Configurations
SpiderSuite Configurations are stored in json format in a SpiderSuite.conf configuration file that is located in the installation folder of SpiderSuite.
You can easily modify the configuration values and save for the changes to take place. You can also easily reset the configurations to default values that come with SpiderSuite, any changes saved or reset will also reset the SpiderSuite.conf file.
General Apllication's configurations
- Font Configures the Spider Suite’s entire application font type, size and style, simply change the application’s font by using the font dialog.
The changes will take effect after restarting SpiderSuite.
- Theme Configures the Spider Suite’s theme for the entire application and for the text editors.
The themes will be applied when you restart the application.
- Disable automatic update check
Disables the automatic check for any available updates for the application which is done when the application is launched (started).
You can still check for updates manually by clicking on the check for updates action on the menu bar.
Configures the Crawler’s limitations.

- Parallel Connections:
Sets the number of parallel connections to connect to the target server with during crawling. According to SpiderSuite’s design, 6 connections is the most optimal configuration value as SpiderSuites employs other techniques to increase the efficiency of the spider such as; use of HTTP pipelining and HTTP2 multi-plexing.
- Timeout:
Sets the maximum waiting duration in milliseconds for a request to elicit a response from the target server.
If checked (set to true), when maximum timeout is reached and there is no response from target server the request will be aborted and closed.
If unchecked (set to false), the request will remain active until it gets a response from server or until the 30 seconds threshold is reached.
- Follow Redirects:
Sets the following of the redirect URL in case of a 3XX response status and the maximum number of redirects to follow.
If checked (set to true), when a request elicits a 3XX redirect response, the crawler will automatically redirect to the received redirection URL. You can also set the maximum number of redirects to follow.
If unchecked (set to false), when a 3XX response is received the crawler will not redirect the request, it will simply save the result and continue to crawl other links
- Delay between Consecutive Requests:
Sets the wait time between sending consecutive requests. The delay is configured in milliseconds.
If checked (set to true), when spider sends a request to the target server it will wait for XXX milliseconds before sending another request to that target server.
If unchecked (set to false), the spider will send multiple requests in a tight loop to the target server.
This should only be checked (set to true) in cases of targets that;
• Can’t handle too many requests
• Detects and prevents high speed crawling
• Has strict crawling rules
Otherwise it slows down the crawling process, as the spider has to delay for XXX milliseconds before sending another request.
- Maximum Pages to Crawl:
Sets the maximum number of successful result pages to be crawled. This only takes into account the successfully crawled pages from the target server.
If checked(set to true), when the spider successfully crawls the XXX number of pages from the target server the spider will automatically stop regardless whether there are still crawlable links available
If not checked (set to false), the spider will crawl the target site until either you stop the crawling manually or until the spider finishes crawling all the links.
- Maximum Crawl Depth:
Sets the maximum page depth to crawl for a particular target. Depth refers to the position of the page from the host domain.
e.g. https://www.example_domain.com/depth_1/ depth _2/ depth_3?name=value
If checked (set to true), the spider will not crawl a page whose depth exceeds the maximum crawl depth. Only pages whose depth are between 0 and max crawl depth will be crawled.
If not checked (set to false), the spider will crawl all pages of all depths of the particular target.
- Maximum Page Size to Crawl:
Sets the maximum page size in bytes for download.
If checked (set to true), pages whose size is above the maximum page download size will not be downloaded.
If not checked (set to false), pages of all sizes will be downloaded and crawled.
- Maximum URL Length:
Sets the maximum allowed length in bytes/characters for a URL link.
If checked (set to true), links whose length is above the maximum link length value will not be crawled.
If not checked (set to false), links of all lengths will be crawled.
Crawler specific configurations.

- Use HTTP2:
Configures the use of HTTP version 2 protocol for request to the target server. If a server turns out to not support HTTP/2 the spider will fall back to using HTTP version 1 by default.
HTTP/2 is the second version of the HTTP protocol aiming to make applications faster, simpler, and more robust by improving many of the drawbacks of the first HTTP version. Has features including;
• Binary protocols – Binary protocols consume less bandwidth, are more efficiently parsed and are less error-prone than the textual protocols used by HTTP/1.1.
