6_블록체인
비트코인 세상에서 여러분이 발생되는 거래가 정확히 어느시점에서 승인되는지 다시한번 환기해보자. 일단 비트코인 지갑을 사용해 트랜젝션을 생성해 낸다. 그 후 이 트랜젝션을 비트코인 네트워크 전역으로 전파시키며, 채굴자는 비트코인 네트워크를 떠돌아다니는 트렌젝션들을 모아서 블록이라는 형태로 저장한다. 그 후 채굴의 과정을 거쳐 블록체인에 포함시키는 순간 여러분이 발생시킨 거래는 공식적으로 인정받게 되는 것이다. 그럼 여기서 블록체인이란 무엇일까?
사실 블록체인의 개념은 별로 복잡하지는 않아서, 그냥 딱 한마디로 표현할수도 있는데 "새로생긴 블록이 이전 블록을 증명해 주는 구조"이다. 물론 이것만으로 이해할 수 있는사람은 별로 없을것이라 생각해 좀 더 세부적으로 표현해 보자면, 일단 비트코인에서 블록은 매 10분에 하나씩 생겨난다. 그리고 새로 생긴 블록은 바로 이전에 새로생긴 블록의 해시값을 가지고 있는 형태이다. 그럼 이게 왜 대단한 것일까?
2017년기준 현재 블록체인상에는 약 50만개의 블록이 쌓여있다. 이 50만개의 블록중 필자가 100번째 블록에 있는 거래데이터를 조작하려고 한다 가정해보자. 그럼 100번째 블록의 해시값은 크게 변하게 될것이다. 그리고 그럼으로 인해 101번째 블록에 명시되어있는 100번째 블록의 해시값이 일치하지 않아 데이터가 조작되었음을 바로 확인할 수 있다. 이런 문제점을 파악하고 101번째 블록에 명시되어있는 100번째 블록의 해시값을 바꾸면 이번에는 102번째 블록에 명시된 101번쨰 블록의 해시값이 서로 달라지게 된다. 즉, 필자가 100번째 블록의 거래데이터를 조작하려면 필자는 100번째부터 가장 최근에 생긴 50만번째 블록까지 모두 조작해야된다는 것이다.
물론 이 모든것은 컴퓨터상에서 발생하는 일이니 간단한 프로그램만 짜면 단순히 N번째 블록이 N-1번째 블록의 해시값만 가지고 있는 50만개의 블록을 조작하는 일은 말그대로 순식간에 끝낼 수 있다. 이런일을 방지하기 위해 비트코인은 PoW(Proof of Work)라는 개념과 함께 채굴이란 시스템을 도입하였다.
이 파트에서는 비트코인의 블록의 구조에 대해 설명한 뒤, 비트코인의 블록체인이 어떻게 작동하는지, 채굴이란 무엇인지, 비트코인에서 운영되는 블록체인 말고 다른 블록체인은 어떻게 비트코인형태의 블록체인의 단점을 극복하려 했는지 등을 설명할 예정이다.
비트코인의 모든 거래데이터는 블록이란 형태로 저장된 뒤 블록체인에 포함된다. 이 블록은 크게 두가지 파트로 나뉘어 지는데 하나는 블록 헤더이고 나머지 하나는 블록 바디이다. 이름에서 예상할수 있는것 처럼 블록헤더에는 블록 그 자체에 대한 정보가 담겨있고 블록 바디에는 블록의 몸체, 즉 거래데이터가 담겨있다. 이번 파트에서는 이러한 거래데이터는 어떻게 담겨져 있는지로 시작해 블록 헤더는 어떤구조를 가져왔는지에 대해 자세히 알아보아 다음 파트에서 만날 블록체인을 이해하기 쉽게 도와줄 것이다.
다만 읽을 때 주의해야할 점이 있다. 2017년 7월 기준 블록은 언제나 약 10분에 한개씩 생성되어 왔으며 각 블록은 항상 1MB이하의 크기를 가져왔다. 이는 약속된 내용이였다. 하지만, 이러한 약속은 2009년 첫 블록이 생성될때 정해진 것이고, 2009년의 비트코인 상황과 지금의 비트코인 상황은 엄청난 차이가 있며, 현재 비트코인은 10분에 생성되는 1MB짜리 블록만 가지고는 모든 거래를 감당하기 힘든 상황에 놓여있다. 좀 더 쉬운표현으로 말하자면 처음 약속을 정할때 현재와 같은 상황을 염두하고 약속을 한 것이 아니기에 그 구조가 한계에 달했다는 것이다.
이러한 상황속에서 비트코인 개발자들은 2017년 8월 1일부터 시작해 2017년 말까지, 어쩌면 더 오랜시간에 거쳐 대규모 업그레이드를 강행할것을 예고해 왔다. 물론 상세한 업그레이드 내용은 이미 공개되어있기 때문에 그에 맞추어 글을 쓰면 되지만 더 큰 문제는 최근 거대한 3개의 비트코인 진영이 각각의 업그레이드 방안을 내놓았고 3가지 버전중 어느것이 더 많은 지지를 얻을지 필자가 이 글을 쓰는 시점에서는 파악할 수 없다는 것이다. 그래서 이 파트에서는 현재 시점으로 사용되는 블록에 대해 설명을 하고 부록형식으로 앞으로 바뀔 형식에 대해 자세히 다뤄볼 예정이니 참고바란다.
