_gen
diff --git a/tests/integration/test_session_log/__init__.py b/tests/integration/test_session_log/__init__.py
new file mode 100644
index 000000000000..e69de29bb2d1
diff --git a/tests/integration/test_session_log/configs/log.xml b/tests/integration/test_session_log/configs/log.xml
new file mode 100644
index 000000000000..7a079b81e693
--- /dev/null
+++ b/tests/integration/test_session_log/configs/log.xml
@@ -0,0 +1,9 @@
+
+
+ trace
+ /var/log/clickhouse-server/clickhouse-server.log
+ /var/log/clickhouse-server/clickhouse-server.err.log
+ 1000M
+ 10
+
+
\ No newline at end of file
diff --git a/tests/integration/test_session_log/configs/ports.xml b/tests/integration/test_session_log/configs/ports.xml
new file mode 100644
index 000000000000..fbaefc16b3a8
--- /dev/null
+++ b/tests/integration/test_session_log/configs/ports.xml
@@ -0,0 +1,9 @@
+
+ 5433
+ 9001
+ 9100
+
+
+ false
+
+
\ No newline at end of file
diff --git a/tests/integration/test_session_log/configs/session_log.xml b/tests/integration/test_session_log/configs/session_log.xml
new file mode 100644
index 000000000000..a0e4e3e2216b
--- /dev/null
+++ b/tests/integration/test_session_log/configs/session_log.xml
@@ -0,0 +1,9 @@
+
+
+ system
+
+
+ toYYYYMM(event_date)
+ 7500
+
+
diff --git a/tests/integration/test_session_log/configs/users.xml b/tests/integration/test_session_log/configs/users.xml
new file mode 100644
index 000000000000..0416dfadc8ae
--- /dev/null
+++ b/tests/integration/test_session_log/configs/users.xml
@@ -0,0 +1,23 @@
+
+
+
+ 0
+
+
+
+
+
+
+ pass
+
+
+ pass
+
+
+ pass
+
+
+ pass
+
+
+
\ No newline at end of file
diff --git a/tests/integration/test_session_log/protos/clickhouse_grpc.proto b/tests/integration/test_session_log/protos/clickhouse_grpc.proto
new file mode 120000
index 000000000000..25d15f11e3bd
--- /dev/null
+++ b/tests/integration/test_session_log/protos/clickhouse_grpc.proto
@@ -0,0 +1 @@
+../../../../src/Server/grpc_protos/clickhouse_grpc.proto
\ No newline at end of file
diff --git a/tests/integration/test_session_log/test.py b/tests/integration/test_session_log/test.py
new file mode 100644
index 000000000000..bb7cafa4ee61
--- /dev/null
+++ b/tests/integration/test_session_log/test.py
@@ -0,0 +1,292 @@
+import os
+
+import grpc
+import pymysql.connections
+import pytest
+import random
+import sys
+import threading
+
+from helpers.cluster import ClickHouseCluster, run_and_check
+
+POSTGRES_SERVER_PORT = 5433
+MYSQL_SERVER_PORT = 9001
+GRPC_PORT = 9100
+SESSION_LOG_MATCHING_FIELDS = "auth_id, auth_type, client_version_major, client_version_minor, client_version_patch, interface"
+
+SCRIPT_DIR = os.path.dirname(os.path.realpath(__file__))
+DEFAULT_ENCODING = "utf-8"
+
+# Use grpcio-tools to generate *pb2.py files from *.proto.
+proto_dir = os.path.join(SCRIPT_DIR, "./protos")
+gen_dir = os.path.join(SCRIPT_DIR, "./_gen")
+os.makedirs(gen_dir, exist_ok=True)
+run_and_check(
+ f"python3 -m grpc_tools.protoc -I{proto_dir} --python_out={gen_dir} --grpc_python_out={gen_dir} {proto_dir}/clickhouse_grpc.proto",
+ shell=True,
+)
+
+sys.path.append(gen_dir)
+
+import clickhouse_grpc_pb2
+import clickhouse_grpc_pb2_grpc
+
+cluster = ClickHouseCluster(__file__)
+instance = cluster.add_instance(
+ "node",
+ main_configs=[
+ "configs/ports.xml",
+ "configs/log.xml",
+ "configs/session_log.xml",
+ ],
+ user_configs=["configs/users.xml"],
+ # Bug in TSAN reproduces in this test https://github.com/grpc/grpc/issues/29550#issuecomment-1188085387
+ env_variables={
+ "TSAN_OPTIONS": "report_atomic_races=0 " + os.getenv("TSAN_OPTIONS", default="")
+ },
+ with_postgres=True,
+)
+
+
+def grpc_get_url():
+ return f"{instance.ip_address}:{GRPC_PORT}"
+
+
+def grpc_create_insecure_channel():
+ channel = grpc.insecure_channel(grpc_get_url())
+ grpc.channel_ready_future(channel).result(timeout=2)
+ return channel
+
+
+session_id_counter = 0
+
+
+def next_session_id():
+ global session_id_counter
+ session_id = session_id_counter
+ session_id_counter += 1
+ return str(session_id)
+
+
+def grpc_query(query, user_, pass_, raise_exception):
+ try:
+ query_info = clickhouse_grpc_pb2.QueryInfo(
+ query=query,
+ session_id=next_session_id(),
+ user_name=user_,
+ password=pass_,
+ )
+ channel = grpc_create_insecure_channel()
+ stub = clickhouse_grpc_pb2_grpc.ClickHouseStub(channel)
+ result = stub.ExecuteQuery(query_info)
+ if result and result.HasField("exception"):
+ raise Exception(result.exception.display_text)
+
+ return result.output.decode(DEFAULT_ENCODING)
+ except Exception:
+ assert raise_exception
+
+
+def postgres_query(query, user_, pass_, raise_exception):
+ try:
+ connection_string = f"host={instance.hostname} port={POSTGRES_SERVER_PORT} dbname=default user={user_} password={pass_}"
+ cluster.exec_in_container(
+ cluster.postgres_id,
+ [
+ "/usr/bin/psql",
+ connection_string,
+ "--no-align",
+ "--field-separator=' '",
+ "-c",
+ query,
+ ],
+ shell=True,
+ )
+ except Exception:
+ assert raise_exception
+
+
+def mysql_query(query, user_, pass_, raise_exception):
+ try:
+ client = pymysql.connections.Connection(
+ host=instance.ip_address,
+ user=user_,
+ password=pass_,
+ database="default",
+ port=MYSQL_SERVER_PORT,
+ )
+ cursor = client.cursor(pymysql.cursors.DictCursor)
+ if raise_exception:
+ with pytest.raises(Exception):
+ cursor.execute(query)
+ else:
+ cursor.execute(query)
+ cursor.fetchall()
+ except Exception:
+ assert raise_exception
+
+
+@pytest.fixture(scope="module")
+def started_cluster():
+ try:
+ cluster.start()
+ yield cluster
+ finally:
+ cluster.shutdown()
+
+
+def test_grpc_session(started_cluster):
+ grpc_query("SELECT 1", "grpc_user", "pass", False)
+ grpc_query("SELECT 2", "grpc_user", "wrong_pass", True)
+ grpc_query("SELECT 3", "wrong_grpc_user", "pass", True)
+
+ instance.query("SYSTEM FLUSH LOGS")
+ login_success_records = instance.query(
+ "SELECT user, client_port <> 0, client_address <> toIPv6('::') FROM system.session_log WHERE user='grpc_user' AND type = 'LoginSuccess'"
+ )
+ assert login_success_records == "grpc_user\t1\t1\n"
+ logout_records = instance.query(
+ "SELECT user, client_port <> 0, client_address <> toIPv6('::') FROM system.session_log WHERE user='grpc_user' AND type = 'Logout'"
+ )
+ assert logout_records == "grpc_user\t1\t1\n"
+ login_failure_records = instance.query(
+ "SELECT user, client_port <> 0, client_address <> toIPv6('::') FROM system.session_log WHERE user='grpc_user' AND type = 'LoginFailure'"
+ )
+ assert login_failure_records == "grpc_user\t1\t1\n"
+ logins_and_logouts = instance.query(
+ f"SELECT COUNT(*) FROM (SELECT {SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = 'grpc_user' AND type = 'LoginSuccess' INTERSECT SELECT {SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = 'grpc_user' AND type = 'Logout')"
+ )
+ assert logins_and_logouts == "1\n"
+
+
+def test_mysql_session(started_cluster):
+ mysql_query("SELECT 1", "mysql_user", "pass", False)
+ mysql_query("SELECT 2", "mysql_user", "wrong_pass", True)
+ mysql_query("SELECT 3", "wrong_mysql_user", "pass", True)
+
+ instance.query("SYSTEM FLUSH LOGS")
+ login_success_records = instance.query(
+ "SELECT user, client_port <> 0, client_address <> toIPv6('::') FROM system.session_log WHERE user='mysql_user' AND type = 'LoginSuccess'"
+ )
+ assert login_success_records == "mysql_user\t1\t1\n"
+ logout_records = instance.query(
+ "SELECT user, client_port <> 0, client_address <> toIPv6('::') FROM system.session_log WHERE user='mysql_user' AND type = 'Logout'"
+ )
+ assert logout_records == "mysql_user\t1\t1\n"
+ login_failure_records = instance.query(
+ "SELECT user, client_port <> 0, client_address <> toIPv6('::') FROM system.session_log WHERE user='mysql_user' AND type = 'LoginFailure'"
+ )
+ assert login_failure_records == "mysql_user\t1\t1\n"
+ logins_and_logouts = instance.query(
+ f"SELECT COUNT(*) FROM (SELECT {SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = 'mysql_user' AND type = 'LoginSuccess' INTERSECT SELECT {SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = 'mysql_user' AND type = 'Logout')"
+ )
+ assert logins_and_logouts == "1\n"
+
+
+def test_postgres_session(started_cluster):
+ postgres_query("SELECT 1", "postgres_user", "pass", False)
+ postgres_query("SELECT 2", "postgres_user", "wrong_pass", True)
+ postgres_query("SELECT 3", "wrong_postgres_user", "pass", True)
+
+ instance.query("SYSTEM FLUSH LOGS")
+ login_success_records = instance.query(
+ "SELECT user, client_port <> 0, client_address <> toIPv6('::') FROM system.session_log WHERE user='postgres_user' AND type = 'LoginSuccess'"
+ )
+ assert login_success_records == "postgres_user\t1\t1\n"
+ logout_records = instance.query(
+ "SELECT user, client_port <> 0, client_address <> toIPv6('::') FROM system.session_log WHERE user='postgres_user' AND type = 'Logout'"
+ )
+ assert logout_records == "postgres_user\t1\t1\n"
+ login_failure_records = instance.query(
+ "SELECT user, client_port <> 0, client_address <> toIPv6('::') FROM system.session_log WHERE user='postgres_user' AND type = 'LoginFailure'"
+ )
+ assert login_failure_records == "postgres_user\t1\t1\n"
+ logins_and_logouts = instance.query(
+ f"SELECT COUNT(*) FROM (SELECT {SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = 'postgres_user' AND type = 'LoginSuccess' INTERSECT SELECT {SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = 'postgres_user' AND type = 'Logout')"
+ )
+ assert logins_and_logouts == "1\n"
+
+
+def test_parallel_sessions(started_cluster):
+ thread_list = []
+ for _ in range(10):
+ # Sleep time does not significantly matter here,
+ # test should pass even without sleeping.
+ for function in [postgres_query, grpc_query, mysql_query]:
+ thread = threading.Thread(
+ target=function,
+ args=(
+ f"SELECT sleep({random.uniform(0.03, 0.04)})",
+ "parallel_user",
+ "pass",
+ False,
+ ),
+ )
+ thread.start()
+ thread_list.append(thread)
+ thread = threading.Thread(
+ target=function,
+ args=(
+ f"SELECT sleep({random.uniform(0.03, 0.04)})",
+ "parallel_user",
+ "wrong_pass",
+ True,
+ ),
+ )
+ thread.start()
+ thread_list.append(thread)
+ thread = threading.Thread(
+ target=function,
+ args=(
+ f"SELECT sleep({random.uniform(0.03, 0.04)})",
+ "wrong_parallel_user",
+ "pass",
+ True,
+ ),
+ )
+ thread.start()
+ thread_list.append(thread)
+
+ for thread in thread_list:
+ thread.join()
+
+ instance.query("SYSTEM FLUSH LOGS")
+ port_0_sessions = instance.query(
+ f"SELECT COUNT(*) FROM system.session_log WHERE user = 'parallel_user'"
+ )
+ assert port_0_sessions == "90\n"
+
+ port_0_sessions = instance.query(
+ f"SELECT COUNT(*) FROM system.session_log WHERE user = 'parallel_user' AND client_port = 0"
+ )
+ assert port_0_sessions == "0\n"
+
+ address_0_sessions = instance.query(
+ f"SELECT COUNT(*) FROM system.session_log WHERE user = 'parallel_user' AND client_address = toIPv6('::')"
+ )
+ assert address_0_sessions == "0\n"
+
+ grpc_sessions = instance.query(
+ f"SELECT COUNT(*) FROM system.session_log WHERE user = 'parallel_user' AND interface = 'gRPC'"
+ )
+ assert grpc_sessions == "30\n"
+
+ mysql_sessions = instance.query(
+ f"SELECT COUNT(*) FROM system.session_log WHERE user = 'parallel_user' AND interface = 'MySQL'"
+ )
+ assert mysql_sessions == "30\n"
+
+ postgres_sessions = instance.query(
+ f"SELECT COUNT(*) FROM system.session_log WHERE user = 'parallel_user' AND interface = 'PostgreSQL'"
+ )
+ assert postgres_sessions == "30\n"
+
+ logins_and_logouts = instance.query(
+ f"SELECT COUNT(*) FROM (SELECT {SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = 'parallel_user' AND type = 'LoginSuccess' INTERSECT SELECT {SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = 'parallel_user' AND type = 'Logout')"
+ )
+ assert logins_and_logouts == "30\n"
+
+ logout_failure_sessions = instance.query(
+ f"SELECT COUNT(*) FROM system.session_log WHERE user = 'parallel_user' AND type = 'LoginFailure'"
+ )
+ assert logout_failure_sessions == "30\n"
diff --git a/tests/performance/aggregate_with_serialized_method.xml b/tests/performance/aggregate_with_serialized_method.xml
new file mode 100644
index 000000000000..91763c69bb94
--- /dev/null
+++ b/tests/performance/aggregate_with_serialized_method.xml
@@ -0,0 +1,32 @@
+
+
+ 8
+ 0
+ 4
+
+
+
+ CREATE TABLE t_nullable
+ (
+ key_string1 Nullable(String),
+ key_string2 Nullable(String),
+ key_string3 Nullable(String),
+ key_int64_1 Nullable(Int64),
+ key_int64_2 Nullable(Int64),
+ key_int64_3 Nullable(Int64),
+ key_int64_4 Nullable(Int64),
+ key_int64_5 Nullable(Int64),
+ m1 Int64,
+ m2 Int64
+ )
+ ENGINE = Memory
+
+ insert into t_nullable select ['aaaaaa','bbaaaa','ccaaaa','ddaaaa'][number % 101 + 1], ['aa','bb','cc','dd'][number % 100 + 1], ['aa','bb','cc','dd'][number % 102 + 1], number%10+1, number%10+2, number%10+3, number%10+4,number%10+5, number%6000+1, number%5000+2 from numbers_mt(20000000)
+ select key_string1,key_string2,key_string3, min(m1) from t_nullable group by key_string1,key_string2,key_string3
+ select key_string3,key_int64_1,key_int64_2, min(m1) from t_nullable group by key_string3,key_int64_1,key_int64_2
+ select key_int64_1,key_int64_2,key_int64_3,key_int64_4,key_int64_5, min(m1) from t_nullable group by key_int64_1,key_int64_2,key_int64_3,key_int64_4,key_int64_5
+ select toFloat64(key_int64_1),toFloat64(key_int64_2),toFloat64(key_int64_3),toFloat64(key_int64_4),toFloat64(key_int64_5), min(m1) from t_nullable group by toFloat64(key_int64_1),toFloat64(key_int64_2),toFloat64(key_int64_3),toFloat64(key_int64_4),toFloat64(key_int64_5) limit 10
+ select toDecimal64(key_int64_1, 3),toDecimal64(key_int64_2, 3),toDecimal64(key_int64_3, 3),toDecimal64(key_int64_4, 3),toDecimal64(key_int64_5, 3), min(m1) from t_nullable group by toDecimal64(key_int64_1, 3),toDecimal64(key_int64_2, 3),toDecimal64(key_int64_3, 3),toDecimal64(key_int64_4, 3),toDecimal64(key_int64_5, 3) limit 10
+
+ drop table if exists t_nullable
+
\ No newline at end of file
diff --git a/tests/queries/0_stateless/00002_log_and_exception_messages_formatting.sql b/tests/queries/0_stateless/00002_log_and_exception_messages_formatting.sql
index eb8e9826eff8..c1acc763d6f6 100644
--- a/tests/queries/0_stateless/00002_log_and_exception_messages_formatting.sql
+++ b/tests/queries/0_stateless/00002_log_and_exception_messages_formatting.sql
@@ -9,10 +9,10 @@ create view logs as select * from system.text_log where now() - toIntervalMinute
-- Check that we don't have too many messages formatted with fmt::runtime or strings concatenation.