• Multiplexing – HTTP/2 is multiplexed, i.e., it can initiate multiple requests in parallel over a single TCP connection. As a result, web pages containing several elements are delivered over one TCP connection.
• Header compression – HTTP/2 uses header compression to reduce the overhead caused by TCP’s slow-start mechanism.
• Server push – HTTP/2 servers push likely-to-be-used resources into a browser’s cache, even before they’re requested. This allows browsers to display content without additional request cycles.
• Increased security – Web browsers only support HTTP/2 via encrypted connections, increasing user and application security.
- HTTP Pipelining:
Configures the spider to use http-pipelining technique to increase speed and efficiency. Works when using HTTP/1.
HTTP pipelining is a feature of HTTP/1.1 which allows multiple HTTP requests to be sent over a single TCP connection without waiting for the corresponding responses.
HTTP/1.1 requires servers to respond to pipelined requests correctly, with non-pipelined but valid responses even if server does not support HTTP pipelining. Despite this requirement, many legacy HTTP/1.1 servers do not support pipelining correctly, forcing most HTTP clients to not use HTTP pipelining. The technique was superseded by multiplexing via HTTP/2.
- Accept Cookies:
Configures the spider to accept and use cookies sent by the target server. The spider will store the cookie and send it back to the same server with later requests.
An HTTP cookie (web cookie, browser cookie) is a small piece of data that a server sends to a user's web browser (in this case SpiderSuite). Cookies are mainly used for three purposes: Session management, Personalization & Tracking.
- Ignore query parameters in html links:
Configures the crawler to ignore all query parameters in all html links it crawls. e.g. https://example.com?param1=1¶m2=2 => https://example.com
- Ignore query parameters in Resource links:
Configures the crawler to ignore all query parameters in resource links only. Resource links here refers to links which are not of html filetype e.g. js, css, xml, json links.
- Crawl sitemap File:
Configures the crawler to first fetch sitemap.xml file is the site contains one. If the site does possess the sitemap.xml file then the spider will use the links from the sitemap.xml file as seed links for crawling the target site.
An XML sitemap is a file that lists a website's essential pages, making sure Google can find and crawl them all. It also helps search engines understand your website structure. You want Google to crawl every important page of your website.
- Follow “robots.txt” Exclusions:
Configures the crawler to follow the “/robots.txt” exclusions if available. The robots.txt exclusion is highly dependent on the user-agent used hence the crawler will follow the exclusions according to the user-agents you’ve chosen.
The robots exclusion standard, also known as the robots exclusion protocol or simply robots.txt, is a standard used by websites to communicate with web crawlers and other web robots.
- Crawl linked files only:
Configures the crawler to crawl only the links that it extracts from the crawled pages meaning it will not crawl other directories in the link structure.
E.g. For a linked link https://example.com/dir1/dir2/dir3, the crawler will only fetch for page https://example.com/dir1/dir2/dir3 and won’t try to crawl other directory pages found in this link such as https://example.com/dir1 and https://example.com/dir/dir2.
- Crawl Resource Links from external domains:
Configures the spider to crawl resources (images, css, js, json, xml & fonts) hosted from a different host. Most webpages uses resources hosted from different hosts. If this feature is selected external resources will are crawled if this feature not selected only resources from the target host will be crawled.
- Strip trailing slash on links:
Configures the filter to strip/remove all trailing slashes in url links it crawls
E.g. https://example.com/ ==> https://example.com
This helps preventing duplicate pages as most of the time the link with and without tralling slash are the same page.
Use with Caution: because the two pages might be different
- Extract links from script tag
Configures the crawler to extract links from javascript code inside the script tag.
If the pages contains many, long and repeatitive javascript scripts it slow might slow down the extraction process hence this configuration disables extraction of links from these scripts.
The disadvantage to this is that the scripts may contain useful links that could expand the target scope.
- Extract links from style tag
Configures the crawler to extract links from CSS code inside the style tag.