블록은 다음표와 같은 데이터 구조를 가진다.
| 크기 | 이름 | 설명 |
|---|---|---|
| 4Byte | Magic no | 언제나 0xD9B4BEF9 를 가지는것으로 정해져있다. |
| 4Byte | Blocksize | 블록의 총 크기가 몇바이트인지에 대한 정보가 담겨있다. |
| 80Byte | Blockheader | 블록헤더 |
| 1~9Byte | Transaction counter | 해당 블록에 포함되는 Tx의 개수 |
| 가변적 | transactions | 각 사용자가 생성한 Tx들이 직렬화되어 들어있다. |
그 다음으로 블록헤더는 다음과 같은 데이터 구조를 가진다.
| 크기 | 이름 | 설명 |
|---|---|---|
| 4Byte | Version | 블록 버전에 대한 정보가 담겨있다. |
| 32Byte | hashPrevBlock | 이전 블록 헤더의 해시값이 담겨있다. |
| 32Byte | hashMerkleRoot | 블록 바디의 머클 트리로부터 나온 머클루트값이 담겨있다. |
| 32Byte | Time | 유닉스 타임스탬프를 사용한다. |
| 4Byte | nBits | 이 블록헤더의 해시값이 충족해야할 조건에대한 정보가 담겨있다. |
| 4Byte | Nonce | nBits를 만족시키기위해 채굴자가 마음대로 조작가능한 공간이다.. |
필자가 처음 블록바디에 대해 알아보려 했을때는 C언어에서 흔히 쓰는 배열처럼 그냥 추가하려는 Tx들을 나열해 놓으면 되지 않을까?라는 생각을 했었다. 결론은 맞았다. 하지만 한가지 추가되는 내용이 있었는데 바로 머클트리의 존재였다.
머클트리는 랄프 머클(Ralph Merkle) 이라는 사람이 "Method of providing digital signatures"라는 제목으로 밝힌 특허에서 처음 공개되었다.
graph BT
Tx1-->H1["H1:Hash(Tx1)"]
Tx2-->H2["H2:Hash(Tx2)"]
Tx3-->H3["H3:Hash(Tx3)"]
Tx4-->H4["H4:Hash(Tx4)"]
H1-->H12["H12:Hash(H1+H2)"]
H2-->H12
H3-->H34["H34:Hash(H3+H4)"]
H4-->H34
H12-->H1234["H1234: Hash(H12+H34)"]
H34-->H1234
머클트리를 만들기위한 과정은 다음과 같다. 일단 가장먼저 블록에 저장된 각각의 Tx으로부터 해시값을 구한다. 여기서 사용되는 해시함수는 SHA256d로 Tx전체 데이터에대하여 SHA2를 두번돌린 값이다. 이렇게 Tx1부터 Tx4까지 각각 해시값을 구해냈으면 다음과정은 H1이라는 해시값 뒤에다가 H2를 붙혀 탄생한 새로운 데이터의 해시값 H12을 구한다. 같은과정을 H3, H4 쪽에도 행해준다. 마지막으로 H12라는 해시값 뒤에다가 H34를 붙혀 탄생한 새로운 데이터의 해시값 H1234를 구한다...... 이 과정은 최상위에 딱 하나의 노드가 남을 때까지 반복되며 이렇게 마지막으로 하나남은 노드를 머클루트라 하며, 이렇게 완성된 머클루트는 블록헤더에 블록바디 전체의 데이터를 보증해주는 역할로 저장된다.
여기서부터는 핵심만
그럼 이러한 머클트리 구조에서 머클루트존재 하나만으로도 블록 바디에 대한 무결성을 보증할 수 있다는것은 알겠지만 어떻게 SPV 노드가 이를 이용할 수 있을까? 아래 그림에서 SPV노드가 Tx4의 데이터를 받았을때, 이것이 올바른 데이터인지에 대해 증명해보려는 상황을 생각해보자.
graph BT
Tx1-->H1["H1:Hash(Tx1)"]
Tx2-->H2["H2:Hash(Tx2)"]
Tx3-->H3(("H3:Hash(Tx3)"))
Tx4-->H4("H4:Hash(Tx4)")
H1-->H12(("H12:Hash(H1+H2)"))
H2-->H12
H3-->H34["H34:Hash(H3+H4)"]
H4-->H34
H12-->H1234["H1234: Hash(H12+H34)"]
H34-->H1234
Tx5-->H5["H5:Hash(Tx5)"]
Tx6-->H6["H6:Hash(Tx6)"]
Tx7-->H7["H7:Hash(Tx7)"]
Tx8-->H8["H8:Hash(Tx8)"]
H5-->H56["H56:Hash(H5+H6)"]
H6-->H56
H7-->H78["H78:Hash(H7+H8)"]
H8-->H78
H56-->H5678(("H5678: Hash(H56+H78)"))
H78-->H5678
H1234-->H12345678
H5678-->H12345678["Merkle Root: Hash(H1234+H5678)"]
일단 SPV노드는 블록헤더에 포함되어있는 Merkle Root에 대한 정보는 알고있고 Tx4에 대한 정보는 받았으니 Tx4의 해시값인 H4도 알고있다. 그럼 여기서 Tx4에대한 정보를 추가적으로 알아내려면 H3, H12, H5678의 정보만 알면된다. 그 이유는 일단 H3와 H4를 이용해 H34를 구할 수 있으며 H34와 H12를 이용해 H1234를 구할 수 있고, 마지막으로 H1234와 H5678을 이용했더니 Merkle Root와 같은 값이 나오면 SPV노드는 완벽한 100%의 확률은 아니지만 거의 100%에 수렴하는 확률로 Tx4는 실제 블록에 포함되어있는 정보 그대로라는 것을 유추할 수 있는 것이다.
즉 SPV노드는 이러한 머클트리의 특징을 통해 머클트리를 사용하지 않았다면 1MB에 달하는 블록을 통쨰로 받아야만했던 상황으로부터 벗어나, 받으려는 Tx 데이터 그자체와 일반적으로 블록안에 포함된 거래의 개수가 약 1000개라는 점을 생각할때 약 10개의 추가적인 32바이트짜리 해시값을 받아오는것 만으로도 자신이 원하는 Tx이 제대로된 Tx이 검증할 수 있는것이다.
