 |
+
|---|
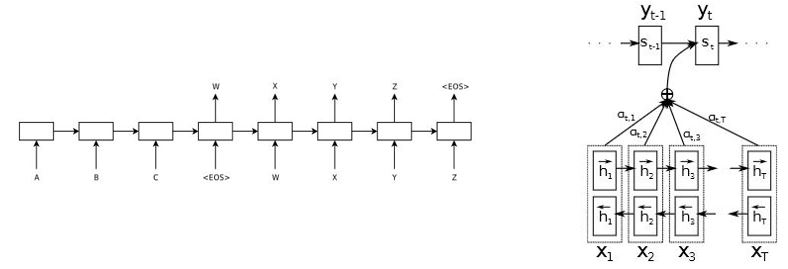
| Figure 1: RNN-based encoder-decoder architecture [1] [2] Left: without attention mechanism | Right: with attention mechism |
+
|
-|:--:|
-| Figure 1: RNN-based encoder-decoder architecture [[1]](https://arxiv.org/abs/1409.3215) [[2]](https://arxiv.org/abs/1409.0473) |
+
|---|
| Figure 1: RNN-based encoder-decoder architecture [1] [2] Left: without attention mechanism | Right: with attention mechism |
+
 |
-|:--:|
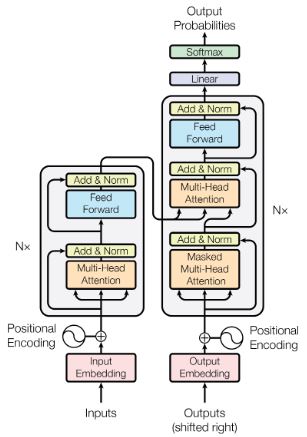
-| Figure 2: Transformer encoder-decoder architecture [[3]](https://arxiv.org/abs/1706.03762)|
+
|
-|:--:|
-| Figure 2: Transformer encoder-decoder architecture [[3]](https://arxiv.org/abs/1706.03762)|
+ |
+
|---|
| Figure 2: Transformer encoder-decoder architecture [3] | +
 |
-|:--:|
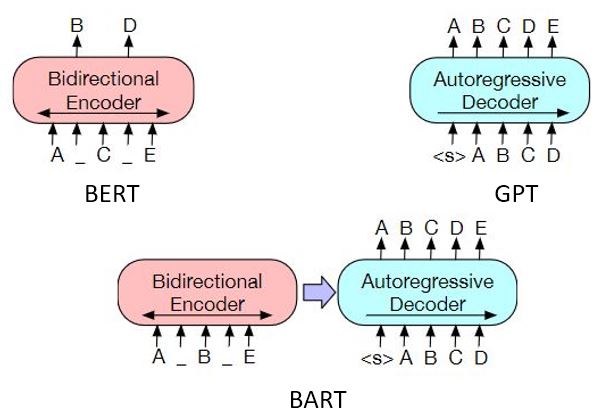
-| Figure 3: The 3 pretraining paradigms for Transformer models [[4]](https://arxiv.org/abs/1810.04805) [[5]](https://openai.com/blog/language-unsupervised/) [[6]](https://arxiv.org/abs/1910.13461)|
-
+
+
In 2020, the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) studied the effectiveness of initializing sequence-to-sequence models with pretrained encoder/decoder checkpoints for sequence generation tasks. It obtained new state-of-the-art results on machine translation, text summarization, etc.
Following this idea, 🤗 [transformers](https://huggingface.co/docs/transformers/index) implements [EncoderDecoderModel](https://huggingface.co/docs/transformers/model_doc/encoderdecoder) that allows users to easily combine almost any 🤗 pretrained encoder (Bert, Robert, etc.) with a 🤗 pretrained decoder (GPT models, decoder from Bart or T5, etc.) to perform fine-tuning on downstream tasks. Instantiate a [EncoderDecoderModel](https://huggingface.co/docs/transformers/model_doc/encoderdecoder) is super easy, and finetune it on a sequence-to-sequence task usually obtains descent results in just a few hours on Google Cloud TPU.
@@ -151,9 +181,19 @@ The obtained sequence of vectors plays the same role as token embeddings in [BER
-|
|
-|:--:|
-| Figure 3: The 3 pretraining paradigms for Transformer models [[4]](https://arxiv.org/abs/1810.04805) [[5]](https://openai.com/blog/language-unsupervised/) [[6]](https://arxiv.org/abs/1910.13461)|
-
+
+
In 2020, the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) studied the effectiveness of initializing sequence-to-sequence models with pretrained encoder/decoder checkpoints for sequence generation tasks. It obtained new state-of-the-art results on machine translation, text summarization, etc.