If the pages contains many, long and repeatitive CSS code it slow might slow down the extraction process hence this configuration disables extraction of links from these styles.
The disadvantage to this is that the styles may contain useful links that could expand the target scope.
- Extract links from comments
Configures the crawler to extract links from code comments.
If the pages contains many, long and repeatitive code comments it might slow slow down the extraction process hence this configuration disables extraction of links from these comments.
The disadvantage to this is that the comments may contain useful links that could expand the target scope.
- Add failed requests (4XX and 5XX) to sitemap
Configures the crawler not to discard 4XX and 5XX error responses and instead, add them to database and send them to sitemap.
Connection, SSL and other system errors will not be added to sitemap only error responses with 4XX and 5XX.
- Allow POST and PUT requests
Configures the crawler to allow sending POST and PUT requests when crawling. Since POST and PUT request may have an effect on the target it is not allowed by default.
- Filter out recurring parameters Configures the crawler to remove repeating parameters even those with different values. This configuration prevents crawling of the same pages with just different parameter values.
Although it might be helpful most of the time, sometimes the parameter values might be essential.
- File types to Crawl:
Configures which files types are allowed to be crawled. HTML files are crawled by default, but for other file types you must allow (by checking the particular checkbox) for them to be crawled. If not allowed the file type will not be added to the spider seed.
Crawler’s request headers configuration.

- Request Headers:
Choose(check the header’s check box of ) the headers you want to use for crawling the target site. You can add your own custom headers by introducing the header name and value then click add button to add the new header to the headers list.
When checked (in use) the Referer header value will be added automatically by the spider during the scan depending on where the link was extracted from.
- User Agent Header
The User-Agent request header is a characteristic string that lets servers and network peers identify the application, operating system, vendor, and/or version of the requesting user agent.
Check the (User Agent Header) checkbox to allow the use of user agents in crawling. Then choose the user agent(s) to use. If multiple user agents are chosen, they will all be used randomly for each request sent.
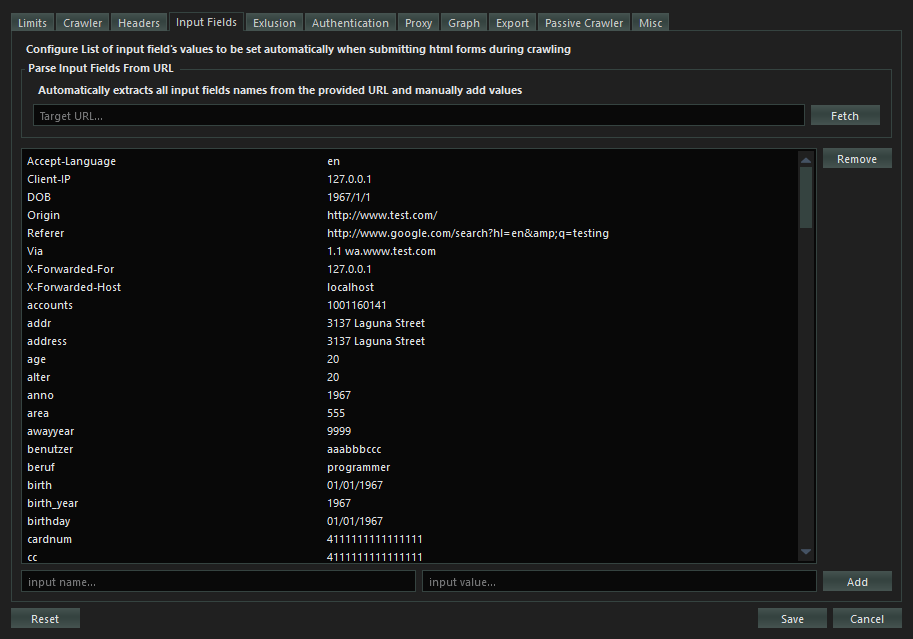
Configures the default values for the listed common input name and types for HTML forms. When crawling the HTML forms, values from all empty input values will be filled by the values from this list.