일반적으로 Tx가 늘어남에따라 머클트리에서 인증을 하기위해 필요한 해시의 개수는 Log2(N)개, 2^10=1024
내용이 좀 부실....;;;; 수정 필요.
눈치가 빠른 독자분들이라면 앞서 거래의 생성부분에 대한 설명을 읽고 있을떄 다음과 같은 한가지 의문이 들것이다.
거래의 입력으로 이전거래의 출력을 사용했다면 최초의 거래의 입력은 어디서부터 나온것인가?
이에대한 답을 알아보기위한 방법은 간단하다.
이전블록이 존재하지 않는 최초의 거래의 입력은 어디서 부터 나왔을까?
일단 비트코인상에서 최초의 거래는 2009년 1월 3일 오후 6시경에 발생했으며 BlockChain.info에서 보여주는 해당 거래 내역은 다음과 같다.
graph LR
subgraph TxId:4a5e1e4baab89f3a32518a88c31bc87f618f76673e2cc77ab2127b7afdeda33b
A["No Inputs (Newly Generated Coins)"] -->|50 BTC| B[1A1zP1eP5QGefi2DMPTfTL5SLmv7DivfNa]
subgraph 입력
A
end
subgraph 출력
B
end
end
뭔가 이상하다. 입력값이 없고 새로 생성된 코인이라고 한다. 이게 어떻게 된 일일까?
앞서 여러번 밝혔다시피 블록은 채굴자에 의해서 생성된다. 그럼 채굴자들은 왜 채굴을 하는것일까? 당연히 비트코인을 벌기 위해서다. 그럼 채굴자들은 비트코인을 어떻게 벌 수 있을까? 이에대한 해결책으로 비트코인은 블록을 만들어낸 자에게 일정분량의 비트코인을 사용할 권리를 부여하였다. 이렇게 매 블록 생성되는 비트코인을 사용하는 거래를 Coinbase Transaction 혹은 생성거래라고 하는데 매 블록의 첫번째 거래는 생성 거래로 되어있는것으로 정해져 있으며 이 생성 거래의 데이터 구조는 다음과 같은 형태를 가진다.
| 크기 | 이름 | 설명 |
|---|---|---|
| 32Byte | Previous Transaction hash | 본래 이전거래의 TxId가 있어야 하나 없으므로 모든 비트가 0이다. |
| 4Byte | Previous Txout-index | 본래 이전거래의 인덱스번호가 있어야 하나 없으므로 모든 비트가 1이다. |
| 1~9Byte | Coinbase data bytes | Coinbase data의 크기를 Byte단위로 나타낸다. |
| 가변적 | Coinbase data | 블록을 생성한 자가 자기가 원하는 데이터를 마음대로 집어넣을 수 있다. |
| 4Byte | sequence | 무조건 0xFFFFFFFF |
비트코인 채굴자는 Coinbase data부분에 자기가 원하는 메세지를 남길 수 있는데 비트코인의 개발자 사토시 나가모토가 처음으로 이곳에 남긴 메세지는 다음과 같다.
��EThe Times 03/Jan/2009 Chancellor on brink of second bailout for banks
실제 The Times라는 신문사에서 발행한 기사로, 비트코인의 개발동기를 엿볼수 있는 기사라고 한다.
지금은 이 공간을 완벽하게 개인이 자유롭게 사용할수는 없고 비트코인 개선안에대한 "투표"나 블록헤더에 추가되지 못한 블록의 추가정보, 채굴을 위한 가능성 확보등의 방법으로 사용되고 있다.
이 생성 거래를 통해 새로 비트코인 네트워크에 추가되는 금액은 매 블록마다 50BTC로 시작하여 매 210,000개의 블록이 생성될때 마다 (약 4년의 기간이다) 반씩 줄어들어 2012년 11월 블록당 25BTC, 2016년 7월 블록당 12.5BTC로 줄어들었으며, 그렇게 계속 줄어들어 2140년경이 되면 블록당 지불되는 비트코인이 없어져, 총 약 2,100만개의 비트코인이 블록마다 발행될 예정인데, 그럼 문제가 발생한다. 2140년 이후에는 채굴자가 받는 이득이 전혀 없는 것일까? 다행이도 그렇지 않다.
2017년 현재기준으로 새로생성되는 블록은 12.5BTC을 새로 생성한다. 하지만 생성거래부분을 보면 이보다는 확실히 많은 양의 비트코인을 받고있는것을 확인할 수 있는데 이부분이 바로 수수료를 회수하는 부분이다. 여러분도 알다시피 비트코인을 사용할때는 수수료를 지불해야하며 더 많은 수수료를 지불할수록 더 빨리 블록체인속에 포함될 수 있다. 이 수수료는 각 Tx의 입력값과 출력값의 차이만큼이 되는데 바로 이 차액이 생성거래부분에 더해지고 채굴자는 수수료를 회수할 수 있는 것이다. (당연하게도 채굴자는 더 많은금액을 받기위해 수수료가 높은 거래부터 처리한다.)
현재 통계상 매 블록마다 약 1BTC의 수수료가 채굴자에게 지불이 된다고 한다. 다만 채굴자들은 이 금액으로는 추후 기본 지급되는 비트코인이 반감되었을때, 운영되는 채굴장비의 유지비를 감당 못해 수수료를 올려야된다고 주장하고 반대로 사용자측은 지금 지불되는 수수료도 많다고 주장해 적절한 수수료의 값이 얼마인가에 대한 논의는 계속되고 있다.
아이들이 가지고 놀기 좋은 정육면체 모양의 나무블록을 상상해보자. 블록A가 놓여져있다. 그 옆에 블록B를 두고 블록A와 블록B를 사슬로 엮어놓는다. 다음으로 블록 C를 블록 B옆에다 두고 블록 B와 블록 C를 사슬로 엮는다. 이제 여기서 블록 B를 들어올려보자. 블록 A와 블록 C가 같이 움직일 것이다.
