#Clasificación HIT Table of Contents
[TOCM]
[TOC]
#Clasificación HIT Clasificación de hit(s), mediante anfis. Clasificación conocida en la literatura como 'hit song science', que hace referencia a la deteción de atributos dentro de las canciones que genean un hit en el mercado.
Para este proyecto nos centramos en clasificar una canción en dos categorías Hit y NO Hit, haciendo uso de validación cruzada y variables encontradas en una base de datos de la empresa Spotify.
Lo primero que tuvimos en cuenta fue la cantidad de datos que tenia la base de datos, 15 variables de entrada, para escoger las mejores entradas, realizamos el proceso de correlación entre las columnas (variables).
De está manera se tomaron las 4 variables que menor correlación positiva tienen con la variable objetivo de clasificación 'popularity' Explicar matriz de dispersión.
El método utilizado para este proyecto, está dividido en varias partes. Lo primero es generar 5 bases de datos, para realizar el proceso de validación cruzada. Para realizar estas subdivisiones de la base de datos y no alterar la distribución de los datos, se separo haciendo uso de la variable año.
A continuación se plantearon 21 casos para el entrenamiento de cada uno de los modelos anfis, los primeros casos mantienen el numero de reglas del primer proyecto, variando tan solo de a un parametro (numero de reglas, numero de iteraciones, tasa de aprendizaje y numero de corridas). * el experimento con 240 reglas fue imposible de realizar pues el computador no podia después de la 3 corrida, por lo que al final tan solo tenemos 20 experimentos.
Con está planeación se pasa a realizar el entrenamiento como se muestra en la grafica, donde conseguiremos un mejor fis y los calculos de error para cada caso, como se muestra en las tablas a continuación, es importante tener en cuenta que los criterios para la optencion de el mejor FIS son el error de validación y las varianzas.
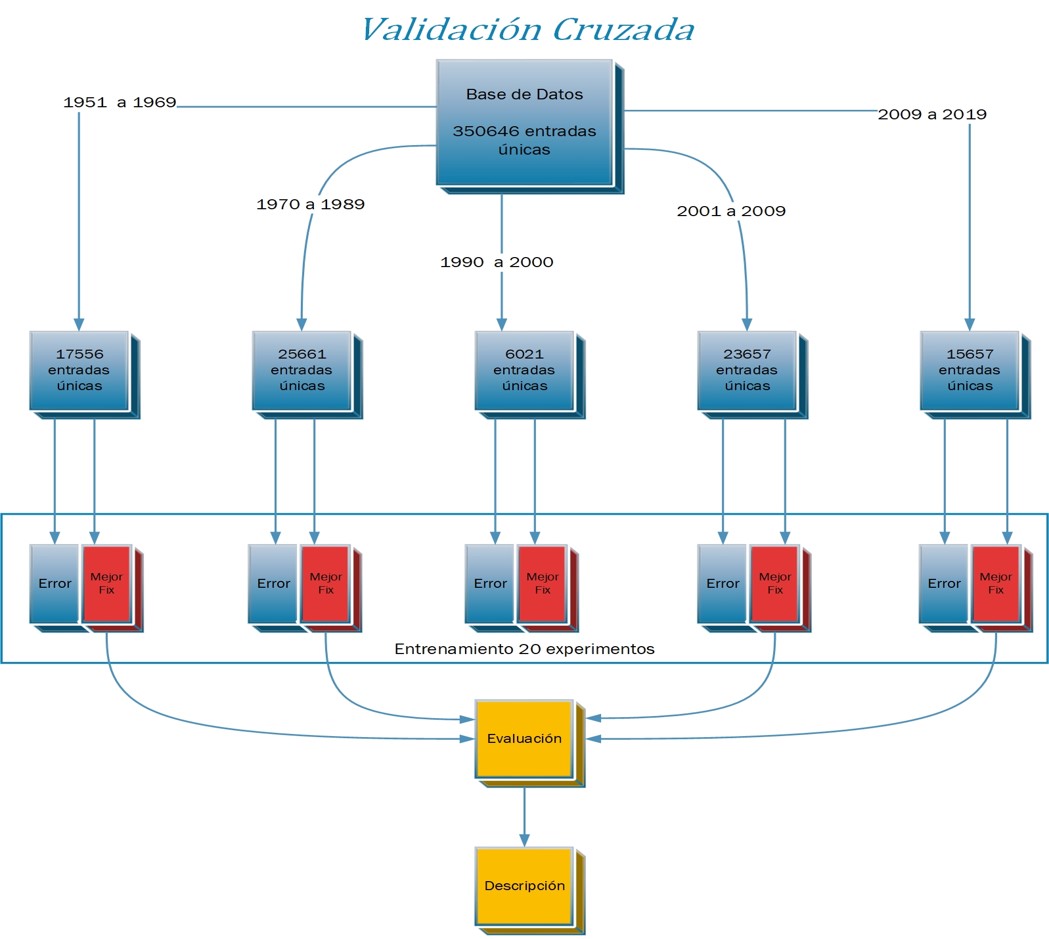
Para el análisis de datos se tomo en cuenta tan solo los 3 mejores FIS, es decir los resultados de las bases de datos 3, 4 y 5.
Despues de realizar el entrenamiento y tener todos los experimentos, se procesde a selecionar los mejores 3 modelos, estos se tomaron buscando el menor error de validacion y una Varianza final mayor a la varianzan incial. Los 3 modelos son los mostrados, estos se les puso a prueba para obtener el error de clasificación, que no es mucho mejor que el primer proyecto, el uso de error de validación no resulta un indicativo adecuado para el problema tratado.
Aqui podemos ver la matris de confunsion para cada modelo, es notable como el segundo modelo tiene mejores resultados que los demas.