![]()
![]()



This repo provides a library for the differential optimisation of scattering muon tomography systems. For a quick overview, check out our abstract and poster from NeurIPS paper poster, and for a more in-depth guide, please read our first publication here (shortly to be published in IOP MLST).
{kind=link}
As a disclaimer, this is a library designed to be extended by users for their specific tasks: e.g. passive volume definition, inference methods, and loss functions. Additionally, optimisation in TomOpt can be unstable, and requires careful tuning by users. This is to say that it is not a polished product for the general public, but rather fellow researchers in the field of optimisation and muon tomography.
If you are interested in using this library seriously, please contact us; we would love to here if you have a specific use-case you wish to work on.
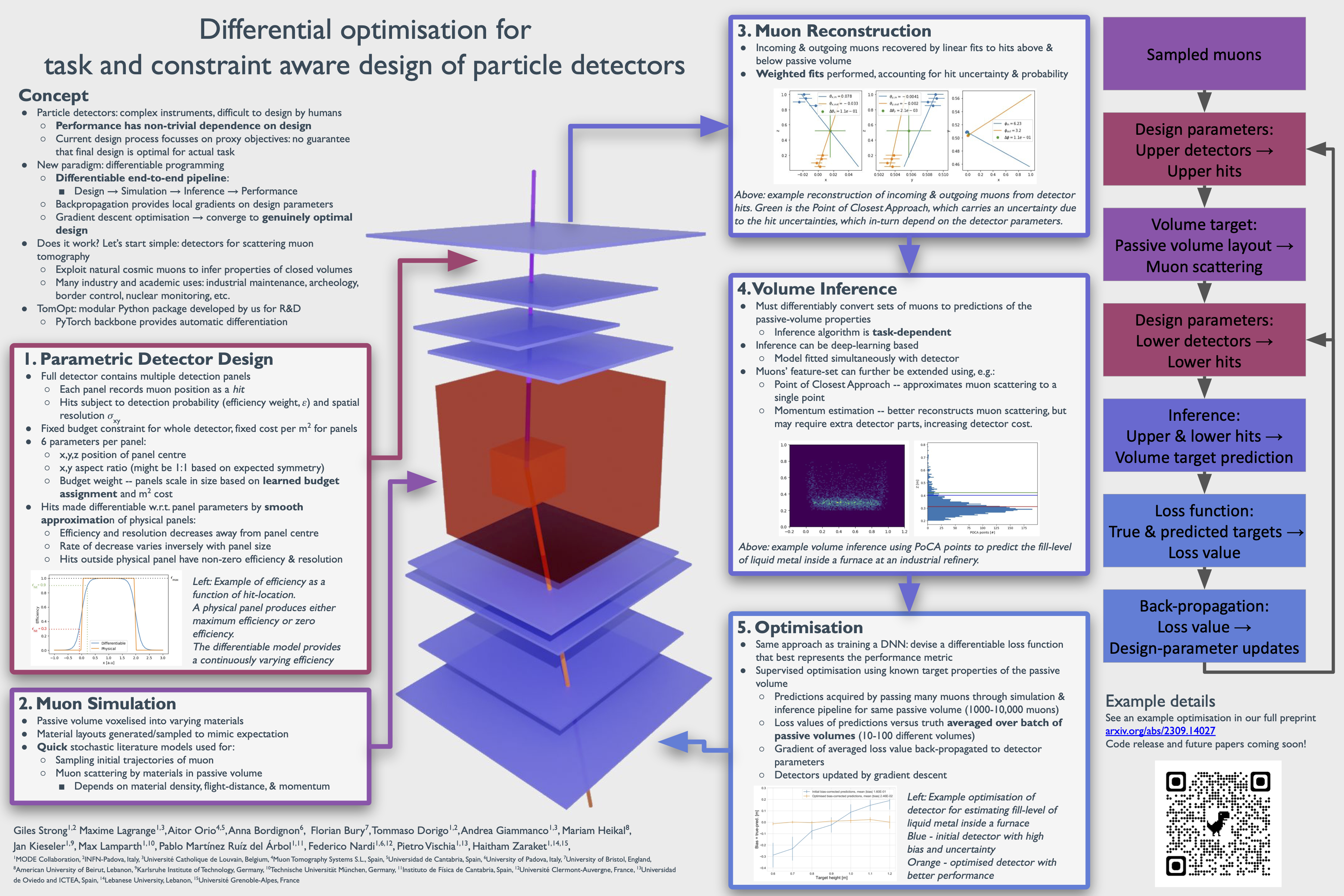
The TomOpt library is designed to optimise the design of a muon tomography system. The detector system is defined by a set of parameters, which are used to define the geometry of the detectors. The optimisation is performed by minimising a loss function, which is defined by the user. The loss function is evaluated by simulating the muon scattering process through the detector system and passive volumes. The information recorded by the detectors is then passed through an inference system to arrive at a set of task-specific parameters. These are then compared to the ground truth, and the loss is calculated. The gradient of the loss with respect to the detector parameters is then used to update the detector parameters.