비트코인의 블록체인은 위 상황과 매우 유사하다. 모든 블록은 사슬처럼 서로 묶여있으며 그중 블록 하나를 조작하려고하면 다른 블록들이 반응을 해서 블록이 조작됬다는 사실을 알려준다. 그럼 이게 데이터적으로 어떻게 구현되어있을까?
구현의 키워드는 데이터의 지문, 해시값이다. 비트코인상의 블록은 모두 이전블록의 해시값을 가지고 있다. 이렇게 다음블록이 자신의 해시값을 가지고 있는 상황에서 만약 해당블록이 조작되었다면 당연히 자기자신의 해시값이 달라져 다음블록에 적혀있는 해시값을 통해 조작된 사실을 쉽게 파악할 수 있다.
하지만 여기서 문제가 발생한다. 모든 블록의 해시값이 조작되면, 어떤 블록의 데이터가 조작되어도 파악할 수가 없다. 이런 상황에서 해시값이 조작되어도 판단할 수 있도록 비트코인에서는 PoW, Proof of Work, 작업증명 이라는 개념을 만들어 냈다. 이 작업증명은 자신이 이 블록을 만들기 위해 엄청난 노력을 했음을 증명해주는 내용이기도 하며, 현재 비트코인 채굴자들이 전세계 슈퍼컴퓨터는 아무것도 아니라는 엄청난 컴퓨팅 성능을 소모해서 하는 연산 또한 이 작업증명을 위한것이라고 보아도 된다.
이 파트에서는 이 작업증명이 무엇인지에 대해 다룬다.
비트코인에서 블록체인에 대한 설명에서 빠질 수없는것이 바로 블록 헤더이다. 그 이유는 위에서 말한 블록체인의 모든것이 블록 헤더에서 구현되어 있기 때문이다. 각 블록헤더는 바로 이전 블록헤더의 해시값을 가지고 있고, 각 블록의 해시값이 조작되지 않았음을 증명할 수단도 블록헤더에서 구현되어있다.
블록 헤더는 다음과 같은 정보를 가지고 있다.
| 크기 | 이름 | 설명 |
|---|---|---|
| 4Byte | Version | 블록 버전에 대한 정보가 담겨있다. |
| 32Byte | hashPrevBlock | 이전 블록 헤더의 해시값이 담겨있다. |
| 32Byte | hashMerkleRoot | 블록 바디의 머클 트리로부터 나온 머클루트값이 담겨있다. |
| 32Byte | Time | 유닉스 타임스탬프를 사용한다. |
| 4Byte | nBits | 이 블록헤더의 해시값이 충족해야할 조건에대한 정보가 담겨있다. |
| 4Byte | Nonce | nBits를 만족시키기위해 채굴자가 마음대로 조작가능한 공간이다.. |
여기서 블록체인과 관련되어 주의깊게 살펴보아야 할 사항은 hashPrevBlock, nBits 그리고 Nonce이다. 일단 hashPrevBlock는 이전 블록의 해시값으로 블록체인의 핵심이라 할 수 있다. 하지만 nBits와 Nonce는 무엇일까?
이에대한 설명을 하기 앞서 다음을 살펴보자. 다음은 400,000번째 블록헤더의 해시값이다.
000000000000000004ec466ce4732fe6f1ed1cddc2ed4b328fff5224276e3f6f
뭔가 이상하다. 앞쪽에 0이 좀 많다고 생각하지 않는가?
단순히 우연일지도 모르니 바로 그 다음블록인 400,001번쨰 블록헤더의 해시값을 살펴보자.
000000000000000005421b1b2ee6d06d037557d7f5ec96852542413cfed40c22
여기에도 엄청난 0이 존재한다. 그뿐이 아니다, 그 다음블록도
0000000000000000016578099aab6d26d41c8815e9ab5f204f505ba4ac3c084d
그 다음블록도
0000000000000000053c5d6913444bcef2a5a2a6ec84cb0dbaef93e6ad3074ba
로 모두 앞에 0이 많이 존재한다는 사실을 알아낼 수 있다.
일반적으로 발생하는 해시값은
ca2099f4706a7b28c5550b304d1f51ef61389617358b45d9714de5f2699638fe
이런 형태를 가진다는 점을 생각해 볼때 위와같이 앞쪽에 0이나온다는 것은 의도되었단 것일까?
맞다.
조금만 생각해보면 어떤 데이터의 해시값이 앞부분이 저렇게 0이 많이 나올 확률은 매우 희박하다는 것을 알 수 있을것이다. 그런데 만약 실제 그러한 데이터를 찾아냈다면, 이는 엄청난 우연의 일치로 그런 데이터를 찾아냈던가, 혹은 엄청나게 많은 데이터의 해시값을 돌려본 끝에 해시값이 앞에 0이 많이 나오는 형태를 찾아냈다고 할 수 있을것이다. 비트코인에서 작업증명이란 바로 이 과정을 말한다.
자 이제 희박한 확률로 나타나는 해시값을 찾아내는게 작업증명 과정이라는 사실을 알았다. 그럼 채굴자가 찾하야 하는 해시값의 조건과 그 조건을 만족하는 해시값을 찾아내는법, 마지막으로 그러한 해시값을 찾아낼 확률이 얼마나 희박할지 알아보자.
일단 해시값이 만족해야할 조건은 nBits에 표현되어 있다.
일단 해시값을 바라보는 시점을 달리해보자. 우리가 보기에 해시값은
ca2099f4706a7b28c5550b304d1f51ef61389617358b45d9714de5f2699638fe
와 같은 이상한 문자열의 나열이다. 하지만 좀더 자세히 들여다 보면 이 표현은 64개의 16진수 숫자로 표현된 256Bits짜리 데이터임을 확인할 수 있다.
ca 20 99 f4 70 6a 7b 28 c5 55 0b 30 4d 1f 51 ef 61 38 96 17 35 8b 45 d9 71 4d e5 f2 69 96 38 fe
이말은 위 문자열은 결국 16진수로 표현된 숫자열 이라는 소리이고 이를 10진수로 바꾸면 다음과 같은 큰 숫자가 탄생한다..
