diff --git a/vision_encoder_decoder_blog.md b/vision_encoder_decoder_blog.md
index facfbbc..ba60a9c 100644
--- a/vision_encoder_decoder_blog.md
+++ b/vision_encoder_decoder_blog.md
@@ -45,11 +45,11 @@ The above models and their variations focus on pretraining either the encoder or
-
+
| 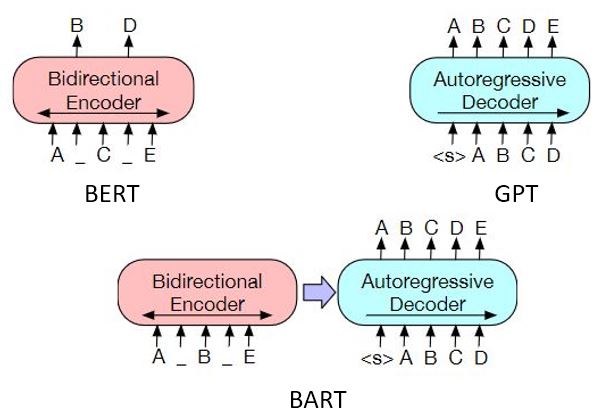 |
|:--:|
| Figure 3: The 3 pretraining paradigms for Transformer models [[4]](https://arxiv.org/abs/1810.04805) [[5]](https://openai.com/blog/language-unsupervised/) [[6]](https://arxiv.org/abs/1910.13461)|
-
|
|:--:|
| Figure 3: The 3 pretraining paradigms for Transformer models [[4]](https://arxiv.org/abs/1810.04805) [[5]](https://openai.com/blog/language-unsupervised/) [[6]](https://arxiv.org/abs/1910.13461)|
-