-- 0.001 threshold should be always enough, the value was about 0.00025
-select 'runtime messages', max2(coalesce(sum(length(message_format_string) = 0) / countOrNull(), 0), 0.001) from logs;
+select 'runtime messages', greatest(coalesce(sum(length(message_format_string) = 0) / countOrNull(), 0), 0.001) from logs;
-- Check the same for exceptions. The value was 0.03
-select 'runtime exceptions', max2(coalesce(sum(length(message_format_string) = 0) / countOrNull(), 0), 0.05) from logs where message like '%DB::Exception%';
+select 'runtime exceptions', greatest(coalesce(sum(length(message_format_string) = 0) / countOrNull(), 0), 0.05) from logs where message like '%DB::Exception%';
-- FIXME some of the following messages are not informative and it has to be fixed
create temporary table known_short_messages (s String) as select * from (select
@@ -36,7 +36,7 @@ create temporary table known_short_messages (s String) as select * from (select
'Database {} does not exist', 'Dictionary ({}) not found', 'Unknown table function {}',
'Unknown format {}', 'Unknown explain kind ''{}''', 'Unknown setting {}', 'Unknown input format {}',
'Unknown identifier: ''{}''', 'User name is empty', 'Expected function, got: {}',
-'Attempt to read after eof', 'String size is too big ({}), maximum: {}', 'API mode: {}',
+'Attempt to read after eof', 'String size is too big ({}), maximum: {}',
'Processed: {}%', 'Creating {}: {}', 'Table {}.{} doesn''t exist', 'Invalid cache key hex: {}',
'User has been dropped', 'Illegal type {} of argument of function {}. Should be DateTime or DateTime64'
] as arr) array join arr;
diff --git a/tests/queries/0_stateless/00284_external_aggregation.sql b/tests/queries/0_stateless/00284_external_aggregation.sql
index d19f9f5aee8f..c1140faaa282 100644
--- a/tests/queries/0_stateless/00284_external_aggregation.sql
+++ b/tests/queries/0_stateless/00284_external_aggregation.sql
@@ -13,13 +13,13 @@ SET group_by_two_level_threshold = 100000;
SET max_bytes_before_external_group_by = '1Mi';
-- method: key_string & key_string_two_level
-CREATE TABLE t_00284_str(s String) ENGINE = MergeTree() ORDER BY tuple();
+CREATE TABLE t_00284_str(s String) ENGINE = MergeTree() ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t_00284_str SELECT toString(number) FROM numbers_mt(1e6);
INSERT INTO t_00284_str SELECT toString(number) FROM numbers_mt(1e6);
SELECT s, count() FROM t_00284_str GROUP BY s ORDER BY s LIMIT 10 OFFSET 42;
-- method: low_cardinality_key_string & low_cardinality_key_string_two_level
-CREATE TABLE t_00284_lc_str(s LowCardinality(String)) ENGINE = MergeTree() ORDER BY tuple();
+CREATE TABLE t_00284_lc_str(s LowCardinality(String)) ENGINE = MergeTree() ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t_00284_lc_str SELECT toString(number) FROM numbers_mt(1e6);
INSERT INTO t_00284_lc_str SELECT toString(number) FROM numbers_mt(1e6);
SELECT s, count() FROM t_00284_lc_str GROUP BY s ORDER BY s LIMIT 10 OFFSET 42;
diff --git a/tests/queries/0_stateless/00522_multidimensional.sql b/tests/queries/0_stateless/00522_multidimensional.sql
index c3c41257ab93..ea9881c612af 100644
--- a/tests/queries/0_stateless/00522_multidimensional.sql
+++ b/tests/queries/0_stateless/00522_multidimensional.sql
@@ -1,5 +1,5 @@
DROP TABLE IF EXISTS multidimensional;
-CREATE TABLE multidimensional ENGINE = MergeTree ORDER BY number AS SELECT number, arrayMap(x -> (x, [x], [[x]], (x, toString(x))), arrayMap(x -> range(x), range(number % 10))) AS value FROM system.numbers LIMIT 100000;
+CREATE TABLE multidimensional ENGINE = MergeTree ORDER BY number SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi' AS SELECT number, arrayMap(x -> (x, [x], [[x]], (x, toString(x))), arrayMap(x -> range(x), range(number % 10))) AS value FROM system.numbers LIMIT 100000;
SELECT sum(cityHash64(toString(value))) FROM multidimensional;
diff --git a/tests/queries/0_stateless/00576_nested_and_prewhere.sql b/tests/queries/0_stateless/00576_nested_and_prewhere.sql
index b15af582a193..5916e679f1ed 100644
--- a/tests/queries/0_stateless/00576_nested_and_prewhere.sql
+++ b/tests/queries/0_stateless/00576_nested_and_prewhere.sql
@@ -1,6 +1,6 @@
DROP TABLE IF EXISTS nested;
-CREATE TABLE nested (x UInt64, filter UInt8, n Nested(a UInt64)) ENGINE = MergeTree ORDER BY x;
+CREATE TABLE nested (x UInt64, filter UInt8, n Nested(a UInt64)) ENGINE = MergeTree ORDER BY x SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO nested SELECT number, number % 2, range(number % 10) FROM system.numbers LIMIT 100000;
ALTER TABLE nested ADD COLUMN n.b Array(UInt64);
diff --git a/tests/queries/0_stateless/00612_count.sql b/tests/queries/0_stateless/00612_count.sql
index 5dd9c7707002..9c435bd97fe9 100644
--- a/tests/queries/0_stateless/00612_count.sql
+++ b/tests/queries/0_stateless/00612_count.sql
@@ -1,6 +1,6 @@
DROP TABLE IF EXISTS count;
-CREATE TABLE count (x UInt64) ENGINE = MergeTree ORDER BY tuple();
+CREATE TABLE count (x UInt64) ENGINE = MergeTree ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO count SELECT * FROM numbers(1234567);
SELECT count() FROM count;
diff --git a/tests/queries/0_stateless/00626_replace_partition_from_table_zookeeper.sh b/tests/queries/0_stateless/00626_replace_partition_from_table_zookeeper.sh
index c32b6d04a425..334025cba28d 100755
--- a/tests/queries/0_stateless/00626_replace_partition_from_table_zookeeper.sh
+++ b/tests/queries/0_stateless/00626_replace_partition_from_table_zookeeper.sh
@@ -11,26 +11,6 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
# shellcheck source=../shell_config.sh
. "$CURDIR"/../shell_config.sh
-function query_with_retry
-{
- local query="$1" && shift
-
- local retry=0
- until [ $retry -ge 5 ]
- do
- local result
- result="$($CLICKHOUSE_CLIENT "$@" --query="$query" 2>&1)"
- if [ "$?" == 0 ]; then
- echo -n "$result"
- return
- else
- retry=$((retry + 1))
- sleep 3
- fi
- done
- echo "Query '$query' failed with '$result'"
-}
-
$CLICKHOUSE_CLIENT --query="DROP TABLE IF EXISTS src;"
$CLICKHOUSE_CLIENT --query="DROP TABLE IF EXISTS dst_r1;"
$CLICKHOUSE_CLIENT --query="DROP TABLE IF EXISTS dst_r2;"
diff --git a/tests/queries/0_stateless/00688_low_cardinality_dictionary_deserialization.sql b/tests/queries/0_stateless/00688_low_cardinality_dictionary_deserialization.sql
index 5a1694038725..c4613acf5f31 100644
--- a/tests/queries/0_stateless/00688_low_cardinality_dictionary_deserialization.sql
+++ b/tests/queries/0_stateless/00688_low_cardinality_dictionary_deserialization.sql
@@ -1,6 +1,5 @@
drop table if exists lc_dict_reading;
-create table lc_dict_reading (val UInt64, str StringWithDictionary, pat String) engine = MergeTree order by val;
+create table lc_dict_reading (val UInt64, str StringWithDictionary, pat String) engine = MergeTree order by val SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into lc_dict_reading select number, if(number < 8192 * 4, number % 100, number) as s, s from system.numbers limit 1000000;
select sum(toUInt64(str)), sum(toUInt64(pat)) from lc_dict_reading where val < 8129 or val > 8192 * 4;
drop table if exists lc_dict_reading;
-
diff --git a/tests/queries/0_stateless/00688_low_cardinality_serialization.sql b/tests/queries/0_stateless/00688_low_cardinality_serialization.sql
index 3c0e64a96377..b4fe4b292004 100644
--- a/tests/queries/0_stateless/00688_low_cardinality_serialization.sql
+++ b/tests/queries/0_stateless/00688_low_cardinality_serialization.sql
@@ -8,8 +8,8 @@ select 'MergeTree';
drop table if exists lc_small_dict;
drop table if exists lc_big_dict;
-create table lc_small_dict (str StringWithDictionary) engine = MergeTree order by str;
-create table lc_big_dict (str StringWithDictionary) engine = MergeTree order by str;
+create table lc_small_dict (str StringWithDictionary) engine = MergeTree order by str SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
+create table lc_big_dict (str StringWithDictionary) engine = MergeTree order by str SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into lc_small_dict select toString(number % 1000) from system.numbers limit 1000000;
insert into lc_big_dict select toString(number) from system.numbers limit 1000000;
@@ -25,4 +25,3 @@ select sum(toUInt64OrZero(str)) from lc_big_dict;
drop table if exists lc_small_dict;
drop table if exists lc_big_dict;
-
diff --git a/tests/queries/0_stateless/00738_lock_for_inner_table.sh b/tests/queries/0_stateless/00738_lock_for_inner_table.sh
index 9a7ae92439df..b62a639d8f4b 100755
--- a/tests/queries/0_stateless/00738_lock_for_inner_table.sh
+++ b/tests/queries/0_stateless/00738_lock_for_inner_table.sh
@@ -13,7 +13,7 @@ uuid=$(${CLICKHOUSE_CLIENT} --query "SELECT reinterpretAsUUID(currentDatabase())
echo "DROP TABLE IF EXISTS tab_00738 SYNC;
DROP TABLE IF EXISTS mv SYNC;
-CREATE TABLE tab_00738(a Int) ENGINE = MergeTree() ORDER BY a;
+CREATE TABLE tab_00738(a Int) ENGINE = MergeTree() ORDER BY a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
-- The matview will take at least 2 seconds to be finished (10000000 * 0.0000002)
CREATE MATERIALIZED VIEW mv UUID '$uuid' ENGINE = Log AS SELECT sleepEachRow(0.0000002) FROM tab_00738;" | ${CLICKHOUSE_CLIENT} -n
@@ -63,4 +63,3 @@ drop_inner_id
wait
drop_at_exit
-
diff --git a/tests/queries/0_stateless/00933_ttl_replicated_zookeeper.sh b/tests/queries/0_stateless/00933_ttl_replicated_zookeeper.sh
index 22d9e0690b39..d06037fb8367 100755
--- a/tests/queries/0_stateless/00933_ttl_replicated_zookeeper.sh
+++ b/tests/queries/0_stateless/00933_ttl_replicated_zookeeper.sh
@@ -5,22 +5,6 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
# shellcheck source=../shell_config.sh
. "$CURDIR"/../shell_config.sh
-function query_with_retry
-{
- retry=0
- until [ $retry -ge 5 ]
- do
- result=$($CLICKHOUSE_CLIENT $2 --query="$1" 2>&1)
- if [ "$?" == 0 ]; then
- echo -n "$result"
- return
- else
- retry=$(($retry + 1))
- sleep 3
- fi
- done
- echo "Query '$1' failed with '$result'"
-}
$CLICKHOUSE_CLIENT --query="DROP TABLE IF EXISTS ttl_repl1"
$CLICKHOUSE_CLIENT --query="DROP TABLE IF EXISTS ttl_repl2"
diff --git a/tests/queries/0_stateless/00975_move_partition_merge_tree.sql b/tests/queries/0_stateless/00975_move_partition_merge_tree.sql
index 2fc82b964030..c17f7c57de08 100644
--- a/tests/queries/0_stateless/00975_move_partition_merge_tree.sql
+++ b/tests/queries/0_stateless/00975_move_partition_merge_tree.sql
@@ -6,14 +6,14 @@ CREATE TABLE IF NOT EXISTS test_move_partition_src (
val UInt32
) Engine = MergeTree()
PARTITION BY pk
- ORDER BY (pk, val);
+ ORDER BY (pk, val) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
CREATE TABLE IF NOT EXISTS test_move_partition_dest (
pk UInt8,
val UInt32
) Engine = MergeTree()
PARTITION BY pk
- ORDER BY (pk, val);
+ ORDER BY (pk, val) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO test_move_partition_src SELECT number % 2, number FROM system.numbers LIMIT 10000000;
diff --git a/tests/queries/0_stateless/00981_topK_topKWeighted_long.sql b/tests/queries/0_stateless/00981_topK_topKWeighted_long.sql
index 48d9dedc61c8..7ee38867b538 100644
--- a/tests/queries/0_stateless/00981_topK_topKWeighted_long.sql
+++ b/tests/queries/0_stateless/00981_topK_topKWeighted_long.sql
@@ -2,7 +2,7 @@
DROP TABLE IF EXISTS topk;
-CREATE TABLE topk (val1 String, val2 UInt32) ENGINE = MergeTree ORDER BY val1;
+CREATE TABLE topk (val1 String, val2 UInt32) ENGINE = MergeTree ORDER BY val1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO topk WITH number % 7 = 0 AS frequent SELECT toString(frequent ? number % 10 : number), frequent ? 999999999 : number FROM numbers(4000000);
diff --git a/tests/queries/0_stateless/00993_system_parts_race_condition_drop_zookeeper.sh b/tests/queries/0_stateless/00993_system_parts_race_condition_drop_zookeeper.sh
index 4205f231698b..6025279e5703 100755
--- a/tests/queries/0_stateless/00993_system_parts_race_condition_drop_zookeeper.sh
+++ b/tests/queries/0_stateless/00993_system_parts_race_condition_drop_zookeeper.sh
@@ -59,7 +59,8 @@ function thread6()
CREATE TABLE alter_table_$REPLICA (a UInt8, b Int16, c Float32, d String, e Array(UInt8), f Nullable(UUID), g Tuple(UInt8, UInt16))
ENGINE = ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/alter_table', 'r_$REPLICA') ORDER BY a PARTITION BY b % 10
SETTINGS old_parts_lifetime = 1, cleanup_delay_period = 0, cleanup_delay_period_random_add = 0,
- cleanup_thread_preferred_points_per_iteration=0, replicated_max_mutations_in_one_entry = $(($RANDOM / 50));";
+ cleanup_thread_preferred_points_per_iteration=0, replicated_max_mutations_in_one_entry = $(($RANDOM / 50)),
+ index_granularity = 8192, index_granularity_bytes = '10Mi';";
sleep 0.$RANDOM;
done
}
diff --git a/tests/queries/0_stateless/01034_move_partition_from_table_zookeeper.sh b/tests/queries/0_stateless/01034_move_partition_from_table_zookeeper.sh
index e0a84323dbd6..39c5742e7a72 100755
--- a/tests/queries/0_stateless/01034_move_partition_from_table_zookeeper.sh
+++ b/tests/queries/0_stateless/01034_move_partition_from_table_zookeeper.sh
@@ -7,23 +7,6 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
# shellcheck source=../shell_config.sh
. "$CURDIR"/../shell_config.sh
-function query_with_retry
-{
- retry=0
- until [ $retry -ge 5 ]
- do
- result=$($CLICKHOUSE_CLIENT $2 --query="$1" 2>&1)
- if [ "$?" == 0 ]; then
- echo -n "$result"
- return
- else
- retry=$(($retry + 1))
- sleep 3
- fi
- done
- echo "Query '$1' failed with '$result'"
-}
-
$CLICKHOUSE_CLIENT --query="DROP TABLE IF EXISTS src;"
$CLICKHOUSE_CLIENT --query="DROP TABLE IF EXISTS dst;"
diff --git a/tests/queries/0_stateless/01034_sample_final_distributed.sql b/tests/queries/0_stateless/01034_sample_final_distributed.sql
index a81fef645dbd..64bafd17b2d9 100644
--- a/tests/queries/0_stateless/01034_sample_final_distributed.sql
+++ b/tests/queries/0_stateless/01034_sample_final_distributed.sql
@@ -3,7 +3,7 @@
set allow_experimental_parallel_reading_from_replicas = 0;
drop table if exists sample_final;
-create table sample_final (CounterID UInt32, EventDate Date, EventTime DateTime, UserID UInt64, Sign Int8) engine = CollapsingMergeTree(Sign) order by (CounterID, EventDate, intHash32(UserID), EventTime) sample by intHash32(UserID);
+create table sample_final (CounterID UInt32, EventDate Date, EventTime DateTime, UserID UInt64, Sign Int8) engine = CollapsingMergeTree(Sign) order by (CounterID, EventDate, intHash32(UserID), EventTime) sample by intHash32(UserID) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into sample_final select number / (8192 * 4), toDate('2019-01-01'), toDateTime('2019-01-01 00:00:01') + number, number / (8192 * 2), number % 3 = 1 ? -1 : 1 from numbers(1000000);
select 'count';
diff --git a/tests/queries/0_stateless/01035_avg.sql b/tests/queries/0_stateless/01035_avg.sql
index d683ada0aec1..a3cb35a80ec1 100644
--- a/tests/queries/0_stateless/01035_avg.sql
+++ b/tests/queries/0_stateless/01035_avg.sql
@@ -22,7 +22,7 @@ CREATE TABLE IF NOT EXISTS test_01035_avg (
d64 Decimal64(18) DEFAULT toDecimal64(u64 / 1000000, 8),
d128 Decimal128(20) DEFAULT toDecimal128(i128 / 100000, 20),
d256 Decimal256(40) DEFAULT toDecimal256(i256 / 100000, 40)
-) ENGINE = MergeTree() ORDER BY i64;
+) ENGINE = MergeTree() ORDER BY i64 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