91424797077149544937923234949946345081157190717769025043989719253972906555646
여기서 작업증명이 만족해야할 조건은 nBits에 표현되어있으며, 그 조건이란 nBits에 표현된 값보다 작아야 한다는 것이다.
단 nBits에 부여된 저장공간의 크기는 4Byte이며 4Byte의 저장공간으로는 32Byte크기를 가지는 숫자열을 표현하지 못하기에 다음과 같이 자연과학분야에서 많이 사용하는 지수표기법의 아이디어를 채용하였다.

지수표기법
물리학, 화학, 천문학에서는 일상적으로 사용하지 않는 엄청 큰 단위나 반대로 엄청 작은 단위를 사용할 일이 많다. 그럴때 마다 0을 많이 사용해서 해당값을 표현하는건 보기도, 쓰기도 힘들다. 그래서 생겨난 방식이 지수표기법이다. 대표적으로 지수표기법을 사용했을때 우주의 나이로 추정되는 150억년이라는 숫자는
$$1.5\times10^{10}$$ 년으로, CPU 공정단위를 표현할때 자주 사용되는 22나노미터라는 숫자는 $$2.2\times10^{-8}$$m로 보기쉽게 표현 가능하다. 컴퓨터 내부에서도 실수형 자료를 표기할때 이런방법을 응용한다.
위 그림대로 nBits에 저장된 4Byte중 앞의 1Byte는 나타낼려는 수의 지수값을 나타내는데 사용되고 나머지 3Byte는 유효숫자를 의미한다. 말로하는것보다 예시를 보여주는게 이해하기가 쉬우니 400,000번째 블록의 경우를 살펴보자. 400,000번째 블록의 nBits는 0x1806B99F 로 이중 0x18은 10진수로 24를 의미하고 24에서 3을 뺸 21이 nBits가 나타내려는 숫자의 지수이다. 그리고 남은 0x06BB9F를
0x6BB9F000000000000000000000000000000000000000000
라는 숫자가 탄생한다. 그럼 400,000번째 블록의 해시값은 진짜 이 수보다 작을까?
nBits: 0x000000000000000006BB9F000000000000000000000000000000000000000000
블록헤더 해시: 000000000000000004ec466ce4732fe6f1ed1cddc2ed4b328fff5224276e3f6f
보는바와 같이 가장큰 단위의 숫자가 nBits는 6인 반면 400,000블록의 해시값은 4로 nBits보다 작은 것을 확인해 볼 수 있다.
그럼 400,000번째 블록을 생성할때 nBits보다 작은 해시값이 나올 확률은 얼마나 될까? 일단 어떤 데이터의 해시값은 16진수로 표현하면
0x0000000000000000000000000000000000000000000000000000000000000000부터
0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF사이의 그 어떠한 값도 올 수 있다. 이것을 다르게 표현하면 총
0x000000000000000006BB9F000000000000000000000000000000000000000000개, 10진수로 표현하면 약
이 둘을 고려해 어떤 데이터에 대하여 해시함수를 돌렸을때 nBits보다 작게 나올 확률은
1해분의 2, SI접두어로 표현하면 100엑사(Exa) 분의 2 정도의 확률이 된다. 이는 엄청나게 작은 확률로 이를 10분=600초에 한번씩 구해낼려면 초당 약 25경번 해시값을 탐색해 봐야한다. 물론 이정도 컴퓨터로 할수있지 않을까? 라는 생각을 가지시는분도 있겠지만 현재 시중에 판매되는 그래픽 카드의 최고사양으로 이러한 해시값을 탐색해보아도 초당 50메가(Mega)번을 탐색하지 못한다.
이렇게 각각의 블록헤더의 해시값은 nBits에 적힌 수에따라 천문학적으로 작은 확률로 탐색가능한 값을 가진다는 사실은 잘 알겠지만, 이러한 nBits의 값은 어떻게 정해지는 것일까?
비트코인에는 난이도라는 개념이 존재한다. 위 예시의 경우 400,000번째 블록의 nBits는 1해분의 2의 확률을 가지지만 2009년 처음 비트코인이 시작할때는 지금과 같은 대규모 채굴공장도 없었고 단지 초당 5~6천번 탐색할수있는 컴퓨터 몇대가 채굴을 했을 뿐이며 당연히 매 10분마다 작업증명이 완료된 블록을 만들어 낼 수 있었을리가 없다. 그럼 nBits의 값은 계속 변해야 하는데, 그 변해야하는 정도를 정하기 위해 비트코인에서는 난이도 라는 개념이 생겼다. 이 개념은 난이도가 10% 증가하면 nBits는 10%감소라는 느낌으로 난이도 증가비율의 역수가 nBits의 증가비율이 되도록 사용된다.
먼저 난이도는 다음과 같이 측정된다. 제일 먼저 사토시 나가모토가 만든 첫번째 블록의 난이도는 "1" 이다. 그리고 2160개의 블록이 새로 생성되면 2160개의 블록이 생성되기까지 걸린 시간T를 구한다. 마지막으로
400,000번째 블록의 경우 이러한 난이도는 값은 163,491,654,908.96으로, 이는 400,000번째 블록은 첫블록대비 163,491,654,908.96배 어려워지고, 400,000번째 블록의 nBits는 첫번째블록의 nBits보다 163,491,654,908.96배 작다는 의미로 해석할 수도 있다.