Following this idea, 🤗 [transformers](https://huggingface.co/docs/transformers/index) implements [EncoderDecoderModel](https://huggingface.co/docs/transformers/model_doc/encoderdecoder) that allows users to easily combine almost any 🤗 pretrained encoder (Bert, Robert, etc.) with a 🤗 pretrained decoder (GPT models, decoder from Bart or T5, etc.) to perform fine-tuning on downstream tasks. Instantiate a [EncoderDecoderModel](https://huggingface.co/docs/transformers/model_doc/encoderdecoder) is super easy, and finetune it on a sequence-to-sequence task usually obtains descent results in just a few hours on Google Cloud TPU.
@@ -151,9 +181,19 @@ The obtained sequence of vectors plays the same role as token embeddings in [BER
-|  |
-|:--:|
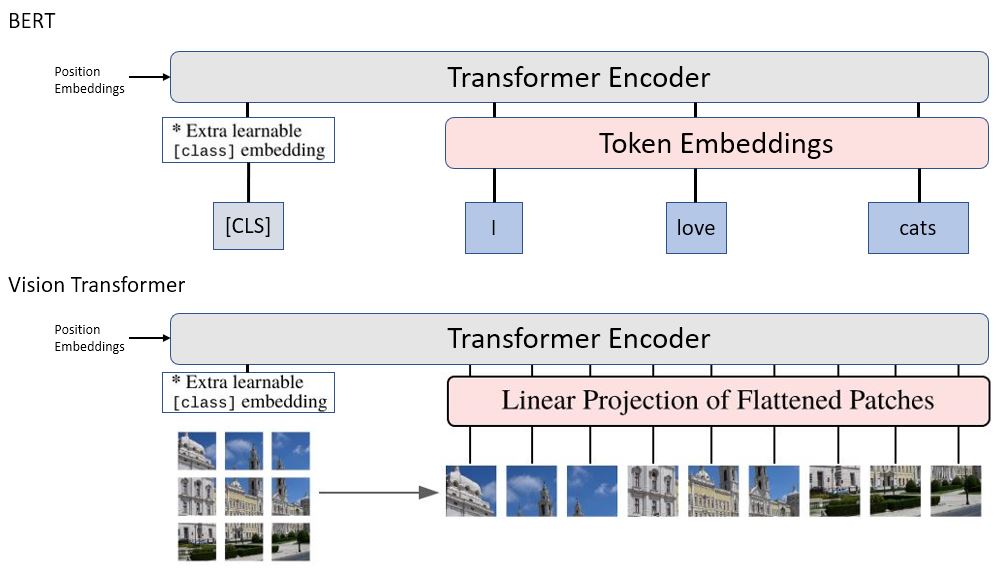
-| Figure 4: BERT v.s. ViT |
+
|
-|:--:|
-| Figure 4: BERT v.s. ViT |
+ |
+
|---|
| Figure 4: BERT v.s. ViT | +
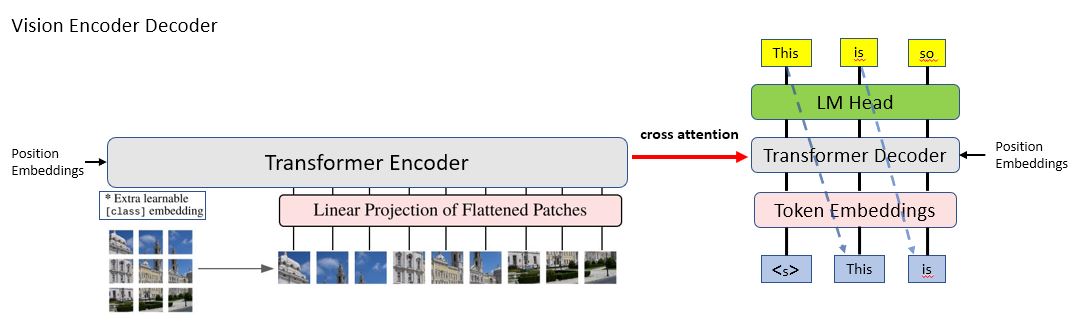 |
-|:--:|
-| Figure 5: Vision-Encoder-Decoder architecture |
+
|
-|:--:|
-| Figure 5: Vision-Encoder-Decoder architecture |
+ |
+
|---|
| Figure 5: Vision-Encoder-Decoder architecture | +