SELECT avg(i8), avg(i16), avg(i32), avg(i64), avg(i128), avg(i256),
avg(u8), avg(u16), avg(u32), avg(u64), avg(u128), avg(u256),
diff --git a/tests/queries/0_stateless/01045_zookeeper_system_mutations_with_parts_names.sh b/tests/queries/0_stateless/01045_zookeeper_system_mutations_with_parts_names.sh
index 68c511b80acd..cd6501bbebff 100755
--- a/tests/queries/0_stateless/01045_zookeeper_system_mutations_with_parts_names.sh
+++ b/tests/queries/0_stateless/01045_zookeeper_system_mutations_with_parts_names.sh
@@ -21,7 +21,7 @@ function wait_mutation_to_start()
${CLICKHOUSE_CLIENT} --query="DROP TABLE IF EXISTS table_for_mutations"
-${CLICKHOUSE_CLIENT} --query="CREATE TABLE table_for_mutations(k UInt32, v1 UInt64) ENGINE MergeTree ORDER BY k PARTITION BY modulo(k, 2)"
+${CLICKHOUSE_CLIENT} --query="CREATE TABLE table_for_mutations(k UInt32, v1 UInt64) ENGINE MergeTree ORDER BY k PARTITION BY modulo(k, 2) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'"
${CLICKHOUSE_CLIENT} --query="SYSTEM STOP MERGES table_for_mutations"
@@ -48,7 +48,7 @@ ${CLICKHOUSE_CLIENT} --query="DROP TABLE IF EXISTS table_for_mutations"
${CLICKHOUSE_CLIENT} --query="DROP TABLE IF EXISTS replicated_table_for_mutations"
-${CLICKHOUSE_CLIENT} --query="CREATE TABLE replicated_table_for_mutations(k UInt32, v1 UInt64) ENGINE ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/replicated_table_for_mutations', '1') ORDER BY k PARTITION BY modulo(k, 2)"
+${CLICKHOUSE_CLIENT} --query="CREATE TABLE replicated_table_for_mutations(k UInt32, v1 UInt64) ENGINE ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/replicated_table_for_mutations', '1') ORDER BY k PARTITION BY modulo(k, 2) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'"
${CLICKHOUSE_CLIENT} --query="SYSTEM STOP MERGES replicated_table_for_mutations"
diff --git a/tests/queries/0_stateless/01049_zookeeper_synchronous_mutations_long.sql b/tests/queries/0_stateless/01049_zookeeper_synchronous_mutations_long.sql
index c77ab50ab8bd..2458fe14981f 100644
--- a/tests/queries/0_stateless/01049_zookeeper_synchronous_mutations_long.sql
+++ b/tests/queries/0_stateless/01049_zookeeper_synchronous_mutations_long.sql
@@ -5,9 +5,9 @@ DROP TABLE IF EXISTS table_for_synchronous_mutations2;
SELECT 'Replicated';
-CREATE TABLE table_for_synchronous_mutations1(k UInt32, v1 UInt64) ENGINE ReplicatedMergeTree('/clickhouse/tables/{database}/test_01049/table_for_synchronous_mutations', '1') ORDER BY k;
+CREATE TABLE table_for_synchronous_mutations1(k UInt32, v1 UInt64) ENGINE ReplicatedMergeTree('/clickhouse/tables/{database}/test_01049/table_for_synchronous_mutations', '1') ORDER BY k SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
-CREATE TABLE table_for_synchronous_mutations2(k UInt32, v1 UInt64) ENGINE ReplicatedMergeTree('/clickhouse/tables/{database}/test_01049/table_for_synchronous_mutations', '2') ORDER BY k;
+CREATE TABLE table_for_synchronous_mutations2(k UInt32, v1 UInt64) ENGINE ReplicatedMergeTree('/clickhouse/tables/{database}/test_01049/table_for_synchronous_mutations', '2') ORDER BY k SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO table_for_synchronous_mutations1 select number, number from numbers(100000);
@@ -29,7 +29,7 @@ SELECT 'Normal';
DROP TABLE IF EXISTS table_for_synchronous_mutations_no_replication;
-CREATE TABLE table_for_synchronous_mutations_no_replication(k UInt32, v1 UInt64) ENGINE MergeTree ORDER BY k;
+CREATE TABLE table_for_synchronous_mutations_no_replication(k UInt32, v1 UInt64) ENGINE MergeTree ORDER BY k SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO table_for_synchronous_mutations_no_replication select number, number from numbers(100000);
diff --git a/tests/queries/0_stateless/01060_shutdown_table_after_detach.sql b/tests/queries/0_stateless/01060_shutdown_table_after_detach.sql
index bfe928d70033..7a853f32d0fa 100644
--- a/tests/queries/0_stateless/01060_shutdown_table_after_detach.sql
+++ b/tests/queries/0_stateless/01060_shutdown_table_after_detach.sql
@@ -1,7 +1,7 @@
-- Tags: no-parallel
DROP TABLE IF EXISTS test;
-CREATE TABLE test Engine = MergeTree ORDER BY number AS SELECT number, toString(rand()) x from numbers(10000000);
+CREATE TABLE test Engine = MergeTree ORDER BY number SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi' AS SELECT number, toString(rand()) x from numbers(10000000);
SELECT count() FROM test;
diff --git a/tests/queries/0_stateless/01077_mutations_index_consistency.sh b/tests/queries/0_stateless/01077_mutations_index_consistency.sh
index c41eab62ecb0..ffbe3692b649 100755
--- a/tests/queries/0_stateless/01077_mutations_index_consistency.sh
+++ b/tests/queries/0_stateless/01077_mutations_index_consistency.sh
@@ -7,7 +7,7 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
$CLICKHOUSE_CLIENT --query "DROP TABLE IF EXISTS movement"
-$CLICKHOUSE_CLIENT -n --query "CREATE TABLE movement (date DateTime('Asia/Istanbul')) Engine = MergeTree ORDER BY (toStartOfHour(date));"
+$CLICKHOUSE_CLIENT -n --query "CREATE TABLE movement (date DateTime('Asia/Istanbul')) Engine = MergeTree ORDER BY (toStartOfHour(date)) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';"
$CLICKHOUSE_CLIENT --query "insert into movement select toDateTime('2020-01-22 00:00:00', 'Asia/Istanbul') + number%(23*3600) from numbers(1000000);"
diff --git a/tests/queries/0_stateless/01079_order_by_pk.sql b/tests/queries/0_stateless/01079_order_by_pk.sql
index 78e304b3118b..0b442bf78c9b 100644
--- a/tests/queries/0_stateless/01079_order_by_pk.sql
+++ b/tests/queries/0_stateless/01079_order_by_pk.sql
@@ -1,6 +1,6 @@
DROP TABLE IF EXISTS mt_pk;
-CREATE TABLE mt_pk ENGINE = MergeTree PARTITION BY d ORDER BY x
+CREATE TABLE mt_pk ENGINE = MergeTree PARTITION BY d ORDER BY x SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'
AS SELECT toDate(number % 32) AS d, number AS x FROM system.numbers LIMIT 10000010;
SELECT x FROM mt_pk ORDER BY x ASC LIMIT 10000000, 1;
diff --git a/tests/queries/0_stateless/01079_parallel_alter_add_drop_column_zookeeper.sh b/tests/queries/0_stateless/01079_parallel_alter_add_drop_column_zookeeper.sh
index 26c2bf133ace..bfdea95fa9e4 100755
--- a/tests/queries/0_stateless/01079_parallel_alter_add_drop_column_zookeeper.sh
+++ b/tests/queries/0_stateless/01079_parallel_alter_add_drop_column_zookeeper.sh
@@ -15,7 +15,7 @@ done
for i in $(seq $REPLICAS); do
- $CLICKHOUSE_CLIENT --query "CREATE TABLE concurrent_alter_add_drop_$i (key UInt64, value0 UInt8) ENGINE = ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/concurrent_alter_add_drop_column', '$i') ORDER BY key SETTINGS max_replicated_mutations_in_queue=1000, number_of_free_entries_in_pool_to_execute_mutation=0,max_replicated_merges_in_queue=1000"
+ $CLICKHOUSE_CLIENT --query "CREATE TABLE concurrent_alter_add_drop_$i (key UInt64, value0 UInt8) ENGINE = ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/concurrent_alter_add_drop_column', '$i') ORDER BY key SETTINGS max_replicated_mutations_in_queue = 1000, number_of_free_entries_in_pool_to_execute_mutation = 0, max_replicated_merges_in_queue = 1000, index_granularity = 8192, index_granularity_bytes = '10Mi'"
done
$CLICKHOUSE_CLIENT --query "INSERT INTO concurrent_alter_add_drop_1 SELECT number, number + 10 from numbers(100000)"
diff --git a/tests/queries/0_stateless/01137_order_by_func.sql b/tests/queries/0_stateless/01137_order_by_func.sql
index 682b2d391cee..536f2d1c61dc 100644
--- a/tests/queries/0_stateless/01137_order_by_func.sql
+++ b/tests/queries/0_stateless/01137_order_by_func.sql
@@ -1,5 +1,5 @@
DROP TABLE IF EXISTS pk_func;
-CREATE TABLE pk_func(d DateTime, ui UInt32) ENGINE = MergeTree ORDER BY toDate(d);
+CREATE TABLE pk_func(d DateTime, ui UInt32) ENGINE = MergeTree ORDER BY toDate(d) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO pk_func SELECT '2020-05-05 01:00:00', number FROM numbers(1000000);
INSERT INTO pk_func SELECT '2020-05-06 01:00:00', number FROM numbers(1000000);
@@ -10,7 +10,7 @@ SELECT * FROM pk_func ORDER BY toDate(d), ui LIMIT 5;
DROP TABLE pk_func;
DROP TABLE IF EXISTS nORX;
-CREATE TABLE nORX (`A` Int64, `B` Int64, `V` Int64) ENGINE = MergeTree ORDER BY (A, negate(B));
+CREATE TABLE nORX (`A` Int64, `B` Int64, `V` Int64) ENGINE = MergeTree ORDER BY (A, negate(B)) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO nORX SELECT 111, number, number FROM numbers(10000000);
SELECT *
diff --git a/tests/queries/0_stateless/01184_long_insert_values_huge_strings.sh b/tests/queries/0_stateless/01184_long_insert_values_huge_strings.sh
index 09a43d13a428..5e115e6b3af8 100755
--- a/tests/queries/0_stateless/01184_long_insert_values_huge_strings.sh
+++ b/tests/queries/0_stateless/01184_long_insert_values_huge_strings.sh
@@ -6,7 +6,7 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
. "$CURDIR"/../shell_config.sh
$CLICKHOUSE_CLIENT -q "drop table if exists huge_strings"
-$CLICKHOUSE_CLIENT -q "create table huge_strings (n UInt64, l UInt64, s String, h UInt64) engine=MergeTree order by n"
+$CLICKHOUSE_CLIENT -q "create table huge_strings (n UInt64, l UInt64, s String, h UInt64) engine=MergeTree order by n SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'"
# Timeouts are increased, because test can be slow with sanitizers and parallel runs.
diff --git a/tests/queries/0_stateless/01231_operator_null_in.sql b/tests/queries/0_stateless/01231_operator_null_in.sql
index 27ab0bbd8389..0424a995b3f0 100644
--- a/tests/queries/0_stateless/01231_operator_null_in.sql
+++ b/tests/queries/0_stateless/01231_operator_null_in.sql
@@ -1,5 +1,5 @@
DROP TABLE IF EXISTS null_in;
-CREATE TABLE null_in (dt DateTime, idx int, i Nullable(int), s Nullable(String)) ENGINE = MergeTree() PARTITION BY dt ORDER BY idx;
+CREATE TABLE null_in (dt DateTime, idx int, i Nullable(int), s Nullable(String)) ENGINE = MergeTree() PARTITION BY dt ORDER BY idx SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO null_in VALUES (1, 1, 1, '1') (2, 2, NULL, NULL) (3, 3, 3, '3') (4, 4, NULL, NULL) (5, 5, 5, '5');
@@ -81,7 +81,7 @@ DROP TABLE IF EXISTS null_in;
DROP TABLE IF EXISTS null_in_subquery;
-CREATE TABLE null_in_subquery (dt DateTime, idx int, i Nullable(UInt64)) ENGINE = MergeTree() PARTITION BY dt ORDER BY idx;
+CREATE TABLE null_in_subquery (dt DateTime, idx int, i Nullable(UInt64)) ENGINE = MergeTree() PARTITION BY dt ORDER BY idx SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO null_in_subquery SELECT number % 3, number, number FROM system.numbers LIMIT 99999;
SELECT count() == 33333 FROM null_in_subquery WHERE i in (SELECT i FROM null_in_subquery WHERE dt = 0);
@@ -111,7 +111,7 @@ DROP TABLE IF EXISTS null_in_subquery;
DROP TABLE IF EXISTS null_in_tuple;
-CREATE TABLE null_in_tuple (dt DateTime, idx int, t Tuple(Nullable(UInt64), Nullable(String))) ENGINE = MergeTree() PARTITION BY dt ORDER BY idx;
+CREATE TABLE null_in_tuple (dt DateTime, idx int, t Tuple(Nullable(UInt64), Nullable(String))) ENGINE = MergeTree() PARTITION BY dt ORDER BY idx SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO null_in_tuple VALUES (1, 1, (1, '1')) (2, 2, (2, NULL)) (3, 3, (NULL, '3')) (4, 4, (NULL, NULL))
SET transform_null_in = 0;
diff --git a/tests/queries/0_stateless/01289_min_execution_speed_not_too_early.sql b/tests/queries/0_stateless/01289_min_execution_speed_not_too_early.sql
index 222a85094d0c..1abe9bf8cd83 100644
--- a/tests/queries/0_stateless/01289_min_execution_speed_not_too_early.sql
+++ b/tests/queries/0_stateless/01289_min_execution_speed_not_too_early.sql
@@ -1,6 +1,6 @@
DROP TABLE IF EXISTS ES;
-create table ES(A String) Engine=MergeTree order by tuple();
+create table ES(A String) Engine=MergeTree order by tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into ES select toString(number) from numbers(10000000);
SET max_execution_time = 100,
diff --git a/tests/queries/0_stateless/01373_summing_merge_tree_exclude_partition_key.sql b/tests/queries/0_stateless/01373_summing_merge_tree_exclude_partition_key.sql
index c5a874efe09d..f1e1ab7c70f7 100644
--- a/tests/queries/0_stateless/01373_summing_merge_tree_exclude_partition_key.sql
+++ b/tests/queries/0_stateless/01373_summing_merge_tree_exclude_partition_key.sql
@@ -4,7 +4,7 @@ DROP TABLE IF EXISTS tt_01373;
CREATE TABLE tt_01373
(a Int64, d Int64, val Int64)
-ENGINE = SummingMergeTree PARTITION BY (a) ORDER BY (d);
+ENGINE = SummingMergeTree PARTITION BY (a) ORDER BY (d) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
SYSTEM STOP MERGES tt_01373;
diff --git a/tests/queries/0_stateless/01441_low_cardinality_array_index.sql b/tests/queries/0_stateless/01441_low_cardinality_array_index.sql
index 8febe8f2e446..4b31a86edfbc 100644
--- a/tests/queries/0_stateless/01441_low_cardinality_array_index.sql
+++ b/tests/queries/0_stateless/01441_low_cardinality_array_index.sql
@@ -4,7 +4,7 @@ CREATE TABLE t_01411(
str LowCardinality(String),
arr Array(LowCardinality(String)) default [str]
) ENGINE = MergeTree()
-ORDER BY tuple();
+ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t_01411 (str) SELECT concat('asdf', toString(number % 10000)) FROM numbers(1000000);
@@ -24,7 +24,7 @@ CREATE TABLE t_01411_num(
num UInt8,
arr Array(LowCardinality(Int64)) default [num]
) ENGINE = MergeTree()
-ORDER BY tuple();
+ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t_01411_num (num) SELECT number % 1000 FROM numbers(1000000);
diff --git a/tests/queries/0_stateless/01524_do_not_merge_across_partitions_select_final.sql b/tests/queries/0_stateless/01524_do_not_merge_across_partitions_select_final.sql
index e3bc8cf6e729..3ce1c3aa1319 100644
--- a/tests/queries/0_stateless/01524_do_not_merge_across_partitions_select_final.sql
+++ b/tests/queries/0_stateless/01524_do_not_merge_across_partitions_select_final.sql
@@ -4,7 +4,7 @@ SET allow_asynchronous_read_from_io_pool_for_merge_tree = 0;
SET do_not_merge_across_partitions_select_final = 1;
SET max_threads = 16;
-CREATE TABLE select_final (t DateTime, x Int32, string String) ENGINE = ReplacingMergeTree() PARTITION BY toYYYYMM(t) ORDER BY (x, t);
+CREATE TABLE select_final (t DateTime, x Int32, string String) ENGINE = ReplacingMergeTree() PARTITION BY toYYYYMM(t) ORDER BY (x, t) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO select_final SELECT toDate('2000-01-01'), number, '' FROM numbers(2);
INSERT INTO select_final SELECT toDate('2000-01-01'), number + 1, '' FROM numbers(2);
diff --git a/tests/queries/0_stateless/01550_create_map_type.sql b/tests/queries/0_stateless/01550_create_map_type.sql
index 26bbf3c7ddea..92362f5596bf 100644
--- a/tests/queries/0_stateless/01550_create_map_type.sql
+++ b/tests/queries/0_stateless/01550_create_map_type.sql
@@ -9,14 +9,14 @@ drop table if exists table_map;
drop table if exists table_map;
-create table table_map (a Map(String, UInt64)) engine = MergeTree() order by a;
+create table table_map (a Map(String, UInt64)) engine = MergeTree() order by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into table_map select map('key1', number, 'key2', number * 2) from numbers(1111, 3);
select a['key1'], a['key2'] from table_map;
drop table if exists table_map;
-- MergeTree Engine
drop table if exists table_map;
-create table table_map (a Map(String, String), b String) engine = MergeTree() order by a;