이렇게 블록헤더의 해시값이 작업증명과정을 거쳐서 일반적으로 나오기 매우 힘든 값이 나온다는 사실은 알아냈으나, 어떻게 그런 해시를 탐색하는가? 어떤 데이터A의 해시값이 1/2^256의 확률로 나온다는 사실은 알아냈으나, 그 다음으로 탐색해야할 데이터B는 어디서 나오는가? 가 Nonce와 관련된 부분이다.
해시함수, 특히 비트코인에서 애용하는 SHA2 해시함수의 경우 한가지 특징을 가지는데, 그것은 바로 어떤 데이터가 단 1비트만 변질되어도 예측 불가능한 전혀 다른 해시값이 나온다는 사실이다. 이를 사소한 변화가 엄청난 변화를 가져온다해서 눈사태 효과라고도 한다. Nonce는 해시함수의 이런 효과를 적극적으로 사용한다. 즉, 블록헤더의 해시값을 구하고 nBits에서 제시한 조건에 만족하지 않으면 Nonce를 1비트만 변질시켜서 다시 시도해 보는것이다. 이를 도식화 하면 다음과 같다.
st=>start: 블록헤더를 생성한다.
op=>operation: 블록헤더의 해시값을 구한다.
cond=>condition: 해시값이
nBits보다 작은가?
cond2=>operation: Nonce를 변질시킨다.
e=>end: 블록생성에 성공하였다.
st->op->cond
cond(yes)->e
cond(no)->cond2->op
이러면 모든게 해결된 것 같지만 아쉽게도 한가지 문제가 남는다. 그것은 바로 Nonce의 크기가 4Bytes밖에 안된다는 것이다. 이것이 왜 문제가 되냐면 Nonce가 표현할 수 있는 경우의 수가 2^32=4,294,967,296, 즉 약 40억개에 불과해 모든 경우의 수를 시도해보아도 1해분의 2의 확률로 성공하는 블록생성에 실패할 수 확률이 더 높다는 것이다. 이에대한 1차적인 해결책은 블록 헤더칸에 블록이 생성된 시간을 나타내는 TimeStamp이다. 이 값은 1990년 1월 1일 0시 0분 부터 몇초가 지났는지의 방법으로 시간을 기록하는데 약 40억개의 가능성을 시도해 보는동안 1초가 지날테고 현재 시간을 TimeStamp에다 갱신시켜 또 다른 40억개의 가능성을 시도해 볼 수 있다. 하지만 이또한 문제가 발생하는데 400,000번째 블록에 적혀있는 nBits조건에 부합하는 초당 탐색회수는 약 25경번 이다. 당연히 1초에 40억개의 가능성으로는 턱도 없다. 그래서 비트코인 개발자는 새로운 변조공간을 찾아냈는데 그것은 바로 코인베이스 거래이다. 앞서 밝힌것처럼 이 공간은 채굴자가 자유롭게 조작할 수 있으며 그 대표적인 예시로 사토시 나가모토가 적은 뉴스기사 제목이다. 이 공간을 조작하면 거래데이터 전체를 보증하는 머클트리의 각각의 해시값이 변하게 되고 블록헤더에 포함되어있는 머클루트의 값도 변하게 되어, 결국 또 다른 가능성을 탐색할 수 있는것이다. 현재 비트코인은 채굴과정에서 Nonce는 당연하고 이 공간까지 모두 이용해서 nBits에 충족하는 해시값을 구하기 위한 조작공간으로 삼고있다.
자 이제 비트코인의 채굴과정에 대해 모두 알아보았다. 이 채굴과정에 성공한 블록은 이제 다른 비트코인 네트워크로 전파되어 비트코인 전체에서 블록체인에 포함된 하나의 블록으로 인정받게 될 것이다. 이에대한 과정은 다음파트에서 알아볼것이다.
하지만 의문이 남는다. 비트코인의 작업증명방식은 확실히 그만한 연산과정을 거치지 않으면 블록을 완성할 수 없다. 이는 매우 이해하기 쉬운 상황으로 내가 연산한 만큼 연산하지 않았으면 조작 못해!라는 상황을 연출해준다. 그만큼 보안성은 인정받는다는 것이다. 다만, 그와 함께 낭비되는 자원도 엄청나다. 일단 비트코인의 경우 더 적은 전기로 더 뛰어낸 채굴성능을 자랑하기 위해 ASIC라는 비트코인 전용 채굴칩이 생겼으며 이 ASIC는 비트코인에서는 뛰어난 능력을 발휘하지만 그와 동시에 다른분야로는 전혀 써먹지 못할 아주 한정된 분야를 자랑한다. 또한 비트코인에서 해시값을 특정값보다 낮은값이 나오기위한 작업은 비트코인 외에서는 완전 쓸모가 없다. 마지막으로 이 채굴과정에서 소모되는 전기의 양은 아마 비트코인이 없었더라면 지구상에서 원전 하나쯤은 없앨 수 있지 않았을까 싶다.
이렇게 비트코인의 채굴과정을 낭비라고 본것이 필자뿐이 아닌가본지 현재 이에대한 여러가지 대안이 제시되었고 실제 구현되거나, 혹은 구현될려고 논의중인 방법들이 존재한다. 이에대해 잠깐 알아보도록 하자.
비트코인이 이러한 많은 연산과정을 요구하는 근본적인 이유는 "누굴 믿어야만 하는가?"에 대한 답으로 "많은 사람의 연산량 그 자체를 믿겠다!"라는 대답을 했기 때문이다. 반대로 전통적인 금융기관인 은행의 경우 "누굴 믿어야만 하는가?"에 대한 답으로 "은행 그 자체를 믿겠다!"라는 대답으로 컴퓨터가 없던 시기에도 사람의 머리와 주판으로 이 모든 과정을 구현할 수 있었다. 그럼 좀 더 구체적인 누군가를 믿으면 연산량이 적어지지 않을까? 그리고 블록체인이 붕괴되면 가장 피해를 많이보는 사람이 가장 믿을만하게 일하지 않을까? 라는 아이디어로 생긴게 PoS, Proof of Stake, 지분증명 이라는 방식이다.
