{kind=link}
{kind=link}
{kind=link}
One common feature of the majority examples of using BERTopic is that the texts are mostly in English. Modern English uses a space to separate words, but languages such as Chinese and Japanese do not follow this convention. This difference plays a huge part when using BERTopic. In this project, I demonstrate the differences in results when generating topics with or without a tokenizer when analyzing Japanese texts.
Figure 1: Change in results with and without a Japanese tokenizer
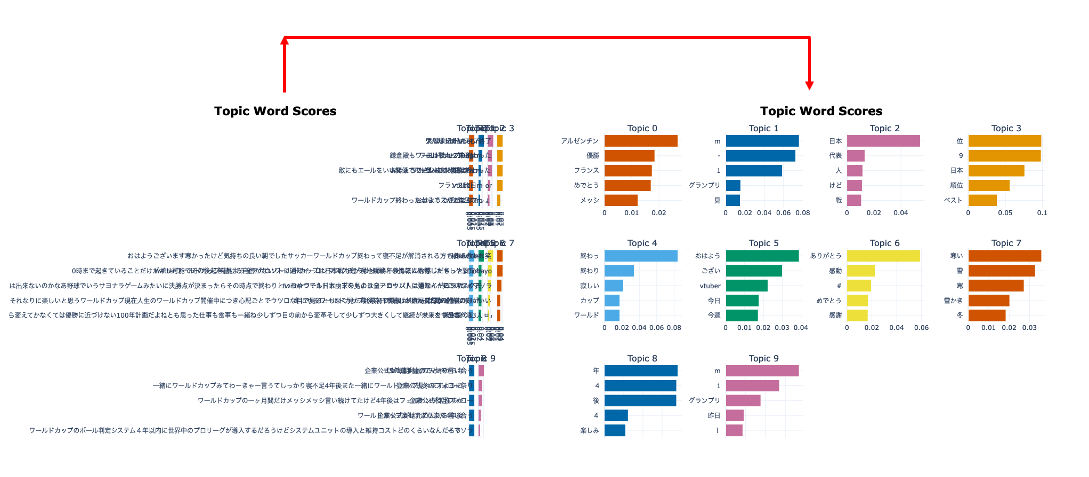
Figure 2: Result without a Japanese Tokenizer

Figure 3: Result with a Japanese Tokenizer
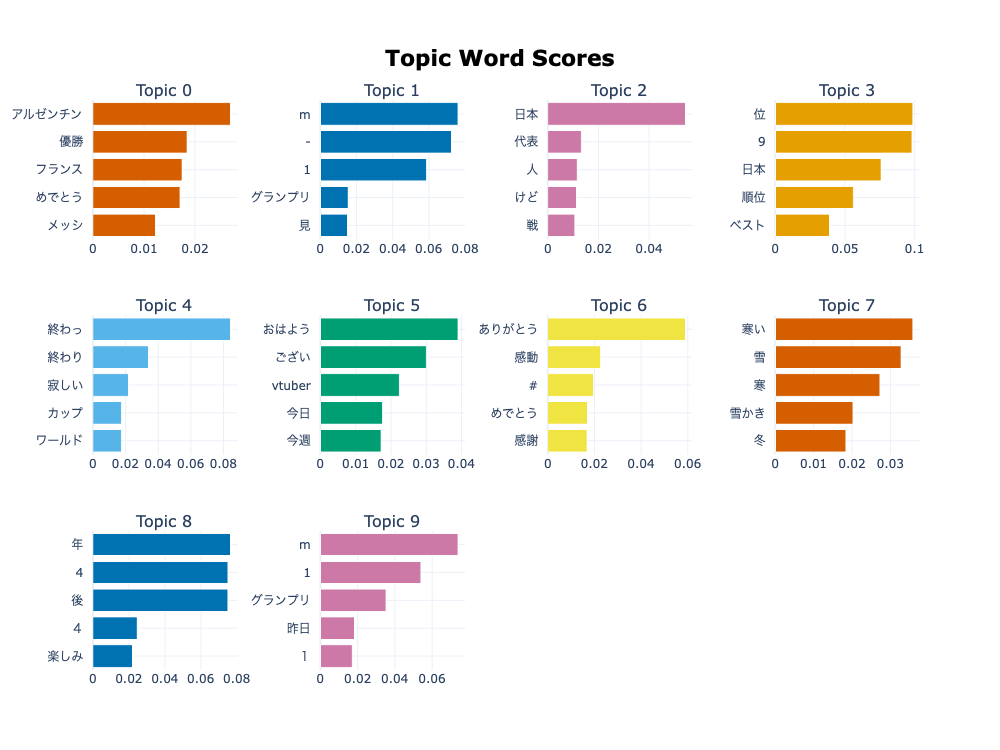
- From analyzing Figure 1, it is evident that applying a Japanese tokenizer to BERTopic significantly impacts the topic representation. When BERTopic is not coupled with a Japanese tokenizer, the topic representations resemble complete sentences rather than individual words, resulting in a cluttered and disorganized topic word score figure. However, when we utilize a Japanese tokenizer, the results are more appropriate for our objective of detecting and visualizing topics. Figure 2 and Figure 3 exhibit the outcomes of each scenario, respectively. Therefore, incorporating a Japanese tokenizer in BERTopic enhances the topic representation and makes it more useful for topic identification and visualization.
https://github.com/JustAnotherArchivist/snscrapehttps://medium.com/@cd_24/using-bertopic-to-analyze-qatar-world-cup-twitter-data-a5956c4949f1I adopted the list of Japanese stop words from the following:
https://github.com/stopwords-iso/stopwords-jaThe codes programmed in this project are displayed in this repository. Feel free to check and use them.
If you are interested in learning more about how to develop a Japanese tokenizer and the necessity of using a tokenizer when utilizing BERTopic for analyzing Japanese texts, I recommend reading my post on Medium. In the article, I delve into the importance of tokenization in natural language processing and explain how Japanese language's unique characteristics require a specific tokenizer to ensure accurate analysis. Furthermore, I outline the steps involved in building a Japanese tokenizer and provide detailed code snippets for your reference.