+create table table_map (a Map(String, String), b String) engine = MergeTree() order by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into table_map values ({'name':'zhangsan', 'gender':'male'}, 'name'), ({'name':'lisi', 'gender':'female'}, 'gender');
select a[b] from table_map;
select b from table_map where a = map('name','lisi', 'gender', 'female');
@@ -24,21 +24,21 @@ drop table if exists table_map;
-- Big Integer type
-create table table_map (d DATE, m Map(Int8, UInt256)) ENGINE = MergeTree() order by d;
+create table table_map (d DATE, m Map(Int8, UInt256)) ENGINE = MergeTree() order by d SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into table_map values ('2020-01-01', map(1, 0, 2, 1));
select * from table_map;
drop table table_map;
-- Integer type
-create table table_map (d DATE, m Map(Int8, Int8)) ENGINE = MergeTree() order by d;
+create table table_map (d DATE, m Map(Int8, Int8)) ENGINE = MergeTree() order by d SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into table_map values ('2020-01-01', map(1, 0, 2, -1));
select * from table_map;
drop table table_map;
-- Unsigned Int type
drop table if exists table_map;
-create table table_map(a Map(UInt8, UInt64), b UInt8) Engine = MergeTree() order by b;
+create table table_map(a Map(UInt8, UInt64), b UInt8) Engine = MergeTree() order by b SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into table_map select map(number, number+5), number from numbers(1111,4);
select a[b] from table_map;
drop table if exists table_map;
@@ -46,7 +46,7 @@ drop table if exists table_map;
-- Array Type
drop table if exists table_map;
-create table table_map(a Map(String, Array(UInt8))) Engine = MergeTree() order by a;
+create table table_map(a Map(String, Array(UInt8))) Engine = MergeTree() order by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into table_map values(map('k1', [1,2,3], 'k2', [4,5,6])), (map('k0', [], 'k1', [100,20,90]));
insert into table_map select map('k1', [number, number + 2, number * 2]) from numbers(6);
insert into table_map select map('k2', [number, number + 2, number * 2]) from numbers(6);
@@ -56,7 +56,7 @@ drop table if exists table_map;
SELECT CAST(([1, 2, 3], ['1', '2', 'foo']), 'Map(UInt8, String)') AS map, map[1];
CREATE TABLE table_map (n UInt32, m Map(String, Int))
-ENGINE = MergeTree ORDER BY n SETTINGS min_bytes_for_wide_part = 0;
+ENGINE = MergeTree ORDER BY n SETTINGS min_bytes_for_wide_part = 0, index_granularity = 8192, index_granularity_bytes = '10Mi';
-- coversion from Tuple(Array(K), Array(V))
INSERT INTO table_map SELECT number, (arrayMap(x -> toString(x), range(number % 10 + 2)), range(number % 10 + 2)) FROM numbers(100000);
@@ -67,7 +67,7 @@ SELECT sum(m['1']), sum(m['7']), sum(m['100']) FROM table_map;
DROP TABLE IF EXISTS table_map;
CREATE TABLE table_map (n UInt32, m Map(String, Int))
-ENGINE = MergeTree ORDER BY n;
+ENGINE = MergeTree ORDER BY n SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
-- coversion from Tuple(Array(K), Array(V))
INSERT INTO table_map SELECT number, (arrayMap(x -> toString(x), range(number % 10 + 2)), range(number % 10 + 2)) FROM numbers(100000);
diff --git a/tests/queries/0_stateless/01592_long_window_functions1.sql b/tests/queries/0_stateless/01592_long_window_functions1.sql
index 4911b7aa792b..c63c651fb0b8 100644
--- a/tests/queries/0_stateless/01592_long_window_functions1.sql
+++ b/tests/queries/0_stateless/01592_long_window_functions1.sql
@@ -7,7 +7,7 @@ set max_insert_threads = 4;
create table stack(item_id Int64, brand_id Int64, rack_id Int64, dt DateTime, expiration_dt DateTime, quantity UInt64)
Engine = MergeTree
partition by toYYYYMM(dt)
-order by (brand_id, toStartOfHour(dt));
+order by (brand_id, toStartOfHour(dt)) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into stack
select number%99991, number%11, number%1111, toDateTime('2020-01-01 00:00:00')+number/100,
diff --git a/tests/queries/0_stateless/01600_parts_types_metrics_long.sh b/tests/queries/0_stateless/01600_parts_types_metrics_long.sh
index 5f724e810422..6bc22f2e7942 100755
--- a/tests/queries/0_stateless/01600_parts_types_metrics_long.sh
+++ b/tests/queries/0_stateless/01600_parts_types_metrics_long.sh
@@ -35,7 +35,7 @@ $CLICKHOUSE_CLIENT --database_atomic_wait_for_drop_and_detach_synchronously=1 --
# InMemory - [0..5]
# Compact - (5..10]
# Wide - >10
-$CLICKHOUSE_CLIENT --query="CREATE TABLE data_01600 (part_type String, key Int) ENGINE = MergeTree PARTITION BY part_type ORDER BY key SETTINGS min_bytes_for_wide_part=0, min_rows_for_wide_part=10"
+$CLICKHOUSE_CLIENT --query="CREATE TABLE data_01600 (part_type String, key Int) ENGINE = MergeTree PARTITION BY part_type ORDER BY key SETTINGS min_bytes_for_wide_part=0, min_rows_for_wide_part=10, index_granularity = 8192, index_granularity_bytes = '10Mi'"
# InMemory
$CLICKHOUSE_CLIENT --query="INSERT INTO data_01600 SELECT 'InMemory', number FROM system.numbers LIMIT 1"
diff --git a/tests/queries/0_stateless/01603_read_with_backoff_bug.sql b/tests/queries/0_stateless/01603_read_with_backoff_bug.sql
index 569a92f3048d..1cf52c0288b1 100644
--- a/tests/queries/0_stateless/01603_read_with_backoff_bug.sql
+++ b/tests/queries/0_stateless/01603_read_with_backoff_bug.sql
@@ -5,7 +5,7 @@ set enable_filesystem_cache=0;
set enable_filesystem_cache_on_write_operations=0;
drop table if exists t;
-create table t (x UInt64, s String) engine = MergeTree order by x;
+create table t (x UInt64, s String) engine = MergeTree order by x SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t SELECT
number,
if(number < (8129 * 1024), arrayStringConcat(arrayMap(x -> toString(x), range(number % 128)), ' '), '')
diff --git a/tests/queries/0_stateless/01606_merge_from_wide_to_compact.sql b/tests/queries/0_stateless/01606_merge_from_wide_to_compact.sql
index 0f2fbcaa76d9..de3b79eec767 100644
--- a/tests/queries/0_stateless/01606_merge_from_wide_to_compact.sql
+++ b/tests/queries/0_stateless/01606_merge_from_wide_to_compact.sql
@@ -5,7 +5,8 @@ CREATE TABLE wide_to_comp (a Int, b Int, c Int)
settings vertical_merge_algorithm_min_rows_to_activate = 1,
vertical_merge_algorithm_min_columns_to_activate = 1,
min_bytes_for_wide_part = 0,
- min_rows_for_wide_part = 0;
+ min_rows_for_wide_part = 0,
+ index_granularity = 8192, index_granularity_bytes = '10Mi';
SYSTEM STOP merges wide_to_comp;
diff --git a/tests/queries/0_stateless/01739_index_hint.reference b/tests/queries/0_stateless/01739_index_hint.reference
index 766dff8c7b02..21673bf698bc 100644
--- a/tests/queries/0_stateless/01739_index_hint.reference
+++ b/tests/queries/0_stateless/01739_index_hint.reference
@@ -23,12 +23,12 @@ select * from tbl WHERE indexHint(p in (select toInt64(number) - 2 from numbers(
0 3 0
drop table tbl;
drop table if exists XXXX;
-create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=128;
+create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=128, index_granularity_bytes = '10Mi';
insert into XXXX select number*60, 0 from numbers(100000);
SELECT sum(t) FROM XXXX WHERE indexHint(t = 42);
487680
drop table if exists XXXX;
-create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=8192;
+create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=8192, index_granularity_bytes = '10Mi';
insert into XXXX select number*60, 0 from numbers(100000);
SELECT count() FROM XXXX WHERE indexHint(t = toDateTime(0)) SETTINGS optimize_use_implicit_projections = 1;
100000
diff --git a/tests/queries/0_stateless/01739_index_hint.sql b/tests/queries/0_stateless/01739_index_hint.sql
index 77c2760535dd..cde46a5a2bf9 100644
--- a/tests/queries/0_stateless/01739_index_hint.sql
+++ b/tests/queries/0_stateless/01739_index_hint.sql
@@ -18,7 +18,7 @@ drop table tbl;
drop table if exists XXXX;
-create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=128;
+create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=128, index_granularity_bytes = '10Mi';
insert into XXXX select number*60, 0 from numbers(100000);
@@ -26,7 +26,7 @@ SELECT sum(t) FROM XXXX WHERE indexHint(t = 42);
drop table if exists XXXX;
-create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=8192;
+create table XXXX (t Int64, f Float64) Engine=MergeTree order by t settings index_granularity=8192, index_granularity_bytes = '10Mi';
insert into XXXX select number*60, 0 from numbers(100000);
diff --git a/tests/queries/0_stateless/01746_test_for_tupleElement_must_be_constant_issue.sql b/tests/queries/0_stateless/01746_test_for_tupleElement_must_be_constant_issue.sql
index 72ba6a036dff..585640665d1a 100644
--- a/tests/queries/0_stateless/01746_test_for_tupleElement_must_be_constant_issue.sql
+++ b/tests/queries/0_stateless/01746_test_for_tupleElement_must_be_constant_issue.sql
@@ -1,5 +1,5 @@
DROP TABLE IF EXISTS ttt01746;
-CREATE TABLE ttt01746 (d Date, n UInt64) ENGINE = MergeTree() PARTITION BY toMonday(d) ORDER BY n;
+CREATE TABLE ttt01746 (d Date, n UInt64) ENGINE = MergeTree() PARTITION BY toMonday(d) ORDER BY n SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO ttt01746 SELECT toDate('2021-02-14') + (number % 30) AS d, number AS n FROM numbers(1500000);
set optimize_move_to_prewhere=0;
SELECT arraySort(x -> x.2, [tuple('a', 10)]) AS X FROM ttt01746 WHERE d >= toDate('2021-03-03') - 2 ORDER BY n LIMIT 1;
diff --git a/tests/queries/0_stateless/01763_filter_push_down_bugs.sql b/tests/queries/0_stateless/01763_filter_push_down_bugs.sql
index 8470b4a33792..367baef142ba 100644
--- a/tests/queries/0_stateless/01763_filter_push_down_bugs.sql
+++ b/tests/queries/0_stateless/01763_filter_push_down_bugs.sql
@@ -9,6 +9,7 @@ CREATE TABLE Test
ENGINE = MergeTree()
PRIMARY KEY (String1,String2)
ORDER BY (String1,String2)
+SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'
AS
SELECT
'String1_' || toString(number) as String1,
@@ -39,15 +40,15 @@ DROP TABLE IF EXISTS Test;
select x, y from (select [0, 1, 2] as y, 1 as a, 2 as b) array join y as x where a = 1 and b = 2 and (x = 1 or x != 1) and x = 1;
DROP TABLE IF EXISTS t;
-create table t(a UInt8) engine=MergeTree order by a;
+create table t(a UInt8) engine=MergeTree order by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t select * from numbers(2);
select a from t t1 join t t2 on t1.a = t2.a where t1.a;
DROP TABLE IF EXISTS t;
DROP TABLE IF EXISTS t1;
DROP TABLE IF EXISTS t2;
-CREATE TABLE t1 (id Int64, create_time DateTime) ENGINE = MergeTree ORDER BY id;
-CREATE TABLE t2 (delete_time DateTime) ENGINE = MergeTree ORDER BY delete_time;
+CREATE TABLE t1 (id Int64, create_time DateTime) ENGINE = MergeTree ORDER BY id SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
+CREATE TABLE t2 (delete_time DateTime) ENGINE = MergeTree ORDER BY delete_time SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t1 values (101, '2023-05-28 00:00:00'), (102, '2023-05-28 00:00:00');
insert into t2 values ('2023-05-31 00:00:00');
diff --git a/tests/queries/0_stateless/01771_bloom_filter_not_has.sql b/tests/queries/0_stateless/01771_bloom_filter_not_has.sql
index f945cbde56b9..00b71d6feeb8 100644
--- a/tests/queries/0_stateless/01771_bloom_filter_not_has.sql
+++ b/tests/queries/0_stateless/01771_bloom_filter_not_has.sql
@@ -1,6 +1,6 @@
-- Tags: no-parallel, long
DROP TABLE IF EXISTS bloom_filter_null_array;
-CREATE TABLE bloom_filter_null_array (v Array(Int32), INDEX idx v TYPE bloom_filter GRANULARITY 3) ENGINE = MergeTree() ORDER BY v;
+CREATE TABLE bloom_filter_null_array (v Array(Int32), INDEX idx v TYPE bloom_filter GRANULARITY 3) ENGINE = MergeTree() ORDER BY v SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO bloom_filter_null_array SELECT [number] FROM numbers(10000000);
SELECT COUNT() FROM bloom_filter_null_array;
SELECT COUNT() FROM bloom_filter_null_array WHERE has(v, 0);
diff --git a/tests/queries/0_stateless/01780_column_sparse_filter.sql b/tests/queries/0_stateless/01780_column_sparse_filter.sql
index 45958b5c4e00..f52beba50b05 100644
--- a/tests/queries/0_stateless/01780_column_sparse_filter.sql
+++ b/tests/queries/0_stateless/01780_column_sparse_filter.sql
@@ -2,7 +2,7 @@ DROP TABLE IF EXISTS t_sparse;
CREATE TABLE t_sparse (id UInt64, u UInt64, s String)
ENGINE = MergeTree ORDER BY id
-SETTINGS ratio_of_defaults_for_sparse_serialization = 0.9;
+SETTINGS ratio_of_defaults_for_sparse_serialization = 0.9, index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t_sparse SELECT
number,
diff --git a/tests/queries/0_stateless/01825_type_json_sparse.sql b/tests/queries/0_stateless/01825_type_json_sparse.sql
index 343013cb3da5..cc7c66382a36 100644
--- a/tests/queries/0_stateless/01825_type_json_sparse.sql
+++ b/tests/queries/0_stateless/01825_type_json_sparse.sql
@@ -7,7 +7,7 @@ SET allow_experimental_object_type = 1;
CREATE TABLE t_json_sparse (data JSON)
ENGINE = MergeTree ORDER BY tuple()
SETTINGS ratio_of_defaults_for_sparse_serialization = 0.1,
-min_bytes_for_wide_part = 0;
+min_bytes_for_wide_part = 0, index_granularity = 8192, index_granularity_bytes = '10Mi';
SYSTEM STOP MERGES t_json_sparse;
diff --git a/tests/queries/0_stateless/01861_explain_pipeline.sql b/tests/queries/0_stateless/01861_explain_pipeline.sql
index aafecf57af12..93c82b6e2651 100644
--- a/tests/queries/0_stateless/01861_explain_pipeline.sql
+++ b/tests/queries/0_stateless/01861_explain_pipeline.sql
@@ -1,5 +1,5 @@
DROP TABLE IF EXISTS test;
-CREATE TABLE test(a Int, b Int) Engine=ReplacingMergeTree order by a;
+CREATE TABLE test(a Int, b Int) Engine=ReplacingMergeTree order by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO test select number, number from numbers(5);
INSERT INTO test select number, number from numbers(5,2);
set max_threads =1;
diff --git a/tests/queries/0_stateless/01906_lc_in_bug.sql b/tests/queries/0_stateless/01906_lc_in_bug.sql
index 581053e14e19..035e1fa155f2 100644
--- a/tests/queries/0_stateless/01906_lc_in_bug.sql
+++ b/tests/queries/0_stateless/01906_lc_in_bug.sql
@@ -8,6 +8,6 @@ select count() as c, x in ('a', 'bb') as g from tab group by g order by c;
drop table if exists tab;
-- https://github.com/ClickHouse/ClickHouse/issues/44503
-CREATE TABLE test(key Int32) ENGINE = MergeTree ORDER BY (key);
+CREATE TABLE test(key Int32) ENGINE = MergeTree ORDER BY (key) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into test select intDiv(number,100) from numbers(10000000);
SELECT COUNT() FROM test WHERE key <= 100000 AND (NOT (toLowCardinality('') IN (SELECT '')));
diff --git a/tests/queries/0_stateless/01913_quantile_deterministic.sh b/tests/queries/0_stateless/01913_quantile_deterministic.sh
index 5a2c72796785..a9c57a61c337 100755
--- a/tests/queries/0_stateless/01913_quantile_deterministic.sh
+++ b/tests/queries/0_stateless/01913_quantile_deterministic.sh
@@ -5,7 +5,7 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
. "$CURDIR"/../shell_config.sh
${CLICKHOUSE_CLIENT} --query "DROP TABLE IF EXISTS d"
-${CLICKHOUSE_CLIENT} --query "CREATE TABLE d (oid UInt64) ENGINE = MergeTree ORDER BY oid"
+${CLICKHOUSE_CLIENT} --query "CREATE TABLE d (oid UInt64) ENGINE = MergeTree ORDER BY oid SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'"
${CLICKHOUSE_CLIENT} --min_insert_block_size_rows 0 --min_insert_block_size_bytes 0 --max_block_size 8192 --query "insert into d select * from numbers(1000000)"
# In previous ClickHouse versions there was a mistake that makes quantileDeterministic functions not really deterministic (in edge cases).