The TomOpt library is designed to be modular, and to allow for the easy addition of new inference systems, loss functions, and passive volume definitions. The library is also designed to be easily extensible to new optimisation algorithms, and to allow for the easy addition of new constraints on the detector parameters.
TomOpt consists of several submodules:
- benchmarks: and ongoing collection of concrete implementations and task-specific extensions that are used to test the library on real-world problems.
- inference: provides classes that infer muon-trajectories from detector data, and infer properties of passive volumes from muon-trajectories.
- muon: provides classes for handling muon batches, and generating muons from literature flux-distributions
- optimisation: provides classes for handling the optimisation of detector parameters, and an extensive callback system to modify the optimisation process.
- plotting: various plotting utilities for visualising the detector system, the optimisation process, and results
- volume: contains classes for defining passive volumes and detector systems
- core: core objects used by all parts of the code
- utils: various utilities used throughout the codebase
For dependency usage, tomopt can be installed via e.g.
pip install tomoptCheck out the repo locally:
git clone git@github.com:GilesStrong/tomopt.git
cd tomoptFor development usage, we use poetry to handle dependency installation.
Poetry can be installed via, e.g.
curl -sSL https://install.python-poetry.org | python3 -
poetry self updateand ensuring that poetry is available in your $PATH
TomOpt requires python >= 3.10. This can be installed via e.g. pyenv:
curl https://pyenv.run | bash
pyenv update
pyenv install 3.10
pyenv local 3.10Install the dependencies:
poetry install
poetry self add poetry-plugin-export
poetry config warnings.export false
poetry run pre-commit installFinally, make sure everything is working as expected by running the tests:
poetry run pytest testsFor those unfamiliar with poetry, basically just prepend commands with poetry run to use the stuff installed within the local environment, e.g. poetry run jupyter notebook to start a jupyter notebook server. This local environment is basically a python virtual environment. To correctly set up the interpreter in your IDE, use poetry run which python to see the path to the correct python executable.
A few examples are included to introduce users and developers to the TomOpt library. These take the form of Jupyter notebooks. In examples/getting_started there are four ordered notebooks:
00_Hello_World.ipynbaims to show the user the high-level classes in TomOpt and the general workflow.01_Indepth_tutorial_single_cycle.ipynbaims to show developers what is going on in a single update iteration.02_Indepth_tutotial_optimisation_and_callbacks.ipynbaims to show users and developers the workings of the callback system in TomOpt03_fixed_budget_mode.ipynbaims to show users and developers how to optimise such that the detector maintains a constant cost.
In examples/benchmarks there is a single notebook that covers the optimisation performed in our first publication, in which we optimised a detector to estimate the fill-height of a ladle furnace at a steel plant. As a disclaimer, this notebook may not fully reproduce our result, and is designed to be used in an interactive manner by experienced users.
If you want to run notebooks on a remote cluster but access them on the browser of your local machine, you need to forward the notebook server from the cluster to your local machine.
On the cluster, run:
poetry run jupyter notebook --no-browser --port=8889
On your local computer, you need to set up a forwarding that picks the flux of data from the cluster via a local port, and makes it available on another port as if the server was in the local machine:
ssh -N -f -L localhost:8888:localhost:8889 username@cluster_hostname
The layperson version of this command is: take the flux of info from the port 8889 of cluster_hostname, logging in as username, get it inside the local machine via the port 8889, and make it available on the port 8888 as if the jupyter notebook server was running locally on the port 8888
You can now point your browser to http://localhost:8888/tree (you will be asked to copy the server authentication token, which is the number that is shown by jupyter when you run the notebook on the server)
If there is an intermediate machine (e.g. a gateway) between the cluster and your local machine, you need to set up a similar port forwarding on the gateway machine. The crucial point is that the input port of each machine must be the output port of the machine before it in the chain. For instance:
jupyter notebook --no-browser --port=8889 # on the cluster
ssh -N -f -L localhost:8888:localhost:8889 username@cluster_hostname # on the gateway. Makes the notebook running on the cluster port 8889 available on the local port 8888
ssh -N -f -L localhost:8890:localhost:8888 username@gateway_hostname # on your local machine. Picks up the server available on 8888 of the gateway and makes it available on the local port 8890 (or any other number, e.g. 8888)
N.B. Most are not currently public
- tomo_deepinfer (contact @GilesStrong for access) separately handles training and model definition of GNNs used for passive volume inference. Models are exported as JIT-traced scripts, and loaded here using the
DeepVolumeInfererclass. We still need to find a good way to host the trained models for easy download. - mode_muon_tomography_scattering (contact @GilesStrong for access) separately handles conversion of PGeant model from root to HDF5, and Geant validation data from csv to HDF5.
- tomopt_sphinx_theme public. Controls the appearance of the docs.
The TomOpt project, and its continued development and support, is the result of the combined work of many people, whose contributions are summarised in the author list