
![]()
![]()
![]()
This repository aims to provide a set of excellent hash map implementations, as well as a btree alternative to std::map and std::set, with the following characteristics:
-
Header only: nothing to build, just copy the
parallel_hashmapdirectory to your project and you are good to go. -
drop-in replacement for
std::unordered_map,std::unordered_set,std::mapandstd::set -
Compiler with C++11 support required, C++14 and C++17 APIs are provided (such as
try_emplace) -
Very efficient, significantly faster than your compiler's unordered map/set or Boost's, or than sparsepp
-
Memory friendly: low memory usage, although a little higher than sparsepp
-
Supports heterogeneous lookup
-
Easy to forward declare: just include
phmap_fwd_decl.hin your header files to forward declare Parallel Hashmap containers [note: this does not work currently for hash maps with pointer keys] -
Dump/load feature: when a
flathash map stores data that isstd::trivially_copyable, the table can be dumped to disk and restored as a single array, very efficiently, and without requiring any hash computation. This is typically about 10 times faster than doing element-wise serialization to disk, but it will use 10% to 60% extra disk space. Seeexamples/serialize.cc. (flat hash map/set only) -
Tested on Windows (vs2015 & vs2017, vs2019, vs2022, Intel compiler 18 and 19), linux (g++ 4.8, 5, 6, 7, 8, 9, 10, 11, 12, clang++ 3.9 to 16) and MacOS (g++ and clang++) - click on travis and appveyor icons above for detailed test status.
-
Automatic support for boost's hash_value() method for providing the hash function (see
examples/hash_value.h). Also default hash support forstd::pairandstd::tuple. -
natvis visualization support in Visual Studio (hash map/set only)
@byronhe kindly provided this Chinese translation of the README.md.
Click here For a full writeup explaining the design and benefits of the Parallel Hashmap.
The hashmaps and btree provided here are built upon those open sourced by Google in the Abseil library. The hashmaps use closed hashing, where values are stored directly into a memory array, avoiding memory indirections. By using parallel SSE2 instructions, these hashmaps are able to look up items by checking 16 slots in parallel, allowing the implementation to remain fast even when the table is filled up to 87.5% capacity.
IMPORTANT: This repository borrows code from the abseil-cpp repository, with modifications, and may behave differently from the original. This repository is an independent work, with no guarantees implied or provided by the authors. Please visit abseil-cpp for the official Abseil libraries.
Copy the parallel_hashmap directory to your project. Update your include path. That's all.
If you are using Visual Studio, you probably want to add phmap.natvis to your projects. This will allow for a clear display of the hash table contents in the debugger.
A cmake configuration files (CMakeLists.txt) is provided for building the tests and examples. Command for building and running the tests is:
mkdir build && cd build && cmake -DPHMAP_BUILD_TESTS=ON -DPHMAP_BUILD_EXAMPLES=ON .. && cmake --build . && make test
#include <iostream>
#include <string>
#include <parallel_hashmap/phmap.h>
using phmap::flat_hash_map;
int main()
{
// Create an unordered_map of three strings (that map to strings)
flat_hash_map<std::string, std::string> email =
{
{ "tom", "tom@gmail.com"},
{ "jeff", "jk@gmail.com"},
{ "jim", "jimg@microsoft.com"}
};
// Iterate and print keys and values
for (const auto& n : email)
std::cout << n.first << "'s email is: " << n.second << "\n";
// Add a new entry
email["bill"] = "bg@whatever.com";
// and print it
std::cout << "bill's email is: " << email["bill"] << "\n";
return 0;
}The header parallel_hashmap/phmap.h provides the implementation for the following eight hash tables:
- phmap::flat_hash_set
- phmap::flat_hash_map
- phmap::node_hash_set
- phmap::node_hash_map
- phmap::parallel_flat_hash_set
- phmap::parallel_flat_hash_map
- phmap::parallel_node_hash_set
- phmap::parallel_node_hash_map
The header parallel_hashmap/btree.h provides the implementation for the following btree-based ordered containers:
- phmap::btree_set
- phmap::btree_map
- phmap::btree_multiset
- phmap::btree_multimap
The btree containers are direct ports from Abseil, and should behave exactly the same as the Abseil ones, modulo small differences (such as supporting std::string_view instead of absl::string_view, and being forward declarable).