이에대한 아이디어는 실로 간단하여 가상화폐의 경우 가상화폐를 가장 많이 보유한 사람이 가장 많은 지분을 가지고 있고, 지분을 가장 많이 가진사람이 블록을 생성할 권리를 가진다는 것이다. 만약 블록생성을 잘못한다면 해당 가상화폐의 신뢰도는 그 가치와 함께 급락할테니 제일 가상화폐가 붕괴되길 꺼려하는 사람일테고, 그만큼 제대로 블록을 생성할 것이라는 아이디어다.
물론 이리보면 간단해 보이기는 하지만 여러가지 현실적인 문제가 겹치는데, 지분을 가장 많이 가진사람이 항상 컴퓨터를 켜놓는다는 법은 없고 가상화폐 붕괴를 통해 이득을 볼수있는 사람이 (잘 상상하긴 힘들지만) 생겨나면 당연히 붕괴시키려 할것이다. 이를 해결하기 위해 Nxt, BlackCoin과 같은 가상화폐는 PoS와 PoW를 합쳐놨다. 즉, 개개인의 채굴자들은 채굴을 하고 채굴 결과를 내놓는데, 나온 해시값이 얼마나 작은지와 채굴자가 소유한 금액이 어느정도인지를 각 가상화폐에서 만든 특별한 함수에 따라 우선순위를 정하고 그 중 가장 높은 우선순위가 나온것을 인정한다는 것이다. 여기에 더해 PeerCoin이란 가상화폐는 금액을 얼마나 오래 보유하고 있었는지도 우선순위에 영향을 주는 형태로 PoS를 구현했다.
노트 : https://blog.ethereum.org/2015/08/01/introducing-casper-friendly-ghost/
비트코인 다음으로 유명한 이더리움에서 채용하려고하는 Casper라는 PoS기반 알고리즘에 대한 설명한 글입니다만......
제가 이해하기론 채굴자는 도박을 하고, 가장 많은 채굴자들이 배팅한 블록이 살아남는다..... 라는것 같은데, 제대로 이해했다는 확신이 없어 이에대한 글을 쓰지는 못했습니다. 저는 시간이 없어 이에대해 알아보지는 못했지만, 한번 알아보시고 쓸만한 가치가 있다 생각하시면 부디 한번 언급하는 형식으로 써주시기 바랍니다.
PBFT는 Practical Byzantine Fault Tolerance의 약자로 이름부터가 비잔티움 장군 문제를 해결하기 위한 방법이다. 1999년에 발표된 이 아이디어는 현재 비트코인과 같은 공개적인 블록체인이 아닌 소규모나 혹은 개인적으로 사용되는 블록체인에 자주 적용되며 기본적인 작동구조는 다음과 같다. Primary 노드 가 일단 추가되는 데이터를 모두 수집한 뒤 이 데이터를 나머지 모든 노드에게 전파시킨다. 그리고 나머지 노드들은 자신을 제외한 모든 노드에게 받은걸 그대로 전파시킨다. 그 다음에 각 노드는 자기가 받은 데이터중 가장 많이 받은 데이터 종류 (즉, 이 상황은 누군가 데이터를 변조시키는 상황을 가정한다.) 를 다시 각 노드로 전파시킨다. 그렇게 각 노드가 미리 약속해둔 수 이상의 같은 데이터를 받는다면 합의가 완료된 것이다. 합의에 실패했다면 그 후는 각 프로그램의 상황에 맞춰 적절히 대응하면 된다.
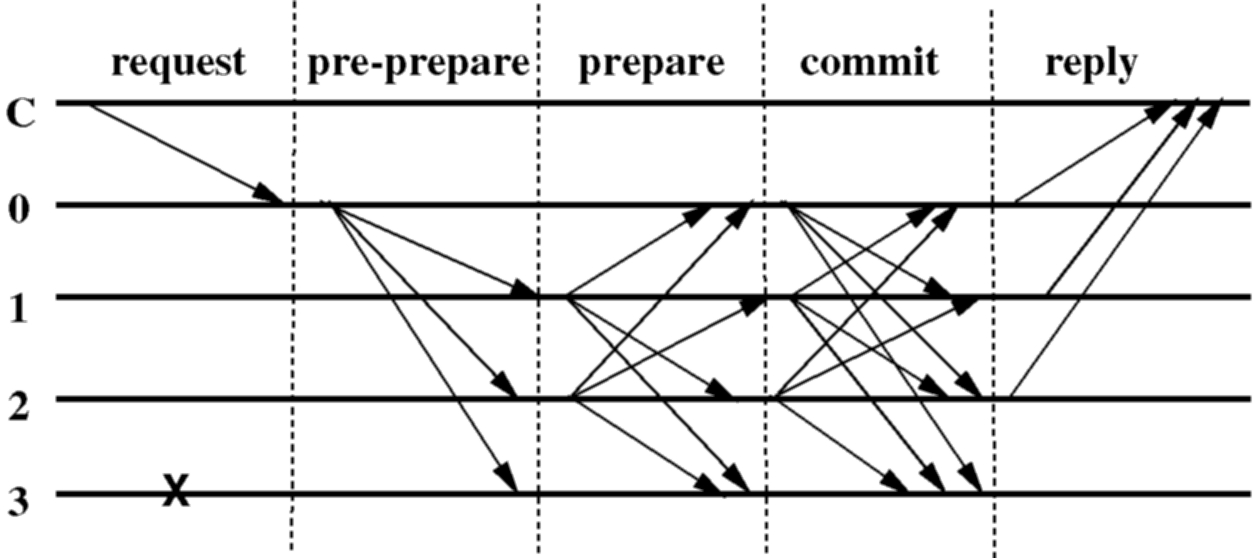
이러한 PBFT의 경우 수만명 이상이 사용하는 것을 전재로 하는 가상화폐의 경우 통신해야하는 양이 유저수가 늘어날때마다 N^2씩 증가하여 대규모 블록체인의 상황에는 사용하지 못하지만, 반대로 기업간 거래나 개인간 채팅같은 소규모 블록체인의 상황에 사용하기에는 명쾌하고 구현하기 간단하며 비록, 블록체인의 형태는 아니었지만 이미 어느정도 사용되어 오면서 검증된 방법이기 때문에, 현재 국민은행이 도입할 예정인 FidoLedger와 IBM이 발표한 IBM BlockChain 1.0이 이 아이디어를 사용했다고 알려져 있다.