You can also add your own custom input name/type and value to be used in HTML form’s inputs.
You can also parse and extract input fields from a URL automatically by fetching it then adding values to the input fields manually This is more efficient and precise.

Configures what link’s query parameters, paths, extensions and cookies should be excluded from crawling.
- Exclude Parameters
Configures which query parameters should be excluded from a network request if present. If exclude all parameters is chosen then query parameters from all links will be removed.
- Exclude File Extensions
Configures the Crawler to exclude crawling all links with file types of the specified extensions (pdf, exe, docx). You can add a file type extension to be excluded
- Exclude Paths
Configures the Crawler to exclude crawling the paths which match to the exclusion patterns. You can add custom excluded paths patterns (regular expression patterns) for each scan.
- Exclude Cookies
Configures the spider to exclude the chosen cookie patterns from the cookie jar. You can add custom cookie patterns (regular expression patterns) to exclude from the scan.
Configures the credentials for authenticated crawl. For current version 1.0.0 of SpiderSuite, it only supports standard based authentications which include Basic, NTLM version 2, Digest-MD5 and SPNEGO/Negotiate.
Simply add the credential values; username, password, host site and the path that requires the authentication. After that you can check the credentials for it to be usable when the crawler detects authentication is required.
Form based authentication will be introduced in the coming versions of SpiderSuite.
Configures http and socks5 proxy connection for the crawler. In case of anonymity or integration with other tools such as Burp Suite & Zed Attack Proxy (ZAP) and bypassing various IP related crawling drawbacks.
All crawler request and responses will pass through the configured proxy.
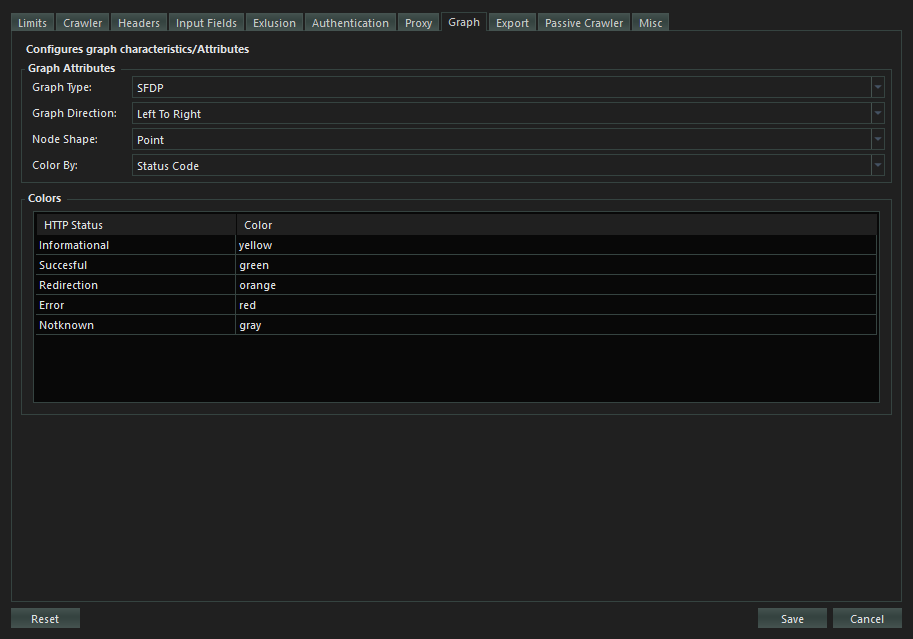
Configures Graph visualizing the Crawled sitemap. You can modify the graph appearance on your own liking for better data presentation.

Configures what data/information about a page should be exported on various export types.
The page URLs will all be exported by default but other data about the webpage such as Status Code, Size, title and Content Type will only be exported when you choose them to be exported.
This feature gives control to the user on what data to be included in the export file.

Configures the SpiderSuite passive crawler.
- Allowed Pages
Configures which pages (page type e.g. html, js, css ) are allowed to be added to the sitemap after the crawling is finished or when you add links.