etcd 就不说了,奇数个副本,可以坏 (n-1)/2 个,有条件的可以单独 SSD 机器部署 etcd 。K8S 所有组件和客户端,都会使用 kubeconfig 或者集群内 rbac 的 serviceaccount 后通过 kubernetes 这个 service 最终连到实体的 kube-apiserver 进程:

etcd 集群下,一般都是 kube-apiserver/kube-controller-manager/kube-scheduler 部署多份,但是所有的都是连接 kube-apiserver,所以需要一个负载均衡负载到 kube-apiserver 副本上。
集群内部自带了第一个 Service CIDR 第一个 IP 的 kubernetes service:
$ kubectl -n default describe svc kubernetes
Name: kubernetes
Namespace: default
Labels: component=apiserver
provider=kubernetes
Annotations: <none>
Selector: <none>
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.96.0.1
IPs: 10.96.0.1
Port: https 443/TCP
TargetPort: 6443/TCP
Endpoints: 192.168.2.111:6443,192.168.2.112:6443,192.168.2.113:6443
Session Affinity: None
Events: <none>
集群内部访问 https://kubernetes.default 最终解析成 10.96.0.1,然后 DNAT 到 endpoint 里任意一个 kube-apiserver。可能有些聪明的人会问,这看起来是 kube-apiserver 上报的自己网卡 IP,如果是 nat 后的怎么处理,kube-apiserver 提供了 --advertise-address 选项,用于告诉访问自己使用哪个 IP。
kube-apiserver 本质上是个 web 七层服务,所以我们要整高可用不要把 k8s 想的太复杂了,保证了 apiserver 的高可用就行了。tcp 和 web 层面,是否软硬件,还是组合使用都行,例如:
- 硬件 F5 配置转发
- nginx、caddy、envoy、haproxy
- 云上 SLB 代理
- keepalived VRRP
- keepalived VRRP + haproxy
- 网络设备 ospf + lvs
- ...
如果是 7层负载均衡,健康检查可以用应用层面 url /healthz:
$ kubectl get --raw / | grep /healthz
"/healthz",
"/healthz/autoregister-completion",
"/healthz/etcd",
"/healthz/log",
"/healthz/ping",
"/healthz/post
...
可以 kube-apiserver 不配置 --anonymous-auth=false 后 /healthz 路由就返回 200 状态码了,或者把证书上传到 SLB 上之类的配置里,7层检查,例如下面是 haproxy 的 7 层检查 tcp 代理:
frontend k8s-api
bind 0.0.0.0:8443
bind 127.0.0.1:8443
mode tcp
option tcplog
tcp-request inspect-delay 5s
default_backend k8s-api
backend k8s-api
mode tcp
option tcplog
option httpchk GET /healthz
http-check expect string ok
balance roundrobin
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server api1 192.168.2.111:6443 check check-ssl verify none
server api2 192.168.2.112:6443 check check-ssl verify none
server api3 192.168.2.113:6443 check check-ssl verify none
kubeconfig 文件里包含有 kubernetes 的 URL 地址,想在使用 kubectl 的时候绕过负载均衡,可以使用 -s, --server= 来指定 kube-apiserver url ,另外可能你会遇到 kubectl 报错无法连接:
