
- Write Once, Read Many times (WORM).
- Divide files into big blocks and distribute across the cluster.
- Store multiple replicas of each block for reliability.
- Programs can ask "where do the pieces of my file live?”.
- Is the master service of HDFS.
- Determines and maintains how the chunks of data are distributed across the DataNodes.
- Stores the chunks of data, and is responsible for replicating the chunks across other DataNodes.
- The NameNode(master node) and DataNodes(worker nodes) are daemons running in a Java virtual machine.
- The entire cluster is unavailable if the NameNode:
- Fails or becomes unreachable.
- Is stopped to perform maintenance.
- Uses a redundant NameNode
- Is configured in an Active/Standby configuration
- Enables fast failover in response to NameNodefailure
- Permits administrator-initiated failover for maintenance
- Is configured by Cloudera Manager
- The NameNode(master node) and DataNodes(worker nodes) are daemons running in a Java virtual machine.
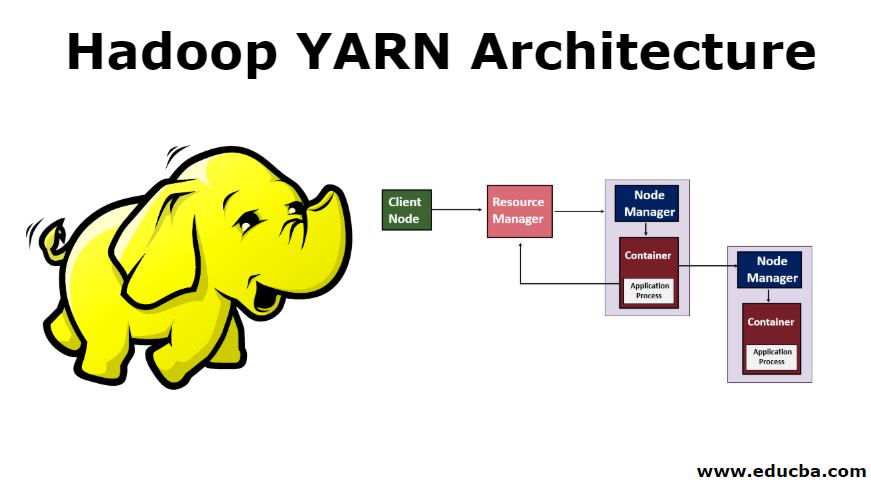
- Yet Another Resource Negotiator
- Architectural center of Enterprise Hadoop
- Provides centralized resource management and job scheduling across multiple types of processing workloads
- Enables multi tenancy
- Global resource scheduler
- Hierarchical queues
- Per-machine agent
- Manages the life-cycle of container
- Container resource monitoring
- Per-application
- Manages application scheduling and task execution
- E.g. MapReduce Application Master
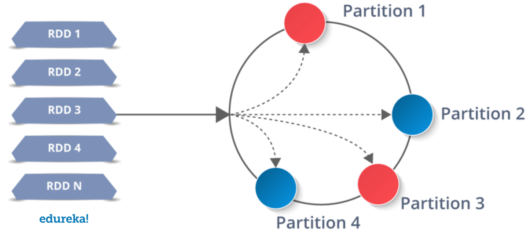
- Resilient Distributed Dataset (RDD)
- Resilient: if data in memory is lost, it can be recreated
- Distributed: Processed across the cluster
- Dataset: Initial data can come from a source such as a file, or it can be created programmatically
- Transformations stored as a graph (DAG) from a base RDD
- Consider an RDD to be a set of operations
- It's not really a container for specific data
- When it needs to provide data
- Optimize required calculations (we'll view this soon)
- Efficiently recover RDDs on node failure (more on this later)
- Lineage: The series of transformations producing an RDD
- Efficient, and adds little overhead to normal operation

- DataFrames model data similar to tables in an RDBMS.
- DataFrames consist of a collection of loosely typed Row objects.
- Rows are organized into columns described by a schema.
- Datasets are strongly-typed—type checking is enforced at compile time rather than run time.
- An associated schema maps object properties to a table-like structure of rows and columns.
- Datasets are only defined in Scala and Java.
- DataFrameis an alias for Dataset[Row]—Datasets containing Row objects.
- DataFrameOperaMons: Transformations
- Transformations create a new DataFrame based on an existing one
- Transformations create a new DataFrame based on an existing one
- Data remains distributed across the application’s executors
- Data in a DataFrame is never modified
- Use transformations to create a new DataFrame with the data you need
- Schema on Read
- SQL to Map Reduce (Reduce complexity of Map Reduce)
- Familiar Programming Context with SQL

- Widely used for data ingest
- Conceptually similar to a publish-subscribe messaging system
- Offers scalability, performance, reliability, and flexibility
- Donated to the Apache Software Foundation in 2011
- Graduated from the Apache Incubator in 2012
- Supported by Cloudera for production use with CDH in 2015
- A single data record passed by Kafka
- Messages in Kafka are variable-size byte arrays
- There is no explicit limit on message size
- Kafka retains all messages for a defined time period and/or total size
- There is no explicit limit on the number of topics
- A topic can be created explicitly or simply by publishing to the topic
- A named log or feed of messages within Kafka
- Producers publish messages to Kafka topics
- A program that writes messages to Kafka
- A program that reads messages from Kafka
- A consumer reads messages that were published to Kafka topics
- Consumer actions do not affect other consumers
- They can come and go without impact on the cluster or other consumers
- A Kafka cluster consists of one or more brokers—servers running the Kafka broker daemon
- Kafka depends on the Apache ZooKeeper service for coordination
- Typically running three or five ZooKeeper instances
One broker is elected controller of the cluster (for assignment of topic partitions to brokers, and so on)
- Doing so is recommended, as it provides fault tolerance
- Followers passively replicate the leader
- If the leader fails, a follower will automatically become the new leader
- The leader writes the message to its local log
- Each follower then writes the message to its own log
- After acknowledgements from followers, the message is committed