This repository contains the code for running the experiments in the paper "Benchmarking FedAvg and FedCurv for Image Classification Tasks", Casella et al., ITADATA2022.
You need to install OpenFL, the framework for Federated Learning developed by Intel:
$ pip install openfl
For more installation options check out the online documentation.
OpenFL enables data scientists to set up a federated learning experiment following one of the workflows:
-
Director-based Workflow: Setup long-lived components to run many experiments in series. Recommended for FL research when many changes to model, dataloader, or hyperparameters are expected
-
Aggregator-based Workflow: Define an experiment and distribute it manually. All participants can verify model code and FL plan prior to execution. The federation is terminated when the experiment is finished
The quickest way to test OpenFL is to follow our tutorials.
Read the blog post explaining steps to train a model with OpenFL.
Check out the online documentation to launch your first federation.
- Ubuntu Linux 16.04 or 18.04.
- Python 3.6+ (recommended to use with Virtualenv).
OpenFL supports training with TensorFlow 2+ or PyTorch 1.3+ which should be installed separately. User can extend the list of supported Deep Learning frameworks if needed.
Federated learning is a distributed machine learning approach that enables collaboration on machine learning projects without having to share sensitive data, such as, patient records, financial data, or classified information. The minimum data movement needed across the federation is solely the model parameters and their updates.
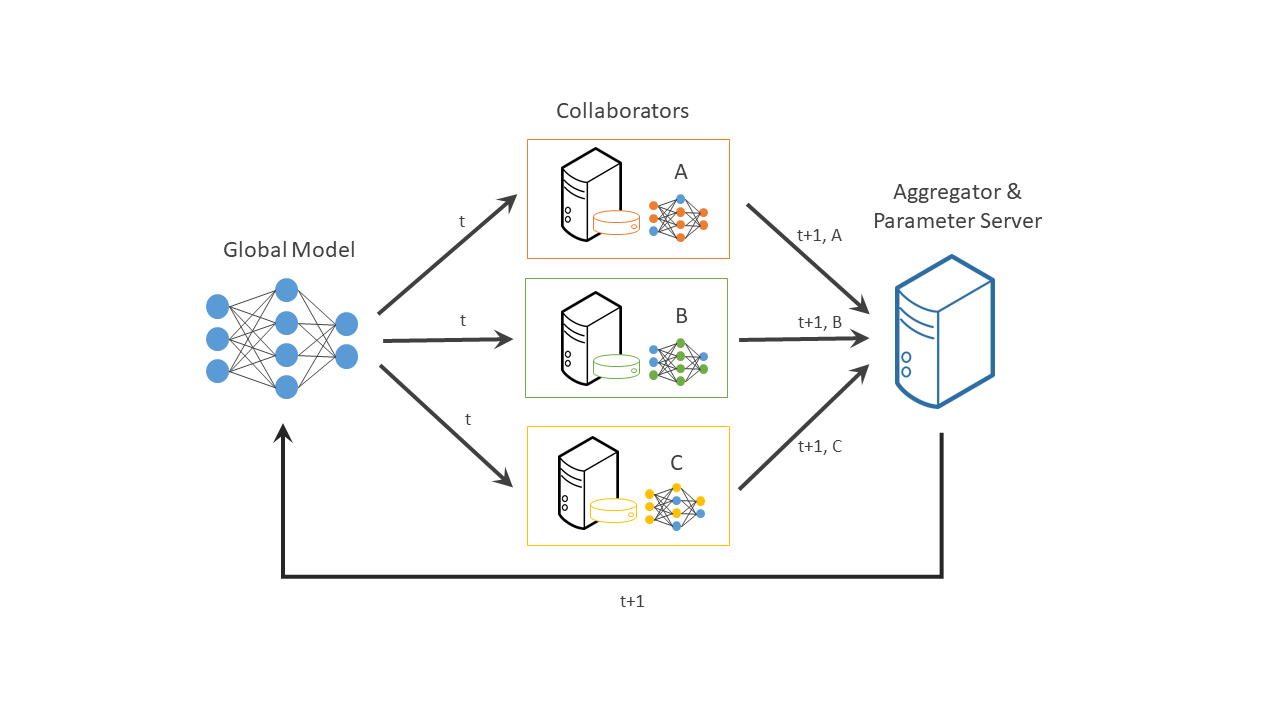
You can test Federated Learning in the following settings:
- CIFAR-10
- MNIST
- MEDMNIST2D (organamnist)
- Uniform (IID)
- Quantity Skew (non-IID)
- Prior shift (non-IID) in three versions: labels quantity skew, pathological labels skew, Dirichlet Labels skew
- Covariate shift (non-IID)
In order to use one of the previous partitionings methods you need to overwrite numpy.py with the provided non-iidness.py
Steps:
./start_director.sh- Start how many envoys you want with
./start_envoy.sh - Create your Jupyter notebook with all the settings you want!
Bruno Casella - bruno.casella@unito.it Roberto Esposito - roberto.esposito@unito.it Carlo Cavazzoni - carlo.cavazzoni@leonardo.com Marco Aldinucci - marco.aldinucci@unito.it
We welcome questions, issue reports, and suggestions:
@inproceedings{casella2022benchmarking,
author = {Bruno Casella and
Roberto Esposito and
Carlo Cavazzoni and
Marco Aldinucci},
editor = {Marco Anisetti and
Angela Bonifati and
Nicola Bena and
Claudio Ardagna and
Donato Malerba},
title = {Benchmarking FedAvg and FedCurv for Image Classification Tasks},
booktitle = {Proceedings of the 1st Italian Conference on Big Data and Data Science, {ITADATA} 2022,
September 20-21, 2022},
series = {{CEUR} Workshop Proceedings},
publisher = {CEUR-WS.org},
year = {2022},
url = {https://iris.unito.it/bitstream/2318/1870961/1/Benchmarking_FedAvg_and_FedCurv_for_Image_Classification_Tasks.pdf}
}