diff --git a/tests/queries/0_stateless/02067_lost_part_s3.sql b/tests/queries/0_stateless/02067_lost_part_s3.sql
index bfdf92500368..6fbde71ff982 100644
--- a/tests/queries/0_stateless/02067_lost_part_s3.sql
+++ b/tests/queries/0_stateless/02067_lost_part_s3.sql
@@ -6,15 +6,18 @@ DROP TABLE IF EXISTS partslost_2;
CREATE TABLE partslost_0 (x String) ENGINE=ReplicatedMergeTree('/clickhouse/table/{database}_02067_lost/partslost', '0') ORDER BY tuple()
SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0, old_parts_lifetime = 1,
- cleanup_delay_period = 1, cleanup_delay_period_random_add = 1, cleanup_thread_preferred_points_per_iteration=0;
+ cleanup_delay_period = 1, cleanup_delay_period_random_add = 1, cleanup_thread_preferred_points_per_iteration=0,
+ index_granularity = 8192, index_granularity_bytes = '10Mi';
CREATE TABLE partslost_1 (x String) ENGINE=ReplicatedMergeTree('/clickhouse/table/{database}_02067_lost/partslost', '1') ORDER BY tuple()
SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0, old_parts_lifetime = 1,
- cleanup_delay_period = 1, cleanup_delay_period_random_add = 1, cleanup_thread_preferred_points_per_iteration=0;
+ cleanup_delay_period = 1, cleanup_delay_period_random_add = 1, cleanup_thread_preferred_points_per_iteration=0,
+ index_granularity = 8192, index_granularity_bytes = '10Mi';
CREATE TABLE partslost_2 (x String) ENGINE=ReplicatedMergeTree('/clickhouse/table/{database}_02067_lost/partslost', '2') ORDER BY tuple()
SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0, old_parts_lifetime = 1,
- cleanup_delay_period = 1, cleanup_delay_period_random_add = 1, cleanup_thread_preferred_points_per_iteration=0;
+ cleanup_delay_period = 1, cleanup_delay_period_random_add = 1, cleanup_thread_preferred_points_per_iteration=0,
+ index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO partslost_0 SELECT toString(number) AS x from system.numbers LIMIT 10000;
diff --git a/tests/queries/0_stateless/02149_read_in_order_fixed_prefix.sql b/tests/queries/0_stateless/02149_read_in_order_fixed_prefix.sql
index 5e662bd78426..0834b76d4ec6 100644
--- a/tests/queries/0_stateless/02149_read_in_order_fixed_prefix.sql
+++ b/tests/queries/0_stateless/02149_read_in_order_fixed_prefix.sql
@@ -5,7 +5,7 @@ SET read_in_order_two_level_merge_threshold=100;
DROP TABLE IF EXISTS t_read_in_order;
CREATE TABLE t_read_in_order(date Date, i UInt64, v UInt64)
-ENGINE = MergeTree ORDER BY (date, i);
+ENGINE = MergeTree ORDER BY (date, i) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t_read_in_order SELECT '2020-10-10', number % 10, number FROM numbers(100000);
INSERT INTO t_read_in_order SELECT '2020-10-11', number % 10, number FROM numbers(100000);
@@ -55,7 +55,7 @@ SELECT a, b FROM t_read_in_order WHERE a = 1 ORDER BY b DESC SETTINGS read_in_or
DROP TABLE t_read_in_order;
CREATE TABLE t_read_in_order(dt DateTime, d Decimal64(5), v UInt64)
-ENGINE = MergeTree ORDER BY (toStartOfDay(dt), d);
+ENGINE = MergeTree ORDER BY (toStartOfDay(dt), d) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t_read_in_order SELECT toDateTime('2020-10-10 00:00:00') + number, 1 / (number % 100 + 1), number FROM numbers(1000);
diff --git a/tests/queries/0_stateless/02150_index_hypothesis_race_long.sh b/tests/queries/0_stateless/02150_index_hypothesis_race_long.sh
index da2dcd055eae..114f60cc3930 100755
--- a/tests/queries/0_stateless/02150_index_hypothesis_race_long.sh
+++ b/tests/queries/0_stateless/02150_index_hypothesis_race_long.sh
@@ -6,7 +6,7 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
$CLICKHOUSE_CLIENT -q "DROP TABLE IF EXISTS t_index_hypothesis"
-$CLICKHOUSE_CLIENT -q "CREATE TABLE t_index_hypothesis (a UInt32, b UInt32, INDEX t a != b TYPE hypothesis GRANULARITY 1) ENGINE = MergeTree ORDER BY a"
+$CLICKHOUSE_CLIENT -q "CREATE TABLE t_index_hypothesis (a UInt32, b UInt32, INDEX t a != b TYPE hypothesis GRANULARITY 1) ENGINE = MergeTree ORDER BY a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'"
$CLICKHOUSE_CLIENT -q "INSERT INTO t_index_hypothesis SELECT number, number + 1 FROM numbers(10000000)"
diff --git a/tests/queries/0_stateless/02151_hash_table_sizes_stats.sh b/tests/queries/0_stateless/02151_hash_table_sizes_stats.sh
index fd6e44577d99..bf79e5f769d6 100755
--- a/tests/queries/0_stateless/02151_hash_table_sizes_stats.sh
+++ b/tests/queries/0_stateless/02151_hash_table_sizes_stats.sh
@@ -17,9 +17,9 @@ prepare_table() {
table_name="t_hash_table_sizes_stats_$RANDOM$RANDOM"
$CLICKHOUSE_CLIENT -q "DROP TABLE IF EXISTS $table_name;"
if [ -z "$1" ]; then
- $CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY tuple();"
+ $CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';"
else
- $CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY $1;"
+ $CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY $1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';"
fi
$CLICKHOUSE_CLIENT -q "SYSTEM STOP MERGES $table_name;"
for ((i = 1; i <= max_threads; i++)); do
diff --git a/tests/queries/0_stateless/02151_hash_table_sizes_stats_distributed.sh b/tests/queries/0_stateless/02151_hash_table_sizes_stats_distributed.sh
index b23be4283b2f..77b9b2942c5a 100755
--- a/tests/queries/0_stateless/02151_hash_table_sizes_stats_distributed.sh
+++ b/tests/queries/0_stateless/02151_hash_table_sizes_stats_distributed.sh
@@ -19,9 +19,9 @@ prepare_table() {
table_name="t_hash_table_sizes_stats_$RANDOM$RANDOM"
$CLICKHOUSE_CLIENT -q "DROP TABLE IF EXISTS $table_name;"
if [ -z "$1" ]; then
- $CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY tuple();"
+ $CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';"
else
- $CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY $1;"
+ $CLICKHOUSE_CLIENT -q "CREATE TABLE $table_name(number UInt64) Engine=MergeTree() ORDER BY $1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';"
fi
$CLICKHOUSE_CLIENT -q "SYSTEM STOP MERGES $table_name;"
for ((i = 1; i <= max_threads; i++)); do
diff --git a/tests/queries/0_stateless/02151_lc_prefetch.sql b/tests/queries/0_stateless/02151_lc_prefetch.sql
index 83d8d23264ed..c2b972311450 100644
--- a/tests/queries/0_stateless/02151_lc_prefetch.sql
+++ b/tests/queries/0_stateless/02151_lc_prefetch.sql
@@ -1,6 +1,6 @@
-- Tags: no-tsan, no-asan, no-ubsan, no-msan, no-debug
drop table if exists tab_lc;
-CREATE TABLE tab_lc (x UInt64, y LowCardinality(String)) engine = MergeTree order by x;
+CREATE TABLE tab_lc (x UInt64, y LowCardinality(String)) engine = MergeTree order by x SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into tab_lc select number, toString(number % 10) from numbers(20000000);
optimize table tab_lc;
select count() from tab_lc where y == '0' settings local_filesystem_read_prefetch=1;
diff --git a/tests/queries/0_stateless/02177_issue_31009.sql b/tests/queries/0_stateless/02177_issue_31009.sql
index 280627954d9c..f25df59f4b4c 100644
--- a/tests/queries/0_stateless/02177_issue_31009.sql
+++ b/tests/queries/0_stateless/02177_issue_31009.sql
@@ -5,8 +5,8 @@ SET max_threads=0;
DROP TABLE IF EXISTS left;
DROP TABLE IF EXISTS right;
-CREATE TABLE left ( key UInt32, value String ) ENGINE = MergeTree ORDER BY key;
-CREATE TABLE right ( key UInt32, value String ) ENGINE = MergeTree ORDER BY tuple();
+CREATE TABLE left ( key UInt32, value String ) ENGINE = MergeTree ORDER BY key SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
+CREATE TABLE right ( key UInt32, value String ) ENGINE = MergeTree ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO left SELECT number, toString(number) FROM numbers(25367182);
INSERT INTO right SELECT number, toString(number) FROM numbers(23124707);
diff --git a/tests/queries/0_stateless/02233_set_enable_with_statement_cte_perf.sql b/tests/queries/0_stateless/02233_set_enable_with_statement_cte_perf.sql
index 71321b4dfe46..3b474369c982 100644
--- a/tests/queries/0_stateless/02233_set_enable_with_statement_cte_perf.sql
+++ b/tests/queries/0_stateless/02233_set_enable_with_statement_cte_perf.sql
@@ -1,8 +1,8 @@
DROP TABLE IF EXISTS ev;
DROP TABLE IF EXISTS idx;
-CREATE TABLE ev (a Int32, b Int32) Engine=MergeTree() ORDER BY a;
-CREATE TABLE idx (a Int32) Engine=MergeTree() ORDER BY a;
+CREATE TABLE ev (a Int32, b Int32) Engine=MergeTree() ORDER BY a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
+CREATE TABLE idx (a Int32) Engine=MergeTree() ORDER BY a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO ev SELECT number, number FROM numbers(10000000);
INSERT INTO idx SELECT number * 5 FROM numbers(1000);
diff --git a/tests/queries/0_stateless/02235_add_part_offset_virtual_column.sql b/tests/queries/0_stateless/02235_add_part_offset_virtual_column.sql
index 1de6447172d7..dc8fceddc523 100644
--- a/tests/queries/0_stateless/02235_add_part_offset_virtual_column.sql
+++ b/tests/queries/0_stateless/02235_add_part_offset_virtual_column.sql
@@ -12,7 +12,8 @@ CREATE TABLE t_1
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(p_time)
-ORDER BY order_0;
+ORDER BY order_0
+SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
CREATE TABLE t_random_1
(
diff --git a/tests/queries/0_stateless/02275_full_sort_join_long.sql.j2 b/tests/queries/0_stateless/02275_full_sort_join_long.sql.j2
index 621352f9c25a..53fab9d62712 100644
--- a/tests/queries/0_stateless/02275_full_sort_join_long.sql.j2
+++ b/tests/queries/0_stateless/02275_full_sort_join_long.sql.j2
@@ -2,8 +2,8 @@
DROP TABLE IF EXISTS t1;
DROP TABLE IF EXISTS t2;
-CREATE TABLE t1 (key UInt32, s String) ENGINE = MergeTree ORDER BY key;
-CREATE TABLE t2 (key UInt32, s String) ENGINE = MergeTree ORDER BY key;
+CREATE TABLE t1 (key UInt32, s String) ENGINE = MergeTree ORDER BY key SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
+CREATE TABLE t2 (key UInt32, s String) ENGINE = MergeTree ORDER BY key SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
{% set ltable_size = 10000000 -%}
{% set rtable_size = 1000000 -%}
diff --git a/tests/queries/0_stateless/02319_no_columns_in_row_level_filter.sql b/tests/queries/0_stateless/02319_no_columns_in_row_level_filter.sql
index e6bc475b0815..27f58dbff5ee 100644
--- a/tests/queries/0_stateless/02319_no_columns_in_row_level_filter.sql
+++ b/tests/queries/0_stateless/02319_no_columns_in_row_level_filter.sql
@@ -4,7 +4,7 @@ DROP TABLE IF EXISTS test_table;
CREATE TABLE test_table (`n` UInt64, `s` String)
ENGINE = MergeTree
-PRIMARY KEY n ORDER BY n;
+PRIMARY KEY n ORDER BY n SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO test_table SELECT number, concat('some string ', CAST(number, 'String')) FROM numbers(1000000);
diff --git a/tests/queries/0_stateless/02336_sparse_columns_s3.sql b/tests/queries/0_stateless/02336_sparse_columns_s3.sql
index 235123597282..bf4622adedc3 100644
--- a/tests/queries/0_stateless/02336_sparse_columns_s3.sql
+++ b/tests/queries/0_stateless/02336_sparse_columns_s3.sql
@@ -5,7 +5,8 @@ DROP TABLE IF EXISTS t_sparse_s3;
CREATE TABLE t_sparse_s3 (id UInt32, cond UInt8, s String)
engine = MergeTree ORDER BY id
settings ratio_of_defaults_for_sparse_serialization = 0.01, storage_policy = 's3_cache',
-min_bytes_for_wide_part = 0, min_compress_block_size = 1;
+min_bytes_for_wide_part = 0, min_compress_block_size = 1,
+index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t_sparse_s3 SELECT 1, number % 2, '' FROM numbers(8192);
INSERT INTO t_sparse_s3 SELECT 2, number % 2, '' FROM numbers(24576);
diff --git a/tests/queries/0_stateless/02344_distinct_limit_distiributed.sql b/tests/queries/0_stateless/02344_distinct_limit_distiributed.sql
index d0d9b130b7ed..c963199e05c2 100644
--- a/tests/queries/0_stateless/02344_distinct_limit_distiributed.sql
+++ b/tests/queries/0_stateless/02344_distinct_limit_distiributed.sql
@@ -1,7 +1,7 @@
drop table if exists t_distinct_limit;
create table t_distinct_limit (d Date, id Int64)
-engine = MergeTree partition by toYYYYMM(d) order by d;
+engine = MergeTree partition by toYYYYMM(d) order by d SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
set max_threads = 10;
diff --git a/tests/queries/0_stateless/02354_distributed_with_external_aggregation_memory_usage.sql b/tests/queries/0_stateless/02354_distributed_with_external_aggregation_memory_usage.sql
index c8ec40bb0a73..3e181a281a0d 100644
--- a/tests/queries/0_stateless/02354_distributed_with_external_aggregation_memory_usage.sql
+++ b/tests/queries/0_stateless/02354_distributed_with_external_aggregation_memory_usage.sql
@@ -2,7 +2,7 @@
DROP TABLE IF EXISTS t_2354_dist_with_external_aggr;
-create table t_2354_dist_with_external_aggr(a UInt64, b String, c FixedString(100)) engine = MergeTree order by tuple();
+create table t_2354_dist_with_external_aggr(a UInt64, b String, c FixedString(100)) engine = MergeTree order by tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t_2354_dist_with_external_aggr select number, toString(number) as s, toFixedString(s, 100) from numbers_mt(5e7);
diff --git a/tests/queries/0_stateless/02377_modify_column_from_lc.sql b/tests/queries/0_stateless/02377_modify_column_from_lc.sql
index a578e7cb03aa..efee323e88d0 100644
--- a/tests/queries/0_stateless/02377_modify_column_from_lc.sql
+++ b/tests/queries/0_stateless/02377_modify_column_from_lc.sql
@@ -9,7 +9,7 @@ CREATE TABLE t_modify_from_lc_1
a LowCardinality(UInt32) CODEC(NONE)
)
ENGINE = MergeTree ORDER BY tuple()
-SETTINGS min_bytes_for_wide_part = 0;
+SETTINGS min_bytes_for_wide_part = 0, index_granularity = 8192, index_granularity_bytes = '10Mi';
CREATE TABLE t_modify_from_lc_2
(
@@ -17,7 +17,7 @@ CREATE TABLE t_modify_from_lc_2
a LowCardinality(UInt32) CODEC(NONE)
)
ENGINE = MergeTree ORDER BY tuple()
-SETTINGS min_bytes_for_wide_part = 0;
+SETTINGS min_bytes_for_wide_part = 0, index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO t_modify_from_lc_1 SELECT number, number FROM numbers(100000);
INSERT INTO t_modify_from_lc_2 SELECT number, number FROM numbers(100000);
diff --git a/tests/queries/0_stateless/02404_memory_bound_merging.reference b/tests/queries/0_stateless/02404_memory_bound_merging.reference
index d9fac433189a..41a3b6bf8ecf 100644
--- a/tests/queries/0_stateless/02404_memory_bound_merging.reference
+++ b/tests/queries/0_stateless/02404_memory_bound_merging.reference
@@ -118,8 +118,7 @@ ExpressionTransform
MergingAggregatedBucketTransform × 4
Resize 1 → 4
GroupingAggregatedTransform 3 → 1
- (Union)
- (ReadFromRemoteParallelReplicas)
+ (ReadFromRemoteParallelReplicas)
select a, count() from pr_t group by a order by a limit 5 offset 500;
500 1000
501 1000
diff --git a/tests/queries/0_stateless/02417_load_marks_async.sh b/tests/queries/0_stateless/02417_load_marks_async.sh
index a5cbcd08f757..72b35a565df5 100755
--- a/tests/queries/0_stateless/02417_load_marks_async.sh
+++ b/tests/queries/0_stateless/02417_load_marks_async.sh
@@ -21,7 +21,7 @@ n8 UInt64,
n9 UInt64
)
ENGINE = MergeTree
-ORDER BY n0 SETTINGS min_bytes_for_wide_part = 1;"
+ORDER BY n0 SETTINGS min_bytes_for_wide_part = 1, index_granularity = 8192, index_granularity_bytes = '10Mi';"
${CLICKHOUSE_CLIENT} -q "INSERT INTO test select number, number % 3, number % 5, number % 10, number % 13, number % 15, number % 17, number % 18, number % 22, number % 25 from numbers(1000000)"
${CLICKHOUSE_CLIENT} -q "SYSTEM STOP MERGES test"
diff --git a/tests/queries/0_stateless/02428_index_analysis_with_null_literal.sql b/tests/queries/0_stateless/02428_index_analysis_with_null_literal.sql
index 33b0ea4b8185..091fbbe17110 100644
--- a/tests/queries/0_stateless/02428_index_analysis_with_null_literal.sql
+++ b/tests/queries/0_stateless/02428_index_analysis_with_null_literal.sql
@@ -1,7 +1,7 @@
-- From https://github.com/ClickHouse/ClickHouse/issues/41814
drop table if exists test;
-create table test(a UInt64, m UInt64, d DateTime) engine MergeTree partition by toYYYYMM(d) order by (a, m, d);
+create table test(a UInt64, m UInt64, d DateTime) engine MergeTree partition by toYYYYMM(d) order by (a, m, d) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into test select number, number, '2022-01-01 00:00:00' from numbers(1000000);
@@ -12,7 +12,7 @@ drop table test;
-- From https://github.com/ClickHouse/ClickHouse/issues/34063
drop table if exists test_null_filter;
-create table test_null_filter(key UInt64, value UInt32) engine MergeTree order by key;
+create table test_null_filter(key UInt64, value UInt32) engine MergeTree order by key SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into test_null_filter select number, number from numbers(10000000);
diff --git a/tests/queries/0_stateless/02443_detach_attach_partition.reference b/tests/queries/0_stateless/02443_detach_attach_partition.reference
new file mode 100644
index 000000000000..77cfb77479d7
--- /dev/null
+++ b/tests/queries/0_stateless/02443_detach_attach_partition.reference
@@ -0,0 +1,4 @@
+default begin inserts
+default end inserts
+30 465
+30 465
diff --git a/tests/queries/0_stateless/02443_detach_attach_partition.sh b/tests/queries/0_stateless/02443_detach_attach_partition.sh
new file mode 100755
index 000000000000..ae104b833e35
--- /dev/null
+++ b/tests/queries/0_stateless/02443_detach_attach_partition.sh
@@ -0,0 +1,86 @@
+#!/usr/bin/env bash
+# Tags: race, zookeeper, long
+
+CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
+# shellcheck source=../shell_config.sh
+. "$CURDIR"/../shell_config.sh
+# shellcheck source=./replication.lib
+. "$CURDIR"/replication.lib
+
+
+$CLICKHOUSE_CLIENT -n -q "
+ DROP TABLE IF EXISTS alter_table0;
+ DROP TABLE IF EXISTS alter_table1;
+
+ CREATE TABLE alter_table0 (a UInt8, b Int16) ENGINE = ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/alter_table', 'r1') ORDER BY a;
+ CREATE TABLE alter_table1 (a UInt8, b Int16) ENGINE = ReplicatedMergeTree('/clickhouse/tables/$CLICKHOUSE_TEST_ZOOKEEPER_PREFIX/alter_table', 'r2') ORDER BY a;
+" || exit 1
+
+function thread_detach()
+{
+ while true; do
+ $CLICKHOUSE_CLIENT -mn -q "ALTER TABLE alter_table$(($RANDOM % 2)) DETACH PARTITION ID 'all'; SELECT sleep($RANDOM / 32000) format Null;" 2>/dev/null ||:
+ done
+}
+function thread_attach()
+{
+ while true; do
+ $CLICKHOUSE_CLIENT -mn -q "ALTER TABLE alter_table$(($RANDOM % 2)) ATTACH PARTITION ID 'all'; SELECT sleep($RANDOM / 32000) format Null;" 2>/dev/null ||:
+ done
+}
+
+insert_type=$(($RANDOM % 3))
+$CLICKHOUSE_CLIENT -q "SELECT '$CLICKHOUSE_DATABASE', 'insert_type $insert_type' FORMAT Null"
+
+function insert()
+{
+ # Fault injection may lead to duplicates
+ if [[ "$insert_type" -eq 0 ]]; then
+ $CLICKHOUSE_CLIENT --insert_deduplication_token=$1 -q "INSERT INTO alter_table$(($RANDOM % 2)) SELECT $RANDOM, $1" 2>/dev/null
+ elif [[ "$insert_type" -eq 1 ]]; then
+ $CLICKHOUSE_CLIENT -q "INSERT INTO alter_table$(($RANDOM % 2)) SELECT $1, $1" 2>/dev/null
+ else
+ $CLICKHOUSE_CLIENT --insert_keeper_fault_injection_probability=0 -q "INSERT INTO alter_table$(($RANDOM % 2)) SELECT $RANDOM, $1" 2>/dev/null
+ fi
+}
+
+thread_detach & PID_1=$!