When btrees are mutated, values stored within can be moved in memory. This means that pointers or iterators to values stored in btree containers can be invalidated when that btree is modified. This is a significant difference with std::map and std::set, as the std containers do offer a guarantee of pointer stability. The same is true for the 'flat' hash maps and sets.
The full types with template parameters can be found in the parallel_hashmap/phmap_fwd_decl.h header, which is useful for forward declaring the Parallel Hashmaps when necessary.
Key decision points for hash containers:
-
The
flathash maps will move the keys and values in memory. So if you keep a pointer to something inside aflathash map, this pointer may become invalid when the map is mutated. Thenodehash maps don't, and should be used instead if this is a problem. -
The
flathash maps will use less memory, and usually be faster than thenodehash maps, so use them if you can. the exception is when the values inserted in the hash map are large (say more than 100 bytes [needs testing]) and costly to move. -
The
parallelhash maps are preferred when you have a few hash maps that will store a very large number of values. Thenon-parallelhash maps are preferred if you have a large number of hash maps, each storing a relatively small number of values. -
The benefits of the
parallelhash maps are:
a. reduced peak memory usage (when resizing), and
b. multithreading support (and inherent internal parallelism)
Key decision points for btree containers:
Btree containers are ordered containers, which can be used as alternatives to std::map and std::set. They store multiple values in each tree node, and are therefore more cache friendly and use significantly less memory.
Btree containers will usually be preferable to the default red-black trees of the STL, except when:
- pointer stability or iterator stability is required
- the value_type is large and expensive to move
When an ordering is not needed, a hash container is typically a better choice than a btree one.
-
The default hash framework is std::hash, not absl::Hash. However, if you prefer the default to be the Abseil hash framework, include the Abseil headers before
phmap.hand define the preprocessor macroPHMAP_USE_ABSL_HASH. -
The
erase(iterator)anderase(const_iterator)both return an iterator to the element following the removed element, as does the std::unordered_map. A non-standardvoid _erase(iterator)is provided in case the return value is not needed. -
No new types, such as
absl::string_view, are provided. All types with astd::hash<>implementation are supported by phmap tables (includingstd::string_viewof course if your compiler provides it). -
The Abseil hash tables internally randomize a hash seed, so that the table iteration order is non-deterministic. This can be useful to prevent Denial Of Service attacks when a hash table is used for a customer facing web service, but it can make debugging more difficult. The phmap hashmaps by default do not implement this randomization, but it can be enabled by adding
#define PHMAP_NON_DETERMINISTIC 1before including the headerphmap.h(as is done in raw_hash_set_test.cc). -
Unlike the Abseil hash maps, we do an internal mixing of the hash value provided. This prevents serious degradation of the hash table performance when the hash function provided by the user has poor entropy distribution. The cost in performance is very minimal, and this helps provide reliable performance even with imperfect hash functions.
| type | memory usage | additional peak memory usage when resizing |
|---|---|---|
| flat tables |  |
 |
| node tables |  |
 |
| parallel flat tables | |
 |
| parallel node tables | |
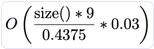 |
- size() is the number of values in the container, as returned by the size() method
- load_factor() is the ratio:
size() / bucket_count(). It varies between 0.4375 (just after the resize) to 0.875 (just before the resize). The size of the bucket array doubles at each resize. - the value 9 comes from
sizeof(void *) + 1, as the node hash maps store one pointer plus one byte of metadata for each entry in the bucket array. - flat tables store the values, plus one byte of metadata per value), directly into the bucket array, hence the
sizeof(C::value_type) + 1. - the additional peak memory usage (when resizing) corresponds the the old bucket array (half the size of the new one, hence the 0.5), which contains the values to be copied to the new bucket array, and which is freed when the values have been copied.
- the parallel hashmaps, when created with a template parameter N=4, create 16 submaps. When the hash values are well distributed, and in single threaded mode, only one of these 16 submaps resizes at any given time, hence the factor
0.03roughly equal to0.5 / 16
The rules are the same as for std::unordered_map, and are valid for all the phmap hash containers:
| Operations | Invalidated |
|---|---|
| All read only operations, swap, std::swap | Never |
| clear, rehash, reserve, operator= | Always |
| insert, emplace, emplace_hint, operator[] | Only if rehash triggered |
| erase | Only to the element erased |
Unlike for std::map and std::set, any mutating operation may invalidate existing iterators to btree containers.
| Operations | Invalidated |
|---|---|
| All read only operations, swap, std::swap | Never |
| clear, operator= | Always |
| insert, emplace, emplace_hint, operator[] | Yes |
| erase | Yes |
In order to use a flat_hash_set or flat_hash_map, a hash function should be provided. This can be done with one of the following methods:
-
Provide a hash functor via the HashFcn template parameter
-
As with boost, you may add a
hash_value()friend function in your class.