비잔티움 장군 문제
먼 옛날 비잔티움제국(동로마 제국)의 장군들은 뒤돌아보면 서로의 등 뒤에 칼을 꽂을 수 있을정도로 서로 사이가 좋지 않았다. 어느날 황제가 이 장군들 보고 어느 도시를 점령하라고 명했고, 장군들은 고생끝에 해당 도시를 포위하는데 성공하였다. 여기서 문제가 발생했는데, 도시를 둘러싸고 있는 모든 장군들이 동시에 습격하지 않으면 이 전쟁은 패할것이 불보듯 뻔한 상황이었고 이제와서 모든 장군들을 모아서 습격 타이밍에 대해서 회의하기는 너무 늦었다. 그래서 서로가 서로에게 전령을 보내서 습격 타이밍을 정하기로 했다.
비잔티움 장군 문제의 배경스토리는 위와 같다. 이 문제는 컴퓨터 업계에
신뢰성을 보장할수 없는 분산적인 체계의 프로토콜을 어떻게 구현할수 있는가?에 대한 질문으로 해석되어 꽤 오랫동안 난제로 남은 문제인데 여기서 해결해야할 사항은 다음과 같다.
- 장군간의 물리적 거리가 상당해서 전령을 통한 통신 딜레이가 엄청나게 크다. A장군이 "아침 먹고 9시 습격 ㄱㄱ"라고 B에게 전령을 보내는것과 동시에 B장군이 A장군에게 "적들 일어날때 7시 기습 ㅇㅋ?"라고 보내고 각 전령이 새벽 2시에 출발해 아침 6시에 도착했다면 B장군이 뭘 해야할지는 되게 애매해지는 것이다.
- 장군들 속에 악의적인 장군이 섞여있어 8시에 공격한다고 합의해놓고 공격을 안할 수 도 있다. 이런경우 다른장군들은 심히 곤란해진다.
이를 컴퓨터 버전으로 적용시키면 다음 문제와 같아진다.
- 서로의 통신시간 문제때문에 합의 사항이 엇갈릴 수 있다. 비트코인에 비유하면 서로다른 두 채굴자에 의해 서로 다른해시값을 가지지만 블록체인에 들어가는데는 문제없는 블록이 동시에 탄생하였다. (이에대한 해결법은 블록전파에서 다룬다.)
- 어떤 악의적인 참여자에 의해 위조된 데이터가 돌아다닐 수 있다.
비트코인은 위 두가지 문제를 완벽히 해결한 사실상 첫 프로그램이라서 그 위상이 같이 높아졌다고 할 수 있다.
이더리움은 PoW에서 앞쪽의 블록헤더가 뒤쪽의 블록헤더를 보증하는 방식을 앞쪽의 블록이 뒤쪽의 블록 그 자체를 보증해주는 방법을 통하여, 위 다용도로 사용 불가한 ASIC의 과도생산 억제에 성공하였다. 그 원리는 실로 간단한데 ASIC는 해시연산에 특화되어있어 CPU나 GPU보다 훨씬 빠른속도로 해시연산을 할 수 있지만, 그 메모리에는 한계가 있어 특정 크기 이상의 데이터의 해시값을 구하는것이 불가능하다. 물론 대용량 메모리를 장착한 ASIC를 만드는 방법도 있지만 시중의 GPU를 사는것 대비 경제성이 떨어진다고 한다. 그럼 더 큰 데이터의 해시연산을 요구하면 ASIC 생산을 포기할테고 결국 채굴은 채굴 이외에도 다른 용도로 사용 가능한 CPU와 GPU로만 하게되고, 채굴자가 채굴을 포기할때는 해당 하드웨어를 다른용도로 사용 가능하기에 비트코인의 두 단점중 하나를 해결할 수 있다는 것이다.
물론 이러한 해결방법도 어느정도 선을 지나가면서 단점이 부각되었는데, 최근 한국에 가상화폐에 거품이 끼면서 채굴을 시도하려는 자가 늘었고, 이미 대규모 설비를 갖추고 특화 하드웨어를 소유한 기존 비트코인 채굴자를 이길수는 없으니 GPU로만 채굴이 가능하고 아직 진입장벽이 낮은 이더리움으로 신규 채굴자가 대거 나타나, 결국 그래픽카드 품귀사태와 함께 그래픽카드 가격이 크게 올라, 가상화폐와는 관계없는 일반인들에게까지 피해를 입히는 사태가 발생하였다. 무엇이든 도가 지나치면 안되는 법이다.
위 두 가상화폐는 비트코인의 작은 해시값 찾기가 완전 무의미하다는 점을 해결한 가상화폐이다. 프라임코인은 소수를 찾는것을 채굴의 목표로, 큐어코인은 단백질 접힘이란 현상을 시뮬레이션하는것을 채굴의 목표로 정했으며, 각각의 연산 결과를 각각 수학계와 생물학계에서 활용하여 새로운 과학적 발견으로 이끌어 나가는것을 궁극적인 목표로 삼고있는 가상화폐이다. 다만 아쉽게도 이 둘 이후 이러한 시도는 보이지가 않는다.