+thread_attach & PID_2=$!
+thread_detach & PID_3=$!
+thread_attach & PID_4=$!
+
+function do_inserts()
+{
+ for i in {1..30}; do
+ while ! insert $i; do $CLICKHOUSE_CLIENT -q "SELECT '$CLICKHOUSE_DATABASE', 'retrying insert $i' FORMAT Null"; done
+ done
+}
+
+$CLICKHOUSE_CLIENT -q "SELECT '$CLICKHOUSE_DATABASE', 'begin inserts'"
+do_inserts 2>&1| grep -Fa "Exception: " | grep -Fv "was cancelled by concurrent ALTER PARTITION"
+$CLICKHOUSE_CLIENT -q "SELECT '$CLICKHOUSE_DATABASE', 'end inserts'"
+
+kill -TERM $PID_1 && kill -TERM $PID_2 && kill -TERM $PID_3 && kill -TERM $PID_4
+wait
+
+$CLICKHOUSE_CLIENT -q "SYSTEM SYNC REPLICA alter_table0"
+$CLICKHOUSE_CLIENT -q "SYSTEM SYNC REPLICA alter_table1"
+query_with_retry "ALTER TABLE alter_table0 ATTACH PARTITION ID 'all'" 2>/dev/null;
+$CLICKHOUSE_CLIENT -q "ALTER TABLE alter_table1 ATTACH PARTITION ID 'all'" 2>/dev/null
+$CLICKHOUSE_CLIENT -q "SYSTEM SYNC REPLICA alter_table1"
+$CLICKHOUSE_CLIENT -q "ALTER TABLE alter_table1 ATTACH PARTITION ID 'all'"
+$CLICKHOUSE_CLIENT -q "SYSTEM SYNC REPLICA alter_table0"
+$CLICKHOUSE_CLIENT -q "SYSTEM SYNC REPLICA alter_table1"
+
+engine=$($CLICKHOUSE_CLIENT -q "SELECT engine FROM system.tables WHERE database=currentDatabase() AND table='alter_table0'")
+if [[ "$engine" == "ReplicatedMergeTree" ]]; then
+ # ReplicatedMergeTree may duplicate data on ATTACH PARTITION (when one replica has a merged part and another replica has source parts only)
+ $CLICKHOUSE_CLIENT -q "OPTIMIZE TABLE alter_table0 FINAL DEDUPLICATE"
+ $CLICKHOUSE_CLIENT -q "SYSTEM SYNC REPLICA alter_table1"
+fi
+
+$CLICKHOUSE_CLIENT -q "SELECT count(), sum(b) FROM alter_table0"
+$CLICKHOUSE_CLIENT -q "SELECT count(), sum(b) FROM alter_table1"
+
+$CLICKHOUSE_CLIENT -q "DROP TABLE alter_table0"
+$CLICKHOUSE_CLIENT -q "DROP TABLE alter_table1"
diff --git a/tests/queries/0_stateless/02457_morton_coding.sql b/tests/queries/0_stateless/02457_morton_coding.sql
index 4fc26f255f42..955cb2e053bd 100644
--- a/tests/queries/0_stateless/02457_morton_coding.sql
+++ b/tests/queries/0_stateless/02457_morton_coding.sql
@@ -11,7 +11,7 @@ create table morton_numbers_02457(
n8 UInt8
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
SELECT '----- CONST -----';
select mortonEncode(1,2,3,4);
@@ -45,7 +45,7 @@ create table morton_numbers_1_02457(
n8 UInt64
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into morton_numbers_1_02457
select untuple(mortonDecode(8, mortonEncode(n1, n2, n3, n4, n5, n6, n7, n8)))
@@ -80,7 +80,7 @@ create table morton_numbers_2_02457(
n4 UInt64
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into morton_numbers_2_02457
select untuple(mortonDecode(4, mortonEncode(n1, n2, n3, n4)))
@@ -114,7 +114,7 @@ create table morton_numbers_3_02457(
n2 UInt64
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into morton_numbers_3_02457
select untuple(mortonDecode(2, mortonEncode(n1, n2)))
diff --git a/tests/queries/0_stateless/02457_morton_coding_with_mask.sql b/tests/queries/0_stateless/02457_morton_coding_with_mask.sql
index 5aeb1f380bea..c95205769d2a 100644
--- a/tests/queries/0_stateless/02457_morton_coding_with_mask.sql
+++ b/tests/queries/0_stateless/02457_morton_coding_with_mask.sql
@@ -20,7 +20,7 @@ create table morton_numbers_mask_02457(
n4 UInt8
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into morton_numbers_mask_02457
select n1.number, n2.number, n3.number, n4.number
@@ -37,7 +37,7 @@ create table morton_numbers_mask_1_02457(
n4 UInt64
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into morton_numbers_mask_1_02457
select untuple(mortonDecode((1,2,1,2), mortonEncode((1,2,1,2), n1, n2, n3, n4)))
@@ -64,7 +64,7 @@ create table morton_numbers_mask_02457(
n2 UInt8
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into morton_numbers_mask_02457
select n1.number, n2.number
@@ -77,7 +77,7 @@ create table morton_numbers_mask_2_02457(
n2 UInt64
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into morton_numbers_mask_2_02457
select untuple(mortonDecode((1,4), mortonEncode((1,4), n1, n2)))
@@ -105,7 +105,7 @@ create table morton_numbers_mask_02457(
n3 UInt8,
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into morton_numbers_mask_02457
select n1.number, n2.number, n3.number
@@ -120,7 +120,7 @@ create table morton_numbers_mask_3_02457(
n3 UInt64
)
Engine=MergeTree()
- ORDER BY n1;
+ ORDER BY n1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into morton_numbers_mask_3_02457
select untuple(mortonDecode((1,1,2), mortonEncode((1,1,2), n1, n2, n3)))
diff --git a/tests/queries/0_stateless/02481_merge_array_join_sample_by.sql b/tests/queries/0_stateless/02481_merge_array_join_sample_by.sql
index 39fc751f3313..1c2123a99d5b 100644
--- a/tests/queries/0_stateless/02481_merge_array_join_sample_by.sql
+++ b/tests/queries/0_stateless/02481_merge_array_join_sample_by.sql
@@ -1,7 +1,7 @@
DROP TABLE IF EXISTS 02481_mergetree;
DROP TABLE IF EXISTS 02481_merge;
-CREATE TABLE 02481_mergetree(x UInt64, y UInt64, arr Array(String)) ENGINE = MergeTree ORDER BY x SAMPLE BY x;
+CREATE TABLE 02481_mergetree(x UInt64, y UInt64, arr Array(String)) ENGINE = MergeTree ORDER BY x SAMPLE BY x SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
CREATE TABLE 02481_merge(x UInt64, y UInt64, arr Array(String)) ENGINE = Merge(currentDatabase(), '^(02481_mergetree)$');
diff --git a/tests/queries/0_stateless/02481_pk_analysis_with_enum_to_string.sql b/tests/queries/0_stateless/02481_pk_analysis_with_enum_to_string.sql
index 91402bbed603..021a55ef2e80 100644
--- a/tests/queries/0_stateless/02481_pk_analysis_with_enum_to_string.sql
+++ b/tests/queries/0_stateless/02481_pk_analysis_with_enum_to_string.sql
@@ -10,7 +10,7 @@ CREATE TABLE gen
)
ENGINE = GenerateRandom;
-CREATE TABLE github_events AS gen ENGINE=MergeTree ORDER BY (event_type, repo_name, created_at);
+CREATE TABLE github_events AS gen ENGINE=MergeTree ORDER BY (event_type, repo_name, created_at) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO github_events SELECT * FROM gen LIMIT 100000;
diff --git a/tests/queries/0_stateless/02482_load_parts_refcounts.sh b/tests/queries/0_stateless/02482_load_parts_refcounts.sh
index 4d588dabeb9e..fe3cee1359ef 100755
--- a/tests/queries/0_stateless/02482_load_parts_refcounts.sh
+++ b/tests/queries/0_stateless/02482_load_parts_refcounts.sh
@@ -5,23 +5,6 @@ CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
# shellcheck source=../shell_config.sh
. "$CURDIR"/../shell_config.sh
-function query_with_retry
-{
- retry=0
- until [ $retry -ge 5 ]
- do
- result=$($CLICKHOUSE_CLIENT $2 --query="$1" 2>&1)
- if [ "$?" == 0 ]; then
- echo -n "$result"
- return
- else
- retry=$(($retry + 1))
- sleep 3
- fi
- done
- echo "Query '$1' failed with '$result'"
-}
-
$CLICKHOUSE_CLIENT -n --query "
DROP TABLE IF EXISTS load_parts_refcounts SYNC;
diff --git a/tests/queries/0_stateless/02521_aggregation_by_partitions.sql b/tests/queries/0_stateless/02521_aggregation_by_partitions.sql
index b7d4a6ee93a6..73d58bb6d6cf 100644
--- a/tests/queries/0_stateless/02521_aggregation_by_partitions.sql
+++ b/tests/queries/0_stateless/02521_aggregation_by_partitions.sql
@@ -18,7 +18,7 @@ select count() from (select throwIf(count() != 2) from t1 group by a);
drop table t1;
-create table t2(a UInt32) engine=MergeTree order by tuple() partition by a % 8;
+create table t2(a UInt32) engine=MergeTree order by tuple() partition by a % 8 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
system stop merges t2;
@@ -31,7 +31,7 @@ select count() from (select throwIf(count() != 2) from t2 group by a);
drop table t2;
-create table t3(a UInt32) engine=MergeTree order by tuple() partition by a % 16;
+create table t3(a UInt32) engine=MergeTree order by tuple() partition by a % 16 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
system stop merges t3;
@@ -53,7 +53,7 @@ drop table t3;
set optimize_aggregation_in_order = 1;
-create table t4(a UInt32) engine=MergeTree order by a partition by a % 4;
+create table t4(a UInt32) engine=MergeTree order by a partition by a % 4 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
system stop merges t4;
@@ -66,7 +66,7 @@ select count() from (select throwIf(count() != 2) from t4 group by a);
drop table t4;
-create table t5(a UInt32) engine=MergeTree order by a partition by a % 8;
+create table t5(a UInt32) engine=MergeTree order by a partition by a % 8 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
system stop merges t5;
@@ -79,7 +79,7 @@ select count() from (select throwIf(count() != 2) from t5 group by a);
drop table t5;
-create table t6(a UInt32) engine=MergeTree order by a partition by a % 16;
+create table t6(a UInt32) engine=MergeTree order by a partition by a % 16 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
system stop merges t6;
@@ -94,7 +94,7 @@ drop table t6;
set optimize_aggregation_in_order = 0;
-create table t7(a UInt32) engine=MergeTree order by a partition by intDiv(a, 2);
+create table t7(a UInt32) engine=MergeTree order by a partition by intDiv(a, 2) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t7 select number from numbers_mt(100);
@@ -104,7 +104,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t7;
-create table t8(a UInt32) engine=MergeTree order by a partition by intDiv(a, 2) * 2 + 1;
+create table t8(a UInt32) engine=MergeTree order by a partition by intDiv(a, 2) * 2 + 1 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t8 select number from numbers_mt(100);
@@ -114,7 +114,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t8;
-create table t9(a UInt32) engine=MergeTree order by a partition by intDiv(a, 2);
+create table t9(a UInt32) engine=MergeTree order by a partition by intDiv(a, 2) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t9 select number from numbers_mt(100);
@@ -124,7 +124,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t9;
-create table t10(a UInt32, b UInt32) engine=MergeTree order by a partition by (intDiv(a, 2), intDiv(b, 3));
+create table t10(a UInt32, b UInt32) engine=MergeTree order by a partition by (intDiv(a, 2), intDiv(b, 3)) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t10 select number, number from numbers_mt(100);
@@ -135,7 +135,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t10;
-- multiplication by 2 is not injective, so optimization is not applicable
-create table t11(a UInt32, b UInt32) engine=MergeTree order by a partition by (intDiv(a, 2), intDiv(b, 3));
+create table t11(a UInt32, b UInt32) engine=MergeTree order by a partition by (intDiv(a, 2), intDiv(b, 3)) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t11 select number, number from numbers_mt(100);
@@ -155,7 +155,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t12;
-create table t13(a UInt32, b UInt32) engine=MergeTree order by a partition by (intDiv(a, 2), intDiv(b, 3));
+create table t13(a UInt32, b UInt32) engine=MergeTree order by a partition by (intDiv(a, 2), intDiv(b, 3)) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t13 select number, number from numbers_mt(100);
@@ -165,7 +165,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t13;
-create table t14(a UInt32, b UInt32) engine=MergeTree order by a partition by intDiv(a, 2) + intDiv(b, 3);
+create table t14(a UInt32, b UInt32) engine=MergeTree order by a partition by intDiv(a, 2) + intDiv(b, 3) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t14 select number, number from numbers_mt(100);
@@ -176,7 +176,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t14;
-- to few partitions --
-create table t15(a UInt32, b UInt32) engine=MergeTree order by a partition by a < 90;
+create table t15(a UInt32, b UInt32) engine=MergeTree order by a partition by a < 90 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t15 select number, number from numbers_mt(100);
@@ -188,7 +188,7 @@ settings force_aggregate_partitions_independently = 0;
drop table t15;
-- to many partitions --
-create table t16(a UInt32, b UInt32) engine=MergeTree order by a partition by a % 16;
+create table t16(a UInt32, b UInt32) engine=MergeTree order by a partition by a % 16 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t16 select number, number from numbers_mt(100);
@@ -200,7 +200,7 @@ settings force_aggregate_partitions_independently = 0, max_number_of_partitions_
drop table t16;
-- to big skew --
-create table t17(a UInt32, b UInt32) engine=MergeTree order by a partition by a < 90;
+create table t17(a UInt32, b UInt32) engine=MergeTree order by a partition by a < 90 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t17 select number, number from numbers_mt(100);
@@ -211,7 +211,7 @@ settings force_aggregate_partitions_independently = 0, max_threads = 4;
drop table t17;
-create table t18(a UInt32, b UInt32) engine=MergeTree order by a partition by a;
+create table t18(a UInt32, b UInt32) engine=MergeTree order by a partition by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t18 select number, number from numbers_mt(50);
@@ -221,7 +221,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t18;
-create table t19(a UInt32, b UInt32) engine=MergeTree order by a partition by a;
+create table t19(a UInt32, b UInt32) engine=MergeTree order by a partition by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t19 select number, number from numbers_mt(50);
@@ -231,7 +231,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t19;
-create table t20(a UInt32, b UInt32) engine=MergeTree order by a partition by a;
+create table t20(a UInt32, b UInt32) engine=MergeTree order by a partition by a SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t20 select number, number from numbers_mt(50);
@@ -241,7 +241,7 @@ select replaceRegexpOne(explain, '^[ ]*(.*)', '\\1') from (
drop table t20;
-create table t21(a UInt64, b UInt64) engine=MergeTree order by a partition by a % 16;
+create table t21(a UInt64, b UInt64) engine=MergeTree order by a partition by a % 16 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t21 select number, number from numbers_mt(1e6);
@@ -249,7 +249,7 @@ select a from t21 group by a limit 10 format Null;
drop table t21;
-create table t22(a UInt32, b UInt32) engine=SummingMergeTree order by a partition by a % 16;
+create table t22(a UInt32, b UInt32) engine=SummingMergeTree order by a partition by a % 16 SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t22 select number, number from numbers_mt(1e6);
diff --git a/tests/queries/0_stateless/02521_lightweight_delete_and_ttl.sql b/tests/queries/0_stateless/02521_lightweight_delete_and_ttl.sql
index 1600761bb844..6bb8b5444e5c 100644
--- a/tests/queries/0_stateless/02521_lightweight_delete_and_ttl.sql
+++ b/tests/queries/0_stateless/02521_lightweight_delete_and_ttl.sql
@@ -3,7 +3,7 @@ DROP TABLE IF EXISTS lwd_test_02521;
CREATE TABLE lwd_test_02521 (id UInt64, value String, event_time DateTime)
ENGINE MergeTree()
ORDER BY id
-SETTINGS min_bytes_for_wide_part = 0;
+SETTINGS min_bytes_for_wide_part = 0, index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO lwd_test_02521 SELECT number, randomString(10), now() - INTERVAL 2 MONTH FROM numbers(50000);
INSERT INTO lwd_test_02521 SELECT number, randomString(10), now() FROM numbers(50000);
@@ -42,4 +42,4 @@ SELECT 'Count', count() FROM lwd_test_02521;
-- { echoOff }
-DROP TABLE lwd_test_02521;
\ No newline at end of file
+DROP TABLE lwd_test_02521;
diff --git a/tests/queries/0_stateless/02536_delta_gorilla_corruption.sql b/tests/queries/0_stateless/02536_delta_gorilla_corruption.sql
index 197a8ad72216..a4e0965e3295 100644
--- a/tests/queries/0_stateless/02536_delta_gorilla_corruption.sql
+++ b/tests/queries/0_stateless/02536_delta_gorilla_corruption.sql
@@ -11,7 +11,7 @@ drop table if exists bug_delta_gorilla;
create table bug_delta_gorilla
(value_bug UInt64 codec (Delta, Gorilla))
engine = MergeTree
-order by tuple()
+order by tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi'
as (select 0 from numbers(30000000));
select count(*)
@@ -32,7 +32,7 @@ select 'The same issue in a much smaller repro happens also in Debug builds';
create table bug_delta_gorilla (val UInt64 codec (Delta, Gorilla))
engine = MergeTree
-order by val;
+order by val SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into bug_delta_gorilla values (0)(1)(3);
select * from bug_delta_gorilla;
diff --git a/tests/queries/0_stateless/02561_sorting_constants_and_distinct_crash.sql b/tests/queries/0_stateless/02561_sorting_constants_and_distinct_crash.sql
index 9b117773b9b4..93a47c6736a5 100644
--- a/tests/queries/0_stateless/02561_sorting_constants_and_distinct_crash.sql
+++ b/tests/queries/0_stateless/02561_sorting_constants_and_distinct_crash.sql
@@ -1,5 +1,5 @@
drop table if exists test_table;
-CREATE TABLE test_table (string_value String) ENGINE = MergeTree ORDER BY string_value;
+CREATE TABLE test_table (string_value String) ENGINE = MergeTree ORDER BY string_value SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
system stop merges test_table;
insert into test_table select * from (
select 'test_value_1'
diff --git a/tests/queries/0_stateless/02565_update_empty_nested.sql b/tests/queries/0_stateless/02565_update_empty_nested.sql
index ca1c1f5f36e2..333168476019 100644
--- a/tests/queries/0_stateless/02565_update_empty_nested.sql
+++ b/tests/queries/0_stateless/02565_update_empty_nested.sql
@@ -7,7 +7,7 @@ CREATE TABLE t_update_empty_nested
)
ENGINE = MergeTree
ORDER BY id
-SETTINGS min_bytes_for_wide_part = 0;
+SETTINGS min_bytes_for_wide_part = 0, index_granularity = 8192, index_granularity_bytes = '10Mi';
SET mutations_sync = 2;
diff --git a/tests/queries/0_stateless/02581_share_big_sets_between_mutation_tasks.sql b/tests/queries/0_stateless/02581_share_big_sets_between_mutation_tasks.sql
index 7b52a89b16fc..eff9e0fa8255 100644
--- a/tests/queries/0_stateless/02581_share_big_sets_between_mutation_tasks.sql
+++ b/tests/queries/0_stateless/02581_share_big_sets_between_mutation_tasks.sql
@@ -1,6 +1,6 @@
DROP TABLE IF EXISTS 02581_trips;
-CREATE TABLE 02581_trips(id UInt32, id2 UInt32, description String) ENGINE=MergeTree ORDER BY id;
+CREATE TABLE 02581_trips(id UInt32, id2 UInt32, description String) ENGINE=MergeTree ORDER BY id SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
-- Make multiple parts
INSERT INTO 02581_trips SELECT number, number, '' FROM numbers(10000);
diff --git a/tests/queries/0_stateless/02796_projection_date_filter_on_view.sql b/tests/queries/0_stateless/02796_projection_date_filter_on_view.sql
index 9d9d7a3abd54..cb26a6bce4fa 100644
--- a/tests/queries/0_stateless/02796_projection_date_filter_on_view.sql
+++ b/tests/queries/0_stateless/02796_projection_date_filter_on_view.sql
@@ -13,7 +13,7 @@ CREATE TABLE fx_1m (
)
ENGINE = MergeTree()
PARTITION BY toYear(dt_close)
-ORDER BY (symbol, dt_close);
+ORDER BY (symbol, dt_close) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
-- add projection
ALTER TABLE fx_1m
diff --git a/tests/queries/0_stateless/02832_alter_delete_indexes_projections.sql b/tests/queries/0_stateless/02832_alter_delete_indexes_projections.sql
index b87230e57d1d..399d0fba564a 100644
--- a/tests/queries/0_stateless/02832_alter_delete_indexes_projections.sql
+++ b/tests/queries/0_stateless/02832_alter_delete_indexes_projections.sql
@@ -2,7 +2,7 @@ set mutations_sync = 2;
drop table if exists t_delete_skip_index;
-create table t_delete_skip_index (x UInt32, y String, index i y type minmax granularity 3) engine = MergeTree order by tuple();
+create table t_delete_skip_index (x UInt32, y String, index i y type minmax granularity 3) engine = MergeTree order by tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t_delete_skip_index select number, toString(number) from numbers(8192 * 10);
select count() from t_delete_skip_index where y in (4, 5);
@@ -12,7 +12,7 @@ select count() from t_delete_skip_index where y in (4, 5);
drop table if exists t_delete_skip_index;
drop table if exists t_delete_projection;
-create table t_delete_projection (x UInt32, y UInt64, projection p (select sum(y))) engine = MergeTree order by tuple();
+create table t_delete_projection (x UInt32, y UInt64, projection p (select sum(y))) engine = MergeTree order by tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into t_delete_projection select number, toString(number) from numbers(8192 * 10);
select sum(y) from t_delete_projection settings optimize_use_projections = 0;
diff --git a/tests/queries/0_stateless/02833_concurrrent_sessions.reference b/tests/queries/0_stateless/02833_concurrrent_sessions.reference
new file mode 100644
index 000000000000..bfe507e8eac0
--- /dev/null
+++ b/tests/queries/0_stateless/02833_concurrrent_sessions.reference
@@ -0,0 +1,34 @@
+sessions:
+150
+port_0_sessions:
+0
+address_0_sessions:
+0
+tcp_sessions
+60
+http_sessions
+30
+http_with_session_id_sessions
+30
+my_sql_sessions
+30
+Corresponding LoginSuccess/Logout
+10
+LoginFailure
+10
+Corresponding LoginSuccess/Logout
+10
+LoginFailure
+10
+Corresponding LoginSuccess/Logout
+10
+LoginFailure
+10
+Corresponding LoginSuccess/Logout
+10
+LoginFailure
+10
+Corresponding LoginSuccess/Logout
+10
+LoginFailure
+10
diff --git a/tests/queries/0_stateless/02833_concurrrent_sessions.sh b/tests/queries/0_stateless/02833_concurrrent_sessions.sh
new file mode 100755
index 000000000000..26b48462a760
--- /dev/null
+++ b/tests/queries/0_stateless/02833_concurrrent_sessions.sh
@@ -0,0 +1,138 @@
+#!/usr/bin/env bash
+# Tags: no-fasttest, no-debug
+
+CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
+# shellcheck source=../shell_config.sh
+. "$CURDIR"/../shell_config.sh
+
+readonly PID=$$
+
+# Each user uses a separate thread.