For example:
#include <parallel_hashmap/phmap_utils.h> // minimal header providing phmap::HashState()
#include <string>
using std::string;
struct Person
{
bool operator==(const Person &o) const
{
return _first == o._first && _last == o._last && _age == o._age;
}
friend size_t hash_value(const Person &p)
{
return phmap::HashState().combine(0, p._first, p._last, p._age);
}
string _first;
string _last;
int _age;
};- Inject a specialization of
std::hashfor the class into the "std" namespace. We provide a convenient and small headerphmap_utils.hwhich allows to easily add such specializations.
For example:
#include <parallel_hashmap/phmap_utils.h> // minimal header providing phmap::HashState()
#include <string>
using std::string;
struct Person
{
bool operator==(const Person &o) const
{
return _first == o._first && _last == o._last && _age == o._age;
}
string _first;
string _last;
int _age;
};
namespace std
{
// inject specialization of std::hash for Person into namespace std
// ----------------------------------------------------------------
template<> struct hash<Person>
{
std::size_t operator()(Person const &p) const
{
return phmap::HashState().combine(0, p._first, p._last, p._age);
}
};
}The std::hash specialization for Person combines the hash values for both first and last name and age, using the convenient phmap::HashState() function, and returns the combined hash value.
#include "Person.h" // defines Person with std::hash specialization
#include <iostream>
#include <parallel_hashmap/phmap.h>
int main()
{
// As we have defined a specialization of std::hash() for Person,
// we can now create sparse_hash_set or sparse_hash_map of Persons
// ----------------------------------------------------------------
phmap::flat_hash_set<Person> persons =
{ { "John", "Mitchell", 35 },
{ "Jane", "Smith", 32 },
{ "Jane", "Smith", 30 },
};
for (auto& p: persons)
std::cout << p._first << ' ' << p._last << " (" << p._age << ")" << '\n';
}Parallel Hashmap containers follow the thread safety rules of the Standard C++ library. In Particular:
-
A single phmap hash table is thread safe for reading from multiple threads. For example, given a hash table A, it is safe to read A from thread 1 and from thread 2 simultaneously.
-
If a single hash table is being written to by one thread, then all reads and writes to that hash table on the same or other threads must be protected. For example, given a hash table A, if thread 1 is writing to A, then thread 2 must be prevented from reading from or writing to A.
-
It is safe to read and write to one instance of a type even if another thread is reading or writing to a different instance of the same type. For example, given hash tables A and B of the same type, it is safe if A is being written in thread 1 and B is being read in thread 2.
-
The parallel tables can be made internally thread-safe for concurrent read and write access, by providing a synchronization type (for example std::mutex) as the last template argument. Because locking is performed at the submap level, a high level of concurrency can still be achieved. Read access can be done safely using
if_contains(), which passes a reference value to the callback while holding the submap lock. Similarly, write access can be done safely usingmodify_if,try_emplace_lorlazy_emplace_l. However, please be aware that iterators or references returned by standard APIs are not protected by the mutex, so they cannot be used reliably on a hash map which can be changed by another thread. -
Examples on how to use various mutex types, including boost::mutex, boost::shared_mutex and absl::Mutex can be found in
examples/bench.cc
While C++ is the native language of the Parallel Hashmap, we welcome bindings making it available for other languages. One such implementation has been created for Python and is described below:
- GetPy - A Simple, Fast, and Small Hash Map for Python: GetPy is a thin and robust binding to The Parallel Hashmap (https://github.com/greg7mdp/parallel-hashmap.git) which is the current state of the art for minimal memory overhead and fast runtime speed. The binding layer is supported by PyBind11 (https://github.com/pybind/pybind11.git) which is fast to compile and simple to extend. Serialization is handled by Cereal (https://github.com/USCiLab/cereal.git) which supports streaming binary serialization, a critical feature for the large hash maps this package is designed to support.
Many thanks to the Abseil developers for implementing the swiss table and btree data structures (see abseil-cpp) upon which this work is based, and to Google for releasing it as open-source.