Stage-wise Fine-tuning for Graph-to-Text Generation
Accepted by the Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing 2021 Student Research Workshop (ACL-IJCNLP 2021 SRW)
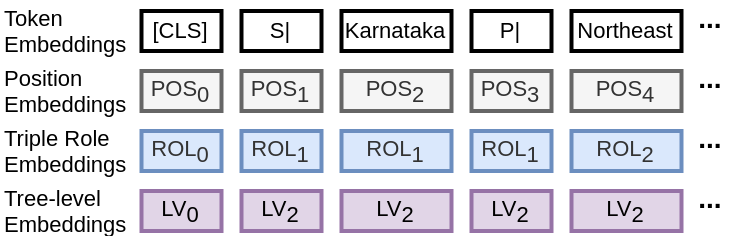
This project is based on the framework HuggingFace Transformers.
- Python 3.8.5
- Ubuntu 18.04/20.04 CAUTION!! The model might not run properly on windows because windows uses backslashes on the path while Linux/OS X uses forward slashes
# Create python environment (optional)
conda create -n stage_fine python=3.8.5
# Install pytorch with cuda (optional)
conda install pytorch==1.7.1 cudatoolkit=11.0 -c pytorch
# Install python dependencies
pip install -r requirements.txt
For this paper, we test our model on the original version of English WebNLG 2017. The preprocessed WebNLG data with position information for this model can be downloaded here.
This repository contains data used for the Wikipedia fine-tuning stage for paper Stage-wise Fine-tuning for Graph-to-Text Generation. The documentation for this dataset is here. The preprocessed Wikipedia Pre-train Pairs with position information for this model can be downloaded here.
You can download preprocessed WebNLG with Position and Wikipedia Pre-train Pairs with Position. Unzip them in the src folder.
If you prefer to preprocess by yourself, download WebNLG 2017 and Wikipedia Pre-train Pairs. Put them under the preprocess folder. Unzip total.zip which contains Wikipedia Pre-train Pairs.
To get WebNLG with Position. Run webnlg_tree.py under this folder:
python webnlg_tree.py
This will create pos.
To get Wikipedia Pre-train Pairs with Position. Run webnlg_tree.py under this folder:
python get_new_pretrained_pos.py
Copy val.* and test.* from pos folder to wiki_pos folder. Move pos folder and wiki_pos folder under the src folder.
You can finetune your model by running finetune_*_all.sh in the src folder. For example, if you want to test t5_large, you can run
./finetune_t5_large_all.sh
Similarly, you can finetune your own model by running finetune_*_alone.sh in the src folder. For example, if you want to test t5_large, you can run
./finetune_t5_large_alone.sh
You can modify hyperparameters such as batch size in those bash files. The result will be under *_results/test_generations.txt.
Our model can be downloaded here. After you extract the file under the src folder, you can run
./test_t5.sh
to get the result.
The result will be under t5_large_pos_test_results/test_generations.txt.
The official evaluation script is based on WebNLG official transcript and DART.
Change OUTPUT_FILE in run_eval_on_webnlg.sh and run the following:
./run_eval_on_webnlg.sh
For details about PARENT score, please check PARENT folder.
Install Bert-Score from pip by
pip install bert-score
Test your file
bert-score -r evaluation/references/reference0 evaluation/references/reference1 evaluation/references/reference2 -c evaluation/example/pos+wiki.txt --lang en
If you have some questions about BERT-Score, please check this issue.
Result from T5-large + Wiki + Position is here.
| Model | BLEU ALL | METEOR ALL | TER ALL | BERTScore P | BERTScore R | BERTScore F1 |
|---|---|---|---|---|---|---|
| T5-large + Wiki + Position | 60.56 | 0.44 | 0.36 | 96.36 | 96.13 | 96.21 |
@inproceedings{wang-etal-2021-stage,
title = "Stage-wise Fine-tuning for Graph-to-Text Generation",
author = "Wang, Qingyun and
Yavuz, Semih and
Lin, Xi Victoria and
Ji, Heng and
Rajani, Nazneen",
booktitle = "Proceedings of the ACL-IJCNLP 2021 Student Research Workshop",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-srw.2",
pages = "16--22"
}