+readonly TCP_USERS=( "02833_TCP_USER_${PID}"_{1,2} ) # 2 concurrent TCP users
+readonly HTTP_USERS=( "02833_HTTP_USER_${PID}" )
+readonly HTTP_WITH_SESSION_ID_SESSION_USERS=( "02833_HTTP_WITH_SESSION_ID_USER_${PID}" )
+readonly MYSQL_USERS=( "02833_MYSQL_USER_${PID}")
+readonly ALL_USERS=( "${TCP_USERS[@]}" "${HTTP_USERS[@]}" "${HTTP_WITH_SESSION_ID_SESSION_USERS[@]}" "${MYSQL_USERS[@]}" )
+
+readonly TCP_USERS_SQL_COLLECTION_STRING="$( echo "${TCP_USERS[*]}" | sed "s/[^[:space:]]\+/'&'/g" | sed 's/[[:space:]]/,/g' )"
+readonly HTTP_USERS_SQL_COLLECTION_STRING="$( echo "${HTTP_USERS[*]}" | sed "s/[^[:space:]]\+/'&'/g" | sed 's/[[:space:]]/,/g' )"
+readonly HTTP_WITH_SESSION_ID_USERS_SQL_COLLECTION_STRING="$( echo "${HTTP_WITH_SESSION_ID_SESSION_USERS[*]}" | sed "s/[^[:space:]]\+/'&'/g" | sed 's/[[:space:]]/,/g' )"
+readonly MYSQL_USERS_SQL_COLLECTION_STRING="$( echo "${MYSQL_USERS[*]}" | sed "s/[^[:space:]]\+/'&'/g" | sed 's/[[:space:]]/,/g' )"
+readonly ALL_USERS_SQL_COLLECTION_STRING="$( echo "${ALL_USERS[*]}" | sed "s/[^[:space:]]\+/'&'/g" | sed 's/[[:space:]]/,/g' )"
+
+readonly SESSION_LOG_MATCHING_FIELDS="auth_id, auth_type, client_version_major, client_version_minor, client_version_patch, interface"
+
+for user in "${ALL_USERS[@]}"; do
+ ${CLICKHOUSE_CLIENT} -q "CREATE USER IF NOT EXISTS ${user} IDENTIFIED WITH plaintext_password BY 'pass'"
+ ${CLICKHOUSE_CLIENT} -q "GRANT SELECT ON system.* TO ${user}"
+ ${CLICKHOUSE_CLIENT} -q "GRANT SELECT ON INFORMATION_SCHEMA.* TO ${user}";
+done
+
+# All _session functions execute in separate threads.
+# These functions try to create a session with successful login and logout.
+# Sleep a small, random amount of time to make concurrency more intense.
+# and try to login with an invalid password.
+function tcp_session()
+{
+ local user=$1
+ local i=0
+ while (( (i++) < 10 )); do
+ # login logout
+ ${CLICKHOUSE_CLIENT} -q "SELECT 1, sleep(0.01${RANDOM})" --user="${user}" --password="pass"
+ # login failure
+ ${CLICKHOUSE_CLIENT} -q "SELECT 2" --user="${user}" --password 'invalid'
+ done
+}
+
+function http_session()
+{
+ local user=$1
+ local i=0
+ while (( (i++) < 10 )); do
+ # login logout
+ ${CLICKHOUSE_CURL} -sS "${CLICKHOUSE_URL}&user=${user}&password=pass" -d "SELECT 3, sleep(0.01${RANDOM})"
+
+ # login failure
+ ${CLICKHOUSE_CURL} -sS "${CLICKHOUSE_URL}&user=${user}&password=wrong" -d "SELECT 4"
+ done
+}
+
+function http_with_session_id_session()
+{
+ local user=$1
+ local i=0
+ while (( (i++) < 10 )); do
+ # login logout
+ ${CLICKHOUSE_CURL} -sS "${CLICKHOUSE_URL}&session_id=${user}&user=${user}&password=pass" -d "SELECT 5, sleep 0.01${RANDOM}"
+
+ # login failure
+ ${CLICKHOUSE_CURL} -sS "${CLICKHOUSE_URL}&session_id=${user}&user=${user}&password=wrong" -d "SELECT 6"
+ done
+}
+
+function mysql_session()
+{
+ local user=$1
+ local i=0
+ while (( (i++) < 10 )); do
+ # login logout
+ ${CLICKHOUSE_CLIENT} -q "SELECT 1, sleep(0.01${RANDOM}) FROM mysql('127.0.0.1:9004', 'system', 'one', '${user}', 'pass')"
+
+ # login failure
+ ${CLICKHOUSE_CLIENT} -q "SELECT 1 FROM mysql('127.0.0.1:9004', 'system', 'one', '${user}', 'wrong', SETTINGS connection_max_tries=1)"
+ done
+}
+
+${CLICKHOUSE_CLIENT} -q "SYSTEM FLUSH LOGS"
+${CLICKHOUSE_CLIENT} -q "DELETE FROM system.session_log WHERE user IN (${ALL_USERS_SQL_COLLECTION_STRING})"
+
+export -f tcp_session;
+export -f http_session;
+export -f http_with_session_id_session;
+export -f mysql_session;
+
+for user in "${TCP_USERS[@]}"; do
+ timeout 60s bash -c "tcp_session ${user}" >/dev/null 2>&1 &
+done
+
+for user in "${HTTP_USERS[@]}"; do
+ timeout 60s bash -c "http_session ${user}" >/dev/null 2>&1 &
+done
+
+for user in "${HTTP_WITH_SESSION_ID_SESSION_USERS[@]}"; do
+ timeout 60s bash -c "http_with_session_id_session ${user}" >/dev/null 2>&1 &
+done
+
+for user in "${MYSQL_USERS[@]}"; do
+ timeout 60s bash -c "mysql_session ${user}" >/dev/null 2>&1 &
+done
+
+wait
+
+${CLICKHOUSE_CLIENT} -q "SYSTEM FLUSH LOGS"
+
+echo "sessions:"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user IN (${ALL_USERS_SQL_COLLECTION_STRING})"
+
+echo "port_0_sessions:"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user IN (${ALL_USERS_SQL_COLLECTION_STRING}) AND client_port = 0"
+
+echo "address_0_sessions:"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user IN (${ALL_USERS_SQL_COLLECTION_STRING}) AND client_address = toIPv6('::')"
+
+echo "tcp_sessions"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user IN (${TCP_USERS_SQL_COLLECTION_STRING}) AND interface = 'TCP'"
+echo "http_sessions"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user IN (${HTTP_USERS_SQL_COLLECTION_STRING}) AND interface = 'HTTP'"
+echo "http_with_session_id_sessions"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user IN (${HTTP_WITH_SESSION_ID_USERS_SQL_COLLECTION_STRING}) AND interface = 'HTTP'"
+echo "my_sql_sessions"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user IN (${MYSQL_USERS_SQL_COLLECTION_STRING}) AND interface = 'MySQL'"
+
+for user in "${ALL_USERS[@]}"; do
+ ${CLICKHOUSE_CLIENT} -q "DROP USER ${user}"
+ echo "Corresponding LoginSuccess/Logout"
+ ${CLICKHOUSE_CLIENT} -q "SELECT COUNT(*) FROM (SELECT ${SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = '${user}' AND type = 'LoginSuccess' INTERSECT SELECT ${SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = '${user}' AND type = 'Logout')"
+ echo "LoginFailure"
+ ${CLICKHOUSE_CLIENT} -q "SELECT COUNT(*) FROM system.session_log WHERE user = '${user}' AND type = 'LoginFailure'"
+ done
diff --git a/tests/queries/0_stateless/02834_remote_session_log.reference b/tests/queries/0_stateless/02834_remote_session_log.reference
new file mode 100644
index 000000000000..e2680982ab0b
--- /dev/null
+++ b/tests/queries/0_stateless/02834_remote_session_log.reference
@@ -0,0 +1,13 @@
+0
+0
+0
+0
+client_port 0 connections:
+0
+client_address '::' connections:
+0
+login failures:
+0
+TCP Login and logout count is equal
+HTTP Login and logout count is equal
+MySQL Login and logout count is equal
diff --git a/tests/queries/0_stateless/02834_remote_session_log.sh b/tests/queries/0_stateless/02834_remote_session_log.sh
new file mode 100755
index 000000000000..3bedfb6c9eeb
--- /dev/null
+++ b/tests/queries/0_stateless/02834_remote_session_log.sh
@@ -0,0 +1,56 @@
+#!/usr/bin/env bash
+# Tags: no-fasttest
+
+CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
+# shellcheck source=../shell_config.sh
+. "$CURDIR"/../shell_config.sh
+
+readonly PID=$$
+readonly TEST_USER=$"02834_USER_${PID}"
+readonly SESSION_LOG_MATCHING_FIELDS="auth_id, auth_type, client_version_major, client_version_minor, client_version_patch, interface"
+
+${CLICKHOUSE_CLIENT} -q "CREATE USER IF NOT EXISTS ${TEST_USER} IDENTIFIED WITH plaintext_password BY 'pass'"
+${CLICKHOUSE_CLIENT} -q "GRANT SELECT ON INFORMATION_SCHEMA.* TO ${TEST_USER}"
+${CLICKHOUSE_CLIENT} -q "GRANT SELECT ON system.* TO ${TEST_USER}"
+${CLICKHOUSE_CLIENT} -q "GRANT CREATE TEMPORARY TABLE, MYSQL, REMOTE ON *.* TO ${TEST_USER}"
+
+${CLICKHOUSE_CLIENT} -q "SYSTEM FLUSH LOGS"
+${CLICKHOUSE_CLIENT} -q "DELETE FROM system.session_log WHERE user = '${TEST_USER}'"
+
+${CLICKHOUSE_CURL} -sS -X POST "${CLICKHOUSE_URL}&user=${TEST_USER}&password=pass" \
+ -d "SELECT * FROM remote('127.0.0.1:${CLICKHOUSE_PORT_TCP}', 'system', 'one', '${TEST_USER}', 'pass')"
+
+${CLICKHOUSE_CURL} -sS -X POST "${CLICKHOUSE_URL}&user=${TEST_USER}&password=pass" \
+ -d "SELECT * FROM mysql('127.0.0.1:9004', 'system', 'one', '${TEST_USER}', 'pass')"
+
+${CLICKHOUSE_CLIENT} -q "SELECT * FROM remote('127.0.0.1:${CLICKHOUSE_PORT_TCP}', 'system', 'one', '${TEST_USER}', 'pass')" -u "${TEST_USER}" --password "pass"
+${CLICKHOUSE_CLIENT} -q "SELECT * FROM mysql('127.0.0.1:9004', 'system', 'one', '${TEST_USER}', 'pass')" -u "${TEST_USER}" --password "pass"
+
+${CLICKHOUSE_CLIENT} -q "SYSTEM FLUSH LOGS"
+
+echo "client_port 0 connections:"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user = '${TEST_USER}' and client_port = 0"
+
+echo "client_address '::' connections:"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user = '${TEST_USER}' and client_address = toIPv6('::')"
+
+echo "login failures:"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user = '${TEST_USER}' and type = 'LoginFailure'"
+
+# remote(...) function sometimes reuses old cached sessions for query execution.
+# This makes LoginSuccess/Logout entries count unstable, but success and logouts must always match.
+
+for interface in 'TCP' 'HTTP' 'MySQL'
+do
+ LOGIN_COUNT=`${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user = '${TEST_USER}' AND type = 'LoginSuccess' AND interface = '${interface}'"`
+ CORRESPONDING_LOGOUT_RECORDS_COUNT=`${CLICKHOUSE_CLIENT} -q "SELECT COUNT(*) FROM (SELECT ${SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = '${TEST_USER}' AND type = 'LoginSuccess' AND interface = '${interface}' INTERSECT SELECT ${SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = '${TEST_USER}' AND type = 'Logout' AND interface = '${interface}')"`
+
+ if [ "$LOGIN_COUNT" == "$CORRESPONDING_LOGOUT_RECORDS_COUNT" ]; then
+ echo "${interface} Login and logout count is equal"
+ else
+ TOTAL_LOGOUT_COUNT=`${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user = '${TEST_USER}' AND type = 'Logout' AND interface = '${interface}'"`
+ echo "${interface} Login count ${LOGIN_COUNT} != corresponding logout count ${CORRESPONDING_LOGOUT_RECORDS_COUNT}. TOTAL_LOGOUT_COUNT ${TOTAL_LOGOUT_COUNT}"
+ fi
+done
+
+${CLICKHOUSE_CLIENT} -q "DROP USER ${TEST_USER}"
diff --git a/tests/queries/0_stateless/02835_drop_user_during_session.reference b/tests/queries/0_stateless/02835_drop_user_during_session.reference
new file mode 100644
index 000000000000..7252faab8c6c
--- /dev/null
+++ b/tests/queries/0_stateless/02835_drop_user_during_session.reference
@@ -0,0 +1,8 @@
+port_0_sessions:
+0
+address_0_sessions:
+0
+Corresponding LoginSuccess/Logout
+9
+LoginFailure
+0
diff --git a/tests/queries/0_stateless/02835_drop_user_during_session.sh b/tests/queries/0_stateless/02835_drop_user_during_session.sh
new file mode 100755
index 000000000000..347ebd22f96c
--- /dev/null
+++ b/tests/queries/0_stateless/02835_drop_user_during_session.sh
@@ -0,0 +1,114 @@
+#!/usr/bin/env bash
+# Tags: no-debug
+
+CURDIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
+# shellcheck source=../shell_config.sh
+. "$CURDIR"/../shell_config.sh
+
+readonly PID=$$
+
+readonly TEST_USER="02835_USER_${PID}"
+readonly TEST_ROLE="02835_ROLE_${PID}"
+readonly TEST_PROFILE="02835_PROFILE_${PID}"
+readonly SESSION_LOG_MATCHING_FIELDS="auth_id, auth_type, client_version_major, client_version_minor, client_version_patch, interface"
+
+function tcp_session()
+{
+ local user=$1
+ ${CLICKHOUSE_CLIENT} -q "SELECT COUNT(*) FROM system.numbers" --user="${user}"
+}
+
+function http_session()
+{
+ local user=$1
+ ${CLICKHOUSE_CURL} -sS "${CLICKHOUSE_URL}&user=${user}&password=pass" -d "SELECT COUNT(*) FROM system.numbers"
+}
+
+function http_with_session_id_session()
+{
+ local user=$1
+ ${CLICKHOUSE_CURL} -sS "${CLICKHOUSE_URL}&user=${user}&password=pass" -d "SELECT COUNT(*) FROM system.numbers"
+}
+
+# Busy-waits until user $1, specified amount of queries ($2) will run simultaneously.