The connection to the server localhost:8080 was refused - did you specify the right host or port?
这是因为没有 ~/.kube/config 文件和 KUBECONFIG 变量文件不存在或者权限问题下,kubectl 默认认为连接 kube-apiserver 地址是 http://localhost:8080 的不需要授权的匿名地址,而现在 kube-apiserver 都会把 insecure-port 关闭了造成的报错。
在一些私有化环境内,客户会无法提供 SLB 和硬件负载均衡,环境也可能是 openstack 环境上的虚拟机而无法使用 VRRP VIP(会因为 IP 和 MAC 不匹配被 drop),所以可以使用 local proxy 方式代理,也就是每个节点上部署一个软件做负载均衡,例如每个节点部署一个 nginx,监听 0.0.0.0:8443 反向代理:
upstream kube_apiserver {
least_conn;
server 192.168.2.111:6443 max_fails=3 fail_timeout=10s;
server 192.168.2.112:6443 max_fails=3 fail_timeout=10s;
server 192.168.2.113:6443 max_fails=3 fail_timeout=10s;
}
server {
listen 0.0.0.0:8443;
proxy_pass kube_apiserver;
proxy_connect_timeout 1s;
}
例如下面是市面上的 sealos 就是使用 kubeadm 部署,staticPod 的目录加了个 yaml,使用的内核 lvs 能力做四层负载。每个 node 跑一个 lvs 的 watch 进程的 pod 去维护 lvs 的规则保持高可用:
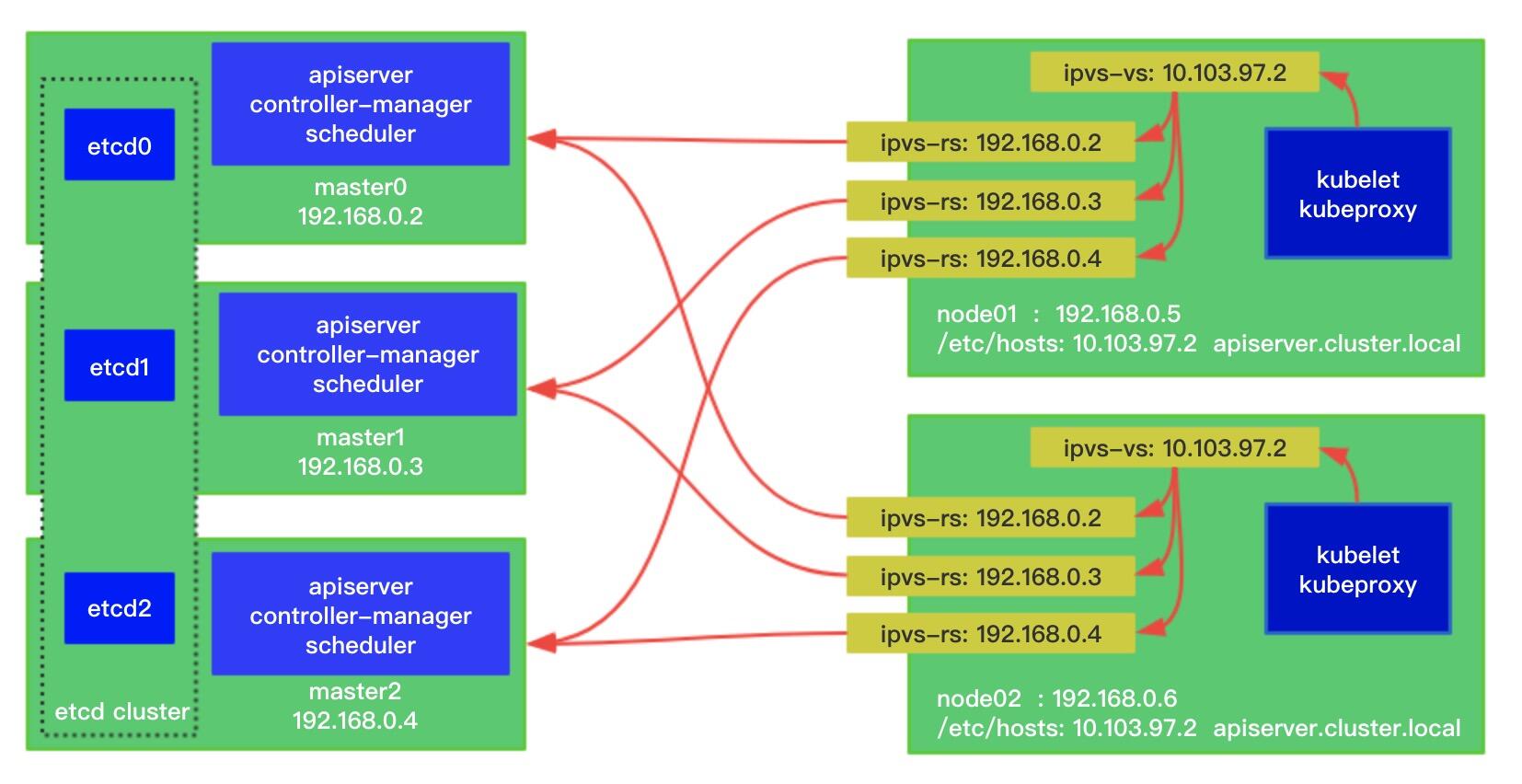
再次重申下,不要局限在自己会的软件和实现手段的顽固思想上,而是看场景和后续升级维护和规模多方面考虑,例如如果客户经常注重漏洞扫描 CVE,那选择 caddy 这种单二进制 web server 做代理更新方便。
例如云上,阿里云的 K8S 实例,kube-apiserver 会创建一个 SLB,所有 client 访问:
# SLB 反向代理的机器/服务,我们一般称之为 real server。
+-------+
| |
-+---------->+ rs |
/ +-------+
/
/
/ +-------+
+--------+ / | |
| client +-----------> SLB ---------->+ rs |
+--------+ \ +-------+
\
\
\ +-------+
------------->+ |
| rs |
+-------+
因为阿里云的托管版 K8S 实例不能登录,所以有些人在自己部署 K8S 后创建 SLB 做负载的时候会发现存在问题。master 上也有 kubelet,kubelet 的 kubeconfig 里的 IP 是 SLB 的时候,这样会是下面的流量图:
+-------+
| |
-+-----------+ rs |
/ +-------+
/
/
/ +-------+
/ | |
SLB <-------------+ rs |
\ +-------+
\
\
\ +-------+
--------------+ |
| rs |
+-------+
例如上面这种 rs 访问 SLB 你会发现有几率超时,这个在 NAT 行为里有个专门的术语,叫 hairpinning(直译为发卡,意思 是像发卡一样,沿着一边上去,然后从另一边绕回来),很多负载均衡会直接扔掉报文。
![]()
不单单是 master,例如 ingress controller 访问自己用的 SLB,而自己又是 SLB 的 rs 列表里,以及有些 Pod 的业务 --external-url 写 SLB 的 IP ,由于 CNI 对 Pod 访问非 Pod/Service CIDR 都会做 SNAT,访问到 SLB 来源 IP SNAT 成了 node 的节点 IP ,这个 node 又是 SLB 的 rs 也会出问题。
其实 Pod 不能访问自己的 Service 也是这个相关,但是 kubelet 提供了选项 hairpinMode: promiscuous-bridge 配置。
- DNS
- 下一部分: Ingress Controller