{kind=link}
Sentence Transformers on EC2 Inf1 and Amazon SageMaker
- trace-model.py takes a static batch-size and name of model to build
- inference.py runs the traced model on a single core (Run this 4 times to start 4 different processes)
- Build out the static batch-size traced models
- Pull the models on to EFS on SageMaker studio (just upload the model files)
- Update batch size and deploy.
To run on EC2, after installing the relevant packages
You can also change model_id using --model_id option
python trace-model.py --batch_size 50
Modify the batch_size and simply run the following four times. Every process runs in a separate neuron core so it has to be started in background 4 times.
NEURON_RT_NUM_CORES=1 python inference.py &
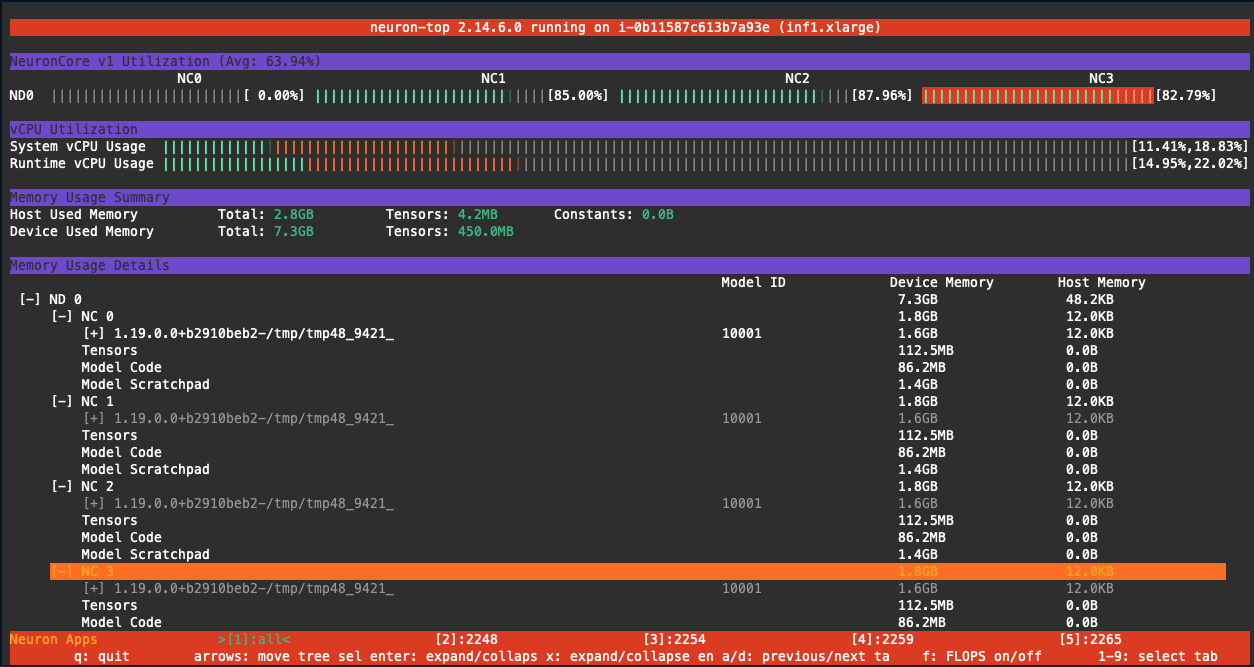
Use Neuron Top (neuron-top) utility on EC2 Inf1
Simply upload the model folders and the notebook and run it through SageMaker
Four copies of the same model loaded to 4 different cores on inf1.xlarge on EC2