+function wait_for_queries_start()
+{
+ local user=$1
+ local queries_count=$2
+ # 10 seconds waiting
+ counter=0 retries=100
+ while [[ $counter -lt $retries ]]; do
+ result=$($CLICKHOUSE_CLIENT --query "SELECT COUNT(*) FROM system.processes WHERE user = '${user}'")
+ if [[ $result == "${queries_count}" ]]; then
+ break;
+ fi
+ sleep 0.1
+ ((++counter))
+ done
+}
+
+${CLICKHOUSE_CLIENT} -q "SYSTEM FLUSH LOGS"
+${CLICKHOUSE_CLIENT} -q "DELETE FROM system.session_log WHERE user = '${TEST_USER}'"
+
+# DROP USE CASE
+${CLICKHOUSE_CLIENT} -q "CREATE USER IF NOT EXISTS ${TEST_USER}"
+${CLICKHOUSE_CLIENT} -q "GRANT SELECT ON system.numbers TO ${TEST_USER}"
+
+export -f tcp_session;
+export -f http_session;
+export -f http_with_session_id_session;
+
+timeout 10s bash -c "tcp_session ${TEST_USER}" >/dev/null 2>&1 &
+timeout 10s bash -c "http_session ${TEST_USER}" >/dev/null 2>&1 &
+timeout 10s bash -c "http_with_session_id_session ${TEST_USER}" >/dev/null 2>&1 &
+
+wait_for_queries_start $TEST_USER 3
+${CLICKHOUSE_CLIENT} -q "DROP USER ${TEST_USER}"
+${CLICKHOUSE_CLIENT} -q "KILL QUERY WHERE user = '${TEST_USER}' SYNC" >/dev/null &
+
+wait
+
+# DROP ROLE CASE
+${CLICKHOUSE_CLIENT} -q "CREATE ROLE IF NOT EXISTS ${TEST_ROLE}"
+${CLICKHOUSE_CLIENT} -q "CREATE USER ${TEST_USER} DEFAULT ROLE ${TEST_ROLE}"
+${CLICKHOUSE_CLIENT} -q "GRANT SELECT ON system.numbers TO ${TEST_USER}"
+
+timeout 10s bash -c "tcp_session ${TEST_USER}" >/dev/null 2>&1 &
+timeout 10s bash -c "http_session ${TEST_USER}" >/dev/null 2>&1 &
+timeout 10s bash -c "http_with_session_id_session ${TEST_USER}" >/dev/null 2>&1 &
+
+wait_for_queries_start $TEST_USER 3
+${CLICKHOUSE_CLIENT} -q "DROP ROLE ${TEST_ROLE}"
+${CLICKHOUSE_CLIENT} -q "DROP USER ${TEST_USER}"
+
+${CLICKHOUSE_CLIENT} -q "KILL QUERY WHERE user = '${TEST_USER}' SYNC" >/dev/null &
+
+wait
+
+# DROP PROFILE CASE
+${CLICKHOUSE_CLIENT} -q "CREATE SETTINGS PROFILE IF NOT EXISTS '${TEST_PROFILE}'"
+${CLICKHOUSE_CLIENT} -q "CREATE USER ${TEST_USER} SETTINGS PROFILE '${TEST_PROFILE}'"
+${CLICKHOUSE_CLIENT} -q "GRANT SELECT ON system.numbers TO ${TEST_USER}"
+
+timeout 10s bash -c "tcp_session ${TEST_USER}" >/dev/null 2>&1 &
+timeout 10s bash -c "http_session ${TEST_USER}" >/dev/null 2>&1 &
+timeout 10s bash -c "http_with_session_id_session ${TEST_USER}" >/dev/null 2>&1 &
+
+wait_for_queries_start $TEST_USER 3
+${CLICKHOUSE_CLIENT} -q "DROP SETTINGS PROFILE '${TEST_PROFILE}'"
+${CLICKHOUSE_CLIENT} -q "DROP USER ${TEST_USER}"
+
+${CLICKHOUSE_CLIENT} -q "KILL QUERY WHERE user = '${TEST_USER}' SYNC" >/dev/null &
+
+wait
+
+${CLICKHOUSE_CLIENT} -q "SYSTEM FLUSH LOGS"
+
+echo "port_0_sessions:"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user = '${TEST_USER}' AND client_port = 0"
+echo "address_0_sessions:"
+${CLICKHOUSE_CLIENT} -q "SELECT count(*) FROM system.session_log WHERE user = '${TEST_USER}' AND client_address = toIPv6('::')"
+echo "Corresponding LoginSuccess/Logout"
+${CLICKHOUSE_CLIENT} -q "SELECT COUNT(*) FROM (SELECT ${SESSION_LOG_MATCHING_FIELDS} FROM system.session_log WHERE user = '${TEST_USER}' AND type = 'LoginSuccess' INTERSECT SELECT ${SESSION_LOG_MATCHING_FIELDS}, FROM system.session_log WHERE user = '${TEST_USER}' AND type = 'Logout')"
+echo "LoginFailure"
+${CLICKHOUSE_CLIENT} -q "SELECT COUNT(*) FROM system.session_log WHERE user = '${TEST_USER}' AND type = 'LoginFailure'"
diff --git a/tests/queries/0_stateless/02842_one_input_format.reference b/tests/queries/0_stateless/02842_one_input_format.reference
new file mode 100644
index 000000000000..714df685535a
--- /dev/null
+++ b/tests/queries/0_stateless/02842_one_input_format.reference
@@ -0,0 +1,12 @@
+dummy UInt8
+0
+0
+0
+data.csv
+data.jsonl
+data.native
+0
+0
+0
+1
+1
diff --git a/tests/queries/0_stateless/02842_one_input_format.sh b/tests/queries/0_stateless/02842_one_input_format.sh
new file mode 100755
index 000000000000..f2199cbe2ce7
--- /dev/null
+++ b/tests/queries/0_stateless/02842_one_input_format.sh
@@ -0,0 +1,22 @@
+#!/usr/bin/env bash
+
+CUR_DIR=$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)
+# shellcheck source=../shell_config.sh
+. "$CUR_DIR"/../shell_config.sh
+
+FILE_DIR=$CLICKHOUSE_TEST_UNIQUE_NAME
+mkdir -p $FILE_DIR
+
+$CLICKHOUSE_LOCAL -q "select * from numbers(100000) format Native" > $FILE_DIR/data.native
+$CLICKHOUSE_LOCAL -q "select * from numbers(100000) format CSV" > $FILE_DIR/data.csv
+$CLICKHOUSE_LOCAL -q "select * from numbers(100000) format JSONEachRow" > $FILE_DIR/data.jsonl
+
+$CLICKHOUSE_LOCAL -q "desc file('$FILE_DIR/*', One)"
+$CLICKHOUSE_LOCAL -q "select * from file('$FILE_DIR/*', One)"
+$CLICKHOUSE_LOCAL -q "select _file from file('$FILE_DIR/*', One) order by _file"
+$CLICKHOUSE_LOCAL -q "select * from file('$FILE_DIR/*', One, 'x UInt8')"
+$CLICKHOUSE_LOCAL -q "select * from file('$FILE_DIR/*', One, 'x UInt64')" 2>&1 | grep "BAD_ARGUMENTS" -c
+$CLICKHOUSE_LOCAL -q "select * from file('$FILE_DIR/*', One, 'x UInt8, y UInt8')" 2>&1 | grep "BAD_ARGUMENTS" -c
+
+rm -rf $FILE_DIR
+
diff --git a/tests/queries/0_stateless/02843_context_has_expired.reference b/tests/queries/0_stateless/02843_context_has_expired.reference
index 573541ac9702..229972f29247 100644
--- a/tests/queries/0_stateless/02843_context_has_expired.reference
+++ b/tests/queries/0_stateless/02843_context_has_expired.reference
@@ -1 +1,5 @@
0
+0
+0
+0
+0
diff --git a/tests/queries/0_stateless/02843_context_has_expired.sql b/tests/queries/0_stateless/02843_context_has_expired.sql
index ccef3458ed70..8355ce2c18c2 100644
--- a/tests/queries/0_stateless/02843_context_has_expired.sql
+++ b/tests/queries/0_stateless/02843_context_has_expired.sql
@@ -1,23 +1,36 @@
-DROP DICTIONARY IF EXISTS dict;
-DROP TABLE IF EXISTS source;
+DROP DICTIONARY IF EXISTS 02843_dict;
+DROP TABLE IF EXISTS 02843_source;
+DROP TABLE IF EXISTS 02843_join;
-CREATE TABLE source
+CREATE TABLE 02843_source
(
id UInt64,
value String
)
ENGINE=Memory;
-CREATE DICTIONARY dict
+CREATE DICTIONARY 02843_dict
(
id UInt64,
value String
)
PRIMARY KEY id
-SOURCE(CLICKHOUSE(TABLE 'source'))
+SOURCE(CLICKHOUSE(TABLE '02843_source'))
LAYOUT(DIRECT());
-SELECT 1 IN (SELECT dictGet('dict', 'value', materialize('1')));
+SELECT 1 IN (SELECT dictGet('02843_dict', 'value', materialize('1')));
-DROP DICTIONARY dict;
-DROP TABLE source;
+CREATE TABLE 02843_join (id UInt8, value String) ENGINE Join(ANY, LEFT, id);
+SELECT 1 IN (SELECT joinGet(02843_join, 'value', materialize(1)));
+SELECT 1 IN (SELECT joinGetOrNull(02843_join, 'value', materialize(1)));
+
+SELECT 1 IN (SELECT materialize(connectionId()));
+SELECT 1000000 IN (SELECT materialize(getSetting('max_threads')));
+SELECT 1 in (SELECT file(materialize('a'))); -- { serverError 107 }
+
+EXPLAIN ESTIMATE SELECT 1 IN (SELECT dictGet('02843_dict', 'value', materialize('1')));
+EXPLAIN ESTIMATE SELECT 1 IN (SELECT joinGet(`02843_join`, 'value', materialize(1)));
+
+DROP DICTIONARY 02843_dict;
+DROP TABLE 02843_source;
+DROP TABLE 02843_join;
diff --git a/tests/queries/0_stateless/02844_distributed_virtual_columns.reference b/tests/queries/0_stateless/02844_distributed_virtual_columns.reference
new file mode 100644
index 000000000000..e69de29bb2d1
diff --git a/tests/queries/0_stateless/02844_distributed_virtual_columns.sql b/tests/queries/0_stateless/02844_distributed_virtual_columns.sql
new file mode 100644
index 000000000000..31a6780f19ed
--- /dev/null
+++ b/tests/queries/0_stateless/02844_distributed_virtual_columns.sql
@@ -0,0 +1,5 @@
+drop table if exists data_01072;
+drop table if exists dist_01072;
+create table data_01072 (key Int) Engine=MergeTree() ORDER BY key;
+create table dist_01072 (key Int) Engine=Distributed(test_cluster_two_shards, currentDatabase(), data_01072, key);
+select * from dist_01072 where key=0 and _part='0';
diff --git a/tests/queries/1_stateful/00072_compare_date_and_string_index.sql b/tests/queries/1_stateful/00072_compare_date_and_string_index.sql
index d652b1bc5599..424e6c2dfeee 100644
--- a/tests/queries/1_stateful/00072_compare_date_and_string_index.sql
+++ b/tests/queries/1_stateful/00072_compare_date_and_string_index.sql
@@ -15,8 +15,8 @@ SELECT count() FROM test.hits WHERE EventDate IN (toDate('2014-03-18'), toDate('
SELECT count() FROM test.hits WHERE EventDate = concat('2014-0', '3-18');
DROP TABLE IF EXISTS test.hits_indexed_by_time;
-CREATE TABLE test.hits_indexed_by_time (EventDate Date, EventTime DateTime('Asia/Dubai')) ENGINE = MergeTree ORDER BY (EventDate, EventTime);
-INSERT INTO test.hits_indexed_by_time SELECT EventDate, EventTime FROM test.hits;
+CREATE TABLE test.hits_indexed_by_time (EventDate Date, EventTime DateTime('Asia/Dubai')) ENGINE = MergeTree ORDER BY (EventDate, EventTime) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
+INSERT INTO test.hits_indexed_by_time SELECT EventDate, EventTime FROM test.hits SETTINGS max_block_size = 65000;
SELECT count() FROM test.hits_indexed_by_time WHERE EventTime = '2014-03-18 01:02:03';
SELECT count() FROM test.hits_indexed_by_time WHERE EventTime < '2014-03-18 01:02:03';
diff --git a/tests/queries/1_stateful/00162_mmap_compression_none.sql b/tests/queries/1_stateful/00162_mmap_compression_none.sql
index 2178644214ac..d2cbcea8aaa5 100644
--- a/tests/queries/1_stateful/00162_mmap_compression_none.sql
+++ b/tests/queries/1_stateful/00162_mmap_compression_none.sql
@@ -1,5 +1,5 @@
DROP TABLE IF EXISTS hits_none;
-CREATE TABLE hits_none (Title String CODEC(NONE)) ENGINE = MergeTree ORDER BY tuple();
+CREATE TABLE hits_none (Title String CODEC(NONE)) ENGINE = MergeTree ORDER BY tuple() SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
INSERT INTO hits_none SELECT Title FROM test.hits;
SET min_bytes_to_use_mmap_io = 1;
diff --git a/tests/queries/1_stateful/00174_distinct_in_order.sql b/tests/queries/1_stateful/00174_distinct_in_order.sql
index aac54d461814..301ff36dd42c 100644
--- a/tests/queries/1_stateful/00174_distinct_in_order.sql
+++ b/tests/queries/1_stateful/00174_distinct_in_order.sql
@@ -4,9 +4,9 @@ drop table if exists distinct_in_order sync;
drop table if exists ordinary_distinct sync;
select '-- DISTINCT columns are the same as in ORDER BY';
-create table distinct_in_order (CounterID UInt32, EventDate Date) engine=MergeTree() order by (CounterID, EventDate);
+create table distinct_in_order (CounterID UInt32, EventDate Date) engine=MergeTree() order by (CounterID, EventDate) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into distinct_in_order select distinct CounterID, EventDate from test.hits order by CounterID, EventDate settings optimize_distinct_in_order=1;
-create table ordinary_distinct (CounterID UInt32, EventDate Date) engine=MergeTree() order by (CounterID, EventDate);
+create table ordinary_distinct (CounterID UInt32, EventDate Date) engine=MergeTree() order by (CounterID, EventDate) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into ordinary_distinct select distinct CounterID, EventDate from test.hits order by CounterID, EventDate settings optimize_distinct_in_order=0;
select distinct * from distinct_in_order except select * from ordinary_distinct;
@@ -14,9 +14,9 @@ drop table if exists distinct_in_order sync;
drop table if exists ordinary_distinct sync;
select '-- DISTINCT columns has prefix in ORDER BY columns';
-create table distinct_in_order (CounterID UInt32, EventDate Date) engine=MergeTree() order by (CounterID, EventDate);
+create table distinct_in_order (CounterID UInt32, EventDate Date) engine=MergeTree() order by (CounterID, EventDate) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into distinct_in_order select distinct CounterID, EventDate from test.hits order by CounterID settings optimize_distinct_in_order=1;
-create table ordinary_distinct (CounterID UInt32, EventDate Date) engine=MergeTree() order by (CounterID, EventDate);
+create table ordinary_distinct (CounterID UInt32, EventDate Date) engine=MergeTree() order by (CounterID, EventDate) SETTINGS index_granularity = 8192, index_granularity_bytes = '10Mi';
insert into ordinary_distinct select distinct CounterID, EventDate from test.hits order by CounterID settings optimize_distinct_in_order=0;
select distinct * from distinct_in_order except select * from ordinary_distinct;
diff --git a/tests/queries/shell_config.sh b/tests/queries/shell_config.sh
index ef70c82aefc8..12bc0002191a 100644
--- a/tests/queries/shell_config.sh
+++ b/tests/queries/shell_config.sh
@@ -155,3 +155,23 @@ function random_str()
local n=$1 && shift
tr -cd '[:lower:]' < /dev/urandom | head -c"$n"
}
+
+function query_with_retry
+{
+ local query="$1" && shift
+
+ local retry=0
+ until [ $retry -ge 5 ]
+ do
+ local result
+ result="$($CLICKHOUSE_CLIENT "$@" --query="$query" 2>&1)"
+ if [ "$?" == 0 ]; then
+ echo -n "$result"
+ return
+ else
+ retry=$((retry + 1))
+ sleep 3
+ fi
+ done
+ echo "Query '$query' failed with '$result'"
+}
diff --git a/utils/check-style/aspell-ignore/en/aspell-dict.txt b/utils/check-style/aspell-ignore/en/aspell-dict.txt
index 812908931ef1..2e231120e418 100644
--- a/utils/check-style/aspell-ignore/en/aspell-dict.txt
+++ b/utils/check-style/aspell-ignore/en/aspell-dict.txt
@@ -1892,7 +1892,6 @@ overfitting
packetpool
packetsize
pageviews
-pandahouse
parallelization
parallelize
parallelized
@@ -2001,6 +2000,7 @@ ptrs
pushdown
pwrite
py
+PyArrow
qryn
quantile
quantileBFloat